前言
- 运气不错,这次压线前10,不过和top还是有差距的
- 数据包括问题和答案可以在比赛官网获取,包括初赛的100题和复赛100题。赛题为输入query输出answer,通过搭建Search Agent,分解问题、多跳搜索识别线索,找到最佳答案,并用题目要求的规范格式进行回答,题目和答案例如
python
"question": "一位物理学领域的学者为一种经典棋盘游戏设计的评分系统,后来被一家北美游戏公司广泛应用于其一款多人在线战术竞技游戏中。这家公司的母公司是一家亚洲科技巨头,该巨头在21世纪10年代完成了对前者的全资收购,并涉足量子计算等前沿科技领域。在这家北美公司开发的另一款第一人称射击游戏中,有一件适合近距离作战的武器,其名称与上述亚洲巨头代理发行的一款格斗手游中的一名在登场角色中年龄偏大的武术教官角色相同。这款格斗手游的名字是什么?"
"answer": "魂武者"- 答案规则:赛题的答案,如果是实体,取名顺序为百度百科>英文wiki>中文wiki,没有特殊说明情况下,答案语言和题目语言一致
- 可以参考的解决方案:阿里的deepresearch
- 比赛限制为,LLM上只能使用阿里的大模型API,禁止微调模型。可以使用Google/bing/阿里IQS等web search(网络搜索api的普通搜索模式)和jina,禁止调用Tavily的websearch;每个问题总时长要求10分钟以内
方案
- 链接:https://github.com/DXWEIE/tianchi_deepresearch_agent
- 架构:ReACT + Best of N
- 搜索引擎:中文使用DDGS、阿里IQS;英文在此基础上使用google;同时如果触发了wiki搜索,分别使用wikipedia和阿里IQS(搜"xxx 百度百科")
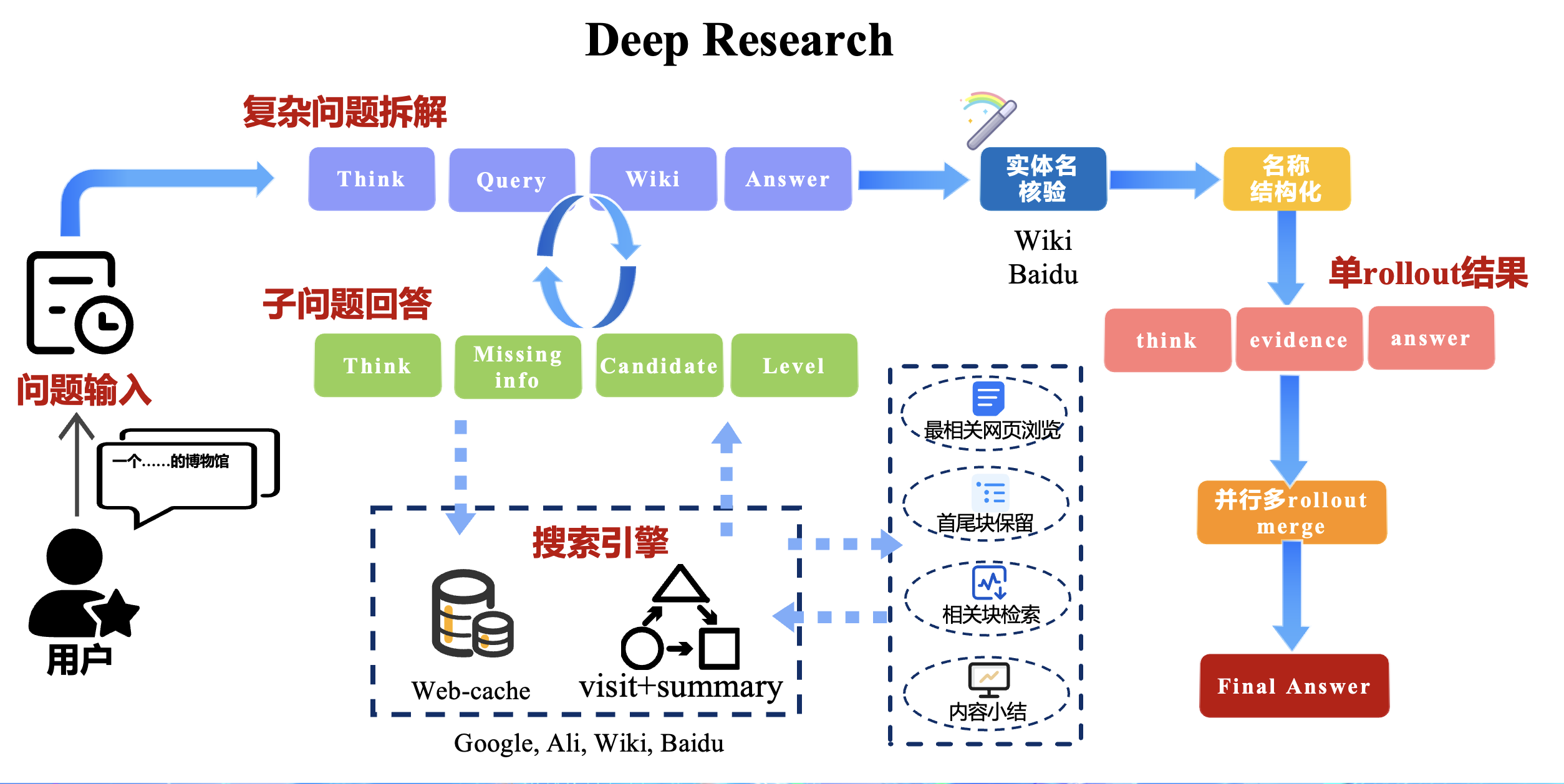
经验记录
- 先把最简单的react跑通,然后再尝试提升效果
- qwen3.5的效果一般,速度也比较慢,优先使用qwen3-max>qwen3.5>qwen3-plus
- 先提升单个链路的能力,最后再尝试并发多rollout然后merge结果取best的
- 后续等看完top的代码更~