总览导航:前馈式 3DGS 研究地图:七条路线背后的真正分歧是什么
- [0. 导言:为什么前馈式 3DGS 值得单独写一篇总览](#0. 导言:为什么前馈式 3DGS 值得单独写一篇总览)
- [1. 3DGS 为什么会走向前馈式](#1. 3DGS 为什么会走向前馈式)
-
- [1.1 optimization-based 3DGS 的成功与边界](#1.1 optimization-based 3DGS 的成功与边界)
- [1.2 前馈式 3DGS 的核心目标到底是什么](#1.2 前馈式 3DGS 的核心目标到底是什么)
- [1.3 为什么"前馈式"不是实现细节,而是研究对象变化](#1.3 为什么“前馈式”不是实现细节,而是研究对象变化)
- [2. optimization-based 与 feed-forward 的根本差别](#2. optimization-based 与 feed-forward 的根本差别)
-
- [2.1 五个维度的系统比较](#2.1 五个维度的系统比较)
- [2.2 数学上:求解器与映射器的差别](#2.2 数学上:求解器与映射器的差别)
- [2.3 工程部署属性:为什么企业会偏爱前馈式](#2.3 工程部署属性:为什么企业会偏爱前馈式)
- [3. 三轴 taxonomy:表示、几何推理、输入/任务](#3. 三轴 taxonomy:表示、几何推理、输入/任务)
-
- [3.1 表示轴:Gaussian Map vs Gaussian Volume / Structured 3D Latent](#3.1 表示轴:Gaussian Map vs Gaussian Volume / Structured 3D Latent)
- [3.2 几何推理轴:Gaussian center / placement 从何而来](#3.2 几何推理轴:Gaussian center / placement 从何而来)
-
- [(1)概率深度 / 可微采样](#(1)概率深度 / 可微采样)
- [(2)cost volume / plane sweeping](#(2)cost volume / plane sweeping)
- [(3)depth foundation 注入 / foundation geometry / pointmap](#(3)depth foundation 注入 / foundation geometry / pointmap)
- [(4)token-level global aggregation](#(4)token-level global aggregation)
- [(5)structured latent reasoning 与 adaptive primitive detection](#(5)structured latent reasoning 与 adaptive primitive detection)
- [3.3 输入与任务轴:posed、pose-free、single-image、generative coupling](#3.3 输入与任务轴:posed、pose-free、single-image、generative coupling)
-
- (1)已知位姿稀疏视图
- [(2)无位姿 / 非标定图像集合](#(2)无位姿 / 非标定图像集合)
- (3)单图对象重建
- [(4)generative coupling](#(4)generative coupling)
- [4. 七个方法簇总图:七条路线背后的真正分歧是什么](#4. 七个方法簇总图:七条路线背后的真正分歧是什么)
-
- [4.1 路线一:像素对齐 / 概率式高斯图](#4.1 路线一:像素对齐 / 概率式高斯图)
- [4.2 路线二:几何优先 / cost volume / depth-first](#4.2 路线二:几何优先 / cost volume / depth-first)
- [4.3 路线三:LRM / Transformer / 大重建模型](#4.3 路线三:LRM / Transformer / 大重建模型)
- [4.4 路线四:Pose-free / Uncalibrated / Foundation Geometry](#4.4 路线四:Pose-free / Uncalibrated / Foundation Geometry)
- [4.5 路线五:Structured 3D Latents / Triplane / Gaussian Volume / Voxel-Aligned](#4.5 路线五:Structured 3D Latents / Triplane / Gaussian Volume / Voxel-Aligned)
- [4.6 路线六:Adaptive Primitive Placement](#4.6 路线六:Adaptive Primitive Placement)
- [4.7 路线七:Generative Coupling / 3D Asset Creation](#4.7 路线七:Generative Coupling / 3D Asset Creation)
- [5. 从 2023 到 2026:关键拐点与演化逻辑](#5. 从 2023 到 2026:关键拐点与演化逻辑)
-
- [5.1 拐点一:pixelSplat 让"前馈式 3DGS"成为成立的问题](#5.1 拐点一:pixelSplat 让“前馈式 3DGS”成为成立的问题)
- [5.2 拐点二:MVSplat / DepthSplat 表明 center prediction 正回归为几何问题](#5.2 拐点二:MVSplat / DepthSplat 表明 center prediction 正回归为几何问题)
- [5.3 拐点三:GRM / GS-LRM / Long-LRM 表明全局 token 聚合进入主舞台](#5.3 拐点三:GRM / GS-LRM / Long-LRM 表明全局 token 聚合进入主舞台)
- [5.4 拐点四:PF3plat / SelfSplat / Splatt3R / AnySplat 让 pose-free 成为核心竞争维度](#5.4 拐点四:PF3plat / SelfSplat / Splatt3R / AnySplat 让 pose-free 成为核心竞争维度)
- [5.5 拐点五:LaRa / VolSplat 表明 3D structured latent 开始取代纯 pixel-aligned 思路](#5.5 拐点五:LaRa / VolSplat 表明 3D structured latent 开始取代纯 pixel-aligned 思路)
- [5.6 拐点六:Off The Grid 表明 primitive placement 从回归走向检测 / 分配](#5.6 拐点六:Off The Grid 表明 primitive placement 从回归走向检测 / 分配)
- [5.7 拐点七:LGM 等工作说明前馈式 3DGS 正变成 3D 资产生成接口](#5.7 拐点七:LGM 等工作说明前馈式 3DGS 正变成 3D 资产生成接口)
- [6. 当前最核心的三个瓶颈](#6. 当前最核心的三个瓶颈)
-
- [6.1 几何可靠性仍未被根治](#6.1 几何可靠性仍未被根治)
- [6.2 primitive placement 仍缺乏真正自由的 3D 组织机制](#6.2 primitive placement 仍缺乏真正自由的 3D 组织机制)
- [6.3 评价协议正在分裂](#6.3 评价协议正在分裂)
- [7. 为什么这些问题会自然导向下一阶段](#7. 为什么这些问题会自然导向下一阶段)
-
- [7.1 geometry-first 与 foundation geometry 的深耦合](#7.1 geometry-first 与 foundation geometry 的深耦合)
- [7.2 structured 3D latent 会成为统一接口](#7.2 structured 3D latent 会成为统一接口)
- [7.3 confidence / uncertainty-aware Gaussian prediction](#7.3 confidence / uncertainty-aware Gaussian prediction)
- [7.4 adaptive primitive placement 会成为关键分水岭](#7.4 adaptive primitive placement 会成为关键分水岭)
- [7.5 feed-forward reconstruction 与 generative asset creation 会进一步耦合](#7.5 feed-forward reconstruction 与 generative asset creation 会进一步耦合)
- [7.6 更统一的 benchmark 与 evaluation protocol](#7.6 更统一的 benchmark 与 evaluation protocol)
- [8. 本系列文章接下来怎么展开](#8. 本系列文章接下来怎么展开)
-
- [8.1 Part I:前馈式 3DGS 的起步范式:从像素到高斯](#8.1 Part I:前馈式 3DGS 的起步范式:从像素到高斯)
- [8.2 Part II:前馈式 3DGS 的 depth-first 转向](#8.2 Part II:前馈式 3DGS 的 depth-first 转向)
- [8.3 Part III:Transformer 如何重写前馈式 3DGS 的信息聚合方式](#8.3 Part III:Transformer 如何重写前馈式 3DGS 的信息聚合方式)
- [8.4 Part IV:Pose-Free 前馈式 3DGS:从实验室输入走向真实世界图像集合](#8.4 Part IV:Pose-Free 前馈式 3DGS:从实验室输入走向真实世界图像集合)
- [8.5 Part V:结构化潜空间与高斯体:前馈式 3DGS 的下一代表示基座](#8.5 Part V:结构化潜空间与高斯体:前馈式 3DGS 的下一代表示基座)
- [8.6 Part VI:Adaptive Placement and Generative Coupling in Feed-Forward 3DGS](#8.6 Part VI:Adaptive Placement and Generative Coupling in Feed-Forward 3DGS)
- [9. 结语](#9. 结语)
- 总参考文献
-
- [A. 综述、总览与研究地图](#A. 综述、总览与研究地图)
- [B. 基础方法、前置谱系与桥接工作](#B. 基础方法、前置谱系与桥接工作)
- [C. 前馈式 3DGS 主干论文池](#C. 前馈式 3DGS 主干论文池)
-
- [C1. 路线一:像素对齐 / 概率式高斯图](#C1. 路线一:像素对齐 / 概率式高斯图)
- [C2. 路线二:几何优先 / Cost Volume / Depth-first](#C2. 路线二:几何优先 / Cost Volume / Depth-first)
- [C3. 路线三:LRM / Transformer / 大重建模型](#C3. 路线三:LRM / Transformer / 大重建模型)
- [C4. 路线四:Pose-Free / Uncalibrated / Foundation Geometry](#C4. 路线四:Pose-Free / Uncalibrated / Foundation Geometry)
- [C5. 路线五:Structured 3D Latents / Triplane / Gaussian Volume / Voxel-Aligned](#C5. 路线五:Structured 3D Latents / Triplane / Gaussian Volume / Voxel-Aligned)
- [C6. 适应性放置 / 预算控制 / 语义扩展](#C6. 适应性放置 / 预算控制 / 语义扩展)
- [D. 生成耦合、内容创建与后处理扩展](#D. 生成耦合、内容创建与后处理扩展)
系列文章全文导航(总览篇)
Part I:前馈式 3DGS 的起步范式:从像素到高斯
[Part II:前馈式 3DGS 的 depth-first 转向](#Part II:前馈式 3DGS 的 depth-first 转向)
[Part III:Transformer 如何重写前馈式 3DGS 的信息聚合方式](#Part III:Transformer 如何重写前馈式 3DGS 的信息聚合方式)
[Part IV:Pose-Free 前馈式 3DGS:从实验室输入走向真实世界图像集合](#Part IV:Pose-Free 前馈式 3DGS:从实验室输入走向真实世界图像集合)
[Part V:结构化潜空间与高斯体:前馈式 3DGS 的下一代表示基座](#Part V:结构化潜空间与高斯体:前馈式 3DGS 的下一代表示基座)
[Part VI:Adaptive Placement and Generative Coupling in Feed-Forward 3DGS](#Part VI:Adaptive Placement and Generative Coupling in Feed-Forward 3DGS)
0. 导言:为什么前馈式 3DGS 值得单独写一篇总览
3D Gaussian Splatting 在 2023 年由 Kerbl 等工作确立为一个极强的场景表示与实时渲染范式:它以各向异性 3D Gaussian 作为显式 primitive,通过可微 splatting 与 density control,在 scene-specific optimization 设定下同时拿到了高视觉质量与实时渲染能力。
也正因为它太成功,问题很快不再是"能不能把一个场景优化出来",而是"能不能把 3D Gaussian 当作一种可学习、可泛化、可批量生成 的三维资产接口"。这正是 pixelSplat 之后整个 feed-forward 方向爆发的根因。(arXiv)
形式上,optimization-based 3DGS 与 feed-forward 3DGS 的差别可写为两类不同的问题:
G ^ s = arg min G ∑ i = 1 N s L render ! ( R ( G , P i ) , I i ) + λ , Ω ( G ) , (1) \hat{\mathcal G}s= \arg\min{\mathcal G} \sum_{i=1}^{N_s} \mathcal L_{\text{render}} !\left( R(\mathcal G,\mathbf P_i),\mathbf I_i \right) + \lambda ,\Omega(\mathcal G), \tag{1} G^s=argGmini=1∑NsLrender!(R(G,Pi),Ii)+λ,Ω(G),(1)
其中 G \mathcal G G 是某一个场景 s s s 的高斯集合, I i , P i \mathbf I_i,\mathbf P_i Ii,Pi 分别是第 i i i 张图像及其相机参数, R ( ⋅ ) R(\cdot) R(⋅) 是 splatting renderer, Ω \Omega Ω 表示 density control、正则项或结构先验。这个式子本质上是逐场景求解。
而前馈式 3DGS 追求的是:
G ^ = F θ ( I i , P i ? ∗ i = 1 N ) , or ( G ^ , P ^ ∗ 1 : N ) = F θ ( I i i = 1 N ) , (2) \hat{\mathcal G}= F_\theta \big( {\mathbf I_i,\mathbf P_i?}*{i=1}^{N} \big), \qquad \text{or} \qquad (\hat{\mathcal G},\hat{\mathbf P}*{1:N})= F_\theta({\mathbf I_i}_{i=1}^{N}), \tag{2} G^=Fθ(Ii,Pi?∗i=1N),or(G^,P^∗1:N)=Fθ(Iii=1N),(2)
即学习一个跨场景映射 F θ F_\theta Fθ,一次前向就给出 Gaussian field,甚至连 pose 一并预测。式 ( 2 ) (2) (2) 不是式 ( 1 ) (1) (1) 的工程加速版,而是把"场景重建"重写成了"3D 表示生成 "问题。(arXiv)
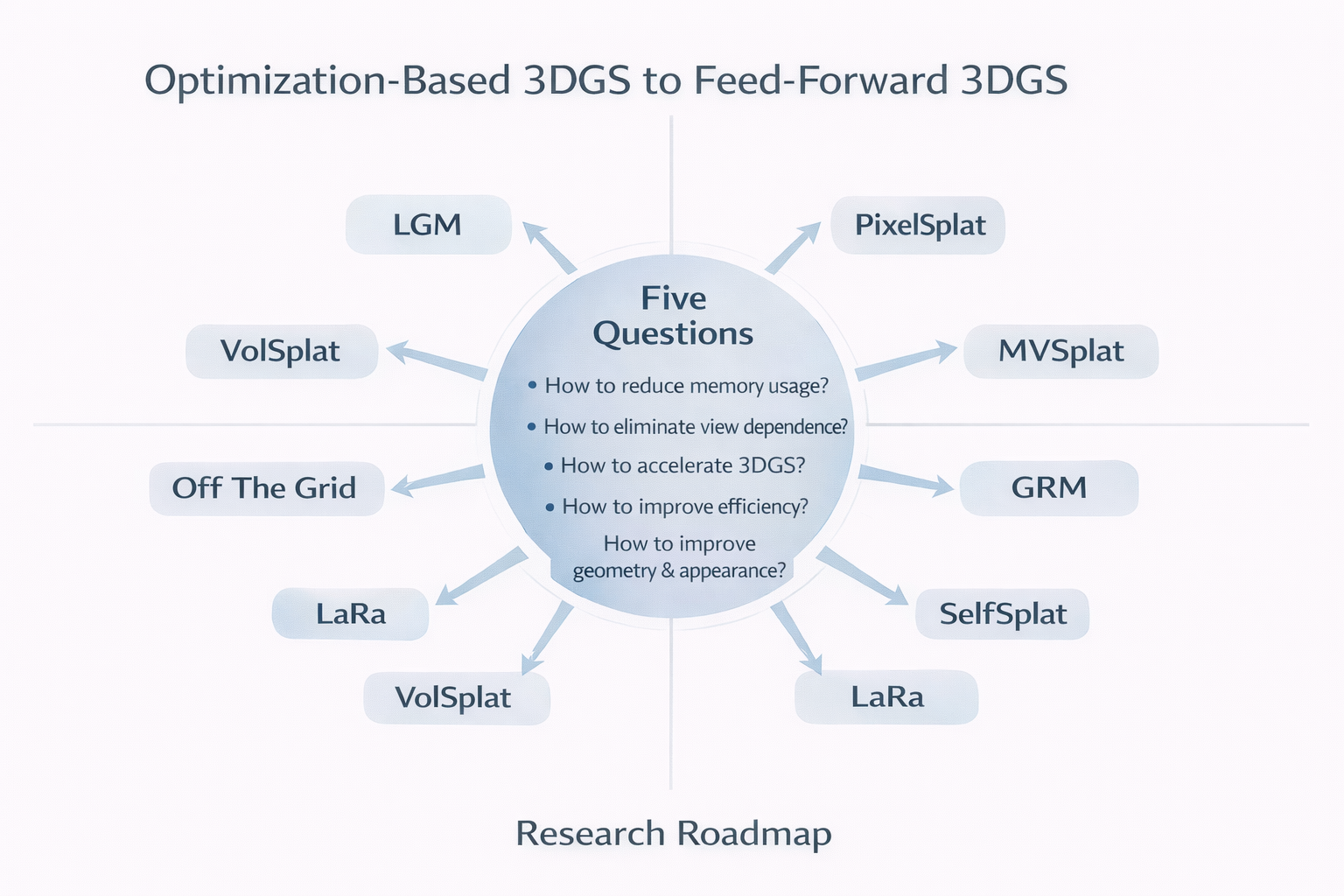
本文的中心论点是:前馈式 3DGS 的发展,不是单线提速,而是围绕五个问题不断重排方法结构:高斯从哪里来、高斯如何放置、多视图信息怎样对齐、是否需要显式位姿、能否成为可生成可编辑可分发的 3D 资产。
pixelSplat、MVSplat、GRM、SelfSplat、LaRa、VolSplat、Off The Grid、LGM 之所以值得被串成一条链,不是因为它们按年份接力,而是因为它们在不断上移整个 field 的主问题。(arXiv)
1. 3DGS 为什么会走向前馈式
1.1 optimization-based 3DGS 的成功与边界
3DGS 的原始成功来自一个非常强的工程折中:用显式高斯替代隐式 MLP 场表示,使表示、优化与渲染三者之间取得了新平衡。它在多视图重建与 novel view synthesis 上表现出极高的训练效率和实时渲染能力,但它依然需要针对每个场景单独优化 ,对输入 pose、初始化点云以及场景级 photometric fitting 具有较强依赖。换句话说,它解决的是"如何把这个 场景优化好",而不是"如何从任意 输入快速生成 3D 资产"。(arXiv)
工程上这意味着几个天然上限。第一 ,scene-specific pipeline 难以支撑大规模批量资产生产。第二 ,跨场景泛化能力不在问题定义之内。第三 ,部署链路更像"求解器"而不是"推理器",这与内容生产平台、实时上云、交互式 3D AIGC、移动端生成等需求并不完全匹配。(arXiv)
1.2 前馈式 3DGS 的核心目标到底是什么
前馈式 3DGS 的核心目标,不是把优化时间从几十分钟压到几秒,而是学习一个从图像集合到 Gaussian field 的通用映射函数 。pixelSplat 已经明确把这个问题写成"从图像对直接预测可渲染 3D Gaussian primitives";MVSplat 进一步把它扩展到 sparse multi-view posed 输入;GRM、GS-LRM、Long-LRM 则把它推向"大重建模型"叙事。(arXiv)
因此,前馈式 3DGS 与 generalized reconstruction / generalized novel view synthesis 的关系不是"相关",而是"同源"。本质上,它是 generalized 3D reconstruction 在 explicit Gaussian representation 上的落地形态:
一方面继承 generalized radiance field 的目标,即跨场景泛化;
另一方面继承 3DGS 的优势,即显式 primitive、实时渲染、资产可导出。(arXiv)
1.3 为什么"前馈式"不是实现细节,而是研究对象变化
如果研究对象还是"单场景最优拟合",那么快一点慢一点只是工程实现问题;但一旦研究对象变成"从输入直接生成 3D 表示",问题就会立刻切换成 representation learning、geometric prior、cross-view aggregation、pose relaxation、uncertainty estimation、asset usability 等更高层的结构性问题。(arXiv)
这也是为什么 feed-forward 3DGS 值得单独建立方法地图。 真正的分歧不在于谁更快、谁更准,而在于:
- 用什么 representation 承载高斯;
- 用什么机制决定 Gaussian center;
- 多视图信息在 2D、3D 还是 latent 空间对齐;
- pose 是输入前提、联合预测,还是被 foundation geometry 吸收;
- 输出是为了 reconstruction,还是为了 3D asset creation。
2. optimization-based 与 feed-forward 的根本差别
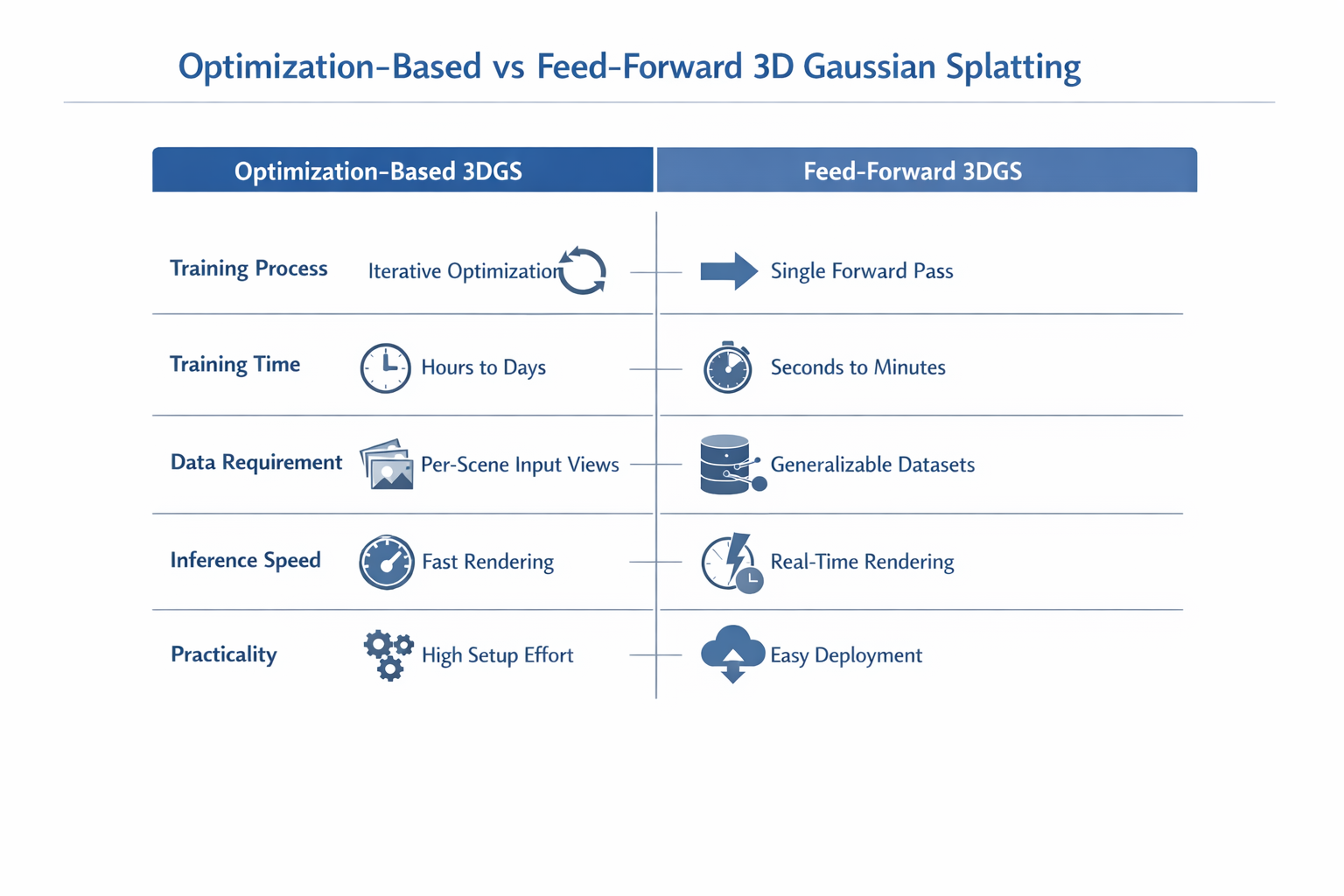
2.1 五个维度的系统比较
| 维度 | optimization-based 3DGS | feed-forward 3DGS |
|---|---|---|
| 训练范式 | 每个场景单独优化 G \mathcal G G | 学习跨场景映射 F θ F_\theta Fθ |
| 推理方式 | 需要 per-scene fitting | 一次前向直接输出 Gaussian field |
| 表示生成方式 | 初始化 + density control + iterative refinement | 直接回归 / 采样 / 解码 Gaussian primitives |
| 泛化能力 | 非主要目标 | 核心目标之一 |
| 资产生产属性 | 更像求解器 | 更像生成接口或重建引擎 |
这个表并不意味着后者必然替代前者。optimization-based 方法在几何精修、场景特化质量、可解释的 per-scene control 上仍然极强;feed-forward 方法则在吞吐、部署、批量化、与生成模型耦合方面更有平台价值。(arXiv)
2.2 数学上:求解器与映射器的差别
optimization-based 3DGS 的核心是:
Solve G for one scene . (3) \text{Solve }\mathcal G \text{ for one scene}. \tag{3} Solve G for one scene.(3)
feed-forward 3DGS 的核心则是:
Learn F θ : X → Y , X = images, poses? , Y = Gaussian sets . (4) \text{Learn }F_\theta:\mathcal X \rightarrow \mathcal Y, \quad \mathcal X={\text{images, poses?}}, \quad \mathcal Y={\text{Gaussian sets}}. \tag{4} Learn Fθ:X→Y,X=images, poses?,Y=Gaussian sets.(4)
看似只是把优化变量挪进了网络,但本质上已经变成了函数逼近问题 。于是,数据分布、out-of-domain 泛化、multi-view token aggregation、pose uncertainty、latent capacity、decoder inductive bias 全部进入主舞台。GRM、GS-LRM、Long-LRM 之所以被视作关键节点,正是因为它们把这个函数逼近问题大模型化了。(arXiv)
2.3 工程部署属性:为什么企业会偏爱前馈式
工程上,前馈式方法的价值非常直接:
它更适合被封装成 API、SDK、批处理服务或内容生产流水线;
更容易与 upstream 的图像采集、SLAM、foundation depth、multi-view diffusion,以及 downstream 的编辑、压缩、分发接口耦合;
更容易形成统一的"输入图像 → 输出资产"的 产品心智。
LGM 已经明显体现了这一点:它不把目标限定在 reconstruction,而是直接面向 high-resolution 3D content creation;GS-LRM 也明确展示了在 downstream 3D generation 任务中的应用潜力。(arXiv)
3. 三轴 taxonomy:表示、几何推理、输入/任务
这一章是全文的理论中枢。需要明确的是,前馈式 3DGS 的方法分歧不是一维序列,而是至少三个正交轴上的组合。
3.1 表示轴:Gaussian Map vs Gaussian Volume / Structured 3D Latent
最早一批方法默认采用 pixel-aligned / map-like Gaussian prediction 。其典型写法是:每个输入像素或每个像素位置上的若干候选,输出一组高斯参数,再通过深度或概率采样把这些 2D 位置 lift 到 3D。pixelSplat 的"概率式 3D 采样"、MVSplat 的 per-view Gaussian regression、GRM / GS-LRM 的 per-pixel Gaussian decoding,本质上都属于这一族。(arXiv)
形式上,可写为:
g u , v ( k ) = ϕ θ ! ( f u , v ( 1 : N ) ) , μ u , v ( k ) = Π − 1 ( u , v , d u , v ( k ) ; P ) , (5) g_{u,v}^{(k)}= \phi_\theta!\big(\mathbf f_{u,v}^{(1:N)}\big), \qquad \mu_{u,v}^{(k)}= \Pi^{-1}(u,v,d_{u,v}^{(k)};\mathbf P), \tag{5} gu,v(k)=ϕθ!(fu,v(1:N)),μu,v(k)=Π−1(u,v,du,v(k);P),(5)
其中 f u , v ( 1 : N ) \mathbf f_{u,v}^{(1:N)} fu,v(1:N) 是多视图聚合后的像素特征, d u , v ( k ) d_{u,v}^{(k)} du,v(k) 是深度或深度分布采样值, Π − 1 \Pi^{-1} Π−1 表示反投影, μ \mu μ 是 Gaussian center。
这类表示的优点是简单、可扩展、天然兼容图像 backbone;但局限也非常清楚:
它把高斯组织强绑定到输入图像采样格上,导致 primitive placement 带有先天 2D 偏置。VolSplat 与 Off The Grid 后续几乎是正面冲着这一点来的:前者改为 voxel-aligned prediction,后者直接把 primitive placement 从规则网格回归改成检测/分配。(arXiv)
为什么 pixel-aligned 是起点而不是终点?
因为 pixel-aligned 最容易把 2D 视觉模型改造成 Gaussian predictor,但它并不天然等价于"好的 3D 组织方式"。输入视角数变化、遮挡、多视图不一致、低纹理区,以及 view-dependent density bias,都会暴露这种组织方式的刚性。
VolSplat 明确把这类问题概括为 pixel alignment 的结构性局限;Off The Grid 则进一步指出规则网格,primitive placement 在质量与效率上都受限。(arXiv)
与之相对的是 Gaussian Volume / voxel / triplane / structured latent 一类表示。这里的关键不再是"每个像素吐出几个高斯",而是先构建某种结构化 3D latent,再由 latent 解码出高斯。LaRa 直接把场景表示为 Gaussian Volumes;VolSplat 采用 voxel-aligned Gaussian prediction;TGS 通过 hybrid triplane-Gaussian intermediate representation 来规避直接回归无结构高斯属性的困难。(arXiv)
形式上可写为:
Z ∈ R X × Y × Z × C or T = T x y , T x z , T y z , (6) \mathbf Z \in \mathbb R^{X\times Y\times Z\times C} \quad \text{or} \quad \mathbf T = {T^{xy},T^{xz},T^{yz}}, \tag{6} Z∈RX×Y×Z×CorT=Txy,Txz,Tyz,(6)
G ^ = D gs ( Z ) or G ^ = D gs ( T , P ) , (7) \hat{\mathcal G}= D_{\text{gs}}(\mathbf Z) \quad \text{or} \quad \hat{\mathcal G}= D_{\text{gs}}(\mathbf T,\mathcal P), \tag{7} G^=Dgs(Z)orG^=Dgs(T,P),(7)
其中 Z \mathbf Z Z 是体素化 latent, T \mathbf T T 是 triplane latent, P \mathcal P P 可为点云、候选位置或 queries。式 ( 7 ) (7) (7) 的意义在于:高斯不再是网络直接回归的原子输出,而是 latent 解码的结果。
工程上这意味着表示的 3D 交互能力上限被抬高了。因为 structured latent 更容易承载全局一致性、局部邻域、密度自适应、编辑接口,甚至后续的 generative control。也正因为如此,structured latent 与 adaptive placement 往往被视为新阶段的两个关键入口。(arXiv)
但需要看到,structured latent 并不是 free-form 3D Gaussian organization 的终点:它只是把 primitive 的生成从"像素直接回归"前移到了"先构造规则化 3D 中间场,再解码高斯",因此虽然提升了多视图一致性与局部邻域建模能力,却也引入了新的结构性代价------第一,体素或 triplane 本身带来离散化偏置,其空间分辨率、显存占用与细节恢复能力之间存在刚性折中;第二,latent grid 只是把锚点从 2D pixel grid 改成了 3D regular grid,本质上仍未完全解决 primitive placement 的自由度问题,高斯仍然常常被限制在预定义结构附近;第三,latent-to-Gaussian decoder 会把几何恢复误差与表示压缩误差叠加到一起,使薄结构、尖锐边界、遮挡交界和高频局部几何更容易被平滑化;第四,这类方法通常改善了"组织能力",但并不自动保证"几何可辨识性"和"最优表示预算分配",因此它更像是为后续 adaptive placement、uncertainty-aware prediction 和 asset-level control 提供了更好的底座,而不是单独完成了这些问题的最终解。
3.2 几何推理轴:Gaussian center / placement 从何而来
前馈式 3DGS 的核心难点并不只是"预测颜色、尺度、opacity",而是Gaussian center 从哪里来。不同路线的真正分歧首先发生在这里。
(1)概率深度 / 可微采样
pixelSplat 的关键贡献之一,是不直接输出单点深度,而是预测稠密 3D 概率分布,并从中采样 Gaussian centers,以缓解 sparse、局部支持表示下的 local minima 问题。换句话说,它把"高斯位置"变成了一个带不确定性的采样问题,而不是点估计问题。(arXiv)
(2)cost volume / plane sweeping
MVSplat 明确把 Gaussian center localization 重写为 multi-view geometry estimation:通过 plane sweeping 构建 cost volume,让多视图匹配相似性直接服务于 depth/center 预测。DepthSplat 又把这条线进一步推进到"Gaussian splatting 与 depth estimation 的双向耦合"。(arXiv)
为什么 cost volume / depth 又回来了?
因为一旦目标从"拟合这个场景"转为"泛化地输出可信几何",appearance-only 的监督很难稳定约束 center prediction。高斯渲染可容忍一定几何偏差,但 generalized reconstruction 不行。于是 depth、cost volume、monocular depth feature、foundation geometry 这些曾经在 MVS / depth estimation 中成熟的几何工具重新回到中心位置。DepthSplat 几乎是用方法名字直接宣告了这一拐点。(arXiv)
(3)depth foundation 注入 / foundation geometry / pointmap
在 pose-free 与真实世界输入设定下,几何问题更难。PF3plat 使用预训练 monocular depth estimation 和 visual correspondence 先做 coarse alignment,再细化 pose 与 depth;Splatt3R 则建立在 MASt3R 这一类 foundation 3D geometry 重建器之上,把 pointmap/point cloud 扩展为 Gaussian primitives;AnySplat 进一步尝试从 unconstrained unposed collections 中统一预测高斯与相机。(arXiv)
(4)token-level global aggregation
GRM、GS-LRM、Long-LRM 的重点不是显式几何体积,而是把多视图像素 token 送入强全局聚合器,再从 token 序列解码高斯。这里的几何不是被 cost volume 显式写出来,而是被 token interaction 吸收入模型参数与中间表征中。GRM 用 transformer 融合多视图像素并输出 pixel-aligned Gaussians;GS-LRM 用极简 transformer 架构直接解码 per-pixel Gaussian parameters;Long-LRM 则把序列长度扩展到 32 幅高分辨率输入,面向 wide-coverage scene-level reconstruction。(arXiv)
(5)structured latent reasoning 与 adaptive primitive detection
LaRa 和 VolSplat 的共通点,是把"几何一致性"更多前移到 3D structured latent 中解决;Off The Grid 则指出,即使 latent 与 aggregation 都足够强,如果 primitive 仍被绑在 rigid grid 上,最终输出仍会受限,因此需要让高斯位置从"回归到格点"转向"检测到连续空间位置"。(arXiv)
3.3 输入与任务轴:posed、pose-free、single-image、generative coupling
第三个轴是输入假设与任务设定。它决定了模型面对的是哪一类现实约束。
(1)已知位姿稀疏视图
pixelSplat、MVSplat、GRM、GS-LRM、Long-LRM 大多以 posed sparse views 为前提。这类设定更利于隔离表示与几何问题,是 field 早期快速推进的主舞台。(arXiv)
(2)无位姿 / 非标定图像集合
PF3plat、SelfSplat、Splatt3R、AnySplat 则把 pose 作为需要被放松甚至联合求解的变量。这里"前馈式"的难度被显著抬高,因为高斯位置误差、相机位姿误差、多视图对应误差会相互耦合。(arXiv)
为什么 pose-free 是真实世界约束的必然结果?
因为真实采集流并不总是提供干净、可靠、同步的相机外参。对 casually captured collections、互联网图片、对象拍摄、历史图像、混合相机集合而言,posed input 不是默认条件,而是昂贵前提。PF3plat、SelfSplat、Splatt3R、AnySplat 之所以重要,不是因为它们"多做了一件事",而是因为它们把 3DGS 从实验室标定设定推向了真实世界输入。(arXiv)
(3)单图对象重建
TGS 与 LGM 代表另一条重要轴线:输入可以退化为单图、text prompt 或 diffusion 生成的 multi-view images,输出目标更偏 3D asset creation 而非严格 reconstruction。TGS 用 triplane-Gaussian hybrid 表示实现单图前馈 3D reconstruction;LGM 则进一步把 multi-view Gaussian features 与 multi-view diffusion 管线耦合,面向 high-resolution 3D content creation。(arXiv)
(4)generative coupling
一旦输入来自 text-to-image 或 image-to-multi-view diffusion,评价目标就会从"还原某个真实场景"转为"生成一个可用的 3D 资产"。这也是 generation coupling 改变评价标准的根本原因:geometry fidelity 不再只对齐真实 GT,而开始与 editability、consistency、asset portability、prompt alignment 一起成为目标。LGM 在这一点上具有明显代表性。(arXiv)
4. 七个方法簇总图:七条路线背后的真正分歧是什么

4.1 路线一:像素对齐 / 概率式高斯图
主矛盾 :如何在不做 per-scene optimization 的前提下,直接从输入图像得到可渲染高斯。
代表节点:pixelSplat。
pixelSplat 的核心思想是:不要把 3D Gaussian 看成必须通过优化长出来的实体,而可以把它们作为网络一次输出的显式 primitive;但为了缓解直接回归 center 的不稳定性,它用概率分布与采样来决定位置。优势是问题被首次明确化,前馈式 3DGS 因而作为独立研究方向成立。局限是 pixel-aligned 的组织方式仍很强,几何一致性更多依赖隐式学习而不是显式约束。它的结构性意义在于:把"前馈地产生高斯"这件事合法化了。 (arXiv)
4.2 路线二:几何优先 / cost volume / depth-first
主矛盾 :高斯可以预测,但高斯中心不够可信。
代表节点:MVSplat、DepthSplat。
这一路线把主要难题从 appearance prediction 移回 geometry estimation。MVSplat 用 plane sweeping cost volume 显式建模跨视图匹配;DepthSplat 更进一步把 depth estimation 与 Gaussian splatting 做成双向促进。优势是 center localization 更有几何抓手;局限是仍可能受 posed sparse-view 假设与 depth 误差传播制约。它对下一阶段的意义是:field 开始承认"高斯中心预测"其实首先是几何问题。 (arXiv)
4.3 路线三:LRM / Transformer / 大重建模型
主矛盾 :局部几何足够了,但跨视图全局聚合能力不足。
代表节点:GRM、GS-LRM、Long-LRM。
这一路线把问题定义为 sequence-to-sequence 的大规模映射:多视图图像 token 经过 transformer 或 hybrid sequence model 聚合,再直接解码为 Gaussians。GRM 明确提出 large Gaussian reconstruction model;GS-LRM 用更简洁的 transformer 直接从 2--4 posed sparse images 解码高斯;Long-LRM 把输入规模扩展到长序列与大场景。优势是全局信息整合能力强、扩展性好;局限是几何可靠性可能仍被"token 会自己学会几何"这一假设束缚。其转折意义在于:前馈式 3DGS 开始大模型化。 (arXiv)
4.4 路线四:Pose-free / Uncalibrated / Foundation Geometry
主矛盾 :真实世界输入往往没有干净 pose。
代表节点:PF3plat、SelfSplat、Splatt3R、AnySplat。
PF3plat 借助 depth foundation 与 correspondence 做 coarse-to-fine 的 pose/depth refinement;SelfSplat 试图在 3D prior-free 设定下自监督地让 pose 与 3D reconstruction 互相增益;Splatt3R 把 foundation geometry 方法 MASt3R 变成 Gaussian predictor 的底座;AnySplat 则朝 unconstrained multi-view collections 进一步前进。优势是问题设定更接近真实世界;局限是 pose、geometry、appearance 三者误差耦合更强。其结构性意义在于:pose-free 不再是附加条件,而是核心竞争维度。 (arXiv)
4.5 路线五:Structured 3D Latents / Triplane / Gaussian Volume / Voxel-Aligned
主矛盾 :即便有了好的几何回归,primitive 仍缺少真正 3D 的组织结构。
代表节点:TGS、LaRa、VolSplat。
TGS 用 triplane-Gaussian 混合表示来处理单图对象重建中的"无结构高斯难直接回归"问题;LaRa 用 Gaussian Volumes 与局部-全局联合注意力增强 large-baseline reconstruction;VolSplat 则更明确地把 pixel-aligned paradigm 改写为 voxel-aligned prediction。优势是 3D 结构感更强、一致性更好、可控性更高;局限是 latent 设计、体素成本与解码复杂度上升。其转折意义在于:高斯开始被视为 latent 解码结果,而非像素直接吐出的末端参数。 (arXiv)
4.6 路线六:Adaptive Primitive Placement
主矛盾 :primitive placement 不应被刚性网格绑死。
代表节点:Off The Grid。
Off The Grid 直接把 primitive placement 从规则像素网格上的密集回归,改成连续空间中的 sub-pixel primitive detection。优势是可以用更少 primitives 放到更该放的位置;局限是检测式训练、分配策略、稳定性与通用性仍需时间验证。其结构性意义非常大:高斯位置预测第一次明确从"回归深度"转向"检测/分配 primitive"。 (arXiv)
4.7 路线七:Generative Coupling / 3D Asset Creation
主矛盾 :输出的不只是可渲染场,而是可复用 3D 资产。
代表节点:LGM,以及与 GS-LRM / PF-LRM 等的耦合趋势。
LGM 把多视图 Gaussian features 与上游 multi-view image generation 耦合起来,直接服务高分辨率 3D 内容生成;GS-LRM、PF-LRM 则证明 reconstruction model 可以成为 downstream generation 的几何/表示接口。优势是离产品化和内容生产更近;局限是评价标准从真实重建转向"资产可用性"后,benchmark、几何 GT、编辑协议都会变得复杂。其转折意义在于:前馈式 3DGS 开始从重建器变成资产生成接口。 (arXiv)
5. 从 2023 到 2026:关键拐点与演化逻辑

5.1 拐点一:pixelSplat 让"前馈式 3DGS"成为成立的问题
在 pixelSplat 之前,3DGS 更多是一个 scene optimization 表示;在 pixelSplat 之后,"从图像对一次前向产生 Gaussian splats"第一次被系统地写成可训练、可评测、可推广的问题。这个拐点的结构性意义,不在于它一定比优化法更强,而在于它把 field 的研究对象从 per-scene solver 转成了 generalizable predictor。(arXiv)
5.2 拐点二:MVSplat / DepthSplat 表明 center prediction 正回归为几何问题
MVSplat 用 cost volume 显式地把 center localization 绑定回多视图几何;DepthSplat 则更进一步把 Gaussian splatting 与 depth estimation 连接起来。换句话说,field 在经历第一轮"可以前馈地产生高斯"之后,很快意识到真正卡住质量上限的不是 renderer,而是 geometry reliability。(arXiv)
5.3 拐点三:GRM / GS-LRM / Long-LRM 表明全局 token 聚合进入主舞台
GRM、GS-LRM、Long-LRM 的共同点,是都把 feed-forward 3DGS 提升为大规模序列建模问题。这里的演化逻辑不是"换个 backbone",而是从局部像素归纳偏置,转向大模型式全局上下文整合。Long-LRM 尤其说明:当输入数量与视野覆盖扩大后,问题已经不再只是 sparse-view object reconstruction,而是 scene-level long-context reconstruction。(arXiv)
5.4 拐点四:PF3plat / SelfSplat / Splatt3R / AnySplat 让 pose-free 成为核心竞争维度
这一拐点的意义在于,field 不再把 posed input 当成理所当然。PF3plat、SelfSplat、Splatt3R、AnySplat 都在不同层面推进 pose relaxation:有的依赖 depth/correspondence foundation,有的依赖 self-supervision,有的依赖 foundation geometry,有的试图统一预测相机与高斯。问题重心由"如何更好地重建已知姿态输入"转为"如何在不完美输入下仍稳定地产生可信 3D"。(arXiv)
5.5 拐点五:LaRa / VolSplat 表明 3D structured latent 开始取代纯 pixel-aligned 思路
LaRa 的 Gaussian Volumes 与 VolSplat 的 voxel-aligned prediction 共同说明:纯 pixel-aligned paradigm 不是终局。高斯不仅需要被"预测出来",还需要被"组织起来"。当表示改成 structured 3D latent,模型才更有机会处理 multi-view consistency、density adaptation、编辑接口以及更强的 3D inductive bias。(arXiv)
5.6 拐点六:Off The Grid 表明 primitive placement 从回归走向检测 / 分配
这可能是 2025 以后最值得注意的信号之一。过去大家默认"只要深度更准,高斯位置就会更准";Off The Grid 指出这还不够,因为 primitive placement 的组织机制本身就有问题。于是,位置不再只是通过反投影得到,而是成为一个可学习的、可分配的、连续空间中的检测问题。(arXiv)
5.7 拐点七:LGM 等工作说明前馈式 3DGS 正变成 3D 资产生成接口
LGM 的目标从一开始就不是严格意义上的真实场景重建,而是高分辨率 3D 内容创建。这意味着 feed-forward 3DGS 已经和 generative modeling、multi-view diffusion、3D asset pipeline 发生深耦合。此时评价标准、产品形态、数据协议都开始变化:我们不再只问它 render 得像不像,而要问它是否可编辑、可导出、可复用、可分发。(arXiv)
6. 当前最核心的三个瓶颈
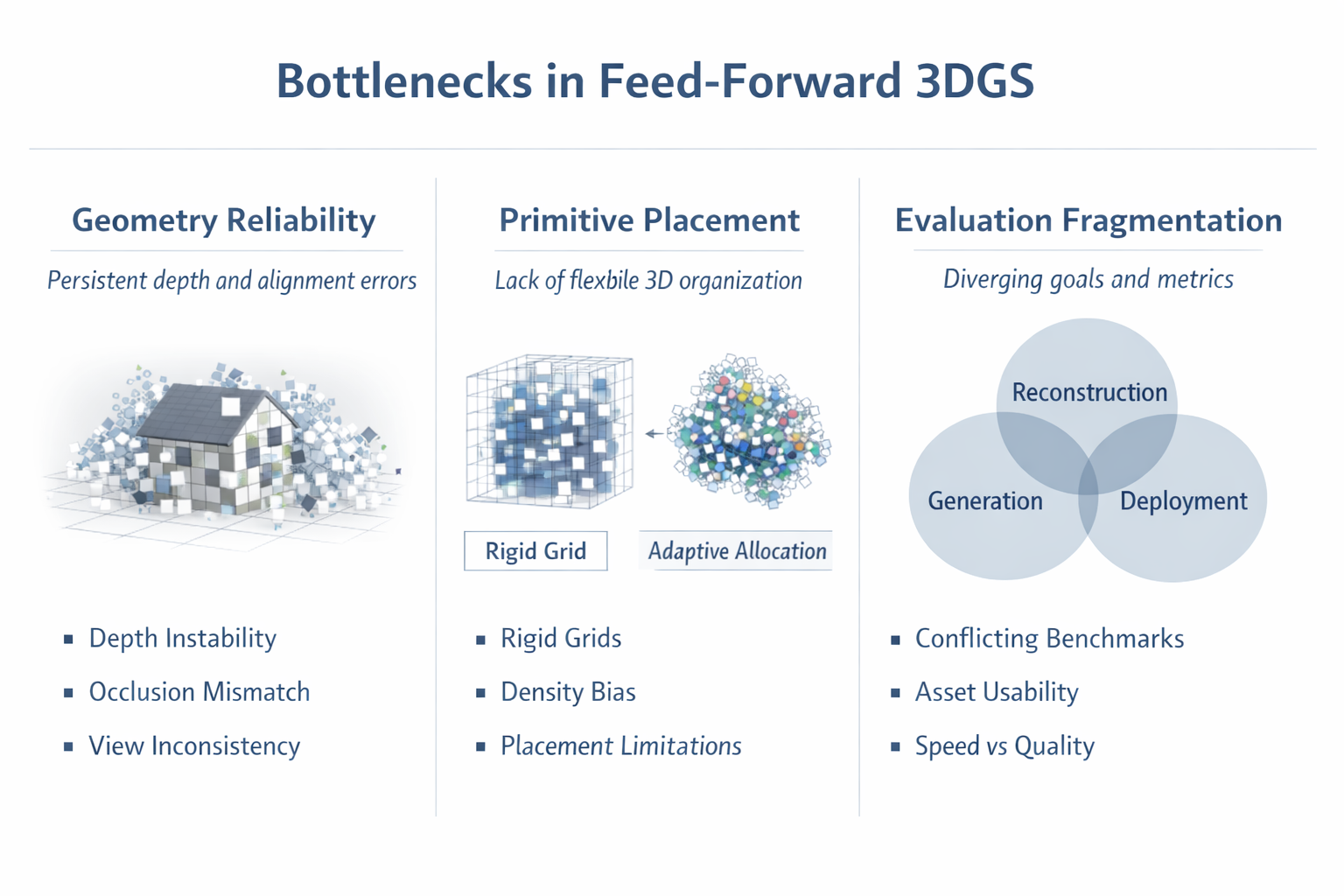
6.1 几何可靠性仍未被根治
形式上,渲染损失对几何误差常常是非对称敏感的:
L render = ∑ r ℓ ! ( C ( r ; G ) , , C ⋆ ( r ) ) , (8) \mathcal L_{\text{render}}= \sum_{\mathbf r} \ell!\left( C(\mathbf r;\mathcal G),, C^\star(\mathbf r) \right), \tag{8} Lrender=r∑ℓ!(C(r;G),,C⋆(r)),(8)
但存在不同的 G \mathcal G G 可以给出接近的像素重建,这意味着 appearance supervision 与 geometry correctness 之间并非一一对应。于是,高斯中心误差、深度不稳定、遮挡区误配、低纹理区域退化、跨视图不一致,仍是最根本瓶颈。MVSplat、DepthSplat、PF3plat、SelfSplat 的存在本身就说明这件事还远未解决。(arXiv)
为什么它重要?因为 geometry 错了,渲染可能暂时还能"看起来对",但编辑、测量、分发、下游生成耦合都会失真。为什么它难?因为 generalized feed-forward 设定下,几何误差来自多源:图像内容、跨视图对应、位姿误差、表示容量、placement 机制,彼此耦合。(arXiv)
6.2 primitive placement 仍缺乏真正自由的 3D 组织机制
pixel-aligned 的强项是简洁,弱项也是简洁。它天然继承 2D 网格,便于工程实现,但高斯密度、布局与视角分布强耦合。VolSplat 已经明确指出 pixel-aligned prediction 会带来 view-biased density 与 alignment error;Off The Grid 则指出 rigid grid primitive placement 限制质量与效率。(arXiv)
为什么这件事重要?因为表示不是中性的。高斯怎么放,直接决定它能不能承载细结构、遮挡边界、跨视图一致性、密度自适应和可压缩性。为什么这件事难?因为一旦摆脱规则网格,模型就必须同时学会:
- 放多少个 primitive;
- 每个 primitive 放在哪里;
- 如何避免塌缩、冗余与不稳定;
- 如何与 renderer、loss、pose、latent 共同训练。
为什么 structured latent 与 adaptive placement 是新阶段?
因为它们分别对应两个更本质的问题:
- structured latent 解决"高斯如何被组织";
- adaptive placement 解决"高斯为什么在这里"。
前者提供 3D 结构化表达底座,后者提供更自由的 primitive allocation 机制。两者一旦结合,前馈式 3DGS 才可能真正从"像素提升到三维"。(arXiv)
6.3 评价协议正在分裂
当前 feed-forward 3DGS 的 evaluation protocol 正明显分裂成至少三组目标:
- reconstruction-oriented:关注 posed / pose-free NVS 与 geometry;
- generation-oriented:关注 prompt alignment、asset quality、editability;
- deployment-oriented:关注 speed、memory、primitive count、可导出性。
LGM 的评价目标与 MVSplat、SelfSplat、AnySplat 就已经不是完全同一问题;pose-aware 与 pose-free 方法之间的 benchmark 也并不天然可比。(arXiv)
为什么重要?因为评价协议决定研究方向会朝哪里收敛。为什么难?因为一旦 feed-forward 3DGS 同时服务 reconstruction 与 asset creation,单一 PSNR/SSIM/LPIPS 已无法覆盖 geometry、rendering、speed、asset usability 四类目标。
为什么 generation coupling 会改变评价标准?
因为此时输出不再只是"对 GT 视图的近似器",而是"用于编辑、再生成、分发和交互的资产中间件"。于是,指标必须从 image fidelity 扩展到 asset-level usability。LGM 代表的正是这种评价范式迁移。(arXiv)
7. 为什么这些问题会自然导向下一阶段
7.1 geometry-first 与 foundation geometry 的深耦合
未来不是简单重复 cost volume,而是把 depth foundation、pointmap foundation、correspondence foundation 更深地嵌入 Gaussian prediction。Splatt3R、PF3plat、DepthSplat、MonoSplat 都已经说明 foundation geometry 在 feed-forward 3DGS 中不是辅助模块,而可能成为几何底座。(arXiv)
7.2 structured 3D latent 会成为统一接口
LaRa、VolSplat、TGS 指向同一个判断:structured 3D latent 更适合作为统一接口,因为它同时兼容 reconstruction、generation、editing、compression 与 downstream reasoning。未来更值得期待的不是"再多吐一点像素对齐高斯",而是把 Gaussian field 变成某种可查询、可解码、可编辑的 latent-backed asset。(arXiv)
7.3 confidence / uncertainty-aware Gaussian prediction
pixelSplat 的概率采样、PF3plat 的 geometry confidence,其实都在指向同一个趋势:模型需要显式知道"哪些高斯可信,哪些不可信"。这可能进一步催生 uncertainty-aware placement、confidence-guided pruning、multi-hypothesis geometry decoding。(arXiv)
形式上,可考虑把每个高斯写成带置信度的 random primitive:
g i = ( μ i , Σ i , α i , c i , ρ i ) , ρ i ∈ 0 , 1 , (9) g_i= (\mu_i,\Sigma_i,\alpha_i,\mathbf c_i,\rho_i), \qquad \rho_i \in 0,1, \tag{9} gi=(μi,Σi,αi,ci,ρi),ρi∈0,1,(9)
其中 ρ i \rho_i ρi 表示几何或放置置信度。工程上这意味着高斯不再只是参数点,而是带可信性语义的资产单元。
7.4 adaptive primitive placement 会成为关键分水岭
Off The Grid 只是一个起点。未来真正的分歧很可能不再是"谁的 backbone 更大",而是谁能更合理地决定:在哪些位置生成 primitive、需要多少 primitive、它们如何随着 scene complexity 自适应变化。(arXiv)
7.5 feed-forward reconstruction 与 generative asset creation 会进一步耦合
GS-LRM、PF-LRM、LGM 已经表明 reconstruction model 与 generation model 之间的边界正在变薄。未来更可能的形态是:一个统一的 3D 表示接口,同时服务真实输入重建、单图生成、多视图生成、编辑与分发。(arXiv)
7.6 更统一的 benchmark 与 evaluation protocol
下一阶段一定需要更统一的 benchmark:既评 image-space fidelity,也评 geometry consistency、pose robustness、primitive efficiency、asset usability。否则 reconstruction-oriented 与 generation-oriented 研究将继续在不同 protocol 上各自最优。(arXiv)
8. 本系列文章接下来怎么展开
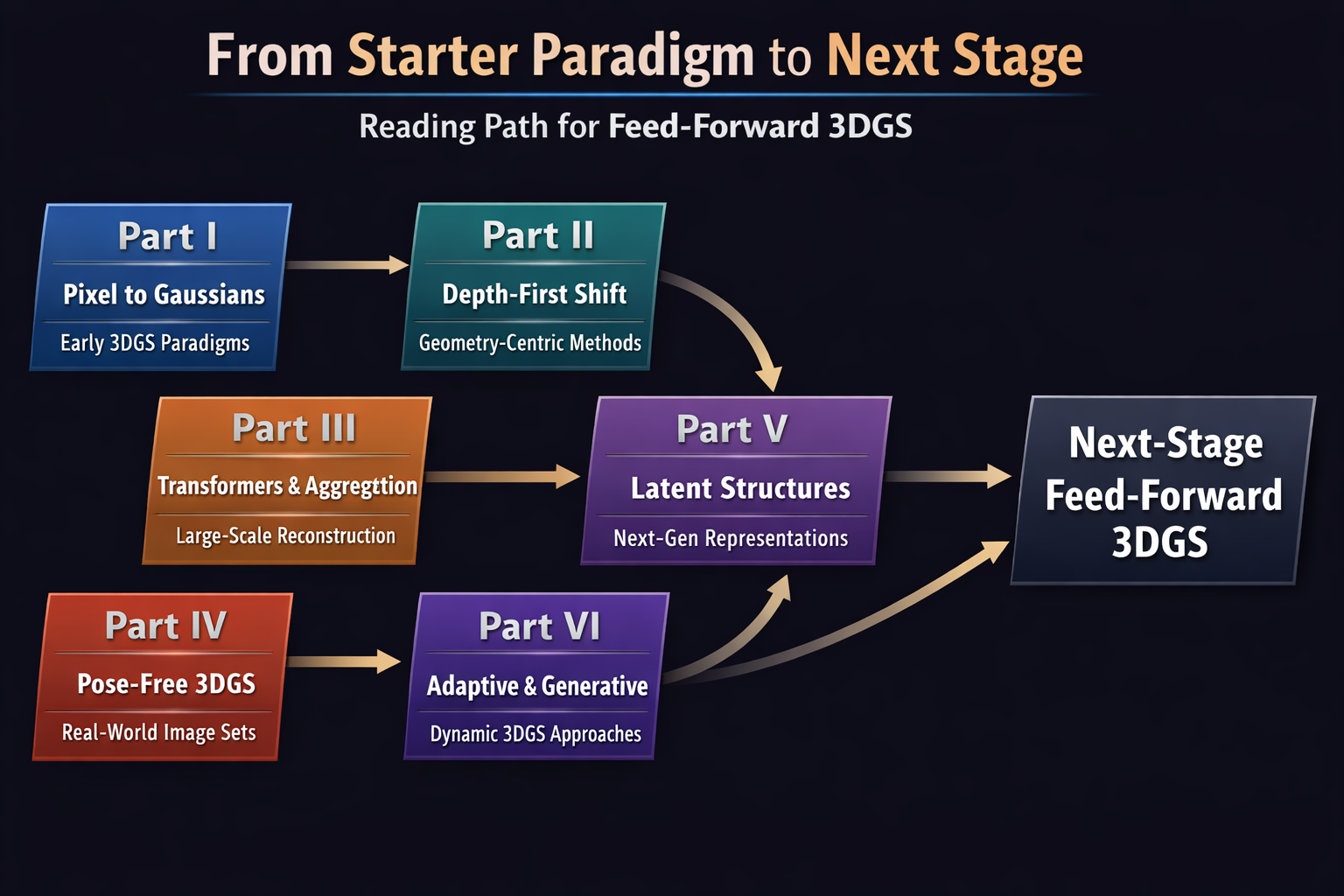
8.1 Part I:前馈式 3DGS 的起步范式:从像素到高斯
这一篇将专门讲 pixelSplat 及其相关早期思路,回答:
- 为什么最早的方法几乎都走 pixel-aligned;
- 概率式 center sampling 的数学直觉是什么;
- 它为什么成立,又为什么不能成为终点。(arXiv)
8.2 Part II:前馈式 3DGS 的 depth-first 转向
这一篇聚焦 MVSplat、DepthSplat 以及 geometry-first 变体,回答:
- 为什么高斯中心定位最终会退化成几何问题;
- cost volume、monocular depth feature、foundation depth 各自承担什么角色;
- geometry supervision 如何改变 Gaussian prediction。(arXiv)
8.3 Part III:Transformer 如何重写前馈式 3DGS 的信息聚合方式
这一篇聚焦大重建模型,回答:
- 为什么 token-level global aggregation 会进入 3DGS;
- LRM 范式与 explicit Gaussian representation 如何结合;
- 长序列、大场景、wide-coverage 何以成为新边界。(arXiv)
8.4 Part IV:Pose-Free 前馈式 3DGS:从实验室输入走向真实世界图像集合
这一篇聚焦 PF3plat、SelfSplat、Splatt3R、AnySplat,回答:
- pose-free 的真正技术难点是什么;
- foundation geometry 在这里是工具、先验还是底座;
- 真实世界输入会如何改写模型设计。(arXiv)
8.5 Part V:结构化潜空间与高斯体:前馈式 3DGS 的下一代表示基座
这一篇聚焦 TGS、LaRa、VolSplat,回答:
- triplane、Gaussian Volume、voxel-aligned latent 的结构优势到底是什么;
- 为什么它们更适合承载编辑、生成、组织与压缩;
- structured latent 如何改变 3DGS 的上层接口。(arXiv)
8.6 Part VI:Adaptive Placement and Generative Coupling in Feed-Forward 3DGS
这一篇聚焦 Off The Grid 与 LGM 一线,回答:
- primitive placement 为什么会从回归走向检测;
- 为什么 generation coupling 会重写评价标准;
- feed-forward 3DGS 如何从重建器走向 3D asset engine。(arXiv)
9. 结语
前馈式 3DGS 的真正主战场,不再只是"能不能一次前向生成",而是"高斯如何更可信地被产生、被放置、被组织、被复用于生成"。
这句话背后的判断是:这个方向早已不是简单的速度优化支线。pixelSplat 让"前馈地产生高斯"成为成立问题;MVSplat 与 DepthSplat 让 field 重新回到几何底座;GRM、GS-LRM、Long-LRM 让它走向大模型化;PF3plat、SelfSplat、Splatt3R、AnySplat 让 pose-free 成为真实世界入口;LaRa 与 VolSplat 说明 structured latent 正在取代纯 pixel-aligned 直觉;Off The Grid 则第一次系统性地挑战 rigid primitive placement;LGM 更进一步表明,前馈式 3DGS 正在变成 3D 资产生成接口。(arXiv)
换句话说,真正的分歧不在于"谁更快、谁更准",而在于谁能给出更可靠的 geometry、更合理的 primitive placement、更强的 3D organization,以及更自然的 asset generation interface。未来的胜负手,不会只是更大的 backbone,而会是更好的几何底座 + 更好的高斯组织方式 + 更强的生成耦合能力 。这也是为什么,前馈式 3DGS 应被看作一个正在重构三维表示生成范式的方向,而不是 3DGS 的旁支加速版。(Haofei Xu)
总参考文献
A. 综述、总览与研究地图
- Advances in Feed-Forward 3D Reconstruction and View Synthesis
- Review of Feed-forward 3D Reconstruction: From DUSt3R to VGGT
- A Survey on 3D Gaussian Splatting
- Recent Advances in 3D Gaussian Splatting
- 3D Gaussian Splatting: Survey, Technologies, Challenges, and Opportunities
- A Survey on 3D Gaussian Splatting Applications: Segmentation, Editing, and Generation
- 3D Gaussian Splatting in Robotics: A Survey
- Learning-based Multi-View Stereo: A Survey
- Towards Next-Generation SLAM: A Survey on 3DGS-SLAM Focusing on Performance, Robustness, and Future Directions
- A Survey on Collaborative SLAM with 3D Gaussian Splatting
B. 基础方法、前置谱系与桥接工作
- NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
- 3D Gaussian Splatting for Real-Time Radiance Field Rendering
- pixelNeRF: Neural Radiance Fields from One or Few Images
- IBRNet: Learning Multi-View Image-Based Rendering
- MVSNet: Depth Inference for Unstructured Multi-view Stereo
- MVSNeRF: Fast Generalizable Radiance Field Reconstruction from Multi-View Stereo
- GeoNeRF: Generalizing NeRF with Geometry Priors
- RegNeRF: Regularizing Neural Radiance Fields for View Synthesis from Sparse Inputs
- SparseNeRF: Distilling Depth Ranking for Few-shot Novel View Synthesis
- LRM: Large Reconstruction Model for Single Image to 3D
- DUSt3R: Geometric 3D Vision Made Easy
- Grounding Image Matching in 3D with MASt3R
- MV-DUSt3R+: Single-Stage Scene Reconstruction from Sparse Views In 2 Seconds
- VGGT: Visual Geometry Grounded Transformer
- LEAP: Liberate Sparse-view 3D Modeling from Camera Poses
- Unifying Correspondence, Pose and NeRF for Pose-Free Novel View Synthesis from Stereo Pairs
- UpFusion: Novel View Diffusion from Unposed Sparse Views
- LVSM: A Large View Synthesis Model with Minimal 3D Inductive Bias
C. 前馈式 3DGS 主干论文池
C1. 路线一:像素对齐 / 概率式高斯图
- Splatter Image: Ultra-Fast Single-View 3D Reconstruction
- pixelSplat: 3D Gaussian Splats from Image Pairs for Scalable Generalizable 3D Reconstruction
- latentSplat: Autoencoding Variational Gaussians for Fast Generalizable 3D Reconstruction
C2. 路线二:几何优先 / Cost Volume / Depth-first
- MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images
- FreeSplat: Generalizable 3D Gaussian Splatting Towards Free-View Synthesis of Indoor Scenes
- FreeSplat++: Generalizable 3D Gaussian Splatting for Efficient Indoor Scene Reconstruction
- DepthSplat: Connecting Gaussian Splatting and Depth
- MonoSplat: Generalizable 3D Gaussian Splatting from Monocular Depth Foundation Models
- Flash3D: Feed-Forward Generalisable 3D Scene Reconstruction from a Single Image
- MVSplat360: Feed-Forward 360 Scene Synthesis from Sparse Views
- IDESplat: Iterative Depth Probability Estimation for Generalizable 3D Gaussian Splatting
- Revisiting Depth Representations for Feed-Forward 3D Gaussian Splatting
- ProSplat: Improved Feed-Forward 3D Gaussian Splatting for Wide-Baseline Sparse Views
- 360-GeoGS: Geometrically Consistent Feed-Forward 3D Gaussian Splatting Reconstruction for 360 Images
C3. 路线三:LRM / Transformer / 大重建模型
- GS-LRM: Large Reconstruction Model for 3D Gaussian Splatting
- GRM: Large Gaussian Reconstruction Model for Efficient 3D Reconstruction and Generation
- Long-LRM: Long-sequence Large Reconstruction Model for Wide-coverage Gaussian Splats
- Long-LRM++: Preserving Fine Details in Feed-Forward Wide-Coverage Reconstruction
- iLRM: An Iterative Large 3D Reconstruction Model
C4. 路线四:Pose-Free / Uncalibrated / Foundation Geometry
- No Pose, No Problem: Surprisingly Simple 3D Gaussian Splatting from Sparse Unposed Images
- PF3plat: Pose-Free Feed-Forward 3D Gaussian Splatting
- SelfSplat: Pose-Free and 3D Prior-Free Generalizable 3D Gaussian Splatting
- Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs
- FreeSplatter: Pose-free Gaussian Splatting for Sparse-view 3D Reconstruction
- AnySplat: Feed-forward 3D Gaussian Splatting from Unconstrained Views
- TokenSplat: Token-aligned 3D Gaussian Splatting for Feed-forward Pose-free Reconstruction
- VicaSplat: A Single Run is All You Need for 3D Gaussian Splatting and Camera Estimation from Unposed Video Frames
- PreF3R: Pose-Free Feed-Forward 3D Gaussian Splatting from Variable-length Image Sequence
- FLARE: Feed-forward Geometry, Appearance and Camera Estimation from Uncalibrated Sparse Views
- StreamGS: Online Generalizable Gaussian Splatting Reconstruction for Unposed Image Streams
- No Pose at All: Self-Supervised Pose-Free 3D Gaussian Splatting from Sparse Views
- MuSASplat: Efficient Sparse-View 3D Gaussian Splats via Lightweight Multi-Scale Adaptation
C5. 路线五:Structured 3D Latents / Triplane / Gaussian Volume / Voxel-Aligned
- Triplane Meets Gaussian Splatting: Fast and Generalizable Single-View 3D Reconstruction with Transformers
- LaRa: Efficient Large-Baseline Radiance Fields
- VolSplat: Rethinking Feed-Forward 3D Gaussian Splatting with Voxel-Aligned Prediction
- EVolSplat: Efficient Volume-based Gaussian Splatting for Urban View Synthesis
- OmniSplat: Taming Feed-Forward 3D Gaussian Splatting for Omnidirectional Images with Editable Capabilities
C6. 适应性放置 / 预算控制 / 语义扩展
- Off The Grid: Detection of Primitives for Feed-Forward 3D Gaussian Splatting
- F4Splat: Feed-Forward Predictive Densification for Feed-Forward 3D Gaussian Splatting
- UniForward: Unified 3D Scene and Semantic Field Reconstruction via Feed-Forward Gaussian Splatting from Only Sparse-View Images
- GSemSplat: Generalizable Semantic 3D Gaussian Splatting from Uncalibrated Image Pairs
- SemanticSplat: Feed-Forward 3D Scene Understanding with Language-Aware Gaussian Fields
D. 生成耦合、内容创建与后处理扩展
- LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
- DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation
- Baking Gaussian Splatting into Diffusion Denoiser for Fast and Scalable Single-stage Image-to-3D Generation
- F3D-Gaus: Feed-forward 3D-aware Generation on ImageNet with Cycle-Consistent Gaussian Splatting
- NovelGS: Consistent Novel-view Denoising via Large Gaussian Reconstruction Model
- Generative Densification: Learning to Densify Gaussians from Sparse Views
- Hi3D: Pursuing High-Resolution Image-to-3D Generation with Video Diffusion Models
- Text-to-3D using Gaussian Splatting
- Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
- DreamFusion: Text-to-3D using 2D Diffusion
- Zero-1-to-3: Zero-shot One Image to 3D Object