
🔥承渊政道: 个人主页
❄️个人专栏: 《C语言基础语法知识》 《数据结构与算法》 《C++知识内容》 《Linux系统知识》 《算法刷题指南》 《测评文章活动推广》 《大模型语言路线学习》
✨逆境不吐心中苦,顺境不忘来时路!✨ 🎬 博主简介:

语言模型作为自然语言处理领域的基石,从诞生之初便承载着让机器理解、生成人类语言的核心使命.从早期基于统计规则的朴素模型,到如今驱动大语言模型爆发的Transformer架构,语言模型的演进史,本质上是一部机器不断逼近人类语言逻辑的迭代史.在很长一段时间里,n-grams凭借简洁的统计思想,成为语言建模的主流方案,它用简单的概率统计捕捉词与词之间的关联,却也在长距离依赖、数据稀疏性等问题上暴露了明显局限.随着深度学习的兴起,RNN、LSTM等序列模型试图突破传统统计模型的桎梏.却又受制于串行计算的效率瓶颈,难以处理更长的文本序列.直到Transformer凭借自注意力机制横空出世,彻底改写了语言模型的发展轨迹,不仅解决了长距离依赖难题,更凭借并行计算的优势,成为GPT、BERT等各类大模型的底层核心.本文将沿着语言模型的发展脉络,从最基础的n-grams原理讲起,逐步梳理统计语言模型到神经网络语言模型的迭代逻辑,最终拆解Transformer的核心创新,用清晰的脉络串联起语言模型的底层基础,帮助读者读懂从传统方法到现代架构的关键跨越,夯实大模型技术的认知根基.废话不多说,下面跟着小编的节奏🎵一起去疯狂的学习吧!
目录
- 1.语言模型的起点:统计方法中的n-grams
- 2.RNN:让模型真正"记住"上下文
- 3.Transformer:从"循环记忆"到"全局注意力"
-
- 3.1Transformer
-
- [3.1.1注意力层(Attention Layer)](#3.1.1注意力层(Attention Layer))
- [3.1.2全连接前馈层(Fully-connected Feedforwad Layer)](#3.1.2全连接前馈层(Fully-connected Feedforwad Layer))
- [3.1.3层正则化(Layer Normalization)](#3.1.3层正则化(Layer Normalization))
- [3.1.4残差连接(Residual Connections)](#3.1.4残差连接(Residual Connections))
- [3.2Transformer 的语言模型](#3.2Transformer 的语言模型)
- 4.模型会预测概率,但文本怎么生成出来?
-
- 4.1概率最大化方法
-
- [4.1.1贪心搜索(Greedy Search)](#4.1.1贪心搜索(Greedy Search))
- [4.1.2波束搜索(Beam Search)](#4.1.2波束搜索(Beam Search))
- 4.2随机采样方法
- 5.语言模型好不好,应该怎么评测?
- 6.结语
1.语言模型的起点:统计方法中的n-grams
语言模型最早的主流思路之一,是直接从语料库中统计词与词共同出现的频率.n-grams就是其中最具代表性的统计语言模型.它的核心思想很朴素:一个文本序列出现的概率,可以通过一系列局部词序列的相对频率来近似计算.比如unigram只看单个词出现的频率,bigram看前一个词和当前词的组合频率,trigram 看前两个词和当前词的关系.n-grams 的优点,在于它让"语言建模"第一次变成了一个可计算的问题.下面举了"长颈鹿脖子长"的例子:哪怕这个完整短语没有直接出现在语料中,bigram 模型仍然可以通过"长颈鹿→脖子"和"脖子→长"的相对频率,计算出这个短语出现的概率.这说明统计语言模型已经具备了一定的泛化能力,不再只是死板地匹配固定规则.不过,n-grams 的问题也很明显.随着n变大,模型会越来越依赖长词串在语料中的精确出现次数,一旦某个组合没见过,就会出现"零概率"问题.n 太小,模型看不到足够上下文;n太大,模型又会严重稀疏.换句话说,n-grams本质上是在拟合语料能力和泛化能力之间做权衡.这类零概率问题通常需要借助平滑技术来缓解.更重要的是,人们并没有把 n-grams 只当成一个经验方法,而是从统计学角度解释了它的合理性:它建立在n 阶马尔可夫假设与离散随机变量的极大似然估计之上.也就是说,n-grams 并不是拍脑袋设计出来的,而是"用有限历史近似完整历史,再用频率去估计条件概率"的结果.这一点很关键,因为它让我们明白:语言模型从一开始,就不是"记住句子",而是在学习一个概率分布.
1.1n-grams语言模型介绍
n-grams语言模型基于马尔可夫假设和离散变量的极大似然估计给出语言符号的概率.
下面会用数学方法去引出n-grams语言模型:
设包含 N N N个元素的语言符号可以表示为 w 1 : N = { w 1 , w 2 , w 3 , ... , w N } w_{1:N}=\{w_1,w_2,w_3,\ldots,w_N\} w1:N={w1,w2,w3,...,wN}. w 1 : N w_{1:N} w1:N 可以代表文本,也可以代表音频序列等载有语义信息的序列.为了便于理解,本章令语言符号 w 1 : N w_{1:N} w1:N 代表文本,其元素 w i ∈ w 1 : N w_i \in w_{1:N} wi∈w1:N 代表词, i = 1 , ... , N i=1,\ldots,N i=1,...,N.在真实语言模型中, w i w_i wi 可以是 Token 等其他形式.关于Token 的介绍会在后面的文章中介绍.
n-grams 语言模型中的 n-gram 指的是长度为 n n n 的词序列.n-grams 语言模型通过依次统计文本中的 n-gram 及其对应的 ( n − 1 ) (n-1) (n−1)-gram 在语料库中出现的相对频率来计算文本 w 1 : N w_{1:N} w1:N 出现的概率.计算公式如下所示:
P n - g r a m s ( w 1 : N ) = ∏ i = n N C ( w i − n + 1 : i ) C ( w i − n + 1 : i − 1 ) (1.1) P_{n\text{-}grams}(w_{1:N})=\prod_{i=n}^{N}\frac{C(w_{i-n+1:i})}{C(w_{i-n+1:i-1})} \tag{1.1} Pn-grams(w1:N)=i=n∏NC(wi−n+1:i−1)C(wi−n+1:i)(1.1)
其中, C ( w i − n + 1 : i ) C(w_{i-n+1:i}) C(wi−n+1:i) 为词序列 { w i − n + 1 , ... , w i } \{w_{i-n+1},\ldots,w_i\} {wi−n+1,...,wi} 在语料库中出现的次数, C ( w i − n + 1 : i − 1 ) C(w_{i-n+1:i-1}) C(wi−n+1:i−1) 为词序列 { w i − n + 1 , ... , w i − 1 } \{w_{i-n+1},\ldots,w_{i-1}\} {wi−n+1,...,wi−1} 在语料库中出现的次数.
其中, n n n 为变量.当 n = 1 n=1 n=1 时,称之为unigram ,其不考虑文本的上下文关系.此时,分子 C ( w i − n + 1 : i ) = C ( w i ) C(w_{i-n+1:i})=C(w_i) C(wi−n+1:i)=C(wi), C ( w i ) C(w_i) C(wi) 为词 w i w_i wi在语料库中出现的次数;分母 C ( w i − n + 1 : i − 1 ) = C t o t a l C(w_{i-n+1:i-1})=C_{total} C(wi−n+1:i−1)=Ctotal, C t o t a l C_{total} Ctotal为语料库中包含的词的总数.
当 n = 2 n=2 n=2时,称之为bigrams ,其对前一个词进行考虑.此时.分子 C ( w i − n + 1 : i ) = C ( w i − 1 , w i ) C(w_{i-n+1:i})=C(w_{i-1},w_i) C(wi−n+1:i)=C(wi−1,wi), C ( w i − 1 , w i ) C(w_{i-1},w_i) C(wi−1,wi) 为词序列 { w i − 1 , w i } \{w_{i-1},w_i\} {wi−1,wi} 在语料库中出现的次数;分母 C ( w i − n + 1 : i − 1 ) = C ( w i − 1 ) C(w_{i-n+1:i-1})=C(w_{i-1}) C(wi−n+1:i−1)=C(wi−1), C ( w i − 1 ) C(w_{i-1}) C(wi−1) 为词 w i − 1 w_{i-1} wi−1 在语料库中出现的次数.
以此类推,当 n = 3 n=3 n=3时,称之为trigrams ,其对前两个词进行考虑.当 n = 4 n=4 n=4时,称之为 4-grams ,其对前三个词进行考虑......

1.2n-grams语言模型对文本出现概率进行计算的具体方式
下面通过一个bigrams 语言模型的例子,展示 n-grams 语言模型对文本出现概率进行计算的具体方式.假设语料库中包含5个句子,如上图1.1所示.基于此语料库,应用bigrams 对文本"长颈鹿脖子长"(其中"长颈鹿""脖子""长"三个词构成)出现的概率进行计算.如下式所示:
P b i g r a m s ( 长颈鹿 , 脖子 , 长 ) = C ( 长颈鹿 , 脖子 ) C ( 长颈鹿 ) ⋅ C ( 脖子 , 长 ) C ( 脖子 ) (1.2) P_{\mathrm{bigrams}}(长颈鹿,脖子,长)=\frac{C(长颈鹿,脖子)}{C(长颈鹿)}\cdot\frac{C(脖子,长)}{C(脖子)}\tag{1.2} Pbigrams(长颈鹿,脖子,长)=C(长颈鹿)C(长颈鹿,脖子)⋅C(脖子)C(脖子,长)(1.2)
在此语料库中: C ( 长颈鹿 ) = 5 C(长颈鹿)=5 C(长颈鹿)=5, C ( 脖子 ) = 6 C(脖子)=6 C(脖子)=6, C ( 长颈鹿 , 脖子 ) = 2 C(长颈鹿, 脖子)=2 C(长颈鹿,脖子)=2, C ( 脖子 , 长 ) = 2 C(脖子, 长)=2 C(脖子,长)=2,故有:
P b i g r a m s ( 长颈鹿 , 脖子 , 长 ) = 2 5 ⋅ 2 6 = 2 15 (1.3) P_{bigrams}(长颈鹿,脖子,长)=\frac{2}{5}\cdot\frac{2}{6}=\frac{2}{15}\tag{1.3} Pbigrams(长颈鹿,脖子,长)=52⋅62=152(1.3)
在此例中,我们可以发现,虽然"长颈鹿脖子长"并没有直接出现在语料库中,但是 bigrams 语言模型仍可以预测出"长颈鹿脖子长"出现的概率为 2 15 \frac{2}{15} 152.由此可见,n-grams 具备对未知文本的泛化能力 .这也是其相较于传统基于规则的方法的优势.但是,这种泛化能力会随着 n n n的增大而逐渐减弱.应用trigrams 对文本"长颈鹿脖子长"出现的概率进行计算,将出现"零概率"的情况.
P t r i g r a m s ( 长颈鹿 , 脖子 , 长 ) = C ( 长颈鹿 , 脖子 , 长 ) C ( 长颈鹿 , 脖子 ) = 0 (1.4) P_{trigrams}(长颈鹿,脖子,长)=\frac{C(长颈鹿,脖子,长)}{C(长颈鹿,脖子)}=0\tag{1.4} Ptrigrams(长颈鹿,脖子,长)=C(长颈鹿,脖子)C(长颈鹿,脖子,长)=0(1.4)
因此,在 n-grams 语言模型中, n n n 代表了拟合语料库的能力与对未知文本的泛化能力之间的权衡.当 n n n 过大时,语料库中难以找到与 n-gram 一模一样的词序列,可能出现大量"零概率"现象;当 n n n 过小时,n-gram 难以承载足够的语言信息,不足以反映语料库的特性.因此,在 n-grams 语言模型中, n n n 的值是影响性能的关键因素.上述"零概率"现象可以通过平滑(Smoothing)技术进行改善,这个有兴趣的可以自己查询相关内容,我就不在这里介绍了.
n-grams语言模型通过统计词序列在语料库中出现的频率来预测语言符号的概率.其对未知序列有一定的泛化性,但也容易陷入"零概率"的困境.随着神经网络的发展,基于各类神经网络的语言模型不断被提出,泛化能力越来越强.基于神经网络的语言模型不再通过显性的计算公式对语言符号的概率进行计算,而是利用语料库中的样本对神经网络模型进行训练.接下来将分别介绍两类最具代表性的基于神经网络的语言模型:基于RNN 的语言模型和基于Transformer的语言模型.
2.RNN:让模型真正"记住"上下文
如果说n-grams 只是用一个固定窗口去近似上下文,那么RNN的出现,才让模型第一次具备了"历史状态积累"的能力.RNN 的关键结构是环路,它能够把前面时刻的信息编码成隐藏状态,并在当前时刻继续使用.这样一来,模型在处理一个词时,不再只看固定长度的前文,而是可以在理论上持续吸收历史信息.
接下来会用前馈神经网络和RNN做了一个很直观的对比.假设输入序列是"长颈鹿 脖子 长",当只给出"脖子"去预测下一个词时,前馈网络只能依据"脖子"本身,可能想到"短""疼"等词;而RNN会同时保留前面的"长颈鹿"信息,因此预测"长"的概率会更高.也就是说,RNN相比统计模型和普通前馈网络,更接近"基于上下文理解语言"的方向.在语言建模任务中,RNN的训练方式也很自然:每一步都根据当前词和前一时刻的隐藏状态,预测下一个词在词表上的概率分布;整段文本的概率,则由这些逐步预测得到的条件概率连乘而成.之前给出了"长颈鹿脖子长"的示意例子,通过两步预测得到整体概率.这样的建模方式,已经非常接近今天自回归语言模型的基本范式.但RNN也不是完美的.由于它在时间维度上不断进行矩阵连乘,训练时很容易出现梯度消失或梯度爆炸.这意味着,虽然它理论上可以记住很长的上下文,但在实际训练中,远距离信息往往难以有效传递.为了解决这个问题,后来才有了GRU和LSTM等带门控结构的改进模型.这类门控结构正是为缓解训练困难而提出,并逐渐成为主流RNN结构.此外,RNN作为自回归模型,还会面临两个经典问题.第一是错误级联放大:模型一旦某一步预测错了,后续步骤会基于错误结果继续生成,越错越多.第二是串行计算效率低:因为后一步必须依赖前一步输出,所以难以并行.为此,训练时通常采用Teacher Forcing,也就是每一步都使用真实答案作为下一步输入;但这又会带来训练与推理不一致的"曝光偏差"问题.Scheduled Sampling就是为了缓解这种偏差而提出的.
2.1循环神经网络RNN
循环神经网络(Recurrent Neural Network, RNN)是一类网络连接中包含环路的神经网络的总称.给定一个序列,RNN 的环路用于将历史状态叠加到当前状态上.沿着时间维度,历史状态被循环累积,并作为预测未来状态的依据.按照推理过程中信号流转的方向,神经网络的正向传播范式可分为两大类:
- 前馈传播范式:计算逐层向前,"不走回头路".而在循环传播范式中,某些层的计算结果会通过环路被反向引回前面的层中,形成"螺旋式前进"的范式.采用前馈传播范式的神经网络可以统称为前馈神经网络(Feed-forward Neural Network,FNN).
- 循环传播范式:采用循环传播范式的神经网络被统称为循环神经网络(Recurrent Neural Network,RNN).以包含输入层、隐藏层、输出层的神经网络为例.下图1.2中展示了最简单的FNN和RNN的网络结构示意图.
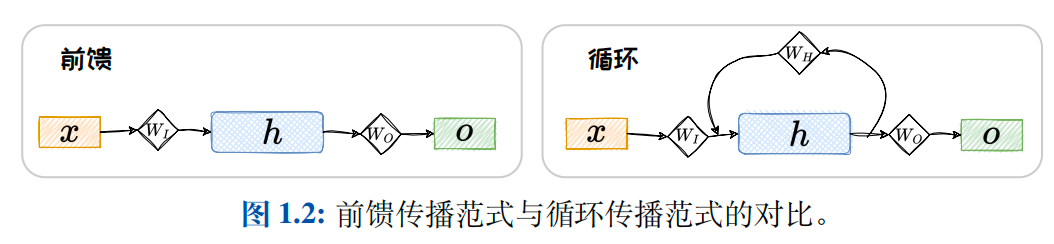
在一个元素一个元素依次串行输入的设定下,RNN可以将历史状态以隐变量的形式循环叠加到当前状态上,对历史信息进行考虑,呈现出螺旋式前进的模式.但是,缺乏环路的 FNN 仅对当前状态进行考虑,无法兼顾历史状态.以词序列{长颈鹿, 脖子, 长} 为例,在给定"脖子"来预测下一个词是什么的时候,FFN 将仅仅考虑"脖子"来进行预测,可能预测出的下一词包含"短","疼"等等;而 RNN 将同时考虑"长颈鹿"和"脖子",其预测出下一词是"长"的概率将更高,历史信息"长颈鹿"的引入,可以有效提升预测性能.
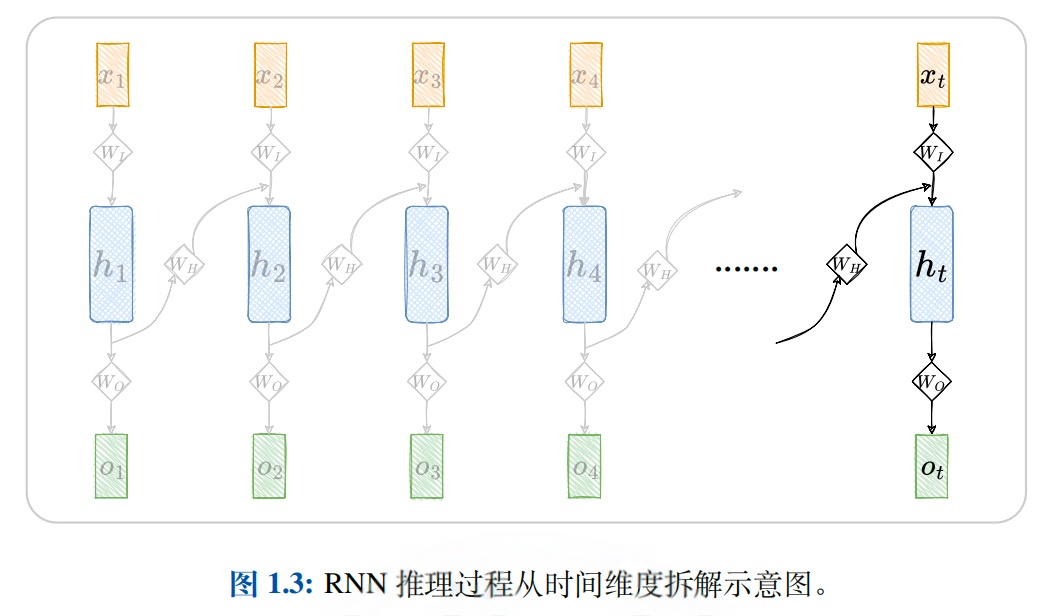
如果FNN 想要做到对历史信息进行考虑,则需要将所有元素同时输入到模型中去,这将导致模型参数量的激增.虽然,RNN 的结构可以让其在参数量不扩张的情况下实现对历史信息的考虑,但是这样的环路结构给RNN 的训练带来了挑战.在训练RNN时,涉及大量的矩阵联乘操作,容易引发梯度衰减 或梯度爆炸问题.
2.2RNN的语言模型
对词序列 { w 1 , w 2 , w 3 , ... , w N } \{w_1, w_2, w_3, \ldots, w_N\} {w1,w2,w3,...,wN},基于RNN的语言模型每次根据当前词 w i w_i wi和循环输入的隐藏状态 h i − 1 h_{i-1} hi−1,来预测下一个词 w i + 1 w_{i+1} wi+1出现的概率,即
P ( w i + 1 ∣ w 1 : i ) = P ( w i + 1 ∣ w i , h i − 1 ) 。 P(w_{i+1}\mid w_{1:i}) = P(w_{i+1}\mid w_i, h_{i-1})。 P(wi+1∣w1:i)=P(wi+1∣wi,hi−1)。
其中,当 i = 1 i=1 i=1 时, P ( w i + 1 ∣ w i , h i − 1 ) = P ( w 2 ∣ w 1 ) P(w_{i+1}\mid w_i, h_{i-1}) = P(w_2\mid w_1) P(wi+1∣wi,hi−1)=P(w2∣w1).基于此, { w 1 , w 2 , w 3 , ... , w N } \{w_1, w_2, w_3, \ldots, w_N\} {w1,w2,w3,...,wN} 整体出现的概率为:
P ( w 1 : N ) = ∏ i = 1 N − 1 P ( w i + 1 ∣ w i , h i − 1 ) 。 P(w_{1:N}) = \prod_{i=1}^{N-1} P(w_{i+1}\mid w_i, h_{i-1})。 P(w1:N)=i=1∏N−1P(wi+1∣wi,hi−1)。
在基于RNN的语言模型中,输出为一个向量,其中每一维代表着词典中对应词的概率.设词典 D D D中共有 ∣ D ∣ |D| ∣D∣个词 { w ^ 1 , w ^ 2 , w ^ 3 , ... , w ∣ D ∣ } \{\hat{w}1, \hat{w}2, \hat{w}3, \ldots, w{|D|}\} {w^1,w^2,w^3,...,w∣D∣},基于 RNN 的语言模型的输出可表示为 o i = { o i w \^ d } d = 1 ∣ D ∣ o_i=\{o_i\\hat{w}_d\}{d=1}^{|D|} oi={oiw\^d}d=1∣D∣,其中, o i w \^ d o_i\\hat{w}_d oiw\^d 表示词典中的词 w ^ d \hat{w}d w^d 出现的概率.因此,对基于 RNN 的语言模型有
P ( w 1 : N ) = ∏ i = 1 N − 1 P ( w i + 1 ∣ w 1 : i ) = ∏ i = 1 N o i w i + 1 。 P(w{1:N}) = \prod{i=1}^{N-1} P(w_{i+1}\mid w_{1:i}) = \prod_{i=1}^{N} o_iw_{i+1}。 P(w1:N)=i=1∏N−1P(wi+1∣w1:i)=i=1∏Noiwi+1。
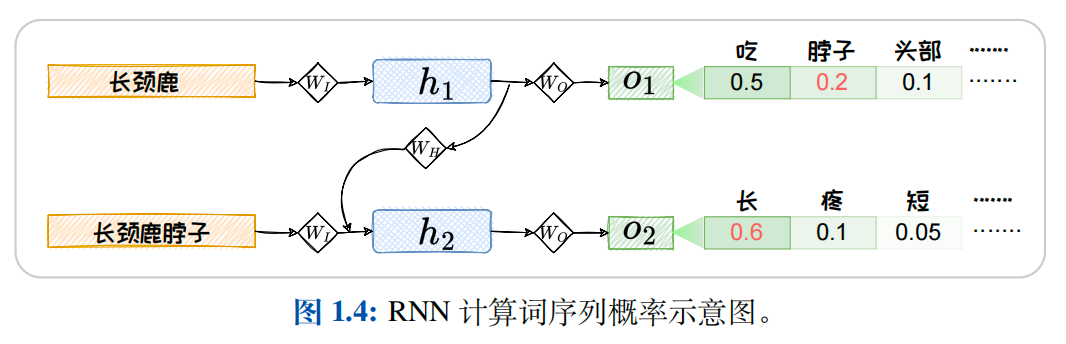
我们还可以对此语言模型的输出进行解码,在"自回归"的范式下完成文本生成任务.在自回归中,第一轮,我们首先将第一个词输入给 RNN 语言模型,经过解码,得到一个输出词.然后,我们将第一轮输出的词与第一轮输入的词拼接,作为第二轮的输入,然后解码得到第二轮的输出.接着,将第二轮的输出和输入拼接,作为第三轮的输入,以此类推.每次将本轮预测到的词拼接到本轮的输入上,输入给语言模型,完成下一轮预测.在循环迭代的"自回归"过程中,我们不断生成新的词,这些词便构成了一段文本.
但上述"自回归"过程存在着两个问题:
- 错误级联放大,选用模型自己生成的词作为输入可能会有错误,这样的错误循环输入,将会不断的放大错误,导致模型不能很好拟合训练集;
- 串行计算效率低,因为下一个要预测的词依赖上一次的预测,每次预测之间是串行的,难以进行并行加速.为了解决上述两个问题,"Teacher Forcing"在语言模型预训练过程中被广泛应用.在Teacher
Forcing中,每轮都仅将输出结果与"标准答案"(Ground Truth)进行拼接作为下一轮的输入.在上图1.4所示的例子中,第二轮循环中,我们用"长颈鹿脖子"来预测下一个词"长",而非选用 o1 中概率最高的词"吃"或者其他可能输出的词.
但是,Teacher Forcing 的训练方式将导致曝光偏差(Exposure Bias)的问题.曝光偏差是指 Teacher Forcing训练模型的过程和模型在推理过程存在差异.TeacherForcing 在训练中,模型将依赖于"标准答案"进行下一次的预测,但是在推理预测中,模型"自回归"的产生文本,没有"标准答案"可参考.所以模型在训练过程中和推理过程中存在偏差,可能推理效果较差.为解决曝光偏差的问题,Bengio等人提出了针对RNN提出了Scheduled Sampling.方法其在Teacher Forcing的训练过程中循序渐进的使用一小部分模型自己生成的词代替"标准答案",在训练过程中对推理中无"标准答案"的情况进行预演.由于RNN模型循环迭代的本质,其不易进行并行计算,导致其在输入序列较长时,训练较慢.下面将对容易并行的Transformer的语言模型进行介绍.
3.Transformer:从"循环记忆"到"全局注意力"
RNN 的核心问题,在于它虽然能处理序列,却很难高效地处理长序列.Transformer 的出现,几乎是对这一困境的正面回应.与RNN一步一步串行处理不同,Transformer 通过注意力机制,让模型在同一层中就能"同时看见"一定范围内的所有上下文,并决定哪些信息更重要.书中把这种能力概括为对历史状态和当前状态进行"通盘考虑".Transformer拆成两个核心模块:注意力模块和全连接前馈模块.其中,注意力层会把输入编码成 query、key、value 三部分,再通过query和key的相似度计算权重,用这些权重对 value 进行加权求和.这个过程的本质,是让模型在处理当前token时,动态决定该关注输入序列中的哪些位置.除了注意力层,还会介绍了全连接前馈层、层正则化和残差连接的作用.全连接前馈层承担了大量参数,某种意义上可以视作Transformer中的"记忆管理模块";层正则化有助于训练稳定和泛化;残差连接则能缓解梯度问题.也就是说,Transformer之所以强,不只是因为"注意力"三个字,而是因为它把多个对深度网络训练至关重要的组件组合成了一个高效、可扩展的整体.在语言模型训练上,Transformer 提供了更灵活的预训练方式.基于Encoder部分可以构造BERT这类 Encoder-only模型,常用任务是掩词补全;同时使用Encoder和Decoder可以构造T5这类 Encoder-Decoder 模型;只保留 Decoder,则可以构造GPT这类 Decoder-only 模型,通过"下一词预测"进行训练.我们需要记住最核心的思想:Transformer是现代大语言模型的结构基础.与RNN相比,Transformer 最显著的优势是更容易并行计算.因为它不需要像RNN那样一步一步传递隐藏状态.所以训练效率大幅提高.这也是它后来能够支撑超大规模预训练的重要原因.当然.Transformer也不是没有代价.它的计算规模会随着输入序列长度呈平方增长.因此在长序列场景下会面临较大的计算压力.
3.1Transformer
Transformer是一类基于注意力机制(Attention)的模块化构建的神经网络结构.
Transformer是由两种模块组合构建的模块化网络结构.两种模块分别为:
- 注意力(Attention)模块:自注意力模块由自注意力层(Self-Attention Layer)、残差连接(Residual Connections)和层正则化(Layer Normalization)组成.
- 全连接前馈(Fully-connected Feedforwad)模块.全连接前馈模块由全连接前馈层,残差连接和层正则化组成.两个模块的结构示意图如下图1.5所示.以下详细介绍每个层的原理及作用.
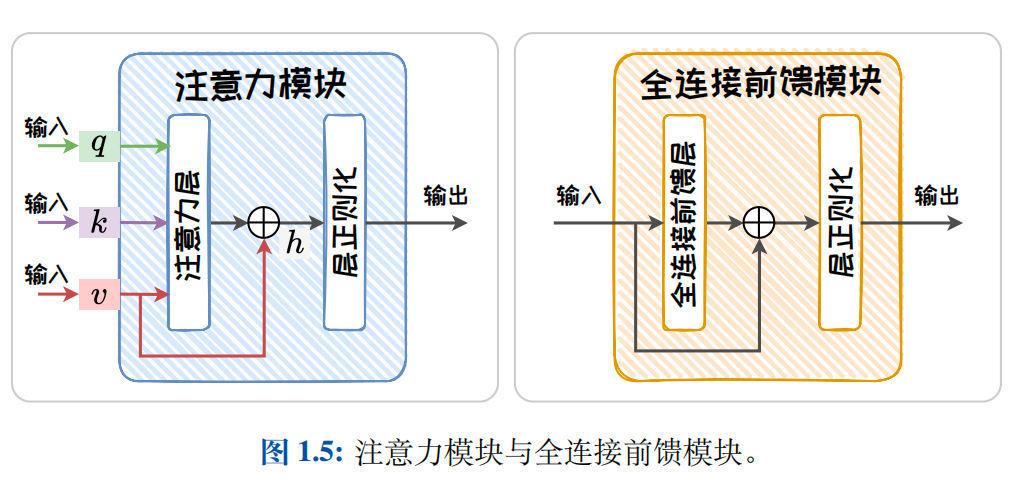
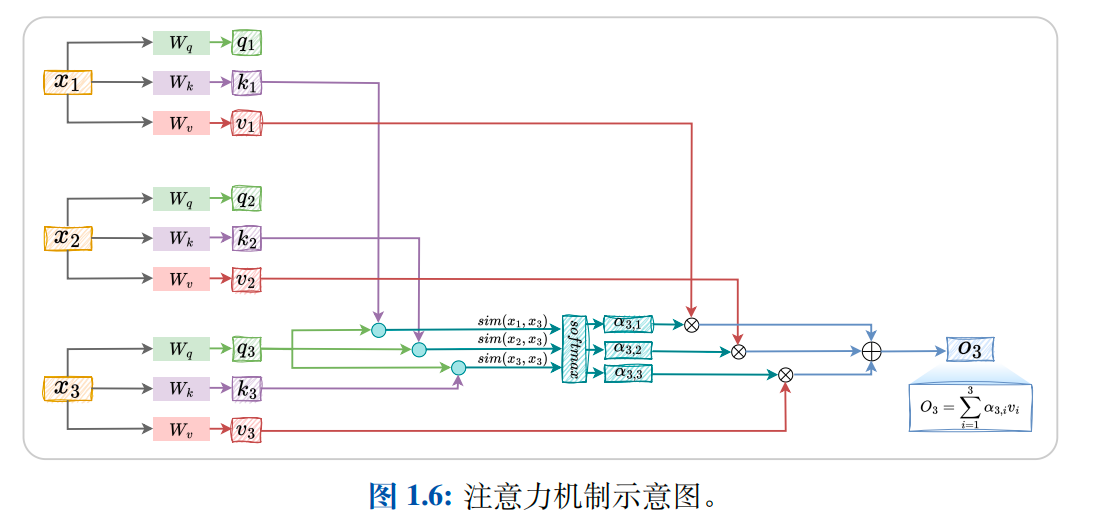
3.1.1注意力层(Attention Layer)
注意力层采用加权平均的思想将前文信息叠加到当前状态上.Transformer 的注意力层将输入编码为 query、key、value 三部分,即将输入 { x 1 , x 2 , ... , x t } \{x_1,x_2,\ldots,x_t\} {x1,x2,...,xt}编码为 { ( q 1 , k 1 , v 1 ) , ( q 2 , k 2 , v 2 ) , ... , ( q t , k t , v t ) } \{(q_1,k_1,v_1),(q_2,k_2,v_2),\ldots,(q_t,k_t,v_t)\} {(q1,k1,v1),(q2,k2,v2),...,(qt,kt,vt)}.其中,query和key用于计算自注意力的权重 α \alpha α,value是对输入的编码.具体的,
A t t e n t i o n ( x t ) = ∑ i = 1 t α t , i v i Attention(x_t)=\sum_{i=1}^{t}\alpha_{t,i}v_i Attention(xt)=i=1∑tαt,ivi
其中,
α t , i = s o f t m a x ( s i m ( x t , x i ) ) = s i m ( q t , k i ) ∑ i = 1 t s i m ( q t , k i ) \alpha_{t,i}=softmax(sim(x_t,x_i))=\frac{sim(q_t,k_i)}{\sum_{i=1}^{t}sim(q_t,k_i)} αt,i=softmax(sim(xt,xi))=∑i=1tsim(qt,ki)sim(qt,ki)
其中, s i m ( ⋅ , ⋅ ) sim(\cdot,\cdot) sim(⋅,⋅) 用于度量两个输入之间的相关程度,softmax 函数用于对此相关程度进行归一化.此外,
q i = W q x i , k i = W k x i , v i = W v x i , q_i=W_qx_i,\quad k_i=W_kx_i,\quad v_i=W_vx_i, qi=Wqxi,ki=Wkxi,vi=Wvxi,
其中, W q W_q Wq、 W k W_k Wk、 W v W_v Wv 分别为 query、key、value 编码器的参数.以包含三个元素的输入 { x 1 , x 2 , x 3 } \{x_1,x_2,x_3\} {x1,x2,x3} 为例,Transformer 自注意力的实现上图1.6 所示.
3.1.2全连接前馈层(Fully-connected Feedforwad Layer)
全连接前馈层占据了Transformer 近三分之二的参数,掌管着Transformer模型的记忆.其可以看作是一种 Key-Value 模式的记忆存储管理模块.全连接前馈层包含两层,两层之间由 ReLU 作为激活函数.设全连接前馈层的输入为 v v v,全连接前馈层可由下式表示:
F F N ( v ) = max ( 0 , W 1 v + b 1 ) W 2 + b 2 FFN(v)=\max(0,W_1v+b_1)W_2+b_2 FFN(v)=max(0,W1v+b1)W2+b2
其中, W 1 W_1 W1 和 W 2 W_2 W2 分别为第一层和第二层的权重参数, b 1 b_1 b1 和 b 2 b_2 b2 分别为第一层和第二层的偏置参数.其中第一层的可看作神经记忆中的 key,而第二层可看作 value.
3.1.3层正则化(Layer Normalization)
层正则化用以加速神经网络训练过程并取得更好的泛化性能.设输入到层正则化层的向量为 v = { v i } i = 1 n v=\{v_i\}_{i=1}^{n} v={vi}i=1n.层正则化层将在 v v v 的每一维度 v i v_i vi 上都进行层正则化操作.具体地,层正则化操作可以表示为下列公式:
L N ( v i ) = α ( v i − μ ) δ + β LN(v_i)=\alpha\frac{(v_i-\mu)}{\delta}+\beta LN(vi)=αδ(vi−μ)+β
其中, α \alpha α 和 β \beta β 为可学习参数. μ \mu μ和 δ \delta δ分别是隐藏状态的均值和方差,可由下列公式分别计算.
μ = 1 n ∑ i = 1 n v i , δ = 1 n ∑ i = 1 n ( v i − μ ) 2 \mu=\frac{1}{n}\sum_{i=1}^{n}v_i,\qquad \delta=\sqrt{\frac{1}{n}\sum_{i=1}^{n}(v_i-\mu)^2} μ=n1i=1∑nvi,δ=n1i=1∑n(vi−μ)2
3.1.4残差连接(Residual Connections)
引入残差连接可以有效解决梯度消失问题.在基本的Transformer 编码模块中包含两个残差连接.第一个残差连接是将自注意力层的输入由一条旁路叠加到自注意力层的输出上,然后输入给层正则化.第二个残差连接是将全连接前馈层的输入由一条旁路引到全连接前馈层的输出上,然后输入给层正则化.
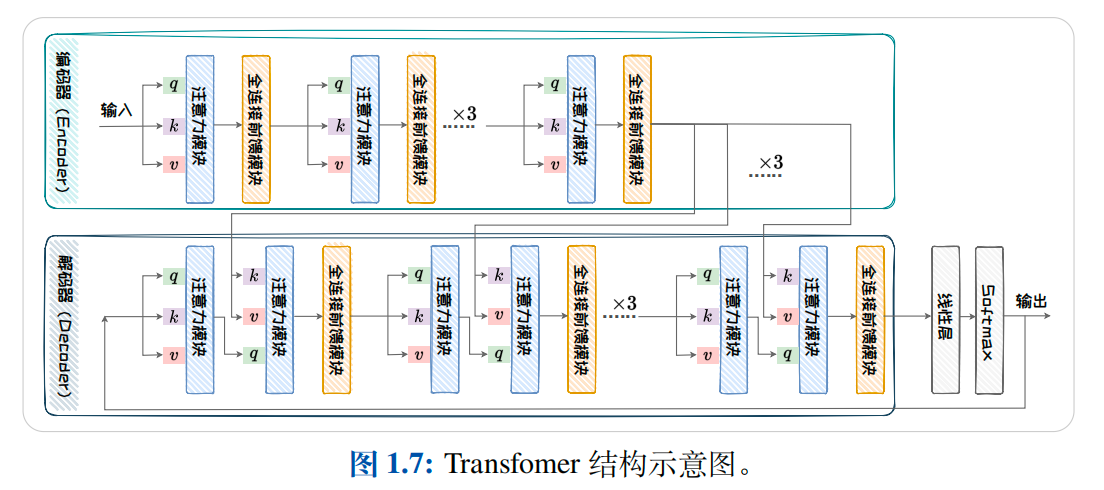
上述将层正则化置于残差连接之后的网络结构被称为 Post-LN Transformer.与之相对的,还有一种将层正则化置于残差连接之前的网络结构,称之为Pre-LNTransformers.对比两者,Post-LN Transformer 应对表征坍(Representation Collapse)的能力更强,但处理梯度消失略弱.而Pre-LN Transformers 可以更好的应对梯度消失,但处理表征坍塌的能力略弱.原始的Transformer采用Encoder-Decoder架构,其包含Encoder和Decoder两部分.这两部分都是由自注意力模块和全连接前馈模块重复连接构建而成.其整体结构如下图1.7所示.其中,Encoder 部分由六个级联的 encoder layer 组成,每个encoder layer 包含一个注意力模块和一个全连接前馈模块.其中的注意力模块为自注意力模块(query,key,value 的输入是相同的).Decoder 部分由六个级联的decoder layer 组成,每个decoder layer 包含两个注意力模块和一个全连接前馈模块.其中,第一个注意力模块为自注意力模块,第二个注意力模块为交叉注意力模块(query,key,value 的输入不同).Decoder 中第一个 decoder layer 的自注意力模块的输入为模型的输出.其后的 decoder layer 的自注意力模块的输入为上一个 decoderlayer 的输出.Decoder 交叉注意力模块的输入分别是自注意力模块的输出(query)和最后一个 encoder layer 的输出(key,value).
Transformer的Encoder部分和 Decoder 部分都可以单独用于构造语言模型,分别对应Encoder-Only 模型和 Decoder-Only 模型.Encoder-Only 模型和 Decoder-Only模型的具体结构将在后面的文章中进行详细介绍.
3.2Transformer 的语言模型
在Transformer 的基础上,可以设计多种预训练任务来训练语言模型.例如,我们可以基于Transformer 的Encoder 部分,结合"掩词补全"等任务来训练EncoderOnly语言模型,如BERT;我们可以同时应用 Transformer的 Endcoder 和 Decoder部分,结合"截断补全"、"顺序恢复"等多个有监督和自监督任务来训练EncoderDecoder 语言模型,如T5;我们可以同时应用 Transformer 的 Decoder 部分,利用"下一词预测"任务来训练 Decoder-Only 语言模型,如GPT-3.这些语言模型将在后续中进行详细介绍.下面将以下一词预测任务为例,简单介绍训练Transformer 语言模型的流程.
对词序列 { w 1 , w 2 , w 3 , ... , w N } \{w_1,w_2,w_3,\ldots,w_N\} {w1,w2,w3,...,wN},基于Transformer 的语言模型根据 { w 1 , w 2 , ... , w i } \{w_1,w_2,\ldots,w_i\} {w1,w2,...,wi} 预测下一个词 w i + 1 w_{i+1} wi+1 出现的概率.在基于Transformer 的语言模型中,输出为一个向量,其中每一维代表着词典中对应词的概率.设词典 D D D中共有 ∣ D ∣ |D| ∣D∣个词 { w ^ 1 , w ^ 2 , ... , w ^ ∣ D ∣ } \{\hat{w}1,\hat{w}2,\ldots,\hat{w}{|D|}\} {w^1,w^2,...,w^∣D∣}.基于Transformer 的语言模型的输出可表示为 o i = { o i w \^ d } d = 1 ∣ D ∣ o_i=\{o_i\\hat{w}_d\}{d=1}^{|D|} oi={oiw\^d}d=1∣D∣,其中, o i w \^ d o_i\\hat{w}_d oiw\^d 表示词典中的词 w ^ d \hat{w}d w^d 出现的概率.因此,对Transformer 的语言模型对词序列 { w 1 , w 2 , w 3 , ... , w N } \{w_1,w_2,w_3,\ldots,w_N\} {w1,w2,w3,...,wN} 整体出现的概率的预测为:
P ( w 1 : N ) = ∏ i = 1 N − 1 P ( w i + 1 ∣ w 1 : i ) = ∏ i = 1 N o i w i + 1 P(w{1:N})=\prod_{i=1}^{N-1}P(w_{i+1}\mid w_{1:i})=\prod_{i=1}^{N}o_iw_{i+1} P(w1:N)=i=1∏N−1P(wi+1∣w1:i)=i=1∏Noiwi+1
与训练 RNN 语言模型相同,Transformer 语言模型也常用如下交叉熵函数作为损失函数.
l C E ( o i ) = − ∑ d = 1 ∣ D ∣ I ( w ^ d = w i + 1 ) log o i w i + 1 = − log o i w i + 1 l_{CE}(o_i)=-\sum_{d=1}^{|D|}I(\hat{w}d=w{i+1})\log o_iw_{i+1}=-\log o_iw_{i+1} lCE(oi)=−d=1∑∣D∣I(w^d=wi+1)logoiwi+1=−logoiwi+1
其中, I ( ⋅ ) I(\cdot) I(⋅) 为指示函数,当 w ^ d = w i + 1 \hat{w}d=w{i+1} w^d=wi+1 时等于1,当 w ^ d ≠ w i + 1 \hat{w}d\ne w{i+1} w^d=wi+1 时等于0.
设训练集为 S S S,Transformer 语言模型的损失可以构造为:
L ( S , W ) = 1 N ∣ S ∣ ∑ s = 1 ∣ S ∣ ∑ i = 1 N l C E ( o i , s ) L(S,W)=\frac{1}{N|S|}\sum_{s=1}^{|S|}\sum_{i=1}^{N}l_{CE}(o_{i,s}) L(S,W)=N∣S∣1s=1∑∣S∣i=1∑NlCE(oi,s)
其中, o i , s o_{i,s} oi,s为Transformer 语言模型输入样本 s 的前 i 个词时的输出.在此损失的基础上,构建计算图,进行反向传播,便可对 Transformer 语言模型进行训练.上述训练过程结束之后,我们可以将 Encoder 的输出作为特征,然后应用这些特征解决下游任务.此外,还可在"自回归"的范式下完成文本生成任务.在自回归中,第一轮,我们首先将第一个词输入给Transformer语言模型,经过解码,得到一个输出词.然后,我们将第一轮输出的词与第一轮输入的词拼接,作为第二轮的输入,然后解码得到第二轮的输出.接着,将第二轮的输出和输入拼接,作为第三轮的输入,以此类推.每次将本轮预测到的词拼接到本轮的输入上,输入给语言模型,完成下一轮预测.在循环迭代的"自回归"过程中,我们不断生成新的词,这些词便构成了一段文本.相较于RNN模型串行的循环迭代模式,Transformer 并行输入的特性,使其容易进行并行计算.但是,Transformer 并行输入的范式也导致网络模型的规模随输入序列长度的增长而平方次增长.这为应用Transformer处理长序列带来挑战.
4.模型会预测概率,但文本怎么生成出来?
很多初学者学到语言模型时,容易停留在"模型会输出一个概率向量"这一步.但前面的内容非常实用的一点,是它进一步解释了:概率输出不等于最终文本,真正决定生成效果的还有解码策略.解码方法分成两大类.第一类是概率最大化方法,也就是尽量选出联合概率最高的文本.最简单的是贪心搜索:每一步都选概率最大的词.它实现最直接,但很容易陷入局部最优.举例说明,在生成以"长颈鹿"开头的故事时,第一步选当前最优词,后续可能导致整体结果反而更差.为了缓解这个问题,可以采用波束搜索,在每一步保留多个高概率候选,最后再从整体上挑选更优路径.不过,概率最大不代表文本最好.这类方法往往会生成最常见、最稳妥、最"平庸"的句子,容易落入重复、乏味的"废话文学".这其实也是很多人初次使用语言模型时的真实体验:模型看似很稳,但不够有趣. 因此,第二类方法------随机采样方法------就显得非常重要.Top-K 采样会先取概率最高的 K 个词,再按归一化后的分布随机采样;Top-P 采样则不固定候选数量,而是选择累计概率达到阈值 p 的最小候选集合.相比固定大小的 Top-K,Top-P 更能适应不同轮次下分布形状的变化,既减少离谱词进入候选集的可能,又保留更多合理但不那么常见的表达.在此基础上,Temperature 机制进一步提供了对"随机性"的调节能力.温度高,分布更平坦,模型更有创造性;温度低,分布更尖锐,模型更保守.书中提到,开放式文本生成通常需要更高随机性,而代码生成等任务则更适合较低随机性.这一点非常值得实践者记住:同一个模型,输出风格常常不是"模型能力"本身决定的,而是"模型能力 + 解码策略"共同决定的.
4.1概率最大化方法
设词典为 D D D,输入文本为 { w 1 , w 2 , w 3 , ... , w N } \{w_1,w_2,w_3,\ldots,w_N\} {w1,w2,w3,...,wN},第 i i i 轮自回归中输出的向量为
o i = { o i w d } d = 1 ∣ D ∣ o_i=\{o_iw_d\}_{d=1}^{|D|} oi={oiwd}d=1∣D∣
模型在 M M M 轮自回归后生成的文本为 { w N + 1 , w N + 2 , w N + 3 , ... , w N + M } \{w_{N+1},w_{N+2},w_{N+3},\ldots,w_{N+M}\} {wN+1,wN+2,wN+3,...,wN+M}.生成文档的出现的概率可由下式进行计算.
P ( w N + 1 : N + M ) = ∏ i = N N + M − 1 P ( w i + 1 ∣ w 1 : i ) = ∏ i = N N + M − 1 o i w i + 1 P(w_{N+1:N+M}) =\prod_{i=N}^{N+M-1} P(w_{i+1}\mid w_{1:i}) =\prod_{i=N}^{N+M-1} o_iw_{i+1} P(wN+1:N+M)=i=N∏N+M−1P(wi+1∣w1:i)=i=N∏N+M−1oiwi+1
基于概率最大化的解码方法旨在最大化 P ( w N + 1 : N + M ) P(w_{N+1:N+M}) P(wN+1:N+M),以生成出可能性最高的文本.该问题的搜索空间大小为 M D M^D MD,是NP-Hard 问题.现有概率最大化方法通常采用启发式搜索方法.将介绍两种常用的基于概率最大化的解码方法.
4.1.1贪心搜索(Greedy Search)
贪心搜索在每轮预测中都选择概率最大的词,即
w i + 1 = arg max w ∈ D o i w w_{i+1}=\arg\max_{w\in D} o_iw wi+1=argw∈Dmaxoiw
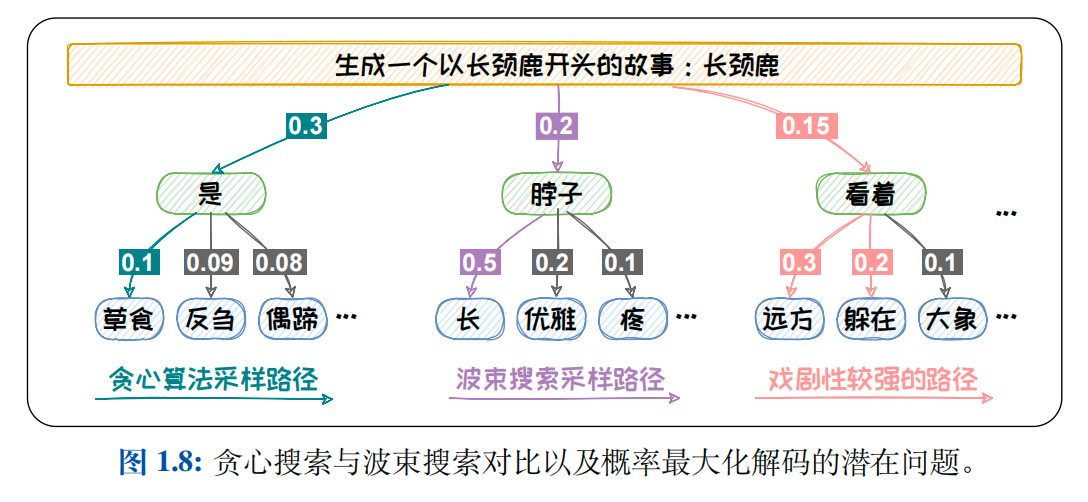
贪心搜索只顾"眼前利益",忽略了"远期效益".当前概率大的词有可能导致后续的词概率都很小.贪心搜索容易陷入局部最优,难以达到全局最优解.以下图1.8为例,当输入为"生成一个以长颈鹿开头的故事:长颈鹿"时,预测第一个词为"是"的概率最高,为0.3.但选定"是"之后,其他的词的概率都偏低.如果按照贪心搜索的方式,我们最终得到的输出为"是草食".其概率仅为0.03.而如果我们在第一个词选择了概率第二的"脖子",然后第二个词选到了"长",最终的概率可以达到0.1.通过此例,可以看出贪心搜索在求解概率最大的时候容易陷入局部最优.为缓解此问题,可以采用波束搜索(Beam Search)方法进行解码.
4.1.2波束搜索(Beam Search)
波束搜索在每轮预测中都先保留 b b b 个可能性最高的词 B i = { w i + 1 1 , w i + 1 2 , ... , w i + 1 b } B_i=\{w_{i+1}^1,w_{i+1}^2,\ldots,w_{i+1}^b\} Bi={wi+11,wi+12,...,wi+1b},即:
min { o i w for w ∈ B i } > max { o i w for w ∈ D − B i } \min\{o_iw\ \text{for}\ w\in B_i\}>\max\{o_iw\ \text{for}\ w\in D-B_i\} min{oiw for w∈Bi}>max{oiw for w∈D−Bi}
在结束搜索时,得到 M M M个集合,即 { B i } i = 1 M \{B_i\}{i=1}^{M} {Bi}i=1M.找出最优组合使得联合概率最大,即:
{ w N + 1 , ... , w N + M } = arg max { w i ∈ B i for 1 ≤ i ≤ M } ∏ i = 1 M o N + i w i \{w{N+1},\ldots,w_{N+M}\} =\arg\max_{\{w^i\in B_i\ \text{for}\ 1\le i\le M\}} \prod_{i=1}^{M} o_{N+i}w\^i {wN+1,...,wN+M}=arg{wi∈Bi for 1≤i≤M}maxi=1∏MoN+iwi
继续以上面的"生成一个以长颈鹿开头的故事"为例,从上图1.8中可以看出如果我们采用 b = 2 的波束搜索方法,我们可以得到"是草食","是反刍","脖子长","脖子优雅"四个候选组合,对应的概率分别为:0.03,0.027,0.1,0.04.我们容易选择到概率最高的"脖子长".但是,概率最大的文本通常是最为常见的文本.这些文本会略显平庸.在开放式文本生成中,无论是贪心搜索还是波束搜索都容易生成一些"废话文学"---重复且平庸的文本.其所生成的文本缺乏多样性.如在上图1.8中的例子所示,概率
最大的方法会生成"脖子长"."长颈鹿脖子长"这样的文本新颖性较低.为了提升生成文本的新颖度,我们可以在解码过程中加入一些随机元素.这样的话就可以解码到一些不常见的组合,从而使得生成的文本更具创意,更适合开放式文本任务.在解码过程中加入随机性的方法,成为随机采样方法.
4.2随机采样方法
为了增加生成文本的多样性,随机采样的方法在预测时增加了随机性.在每轮预测时,其先选出一组可能性高的候选词,然后按照其概率分布进行随机采样,采样出的词作为本轮的预测结果.当前,主流的 Top-K 采样和 Top-P 采样方法分别通过指定候选词数量和划定候选词概率阈值的方法对候选词进行选择.在采样方法中加入Temperature 机制可以对候选词的概率分布进行调整.
4.2.1Top-K采样
Top-K 采样在每轮预测中都选取 K K K 个概率最高的词 { w i + 1 1 , w i + 1 2 , ... , w i + 1 K } \{w_{i+1}^1,w_{i+1}^2,\ldots,w_{i+1}^K\} {wi+11,wi+12,...,wi+1K} 作为本轮的候选词集合,然后对这些词的概率用softmax函数进行归一化,得到如下分布函数
p ( w i + 1 1 , ... , w i + 1 K ) = { exp ( o i w i + 1 1 ) ∑ j = 1 K exp ( o i w i + 1 j ) , ... , exp ( o i w i + 1 K ) ∑ j = 1 K exp ( o i w i + 1 j ) } . p(w_{i+1}^1,\ldots,w_{i+1}^K)= \left\{ \frac{\exp\!\left(o_iw_{i+1}\^1\right)}{\sum_{j=1}^{K}\exp\!\left(o_iw_{i+1}\^j\right)}, \ldots, \frac{\exp\!\left(o_iw_{i+1}\^K\right)}{\sum_{j=1}^{K}\exp\!\left(o_iw_{i+1}\^j\right)} \right\}. p(wi+11,...,wi+1K)=⎩ ⎨ ⎧∑j=1Kexp(oiwi+1j)exp(oiwi+11),...,∑j=1Kexp(oiwi+1j)exp(oiwi+1K)⎭ ⎬ ⎫.
然后根据该分布采样 出本轮的预测的结果,即
w i + 1 ∼ p ( w i + 1 1 , ... , w i + 1 K ) . w_{i+1}\sim p(w_{i+1}^1,\ldots,w_{i+1}^K). wi+1∼p(wi+11,...,wi+1K).
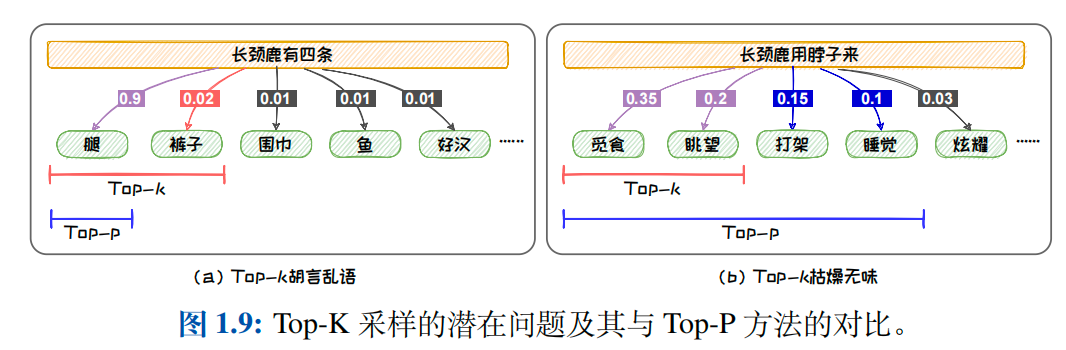
Top-K 采样可以有效的增加生成文本的新颖度,例如在上述图1.8所示的例子中选用Top-3采样的策略,则有可能会选择到"看着躲在"."长颈鹿看着躲在"可能是一个极具戏剧性的悬疑故事的开头.但是,将候选集设置为固定的大小 K 将导致上述分布在不同轮次的预测中存在很大差异.当候选词的分布的方差较大的时候,可能会导致本轮预测选到概率较小、不符合常理的词,从而产生"胡言乱语".例如,在下图1.9(a)所示的例子中,Top-2 采样有可能采样出"长颈鹿有四条裤子".而当候选词的分布的方差较小的时候,甚至趋于均匀分布时,固定尺寸的候选集中无法容纳更多的具有相近概率的词,导致候选集不够丰富,从而导致所选词缺乏新颖性而产生"枯燥无趣"的文本.例如,在下图1.9(b)所示的例子中,通过 Top-2 采样,我们只能得到"长颈鹿用脖子来觅食"或者"长颈鹿用脖子来眺望",这些都是人们熟知的长颈鹿脖
子的用途,缺乏新意.但是其实长颈鹿的脖子还可以用于打架或睡觉,Top-2 采样的方式容易将这些新颖的不常见的知识排除.为了解决上述问题,我们可以使用Top-P 采样,也称Nucleus采样.
4.2.2Top-P采样
为了缓解固定候选集所带来的问题,Top-P 采样(即 Nucleus 采样)被提出.其设定阈值 p p p 来对候选集进行选取.其候选集可表示为 S p = { w i + 1 1 , w i + 1 2 , ... , w i + 1 ∣ S p ∣ } S_p=\{w_{i+1}^1,w_{i+1}^2,\ldots,w_{i+1}^{|S_p|}\} Sp={wi+11,wi+12,...,wi+1∣Sp∣},其中,对 S p S_p Sp 有,
∑ w ∈ S p o i w ≥ p \sum_{w\in S_p} o_iw\ge p w∈Sp∑oiw≥p
候选集中元素的分布服从
p ( w i + 1 1 , ... , w i + 1 ∣ S p ∣ ) = { exp ( o i w i + 1 1 ) ∑ j = 1 ∣ S p ∣ exp ( o i w i + 1 j ) , ... , exp ( o i w i + 1 ∣ S p ∣ ) ∑ j = 1 ∣ S p ∣ exp ( o i w i + 1 j ) } p(w_{i+1}^1,\ldots,w_{i+1}^{|S_p|}) =\left\{ \frac{\exp(o_iw_{i+1}\^1)}{\sum_{j=1}^{|S_p|}\exp(o_iw_{i+1}\^j)}, \ldots, \frac{\exp(o_iw_{i+1}\^{\|S_p\|})}{\sum_{j=1}^{|S_p|}\exp(o_iw_{i+1}\^j)} \right\} p(wi+11,...,wi+1∣Sp∣)={∑j=1∣Sp∣exp(oiwi+1j)exp(oiwi+11),...,∑j=1∣Sp∣exp(oiwi+1j)exp(oiwi+1∣Sp∣)}
然后根据该分布采样出本轮的预测的结果,即
w i + 1 ∼ p ( w i + 1 1 , ... , w i + 1 ∣ S p ∣ ) w_{i+1}\sim p(w_{i+1}^1,\ldots,w_{i+1}^{|S_p|}) wi+1∼p(wi+11,...,wi+1∣Sp∣)
应用阈值作为候选集选取的标准之后,Top-P 采样可以避免选到概率较小、不符合常理的词,从而减少"胡言乱语".例如在上图1.9 (a) 所示例子中,我们若以 0.9作为阈值,则就可以很好的避免"长颈鹿有四条裤子"的问题.并且,其还可以容纳更多的具有相近概率的词,增加文本的丰富度,改善"枯燥无趣".例如在图1.9(b)所示的例子中,我们若以 0.9 作为阈值,则就可以包含打架、睡觉等长颈鹿脖子鲜为人知的用途.
4.2.3Temperature机制
Top-K 采样和 Top-P 采样的随机性由语言模型输出的概率决定,不可自由调整.但在不同场景中,我们对于随机性的要求可能不一样.比如在开放文本生成中,我们更倾向于生成更具创造力的文本,所以我们需要采样具有更强的随机性.而在代码生成中,我们希望生成的代码更为保守,所以我们需要较弱的随机性.引入 Temperature 机制可以对解码随机性进行调节.Temperature 机制通过对 Softmax函数中的自变量进行尺度变换,然后利用Softmax 函数的非线性实现对分布的控制.设Temperature尺度变换的变量为T.引入Temperature 后,Top-K 采样的候选集的分布如下所示:
p ( w i + 1 1 , ... , w i + 1 K ) = { exp ( o i w i + 1 1 T ) ∑ j = 1 K exp ( o i w i + 1 j T ) , ... , exp ( o i w i + 1 K T ) ∑ j = 1 K exp ( o i w i + 1 j T ) } 。 p(w_{i+1}^1,\ldots,w_{i+1}^K)= \left\{ \frac{\exp\left(\frac{o_iw_{i+1}\^1}{T}\right)}{\sum_{j=1}^{K}\exp\left(\frac{o_iw_{i+1}\^j}{T}\right)}, \ldots, \frac{\exp\left(\frac{o_iw_{i+1}\^K}{T}\right)}{\sum_{j=1}^{K}\exp\left(\frac{o_iw_{i+1}\^j}{T}\right)} \right\}。 p(wi+11,...,wi+1K)=⎩ ⎨ ⎧∑j=1Kexp(Toiwi+1j)exp(Toiwi+11),...,∑j=1Kexp(Toiwi+1j)exp(Toiwi+1K)⎭ ⎬ ⎫。
引入 Temperature 后,Top-P 采样的候选集的分布如下所示:
p ( w i + 1 1 , ... , w i + 1 ∣ S p ∣ ) = { exp ( o i w i + 1 1 T ) ∑ j = 1 ∣ S p ∣ exp ( o i w i + 1 j T ) , ... , exp ( o i w i + 1 ∣ S p ∣ T ) ∑ j = 1 ∣ S p ∣ exp ( o i w i + 1 j T ) } . p(w_{i+1}^1,\ldots,w_{i+1}^{|S_p|})= \left\{ \frac{\exp\left(\frac{o_iw_{i+1}\^1}{T}\right)}{\sum_{j=1}^{|S_p|}\exp\left(\frac{o_iw_{i+1}\^j}{T}\right)}, \ldots, \frac{\exp\left(\frac{o_iw_{i+1}\^{\|S_p\|}}{T}\right)}{\sum_{j=1}^{|S_p|}\exp\left(\frac{o_iw_{i+1}\^j}{T}\right)} \right\}. p(wi+11,...,wi+1∣Sp∣)=⎩ ⎨ ⎧∑j=1∣Sp∣exp(Toiwi+1j)exp(Toiwi+11),...,∑j=1∣Sp∣exp(Toiwi+1j)exp(Toiwi+1∣Sp∣)⎭ ⎬ ⎫.
容易看出,当 T > 1 时,Temperature 机制会使得候选集中的词的概率差距减小,分布变得更平坦,从而增加随机性.当 0 < T < 1 时,Temperature 机制会使得候选集中的元素的概率差距加大,强者越强,弱者越弱,概率高的候选词会容易被选到,从而随机性变弱.Temperature 机制可以有效的对随机性进行调节来满足不同的需求.
5.语言模型好不好,应该怎么评测?
模型训练完、文本生成出来之后,最后一个关键问题就是:我们怎么知道它到底好不好?评测方法分成了两类:内在评测和外在评测.内在评测不依赖具体任务,直接考察语言模型对测试文本的概率建模能力,其中最经典的指标就是困惑度(Perplexity, PPL).它衡量的是模型面对测试文本时有多"困惑".如果模型对测试文本赋予更高概率,说明它更"确信",困惑度就更低;反之则更高.困惑度可以写成平均负对数概率的指数形式,因此它与信息熵、交叉熵也有紧密联系.简单说,PPL 越低,通常说明模型越不容易"胡言乱语".但仅看 PPL 还不够,因为很多应用并不只是"预测下一个词",而是希望模型完成翻译、摘要、问答等具体任务.这就需要外在评测.接下来介绍了经典的统计指标:BLEU 和 ROUGE.BLEU 更偏向精度,常用于机器翻译;ROUGE 更偏向召回,常用于摘要生成.这类指标的优势是可计算、可比较,但问题在于它们过于依赖与参考答案的表面重合,难以充分反映生成文本的表达多样性. 为了解决这一问题,进一步介绍了基于语言模型的评测方法.BERTScore 通过上下文词向量来衡量生成文本与参考文本的相似度,相比 n-gram 重叠类指标更接近人类直觉.再进一步,G-EVAL 甚至可以不依赖人工参考答案,而是借助GPT-4 这样的生成模型,结合任务描述、评分标准和评测步骤,对生成结果进行打分.这个方向其实已经非常接近今天大模型应用中的主流评测思路:让模型作为"裁判",去评估另一个模型的输出.
5.1内在评测
在内在评测中,测试文本通常由与预训练中所用的文本独立同分布的文本构成,不依赖于具体任务.最为常用的内部评测指标是困惑度(Perplexity).其度量了语言模型对测试文本感到"困惑"的程度.设测试文本为 s t e s t = w 1 : N s_{test}=w_{1:N} stest=w1:N.语言模型在测试文本 stest 上的困惑度PPL可由下式计算:
P P L ( s t e s t ) = P ( w 1 : N ) − 1 N = ∏ i = 1 N 1 P ( w i ∣ w < i ) N PPL(s_{test})=P(w_{1:N})^{-\frac{1}{N}} =\sqrtN{\prod_{i=1}^{N}\frac{1}{P(w_i\mid w_{<i})}} PPL(stest)=P(w1:N)−N1=Ni=1∏NP(wi∣w<i)1
由上式可以看出,如果语言模型对测试文本越"肯定"(即生成测试文本的概率越高),则困惑度的值越小.而语言模型对测试文本越"不确定"(即生成测试文本的概率越低),则困惑度的值越大.由于测试文本和预训练文本同分布,预训练文本代表了我们想要让语言模型学会生成的文本,如果语言模型在这些测试文本上越不"困惑",则说明语言模型越符合我们对其训练的初衷.因此,困惑度可以一定程度上衡量语言模型的生成能力.对困惑度进行改写,其可以改写成如下等价形式.
P P L ( s t e s t ) = exp ( − 1 N ∑ i = 1 N log P ( w i ∣ w < i ) ) PPL(s_{test})=\exp\left(-\frac{1}{N}\sum_{i=1}^{N}\log P(w_i\mid w_{<i})\right) PPL(stest)=exp(−N1i=1∑NlogP(wi∣w<i))
其中, − 1 N ∑ i = 1 N log P ( w i ∣ w < i ) -\frac{1}{N}\sum_{i=1}^{N}\log P(w_i\mid w_{<i}) −N1∑i=1NlogP(wi∣w<i) 可以看作是生成模型生成的词分布与测试样本真实的词分布间的交叉熵,即
− 1 N ∑ i = 1 N ∑ d = 1 ∣ D ∣ I ( w ^ d = w i ) log o i − 1 w i -\frac{1}{N}\sum_{i=1}^{N}\sum_{d=1}^{|D|} I(\hat{w}d=w_i)\log o{i-1}w_i −N1i=1∑Nd=1∑∣D∣I(w^d=wi)logoi−1wi
其中 D D D为语言模型所采用的词典.因为 P ( w i ∣ w < i ) ≤ 1 P(w_i\mid w_{<i})\le 1 P(wi∣w<i)≤1,所以此交叉熵是生成模型生成的词分布的信息熵的上界,即
− 1 N ∑ i = 1 N P ( w i ∣ w < i ) log P ( w i ∣ w < i ) ≤ − 1 N ∑ i = 1 N log P ( w i ∣ w < i ) -\frac{1}{N}\sum_{i=1}^{N} P(w_i\mid w_{<i})\log P(w_i\mid w_{<i}) \le -\frac{1}{N}\sum_{i=1}^{N}\log P(w_i\mid w_{<i}) −N1i=1∑NP(wi∣w<i)logP(wi∣w<i)≤−N1i=1∑NlogP(wi∣w<i)
因此,困惑度减小也意味着熵减,意味着模型"胡言乱语"的可能性降低.
5.2外在评测
在外在评测中,测试文本通常包括该任务上的问题和对应的标准答案,其依赖于具体任务.通过外在评测,我们可以评判语言模型处理特定任务的能力.外在评测方法通常可以分为基于统计指标的评测方法和基于语言模型的评测方法两类.
5.2.1基于统计指标的评测
基于统计指标的方法构造统计指标来评测语言模型的输出与标准答案间的契合程度,并以此作为评测语言模型生成能力的依据.BLEU(BiLingual EvaluationUnderstudy)和 ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是应用最为广泛的两种统计指标.其中,BLEU 是精度导向的指标,而 ROUGE 是召回导向的指标.BLEU 被提出用于评价模型在机器翻译(Machine Translation, MT)任务上的效果.其在词级别上计算生成的翻译与参考翻译间的重合程度.ROUGE 被提出用于评价模型在摘要生成(Summarization)任务上的效果.常用的 ROUGE 评测包含 ROUGE-N, ROUGE-L, ROUGE-W,和 ROUGE-S 四种.其中,ROUGE-N 是基于 n-gram 的召回指标,ROUGE-L 是基于最长公共子序列
(Longest Common Subsequence, LCS)的召回指标.ROUGE-W 是在 ROUGE-L 的基础上,引入对 LCS 的加权操作后的召回指标.ROUGE-S 是基于 Skip-bigram 的召回指标.基于统计指标的评测方法通过对语言模型生成的答案和标准答案间的重叠程度进行评分.这样的评分无法完全适应生成任务中表达的多样性,与人类的评测相差甚远,尤其是在生成的样本具有较强的创造性和多样性的时候.为解决此问题,可以在评测中引入一个其他语言模型作为"裁判",利用此"裁判"在预训练阶段掌握的能力对生成的文本进行评测.
5.2.2基于语言模型的评测
目前基于语言模型的评测方法主要分为两类:
- 基于上下文词嵌入(Contextual Embeddings)的评测方法;
- 基于生成模型的评测方法.典型的基于上下文词嵌入的评测方法是BERTScore.典型的基于生成模型的评测方法 G-EVAL与 BERTScore 相比,G-EVAL 无需人类标注的参考答案.这使其可以更好的适应到缺乏人类标注的任务中.
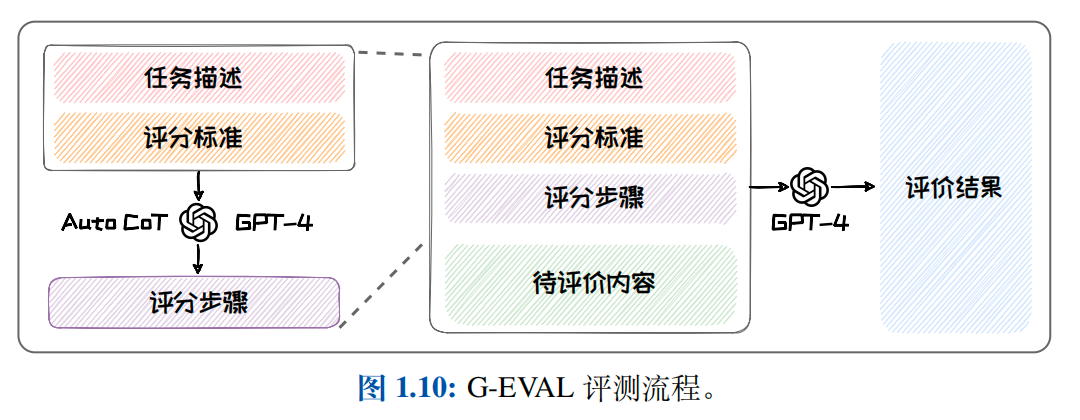
相较于统计评测指标,BERTScore 更接近人类评测结果.但是,BERTScore 依赖于人类给出的参考文本.这使其无法应用于缺乏人类标注样本的场景中.得益于生成式大语言模型的发展,G-EVAL 利用 GPT-4 在没有参考文本的情况下对生成文本进行评分.G-EVAL 通过提示工程(Prompt Engineering)引导GPT-4 输出评测分数.
如下图所示,G-EVAL 的 Prompt 分为三部分:
- 任务描述与评分标准:任务描述指明需要的评测的任务式什么(如摘要生成),评分标准给出评分需要的范围,评分需要考虑的因素等内容.
- 评测步骤:在第一部分内容的基础上由 GPT-4 自己生成的思维链(Chain-of-Thoughts, CoT).
- 输入文本与生成的文本:输入文本与生成的文本是源文本和待评测模型生成的文本.例如摘要生成任务中的输入文本是原文,而生成的文本就是生成摘要.将上述三部分组合在一个prompt 里面然后输入给GPT-4,GPT-4 便可给出对应的评分.直接将 GPT-4 给出的得分作为评分会出现区分度不够的问题,因此,G-EVAL还引入了对所有可能得分进行加权平均的机制来进行改进.
除 G-EVAL 外,近期还有多种基于生成模型的评测方法被提出.其中典型的有 InstructScore,其除了给出数值的评分,还可以给出对该得分的解释.基于生成模型的评测方法相较于基于统计指标的方法和基于上下文词嵌入的评测方法而言,在准确性、灵活性、可解释性等方面都具有独到的优势.可以预见,未来基于生成模型的评测方法将得到更为广泛的关注和应用.
6.结语
今天我们谈大模型,常常会直接讨论参数规模、指令微调、推理能力、多模态能力.但如果没有对"语言模型基础"的理解,这些讨论很容易流于表面.本篇文章最珍贵的地方就在于,它没有一上来就追逐热点,而是回到最本质的问题:语言为什么能被概率化?模型如何从统计走向神经网络?生成为什么离不开采样?评测又为什么不能只看一个分数?理解这些问题,才算真正迈进了大语言模型的大门.最后关于本文所给的相关公式是小编进行了大量的阅读所提炼出来的结果,希望大家能有所收获!

🚀真正的勇者不是流泪的人,而是含泪奔跑的人!
每日心灵鸡汤:慢慢来吧,总能和解焦虑!
别焦虑,人与人的生活节奏都不一样,有人3分钟泡面有人3小时煲汤,有的人外卖已送达,有的人才刚切好蒜苔和肉,重要的是,当你选择了你要的方式,坚定下去别胡思乱想.大家赶的时间不一样,慢慢会有人理解你的小情绪,慢慢理解你长大后的小心愿,慢慢了解你说的海边小岛上的圆月.烧烤摊上最快的菜可能是拍黄瓜,有些包子第一口咬不到肉.慢慢来的都是诚意,好戏啊都在烟火里.
