
💡Yupureki:个人主页
✨个人专栏:《C++》 《算法》《Linux系统编程》《高并发内存池》《MySQL数据库》
🌸Yupureki🌸的简介:

目录
[1. 线程概念](#1. 线程概念)
[1.1 什么是线程?](#1.1 什么是线程?)
[1.2 分页式内存管理](#1.2 分页式内存管理)
[1.2.1 虚拟地址和页表的由来](#1.2.1 虚拟地址和页表的由来)
[1.2.2 页表](#1.2.2 页表)
[1.2.3 页目录](#1.2.3 页目录)
[1.2.4 两级页表的转化](#1.2.4 两级页表的转化)
[1.2.5 缺页中断](#1.2.5 缺页中断)
[2. 线程VS进程](#2. 线程VS进程)
[2.1 资源占用](#2.1 资源占用)
[2.2 切换开销](#2.2 切换开销)
[2.3 通信方式](#2.3 通信方式)
[2.4 数据同步](#2.4 数据同步)
[2.5 总结](#2.5 总结)
[2.6 如何选择?](#2.6 如何选择?)
[3. 线程控制](#3. 线程控制)
[3.1 线程创建](#3.1 线程创建)
[3.2 线程终止](#3.2 线程终止)
[3.3 线程等待](#3.3 线程等待)
[3.4 分离线程](#3.4 分离线程)
[3.5 线程ID](#3.5 线程ID)
[3.5.1 用户态线程 ID](#3.5.1 用户态线程 ID)
[3.5.2 内核态线程 ID](#3.5.2 内核态线程 ID)
[3.6 进程地址空间布局](#3.6 进程地址空间布局)
1. 线程概念
1.1 什么是线程?
- 在一个程序里的一个执行路线就叫做线程(thread)。更准确的定义是:线程是"一个进程内部的控制序列"
- 一切进程至少都有一个执行线程
- 线程在进程内部运行,本质是在进程地址空间内运行
- 在Linux系统中,在CPU眼中,看到的PCB都要比传统的进程更加轻量化
- 透过进程虚拟地址空间,可以看到进程的大部分资源,将进程资源合理分配给每个执行流,就形成了线程执行流
本质:
一个进程内的所有线程共享资源,包括虚拟地址空间,时间片等
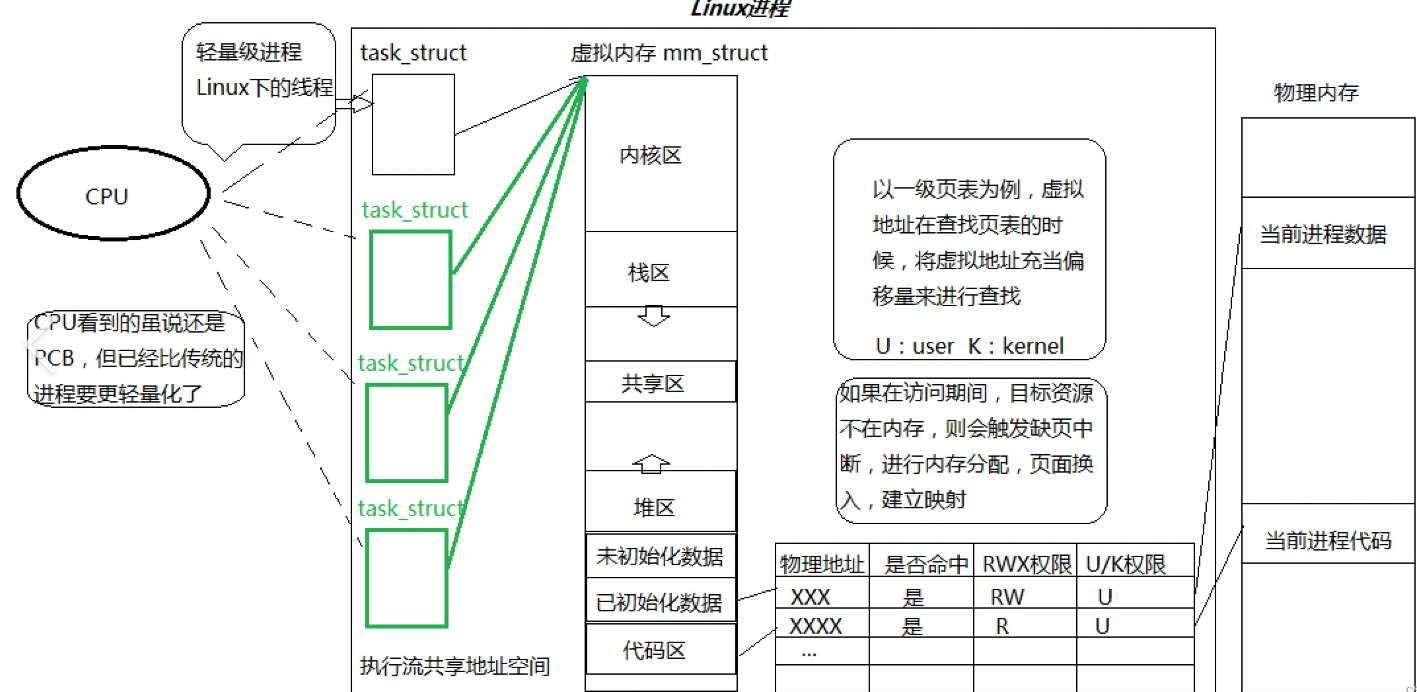
在Linux中的线程被叫做轻量级进程,本质还是用进程模拟的。但为了迎合大众,还是叫做线程
要真正理解线程,就必须搞清楚,内核是如何进行资源划分的,尤其是代码
1.2 分页式内存管理
1.2.1 虚拟地址和页表的由来
每个进程都有其虚拟地址空间 和页表,页表中存在虚拟地址到物理地址的映射关系
但胡乱映射,抢占真实的物理内存很容易造成内存使用不充分的情况,即内存碎片问题
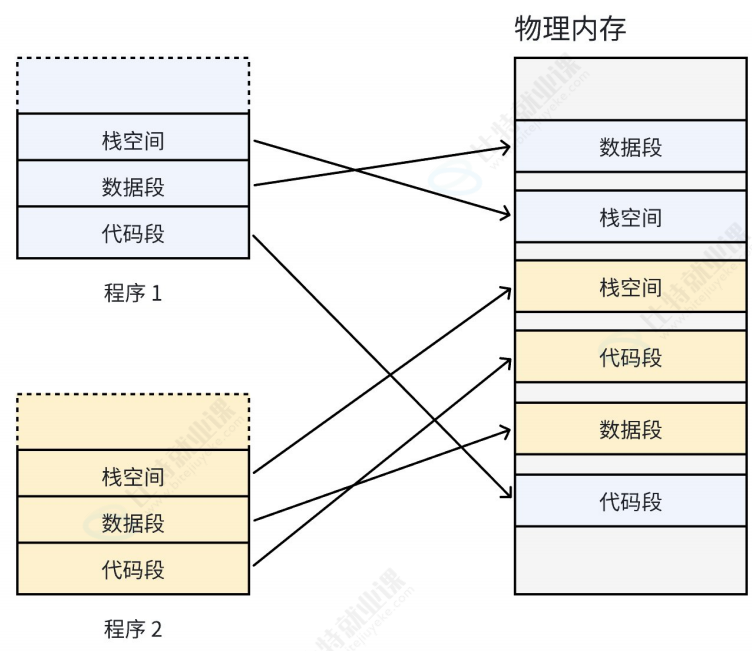
**我们希望操作系统提供给用户的空间必须是连续的,但是物理内存最好不要连续。**此时虚拟内存和分页的机制便出现了
核心概念:什么是分页?
操作系统将虚拟地址空间 和物理内存 都划分成大小固定的块,称为页 (Page)和页框 (Page Frame)。通常大小是4KB(在某些体系结构上可以是 4MB 或 2MB 等大页)。
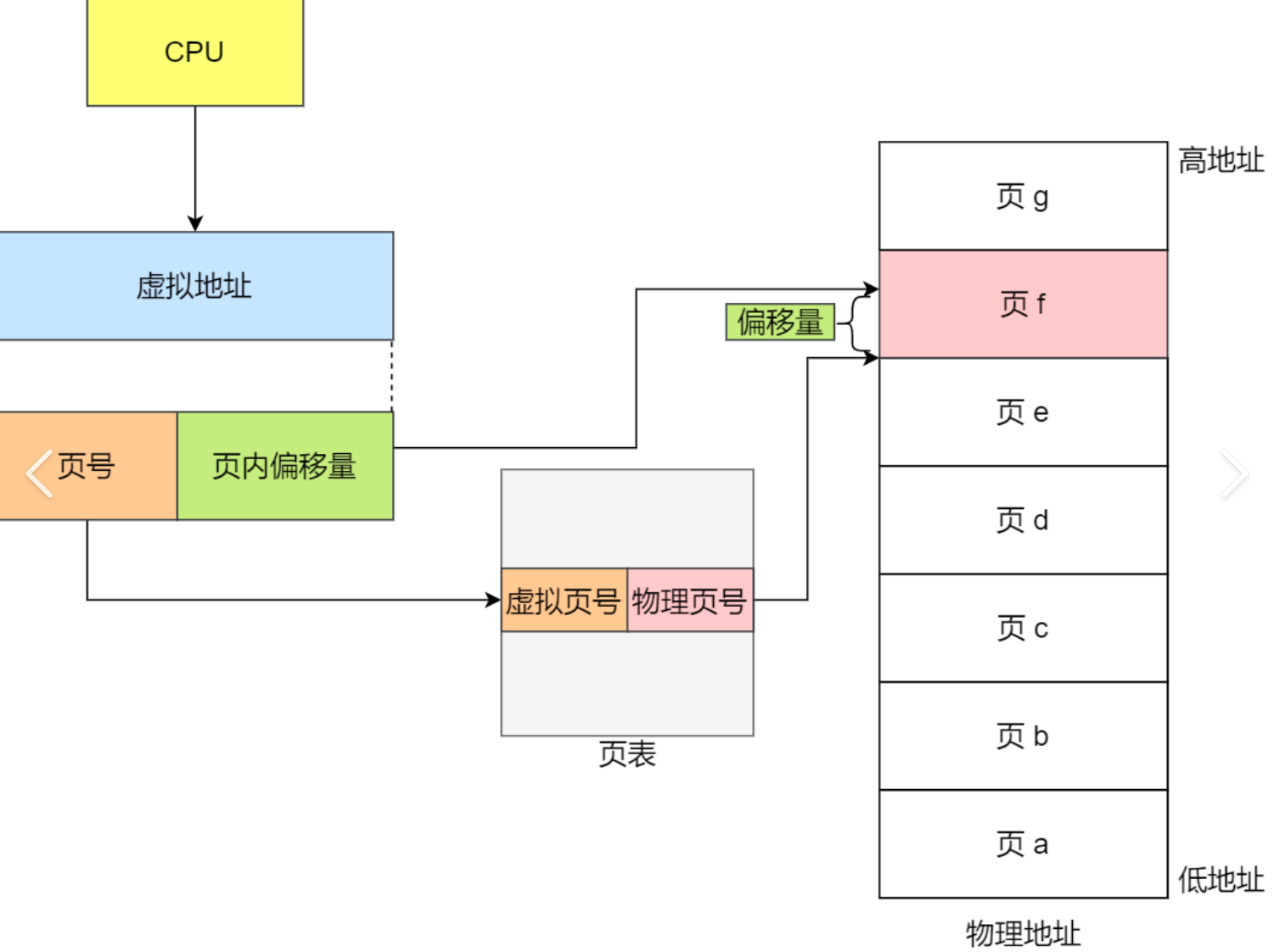
1.2.2 页表
页表中的每一个表项,指向一个物理页的开始地址 。在32位系统中,虚拟内存的最大空间是4GB,
这是每一个用户程序都拥有的虚拟内存空间。既然需要让4GB的虚拟内存全部可用,那么页表中就需要能够表示这所有的4GB空间,那么就一共需要4GB/4KB=1048576个表项。
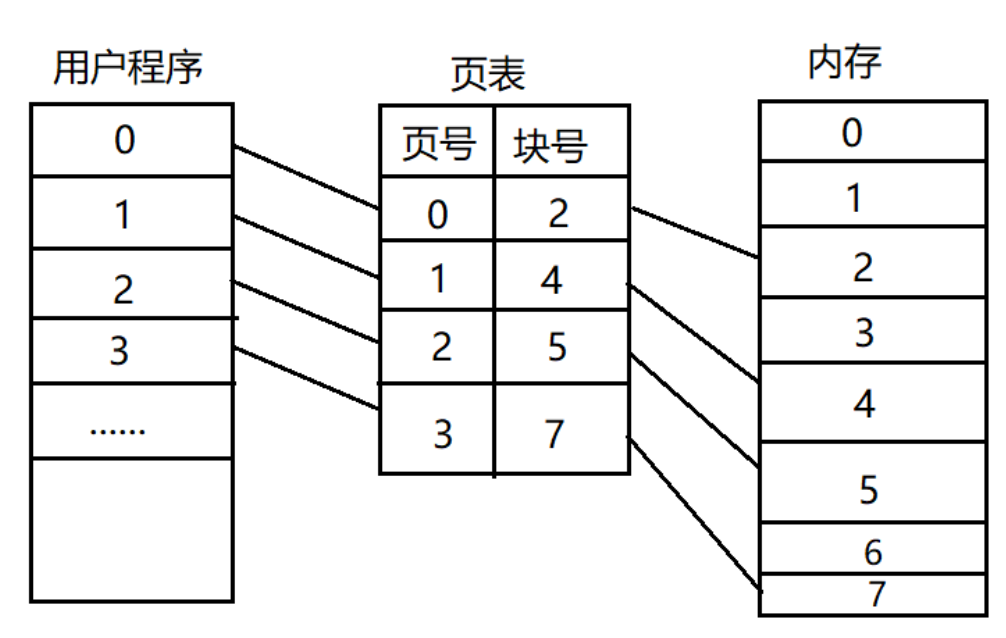
页表中的物理地址,与物理内存之间,是随机的映射关系 ,哪里可用就指向哪里(物理页)。虽然最终使用的物理内存是离散的,但是与虚拟内存对应的线性地址是连续的。处理器在访问数据、获取指令时,使用的都是线性地址,只要它是连续的就可以了,最终都能够通过页表找到实际的物理地址。
但是假设,在32位系统中,地址的长度是4个字节,那么页表中的每一个表项就是占用4个字节。所以页表占据的总空间大小就是:1048576*4=4MB 的大小。也就是说映射表自己本身,就要占用
4MB/4KB=1024个物理页。这还是只是页号的记录,甚至没记录具体在页内的偏移量,那样就更大了。
但是根据局部性原理可知,很多时候进程在一段时间内只需要访问某几个页 就可以正常运行
了。就比如我只让一个程序计算1+1等于多少,至于记录所有的页吗?因此也没有必要一次让所有的物理页都常驻内存。
1.2.3 页目录
为了解决页表浪费的情况,我们专门引入页目录来管理页表 ,一个页目录可以映射1024个页表
页目录中存的是每个页表的物理地址,由于有1024个页表,因此需要1024*4即4kb来存储页表的物理地址
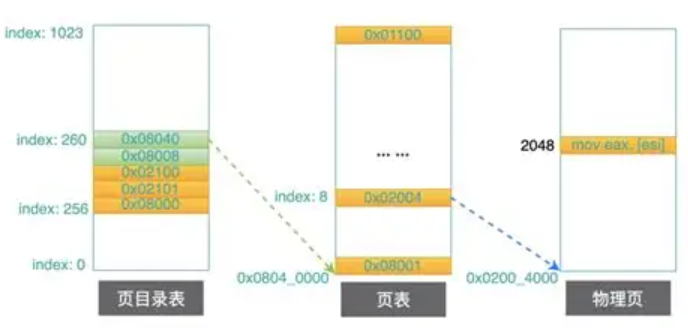
因此,我先建立一个页目录表,一个页目录表可以存1024个页表,而不是像之前直接一次性存1024*1024个页表。如果用的页数大于1024,我们再建一个页目录,再映射1024个页表即可。因此这样是每次1024个页表的创建
页目录的物理地址 被CR3寄存器指向,这个寄存器中,保存了当前正在执行任务的页目录地址。
1.2.4 两级页表的转化
我们之前说过,物理内存被分为1048576 个页,当我们知道其中一个页的起始地址,要想找到这个页中的具体的地址,只需要知道偏移量即可。那一个页内有多少种偏移量?4kb=4096=2^12,即一共有2^12种偏移量,这对应12个比特位
因此页表 存的是页内偏移量 ,即12个比特位 ,在32位平台下为前12个比特位
一个页目录有1024 个页表,即2^10 个页表,那么页目录 就存中间的10个比特位 ,表示页目录内的页表号
那剩余10个比特位谁存?寄存器 存,寄存器存最后的10个比特位,表示页目录的序号
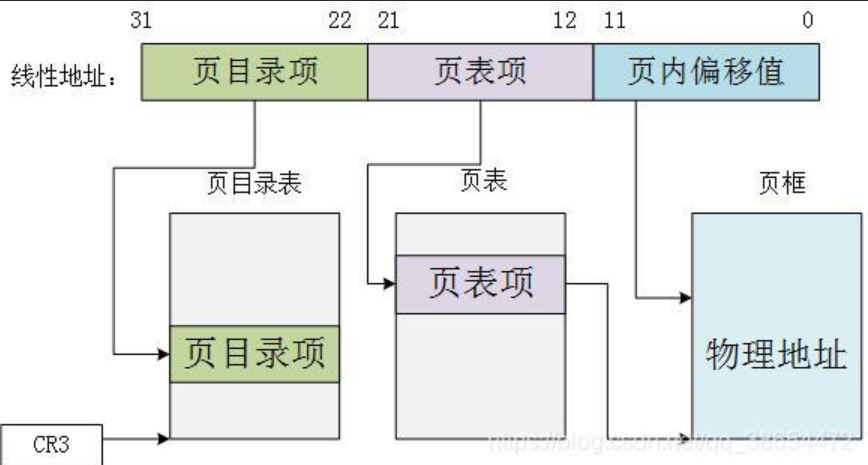
以上就是MMU的工作流程。MMU(MemoryManageUnit)是一种硬件电路,其速度很快,主要工作是进行内存管理,地址转换只是它承接的业务之一。
让我们现在总结一下**:单级页表对连续内存要求高,于是引入了多级页表,但是多级页表也是一把双刃剑,在减少连续存储要求且减少存储空间的同时降低了查询效率。**
1.2.5 缺页中断
现代操作系统都使用虚拟内存 。每个进程拥有独立的虚拟地址空间,而物理内存是共享的。CPU中的MMU负责将虚拟地址转换为物理地址,它通过查询页表来完成转换。
当发生以下三种情况时,MMU无法完成转换,就会触发缺页中断:
-
页面未映射 :虚拟地址所在的页表项为空(
pte_none),说明该地址从未被分配,或者被munmap释放了。 -
页面被换出 :页表项存在,但被标记为"不存在"(
Present位为0),通常是因为物理页被交换到了磁盘上的Swap分区。 -
权限不足 :页表项存在,但尝试的操作违反了权限。例如,试图写入一个只读的页面,或者执行一个被禁止执行的页面(见于
mmap的PROT_NONE或写时复制机制)。
当CPU捕获到缺页异常后,会陷入内核态 ,执行内核的do_page_fault函数。简单来说,这个函数会获取上下文数据,分析合法性,最终分配物理空间,重新填充虚拟地址到物理地址的映射
为什么要有缺页中断?
缺页中断的存在,本质上是为了解决计算机体系中一个根本矛盾:物理内存的容量和地址空间是有限且珍贵的,而应用程序需要的是无限、连续、且互不干扰的虚拟地址空间。如果没有缺页中断,虚拟内存就只是一个"空壳",无法真正运行程序。
因此缺页中断最显著的优点便是节约了空间。如果没有缺页中断,程序启动时,操作系统必须将其全部代码和数据(比如一个几十GB的游戏或大型数据库)一次性读入物理内存。
有了缺页中断:程序启动时,操作系统只是建立虚拟地址到文件的映射,并不实际加载数据。只有当CPU执行到某一页代码或访问某一页数据时,才触发缺页中断,内核此时才从磁盘加载这一页。这大大减少了启动时间和物理内存占用,让大程序在有限内存中也能运行。
2. 线程VS进程
2.1 资源占用
理清了分页式内存管理 的机制,我们便能从资源占用角度分析线程和进程的区别
- 进程拥有独立的地址空间、文件描述符、堆、栈、信号处理等资源。
- 线程与同进程内的其他线程共享地址空间、堆、全局变量、文件描述符 等;只拥有独立的栈、寄存器和线程局部存储(TLS)。
因此线程占用的资源要比进程小
- 同时,由于进程拥有独立的进程地址空间,子进程需要复制需要复制父进程的页表、文件描述符表等,使用
fork()时涉及写时拷贝(COW)机制。 - 而创建线程(
pthread_create)只需分配线程栈和线程控制块(TCB),复用进程的地址空间。
因此创建子线程的开销要比进程的小
但进程的开销大并不一定代表臃肿,独立的空间让进程安全性更大
- 一个进程崩溃不会波及其他进程,适合高可靠性场景(如浏览器多进程架构)。
- 而一个线程因野指针、除零等错误导致崩溃,整个进程(包括所有线程)都会终止。
2.2 切换开销
- 进程切换涉及页表切换、TLB(旁路转换缓冲,Translation Lookaside Buffer)刷新、CPU 上下文切换。
- 同进程内线程切换时地址空间不变,无需刷新 TLB,仅需保存和恢复寄存器、栈指针等。
2.3 通信方式
- 进程通信复杂,需借助进程间通信(IPC):管道、消息队列、共享内存、信号、套接字等。
- 线程通信简单,直接读写全局变量、共享内存,但需加锁(互斥锁、读写锁等)同步。
2.4 数据同步
- 进程IPC 机制大多内核介入,相对重量级。
- 线程间数据天然共享,但必须显式使用同步原语(互斥锁、条件变量、自旋锁等)避免竞态条件。
然而过于自由地共享资源也不一定是好事
- 进程进程间数据天然不共享,无需显式加锁,减少了并发编程的复杂性(但代价是需要设计 IPC)。
- 虽然线程间天然共享进程的内存空间,数据交换几乎零成本。但是同步带来资源竞争的风险,需要涉及同步,加锁的机制来防止激烈的竞争
2.5 总结
| 特性 | 进程 | 线程 |
|---|---|---|
| 资源开销 | 高 | 低 |
| 切换速度 | 慢 | 快 |
| 隔离性 | 强 | 弱 |
| 通信复杂度 | 较高(需 IPC) | 低(共享内存,需同步) |
| 编程难度 | 相对简单(无锁) | 较高(需精细的同步设计) |
| 适用场景 | 稳定优先、隔离性要求高 | 性能优先、高频数据交互 |
进程的优缺点
优点
-
稳定性与隔离性强
一个进程崩溃不会波及其他进程,适合高可靠性场景(如浏览器多进程架构)。
-
安全性高
独立的地址空间使得一个进程无法直接访问另一个进程的内存数据(需通过内核授权的 IPC),减少了安全漏洞扩散的风险。
-
利用多核 CPU
通过多进程可以充分利用多核,且不需要担心锁竞争导致的性能下降(但进程间通信仍可能成为瓶颈)。
-
编程模型简单
进程间数据天然不共享,无需显式加锁,减少了并发编程的复杂性(但代价是需要设计 IPC)。
缺点
-
资源开销大
创建和销毁进程都需要申请和回收大量资源(内存页表、文件描述符等),进程切换开销也远高于线程。
-
进程间通信效率低
IPC 机制通常需要内核参与和数据拷贝(共享内存除外),性能低于线程间直接访问共享内存。
-
扩展性受限
进程数过多时,系统负载(调度开销、内存占用)会显著增加。
线程的优缺点
优点
-
轻量高效
创建、销毁和切换速度快,资源占用少,适合高并发场景(如 Web 服务器、数据库)。
-
通信便捷
线程间天然共享进程的内存空间,数据交换几乎零成本,只需注意同步即可。
-
资源利用率高
线程可以充分利用多核并行执行任务,且共享资源(如打开的文件、内存池)避免了重复复制。
缺点
-
稳定性差
一个线程因野指针、除零等错误导致崩溃,整个进程(包括所有线程)都会终止。
-
同步复杂
共享数据带来了竞态条件风险,必须引入锁、条件变量等同步机制,容易产生死锁、性能下降(锁竞争)等问题。
-
调试难度大
多线程程序的 bug(如数据竞争、死锁)往往具有偶发性,难以复现和定位。
-
存在安全隐患
线程间直接共享内存,若某个线程存在漏洞(如缓冲区溢出),可能被攻击者利用来读写其他线程的敏感数据。
2.6 如何选择?
在实际开发中,选择进程还是线程取决于具体场景:
-
优先选多进程:
-
需要高稳定性、强隔离性(如守护进程、关键服务、Chrome 浏览器标签页)
-
任务之间关联性低,通信少
-
希望避免锁的复杂性
-
-
优先选多线程:
-
高并发、高吞吐场景(如 Nginx、Redis)
-
任务之间需要频繁共享大量数据
-
对资源开销敏感(如嵌入式设备)
-
-
混合模型 :
实际大型系统中常采用多进程 + 多线程 混合模式。例如,主进程负责管理,多个工作进程各自内部使用线程池处理请求(如 Apache 的
prefork和worker模式、Nginx 的多进程架构)。这样既利用进程隔离提高稳定性,又通过线程提高并发效率。
3. 线程控制
接下来我们通过 POSIX 线程库(pthread) ,在 Linux 环境下进行线程操作的实战演练,涵盖线程的创建、终止、等待和分离。所有示例代码均使用 C/C++语言,编译时需链接 pthread 库(gcc -pthread)。
3.1 线程创建
cpp
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine)(void *), void *arg);-
thread:输出参数,返回新线程的 ID。 -
attr:线程属性,一般传NULL使用默认属性。 -
start_routine:线程入口函数,返回void*,参数为void*。 -
arg:传递给线程函数的参数。 -
返回值:成功返回 0,失败返回错误码。
创建线程时,最重要的莫过于设计子线程运行的函数 ,在pthread_create指定该函数后,子线程创建后自动从该函数开始运行,同时函数的参数固定 (void* arg),pthread_create传入的arg参数 自动传入子线程运行的函数内
cpp
void* thread_func(void* arg) {
.....
}测试:
cpp
#include <pthread.h>
#include <stdio.h>
#include <unistd.h>
// 线程函数
void* thread_func(void* arg) {
int num = *(int*)arg;
printf("线程 %d 正在运行\n", num);
sleep(1);
printf("线程 %d 结束\n", num);
return NULL;
}
int main() {
pthread_t t1, t2;
int arg1 = 1, arg2 = 2;
// 创建线程
if (pthread_create(&t1, NULL, thread_func, &arg1) != 0) {
perror("pthread_create t1");
return 1;
}
if (pthread_create(&t2, NULL, thread_func, &arg2) != 0) {
perror("pthread_create t2");
return 1;
}
// 等待线程结束(后面会详细介绍)
pthread_join(t1, NULL);
pthread_join(t2, NULL);
printf("主线程退出\n");
return 0;
}
3.2 线程终止
线程可以在以下情况下终止:
-
调用
pthread_exitcppvoid pthread_exit(void *retval);retval:线程退出状态,可由其他线程通过pthread_join获取。调用pthread_exit后,线程立即终止,不会执行后续代码。 -
被其他线程取消(
pthread_cancel)cppint pthread_cancel(pthread_t thread);向目标线程发送取消请求,目标线程是否响应取决于其取消状态和类型。此处暂不深入。
-
从线程函数返回
线程函数执行
return,返回值作为线程退出状态。
测试:
cpp
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
void* worker(void* arg) {
int* p = (int*)malloc(sizeof(int));
*p = 42;
printf("工作线程准备退出,返回地址 %p 值为 %d\n", p, *p);
pthread_exit(p); // 返回动态分配的内存地址
}
int main() {
pthread_t tid;
void* ret;
pthread_create(&tid, NULL, worker, NULL);
pthread_join(tid, &ret);
printf("主线程获取到返回值:%d\n", *(int*)ret);
free(ret); // 记得释放内存
return 0;
}
3.3 线程等待
为什么需要线程等待?
- 已经退出的线程,其空间没有被释放,仍然在进程的地址空间内。
- 创建新的线程不会复用刚才退出线程的地址空间。
函数原型
cpp
int pthread_join(pthread_t thread, void **retval);-
thread:要等待的线程 ID。 -
retval:输出参数,保存线程退出状态(如果线程通过return或pthread_exit返回,则指向返回值;若线程被取消,则PTHREAD_CANCELED)。 -
行为:
-
调用线程阻塞,直到目标线程终止。
-
自动回收目标线程的资源(栈、寄存器状态等),防止僵尸线程。
-
一个线程只能被
join一次,且必须是可连接的(joinable)状态。
-
测试:
cpp
#include <pthread.h>
#include <stdio.h>
#include <cstdlib>
void* add(void* arg) {
int* nums = (int*)arg;
int* result = (int*)malloc(sizeof(int));
*result = nums[0] + nums[1];
return result;
}
int main() {
pthread_t tid;
int input[2] = {10, 20};
int* sum;
pthread_create(&tid, NULL, add, input);
pthread_join(tid, (void**)&sum);
printf("10 + 20 = %d\n", *sum);
free(sum);
return 0;
}
3.4 分离线程
- 默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成系统泄漏。
- 如果不关心线程的返回值,join是一种负担,这个时候,我们可以告诉系统,当线程退出时,自动释放线程资源。
函数原型
cpp
int pthread_detach(pthread_t thread);-
将线程设置为分离状态(detached)。
-
分离线程终止时,系统自动回收其资源,无需也不允许其他线程对它调用
pthread_join。 -
线程可以在创建时通过属性设置为分离,也可以在运行中自己或由其他线程调用
pthread_detach分离。
测试:
cpp
#include <pthread.h>
#include <stdio.h>
#include <unistd.h>
void* detached_task(void* arg) {
printf("分离线程开始工作\n");
sleep(2);
printf("分离线程结束,资源自动回收\n");
return NULL;
}
int main() {
pthread_t tid;
pthread_attr_t attr;
// 初始化线程属性
pthread_attr_init(&attr);
// 设置为分离状态
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED);
if (pthread_create(&tid, &attr, detached_task, NULL) != 0) {
perror("pthread_create");
return 1;
}
pthread_attr_destroy(&attr); // 属性不再需要
// 主线程继续执行,不等待分离线程
printf("主线程继续运行,无需 join\n");
sleep(3); // 让分离线程有机会执行完
printf("主线程退出\n");
return 0;
}
3.5 线程ID
在 Linux 的多线程编程中,你会遇到两种"线程 ID":
-
用户态线程 ID(pthread_t)
-
内核态线程 ID(tid,即 task_struct 中的 pid)
3.5.1 用户态线程 ID
pthread_t用于进程内,是用来标识进程内唯一线程的
-
类型 :
pthread_t(通常是一个结构体或指针,取决于实现) -
获取方式 :
pthread_self() -
作用域 :只在当前进程中有效,用于
pthread库的函数(如pthread_join,pthread_cancel) -
本质 :由线程库(NPTL)维护的一个句柄,不一定是整数 ,在不同平台可能不同(例如 glibc 中它是一个
unsigned long int,实际是指向一个struct pthread的指针)。 -
特点 :两个不同进程中的线程可以有相同的
pthread_t值,但彼此无关。
3.5.2 内核态线程 ID
tid用于系统中,用来标识唯一的进程。因为一开始进程内只有一个线程,这个线程被称为主线程。我们用tid用来表示进程,也相当于表示其中的主线程
-
类型 :
pid_t(即int) -
获取方式 :系统调用
gettid()(glibc 未直接封装,需用syscall(SYS_gettid)) -
作用域 :系统全局唯一(同一时刻),在
/proc/[pid]/task/目录下可见,也是ps -eLf命令中显示的LWP(轻量级进程)列。 -
本质 :Linux 内核中每个线程由一个
task_struct表示,它的pid字段就是内核线程 ID。而进程 ID(PGID)则是线程组中第一个线程的 PID。
注意 :
pthread_create返回的线程 ID 和内核线程 ID 是一一对应 的,但它们是不同的值。你可以通过pthread_self()获取用户态 ID,通过gettid()获取内核态 ID。
3.6 进程地址空间布局
一个进程的虚拟地址空间(Virtual Address Space)是操作系统为每个进程提供的独立内存视图。在多线程环境下,所有线程共享同一个地址空间,但每个线程拥有独立的栈和线程局部存储(TLS)。
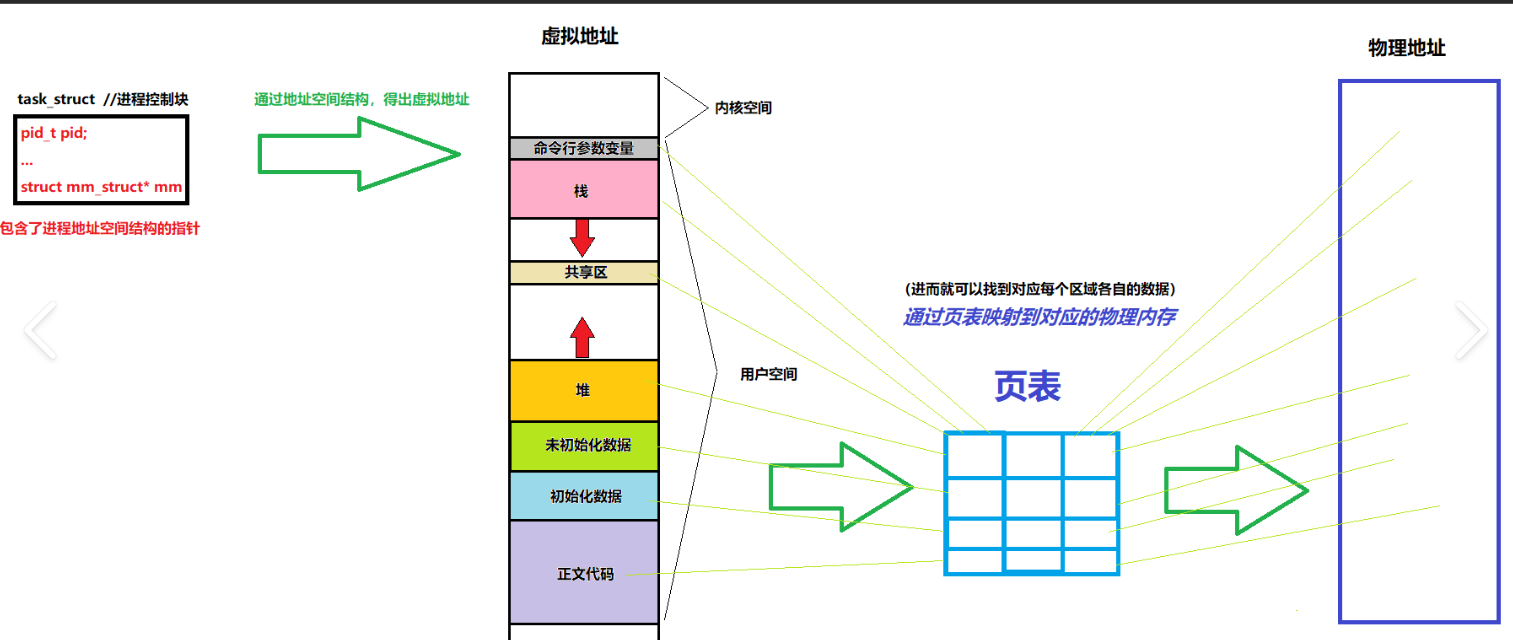
在多线程中,创建子线程时,线程库会通过**mmap** 在内存映射段分配一块内存作为线程栈(默认大小通常为 8MB)
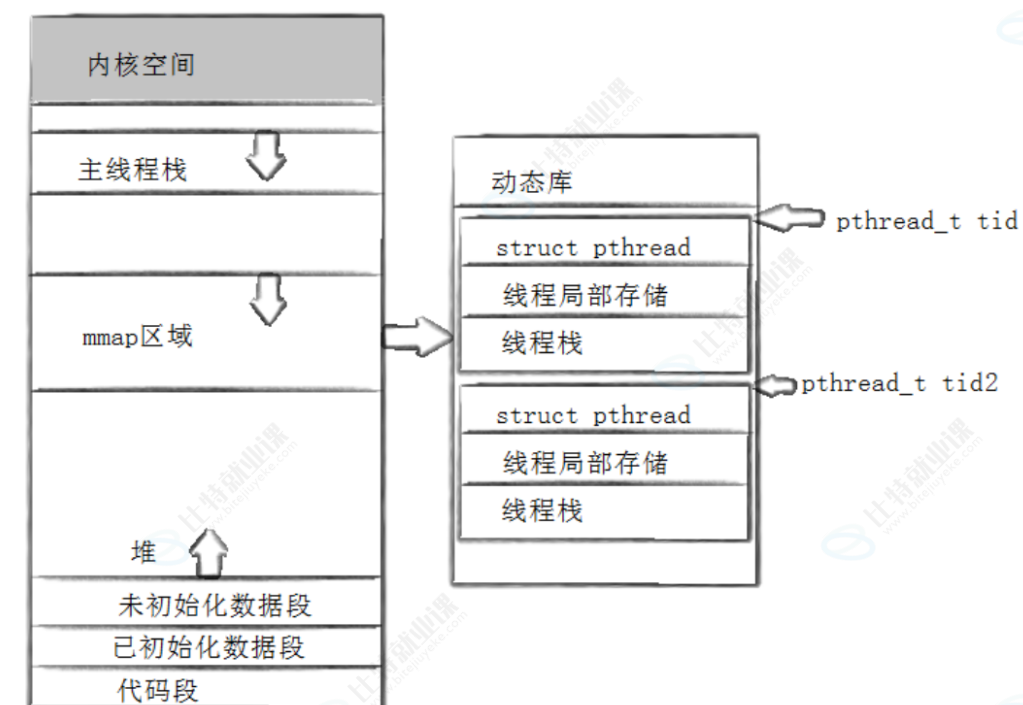
因此每个线程 拥有独立的栈(位于地址空间的某个位置,通常由 mmap 分配)和寄存器上下文。线程局部存储(TLS)也是每个线程独立的,但位于共享区域(如通过 __thread 关键字修饰的变量)。