文章目录
- [Transformer学习笔记:从 Attention 核心理论到机器翻译代码项目学习实战](#Transformer学习笔记:从 Attention 核心理论到机器翻译代码项目学习实战)
-
- [理论篇:解构 Transformer 的灵魂与骨肉](#理论篇:解构 Transformer 的灵魂与骨肉)
-
- 什么是注意力?
- 什么是自注意力的核心
- [1. 整体架构:Encoder-Decoder 范式](#1. 整体架构:Encoder-Decoder 范式)
- [2. 数据入口:文本是如何"数字化"的?](#2. 数据入口:文本是如何“数字化”的?)
-
- [2.1 词嵌入(Word Embedding)](#2.1 词嵌入(Word Embedding))
- [2.2 位置编码(Positional Encoding)](#2.2 位置编码(Positional Encoding))
- [3. 自注意力机制(Self-Attention)](#3. 自注意力机制(Self-Attention))
-
- [3.1 绝妙的比喻:Q、K、V 是什么?](#3.1 绝妙的比喻:Q、K、V 是什么?)
- [3.2 缩放点积注意力(Scaled Dot-Product Attention)](#3.2 缩放点积注意力(Scaled Dot-Product Attention))
- [4. 多头注意力(Multi-Head Attention)](#4. 多头注意力(Multi-Head Attention))
- [5. 网络稳定器:Add & Norm](#5. 网络稳定器:Add & Norm)
- [6. 前馈神经网络(FFN)与 掩码(Mask)](#6. 前馈神经网络(FFN)与 掩码(Mask))
- 掩码注意力机制------填充掩码
- Padding(填充)
- 因果掩码 (Causal Mask)
- [Transformer 整体结构定义](#Transformer 整体结构定义)
- 7.句子案列:"我是一只鸟"
- [🚀 第一阶段:编码器(Encoder)------ 深入理解"我是一只鸟"](#🚀 第一阶段:编码器(Encoder)—— 深入理解“我是一只鸟”)
-
- [1. Inputs(输入)](#1. Inputs(输入))
- [2. Input Embedding(词嵌入向量)](#2. Input Embedding(词嵌入向量))
- [3. Positional Encoding(位置编码)](#3. Positional Encoding(位置编码))
- [4. 进入编码器堆叠层(Encoder N×)](#4. 进入编码器堆叠层(Encoder N×))
-
- [步骤 4.1:Multi-Head Attention(多头自注意力机制)](#步骤 4.1:Multi-Head Attention(多头自注意力机制))
- [步骤 4.2:Add & Norm(层归一化与残差连接)](#步骤 4.2:Add & Norm(层归一化与残差连接))
- [步骤 4.3:Feed Forward(前馈神经网络层)](#步骤 4.3:Feed Forward(前馈神经网络层))
- [步骤 4.4:Add & Norm(再次归一化与残差连接)](#步骤 4.4:Add & Norm(再次归一化与残差连接))
- [🎯 第二阶段:解码器(Decoder)------ 逐字生成"I am a bird"](#🎯 第二阶段:解码器(Decoder)—— 逐字生成“I am a bird”)
-
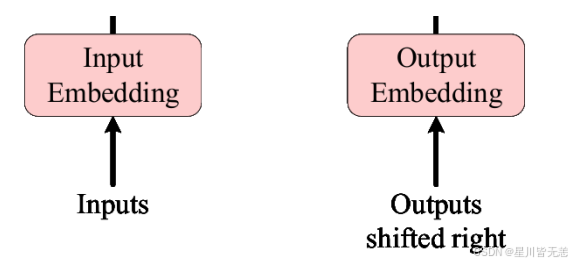
- [1. Outputs (shifted right)(目标输入)](#1. Outputs (shifted right)(目标输入))
- [2. Output Embedding & Positional Encoding](#2. Output Embedding & Positional Encoding)
- [3. 进入解码器堆叠层(Decoder N×)](#3. 进入解码器堆叠层(Decoder N×))
-
- [步骤 3.1:Masked Multi-Head Attention(带因果掩码的多头自注意力机制)](#步骤 3.1:Masked Multi-Head Attention(带因果掩码的多头自注意力机制))
- [步骤 3.2:Multi-Head Attention(多头交叉注意力机制)](#步骤 3.2:Multi-Head Attention(多头交叉注意力机制))
- [步骤 3.3:Feed Forward 与 Add & Norm](#步骤 3.3:Feed Forward 与 Add & Norm)
- [4. 最终输出预测(Linear 与 Softmax)](#4. 最终输出预测(Linear 与 Softmax))
- [项目实战:基于 Transformer 的中英机器翻译](#项目实战:基于 Transformer 的中英机器翻译)
-
- [1. 语料准备与分词(Tokenization)](#1. 语料准备与分词(Tokenization))
- [2. 构建数据加载器与 Mask 生成](#2. 构建数据加载器与 Mask 生成)
- [3. PyTorch 完美复刻 Transformer 模型](#3. PyTorch 完美复刻 Transformer 模型)
- Transformer模型中前馈神经网络的实现
- [4. 优化器策略与多 GPU 训练](#4. 优化器策略与多 GPU 训练)
- [5. 高级推理:Beam Search(集束搜索)](#5. 高级推理:Beam Search(集束搜索))
Transformer学习笔记:从 Attention 核心理论到机器翻译代码项目学习实战
Transformer 凭借其极其大胆的创新------"彻底抛弃循环(RNN)和卷积(CNN),仅仅依赖注意力机制(Attention Mechanism)",在 NLP 乃至多模态领域大放异彩。
通过结合原论文《Attention Is All You Need》------"注意力就是你所需要的一切" 梳理一下 Transformer 的学习记录。
《Attention Is All You Need》.pdf链接: https://pan.baidu.com/s/1ZG0YK3qa8afTRPd0ECmi2g?pwd=hm5i 提取码: hm5i
项目中用到的Data:
链接: https://pan.baidu.com/s/1ZzVxFX17MzBn6ypDXNaNGA?pwd=jjzx 提取码: jjzx
内容是在我理解的基础上进行整理的,如有问题或不恰当之处,欢迎各位指正!
理论篇:解构 Transformer 的灵魂与骨肉
什么是注意力?
例如,当我们看一句话的时候,每一个字会重点关注与之相关联的字。
什么是自注意力的核心
让模型自动算出每个字与所有字的关联程度(注意力分数),在用这个字分数给每个字生成一个融合上下文信息的新表示(新的向量矩阵)
1. 整体架构:Encoder-Decoder 范式
Transformer 依然采用了经典的编码器-解码器(Encoder-Decoder)结构。
原文介绍

-
编码器(Encoder): 负责将输入序列编码为上下文相关的特征表示。原论文由 6 个相同的层堆叠而成。
解码器(Decoder): 同样由 6 个相同的层堆叠而成,在编码器输出的基础上,逐步生成目标文本。
当然这个堆层数并不是定死的,可以根据自己的实际任务情况进行调整!
🌟 核心优势: 完全基于自注意力机制(Self-Attention),使得序列中的输入是可以并行的,并行计算训练效率高,省时间!还彻底摆脱了 RNN 的循环限制,极大地提升了训练效率和长距离依赖的建模能力。简单来说:Transformer是可以并行计算的,还解决了长距离依赖问题!
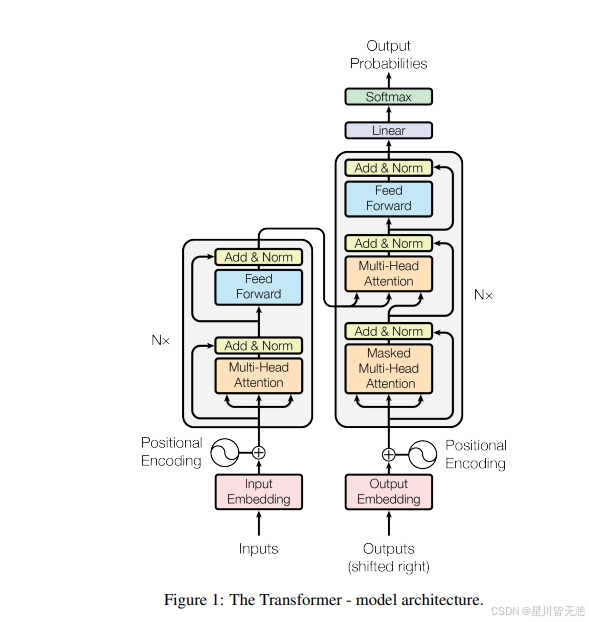
每个子层的输出之后,先进行残差连接(Add)x+Sublayer(x),防止梯度消失,保证数据在层与层之间的传递和训练稳定性能。接着进行层归一化LayerNorm(x+Sublayer(x)),层归一化的对象是对每个样本的每一层(特征维度) 进行归一化。为了方便这些残差连接,模型中的所有子层,以及嵌入层,都会产生维度d_model= 512的输出。
2. 数据入口:文本是如何"数字化"的?
Transformer里面的计算都是数值计算,所有文本在进入模型前都需要进行被"数字化"!
2.1 词嵌入(Word Embedding)
传统的独热向量(One-hot)由于非常稀疏,无法表达离散数据间的语义关联。
说到底还是独热向量表达信息的能力太弱,更别说长文本,超长文本这些,如果文本非常大的话,那这个独热向量的维度大得离谱...
我们使用词嵌入矩阵(Embedding Matrix),将 ID 映射为具有连续维度的向量(一般论文模型中 d_model=512),从而实现"语义相近的词向量距离近,差异大的词距离远"。
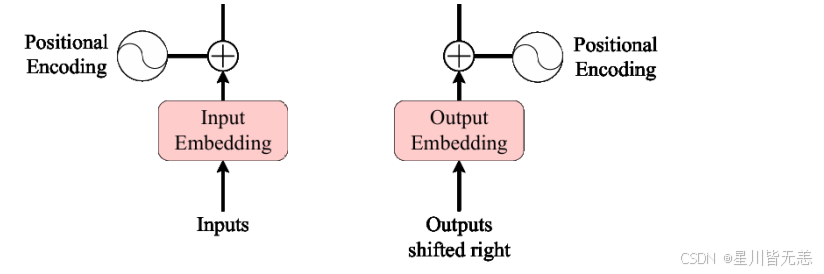
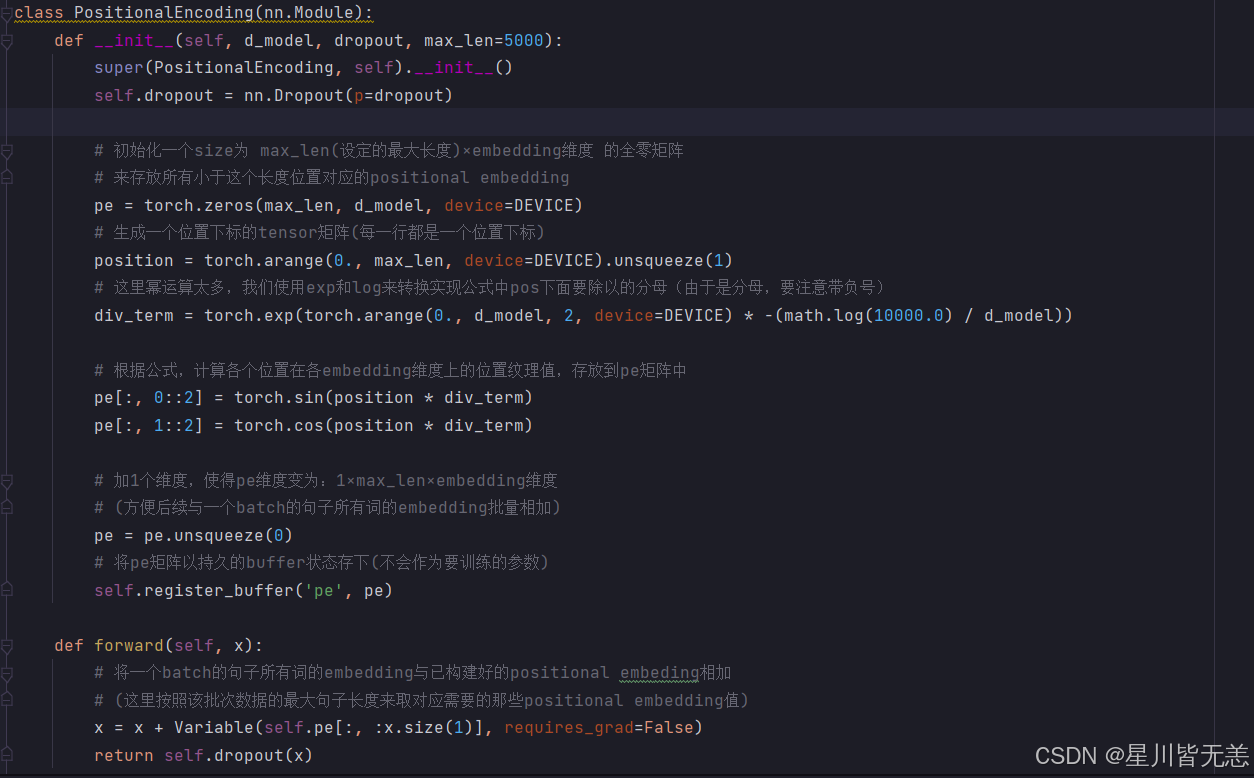
2.2 位置编码(Positional Encoding)
rnn是循环神经网络,是按照时间步递归处理时间序列,每一步的状态依赖前一步的隐藏状态,必须等前一步的时间步计算完才能计算下一个。
而LSTM长短时记忆网络作为RNN的变体,也是要上一个步骤计算完才能完成下一个的步骤。但是LSTM解决了RNN的记忆力太差(梯度消失)问题,这事因为当层数非常多的时候,层层相乘,梯度会变得越来越小逐步趋于0,信息在曾与层之前的传递就无法保证,容易出现 记住后面的忘了前面的!
LSTM 的出现就是为了专门解决这个"长距离依赖"问题:

LSTM 就像是手里拿了一个笔记本(细胞状态 C_t),遇到废话就划掉(遗忘门),遇到重点就记下来(输入门),最后根据最终总结搜集到的有用信息_笔记来理解当前的话(输出门)。
根据模型图很容易看出来,Transformer模型不包含卷积也不包含递归!正因为模型没有 RNN 循环结构,输入是并行的,它天生是个"脸盲",当输入一个句子的时候,如果没有位置编码向量,就无法感知词语的先后顺序。因此,我们需要通过位置编码来给每个位置注入时序信息。正是因为有了位置编码向量,模型才能感知到句子的顺序信息!

原论文中很明显告诉我们 输出的文本经过转换为词嵌入向量之后的维度d和位置编码的维度d一定是一样的,否则维度不同无法相加!
原论文采用了正余弦公式:

pos 指当前词在句子中的位置,i 指词嵌入矩阵的维度索引。偶数维度用 sin,奇数维度用 cos。这就好比给每个词打上了一个"时间戳",保留了序列的顺序信息。
位置编码向量的每一维都对应一个一个正弦波!
3. 自注意力机制(Self-Attention)
为什么叫"自"注意力?因为 Q,K,V 都来自同一句话本身,通俗一点就是,自己和自己做注意力计算。没和其他东西,没和其他人做注意力计算,所以叫"自"!整个过程都是我自己参与。
3.1 绝妙的比喻:Q、K、V 是什么?
通过相亲案例理解:
- Q (Query / 查询): 【我要找什么】------ 用来发起匹配的需求。
- K (Key / 键): 【我是什么】------ 用来被别人匹配的自我介绍。
- V (Value / 值): 【我有什么】------ 匹配成功后,用来最终提取的实际内容。
3.2 缩放点积注意力(Scaled Dot-Product Attention)
自注意力的核心,就是让模型自动算出每个词和其他所有词的关联程度(注意力分数),再用这个分数给每个词生成一个融合了上下文信息的特征表示。
计算公式为:
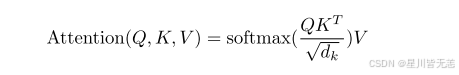
- 拿着自己的需求 Q 和每个字的自我介绍 K的转置 匹配(矩阵相乘)。如果两个向量点点积结果越大,则匹配度越高,两个字越相关。
- 为了防止点积结果过大导致 Softmax 梯度消失,除以缩放因子根号下d_k
- 通过每个字的查询向量和所有字的键向量点积之后拿到注意力机制得分,但这时候所有分数的之和不为1,通过 Softmax 函数将原始分数变成加起来等于 1 的概率权重。这样就把原始注意力融合分数转变为注意力权重,方便后面进行加权求和!
- 最后将每个字的注意力权重分数与所有字的 V(值向量) 矩阵加权相乘求和,提取出融合后的上下文特征。
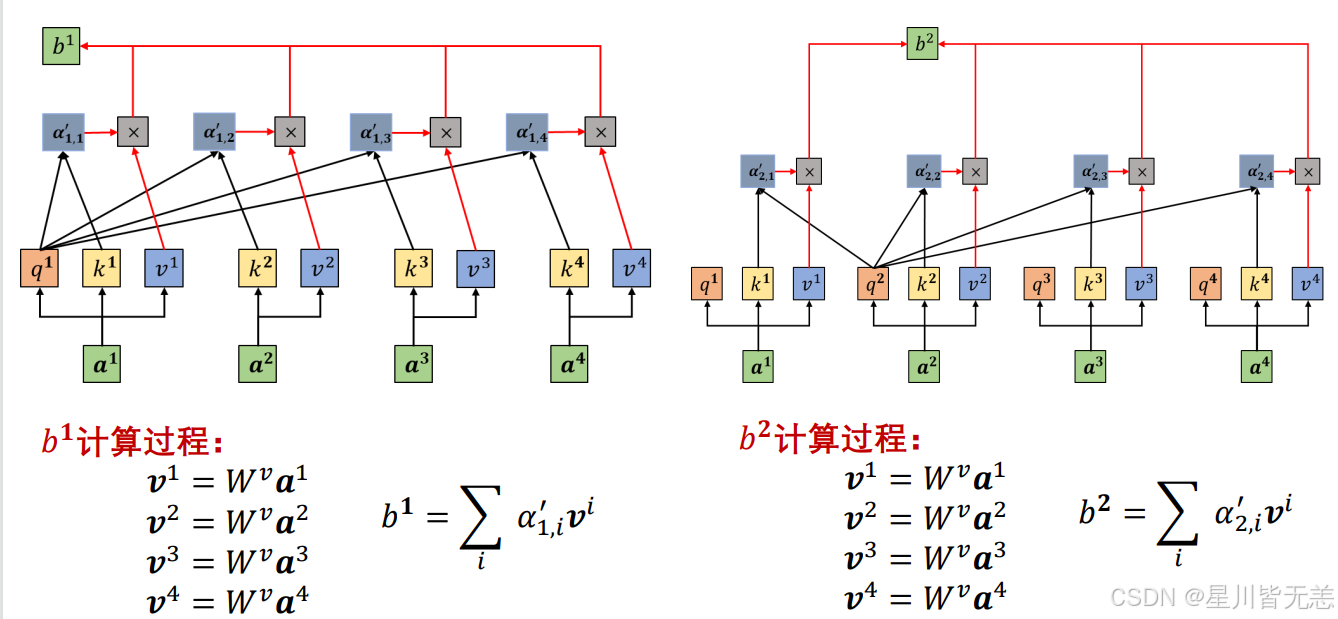
4. 多头注意力(Multi-Head Attention)
为什么用多头? 单头就像一个角度看世界,容易看不全。多头则是多个角度同时观察,信息更丰富、更精准。
模型会将 Q,K,V 分成几个头(比如 8 头),不同的头去学习不同的注意力模式(有的学主谓关系,有的学代词指代)。
每个头的权重矩阵(w_q,w_k,w_v)都不一样,最后再把所有头的输出拼接(Concat)起来,通过线性层 W_0 恢复模型维度。
w_0将多头拼接变为多头融合,将维度拉回,让后续网络能用、还能和输入做残差...
假如你输入的是Lxd 维度的数据 那么最终融合输出的也是Lxd
多头拼接并线性融合模型:

5. 网络稳定器:Add & Norm
这部分由**残差连接(Residual Connection)和层归一化(Layer Normalization)**组成。
-
残差连接 (Add): 深层神经网络(比如 ResNet 或堆了很多层的 Transformer)在反向传播时容易产生梯度消失,导致前面的层学不动。残差结构 Xout=x+Sublayer(x) 提供了一条直通路径,保住了梯度的流动,防止信息丢失。
即使注意力层学废了,原汁原味的信息还在
-
层归一化 (Norm): 与 CNN 常用的 Batch Norm 不同,这里是对每个样本的特征维度(每层)进行归一化,使得数据分布更加稳定,加速收敛。
原论文是先残差连接再做归一化,但是在模层数很深(比如几十层)容易出现训练梯度不稳定的情况,必须配合非常谨慎的Warmup学习率策略,但是目前业界更流行的是Pre-LN结构,先进行层归一化,再进行残差连接,梯度流动更加顺畅,训练更稳定。
因为后来学术界和工业界在实践中发现,原论文的 Post-LN 在模型层数很深时(比如几十层)容易出现训练梯度不稳定的情况,必须配合非常谨慎的 Warmup 学习率策略。而把归一化提前的 Pre-LN 结构,梯度流动更加顺畅,训练更稳定。这也是为什么后来的主流大模型(如 GPT 系列、LLaMA 等)基本都悄悄换成了 Pre-LN 的原因。
例如:
python
class SublayerConnection(nn.Module):
# ...
def forward(self, x, sublayer):
# 返回Layer Norm和残差连接后结果
return x + self.dropout(sublayer(self.norm(x))) return x + self.dropout(sublayer(self.norm(x)))就是Pre-ln结构

需要注意的是在层归一化中,缩放参数 γ 和平移参数 β 是可学习的,并通过反向传播算法进行更新;而均值和方差是基于当前输入动态计算的统计量,不参与参数学习。
层归一化和批归一化的区别:
| 特性 | LayerNorm | BatchNorm |
|---|---|---|
| 统计范围 | 单个样本内部 | 一个 batch |
| 是否依赖 batch size | ❌ 不依赖 | ✔ 依赖 |
| 推理阶段 | 不需要额外统计 | 需要 running mean/var |
6. 前馈神经网络(FFN)与 掩码(Mask)

前馈神经网络(FFN)为无循环的多层神经网络,数据从输入到输出单向流动,同层和跨层之间没有神经元的连接,用于进一步提取非线性特征。假如一个简单的线性变换--->x--->Linear(x)--->CNN--->y。里面的层可以是线性层也可以是卷积层。典型特征是上一层的输出是下一层的输入,不带有循环神经网络。
前馈神经网络是一种网络类型,不是仅仅指的某一个神经网络结构。
前馈神经网络在模型中不同位置的线性变换是相同的,但是不同位置的对应参数不一定相同。
掩码注意力机制------填充掩码
为什么要填充掩码?这是因为Transformer在处理批次样本数据的时候要求同一批次的所有句子长度要保持一致,方便后面在GPU上面运行。为了让同一批次不同长度的句子对齐,我们填充了无效字符,掩码机制可以屏蔽这些无用信息。
这里有需要注意点的一点是,Transformer可以出来不同批次中序列长度不一致的数据,加入第一个batch里面序列长度为20,第二个batch里面序列长度为50,但是只要是同一批次里面的序列长度一定要是一样的!!!
本质原因是Transformer输入的是三维张量:(batch_size, seq_len, d_model),如果同一批次有序列长度不一样的样本数据,那么第二维就无法保证一致,无法堆成一个矩阵。
例如:
- 句子 A:长度 20
- 句子 B:长度 50
必须做:
Padding(填充)
把短序列补齐:
bsh
A: 20 → 50(补 PAD)
B: 50 → 50这里有个疑问,就是为什么同批次的数据样本维度必须保持一致,不同批次的或者说其他批次的就可以不一样?
假设我们全局最长的句子是 500 个词,如果把所有 Batch 的所有句子都强行 Pad 到 500,会产生海量的无效计算(哪怕这个 Batch 里最长的句子才 20 个词)。 因此,更优雅的做法是动态填充:比如第一个 Batch 里最长句子是 20,我们就把这个 Batch 统一定长为 20;第二个 Batch 里最长是 50,我们就把第二个 Batch 统一定长为 50。
在工程优化方面,可以把序列长度相近的句子放在同一批次中,提升训练效率,减少 padding 浪费,节省显存开销。
因果掩码 (Causal Mask)
这是 Decoder 专用的机制!在推理时模型是逐字生成的。掩码会屏蔽当前 Token 之后的所有位置(设为 -∞),防止模型"偷看未来",保证生成的合法性,避免信息泄露。实际上是在推理时候逐字生成的掩码会在未来位置上的权重设为,保证模型只能用已生成的内容,这就是我们在平常利用AI大模型生成内容时候,都是有序的依此输出的原因。
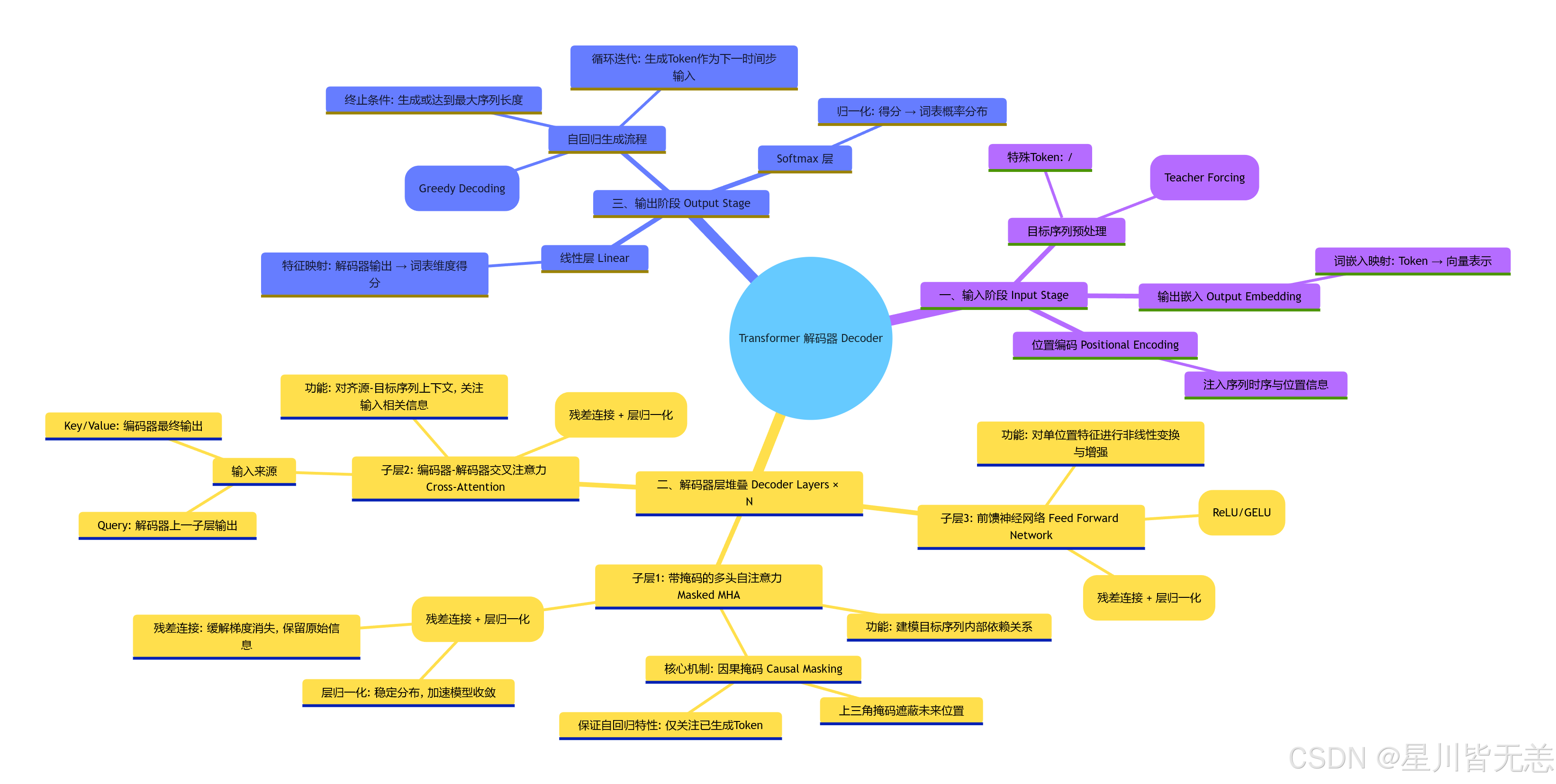
解码器思维导图
为什么要加和?
给模型一个开始生成的信号,没有模型不知道从哪里开始,给模型一个结束生成的信号。
Transformer 整体结构定义
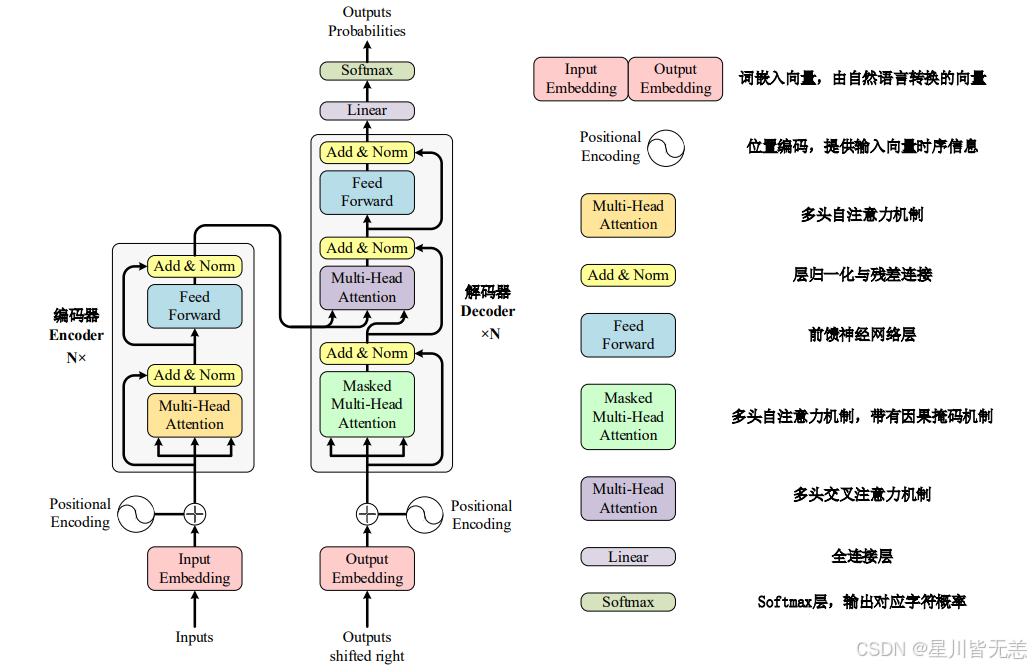
7.句子案列:"我是一只鸟"
🚀 第一阶段:编码器(Encoder)------ 深入理解"我是一只鸟"
编码器的任务,是把这句中文彻底嚼碎,提取出包含完美上下文的终极特征向量。
1. Inputs(输入)
首先,句子会被分词器(Tokenizer)切分。我们假设切分结果是 5 个 Token:["我", "是", "一", "只", "鸟"]。
2. Input Embedding(词嵌入向量)
计算机不认识汉字,它只认识数字。
- 动作: 查字典(词表),把这 5 个字映射成 5 个连续的、高维的稠密向量(比如你代码里设定的 dm ode**l=512 维)。
- 结果: 此时,"鸟"这个字变成了一串 512 个数字的数组。在这个高维空间里,它可能离"飞"、"羽毛"这些词的向量比较近。
3. Positional Encoding(位置编码)
Transformer 是高度并行的,5 个字是同时扔进模型的。为了防止模型以为你输入的是"鸟是一只我",必须加上位置标签。
- 动作: 模型会用正余弦公式生成 5 个同样是 512 维的位置向量:
Pos(0)对应"我",Pos(4)对应"鸟"。 - 相加: 将【词嵌入向量】和【位置编码向量】直接逐元素相加。
- 结果: 现在的输入不仅包含了"它是什么字",还包含了"它在第几个位置"。
4. 进入编码器堆叠层(Encoder N×)
这 5 个带着位置信息的向量,排成一个矩阵,正式进入图左侧的灰色大框(这里会循环 N 次,也就是堆叠 N 层)。
步骤 4.1:Multi-Head Attention(多头自注意力机制)
这是最核心的灵魂!"我是一只鸟"这句话里的 5 个字,开始互相"相亲打分"。
- 生成 Q、K、V: 每个字都会通过三个不同的权重矩阵,生成自己的 Q (查询:我要找什么上下文)、K (键:我能提供什么上下文)、V(值:我实际的语义内容)。
- 打分计算: 当计算"鸟"这个字的注意力时,它的 Q 鸟 会去和所有字的 K 分别做点积(包括它自己)。
- 模型可能会发现,Q 鸟 和 K只 的匹配分数非常高,因为"只"是量词,直接修饰"鸟"。
- 同时,Q 鸟 和 K我 也有一定的分数,因为确定了主语是谁。
- 加权融合: 用 Softmax 归一化这些分数后,乘以每个字对应的 V 矩阵。
- 结果: 经过这一步,"鸟"这个字的向量被彻底改变了。它不再是字典里那个孤立的"鸟",而是融合了"我"、"一只"等上下文信息的"特定的鸟"。
步骤 4.2:Add & Norm(层归一化与残差连接)
- Add(残差连接): 把步骤 3 刚进来的原始输入,直接加到刚才 4.1 算出的融合向量上(Xou**t =x +Sublayer(x))。即使注意力层学废了,原汁原味的信息还在,防止梯度消失。
- Norm(层归一化): 对这 5 个向量分别做归一化,让数据分布变得稳定,防止训练时数值爆炸。
步骤 4.3:Feed Forward(前馈神经网络层)
- 动作: 这是一个两层的全连接网络(带 ReLU 激活函数)。它不发生字与字之间的交互,而是对"我"、"是"、"一"、"只"、"鸟"这 5 个向量,逐个进行非线性空间映射,挖掘更深层的局部特征。
步骤 4.4:Add & Norm(再次归一化与残差连接)
- 和 4.2 一样,把 FFN 的输入和输出相加,再做一次归一化。
【编码器输出】 经过 N 层的反复锤炼,编码器最终吐出了 5 个极度丰满、蕴含了完美全局上下文的 512 维向量。这 5 个向量就是图中间那两个指向解码器的黑色箭头(它们将作为解码器的 K 和 V)。
🎯 第二阶段:解码器(Decoder)------ 逐字生成"I am a bird"
解码器和编码器不同,它是自回归 的,也就是一个词一个词地往外蹦。我们来看看它生成第一个英文单词 I 的瞬间发生了什么。
1. Outputs (shifted right)(目标输入)
生成第一个词时,解码器只收到一个特殊的起始符号 <bos>(Begin of Sentence)。
- 为什么叫 shifted right(右移)? 在训练时,我们会把标准答案 "I am a bird" 往右移一位,最前面补上
<bos>,用[<bos>, I, am, a]去预测[I, am, a, bird]。
2. Output Embedding & Positional Encoding
和编码器完全一样,把 <bos> 变成 512 维的稠密向量,并加上位置编码。
3. 进入解码器堆叠层(Decoder N×)
步骤 3.1:Masked Multi-Head Attention(带因果掩码的多头自注意力机制)
- 动作:
<bos>和它自己做自注意力计算。 - 为什么带 Masked(掩码)? 假设当前已经生成了
[<bos>, I],准备预测am。模型在做自注意力时,I只能看到<bos>和I,绝对不能看到未来的am、a、bird。掩码机制强行把未来位置的分数变成了 −∞(Softmax 后变 0),杜绝了作弊! - 后续: 做一次 Add & Norm。
步骤 3.2:Multi-Head Attention(多头交叉注意力机制)
这是最激动人心的跨语言沟通环节!图中画得很清楚,这一层有三个输入箭头:
- *Q*(查询): 来自下方的解码器(当前状态,比如带着
<bos>信息的向量)。它在问:"为了生成下一个英文词,我应该关注中文里的哪些信息?" - *K* 和 *V*(键和值): 来自左侧编码器的最终输出(也就是彻底理解了"我是一只鸟"的那 5 个超级向量)。
- 打分计算: 解码器的 Q 会去和中文句子的 5 个 K 分别计算点积分数。模型会发现,在起步阶段(
<bos>),注意力分数最高的往往是中文的第一个词"我"。 - 融合提取: 提取"我"的 V 向量为主的特征信息。
- 后续: 做一次 Add & Norm。
步骤 3.3:Feed Forward 与 Add & Norm
对交叉注意力提取到的跨语言特征,进行空间映射和归一化(操作同编码器 4.3 和 4.4)。
4. 最终输出预测(Linear 与 Softmax)
经过 N 层解码器堆叠后,得到了一个代表下一个预测词的 512 维隐层向量。
- Linear(全连接层): 把这个 512 维的向量映射到目标语言的词表大小(假设英文词表有 32,000 个词,这就变成了一个 32,000 维的向量)。
- Softmax(概率输出): 将这 32,000 个数字转化为概率分布(总和为 1)。
- 诞生: 我们查找概率最高的那个位置,发现对应的词典 ID 是
I(或者I的概率是 95%)。
至此,模型成功输出了第一个词 I!
接下来,模型会把 [<bos>, I] 作为新的 Decoder 输入,重新走一遍第二阶段的整个流程,通过交叉注意力关注中文的"是",从而预测出下一个词 am,直到输出结束符 <eos>。
项目实战:基于 Transformer 的中英机器翻译
1. 语料准备与分词(Tokenization)
在 WMT 2018 的新闻翻译任务 中,语言对包括 "Chinese↔English"即中-英/英-中方向。
数据网址;https://www.statmt.org/wmt18/
现代 NLP 必备的子词分词器,我使用了 Google 的 SentencePiece,以 BPE 算法训练出了词表大小为 32,000 的中英文分词模型。
python
# 固定 4 个特殊符号的 id:<pad>=0, <unk>=1, <bos>=2, <eos>=3
input_argument = (
'--input=%s --model_prefix=%s --vocab_size=%s --model_type=%s '
'--character_coverage=%s --pad_id=0 --unk_id=1 --bos_id=2 --eos_id=3 '
)
# 中文推荐 character_coverage 设为 0.9995,英文为 1.0
python
import json
import mysql.connector
from mysql.connector import Error
import os
# 数据库配置
DB_CONFIG = {
'host': 'localhost', # 数据库主机地址
'user': 'root', # 数据库用户名
'password': 'xxxx', # 数据库密码
'database': 'tf_data', # 数据库名称(请先在MySQL中创建此数据库)
'charset': 'utf8mb4' # 使用utf8mb4以支持所有语言字符
}
# 待处理的文件列表及对应的数据集类型
FILES_TO_PROCESS = {
'train.json': 'train',
'dev.json': 'dev',
'test.json': 'test'
}
def create_table(cursor):
"""创建用于存储句子对的数据表"""
create_table_query = """
CREATE TABLE IF NOT EXISTS sentence_pairs (
id INT AUTO_INCREMENT PRIMARY KEY,
dataset_type VARCHAR(20) NOT NULL COMMENT '数据来源(train/dev/test)',
en_text TEXT NOT NULL COMMENT '英文',
zh_text TEXT NOT NULL COMMENT '中文'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
"""
cursor.execute(create_table_query)
print("数据表 `sentence_pairs` 检查/创建成功。")
def insert_data(cursor, connection, file_path, dataset_type):
"""读取JSON文件并批量插入数据库"""
if not os.path.exists(file_path):
print(f"文件不存在,跳过: {file_path}")
return
# 读取JSON文件
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
# 准备插入的数据,格式为 (dataset_type, en_text, zh_text)
records_to_insert = []
for item in data:
if len(item) == 2:
en_text = item[0]
zh_text = item[1]
records_to_insert.append((dataset_type, en_text, zh_text))
# 使用 executemany 进行批量插入以提高性能
insert_query = """
INSERT INTO sentence_pairs (dataset_type, en_text, zh_text)
VALUES (%s, %s, %s)
"""
# 分批次插入,防止数据量过大导致内存溢出或超出MySQL包大小限制
batch_size = 5000
for i in range(0, len(records_to_insert), batch_size):
batch = records_to_insert[i:i + batch_size]
cursor.executemany(insert_query, batch)
connection.commit()
print(f"成功将 {len(records_to_insert)} 条数据从 {file_path} 存入数据库。")
def main():
try:
# 建立数据库连接
connection = mysql.connector.connect(**DB_CONFIG)
if connection.is_connected():
print("成功连接到MySQL数据库")
cursor = connection.cursor()
# 创建表
create_table(cursor)
# 遍历文件并导入数据
for filename, dataset_type in FILES_TO_PROCESS.items():
# 假设 JSON 文件与当前 Python 脚本在同一目录下
# 如果在不同目录,请修改 filename 为完整的相对或绝对路径
insert_data(cursor, connection, filename, dataset_type)
except Error as e:
print(f"数据库操作出错: {e}")
finally:
# 关闭连接
if 'connection' in locals() and connection.is_connected():
cursor.close()
connection.close()
print("MySQL数据库连接已关闭。")
if __name__ == "__main__":
main()
通过将json格式数据转存到本地的mysql,打开之后可以看到本质上,就是在一个列表中有一句英文对应一句翻译中文。
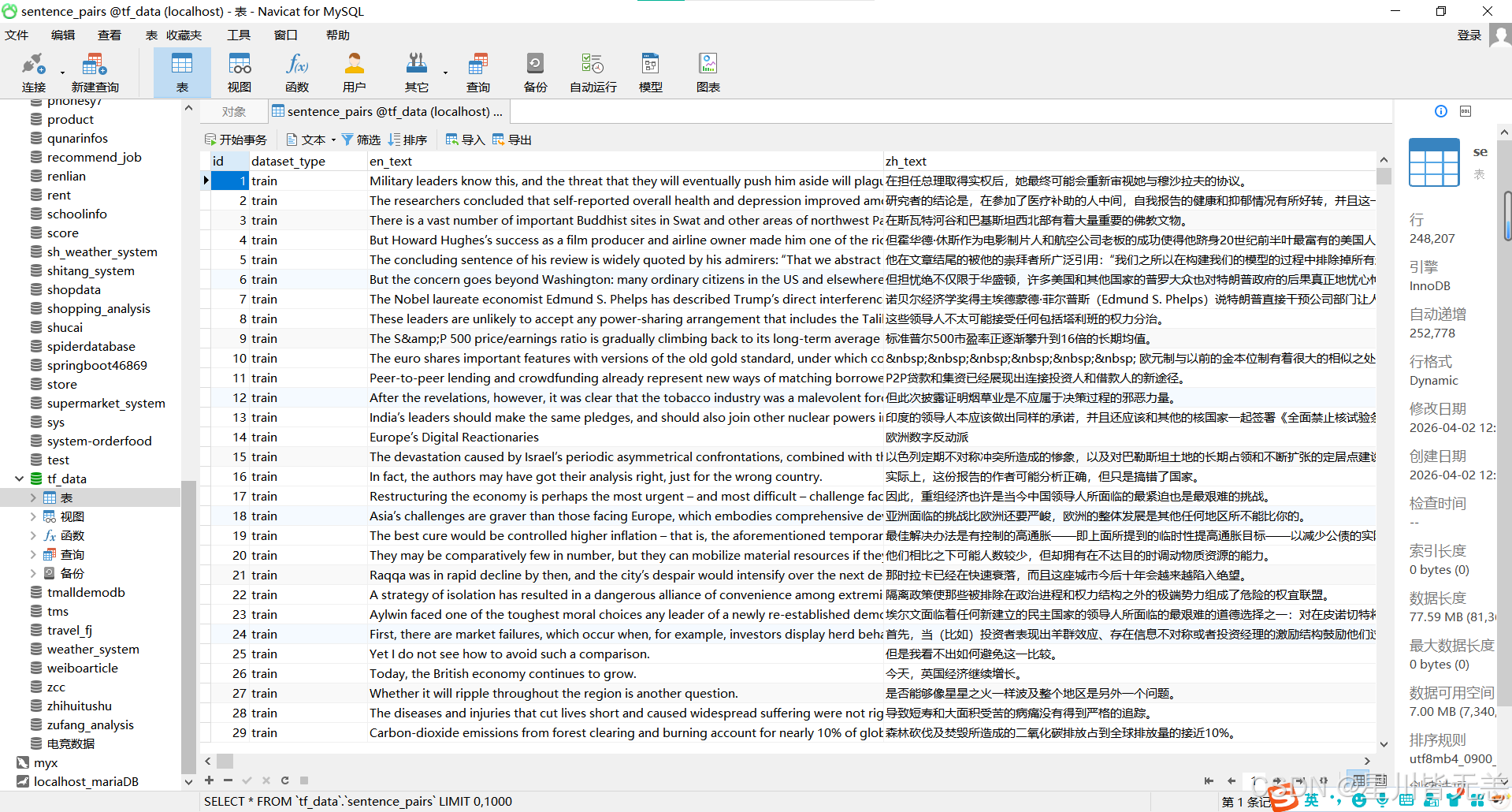
而且数据量也是不小, 一共导入 252,777 条数据
对原始的 json 文件进行处理,将对应的中 文和英文句子抽离出来,放入到对应的文件中,该操作是方便后续利用对应的中文和英文文本制作对应的分词器和词表。生成的文件如下
利用 analyze_corpus.py 脚本,即可对的 corpus.ch、corpus.en 进行分析
中英文语料库信息;
python
import os
def analyze_corpus(ch_path, en_path):
"""
分析双语语料库文件的详细信息
Args:
ch_path: 中文文件路径
en_path: 英文文件路径
"""
# 检查文件是否存在
if not os.path.exists(ch_path):
print(f"中文文件不存在: {ch_path}")
return
if not os.path.exists(en_path):
print(f"英文文件不存在: {en_path}")
return
# 获取文件大小
ch_size = os.path.getsize(ch_path)
en_size = os.path.getsize(en_path)
# 读取文件内容并统计行数
with open(ch_path, 'r', encoding='utf-8') as f:
ch_lines = f.readlines()
with open(en_path, 'r', encoding='utf-8') as f:
en_lines = f.readlines()
# 计算字符数(不包括换行符)
ch_chars = sum(len(line.strip()) for line in ch_lines)
en_chars = sum(len(line.strip()) for line in en_lines)
# 打印统计信息
print("=" * 50)
print("语料库统计信息")
print("=" * 50)
print(f"\n中文文件 ({ch_path}):")
print(f" 文件大小: {ch_size / 1024 / 1024:.2f} MB")
print(f" 总行数: {len(ch_lines):,}")
print(f" 总字符数: {ch_chars:,}")
print(f" 平均每行字符数: {ch_chars / len(ch_lines):.1f}")
print(f"\n英文文件 ({en_path}):")
print(f" 文件大小: {en_size / 1024 / 1024:.2f} MB")
print(f" 总行数: {len(en_lines):,}")
print(f" 总字符数: {en_chars:,}")
print(f" 平均每行字符数: {en_chars / len(en_lines):.1f}")
# 验证中英文行数是否匹配
if len(ch_lines) == len(en_lines):
print("\n✓ 中英文文件行数匹配")
else:
print("\n✗ 警告:中英文文件行数不匹配!")
print("=" * 50)
if __name__ == "__main__":
ch_path = 'corpus.ch'
en_path = 'corpus.en'
analyze_corpus(ch_path, en_path)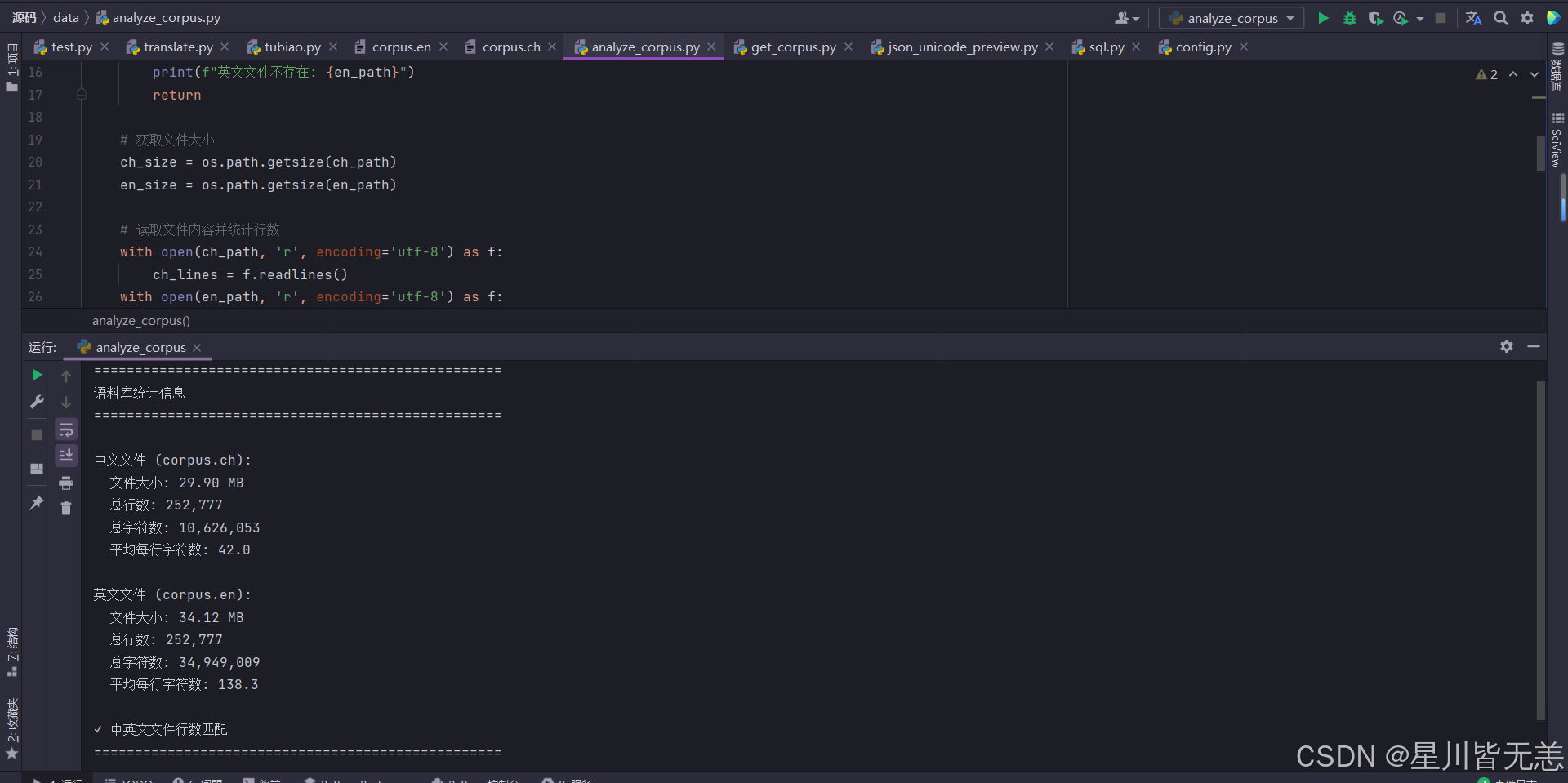
运行结果信息:
python
==================================================
语料库统计信息
==================================================
中文文件 (corpus.ch):
文件大小: 29.90 MB
总行数: 252,777
总字符数: 10,626,053
平均每行字符数: 42.0
英文文件 (corpus.en):
文件大小: 34.12 MB
总行数: 252,777
总字符数: 34,949,009
平均每行字符数: 138.3
✓ 中英文文件行数匹配中英文数据文件行数是匹配对应的,再此确认的基础上,我们可以认为这样等等数据做翻译任务是可行的。
在将中英双语语料喂给 Transformer 之前,我们必须先将其"切碎"并映射为数字 ID。在这个实战项目中,我没有使用传统的 jieba(中文)或 nltk(英文),而是直接使用了 Google 开源的 SentencePiece ,并采用了 BPE(Byte-Pair Encoding) 算法。
之前从咱们传统分词用的比较多的是jieba,传统分词遇到生僻词会直接标记为 <unk>,导致信息丢失。而 BPE 是一种"子词"算法,遇到不认识的词,它会将其拆分成认识的词根或字母组合,极大缓解了未登录词问题。
SentencePiece 直接把所有输入当成 Unicode 字符流处理,不管是中文还是英文,都可以用同一套逻辑训练词表,甚至不需要提前分词!
在代码里,我们这样设置:
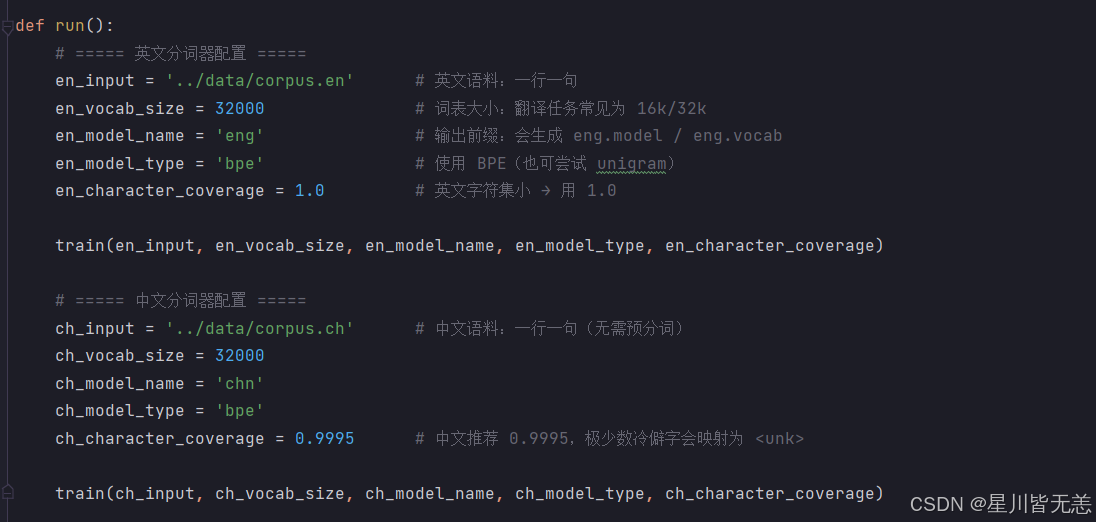
字符覆盖率 (character_coverage):
- 英文设为 1.0:因为英文字符集很小(26 个字母+符号),完全可以 100% 覆盖。
- 中文设为 0.9995:这是中文 NLP 的常规操作。汉字有几万个,其中包含大量极少使用的生僻字或特殊符号。如果设为 1.0,会导致词表被这些无用字符挤占;设为 0.9995 可以过滤掉这万分之五的冷僻字符,让模型把 32000 的词表容量全用在刀刃上。
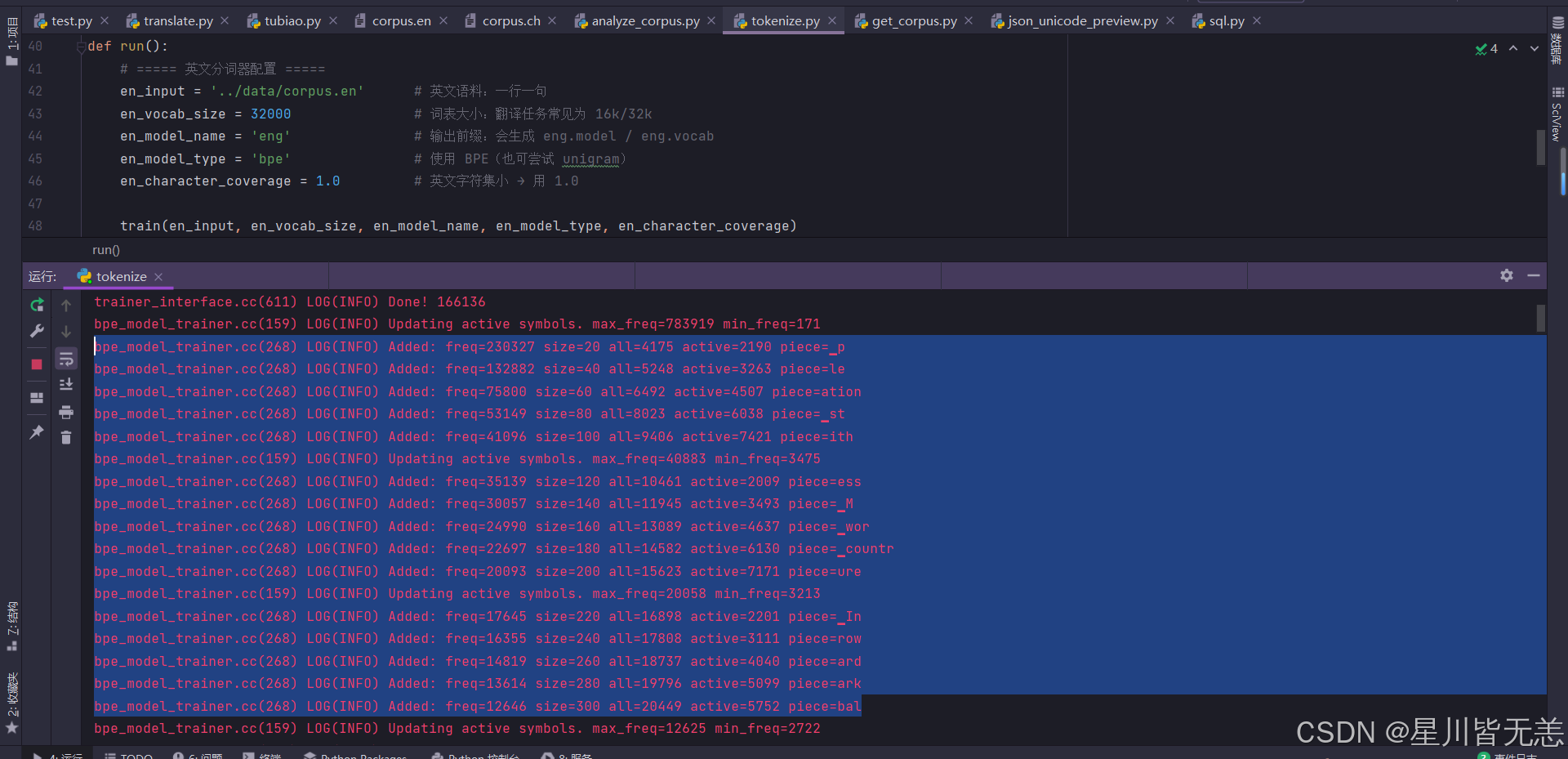
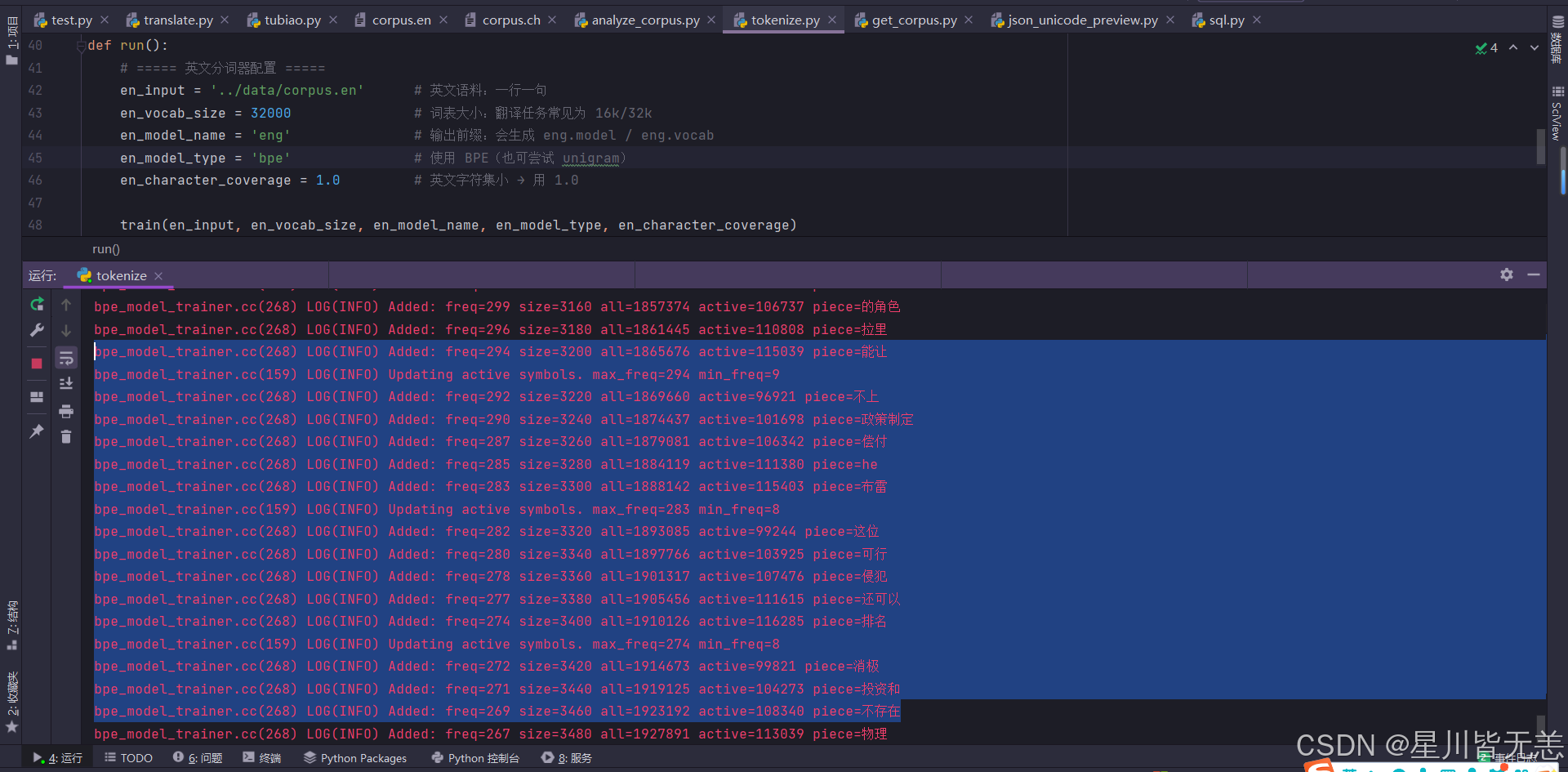
数据量大 这里分词要等一会,漫长等待ing...
等了大概7.8分钟也是好了,时间有点久...
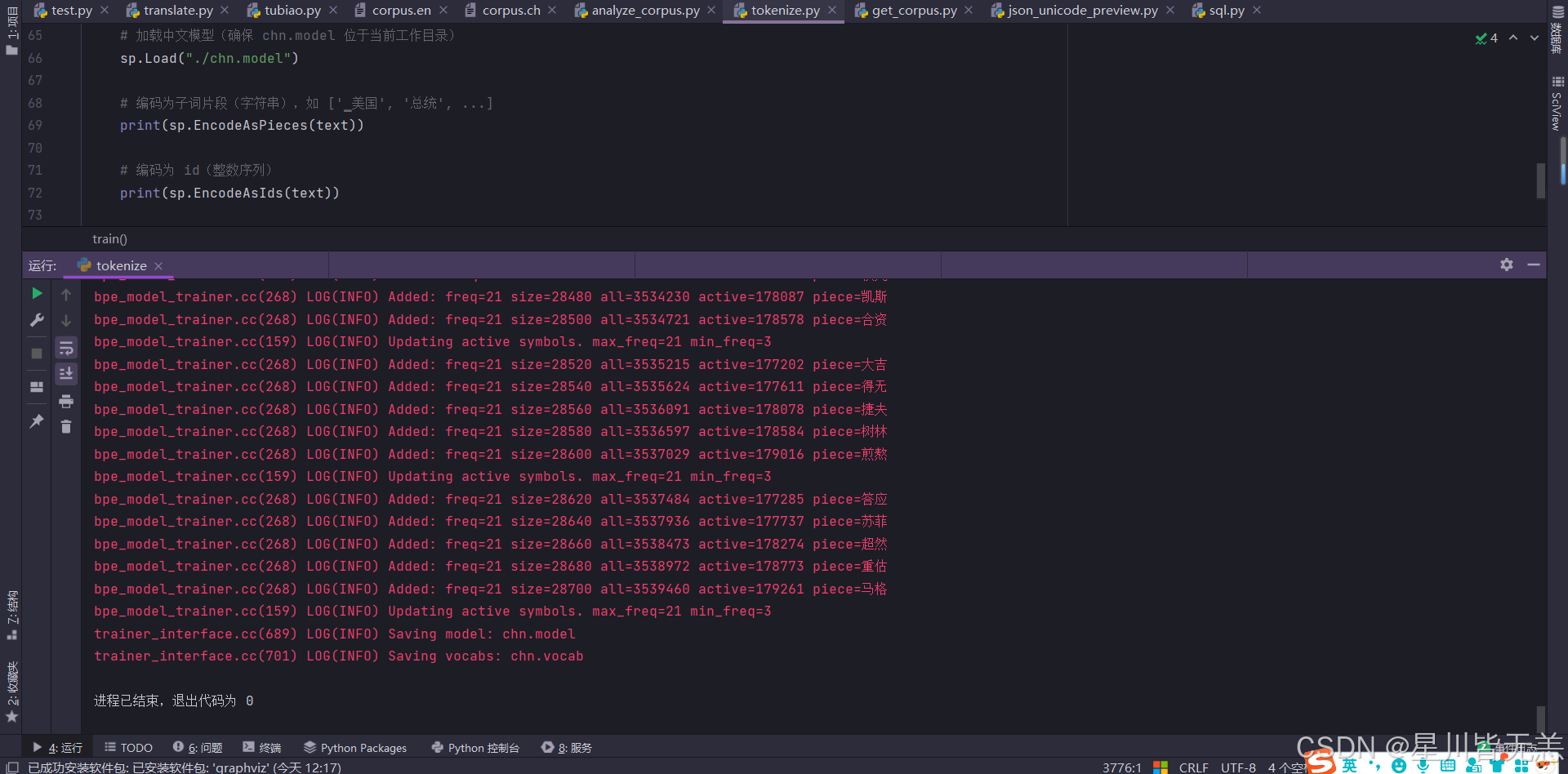

BPE算法训练完成后,会自动在当前工作目录下,生成两个文件:
<model_name>.model:"分词器的大脑",包含了完整的 BPE 合并树结构和反向解码规则的高效二进制文件。<model_name>.vocab:这是一个方便人类查看的纯文本文件,里面按顺序列出了所有 32000 个子词以及它们的初始概率得分。
2. 构建数据加载器与 Mask 生成
在 data_loader.py 中,我们需要处理好源语言(Source)和目标语言(Target)的 Padding Mask 以及极其重要的 Subsequent Mask(因果掩码)。
Python
# data_loader.py 核心逻辑
def subsequent_mask(size):
"""生成遮蔽矩阵,防止解码时看到未来的词"""
attn_shape = (1, size, size)
# 创建上三角矩阵,右上角为1,左下角为0
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0
class Batch:
def __init__(self, src_text, trg_text, src, trg=None, pad=0):
# 源语言 Mask(屏蔽 Padding)
self.src_mask = (src != pad).unsqueeze(-2)
if trg is not None:
# 去掉最后一个词作为输入,从第二个词开始作为预测目标
self.trg = trg[:, :-1]
self.trg_y = trg[:, 1:]
# 目标语言 Mask = Padding Mask & Causal Mask
self.trg_mask = self.make_std_mask(self.trg, pad)3. PyTorch 完美复刻 Transformer 模型
python
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
# 初始化方法,传入模型的维度(d_model)和词汇表的大小(vocab)
super(Embeddings, self).__init__()
# Embedding层,将词汇表的大小映射为d_model维的向量
self.lut = nn.Embedding(vocab, d_model)
# 存储模型的维度 d_model
self.d_model = d_model
def forward(self, x):
# 返回x对应的embedding矩阵(需要乘以math.sqrt(d_model))
# 这是为了保持词向量的方差,使其适应后续层的训练。
return self.lut(x) * math.sqrt(self.d_model)对应词嵌入层,通常与"位置编码"并列 为输入端的一部分
位置编码层:
attention 函数实现注意力计算的核心部分。计算 query 和 key 之间的点积, 并根据该相似度对 value 进行加权求和
python
def attention(query, key, value, mask=None, dropout=None):
# 将query矩阵的最后一个维度值作为d_k
d_k = query.size(-1)
# 将key的最后两个维度互换(转置),才能与query矩阵相乘,乘完了还要除以d_k开根号
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
"""
Encoder:主要使用padding mask处理不等长序列
Decoder:同时使用padding mask和sequence mask
padding mask处理填充部分
sequence mask防止看到未来信息
"""
# 如果存在要进行mask的内容,则将那些为0的部分替换成一个很大的负数
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 将mask后的attention矩阵按照最后一个维度进行softmax
p_attn = F.softmax(scores, dim=-1)
# 如果dropout参数设置为非空,则进行dropout操作
if dropout is not None:
p_attn = dropout(p_attn)
# 最后返回注意力矩阵跟value的乘积,以及注意力矩阵
return torch.matmul(p_attn, value), p_attn在 tf_model.py 中,展示最核心的 MultiHeadedAttention 和 EncoderLayer。
Python
# tf_model.py: 多头注意力实现
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
self.d_k = d_model // h # 计算单头维度 (e.g., 512 / 8 = 64)
self.h = h
# 4个线性层分别用于生成 Q, K, V 以及最后的输出融合 W_O
self.linears = clones(nn.Linear(d_model, d_model), 4)
def forward(self, query, key, value, mask=None):
nbatches = query.size(0)
# 1. 线性映射并切分成 h 个头
query, key, value = [l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2. 调用 attention 计算分数
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
# 3. 将多头拼接起来 (Concat)
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
# 4. 最后做一次线性变换恢复维度
return self.linears[-1](x)层归一化:
python
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
# 初始化α为全1, 而β为全0
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
# 平滑项
self.eps = eps
def forward(self, x):
# 这是一个前向传播函数,用于执行Layer Normalization操作
# 输入x是神经网络层的输出
# 按最后一个维度计算均值和方差
# keepdim=True确保输出的维度与输入相同
mean = x.mean(-1, keepdim=True) # 计算最后一个维度的均值
std = x.std(-1, keepdim=True) # 计算最后一个维度的标准差
# 返回Layer Norm的结果
# Layer Norm公式: y = a * (x - mean) / sqrt(std^2 + eps) + b
# 其中a和b是可学习的参数,eps是为了防止除以0的小常数
return self.a_2 * (x - mean) / torch.sqrt(std ** 2 + self.eps) + self.b_2代码里面的 a_2 和 b_2 是干什么用的?
如果不加 a_2 和 b_2,数据就被强行变成均值为 0、方差为 1 的标准正态分布了。这虽然好训练,但会破坏网络前面好不容易提取到的特征表达。
因此,我们引入了 a_2和 b_2。这两个变量被包在了 nn.Parameter 里,意味着它们是可学习的参数。模型会在反向传播时,自己学会如何把归一化后的数据"缩放"和"平移"到一个最合适的分布上。
注意编码器层是如何通过残差模块将注意力机制与 FFN 串联起来的:
Python
class EncoderLayer(nn.Module):
def forward(self, x, mask):
# Sublayer[0] 内部集成了 LayerNorm -> Attention -> Add
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
# Sublayer[1] 内部集成了 LayerNorm -> FFN -> Add
return self.sublayer[1](x, self.feed_forward)Transformer模型中前馈神经网络的实现
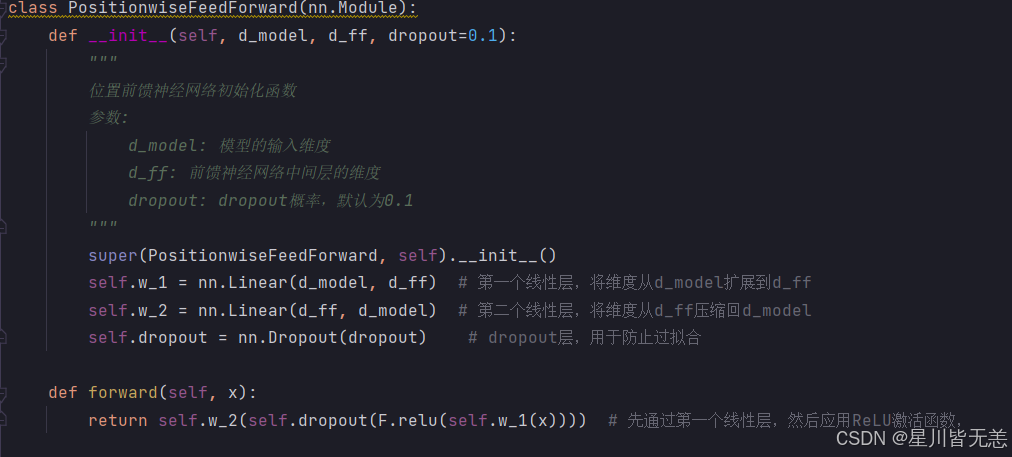
Transformer 模型中的前馈神经网络。它包含 两个线性层和一个 ReLU 激活函数,通过 dropout 防止过拟合
在深度学习里,我们经常说的线性层和全连接层是一个概念。线性层=全连接层
整个运算为纯线性运算没有拐弯,因此为线性层。如果后面加了ReLu/Sigmod激活函数,那么整体就不在是纯线性。
线性层也叫全连接层,前一层的每一个神经元都和后一层的每一个神经元全部连上线,没有漏掉任何一根线。
线性角度:每一根线都有权重,w_1,w_2,w_3,w_4 ...
输出=输入x权重+偏置
SublayerConnection 是 Transformer 模型中的一个关键组件,它负责将各个 子层(如多头注意力层、前馈神经网络层)与残差连接和层归一化相结合
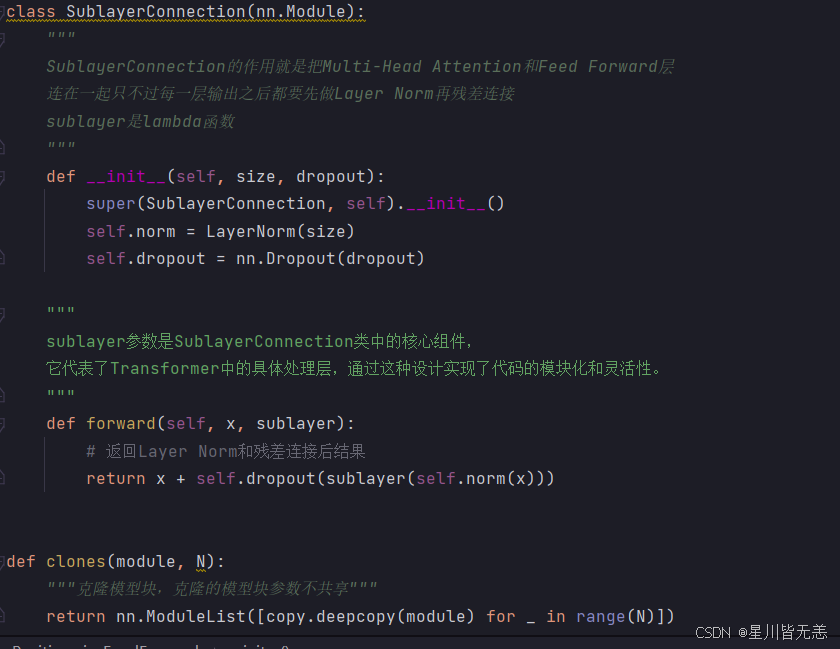
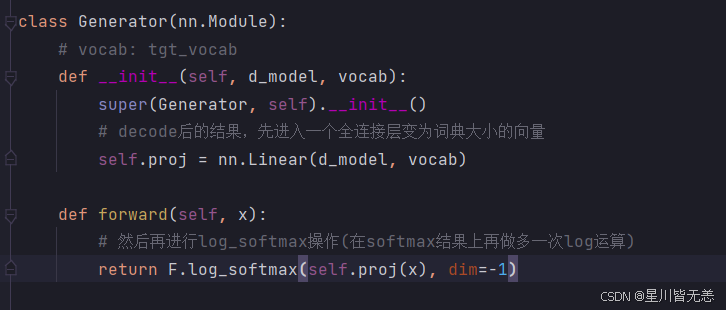
Generator 是 Transformer 模型中的生成器部分,主要负责将解码器的输 出转换为 目标词汇表的概率分布
4. 优化器策略与多 GPU 训练
python
def test(data, model, criterion):
with torch.no_grad():
# 加载模型
model.load_state_dict(torch.load(config.model_path))
model_par = torch.nn.DataParallel(model)
model.eval()
# 开始预测
test_loss = run_epoch(data, model_par,
MultiGPULossCompute(model.generator, criterion, config.device_id, None))
bleu_score = evaluate(data, model, 'test')
logging.info('Test loss: {}, Bleu Score: {}'.format(test_loss, bleu_score))
def run():
# 创建训练数据集和开发数据集
# 使用MTDataset类分别加载训练数据和开发数据
train_dataset = MTDataset(config.train_data_path) # 初始化训练数据集,使用配置中指定的训练数据路径
dev_dataset = MTDataset(config.dev_data_path) # 初始化开发数据集,使用配置中指定的开发数据路径
test_dataset = MTDataset(config.test_data_path)
# 创建训练数据加载器,用于训练过程中批量加载数据
# shuffle=True 表示在每个epoch开始时会打乱数据顺序,以增加模型的泛化能力
# batch_size=config.batch_size 表示每个批次的样本数量,具体值由配置文件决定
# collate_fn=train_dataset.collate_fn 表示自定义的数据整理函数,用于处理每个批次的数据
train_dataloader = DataLoader(train_dataset, shuffle=True, batch_size=config.batch_size,
collate_fn=train_dataset.collate_fn)
dev_dataloader = DataLoader(dev_dataset, shuffle=False, batch_size=config.batch_size,
collate_fn=dev_dataset.collate_fn)
test_dataloader = DataLoader(test_dataset, shuffle=False, batch_size=config.batch_size,
collate_fn=test_dataset.collate_fn)
# 初始化模型
model = make_model(config.src_vocab_size, config.tgt_vocab_size, config.n_layers,
config.d_model, config.d_ff, config.n_heads, config.dropout)
# 将模型包装成数据并行模式,这样可以在多个GPU上并行处理数据,提高训练效率
model_par = torch.nn.DataParallel(model)
# 训练阶段,选择损失函数和优化器
# CrossEntropyLoss是常见的分类问题损失函数,ignore_index=0表示忽略填充部分
# reduction='sum'表示计算损失时会对所有token的损失求和
criterion = torch.nn.CrossEntropyLoss(ignore_index=0, reduction='sum')
# 调用get_std_opt函数获取标准的Noam优化器,这通常包括学习率调度器(如预热后衰减)
optimizer = get_std_opt(model)
# 开始训练
train(train_dataloader, dev_dataloader, model, model_par, criterion, optimizer)
# test(test_dataloader, model, criterion)
显卡比较低的话,可以用这一套参数
python
# # d_model 从 512 改为 256
# d_model = 256
# # 多头注意力机制中的头数。从 8 改为 4 (保持 d_model / n_heads = 64)
# n_heads = 4
# # n_layers 从 6 改为 3 论文中的n 复合层一般为6
# n_layers = 3
# # 自注意力机制中每个头的键(Key)向量的维度。保持 64
# d_k = 64
# # 自注意力机制中每个头的值(Value)向量的维度。保持 64
# d_v = 64
# # d_ff 是前馈网络隐藏层的大小。从 2048 改为 1024
# d_ff = 1024
# # dropout = 0.1 表示在训练过程中,随机丢弃10%的神经元来避免模型过拟合。
# dropout = 0.1训练一轮都很慢...显卡越低训练时间越久...
50xx系列的一轮都要1h起步,低级显卡只能调整批次,降低维度,调整多头注意力机制中的头数和降低隐藏层层数,不然性能跑不起来...
训练轮次:模型在大概 25-30 轮左右大约收敛,BLEU分数趋于稳定.
轮次可以自己设定:
python
epoch_num = 3
每次运行都会自动生成独立的 exp 文件夹(如 exp1, exp2...),并将该次实验产生的高分权重保存在对应的 weights/ 下
深度 Transformer 非常娇贵,不能使用固定的学习率。需要采用 Warmup 策略(预热步数):前期学习率呈线性增长,之后再随着步数平方根的倒数缓慢衰减。
Python
# train_utils.py 自定义 NoamOpt
class NoamOpt:
def rate(self, step=None):
if step is None:
step = self._step
# 论文原版公式
return self.factor * (self.model_size ** (-0.5) * min(step ** (-0.5), step * self.warmup ** (-1.5)))训练好的模型文件:

5. 高级推理:Beam Search(集束搜索)
模型搭建完毕并跑通训练后,我们如何客观评价它翻译得好不好呢?这就必须请出机器翻译界最经典、最常用的自动评估指标------BLEU (Bilingual Evaluation Understudy)。
BLEU 的核心思想非常直观:它通过统计机器翻译输出与人工参考翻译之间的 N-gram(N元语法)重合度来打分。重合度越高,说明机器翻译越接近人类水平。
BLEU 的评分范围严格限制在 0 到 100 之间,业界通常有如下的共识分段:
- 0 - 20:较差的翻译。翻译结果几乎与参考翻译完全不匹配,可以说是不知所云。
- 20 - 40:一般的翻译。尽管能够让人理解大概含义,但翻译中通常包含明显的语法或词汇错误。
- 40 - 60:中等质量的翻译。翻译与参考翻译有一定程度的一致性,日常交流基本够用。
- 60 - 80:高质量翻译。通常能够准确、流畅地表达参考翻译的绝大部分内容。
- 80 - 100:极好的翻译。翻译几乎与参考翻译完全一致,语言极致流畅且毫无语法错误(实际上,即使是两个人类专家翻译同一句话,也很难达到 100 分)。
模型训练完毕后,如果我们只贪心寻找每一步概率最高的词(Greedy Search),很容易陷入局部最优。实战项目中我实现了 Beam Search(集束搜索),它在每一步都会保留 beam_size 个得分最高的候选路径,大大提高了翻译质量。
模型推理translate.py脚本
python
def translate(src, model):
"""用训练好的模型进行预测单句,打印模型翻译结果"""
# 加载中文分词器
sp_chn = chinese_tokenizer_load()
with torch.no_grad(): # 禁用梯度计算,以节省内存
# 加载训练好的模型权重
model.load_state_dict(torch.load(config.test_model_path))
model.eval() # 将模型设置为评估模式
# 创建源句子的掩码(mask),以确保填充的部分不会参与计算
src_mask = (src != 0).unsqueeze(-2)
# 使用束搜索(beam search)进行解码
decode_result, _ = beam_search(
model,
src,
src_mask,
config.max_len, # 最大翻译长度
config.padding_idx, # 填充符号的索引
config.bos_idx, # 句子开始符号的索引
config.eos_idx, # 句子结束符号的索引
config.beam_size, # 束搜索的大小
config.device # 设备(CPU或GPU)
)
# 从解码结果中提取最优结果
decode_result = [h[0] for h in decode_result]
# 使用中文分词器将解码结果的id转化为实际的中文词语
translation = [sp_chn.decode_ids(_s) for _s in decode_result]
# # 打印并返回翻译结果的第一句
# print(translation[0])
return translation[0]
def one_sentence_translate(sent):
"""翻译单句英文"""
# 初始化翻译模型,使用指定的参数(词汇表大小、层数、模型维度等)
model = make_model(
config.src_vocab_size, # 源语言词汇表大小
config.tgt_vocab_size, # 目标语言词汇表大小
config.n_layers, # 模型的层数
config.d_model, # 模型的维度(通常是隐藏层的大小)
config.d_ff, # 前馈网络的维度
config.n_heads, # 注意力头的数量
config.dropout # dropout比率
)
# 加载源语言和目标语言的分词器,用于获取BOS和EOS标记
BOS = english_tokenizer_load().bos_id() # 获取开始符号(BOS)的ID,通常是2
EOS = english_tokenizer_load().eos_id() # 获取结束符号(EOS)的ID,通常是3
# 将输入的句子转化为token IDs,添加BOS和EOS标记
src_tokens = [[BOS] + english_tokenizer_load().EncodeAsIds(sent) + [EOS]]
# 将句子转换为长整型Tensor,并发送到指定的设备(如GPU或CPU)
batch_input = torch.LongTensor(np.array(src_tokens)).to(config.device)
# 调用translate函数进行翻译
return translate(batch_input, model)
def translate_example():
"""单句翻译示例"""
"The government has implemented various policies toimprove the living standards of its citizens."
"政府实施了诸多政策,改善公民的生活水平。"
while True: # 使用循环,让用户可以反复输入句子
# 提示用户输入英文句子
sent = input("请输入英文句子进行翻译:")
translation = one_sentence_translate(sent)
# 调用翻译函数进行翻译
print("翻译结果:", translation)
if __name__ == "__main__":
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
import warnings
warnings.filterwarnings('ignore')
translate_example()先拿知识库中的数据进行测试:


虽然翻译的不是特别专业,毕竟咱们的模型训练BLEU也就26多,介于一般效果之中,如果有更好的训练条件和更大规模的数据,效果会更好!
后续调优策略可以参考:
| 调优维度 | 作用阶段 | 具体策略 | 核心原理与作用 |
|---|---|---|---|
| 解码策略 | 推理阶段 (Inference) | 适度增大 Beam Size | 扩大每一步的候选搜索空间,提升翻译质量。过大(>10)反而会导致句子偏短保守。 |
| 解码策略 | 推理阶段 (Inference) | 引入长度惩罚 (Length Penalty) | 纯概率对数相加会导致模型严重偏爱短句。引入 α = 0.6 \alpha=0.6 α=0.6 的惩罚项可以补偿长句得分,显著提升 BLEU。 |
| 显存优化 | 训练阶段 (Training) | 梯度累加 (Gradient Accumulation) | 在极小物理 Batch Size(如 4)下模拟大 Batch Size(如 32),极大地稳定梯度更新,防止震荡不收敛。 |
| 训练周期 | 训练阶段 (Training) | 拉长 Epoch 轮次 | 复杂的深层注意力网络需要充分的数据迭代。解决梯度震荡后,3 轮热身远远不够,必须让模型充分收敛。 |
| 损失函数 | 训练阶段 (Training) | 标签平滑 (Label Smoothing) | 缓解模型在预测时过于绝对化(Overconfident),提升模型的泛化能力和最终测试集 BLEU 分数。 |
| 学习率 | 训练阶段 (Training) | 动态微调 Warmup 步数 | Transformer 不能用固定学习率。配合实际有效的 Batch Size,调整预热步数,使学习率平稳度过危险期。 |