一.题目解析


算法讲解:
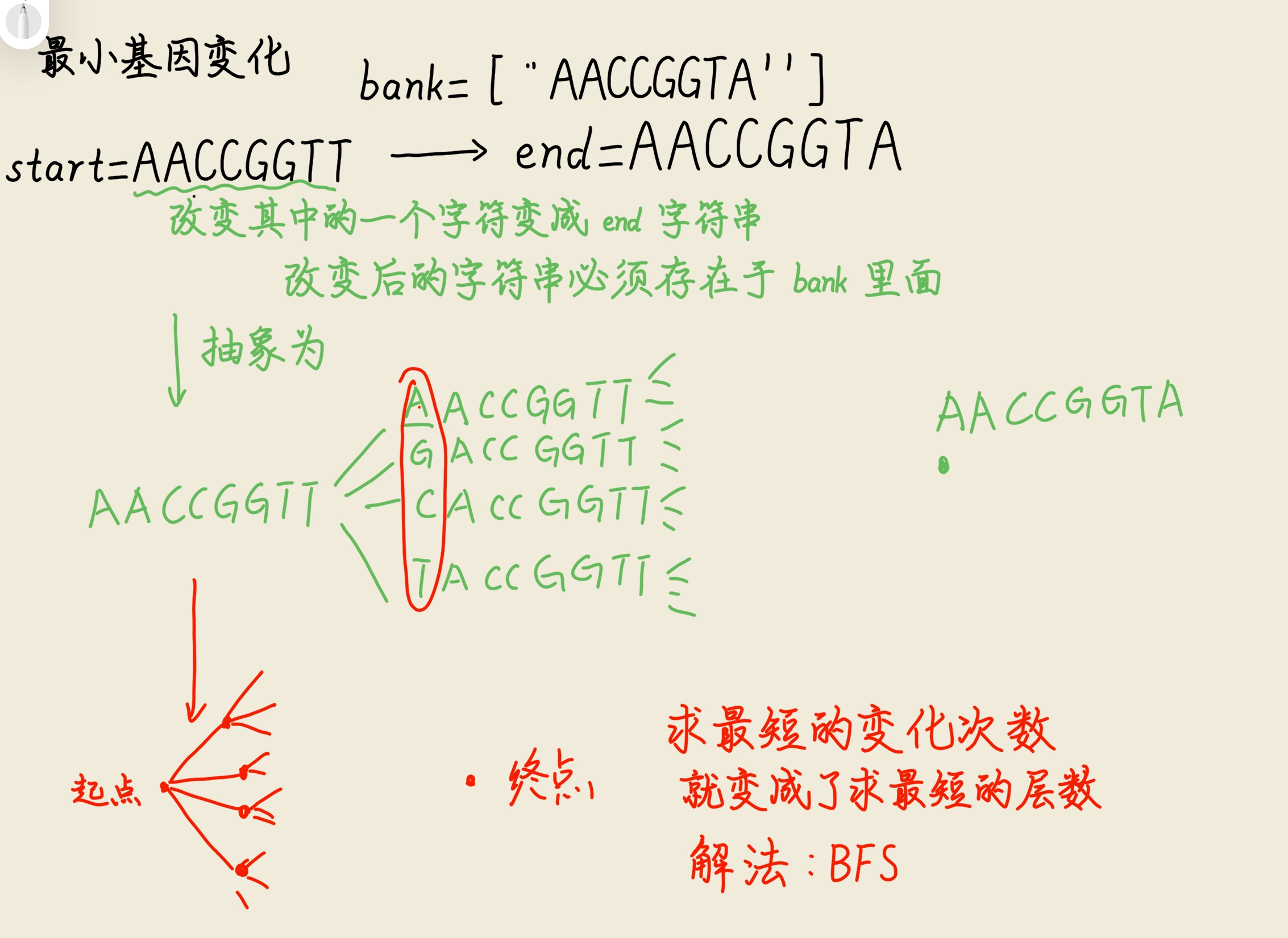
1.改变一个字符之后,需要在bank里面看一下存不存在,所以我们可以将bank数组导入到一个hash表里面快速判断存不存在.
2.遍历全部情况:一个指针遍历start的8个字母,再创建一个string change="AGCT"指针遍历一个位置四种情况.
3.枚举出来的字符串只有bank里面的才需要加入队列
4.使用hash表来表示该字符串已经遍历
5.BFS基础:队列 queue<string>q实现宽搜
判断该位置是否遍历(这里使用hash表
6.结合代码和抽象图再一次理解
二.代码编写:
以下代码有一个BUG
cpp
class Solution {
public:
int minMutation(string startGene, string endGene, vector<string>& bank) {
unordered_set<string>vis;//判断是否遍历
unordered_set<string>hash(bank.begin(),bank.end());//bankhash快速判断是否存在
string change="AGCT";
if(startGene==endGene)return 0;//边界情况
if(!hash.count(endGene))return -1;
queue<string>q;//队列实现宽搜
q.push(startGene);
vis.insert(startGene);
int ret=0;
while(q.size())
{
ret++;
int sz=q.size();
while(sz--)
{
string s=q.front();
q.pop();
for(int i=0;i<8;i++)//一字符串的8个位置
{
for(int j=0;j<4;j++)
{
s[i]=change[j];//已经将原来的字符串改坏了,所以我们使用tmp修改
if(hash.count(s)&&!vis.count(s))
{
if(s==endGene)return ret;
else q.push(s),vis.insert(s);
}
}
}
}
}
return -1;
}
};
正确代码编写:
cpp
class Solution {
public:
int minMutation(string startGene, string endGene, vector<string>& bank) {
unordered_set<string>vis;//判断是否遍历
unordered_set<string>hash(bank.begin(),bank.end());//bankhash快速判断是否存在
string change="AGCT";
if(startGene==endGene)return 0;//边界情况
if(!hash.count(endGene))return -1;
queue<string>q;//队列实现宽搜
q.push(startGene);
vis.insert(startGene);//哈希表标记已经搜索过的状态
int ret=0;
while(q.size())//BFS
{
ret++;
int sz=q.size();
while(sz--)
{
string s=q.front();
q.pop();
for(int i=0;i<8;i++)//一字符串的8个位置
{
string tmp=s;//防止原字符串被污染
for(int j=0;j<4;j++)
{
tmp[i]=change[j];//已经将原来的字符串改坏了,所以我们使用tmp修改
if(hash.count(tmp)&&!vis.count(tmp))//在bank里面存在,并且没有遍历过
{
if(tmp==endGene)return ret;//相等就返回步数
else q.push(tmp),vis.insert(tmp);//BFS不相等就继续入队改变
}
}
}
}
}
return -1;
}
};