一、 进程优先级
1、基本概念
CPU对资源分配的先后顺序、其指的就是进程的优先权
优先级高的进程那么就有优先执行的权利。配置进程优先级对于我们的多任务环境的Linux是很有必要的,其可以改进我们操作系统的性能。
而且其还可以将进程运行到指定的CPU上,那么这样一来,就可以将一些不重要的进程安排到某个CPU上,这样就又可以大大的提高系统的整体的性能。
那么其和我们前面提到的权限有何不同呢?
优先级VS权限
**权限:**决定的是能不能做这个事情
**优先级:**决定的是何时能做,其可以做,但是就是先后的问题,此时进程已经可以得到某种资源 的前提下、得到某种资源的先后顺序
设置优先级的好处:
可以提高我们对于资源的分配效率,使得资源的分配更加公平合理。
2、查看系统进程
在Linux和unix系统中,使用ps -l命令就会输出如下信息:

有几个信息我们前面已经很熟悉了:
UID:表示执行这个进程的执行者的信息
PID:这个进程的编号
PPID:表示这个进程的父进程、即这个进程是由那个进程衍生发展而来的
PRI:表示这个进程的优先级、其值越小表示其优先级越高
NI:表示这个进程的nice值
上面的PRI和NI就是我们进程优先级的信息了,然后PRI我们已经知道了是优先级的等级,那么NI是啥呢?
NI,其实就是优先级的修正数值,调整进程的优先级,在Linux下就是对nice值进行修改。
那么我们如何对nice值进行修改呢?
使用top命令可以进行更改。
过程如下:
top后按r然后输入要修改的进程的PID,然后输入nice值。
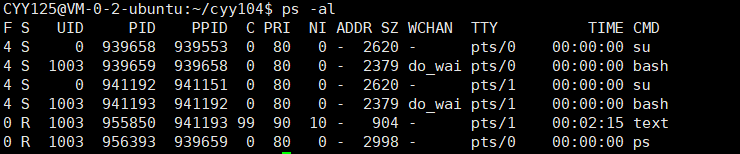
可以看到我上面就将text这个进程的nice值修改成了10,然后其PRI就变成了90。
所以加入了nice值后,就会使得PRI变成:
PRI(new)=PRI(old)+nice
那么当我们的nice值为负值的时候,那么我们进程优先级就会变小,即优先级变高。
但是我们也不能说去无限大的调整进程的优先级,nice也是有一个范围值的。
nice的范围值-20,19。
然后PIR其基准值是80,那么我们的进程优先级的范围就为60,99。一共四十个级别
注意:
1、
PRI(new)=PRI(old)+ nice
其中PRI(old)为80,并不是前一次的PRI
2、对于优先级的更改不能改变的太频繁和太狠
原因:
我们的操作系统大部分是分时操作系统。
分时操作系统:
给进程分配时间片,相对公平公正的调度策略,较为均衡的让不同的进程都可以在一段时间内,都能得到CPU的资源
补充:
竞争性:系统进程数目众多、但是CPU的资源只有少量,甚至只有一个、所以进程之间是具有竞 争属性的。为了高效完成任务,更加合理竞争相关的资源,就有了优先级。
独立性:多进程运行、其需要独享各种资源、各个进程之间互不干扰
并行:多个进程在多个CPU下分别、同时的运行
并发:多个进程在一个CPU下采用切换的方式、在一段时间之内、让多个进程可以推进
二、进程切换
CPU上下文切换:其实际含义就是任务切换、或者CPU寄存器切换。当多任务内核决定运行另外的任务时候、它保存正在运行任务的当前状态、也就是CPU寄存器中的全部内容。这些内容会被报保存在任务自己的堆栈中、入栈工作完成后就会把下一个将要运行的任务的当前状况从该任务的栈中重新装入CPU寄存器、并开始下一个任务的运行、这一个过程就是上下文切换(context switch)。
简单来说就是:
寄存器是共享的,但是寄存器中的数据,本质是进程私有的。
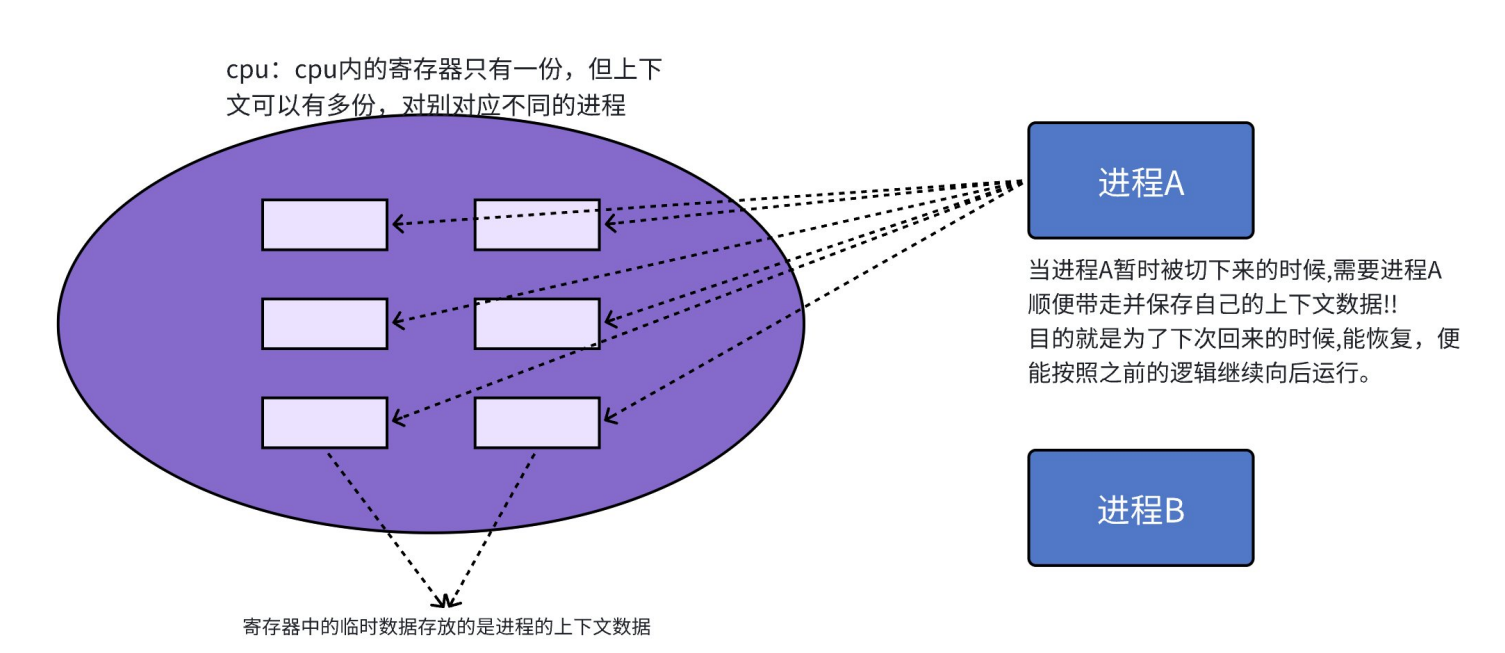
实际上、操作系统是使用的链表的结构对其进行管理的、其链表结构如下:
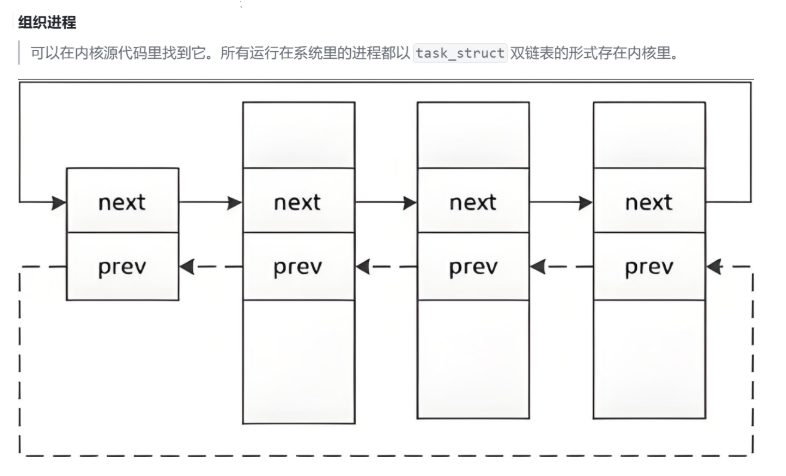
上面就是我们对于进程组织的双向链表。
Linux内核中,会将所有的进程task_struct,统一放在一张双链表中。
但是前面我们提到我们的进程还有其运行队列阻塞队列等,那么是否是可以链表存储呢/
确实是这样,我们的这些数据也可以是结构体的对象。
然后我们的CPU都有一个调度队列:
struct runqueue{};
如下所示:
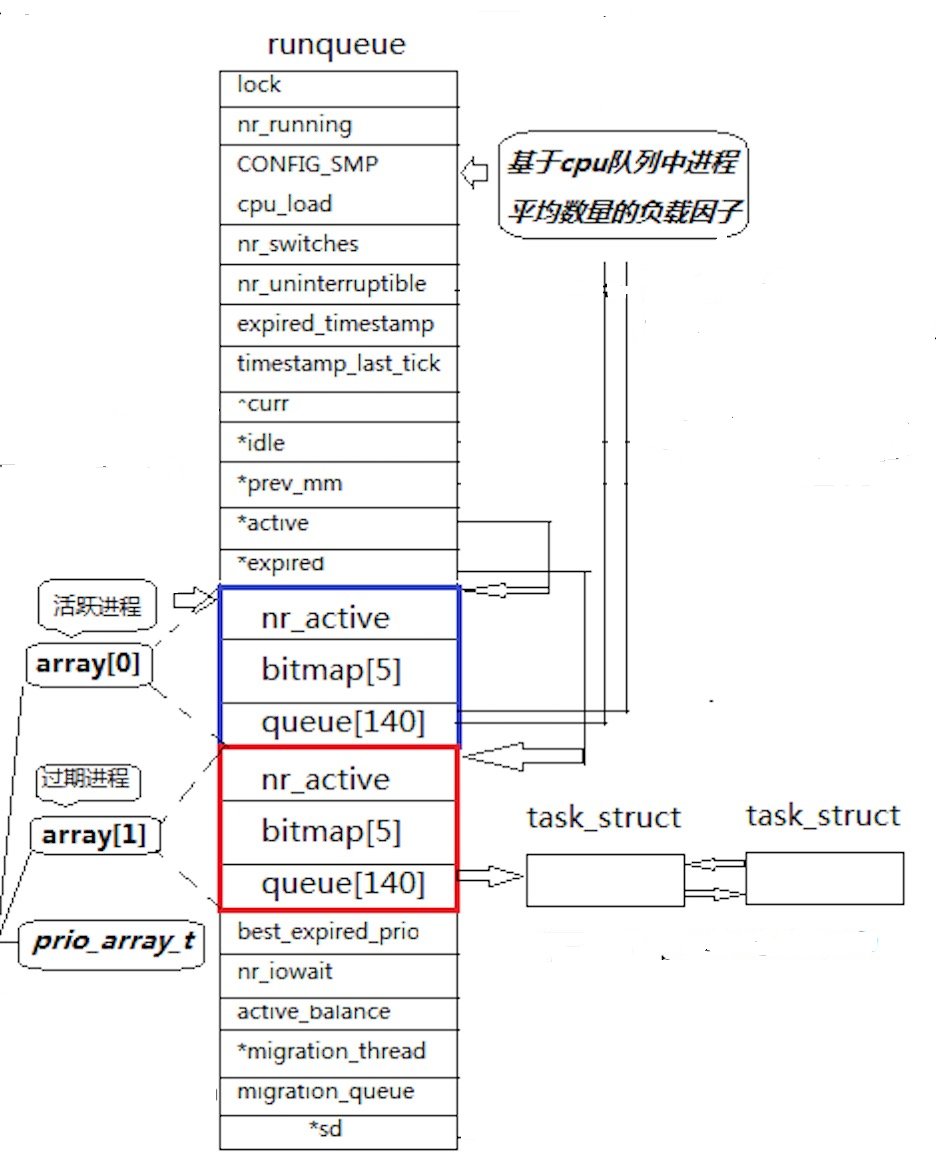
我们就关注蓝色和红色部分,首先,有一个数组,int arr2;其存放的是array0和array1如上图。
然后*active=array0;
*axpired=array1;
然后这两个数组中有分别有三种数据
nr_active:表示runqueue中是否有进程,其记录的是进程的总个数。
queue140:这个就是存放我们的进程的结构体地址的队列,其是按照进程的优先级进行存放的,首先我们看到这个queue的大小是140,0~99这个区间的我们不关心,我们关心的是100~139这个区间的,那么可以看到其大小刚刚好是我们nice的范围。那么我们对于进程的结构体地址的存放就是会将其nice+100,那么就是其存放的下标了。
然后bitmap5;这个也是一个进程队列,但是其功能是帮助我们可以更高效率的查找到对应进程存储的位置。其实际上使用的原理是位图。
就比如我们是一共140个位置,那么我们设置32个比特位为一组,那么我们设置5组就可以表示完我们的140个位置的了,然后我们每次就使用8个位次进行计算,我们每次都使用11111111,和其进行位运算,然后就可以加快我们判断那边有进程了。
那么我们的操作系统是否就直接按照进程的优先级来决定进程的执行先后呢?
那么我们发现还有一个问题:
就是比如我们当前执行的程序的优先级是61的,然后中途就源源不断的插入了优先级为60的进程,那么我们的操作系统是否就会马上不干了,跑去执行进程优先级为60的进程?
那么这样的话,我们进程优先级为61的进程就会一直得不到CPU的运行,这种叫做饥饿进程。
那么这和我们分时操作系统的要求就违背了。
我们发现,我们上面的话,有两个queue,首先,就是活跃进程array0,我们CPU就是从这个里面寻找进程进行运行,那么我们后面来的进程,就会先被存入到那个过期进程中,然后我们有一些运行的进程,其时间片过期了,那么我们也会将其记录到这个过期进程中,然后当这个活跃进程的queue被执行完毕,然后就会将这两个queue进行交换。