摘要 :本文说明 Qwen3.5 开放权重系列的文本骨干 (公开权重多为 图文统一 的 ForConditionalGeneration,含 Vision Encoder ;数学与实现细节以 text_config 为主)。相对 Qwen3 及更早代际,Qwen3.5 的硬变化是 高效混合架构 :在堆叠的 Decoder 层中 交替使用「线性注意力类子层(配置名 linear_attention)」与「标准因果全注意力子层(full_attention)」 ,典型节奏为 每 4 层中 3 层线性、1 层全注意力 (full_attention_interval: 4),并与 稀疏 MoE(多规格) 、更大上下文标称(如 262K) 、RoPE 变体(含多模态 mRoPE 相关字段) 等结合。文中直接写出 各模块在数据流中的含义与公式级直觉,并与 Qwen 1、Qwen 2、Qwen 3 对照。
关键词:Qwen3.5;混合注意力;Gated DeltaNet;线性注意力;全注意力;MoE;mRoPE;Decoder-only;大语言模型
同系列博文(延伸阅读):
💡 理解要点 :可以把 Qwen3.5 想成:在 自回归 Decoder 大框架不变的前提下,不再让每一层都做「标准的 O ( L 2 ) O(L^2) O(L2) softmax 全注意力」 ;而是 大部分层 用 随序列长度近线性扩展 的 线性注意力 / 状态压缩类 机制(实现与论文脉络上接近 Gated DeltaNet 路线),每隔若干层插入一层全注意力 ------保留 任意位置两两精细对齐 的能力。再叠上 MoE(多规格) 、更大词表与更长上下文 ,以及 原生多模态 (图像经 Vision Encoder 与文本 早期融合 )。这与 Qwen3「每层都是 GQA 全注意力 + 可选 MoE FFN 」的配方 有明显结构差异。
1. 概述:文献来源、发布形态与系列定位
1.1 有没有「Qwen3.5 论文」?
截至本文写作时,Qwen 团队在 GitHub 仓库 中提供的引用条目为 技术报告式 bibtex ,标题为 Qwen3.5: Towards Native Multimodal Agents ,链接指向官方博客 (https://qwen.ai/blog?id=qwen3.5),并非 与 Qwen3 类似的 独立 arXiv PDF 长文。这里的「架构解析」主要是从下面的数据源中得到:
- 官方博客(能力、训练取向、多模态与 Agent 叙事);
- GitHub README(「Efficient Hybrid Architecture: Gated Delta Networks + sparse MoE」等一句话架构摘要);
- Hugging Face
config.json(layer_types、full_attention_interval、头数与 MoE 超参等)。
🔍 说明 :凡涉及 层数、头数、专家数、上下文长度 ,以 我们下载的权重自带的
config.json为准;不同尺寸(如 397B-A17B、122B-A10B、35B-A3B、27B 以及 9B / 4B / 2B / 0.8B 等)互不相同。
1.2 官方强调的若干「产品级」能力(与架构相关)
根据 Qwen3.5 README 与 Qwen3.5 官方博客 的表述,可概括为:
- 统一图文基础模型 :多模态 token 与文本 早期融合 训练,推理侧常见为 单栈 ConditionalGeneration(图像 → Vision Encoder → 与文本隐层对齐)。
- 高效混合架构 :Gated Delta Networks 与 稀疏 MoE 组合,面向 高吞吐、低延迟 推理。
- 规模化强化学习 、语种覆盖扩大 (201 种语言与方言)、训练基础设施 升级等------这些 不改变 我们读
config.json时对「每一层类型」的判断,但解释 为何同样激活参数量下行为更强 时需要考虑 数据与后训练。
1.3 与 Qwen 1 / Qwen 2 / Qwen 3 的一览对照
| 维度 | Qwen 1 | Qwen 2 | Qwen 3 | Qwen3.5(文本骨干,概括) |
|---|---|---|---|---|
| 注意力主形态 | 以 MHA 为报告基线 | 稠密 GQA 全注意力 | 稠密 GQA 全注意力 + QK-Norm,无 QKV bias | 混合 :多数层 linear_attention + 周期性 full_attention (全注意力层仍为 GQA 式少 KV 头配置) |
| FFN | SwiGLU;中间维 8 3 d \frac{8}{3}d 38d 叙述 | SwiGLU;表驱动中间维 | 同左 | SwiGLU;MoE 型号极稀疏 + 部分配置含 shared expert 字段 |
| 位置编码 | RoPE | RoPE + 长文 YARN/DCA 等 | RoPE + ABF/YARN/DCA 等 | RoPE 参数升级 (如 rope_theta 更大 、partial_rotary_factor、mRoPE 相关字段 服务多模态) |
| 上下文 | 较短 + 推理技巧 / 1.5 代 32K 等 | 32K 训练 + 外推至约 128K 级 | 32K 长阶段 + 外推叙事 | 公开配置常见 max_position_embeddings: 262144(262K) ;API/托管形态另有 更长窗口 的产品叙述(第三方总结如 Digital Applied 对 Flash 1M context 的介绍,以官方当前说明为准) |
| 多模态 | 非本篇核心 | Qwen2-VL 另线 | Qwen3-VL 另线 | 原生统一权重 常见(vision_config + text_config) |
2. 整体架构总览
下面一图从 输入 → 融合 → N 层 Decoder → 输出 串起 Qwen3.5 公开权重 里最常见的形态:图文统一 checkpoint(vision_config + text_config)、主干为 Decoder-only ;MoE 是否出现、专家数、是否 shared expert 等 因型号而异 ,以对应 config.json 为准。注意力与混合层级的直觉见 §2.1--§2.4 ;子层 2(FFN) 的 稠密 SwiGLU / MoE 路由与共享专家 的公式与 Mermaid 细图 在 §8 (总览图中 FF → §8 虚线对应)。
输入侧(多模态统一权重)
单层骨架(重复 N 层;注意力子层类型由 layer_types 指定)
Pre-Norm:RMSNorm
子层 1:linear_attention(Gated DeltaNet 路线)或 full_attention(因果 GQA + RoPE + softmax,无 attention_bias)
残差
Pre-Norm:RMSNorm
子层 2:SwiGLU 稠密 FFN 或 稀疏 MoE(部分型号含 shared expert)
残差
FFN 详图:§8.1 稠密 SwiGLU · §8.2 MoE(门控 / top-k / 共享专家)
典型深度节奏(公开权重常见 full_attention_interval: 4)
linear_attention
linear_attention
linear_attention
full_attention
...
图像(可选;纯文本推理可走空或闲置支路)
Vision Encoder(CNN / ViT 类,vision_config)
视觉 token 隐状态
文本字符串
Tokenizer(BBPE 等)
Token Embedding(text_config)
早期融合:图文对齐为一条序列表示(L×d)
Decoder-only 主干:堆叠 N 层
无 Encoder--Decoder 交叉注意力
LM Head → 词表维度 logits
tie_word_embeddings 以 config 为准
自回归下一 token / 多模态条件生成后续
读权重时请核对:layer_types、full_attention_interval、RoPE / mRoPE 相关字段、MoE 超参、max_position_embeddings 等
可沿主链阅读:图像 → Vision Encoder → 视觉 token;文本 → Tokenizer → Embedding;两路 早期融合 → N 层 Decoder(每层先 linear 或 full 注意力 ,再 FFN/MoE ,均带 Pre-Norm 与残差 )→ LM Head → logits。典型 3 层 linear + 1 层 full 循环。
2.1 仍是自回归 Decoder,但「每一层不全是 softmax 注意力」
与 Decoder Only Transformer 一致:语言建模仍是 因果链 ------预测下一 token 时只能依赖 已出现 的上文。Qwen3.5 没有 Encoder--Decoder 里的 交叉注意力。
与 Qwen3 不同的是:Qwen3 的 每个 Transformer Block 里,注意力子层在数学形态上都是 缩放点积 + softmax 的 全注意力 (配合 GQA、RoPE、QK-Norm 等)。Qwen3.5 在 深度方向 上把 Block 分成两类(在 config.json 的 layer_types 里显式列出):
linear_attention:线性注意力 / 状态更新 类子层(官方 README 称为 Gated Delta Networks 路线;理论脉络可参考 NVIDIA 开源实现的说明 NVlabs/GatedDeltaNet 及论文 Gated Delta Networks: Improving Mamba2 with Delta Rule ,ICLR 2025)。full_attention:标准因果全注意力 (仍用 Q/K/V 线性映射、RoPE、softmax、 W O W_O WO 等大家熟悉的配方;实现上常配合 GQA :num_attention_heads与num_key_value_heads可不等)。
入门精读:full_attention 与 linear_attention 到底差在哪?
下面用「当前词要看上文哪些词、怎么看」这一件事,把两种子层分开说清楚(不涉及 Qwen3.5 源码里每一个张量名)。
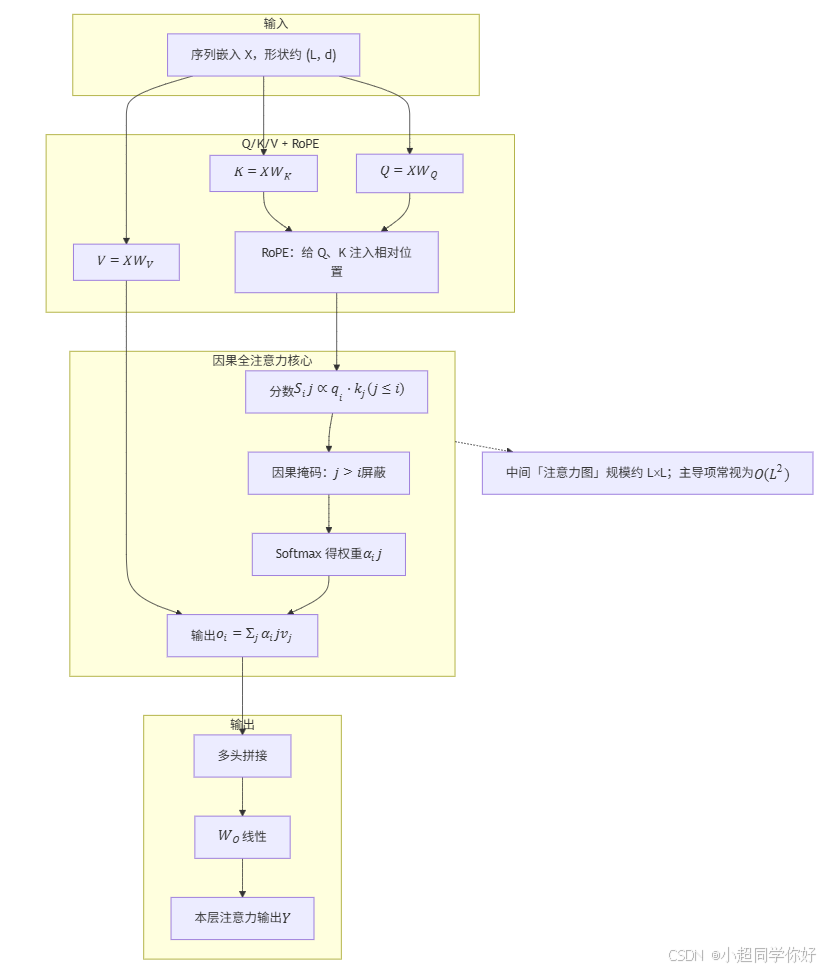
(1)full_attention:显式「两两打分」的因果全注意力
- 对序列中 每一个位置 i i i,模型都要回答:第 i i i 个 token 应该关注前面哪些位置 j ≤ i j \le i j≤i?关注多少?
- 做法是大家熟悉的 Q/K/V :用当前位置的 查询 q i q_i qi 去和 所有允许位置 的 键 k j k_j kj 算相似度,经 softmax 得到一组 权重 α i j \alpha_{ij} αij(对 j > i j>i j>i 的位置强制为 0,即 因果掩码 ),再用权重去 加权求和 所有 v j v_j vj,得到位置 i i i 的输出。
- 关键特征 :为了得到所有 α i j \alpha_{ij} αij,中间会出现 长度 × \times × 长度 规模的中间量(可理解为「注意力图」),序列长度 L L L 翻倍时,这部分算力和显存大致按 L 2 L^2 L2 增长------所以叫 二次复杂度 的 全注意力。
- GQA 只是 省 KV :多个查询头 共享 同一套 K K K、 V V V(
num_key_value_heads< < <num_attention_heads),减少 推理时要缓存的 KV ,但 「对每个 i i i 仍要对所有 j j j 做一遍可见范围内的对齐」 这一件事 没变。 - RoPE 给 q i q_i qi、 k j k_j kj 带上 相对位置 信息,让模型知道「远/近」关系;W O W_O WO 把多头拼好的结果再线性变回和残差支路同维的向量。
一句话:full_attention = 标准 Decoder 里那种「当前词对上文每一个词都能单独调权重」的注意力 ;能力强,长序列成本高。
full_attention 架构示意图:
输出
因果全注意力核心
Q/K/V + RoPE
输入
序列嵌入 X,形状约 (L, d)
Q = X W Q K = X W K V = X W V RoPE:给 Q、K 注入相对位置
分数 S i j ∝ q i ⋅ k j ( j ≤ i ) 因果掩码: j > i 屏蔽 Softmax 得权重 α i j 输出 o i = Σ j α i j v j 多头拼接
W O 线性 本层注意力输出 Y 中间「注意力图」规模约 L×L;主导项常视为 O ( L 2 )
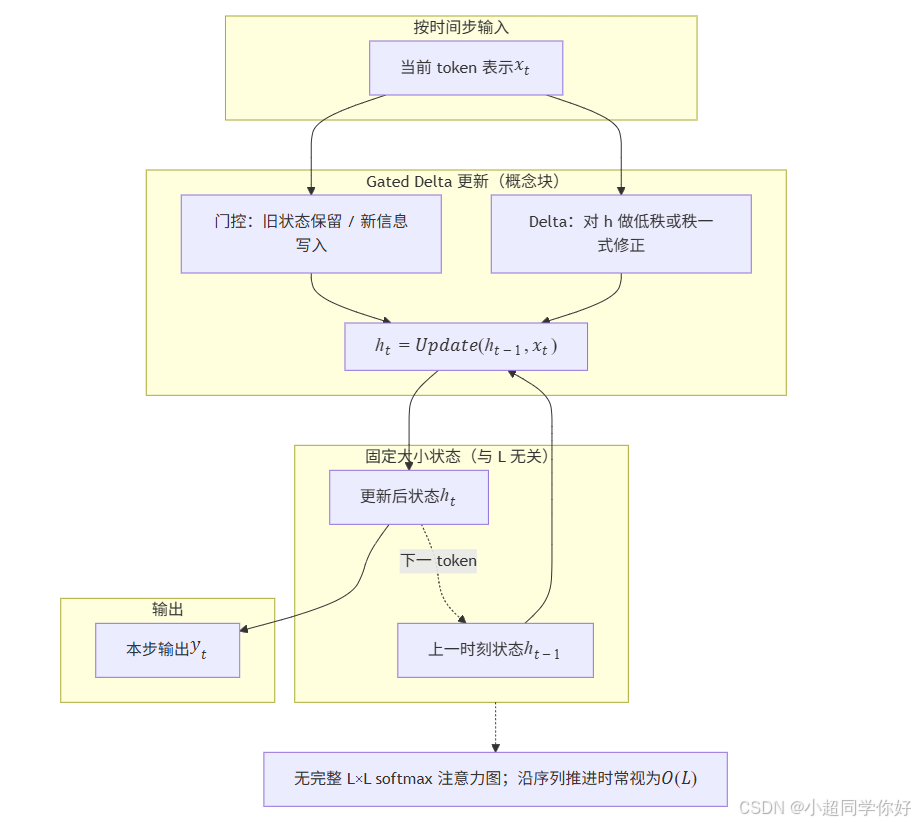
(2)linear_attention(Gated DeltaNet 一类):用「固定大小状态」压缩历史
- 这里 不再 (在同一层里)用 完整的 L × L L \times L L×L softmax 注意力图 作为核心机制。取而代之的是:维护一个(或一组)与序列长度 L L L 无关、维度固定的内部状态 (可记为 h t h_t ht),每读入一个新 token,就用当前输入 更新 h t h_t ht。
- 直觉类比 :读很长的文章时,你不是每一句都把 从第一段到当前句的每一个字 重新做一遍「和谁最相关」的全表对表;而是手里有一页 固定行数的笔记 ,每读新句就把笔记 改写一行 ------笔记大小不随文章页数变 。因此序列从 L L L 变 2 L 2L 2L,这一层的计算量大致按 L L L 线性涨,而不是平方涨。
- Gated DeltaNet 在这条线上再叠两件事(名字即含义):
- Delta(增量) :新信息到来时,对状态做 秩一 / 低秩式的修正(「在原记忆上打补丁」),而不是每一步完全重算整段历史。
- Gate(门控) :用 可学习的门 控制 旧状态保留多少、新信息写入多少,减轻长链递推时的不稳定(和 LSTM、Mamba 里「门控」的用途同类)。
- 代价 :单层内 不能 像 softmax 全注意力那样,一步就得到「任意 i i i 对任意 j j j」的 全局精细分配表 ;长程依赖要靠 状态递推 间接传递。所以 Qwen3.5 每隔几层插一层
full_attention,用 全注意力 把序列里任意两点 再对齐一次 ,弥补线性层在 细粒度对齐 上的不足。
linear_attention 架构示意图:
输出
Gated Delta 更新(概念块)
固定大小状态(与 L 无关)
按时间步输入
下一 token
当前 token 表示 x t 上一时刻状态 h t − 1 更新后状态 h t 门控:旧状态保留 / 新信息写入
Delta:对 h 做低秩或秩一式修正
h t = U p d a t e ( h t − 1 , x t ) 本步输出 y t 无完整 L×L softmax 注意力图;沿序列推进时常视为 O ( L )
(3)为什么要两种叠在一起?
- 只有全注意力 :长上下文时 算力、KV 显存 吃紧。
- 只有线性/状态层 :便宜、能扛长文 ,但 「精确指向某一个远处 token」 的能力容易弱。
- 3:1 交错 :大部分层 省算力、扛长度 ,少数层 做「全局精细对表」 ------这是 效率与表达能力 的折中,而不是二选一。
公开权重里 full_attention_interval: 4 与 layer_types 的 3 个 linear + 1 个 full 循环一致------这与第三方博文总结的 「3:1 线性 : 全注意力」 一致(例如 Digital Applied:Qwen 3.5 Medium 架构导读、Medium:Qwen 3.5 explained)。
Decoder 堆叠(示意)
Block: linear_attention
Block: linear_attention
Block: linear_attention
Block: full_attention
Block: linear_attention
...
循环:3 层 linear → 1 层 full;full 做全局精细对表
💡 直觉 :全注意力 像「任意两字之间都可精细对表」------强,但序列一长算力和 KV 开销暴涨(O ( L 2 ) O(L^2) O(L2) 主导)。线性注意力层 像「读长文时不断把已读内容 压进固定大小的笔记本 (状态),再读新句只更新笔记本」------长度翻倍不等于算力四倍 ,但若不穿插全注意力,细粒度对齐能力可能不足。3:1 交错是工程与效果的折中。
2.2 宏观看:多模态时的数据流(概念)
对 图文统一 权重,可粗画为(与上文 架构示意(Mermaid) 相同,需支持 Mermaid 的预览器):
文本支路
视觉支路
图像 patches
Vision Encoder(CNN / ViT 类,vision_config)
视觉 token 隐状态
文本字符串
Tokenizer
Embedding
早期融合后的序列表示
交替:linear_attention / full_attention 块 +(MoE 或稠密)FFN
LM Head → logits / 或继续多模态解码管线
不渲染 Mermaid 时 ,可按顺序读:视觉 patches → Vision Encoder → 视觉 token;文本 Tokenizer → Embedding;两路汇入 早期融合序列 → 交替注意力块与 FFN → LM Head(或多模态解码)。
纯文本推理 时,Vision 支路可闲置;读架构仍应知道 text_config 与 vision_config 耦合在同一 checkpoint。
2.3 单个「全注意力 Block」与 Qwen3 的相似度
在 full_attention 层上,数据流仍接近 Qwen3:Pre-Norm(RMSNorm)→ 因果 GQA 全注意力(RoPE、无 attention_bias)→ 残差 → RMSNorm → FFN / MoE → 残差 。差别主要在:并非每一层都是这一形态 ------相邻层可能是 linear_attention。
2.4 MoE 在 Qwen3.5 中的位置
与 Qwen3 一样:MoE 替换 FFN 段 ;全注意力层 里的注意力仍是稠密路由(非专家)。以 Qwen3.5-35B-A3B 的 text_config 为例(数值随权重版本可能变化):num_experts: 256 ,num_experts_per_tok: 8 ,并出现 shared_expert_intermediate_size ------即除 top- k k k 路由专家外,还有 共享专家 支路 来源:Hugging Face `Qwen/Qwen3.5-35B-A3B` `config.json`。这与 Qwen3 技术报告中 MoE「无共享专家」 的叙述 不同 ,读两代 MoE 时务必 分型号核对 config。
3. Tokenizer、词表与 Embedding
3.1 BBPE 与词表规模
Qwen 系列一贯使用 byte-level BPE 思路:多语友好、减轻 OOV。Qwen3.5 公开 text_config.vocab_size 常见为 248320 (例如 27B、35B-A3B 配置),大于 Qwen3 报告中的 151669 ------意味着 控制 token、多模态特殊 token、工具调用等 进一步扩张;具体 ID 映射 以 tokenizer.json / tokenizer_config.json 为准。
💡 理解要点 :词表扩张 → 同样文本 token 数可能变化 ;Embedding 与 LM Head(若 untied)参数量 与 V V V 线性相关。
Qwen 系列代际词表规模对照 (便于把上式里的 V V V 落到具体数量级;实现以各 checkpoint 的 vocab_size 与 tokenizer 文件为准):
| 代际 | 词表规模 V V V(常用叙述口径) | 说明 |
|---|---|---|
| Qwen 1 | 约 152K ( ∼ 1.52 × 10 5 \sim 1.52\times 10^5 ∼1.52×105) | 技术报告给出约 152K 量级;全体尺寸共用一套 BPE 词表思路,见 31_qwen_1.md。 |
| Qwen 2 | 151,646 | 151,643 个常规 token + 3 个控制 token;报告表 1 固定口径,见 32_qwen_2.md §2。 |
| Qwen 3 | 151,669(技术报告) | 相对 Qwen2 +23 token(特殊符号等)。config.json 中 vocab_size 可能大于 151669 (如 151936 ),多为 张量对齐 / padding ,嵌入行数以该 checkpoint 为准,见 34_qwen_3.md §3.1。 |
| Qwen3.5 | 248,320 (多款开源 text_config 常见) |
例如 27B、35B-A3B 等;较 Qwen3 报告口径 显著增大 ,多模态 / 工具 / 控制类 token 扩张。更小规格(如 9B / 4B / 2B 等)是否相同以各自 config.json 为准(见上文 §3.1)。 |
读表注意 :上表是 系列代际对比 ;同一代内不同尺寸通常 共用同一套 tokenizer 与词表规模 ,但 Qwen3.5 小模型是否均为 248320 需 逐型号核对 ,且 vocab_size ≥ 名义词表行数 时,算参数量与形状以 config.json + tokenizer.json 为准。
3.2 嵌入矩阵与形状
记 词表行数 为 V V V(实现上通常取 text_config.vocab_size,可与 tokenizer 名义词表略有差异,见下表),隐维度为 d model d_{\text{model}} dmodel(hidden_size)。嵌入矩阵按「词表索引 × 隐维度」存放可学习向量:
E ∈ R V × d model . E \in \mathbb{R}^{V \times d_{\text{model}}}. E∈RV×dmodel.
对序列第 i i i 个位置( i = 0 , ... , L − 1 i=0,\ldots,L-1 i=0,...,L−1),Tokenizer 给出 非负整数 token ID w i ∈ { 0 , ... , V − 1 } w_i \in \{0,\ldots,V-1\} wi∈{0,...,V−1}。把 E E E 的第 w i w_i wi 行 (长度为 d model d_{\text{model}} dmodel 的行向量 )转置成列向量,记为
e w i = E w i , : ⊤ ∈ R d model . \mathbf{e}{w_i} = Ew_i,\\,:^\top \in \mathbb{R}^{d{\text{model}}}. ewi=Ewi,:⊤∈Rdmodel.
长度为 L L L 的整段序列 ( w 0 , ... , w L − 1 ) (w_0,\ldots,w_{L-1}) (w0,...,wL−1) 按 行 堆成送入 第一层 Decoder 的输入矩阵(与 32_qwen_2.md §3.1、34_qwen_3.md §3.2 一致):
X = e w 0 ⊤ ⋮ e w L − 1 ⊤ ∈ R L × d model . X = \begin{bmatrix} \mathbf{e}{w_0}^\top \\ \vdots \\ \mathbf{e}{w_{L-1}}^\top \end{bmatrix} \in \mathbb{R}^{L \times d_{\text{model}}}. X= ew0⊤⋮ewL−1⊤ ∈RL×dmodel.
批量推理 / 训练 时,常再引入 batch 维 B B B,得到 X b a t c h ∈ R B × L × d model X_{\mathrm{batch}} \in \mathbb{R}^{B \times L \times d_{\text{model}}} Xbatch∈RB×L×dmodel,即 B B B 条序列并行;下文为简洁仍写单条 L × d model L \times d_{\text{model}} L×dmodel。
与「经典 GPT 式」的差别(仍与 Qwen 1/2/3 相同) :不在 X X X 上再加正弦绝对位置向量 ;相对位置 由 RoPE 在注意力里作用到 Q、K (Qwen3.5 另有 mRoPE 等多模态相关字段,见 §7 )。多模态早期融合 时,图像经 Vision Encoder 得到的 视觉 token 与文本 token 拼成同一条序列 再进栈;文本侧 仍按上式从 E E E 查表 ,视觉侧由 视觉塔输出维 与 投影 / 对齐层 接到与 d model d_{\text{model}} dmodel 一致的表示(具体以权重实现为准)。
3.3 绑权(Weight Tying)
语言模型最后一层要把 隐状态 映射到 词表大小 V V V 的 logits ,与 §3.2 的嵌入矩阵 E ∈ R V × d model E \in \mathbb{R}^{V \times d_{\text{model}}} E∈RV×dmodel 成对出现。记 最后一层 在「当前要预测的位置」上的隐向量为 h ∈ R d model \mathbf{h} \in \mathbb{R}^{d_{\text{model}}} h∈Rdmodel(列向量;推理时常取序列 最后一个 非填充位置,与 32_qwen_2.md §3.2 一致)。
(1)不绑权(untied,tie_word_embeddings: false)
单独维护 输出投影 W out ∈ R d model × V W_{\text{out}} \in \mathbb{R}^{d_{\text{model}} \times V} Wout∈Rdmodel×V(及可选 b out ∈ R V \mathbf{b}_{\text{out}} \in \mathbb{R}^V bout∈RV),与 E E E 参数独立 。logits 列向量 s ∈ R V \mathbf{s} \in \mathbb{R}^V s∈RV 为
s = W out ⊤ h + b out . \mathbf{s} = W_{\text{out}}^\top \mathbf{h} + \mathbf{b}_{\text{out}}. s=Wout⊤h+bout.
等价地,第 w w w 个词的分量 s w = h ⊤ w w ( out ) + ( b out ) w s_w = \mathbf{h}^\top \mathbf{w}^{(\text{out})}w + (b{\text{out}})_w sw=h⊤ww(out)+(bout)w,其中 w w ( out ) \mathbf{w}^{(\text{out})}w ww(out) 是 W out W{\text{out}} Wout 的 第 w w w 列 (与 e w \mathbf{e}w ew 不必相同 )。参数量 上多了一块与词表同宽的 **d model × V d{\text{model}} \times V dmodel×V** 级矩阵(Qwen3.5 的 V V V 已达 248320 量级时,这一块很显眼)。
(2)绑权(tied,tie_word_embeddings: true)
令
W out = E ⊤ , W_{\text{out}} = E^\top, Wout=E⊤,
即 输出层权重与嵌入矩阵互为转置 ,不再单独存 一份 W out W_{\text{out}} Wout。此时第 w w w 个 logit 可写成
s w = h ⊤ e w + ( b out ) w , s_w = \mathbf{h}^\top \mathbf{e}w + (b{\text{out}})_w, sw=h⊤ew+(bout)w,
也就是 h \mathbf{h} h 与 输入端用来表示词 w w w 的嵌入向量 e w \mathbf{e}_w ew 的 内积 (再加偏置):「从上下文得到的方向」与「词表里的词向量方向」强制共用同一套 V V V 个 d model d_{\text{model}} dmodel 维基。
收益 :省掉约 一整块 d model × V d_{\text{model}} \times V dmodel×V 的输出权重;代价 / 归纳偏置 :输入、输出在词表维上耦合更紧,大模型有时更愿意用 untied 换表达自由度(与 Qwen 系列各代按规模切换策略一致)。
(3)各代 Qwen 绑权策略对照
下表概括 输入嵌入 E E E 与输出投影 W out W_{\text{out}} Wout 是否共用 (tie_word_embeddings / 报告 Embedding Tying );具体 checkpoint 仍以 config.json 为准(MoE、多版本权重尤需逐包核对)。
| 系列 | 总体规律(叙述口径) | 报告或开源配置中的典型例子 | 依据 / 备注 |
|---|---|---|---|
| Qwen 1 | 报告明确 不绑权(untied) | 各尺寸均 独立 W out W_{\text{out}} Wout | qwen 1 |
| Qwen 2 | 小模型 tied,大模型 untied | True :0.5B、1.5B;False:7B、72B、57B-A14B(MoE)等 | qwen 2 |
| Qwen 3 | 小模型多 tied,8B 及以上多 untied | Yes :0.6B、1.7B、4B;No :8B、14B、32B;MoE 各款以 config.json 为准 |
qwen 3 |
| Qwen3.5 | 中大型开源权重常见 untied ;小规格因型号而异 | 27B、35B-A3B 等常见 tie_word_embeddings: false ;9B / 4B / 2B 等 勿凭代际猜测 |
本文 §3.3;以 Hugging Face 各 config.json 为准 |
Qwen3.5 小结 :与 Qwen3 多款 中大型 稠密 / MoE 一样,27B / 35B-A3B 一类常选 不绑权 ;更小或更新权重是否 tied,只信对应 checkpoint 的 tie_word_embeddings 字段。
4. RMSNorm 与 Pre-Norm
对 x ∈ R d model \mathbf{x}\in\mathbb{R}^{d_{\text{model}}} x∈Rdmodel,
R M S ( x ) = ε + 1 d model ∑ j x j 2 , R M S N o r m ( x ) = x R M S ( x ) ⊙ γ . \mathrm{RMS}(\mathbf{x}) = \sqrt{\varepsilon + \frac{1}{d_{\text{model}}}\sum_{j} x_j^2}, \quad \mathrm{RMSNorm}(\mathbf{x}) = \frac{\mathbf{x}}{\mathrm{RMS}(\mathbf{x})} \odot \boldsymbol{\gamma}. RMS(x)=ε+dmodel1j∑xj2 ,RMSNorm(x)=RMS(x)x⊙γ.
Qwen 1 / 2 / 3 / 3.5 在「Pre-Norm + RMSNorm 」上与 LLaMA 系 一致 (对照 12_LLaMA_architecture.md)。
4.1 Pre-Norm 指什么
Pre-Norm :在每个子层(注意力或 FFN)之前 先做归一化,再把归一化后的张量送进该子层;子层输出与 子层输入的残差支路 相加。不是 在子层输出之后再做 Norm(那是 Post-Norm 叙述里常见画法)。同一隐维度上,每个 Decoder 块里通常有两次 RMSNorm ,分别对应 注意力子层前 与 FFN(或 MoE)子层前。
4.2 在 Qwen3.5 单个 Decoder 块中的位置
Qwen3.5 的 layer_types 只区分 注意力子层 是 linear_attention 还是 full_attention ;归一化与残差的排布 与 Qwen3 相同,不因「线性 / 全注意力」而改变骨架 。记第 ℓ \ell ℓ 层块入口的隐表示为 H ( ℓ − 1 ) H^{(\ell-1)} H(ℓ−1)(对 ℓ = 1 \ell=1 ℓ=1 即 Embedding 后的 X X X),则 一层 可写成:
- 注意力支路 : H ( ℓ − 1 ) → R M S N o r m ( ⋅ ) → H^{(\ell-1)} \;\to\; \mathrm{RMSNorm}(\cdot) \;\to H(ℓ−1)→RMSNorm(⋅)→
linear_attention或full_attention→ \;\to → 与 H ( ℓ − 1 ) H^{(\ell-1)} H(ℓ−1) 残差相加 得中间表示 H ~ ( ℓ ) \tilde H^{(\ell)} H~(ℓ)。 - FFN 支路 : H ~ ( ℓ ) → R M S N o r m ( ⋅ ) → \tilde H^{(\ell)} \;\to\; \mathrm{RMSNorm}(\cdot) \;\to H~(ℓ)→RMSNorm(⋅)→ SwiGLU 稠密 FFN 或 MoE → \;\to → 与 H ~ ( ℓ ) \tilde H^{(\ell)} H~(ℓ) 残差相加 得 H ( ℓ ) H^{(\ell)} H(ℓ),作为下一层输入。
与上文 §2.3 文字一致:Pre-Norm(RMSNorm)→ 注意力子层 → 残差 → RMSNorm → FFN / MoE → 残差 。MoE 只替换 FFN 段 (§2.4),不改变「第二个 RMSNorm 在 MoE 之前」这一位置。
注意 :RMSNorm 不作用在 Token Embedding 输出上单独占一层 ;进入 第 1 个 Decoder 块 时,首先遇到的是 该块内、注意力子层之前 的那次 RMSNorm(实现上即「堆叠入口的第一个归一化」在 **Block 1 的 attention 前」)。QK-Norm (若实现中存在)属于 注意力子层内部 对 Q Q Q、 K K K 的归一化,与 块级 RMSNorm 不是同一处(参见 §5 与实现源码)。
5. 全注意力子层(full_attention):与 Qwen3 同族的 GQA
当 layer_types[i] == "full_attention" 时,子层仍是 因果缩放点积注意力 形态:
- Pre-Norm 后得到 X ∈ R L × d model X \in \mathbb{R}^{L \times d_{\text{model}}} X∈RL×dmodel。
- 线性投影 得 Q Q Q、 K K K、 V V V;配置里通常
attention_bias: false (与 Qwen3 一致,无 QKV bias)。 - GQA :
num_attention_heads= h q h_q hq,num_key_value_heads= h kv h_{\text{kv}} hkv, h kv < h q h_{\text{kv}} < h_q hkv<hq 时节省 KV Cache(含义见 34_qwen_3.md §5 的 MHA/GQA/MQA 表)。 - RoPE 作用于 Q、K(见 §7)。
- 因果掩码 + softmax + W O W_O WO。
与 Qwen2 的差异 :Qwen2 报告强调 QKV bias ;Qwen3 / Qwen3.5 常见为 无 bias 。与 Qwen3 的差异 :Qwen3 技术报告强调 QK-Norm ;Qwen3.5 是否在 每一层 full_attention 都保留同名模块,应以 实现代码 / 版本 为准------读论文式解析时,以 Transformers / vLLM 对应版本源码为准。
5.1 数值例子(Qwen3.5-27B 的 text_config)
hidden_size: 5120num_hidden_layers: 64num_attention_heads: 24,num_key_value_heads: 4,head_dim: 256
此处 24 × 256 = 6144 ≠ 5120 = hidden_size 24 \times 256 = 6144 \neq 5120 = \texttt{hidden\size} 24×256=6144=5120=hidden_size,与「 h q ⋅ d h = d model h_q \cdot d_h = d{\text{model}} hq⋅dh=dmodel」的 LLaMA 式简化 不一致 ------说明全注意力路径上存在 额外投影 / 分组布局 (例如 Q/K/V 或输出侧再映射回 hidden_size)。唯一可靠依据 是该版本 modeling_qwen3_5*.py 中的张量形状,不可 仅凭 head_dim 硬推 W Q W_Q WQ 方阵维度。
🔍 读配置提醒 :
head_dim、num_attention_heads与hidden_size三者关系 因实现而异 ;与 Qwen2 报告里「 d h = d model / h d_h = d_{\text{model}}/h dh=dmodel/h」的常见写法对比时,要把 Qwen3.5 当作 需查源码 的一类。
6. 线性注意力子层(linear_attention):Gated DeltaNet 路线在做什么
6.0 linear_attention 里具体在干什么?
可以把 full_attention 和 linear_attention 想成两种「读上文」的方式(输出仍是「每个位置一个向量」,都要接后面的 FFN,整块骨架仍是 §4 里那种 RMSNorm → 子层 → 残差):
-
full_attention(标准因果注意力)到了第 i i i 个 token,模型要显式 回答:上文里每一个 位置 j ≤ i j \le i j≤i,我该看多少?所以会算一张「谁看谁的」大表(注意力权重),序列越长,这张表越大 ,算力和显存大致按长度平方 涨。好处是:任意两个位置 之间都可以立刻精细对齐。
-
linear_attention(这里实现上靠近 Gated DeltaNet 一类)到了第 i i i 个 token,不再 在这一层里维护整张「长度 × 长度」的 softmax 注意力表。取而代之的是:网络手里有一份固定大小 的「对过去的摘要 / 内部状态 」(可以想象成页数固定的笔记本 ,不随文章变长而变厚)。每读一个新 token ,就用当前输入更新 这份摘要,再据此算出当前位置 的输出。
直白地说 :它更像在顺着读 :「带着当前笔记 + 新读到的一句 → 改写笔记 → 给出这一句的表示」,而不是「把从开头到当前句的每一个字 再和当前句做一遍全表对表」。因此对很长 的序列,这一层往往更省算力、更省显存 ;代价是:不能像全注意力那样 在同一层里对任意远、任意两个 token 做那种一步到位的精细对表 ,所以 Qwen3.5 才要每隔几层插一层full_attention来补全局对齐能力(见 §2.1)。
「Gated」和「Delta」在口语里是什么意思?
- Gate(门控) :更新那份「笔记本」时,网络用可学习的开关 决定:旧摘要保留多少、新读到的内容写进多少 。避免读了几千 token 以后,内部状态爆掉或漂掉------和 LSTM、Mamba 里「门控」的用途是同一类直觉。
- Delta(增量) :新信息来时,往往是对状态做一小块、低秩式的修正 (「在原记忆上打补丁」),而不是每一步把整段历史从零重算一遍 ------所以叫 Delta 路线。
和 config.json 里那些 linear_* 字段的关系(仍然直白) :
线性子层内部并不是「没有 Q/K/V」 ,而是换一种更省的方式 组织计算(多组 key/value 头 、头维、以及可能和局部卷积核 混合------对应 linear_num_*、linear_*_dim、linear_conv_kernel_dim)。你不必 先背清每个张量名;只要记住:它们是在规定「这份递推状态有多宽、分几条并行、是否带一点局部卷积」 ,精确形状以 modeling_qwen3_5*.py 为准。
attn_output_gate :在子层算完之后 再做一个门控混合 ,属于工程上让训练更稳、表达更灵活的一层小结构,理解成「输出再调一下闸」即可。
6.1 与全注意力的复杂度对比(为什么需要它)
标准全注意力:单头 logits 矩阵 S ∈ R L × L S \in \mathbb{R}^{L \times L} S∈RL×L,内存与算力 随 L L L 二次增长 。线性注意力 族(含 Mamba/SSM 、DeltaNet 、Gated DeltaNet 等变体)的核心是:用递推状态 h t h_t ht 汇总历史 ,使得 单步更新 往往 O ( d 2 ) O(d^2) O(d2) 或 O ( d ⋅ k ) O(d \cdot k) O(d⋅k) 级,对长度 L L L 近似线性。
6.2 「Delta」与「Gate」的极简直觉(不写完整递推式)
- Delta 规则 思想:新输入到来时,用 秩一 / 低秩更新 修正内部记忆(类似「在笔记本上划掉旧一行、写上更正」),比「每一步重读全历史」更省。
- Gate(门控) :控制 多少旧状态保留、多少新信息写入 ------与 LSTM / Mamba 类门控 同一类归纳 ,用于 稳定长链递推。
官方 README 将 Qwen3.5 的线性侧称为 Gated Delta Networks ,与 NVlabs/GatedDeltaNet 论文标题一致;具体在 Qwen3.5 里与 linear_conv_kernel_dim、linear_*_heads 等字段如何一一对应 ,属于 实现细节 ,应以 开源 modeling 代码 为唯一精确来源。
6.3 config.json 中线性侧专有字段(含义层)
以 27B 为例(35B-A3B 数值不同但字段同型):
linear_num_key_heads/linear_num_value_heads:线性子层内部的 键/值头数 ,可与全注意力层的num_key_value_heads不同。linear_key_head_dim/linear_value_head_dim:线性侧头维。linear_conv_kernel_dim:与 局部卷积 / 短核 混合有关的超参(常见于 局部+全局 混合设计),精确语义看源码。attn_output_gate: true :对 注意力子层输出 再作 门控混合(提升表达与训练稳定性的一类工程技巧)。
💡 和 Qwen1/2/3 对比 :Qwen1~3 的每一层 都没有这一整类
linear_attention层 ;这是 Qwen3.5 在「层类型」上的根本新东西。
7. RoPE 与多模态相关位置参数
Qwen3.5 text_config 中常见:
rope_theta:如 1e7 ( 10 7 10^7 107),比 Qwen2/3 常见的 1e6 更大 ------与「更长序列、更慢旋转 」的工程取向一致(直观同 32_qwen_2.md 对基频的讨论)。partial_rotary_factor:如 0.25 ------仅对部分维施加旋转,属 实现节约与表达力折中。mrope_interleaved、mrope_section:多模态 RoPE(mRoPE) 相关配置,用于 文本 + 视觉 + 可选时间维 的 交错位置编码 ------这是 Qwen3.5 相对纯文本 Qwen3 的关键 多模态机制 ,细节需对照 视觉 token 如何插入序列 的代码。
8. FFN、SwiGLU 与 MoE(text_config)
与 §2 总览的对应关系 :§2 单层骨架里的 「子层 2」节点(FF) 即本节所描述的 FFN 槽位 ------要么是 稠密 SwiGLU(§8.1) ,要么是 稀疏 MoE(§8.2) ;二者 二选一 占同一深度,以 config 为准。下文 §8.1、§8.2 中的 Mermaid 图 是对该节点的 展开,不必再画进 §2 总览(避免图面过重)。
8.1 稠密 FFN(非 MoE 或专家关闭层)
在 Block 里的位置 :注意力子层(linear_attention 或 full_attention)与第一个残差之后,得到 H ~ \tilde{H} H~;再经 第二个 RMSNorm (§4)得到送入 FFN 的张量。下文记 单条序列、单位置 的隐向量为行向量形式堆叠时的 x ~ ⊤ \tilde{\mathbf{x}}^\top x~⊤;矩阵写法 时 X ~ ∈ R L × d model \tilde{X} \in \mathbb{R}^{L \times d_{\text{model}}} X~∈RL×dmodel,每一行对应一个 token 位置。
稠密 FFN 指:每一个 token 都走 同一套 两层(或三段)MLP 参数------没有「路由器」、没有「多份专家副本」;与 MoE 层 二选一占据 FFN 槽位 (同一深度上,要么整层稠密,要么整层 MoE,以 config 为准)。
SwiGLU (hidden_act: silu)仍是 Qwen 系常见的 门控线性单元 :用 Swish (SiLU)在一条支路上做门,与另一条支路逐元素相乘,再投影回 d model d_{\text{model}} dmodel:
S w i G L U ( X ~ ) = ( σ swish ( X ~ W 1 ) ⊙ ( X ~ W 3 ) ) W 2 . \mathrm{SwiGLU}(\tilde{X}) = \big(\sigma_{\text{swish}}(\tilde{X} W_1) \odot (\tilde{X} W_3)\big) W_2. SwiGLU(X~)=(σswish(X~W1)⊙(X~W3))W2.
架构示意(稠密 SwiGLU) :与 §4 一致, X ~ \tilde{X} X~ 来自 第二个 RMSNorm 之后;所有位置共用 W 1 , W 3 , W 2 W_1,W_3,W_2 W1,W3,W2。支持 Mermaid 的预览器可渲染下图。
Block 内 FFN 段(稠密)
送入 FFN 的张量 X̃
L×d_model
线性 W1:d_model → d_ff
线性 W3:d_model → d_ff
SiLU(逐元素)
⊙ 逐元素相乘
线性 W2:d_ff → d_model
FFN 输出,与注意力支路残差相加
记号与形状(直觉) : W 1 , W 3 ∈ R d model × d ff W_1,W_3 \in \mathbb{R}^{d_{\text{model}} \times d_{\text{ff}}} W1,W3∈Rdmodel×dff, W 2 ∈ R d ff × d model W_2 \in \mathbb{R}^{d_{\text{ff}} \times d_{\text{model}}} W2∈Rdff×dmodel;其中 d ff d_{\text{ff}} dff 对应 intermediate_size(或等价命名),不必 再等于 Qwen1 时代报告里统一的 8 3 d \frac{8}{3}d 38d,以本型号 config 为准 。 σ swish \sigma_{\text{swish}} σswish 即 S i L U ( t ) = t ⋅ σ ( t ) \mathrm{SiLU}(t)=t\cdot\sigma(t) SiLU(t)=t⋅σ(t); ⊙ \odot ⊙ 为按最后一维逐元素相乘。输出与 FFN 输入 做 残差 得到当前层输出(§4)。
8.2 MoE:门控、top- k k k、共享专家
MoE 替换的是 FFN 段 ,不 替换注意力子层:路由发生在 每个 token 的隐向量 上,注意力里仍是稠密 Q/K/V(与 §2.4 一致)。
单 token、单 MoE 层 (隐向量 x ∈ R d model x \in \mathbb{R}^{d_{\text{model}}} x∈Rdmodel,列向量)可概括为三步:
- 路由(门控) :线性层 G G G 把 x x x 映到 专家维 logits: ℓ = G ( x ) ∈ R N exp \boldsymbol{\ell} = G(x) \in \mathbb{R}^{N_{\text{exp}}} ℓ=G(x)∈RNexp, N exp = num_experts N_{\text{exp}}=\texttt{num\_experts} Nexp=num_experts。
- 选专家 :对 ℓ \boldsymbol{\ell} ℓ 做 s o f t m a x \mathrm{softmax} softmax 得 p p p(或 仅在 top- k k k 子集上 再归一化------实现细节以源码为准 ),取 概率最大的 k k k 个 下标 t o p k ( p ) \mathrm{topk}(p) topk(p), k = num_experts_per_tok k=\texttt{num\_experts\_per\_tok} k=num_experts_per_tok。
- 加权求和 :被选中的每个专家 R i R_i Ri 本质仍是 小型 FFN (常同构于稠密 SwiGLU 块),只对 该 token 计算 R i ( x ) R_i(x) Ri(x),再按路由权重加权求和。
共享专家(若配置启用) :在 top- k k k 之外 ,再设一路 始终参与 的变换 S ( x ) S(x) S(x)(shared_expert_* 等字段),相当于「全体 token 都经过 的公共 FFN」,缓解 稀疏路由 下部分模式 永远不被某些专家覆盖 的风险。总输出可写为:
ℓ = G ( x ) , p = s o f t m a x ( ℓ ) , y = ∑ i ∈ t o p k ( p ) p i R i ( x ) + S ( x ) ⏟ 共享专家(若配置启用) . \boldsymbol{\ell} = G(x), \quad p = \mathrm{softmax}(\boldsymbol{\ell}), \quad y = \sum_{i \in \mathrm{topk}(p)} p_i R_i(x) + \underbrace{S(x)}_{\text{共享专家(若配置启用)}}. ℓ=G(x),p=softmax(ℓ),y=i∈topk(p)∑piRi(x)+共享专家(若配置启用) S(x).
架构示意(MoE FFN,单位置) :每个 token 单独路由;仅 top- k k k 个 R i R_i Ri 参与该 token 的计算(共享支路 S S S 若启用则总是 计算)。路由权重与是否对 top- k k k 再归一化以 源码 为准。
隐向量 x
d_model
路由器 G
ℓ = G(x),维数 num_experts
softmax → 路由分布 p
取 top-k 专家索引
k = num_experts_per_tok
仅 k 个专家 R_i:各为小型 FFN
加权求和 Σ p_i R_i(x)
共享专家 S(x)
若 config 启用
输出 y
参数量直觉 :总参数量 含 所有专家 的 R i R_i Ri(以及 G G G、 S S S);前向每 token 实际计算 只激活 k k k 个专家 +(若有)共享支路 ,故 激活参数 远小于把同宽 稠密 FFN 铺满每一层。
Qwen3.5 与 Qwen3 的 MoE 叙事差异(务必分文档核对):
- Qwen3.5-35B-A3B (开源
config.json示例):num_experts: 256 ,num_experts_per_tok: 8 ,并出现shared_expert_intermediate_size等------即 256 路里每 token 激活 8 路 + 共享专家支路。 - Qwen3 技术报告常见叙述:128 路由专家、top-8 、不设共享专家 的 MoE 配方------与 Qwen3.5 默认开源配置 不是同一套数字。
因此读论文或对比两代 MoE 时,以各自权重里的 text_config 为准 ,勿把 Qwen3 报告 与 Qwen3.5 某 checkpoint 混成一张表。
8.3 负载均衡
router_aux_loss_coef 一类字段表明训练时使用 辅助损失 防止路由塌缩------思想与通用 MoE 训练一致(参见 32_qwen_2.md §6 对负载均衡的讨论精神)。
9. MTP(Multi-Token Prediction)配置项简述
text_config 中 mtp_num_hidden_layers: 1 等字段表明:在主干之外 存在 多步预测 / 投机解码 相关头(具体是否启用取决于推理框架)。这不改变 主因果链一步 logits 的定义,但影响 训练目标与推理加速策略 。实现细节以 对应版本 Transformers / vLLM 文档为准。
10. Vision Encoder(vision_config)与「原生多模态」
公开权重的 vision_config 描述 patch 嵌入、深度、宽度、patch_size 等------典型为 ViT/CNN 混合 类视觉塔,输出 out_hidden_size 与文本 hidden_size 对齐后 拼入 token 序列 。Qwen1/2/3 纯文本权重 无此块;Qwen3-VL 等为 另线产品 。Qwen3.5 README 强调 统一基础模型 ------读架构时应 把文本混合层与视觉塔放在同一张图里。
11. 长上下文与工程侧「动态长度」
- 配置级标称 :常见
max_position_embeddings: 262144(262K)。 - 托管/API 形态 :第三方文章(如 Digital Applied)描述 Flash 等 1M token 级窗口与 混合注意力带来的近线性扩展 ------属于 产品与实现组合 的结论,以阿里云 Model Studio / 官方说明为准。
- 训练/推理工程 :社区文(如 Medium:Qwen 3.5 small series)常强调 动态 batch、packing 对 短请求 的重要性------这与 注意力复杂度 无关,是 服务多用户时避免 pad 浪费 的通用手段;参数仍全部加载 ,变的是 算多少有效 token。
12. 总览表:Qwen 1 / 2 / 3 / 3.5
| 维度 | Qwen 1 | Qwen 2 | Qwen 3 | Qwen3.5 |
|---|---|---|---|---|
| 注意力 | 以 MHA 为报告基线 | 每层 GQA 全注意力 | 每层 GQA 全注意力 + QK-Norm | 混合 linear_attention + full_attention (常 3:1) |
| QKV bias | 有 | 有 | 无(报告) | 配置常见 无 |
| FFN | SwiGLU | SwiGLU | SwiGLU | SwiGLU;MoE 更复杂 (如 256/8 + 共享专家 等) |
| 位置 | RoPE | RoPE + 长文套件 | RoPE + ABF/YARN/DCA | 更强 RoPE 超参 + mRoPE 字段 |
| 多模态 | 非核心 | VL 另线 | VL 另线 | 统一图文权重常见 |
| 权威长文 | arXiv:2309.16609 | arXiv:2407.10671 | arXiv:2505.09388 | 官方博客 + GitHub bibtex(非独立 arXiv 长文) |
13. 各环节参数量(粗算思路)
| 模块 | Qwen3.5 相对前代的增量注意点 |
|---|---|
| Embedding / LM Head | V V V 常 显著大于 Qwen3 的 151669 叙述 → 词表维参数更大 |
| 全注意力层 | 与 Qwen3 同型粗算 ;但 层数与头数 按 本型号 config |
| 线性注意力层 | 参数模式不同于 标准 4 d 2 4d^2 4d2 的 W Q , W K , W V , W O W_Q,W_K,W_V,W_O WQ,WK,WV,WO 叙述;需 分实现拆解 |
| MoE | 专家数、共享专家、top- k k k 均以 config 为准;激活参数量 ≪ \ll ≪ 总参 |