摘要
将生命之树中的数十亿蛋白质进行关联分析,仍是比较生物圈基因组学与人工智能驱动结构预测领域的核心难题。本文提出1种级联式超快速聚类方法DIAMOND DeepClust,可实现行星尺度的蛋白质空间组织,支持万亿级序列分析,同时在低序列一致性条件下保持聚类灵敏度。本研究将190亿条生物圈蛋白质序列聚为5.44亿个非单例簇,实验证明该DeepClust数据库可提升AlphaFold2的蛋白质结构预测效果。
#DIAMOND #DeepClust #蛋白质宇宙 #蛋白质序列聚类 #级联聚类 #地球生物基因组计划 #蛋白质结构预测
基准测试
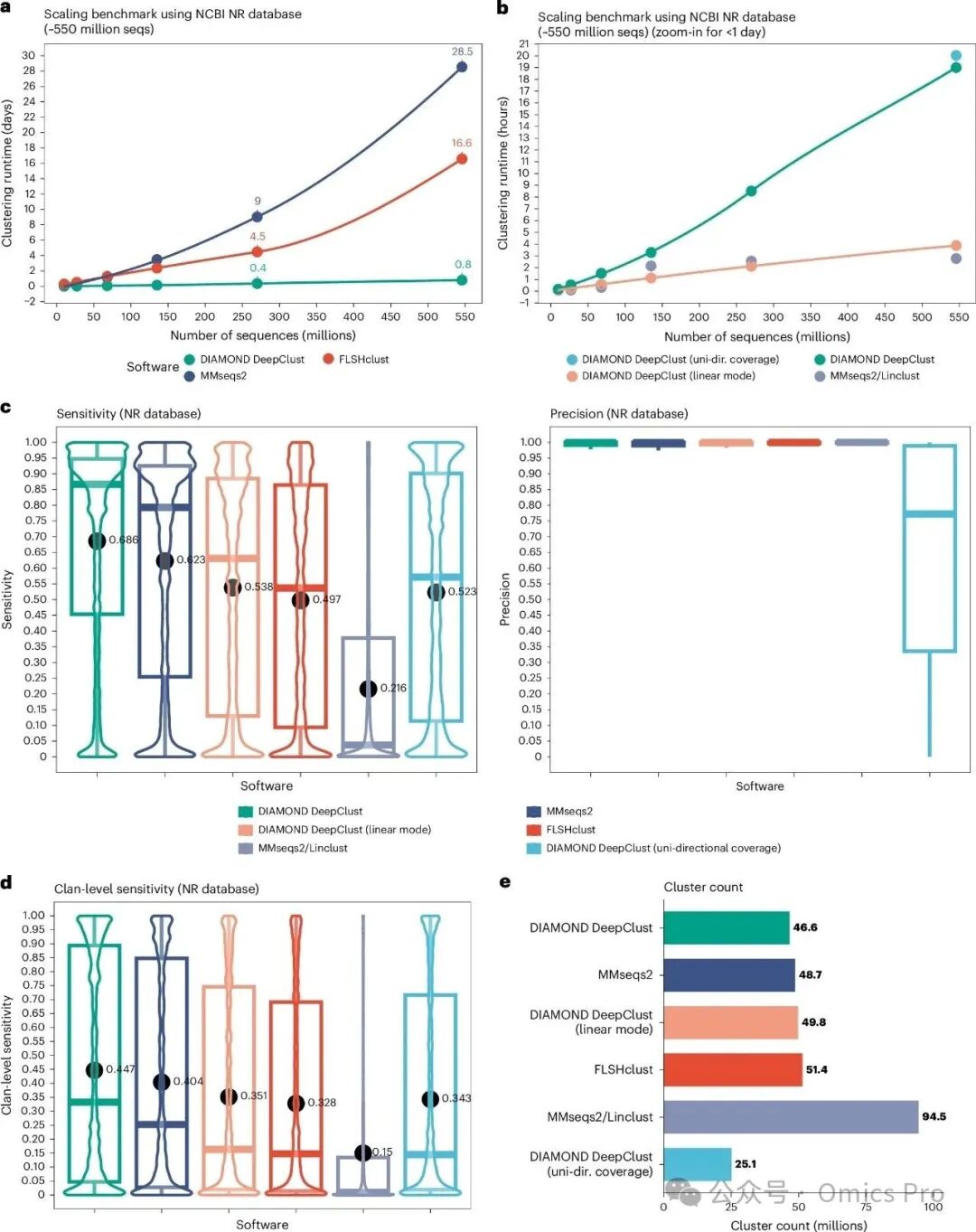
图 1 DIAMOND DeepClust、MMseqs2 与FLSHclust聚类性能基准测试
展示NCBI NR数据库(约5.46亿条蛋白质序列)的深度聚类计算基准,采用双向覆盖准则(无特殊说明时),不设置序列一致性阈值。
a) 64核服务器上,NR数据库及递增规模子样本的聚类耗时(单位:天)。
b) 与a) 一致,仅展示耗时小于1天的工具,单位:小时。
c) 基于Pfam结构域架构,压缩NCBI NR数据库时,1.5亿条注释输入序列的灵敏度与精度分布。
d) 将同一Pfam族系中不同家族视为等效时的聚类灵敏度。
e) 各工具生成的簇数量(箱线内横线为中位数;箱边为第25、75百分位数;须线为4分位距1.5倍内的极值)。
实验研究
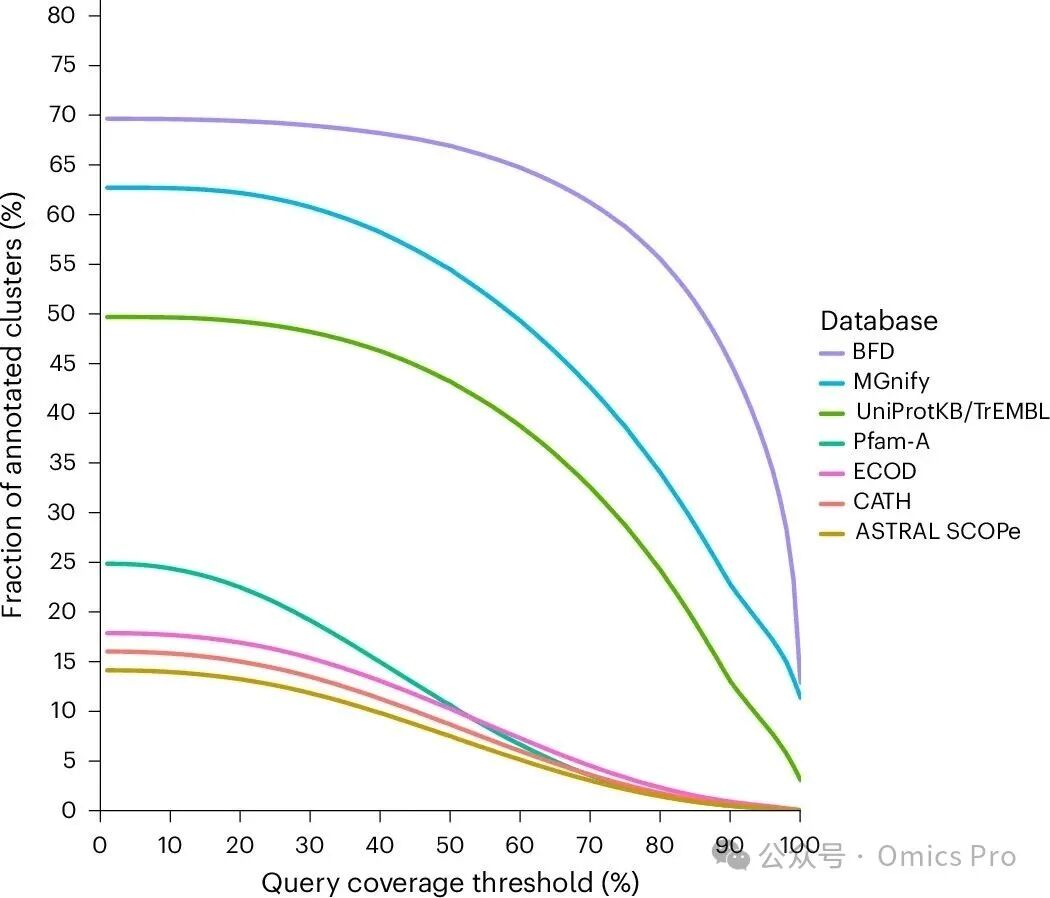
图 2 DIAMOND DeepClust聚类的蛋白质宇宙与现有数据库的关联特征
展示190亿条序列数据集中,簇规模≥3的代表序列在不同查询覆盖度阈值下,可基于现有数据库完成注释的比例(样本量:100万条代表序列)。
数据
190亿条蛋白质序列的聚类结果
https://objectstore.hpccloud.mpcdf.mpg.de/deepclust/index.html
代码
DIAMOND DeepClust地址
https://github.com/bbuchfink/diamond
基准测试、数据分析与绘图
https://github.com/drostlab/deepclust-data
适配ColabFold使用本实验数据库
https://github.com/drostlab/deepclust_colabfold
从Parquet文件提取序列
https://github.com/drostlab/deepclust_dataretrieval
详细总结
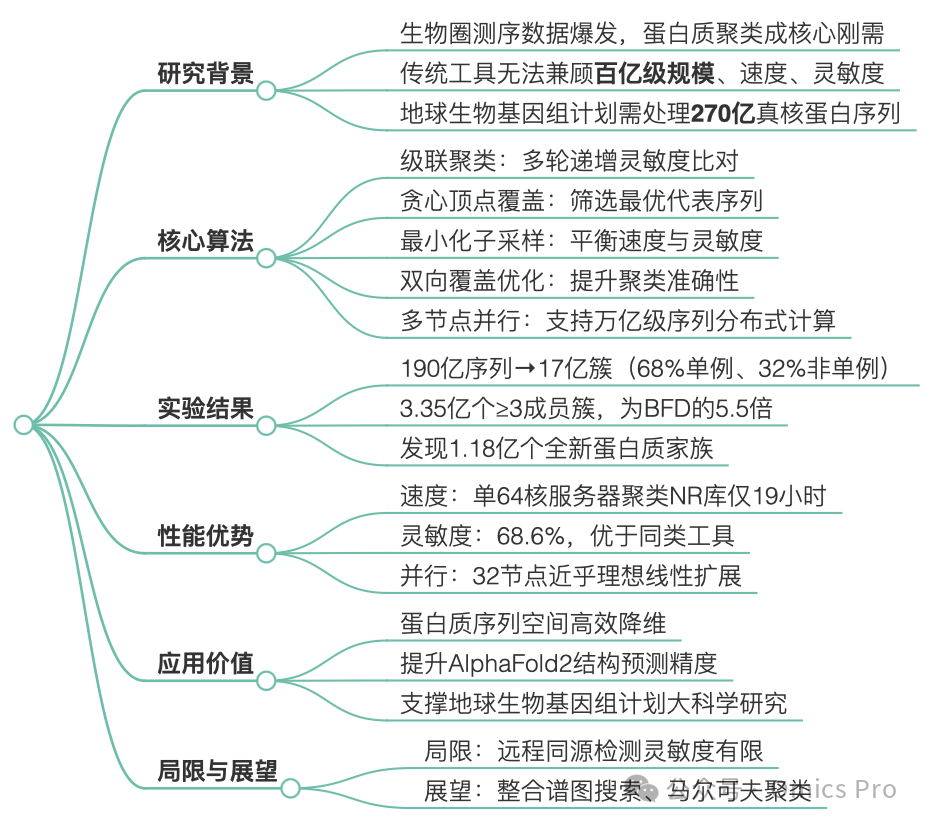
思维导图
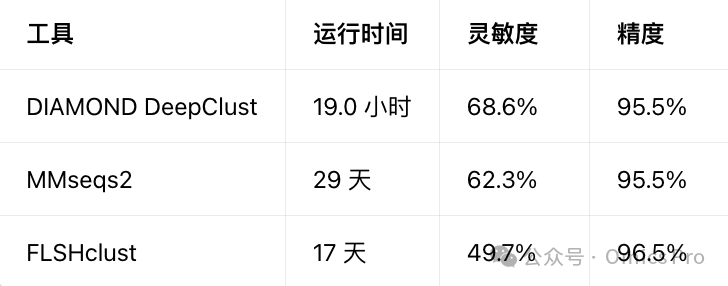
性能基准测试(NCBI NR库,5.46亿序列)
参考
Nat Methods. 2026 Mar 24. doi: 10.1038/s41592-026-03030-z.
Clustering the protein universe of life using DIAMOND DeepClust
注:AI辅助创作,如有错误欢迎指出。内容仅供参考,不构成任何建议。