
🎬 个人主页 :艾莉丝努力练剑
❄专栏传送门 :《C语言》《数据结构与算法》《C/C++干货分享&学习过程记录》
《Linux操作系统编程详解》《笔试/面试常见算法:从基础到进阶》《Python干货分享》
⭐️为天地立心,为生民立命,为往圣继绝学,为万世开太平
🎬 艾莉丝的简介:

文章目录
- [6 ~> 线程ID及进程地址空间布局](#6 ~> 线程ID及进程地址空间布局)
-
- [6.1 线程ID是什么?](#6.1 线程ID是什么?)
- [6.2 理解库](#6.2 理解库)
-
- [6.2.1 Linux "没有"真正的线程](#6.2.1 Linux “没有”真正的线程)
- [6.2.2 动态库的加载与映射](#6.2.2 动态库的加载与映射)
- [6.2.3 线程库与地址空间的关系](#6.2.3 线程库与地址空间的关系)
- [6.2.4 指令分析 (ldd 与 ls)](#6.2.4 指令分析 (ldd 与 ls))
- [6.2.5 总结建议](#6.2.5 总结建议)
- [6.2.6 理解库:思维导图](#6.2.6 理解库:思维导图)
- [6.3 理解"线程":用户线程](#6.3 理解“线程”:用户线程)
-
- [6.3.1 先描述:struct pthread (用户级 TCB)](#6.3.1 先描述:struct pthread (用户级 TCB))
- [6.3.2 再组织:内存中的"数组"与地址](#6.3.2 再组织:内存中的“数组”与地址)
- [6.3.3 线程 ID 的本质:一个"索引指针"](#6.3.3 线程 ID 的本质:一个“索引指针”)
- [6.3.4 完整的线程 = 用户库描述 + 内核 LWP 调度](#6.3.4 完整的线程 = 用户库描述 + 内核 LWP 调度)
- [6.3.5 总结](#6.3.5 总结)
- [6.3.6 "线程"思维导图](#6.3.6 “线程”思维导图)
- [6.4 查看源码:glibc源码](#6.4 查看源码:glibc源码)
-
- [6.4.1 申请空间:allocate_stack(创建struct结构体,填充字段)](#6.4.1 申请空间:allocate_stack(创建struct结构体,填充字段))
- [6.5 线程栈](#6.5 线程栈)
-
- [6.5.1 Linux线程栈](#6.5.1 Linux线程栈)
- [6.5.2 内存布局对比图](#6.5.2 内存布局对比图)
- [6.5.3 一句话理解](#6.5.3 一句话理解)
- [6.6 线程局部存储](#6.6 线程局部存储)
-
- [6.6.1 是什么?](#6.6.1 是什么?)
- [6.6.2 有什么用?](#6.6.2 有什么用?)
- [7 ~> 线程封装](#7 ~> 线程封装)
-
- [7.1 为什么要封装?](#7.1 为什么要封装?)
- [7.2 封装的核心技术挑战](#7.2 封装的核心技术挑战)
- [7.3 从"用户对象"到"库地址空间"再到"内核 LWP"的完整链路](#7.3 从“用户对象”到“库地址空间”再到“内核 LWP”的完整链路)
- [7.4 封装代码的逻辑精髓(核心逻辑实现)](#7.4 封装代码的逻辑精髓(核心逻辑实现))
- [7.5 知识点的闭环](#7.5 知识点的闭环)
- [7.6 回顾线程封装](#7.6 回顾线程封装)
-
- [7.6.1 如何把线程创建面向对象化?](#7.6.1 如何把线程创建面向对象化?)
- [7.6.2 线程启动](#7.6.2 线程启动)
- [7.6.3 线程状态](#7.6.3 线程状态)
- [7.6.4 正常使用的流程](#7.6.4 正常使用的流程)
- [7.6.5 优化:获取线程的名字](#7.6.5 优化:获取线程的名字)
-
- [7.6.5.1 函数原型与基础](#7.6.5.1 函数原型与基础)
- [7.6.5.2 核心代码逻辑分析](#7.6.5.2 核心代码逻辑分析)
-
- [7.6.5.2.1 写入名称(生产者端)](#7.6.5.2.1 写入名称(生产者端))
- [7.6.5.2.2 读取名称(消费者/观察端)](#7.6.5.2.2 读取名称(消费者/观察端))
- [7.6.5.3 为什么需要这两个函数?](#7.6.5.3 为什么需要这两个函数?)
- [7.6.5.4 深度补充:底层原理与替代方案](#7.6.5.4 深度补充:底层原理与替代方案)
-
- [7.6.5.4.1 底层路径](#7.6.5.4.1 底层路径)
- [7.6.5.4.2 替代方案:prctl](#7.6.5.4.2 替代方案:prctl)
- [7.6.5.5 注意事项](#7.6.5.5 注意事项)
- [7.6.5.6 总结表](#7.6.5.6 总结表)
- 结尾
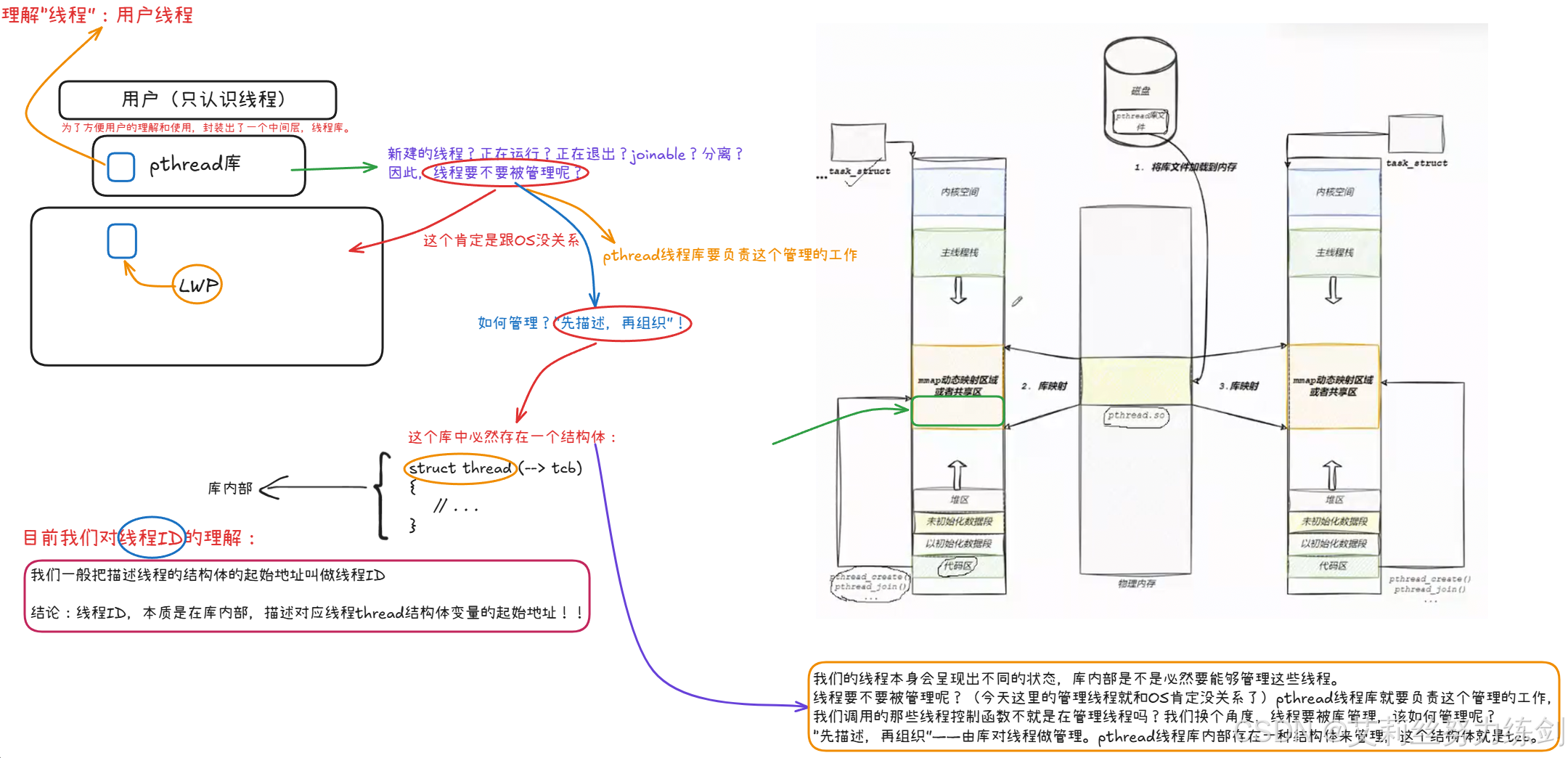
6 ~> 线程ID及进程地址空间布局
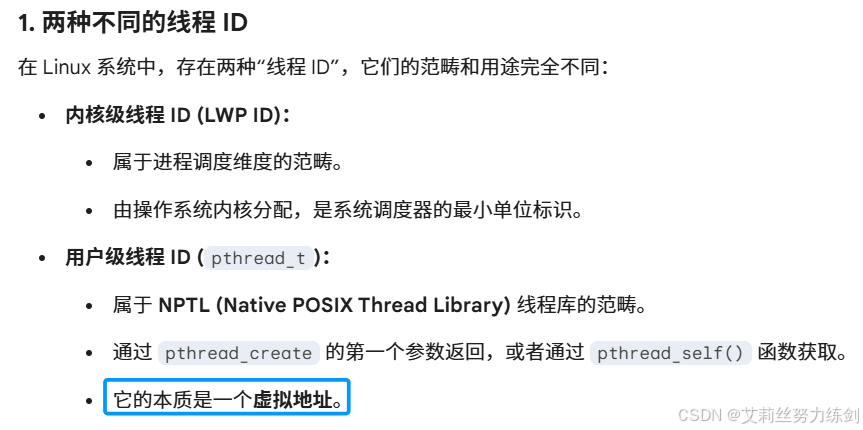
6.1 线程ID是什么?
线程ID不是LWP,而是地址,并且是虚拟地址 !!!属于 进程地址空间上的一部分地址!

cpp
pthread_t pthread_self(void);
pthread_t到底是什么类型呢?取决于实现。对于Linux目前实现的NPTL实现而言,pthread_t类型的线程ID,本质就是一个进程地址空间上的一个地址。
6.2 理解库
我们要理解"Linux 线程库 (pthread) 的加载原理 以及它在虚拟地址空间中的映射关系"。
库的制作与原理那里提过:

Linux内核没有直接的线程概念,而是给我们提供用户级的pthread库,在当前的新的ubuntu系统下:
pthread动态库:

我们主要来聊聊这个动态库,你的程序要加载到内存,形成地址空间,那么它所依赖的动态库要不要加载到内存?要的!加载到内存当中,会映射到进程的虚拟地址空间。
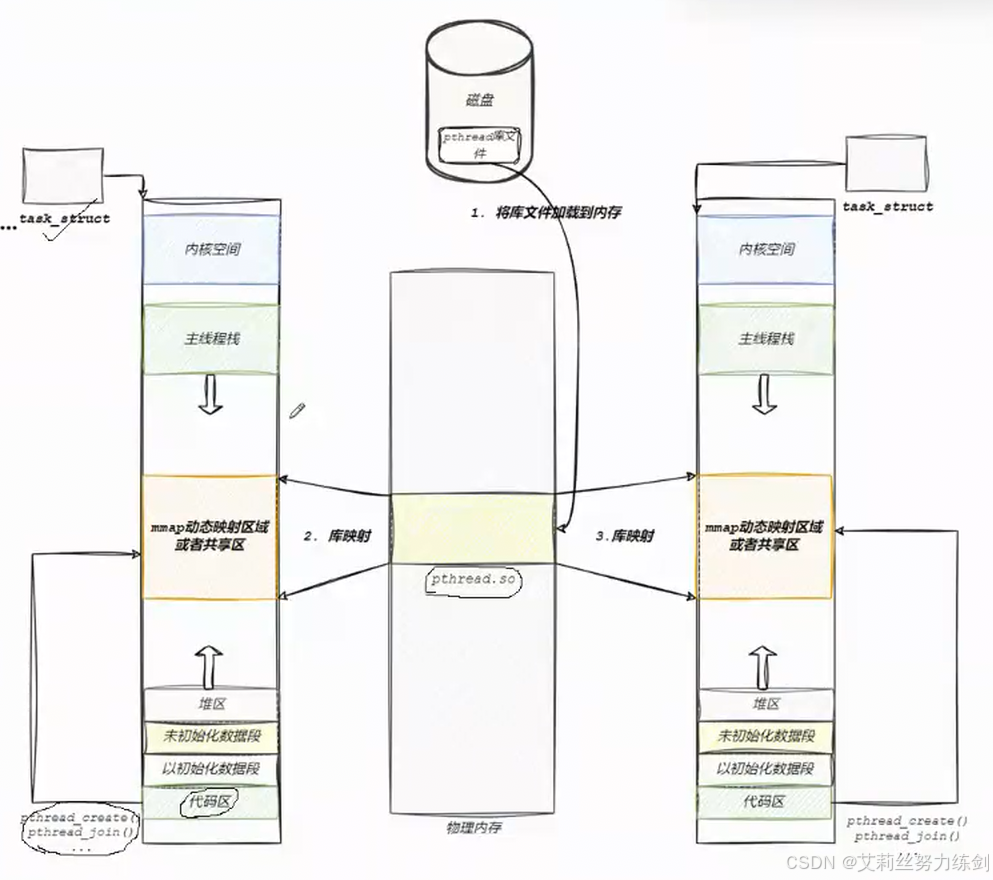
6.2.1 Linux "没有"真正的线程

6.2.2 动态库的加载与映射
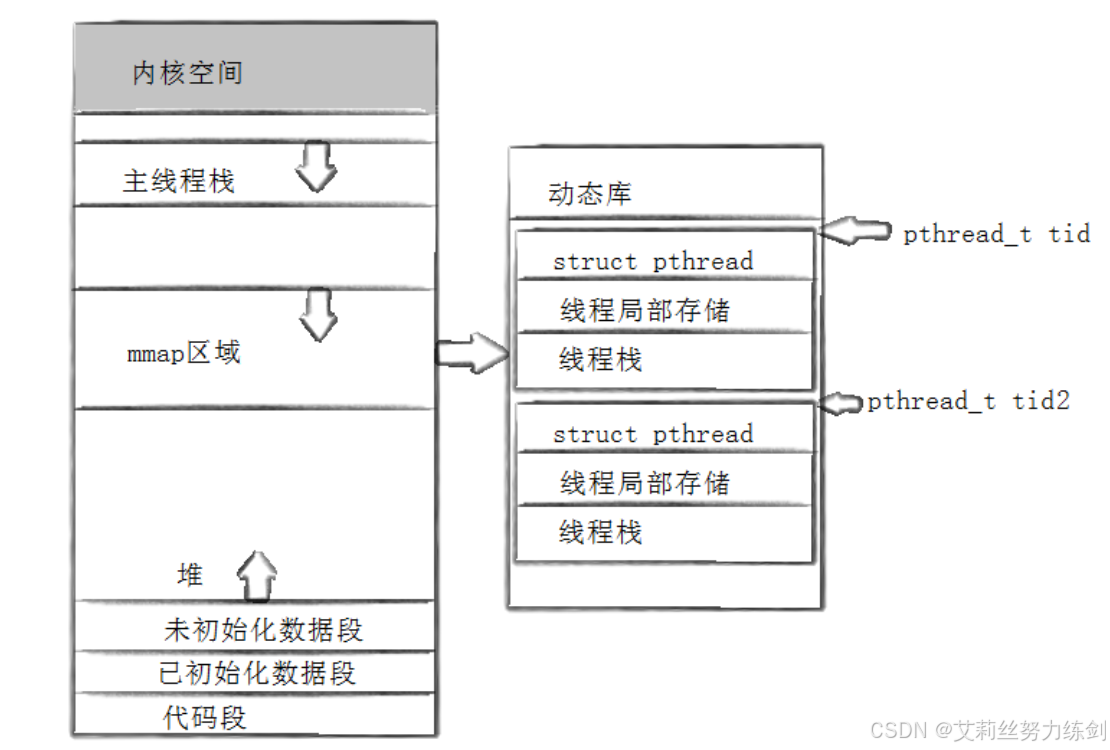
下面这张图展示了动态库是如何进入进程世界的:
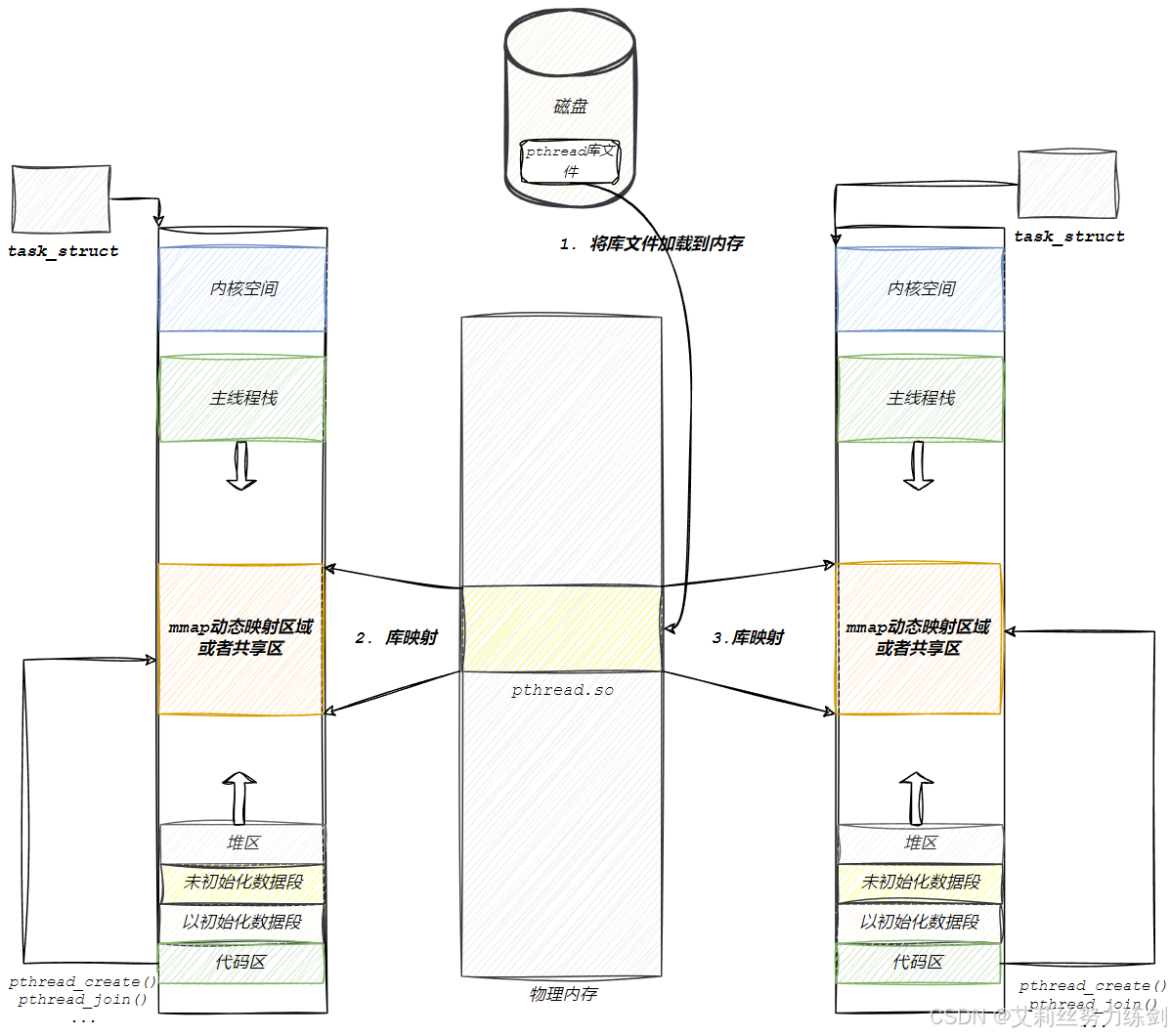
分析一下:

6.2.3 线程库与地址空间的关系
有了前面的流程图,就进一步解释了为什么 pthread_t 是一个地址:

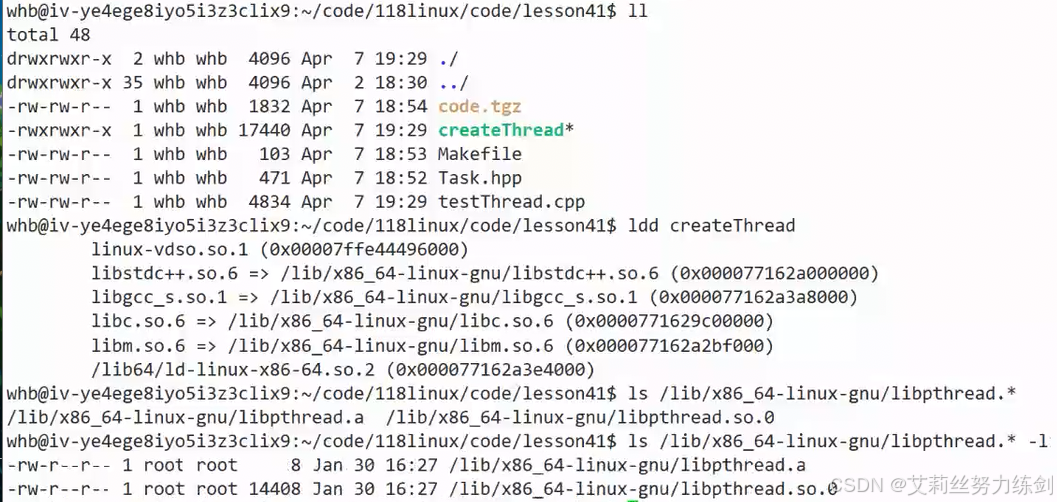
6.2.4 指令分析 (ldd 与 ls)

6.2.5 总结建议
- 线程 ID (
pthread_t) = 该线程在mmap区域中控制块的起始虚拟地址。

6.2.6 理解库:思维导图

6.3 理解"线程":用户线程
我们之前讲过内核中只有轻量级进程。然后为了方便用户的理解和使用,封装出了一个中间层,线程库。
我们的线程本身会呈现出不同的状态,库内部是不是必然要能够管理这些线程。线程要不要被管理呢?(今天这个肯定是跟OS没关系了)pthread线程库就要负责这个管理的工作,我们调的那些线程控制函数不就是在管理线程嘛。我们换个角度呢,线程要被库管理,该如何管理呢?先描述,再组织。
6.3.1 先描述:struct pthread (用户级 TCB)
那这个库中必然存在一个结构体:

我们当年学C语言的时候,我们平常使用malloc要告诉多少个字节,但是free的时候不需要告诉有多少个!还有C++标准库,我们的一些容器,vector、链表、哈希、......,每一种容器都是"先描述再组织",可以在库内部做管理。
除了这些结构,我们还提供了很多方法,在库里面做操作。
校外和校内,两个"我",两个人合起来才是我------
- 内核LWP和pthread合起来就是完整的线程概念,用户级的就是pthread库的。
- 内核提供流,上层提供描述结构体。
外面人看来就是由库通过了一个线程描述结构体。
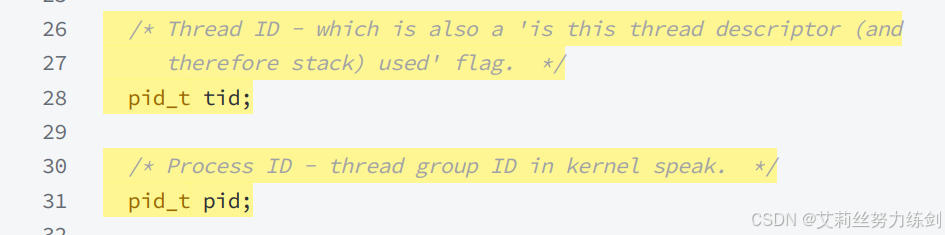
描述线程的结构体的起始地址就叫做线程ID。
目前我们理解得出的结论:在库内部,描述对应线程thread结构体变量的对应的起始地址就是线程ID。
我们当年学C语言的时候,我们平常使用malloc要告诉多少个字节,但是free的时候不需要告诉有多少个。还有cpp标准库,我们的一些容器。都是可以在库内部做管理工作的。
我们除了这些结构不还提供了很多方法嘛,在库里进行操作。内核LWP和pthread合起来就是完整的线程概念,用户级的就是pthread库的。内核提供给pthread库,然后对外面向用户。
我们一般把描述线程的结构体的起始地址叫做线程ID。
结论:线程ID本质是在库内部,描述对应线程thread结构体的起始地址!

6.3.2 再组织:内存中的"数组"与地址
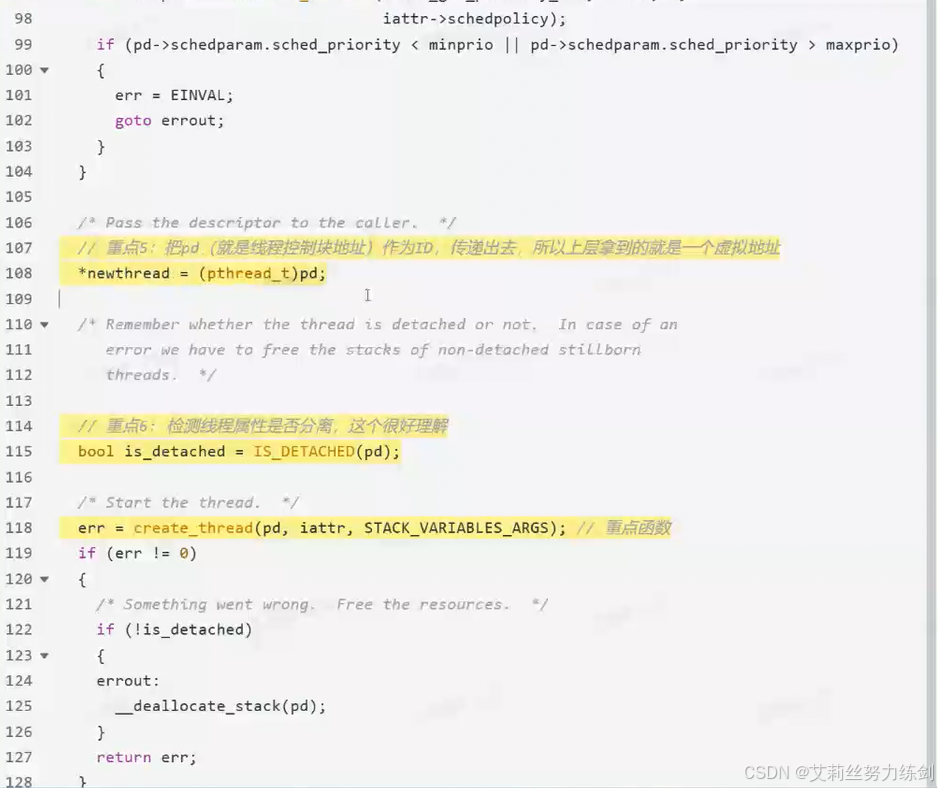
- pthread库是以
MMAP的方式映射的
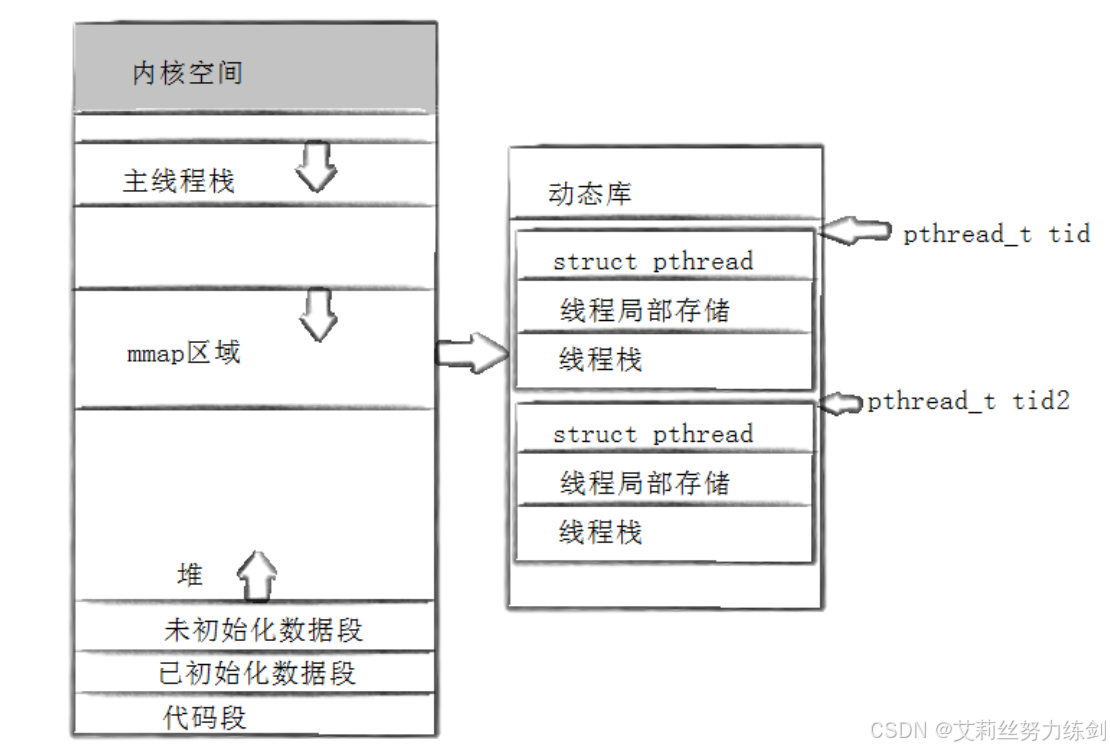
描述我们大致已经知道了,那么组织呢?只有这一个结构体吗?

6.3.3 线程 ID 的本质:一个"索引指针"
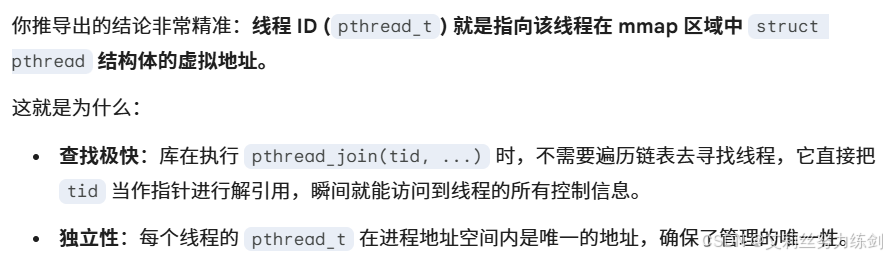
6.3.4 完整的线程 = 用户库描述 + 内核 LWP 调度

6.3.5 总结

6.3.6 "线程"思维导图
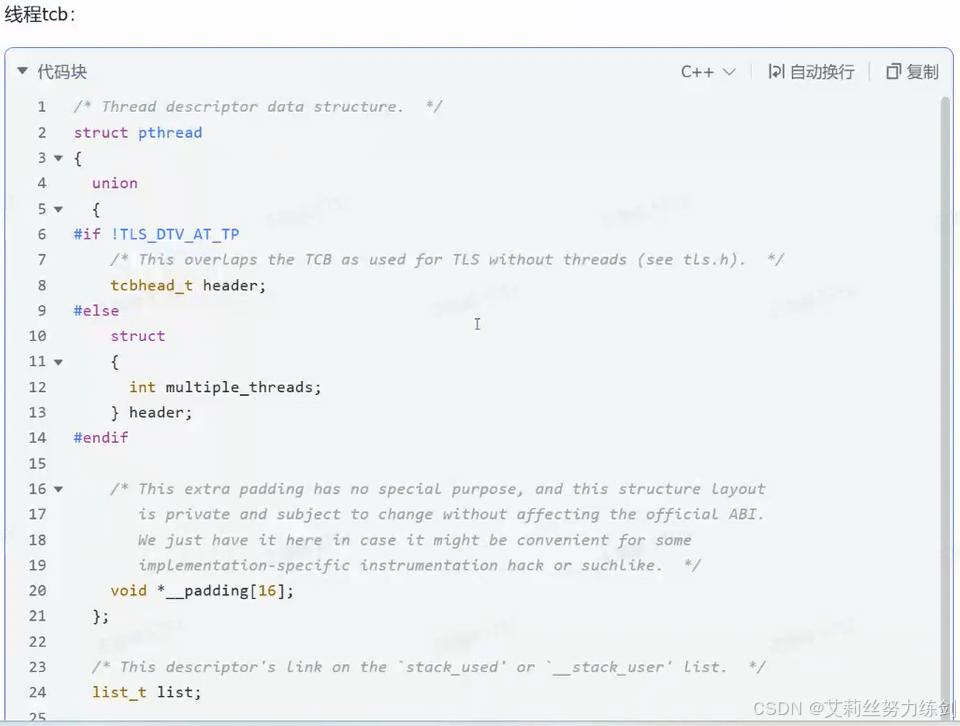
6.4 查看源码:glibc源码
库当中描述线程的结构体:
线程所属进程的PID:
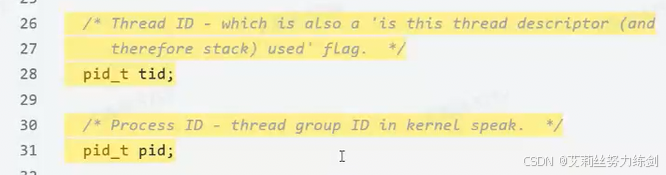
tid是LWP。

pthread_join在干什么?
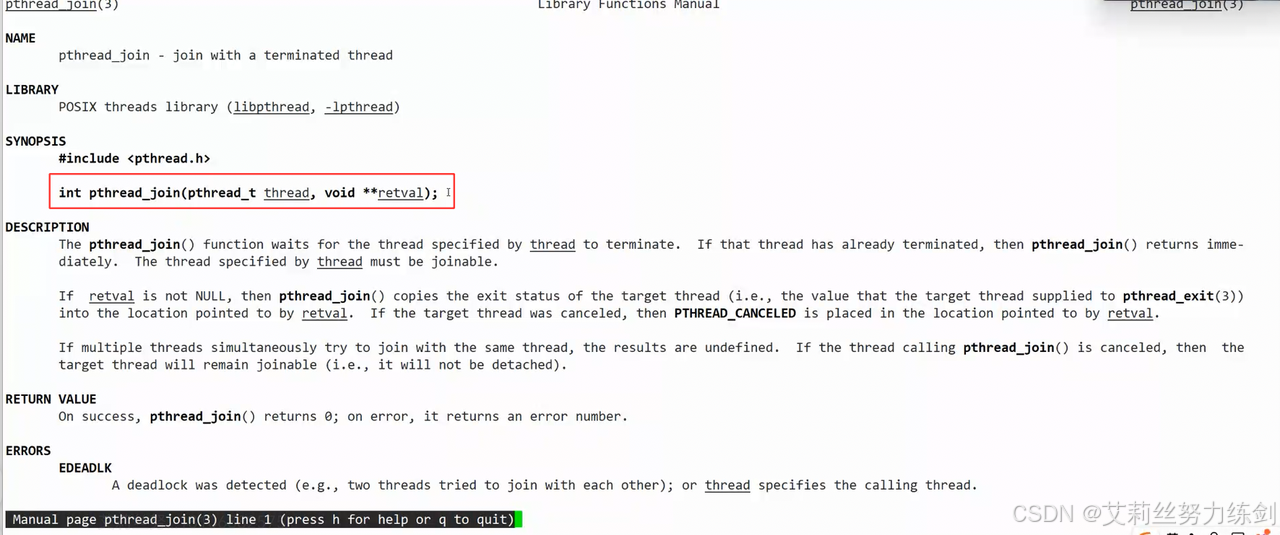
pthread_join就是拿着起始虚拟地址,然后拿到result拷贝给用户。
回调方法:

主要是为了观察对内核中轻量级进程封装的过程,我们一会儿搓一点,不要求完全了如指掌。
pthread_create里面的参数:
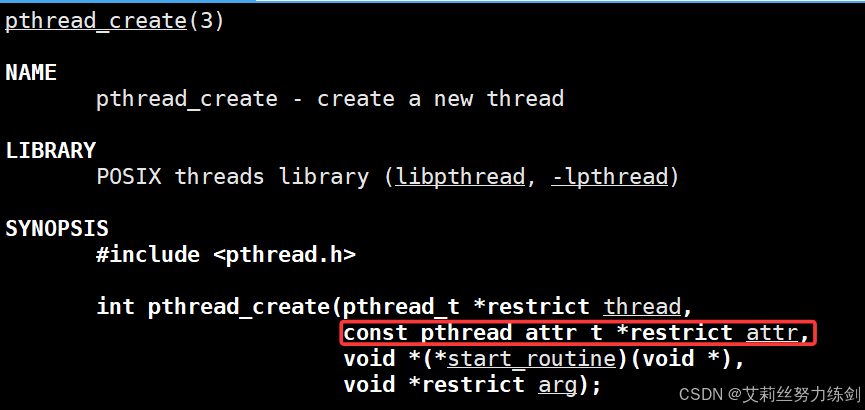
线程属性:
cpp
struct pthread_attr
{
/* Scheduler parameters and priority. */
struct sched_param schedparam;
int schedpolicy;
/* Various flags like detachstate, scope, etc. */
int flags;
/* Size of guard area. */
size_t guardsize;
/* Stack handling. */
void *stackaddr;
size_t stacksize;
/* Affinity map. */
cpu_set_t *cpuset;
size_t cpusetsize;
};描述该线程的控制块的结构体的地址。

线程tcb:
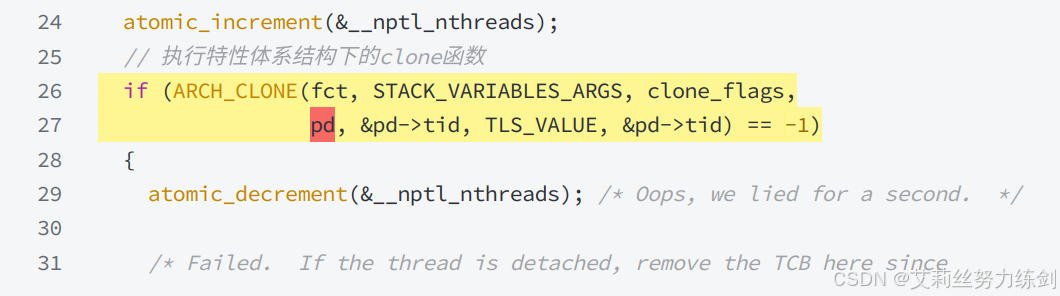
create_thread:
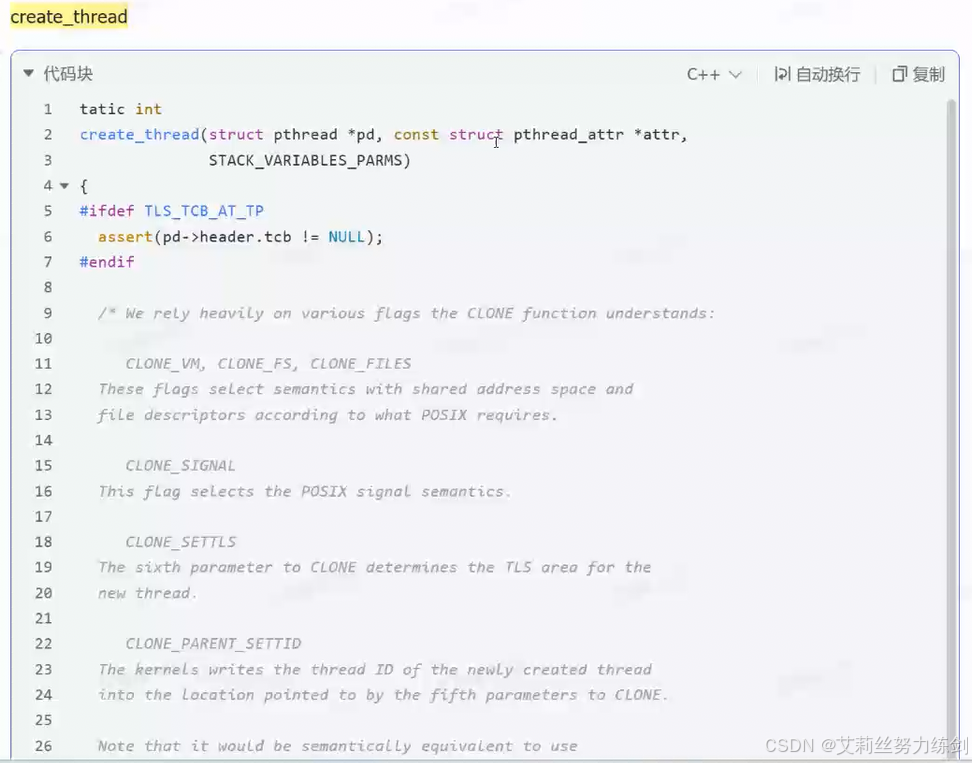
在底层调用了do_clone:

看一下源码:
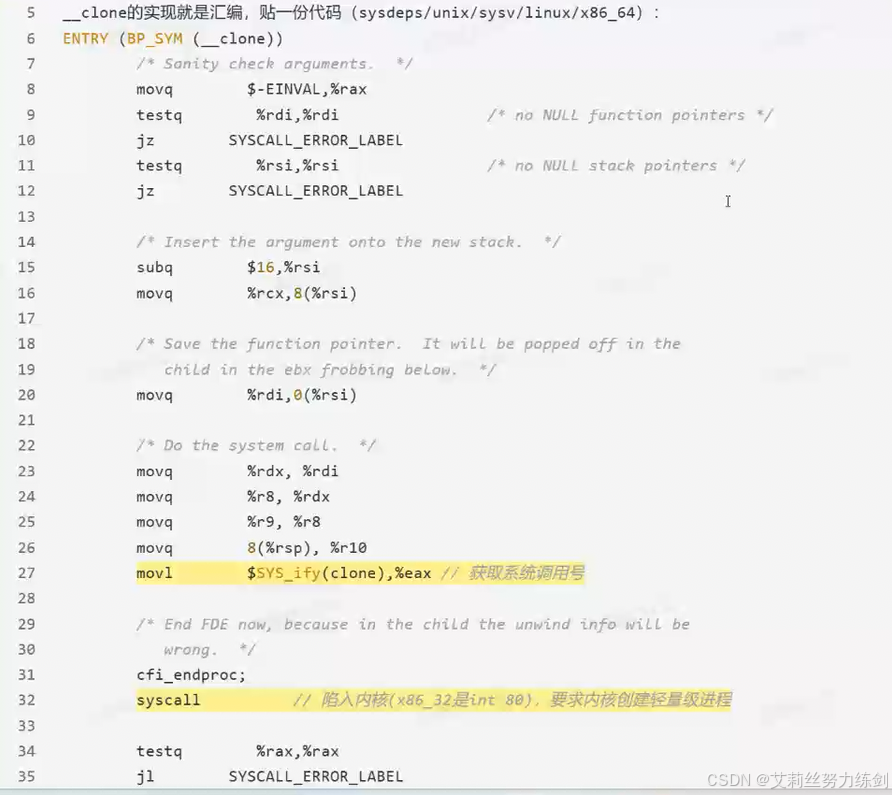
等价于直接调用clone:

6.4.1 申请空间:allocate_stack(创建struct结构体,填充字段)
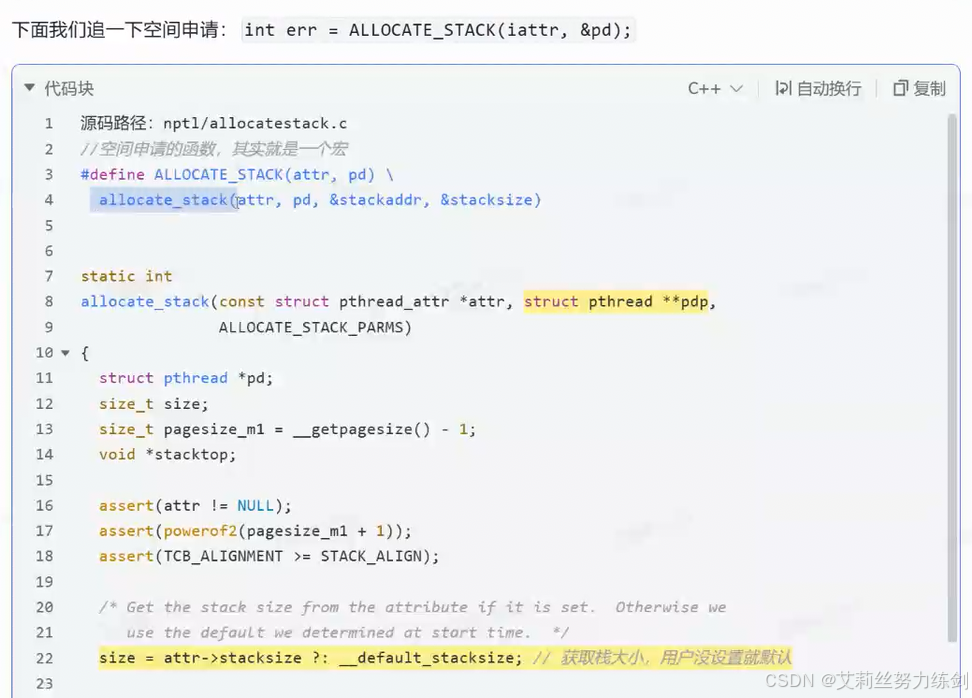
地址空间上重新mmap申请一份空间。
总结:


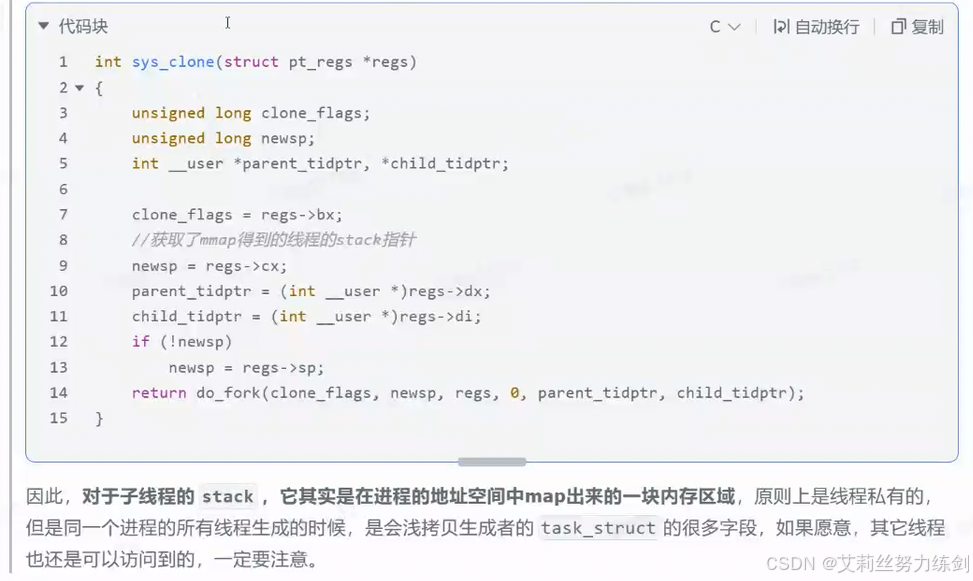
6.5 线程栈

cpp
mem = mmap (NULL, size, prot,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_STACK, -1, 0); 
使用mmap系统调用就可以申请空间。
6.5.1 Linux线程栈

6.5.2 内存布局对比图

6.5.3 一句话理解
主线程栈是内核的"亲儿子",有特权可以动态变大;子线程栈是 glibc 找内核"租"来的固定地皮,用完就没,且本质上大家都在一个大院里(地址空间共享)。
pthread库本质就是对系统调用库的封装,描述线程的相关结构体信息是在库当中的,tid本质就是一个地址。
6.6 线程局部存储
6.6.1 是什么?
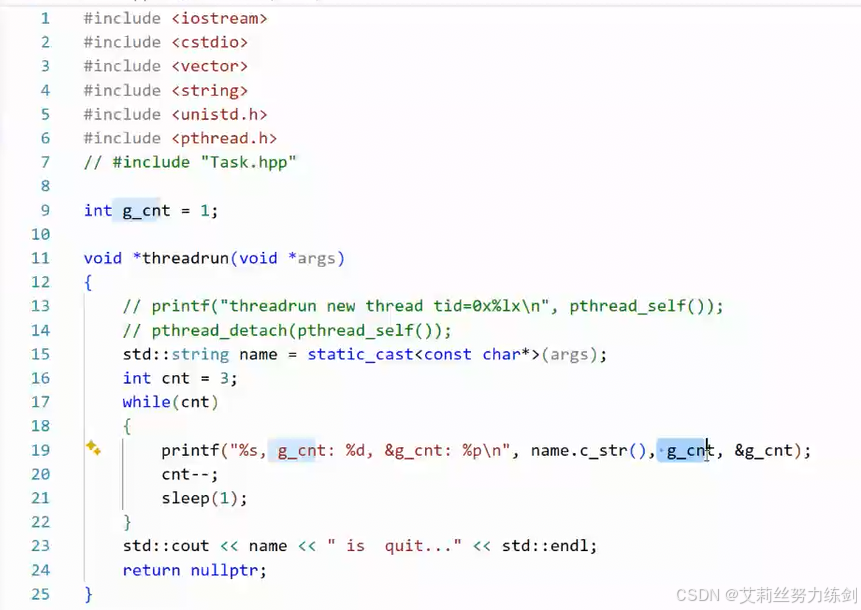
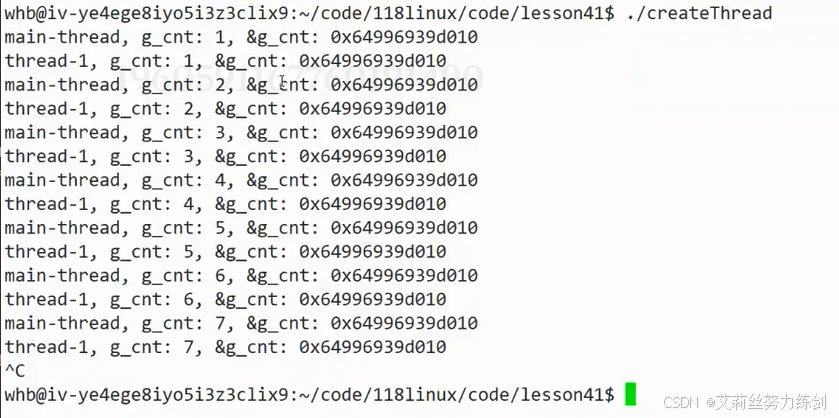
我把cnt改成true:
编译:
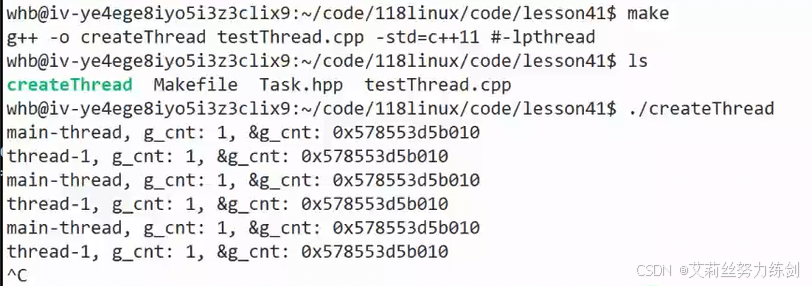
共享这个全局变量,你修改我也可以看到,变量地址也是一样的,肯定是同一个。
再改一下:

运行:
再改:
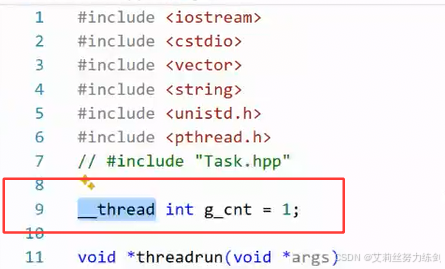
告诉编译器,局部存储的形式。
这种变量就是线程局部存储。
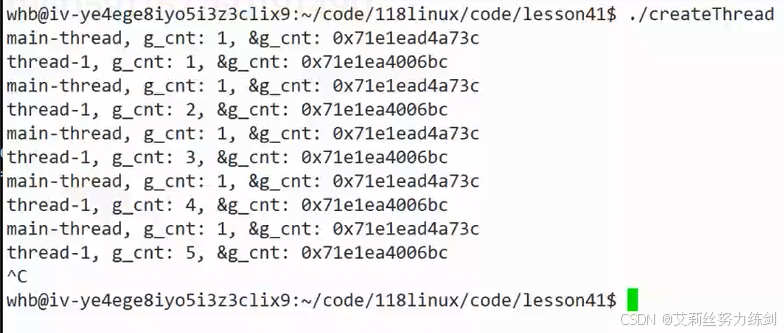
这个互不影响了,变量也不一样了,只是在编码上用了同一个名字。
6.6.2 有什么用?
要获取线程的LWP(轻量级进程),得自己封装一个系统调用;当然,也可以传递系统调用号在底层进行系统调用那一套流程:
自己封装一个系统调用:
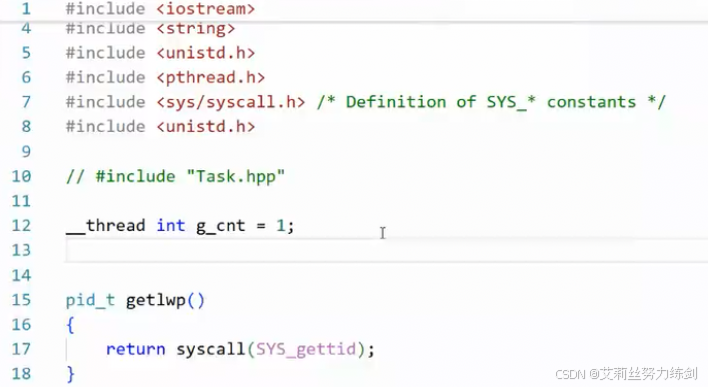
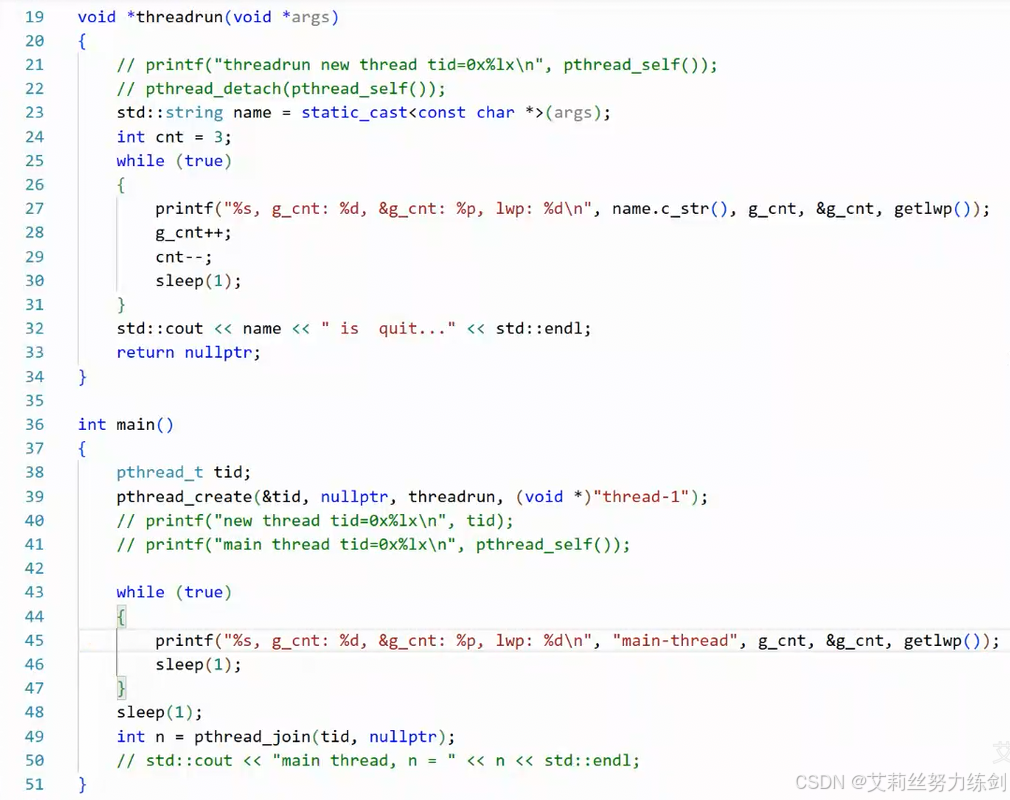
通过系统调用号来调用系统调用(转到定义可以查看):
编译运行:
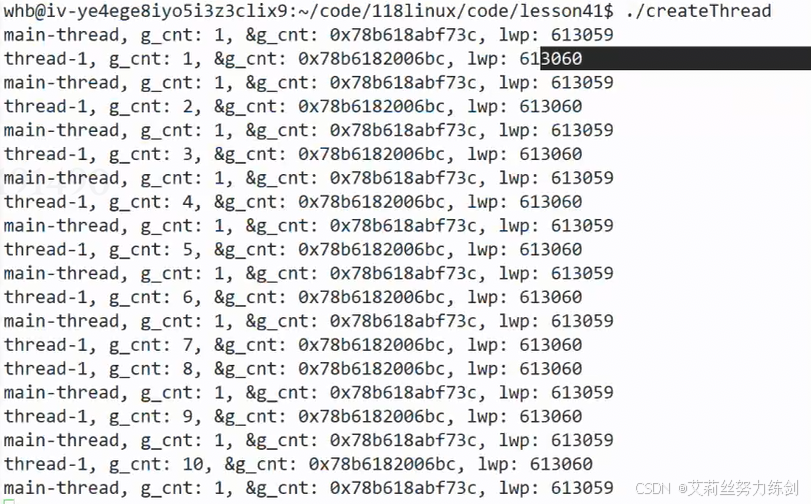
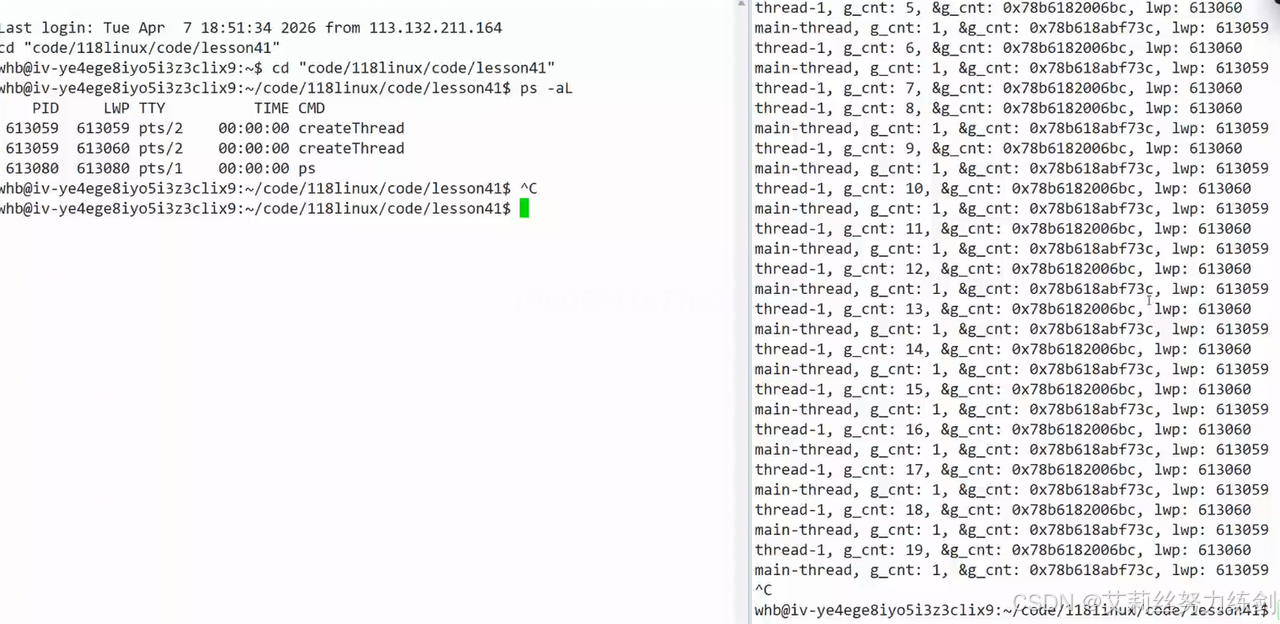
不可能一直调用系统调用------太麻烦了,像这样再也不用系统调用了,直接调用系统调用号就行:

编译运行:
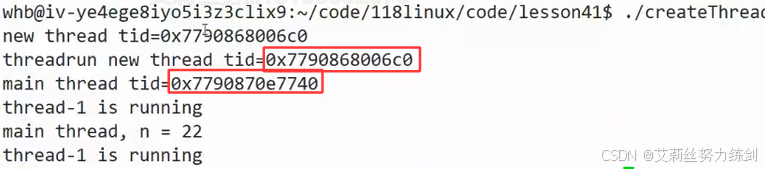
- 两个id打印出来是不一样的。

基本上只能用来存储一些简单类型。

pthread库:对系统调用做封装。
7 ~> 线程封装
pthread 库在用户空间的管理逻辑(先描述,再组织),那么"线程封装"本质上就是将 C 风格的库接口,进一步升华为 C++ 面向对象。
我将这份线程封装的逻辑整理为以下三个核心板块,不仅是代码的堆砌,更是对 "如何优雅地管理线程生命周期" 的深度思考。
7.1 为什么要封装?

7.2 封装的核心技术挑战

7.3 从"用户对象"到"库地址空间"再到"内核 LWP"的完整链路
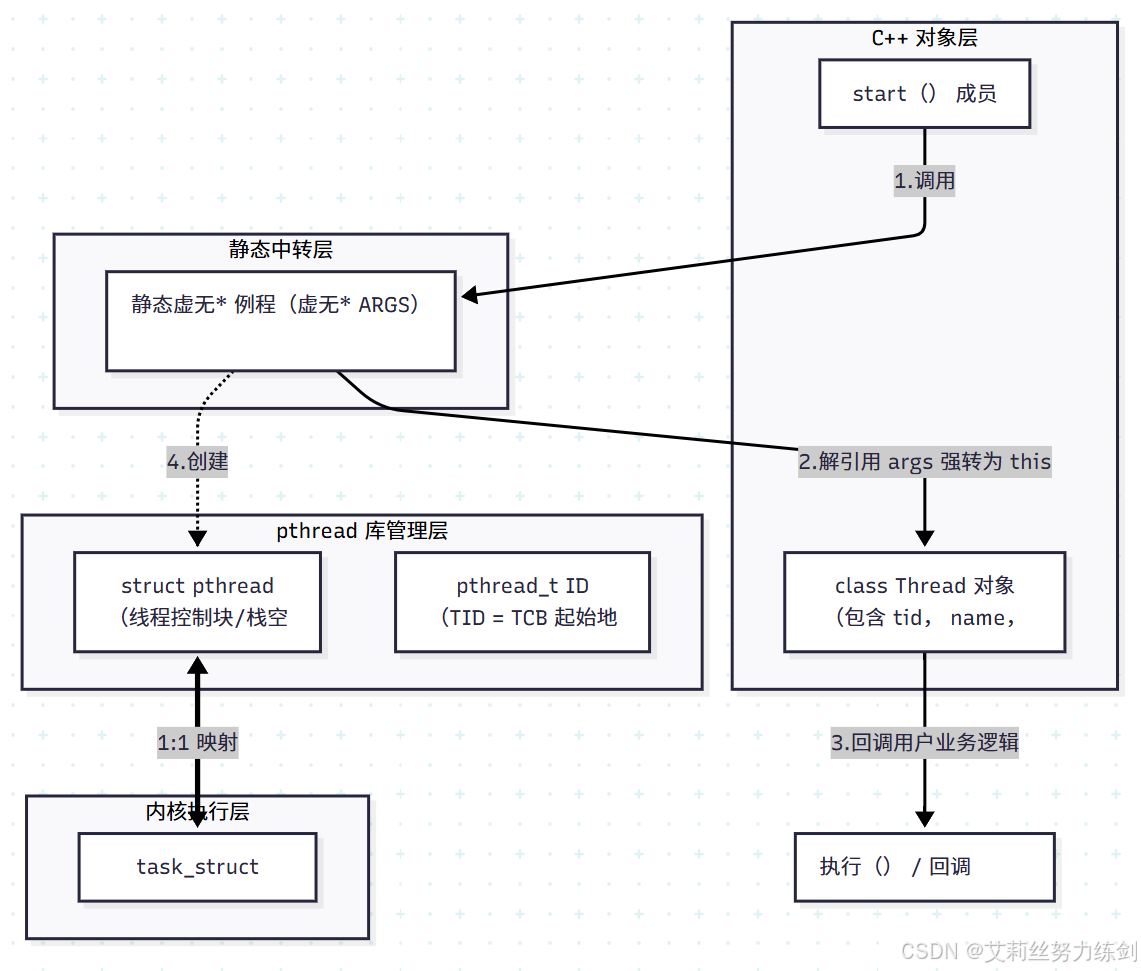
7.4 封装代码的逻辑精髓(核心逻辑实现)
cpp
class Thread {
public:
typedef void (*callback_t)(int); // 用户业务逻辑
Thread(callback_t func, int data)
: func_(func), data_(data), tid_(0) {}
// 1. 核心启动接口
void start() {
// 将 this 指针作为 void* args 传进去
pthread_create(&tid_, nullptr, routine, this);
}
void join() {
pthread_join(tid_, nullptr);
}
private:
// 2. 静态包装器:解决 C/C++ 兼容性
static void* routine(void* args) {
// 静态函数拿回 this 指针,重返面向对象世界
Thread* self = static_cast<Thread*>(args);
self->run();
return nullptr;
}
void run() {
func_(data_); // 执行真正的用户逻辑
}
pthread_t tid_;
callback_t func_;
int data_;
};7.5 知识点的闭环

7.6 回顾线程封装
7.6.1 如何把线程创建面向对象化?
封装的本质:把线程创建面向对象化。
模块和模块之间解耦,艾莉丝习惯用lambda。
使用C++11的多线程:
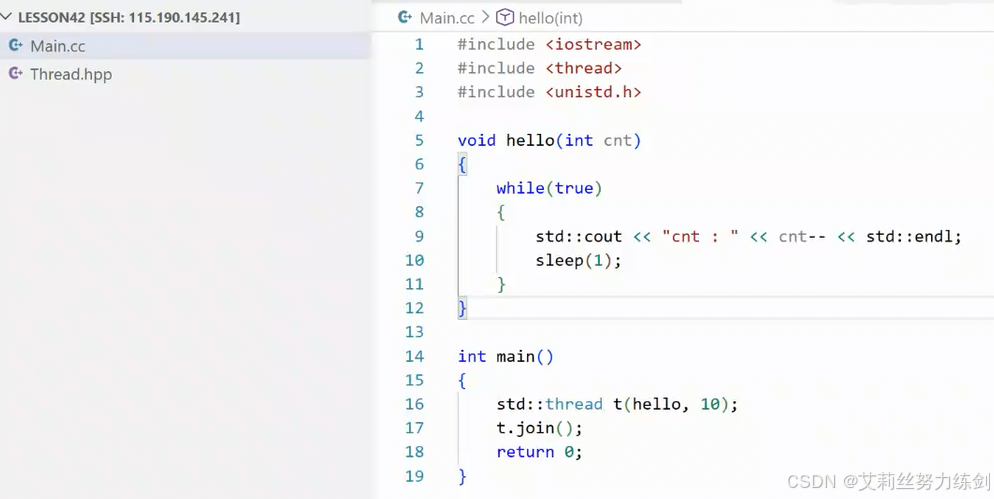
线程控制非常简单。
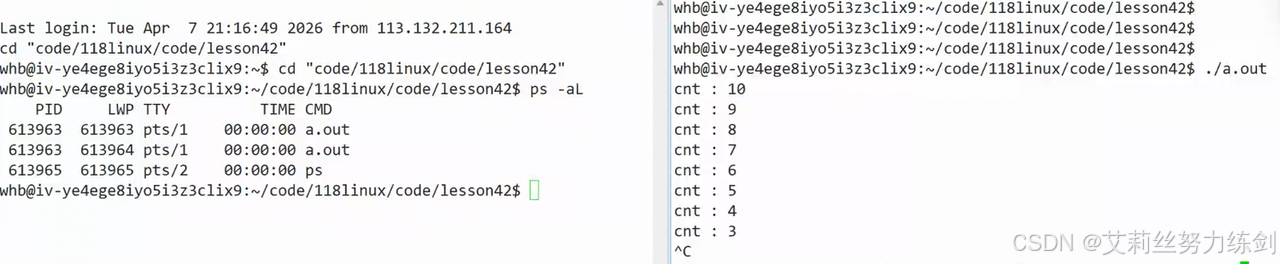
编译器等级很高,支持高级语法,不需要带-std。
语言级别都已经表现出了很强的跨平台性------创建线程的接口,都是LWP。
7.6.2 线程启动
- 用
_区分类内和类外
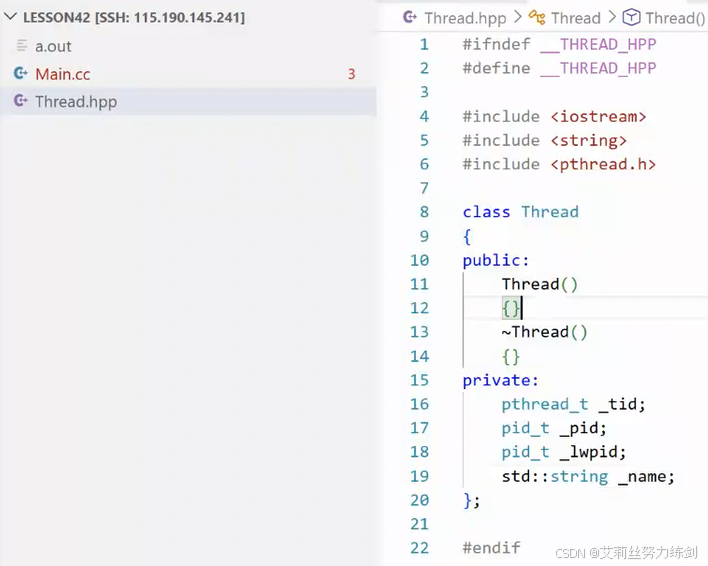
有bug:

创建出线程:
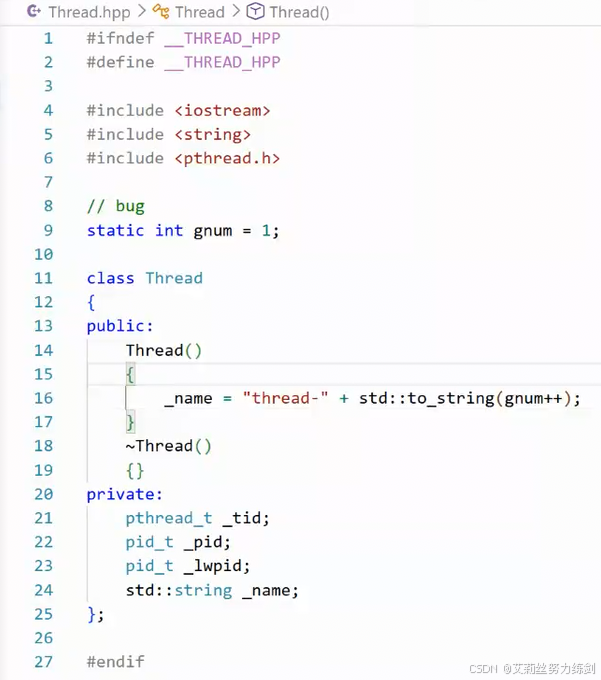
未来想让线程执行什么任务?C++有lambda表达式了------通过lambda,任意函数的参数也可以自定义。
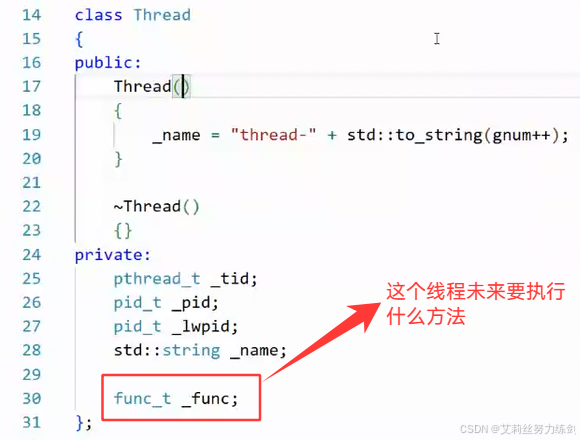
并没有在内核中创建轻量级进程:
- 只是创建了一个自己定义的线程对象
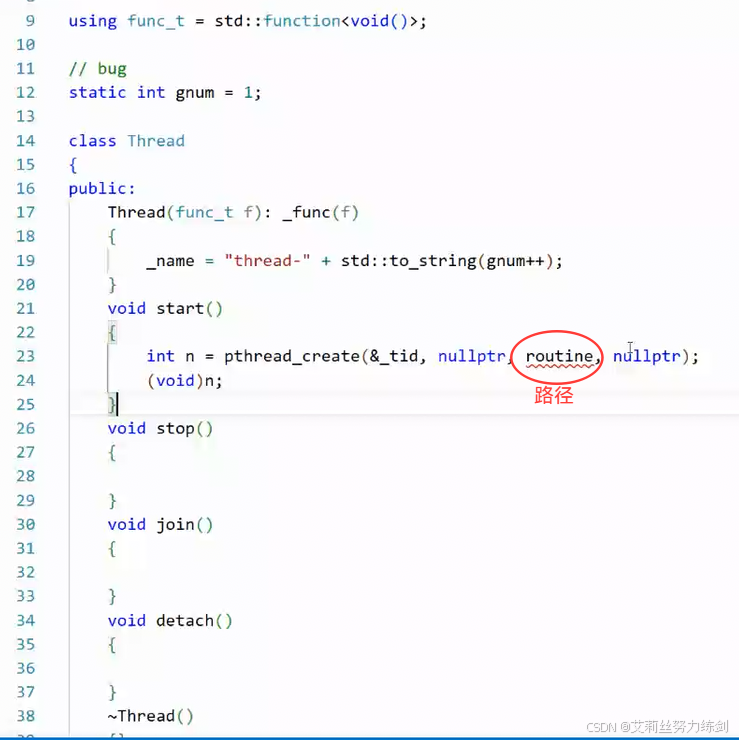
不想把routine暴露在外部:
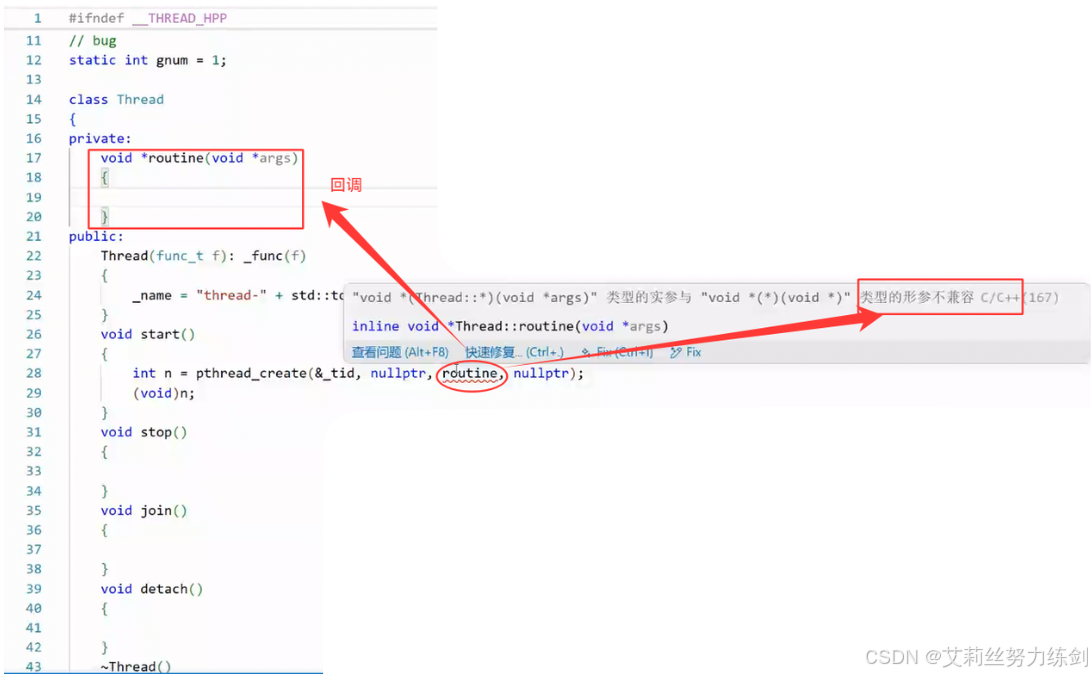
成员函数默认携带有this指针参数------类型不匹配。
- 把函数扔到类外:使用麻烦;
- 加static,没有this指针
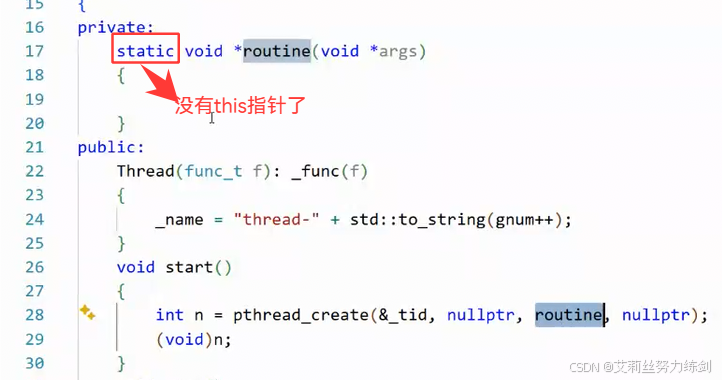
没有this指针,没法直接访问类内。

把线程获取私有化:
系统调用号:
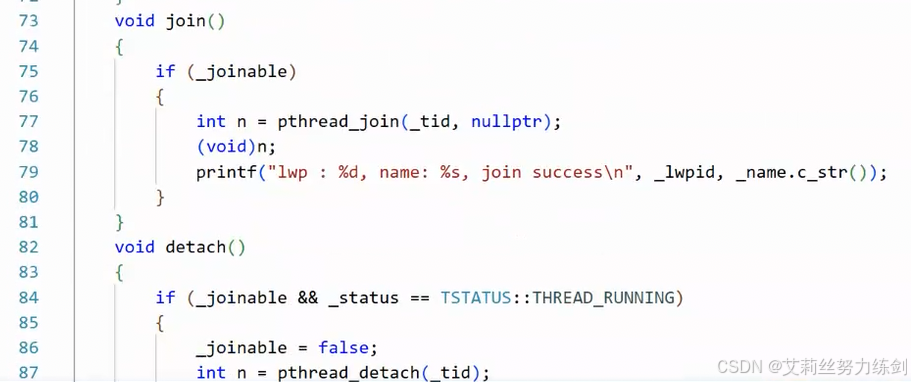
Join
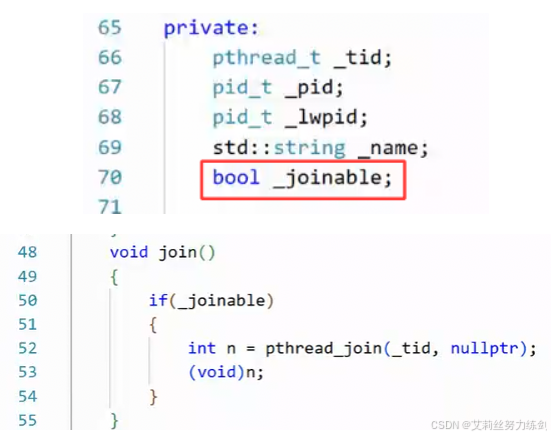
- 不要
joinable,返回值做分离
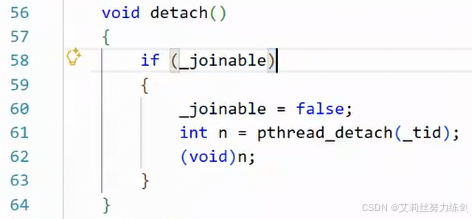
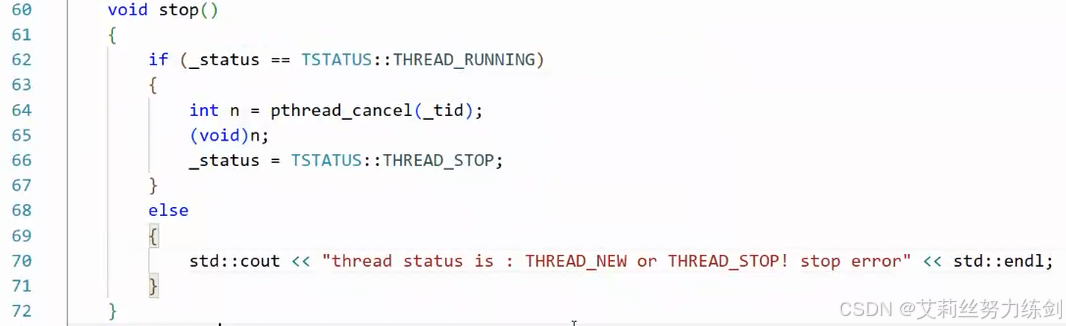
- stop终止线程
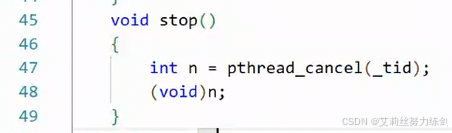
死循环,永远不退出!
以面向对象的方式对线程进行封装:
怎么调用回调方法呢?
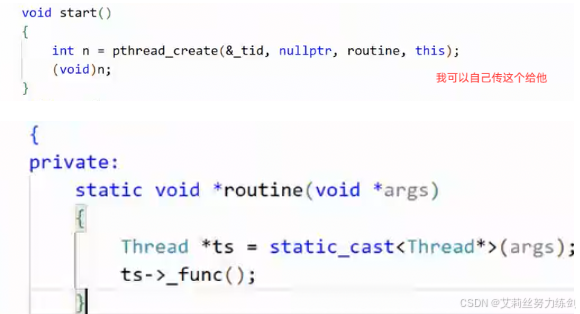
创建好线程不代表已经启动线程了,得调用start。
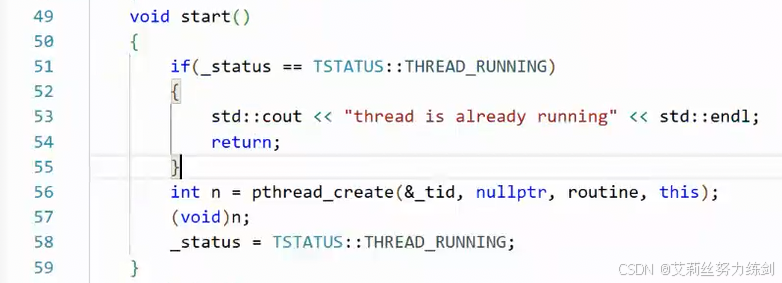
7.6.3 线程状态
枚举设置了三种线程状态:
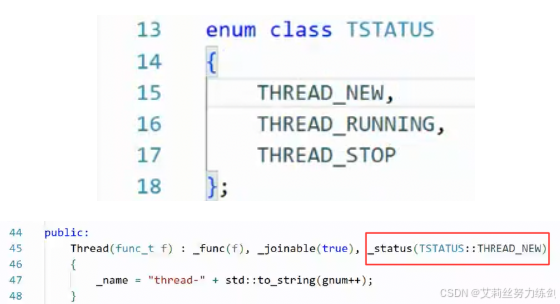
start()
stop()
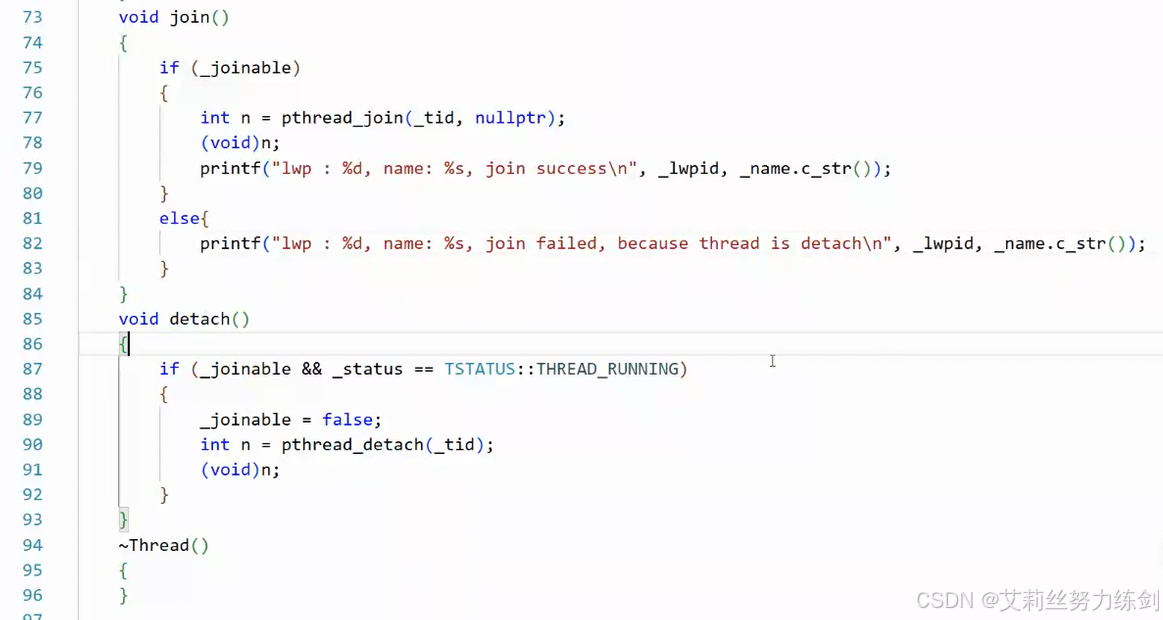
join和detach
一个线程要分离的话,必须还得是RUNNING状态。
重复启动一下:
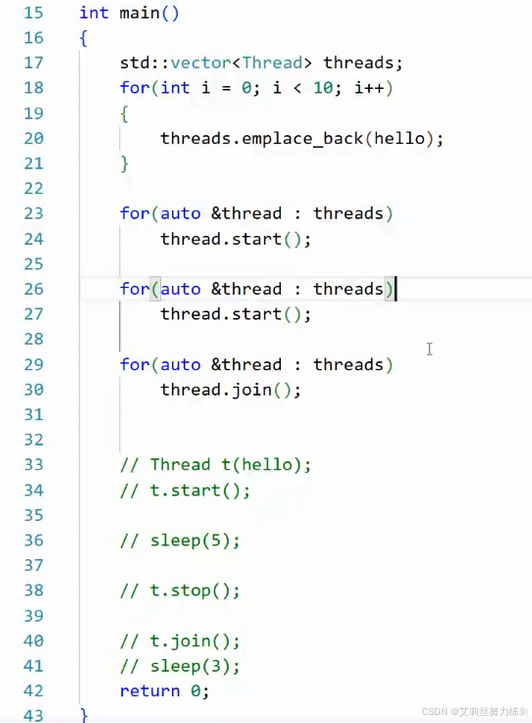
运行:
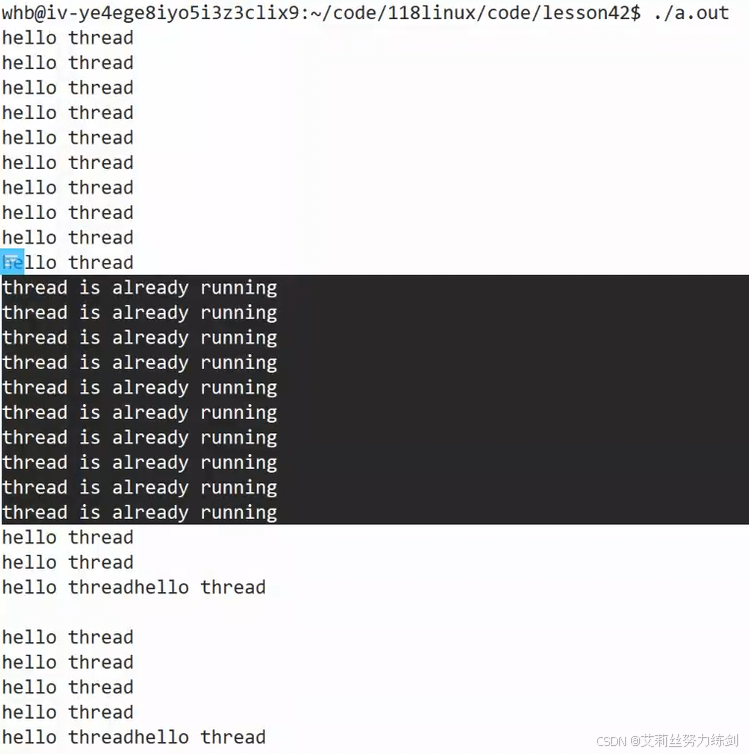
我可以再干一件事情:
线程分离了再join没有意义------相当于报错了:
加一下sleep,不要让主线程退得太快:
运行一下:
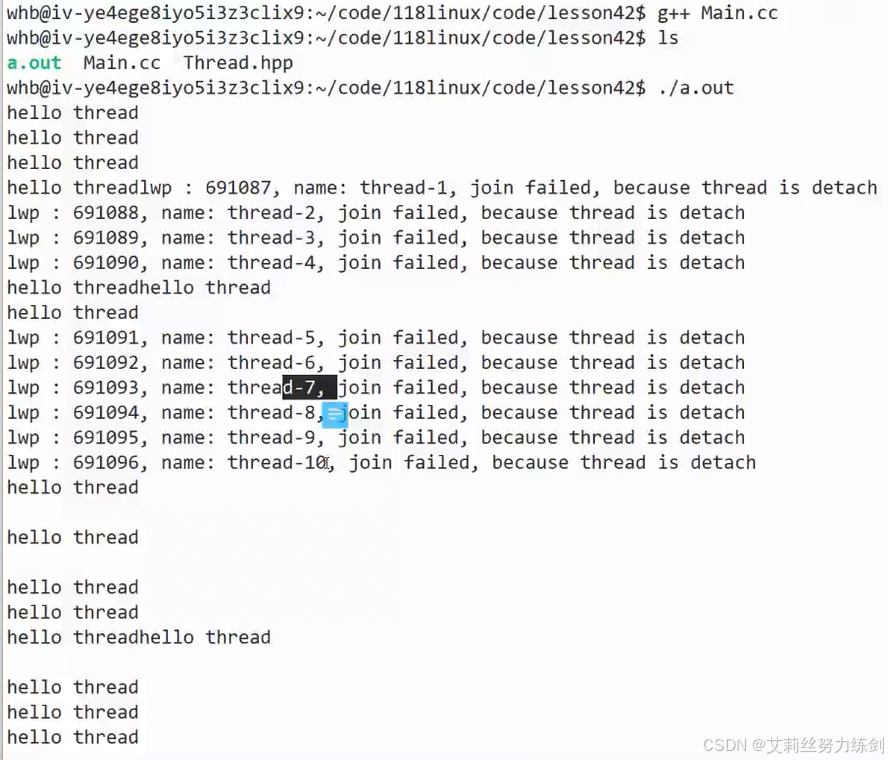
两组消息打印出现了混乱,我们一会儿看一下。
7.6.4 正常使用的流程
改成倒计时5秒,线程跑5秒钟:
- 预期的现象:一批线程创建出来,一批线程被join
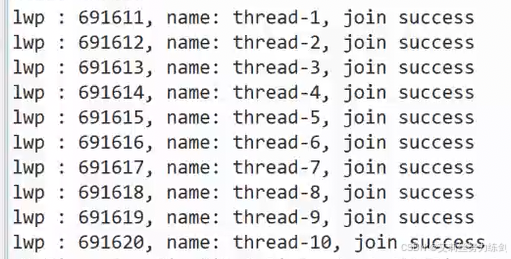
- 线程封装,参数模版化
7.6.5 优化:获取线程的名字
Linux 环境下如何使用 pthread_setname_np 和 pthread_getname_np 来管理线程名称。
这在多线程调试(如使用 top -H 或 gdb)时非常有用。
我想要知道线程的名字------
库函数:
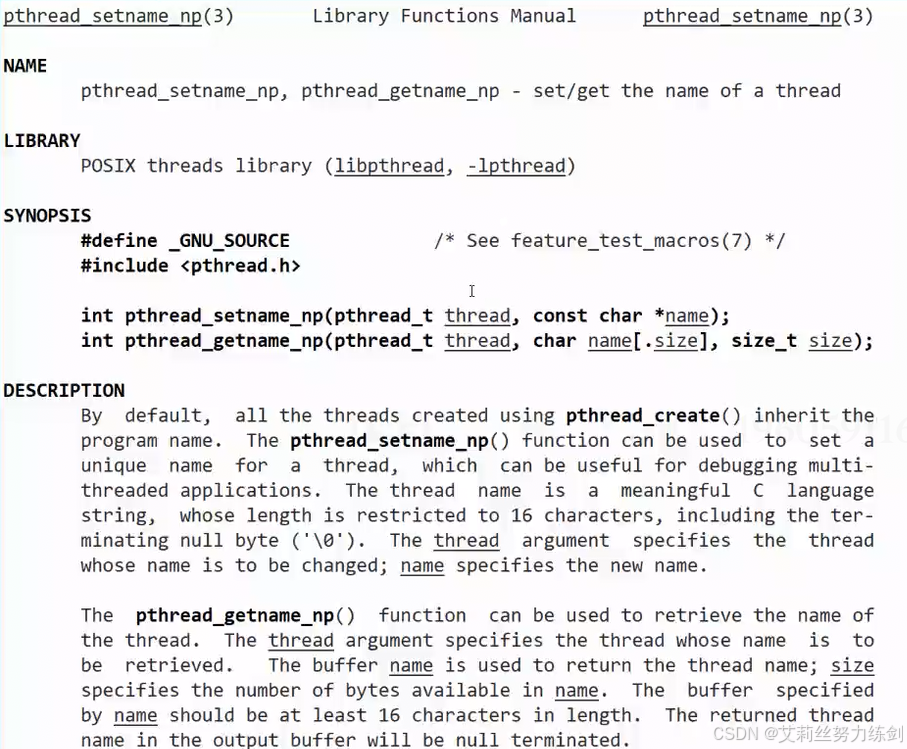
可以跨函数来调用。
7.6.5.1 函数原型与基础
这两个函数属于 POSIX 线程库的非标准扩展 (这就是为什么名字后面带 _np,即 non-portable)。
c
#define _GNU_SOURCE /* 必须定义这个宏才能使用 */
#include <pthread.h>
// 设置线程名称
int pthread_setname_np(pthread_t thread, const char *name);
// 获取线程名称
int pthread_getname_np(pthread_t thread, char *name, size_t len);关键约束
-
长度限制 :线程名称(包括终止符
\0)不能超过 16 个字符 。如果传入的字符串太长,函数会返回错误(通常是ERANGE)。 -
线程引用 :可以通过
pthread_self()给当前线程改名,也可以通过保存好的pthread_t标识符给其他线程改名。
7.6.5.2 核心代码逻辑分析
7.6.5.2.1 写入名称(生产者端)
在你的 Thread 类封装中,通常在线程的入口函数(routine)内进行设置:
c
static void *routine(void *args) {
Thread *ts = static_cast<Thread *>(args);
// 在线程启动的第一时间,为自己命名
pthread_setname_np(pthread_self(), ts->_name.c_str());
ts->_func(); // 执行用户回调
return nullptr;
}7.6.5.2.2 读取名称(消费者/观察端)
在任务函数内部,可以通过 pthread_getname_np 获取当前线程的名字,增加日志的可读性:
c
void hello() {
char name[64];
pthread_getname_np(pthread_self(), name, sizeof(name));
// 输出:hello thread: thread-1
std::cout << "hello thread: " << name << std::endl;
}7.6.5.3 为什么需要这两个函数?
在实际开发中,如果程序崩溃或卡死,仅仅看到 PID 是不够的。
调试利器:
-
在终端输入
top -H -p [PID],你可以直接看到各个线程的名字,一眼看出哪个线程占用了过高 CPU。 -
在
gdb中,输入info threads可以直接看到线程名,而不是一堆冷冰冰的数字 ID。
日志分明:
- 多线程共用标准输出时,日志往往是交织的。通过在日志模板里加入线程名,可以快速过滤出特定业务逻辑的执行流。
7.6.5.4 深度补充:底层原理与替代方案
7.6.5.4.1 底层路径
Linux 内核实际上通过 /proc/self/task/[tid]/comm 文件来存储线程名。pthread_setname_np 本质上是封装了对这个内核接口的写入。
7.6.5.4.2 替代方案:prctl
除了 pthread 库的函数,Linux 还提供了 prctl 系统调用,它只能操作当前线程:
c
#include <sys/prctl.h>
// 设置当前线程名
prctl(PR_SET_NAME, "my_thread_name");7.6.5.5 注意事项
-
线程安全 :
pthread_getname_np是线程安全的,但提供的缓冲区name必须足够大(建议固定 16 或以上)。 -
C++11 兼容性 :原生的
std::thread并没有提供设置名字的成员函数。如果你使用std::thread,依然需要调用native_handle()获取底层pthread_t来设置:
c
std::thread t1(func);
pthread_setname_np(t1.native_handle(), "worker_t");7.6.5.6 总结表

结尾
uu们,本文的内容到这里就全部结束了,艾莉丝在这里再次感谢您的阅读!
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| ### 艾莉丝努力练剑 C/C++ & Linux 底层探索者 | 一个正在努力练剑的技术博主 *** ** * ** *** 👀 【关注】 跟随我一起深耕技术领域,见证每一次成长。 ❤️ 【点赞】 让优质内容被更多人看见,让知识传递更有力量。 ⭐ 【收藏】 把核心知识点存好,在需要时随时查、随时用。 💬 【评论】 分享你的经验或疑问,评论区一起交流避坑! 不要忘记给博主"一键四连"哦! "今日练剑达成!"  "技术之路难免有困惑,但同行的人会让前进更有方向。" |
"技术之路难免有困惑,但同行的人会让前进更有方向。" |
结语:希望对学习Linux相关内容的uu有所帮助,不要忘记给博主"一键四连"哦!
往期回顾:
【Linux线程】Linux系统多线程(三):Linux线程 VS 进程,线程控制
🗡博主在这里放了一只小狗,大家看完了摸摸小狗放松一下吧!🗡 ૮₍ ˶ ˊ ᴥ ˋ˶₎ა
