目录
1.摘要
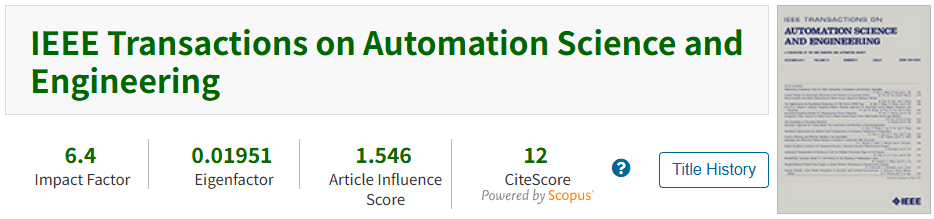
针对多无人机在面临突发危险区域时路径规划的安全性和不确定性挑战,本文提出了一种基于多智能体强化学习(MARL)解决方案,该方案通过引入控制障碍函数保障了系统在突发变道时的快速响应与安全重规划,并结合概率神经网络量化危险的不确定性,提升了对突发威胁的预判能力,从而弥补纯反应式安全的效率短板。同时,该模型利用基于距离加权的平均场机制整合邻近无人机的观测信息,充分发挥集群智能以实现协同避让。
2.面向多无人机路径规划的分布式部分可观测马尔可夫决策过程
环境描述
随机危险环境下的多无人机三维路径规划在满足避障与安全距离约束的前提下,最小化无碰撞路径的总长度。系统采用离散时间模型描述无人机的运动学状态,其位置与速度的更新过程为:
p u , i k + 1 = p u , i k + v u , i k τ , v u , i k + 1 = v u , i k + a u , i k τ p_{u,i}^{k+1} = p_{u,i}^{k} + v_{u,i}^{k} \tau, \quad v_{u,i}^{k+1} = v_{u,i}^{k} + a_{u,i}^{k} \tau pu,ik+1=pu,ik+vu,ikτ,vu,ik+1=vu,ik+au,ikτ
环境中随机生成且形状任意的危险区域通过K-means聚类被近似建模为多个重叠球体,这些球体的半径随时间呈高斯分布动态扩张:
ρ j , m k + 1 = ρ j , m k + Δ ρ j , m k , Δ ρ j , m k ∼ N ( μ j , m , σ j , m 2 ) \rho_{j,m}^{k+1} = \rho_{j,m}^{k} + \Delta \rho_{j,m}^{k}, \quad \Delta \rho_{j,m}^{k} \sim \mathcal{N}(\mu_{j,m}, \sigma_{j,m}^2) ρj,mk+1=ρj,mk+Δρj,mk,Δρj,mk∼N(μj,m,σj,m2)
在局部感知方面,每架无人机的观测向量整合了自身状态以及最近邻的局部感知信息:
z i k = ( p u , i k , v u , i k , { p u , j k , v u , j k } j ∈ G i , { p j , m k , v j , m k } m ∈ M i ) z_i^{k} = \left( p_{u,i}^{k}, v_{u,i}^{k}, \{ p_{u,j}^{k}, v_{u,j}^{k} \}{j \in G_i}, \{ p{j,m}^{k}, v_{j,m}^{k} \}_{m \in M_i} \right) zik=(pu,ik,vu,ik,{pu,jk,vu,jk}j∈Gi,{pj,mk,vj,mk}m∈Mi)
CBF约束下的动作过滤
每架无人机的动作向量由航向、俯仰和横滚的角速度构成:
x i k = ( ω ψ , i k , ω θ , i k , ω ϕ , i k ) \boldsymbol{x}i^{k} = (\omega{\psi,i}^{k}, \omega_{\theta,i}^{k}, \omega_{\phi,i}^{k}) xik=(ωψ,ik,ωθ,ik,ωϕ,ik)
系统引入了控制障碍函数(CBF),针对第 i i i 架无人机及其邻接目标 n n n(其他无人机或危险球体),定义如下安全屏障函数:
H i n ( t ) ( p u , i ( t ) , p n ( t ) ) = ∥ p u , i ( t ) − p n ( t ) ∥ − ( d i n ( t ) + d s ) H_{in}^{(t)}(p_{u,i}^{(t)}, p_n^{(t)}) = \|p_{u,i}^{(t)} - p_n^{(t)}\| - (d_{in}^{(t)} + d_s) Hin(t)(pu,i(t),pn(t))=∥pu,i(t)−pn(t)∥−(din(t)+ds)
当该函数值大于等于零时,即代表系统处于满足距离约束的安全集中。由于系统在离散时间下运行,当前时间步 k k k 必须满足如下瞬时导数条件,以保证屏障函数的变化率始终指向安全区域:
H ˙ i n k ( p u , i k , p n k ) ≥ − α H i n k ( p u , i k , p n k ) \dot{H}{in}^{k}(p{u,i}^{k}, p_n^{k}) \geq -\alpha H_{in}^{k}(p_{u,i}^{k}, p_n^{k}) H˙ink(pu,ik,pnk)≥−αHink(pu,ik,pnk)
在实际执行阶段,安全过滤器通过求解二次规划问题,将强化学习(MARL)策略生成的原始动作投影到满足所有邻居约束的安全动作集中:
x i , s k = arg min x ^ i k ∥ x ^ i k − x i k ∥ 2 s.t. H ˙ i n k ≥ − α H i n k , ∀ n ∈ G i \boldsymbol{x}{i,s}^{k} = \arg\min{\hat{\boldsymbol{x}}_i^{k}} \|\hat{\boldsymbol{x}}i^{k} - \boldsymbol{x}i^{k}\|^2 \quad \text{s.t.} \quad \dot{H}{in}^{k} \geq -\alpha H{in}^{k}, \forall n \in G_i xi,sk=argx^ikmin∥x^ik−xik∥2s.t.H˙ink≥−αHink,∀n∈Gi
奖励函数
总奖励由目标引导奖励、威胁预警惩罚以及碰撞惩罚组成:
r k = r g k + ϵ t r t k + r c r^{k}=r_g^{k}+\epsilon_tr_t^{k}+r_c rk=rgk+ϵtrtk+rc
目标引导奖励通过当前位置到目标点的归一化距离差之和来计算:
r g k = − ∑ i = 1 I ∥ p i , g − p u , i k + 1 ∥ ∥ p i , g − p u , i 0 ∥ r_g^{k}=-\sum_{i=1}^I\frac{\|p_{i,g}-p_{u,i}^{k+1}\|}{\|p_{i,g}-p_{u,i}^{0}\|} rgk=−i=1∑I∥pi,g−pu,i0∥∥pi,g−pu,ik+1∥
为鼓励安全飞行,系统在每个邻接目标周围划定了距离为 d t d_t dt 的威胁预警区。当无人机进入该区域时,会触发基于距离线性缩放的单体威胁惩罚 r i n k r_{in}^{k} rink
r t k = ∑ i = 1 I ∑ n ∈ G i r i n k r_t^{k}=\sum_{i=1}^I\sum_{n\in G_i}r_{in}^{k} rtk=i=1∑In∈Gi∑rink
3.基于强化学习的路径规划方法
策略训练中的不确定性缓解
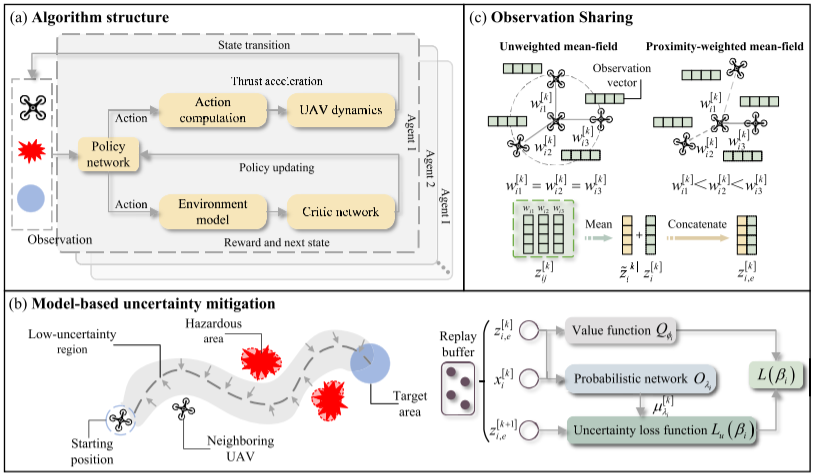
采用概率神经网络(PNN)作为虚拟环境模型,通过近似观测状态转移来量化未来的不确定性。不同于确定性输出,PNN以当前观测与安全过滤动作作为输入,输出下一观测状态的高斯分布 N ( μ λ i k , Σ λ i k ) \mathcal{N}(\mu_{\lambda_i}^{k}, \Sigma_{\lambda_i}^{k}) N(μλik,Σλik),其中均值 μ λ i k \mu_{\lambda_i}^{k} μλik 代表预期状态,协方差 Σ λ i k \Sigma_{\lambda_i}^{k} Σλik 量化由危险引发的不确定性。
网络通过最小化负对数似然损失进行训练,以实现精准的分布拟合:
L ( λ i ) = E log Σ λ i \[ k 2 + ( z i k + 1 − μ λ i k ) 2 2 Σ λ i k ] L(\lambda_i) = \mathbb{E}\left\\frac{\\log \\Sigma_{\\lambda_i}\^{\[k}}{2} + \frac{(z_{i}^{k+1} - \mu_{\lambda_i}^{k})^2}{2\Sigma_{\lambda_i}^{k}}\right] L(λi)=E2logΣλi\[k+2Σλik(zik+1−μλik)2]
为引导无人机主动避开突发危险等高不确定性区域,系统引入了约束不确定性损失,对偏离预测均值的行为进行惩罚:
L u ( β i ) = E ∥ z i k + 1 − μ λ i k ∥ L_u(\beta_i) = \mathbb{E}\|z_i^{k+1} - \mu_{\lambda_i}^{k}\| Lu(βi)=E∥zik+1−μλik∥
在多智能体深度确定性策略梯度(MADDPG)算法的训练框架下,该不确定性损失被整合进无人机局部策略网络的优化过程中。系统通过超参数 ϵ u \epsilon_u ϵu 来平衡标准策略损失 L ∗ ( β i ) L^*(\beta_i) L∗(βi)( E − Q ϕ i ( z \[ k , x s k ) ] \mathbb{E}-Q_{\\phi_i}(z\^{\[k}, x_s^{k})] E−Qϕi(z\[k,xsk)],用于最大化的奖励)与不确定性最小化,修正后的策略总损失函数为:
L ( β i ) = L ∗ ( β i ) + ϵ u L u ( β i ) L(\beta_i) = L^*(\beta_i) + \epsilon_u L_u(\beta_i) L(βi)=L∗(βi)+ϵuLu(βi)
同时,算法中的中心化价值网络根据观测-动作价值函数提供的梯度进行优化,通过最小化目标值 y i k y_i^{k} yik 与预测值之间的均方误差来迭代拟合:
L ( ϕ i ) = E ∥ Q ϕ i ( z k , x s k ) − y i k ∥ 2 L(\phi_i) = \mathbb{E}\|Q_{\phi_i}(z^{k}, x_s^{k}) - y_i^{k}\|^2 L(ϕi)=E∥Qϕi(zk,xsk)−yik∥2
融合邻居观测的规划方法
为有效整合邻近无人机的局部感知信息,本文引入了一种基于距离加权的平均场机制通过加权聚合邻居状态,将多智能体复杂的两两交互策略近似简化为考虑自身观测与聚合观测的策略表达:
π i ( z k ) ≈ π i ( z i k , z ˉ i k ) \pi_i(z^{k})\approx\pi_i(z_i^{k},\bar{z}_i^{k}) πi(zk)≈πi(zik,zˉik)
其中,聚合观测特征 z ˉ i k \bar{z}i^{k} zˉik及其对应的交互权重 w i j k w{ij}^{k} wijk定义为:
z ˉ i k = ∑ j ∈ G i w i j k z j k , w i j k = 1 ∥ p u , i k − p u , j k ∥ ∑ l ∈ G i ( 1 ∥ p u , i k − p u , i k ∥ ) \bar{z}{i}^{k}=\sum{j\in G_{i}}w_{ij}^{k}z_{j}^{k},\quad w_{ij}^{k}=\frac{\frac{1}{\|p_{u,i}^{k}-p_{u,j}^{k}\|}}{\sum_{l\in G_{i}}\left(\frac{1}{\|p_{u,i}^{k}-p_{u,i}^{k}\|}\right)} zˉik=j∈Gi∑wijkzjk,wijk=∑l∈Gi(∥pu,ik−pu,ik∥1)∥pu,ik−pu,jk∥1
权重 w i j k w_{ij}^{k} wijk与无人机间的空间距离成反比,距离越近则交互权重越大,从而使系统自动聚焦于碰撞风险较高的关键邻接目标。

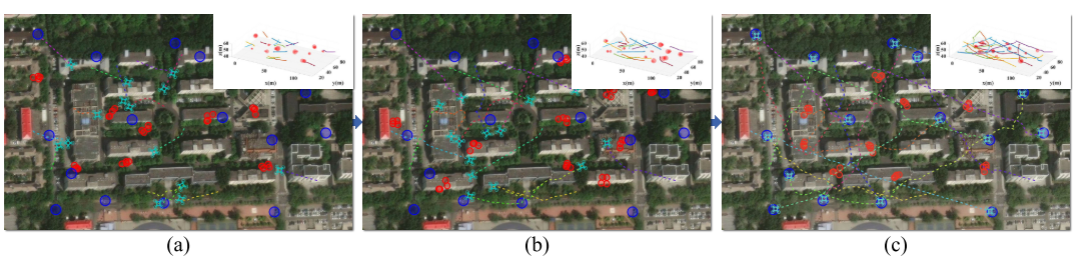
4.结果展示
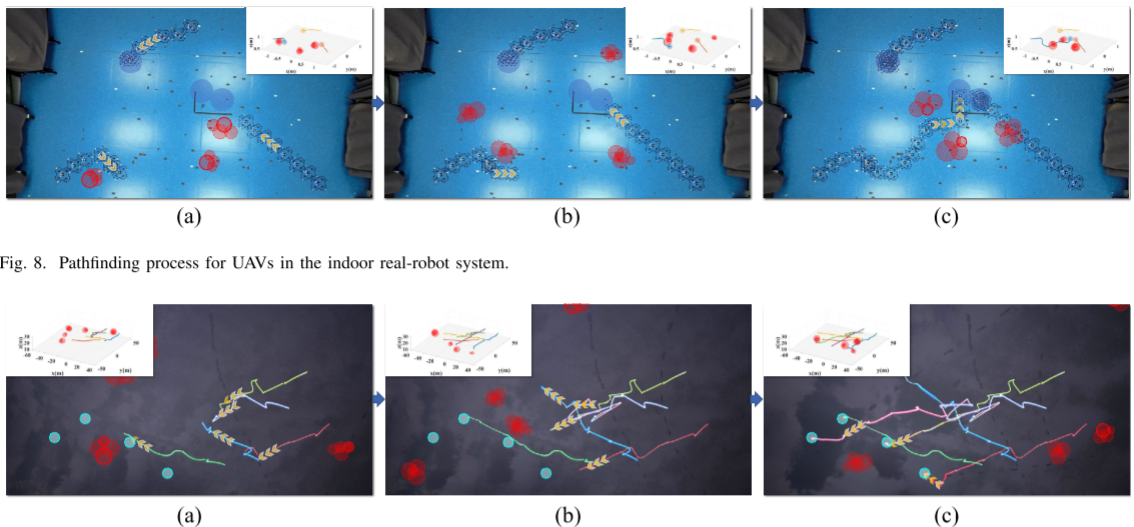
5.参考文献
Wu Q, Chen L, Liu K, et al. Reinforcement Learning-Based Pathfinding for Multiple UAVs Facing Abrupt Hazardous AreasJ. IEEE Transactions on Automation Science and Engineering, 2026.
6.代码获取
xx