https://blog.csdn.net/2601_95366422/article/details/159112601
上节课链接
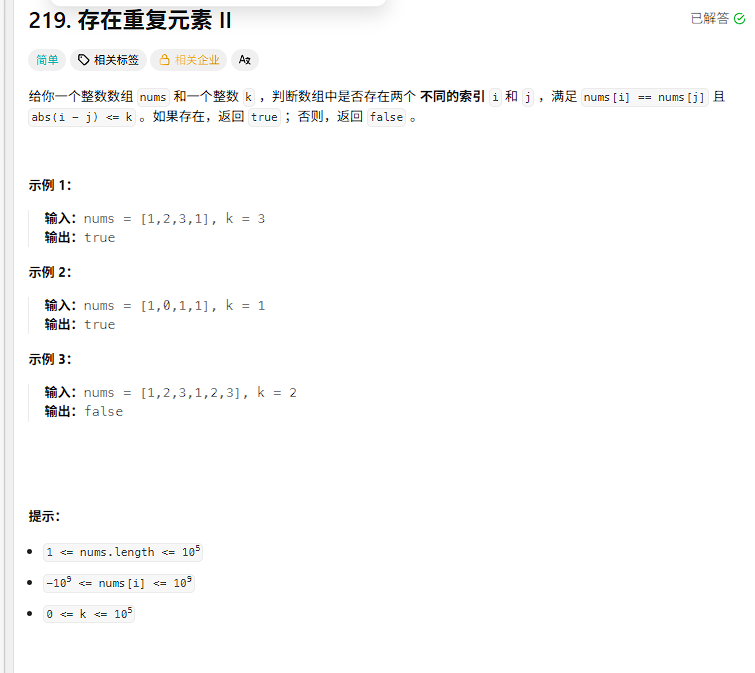
一.题目
二.思路讲解
2.1 思路讲解
本题不仅需要判断数组中是否存在相同元素 ,还要检查这两个相同元素的索引之差 的绝对值是否小于等于 k 。如果直接使用双重循环,时间复杂度为 O(n²),不可取。我们需要一种能够同时记录元素值和其下标的方法,以便在遍历时快速找到之前出现过的相同元素的位置。
我们可以借助哈希表 来解决:哈希表的键存储元素值,值存储该元素最近一次出现的下标。但是,这里有一个细节:下标可能为 0 ,如果我们将下标直接存入哈希表,那么当我们检查某个元素是否出现过时,就需要通过哈希表的 find 或 count 来判断,而不能单纯用值是否为 0 来判断。为了简化判断,我们可以将下标 加 1 后存入哈希表,这样哈希表中的值如果大于 0,就表示该元素已经出现过,且实际下标为 值 - 1。这样,我们只需要通过哈希表的值是否为 0 就能判断元素是否存在,避免了使用 find 的开销。
三.代码演示
cpp
class Solution {
public:
bool containsNearbyDuplicate(vector<int>& nums, int k)
{
unordered_map<int, int>hash;//前面一个为元素的值,后面一个为元素的下标
hash[nums[0]] = 1;
for (int i = 1; i < nums.size(); i++)
{
if (hash[nums[i]] != 0)
{
int t = abs(hash[nums[i]] - 1 - i);
if (t <= k)
return true;
else
hash[nums[i]] = i + 1;//当这个元素和下一个元素相同元素不匹配,那么让下一个元素替换当前这个元素
}
else
hash[nums[i]] = i + 1;
}
return false;
}
};四.代码讲解
一、初始化哈希表并存入第一个元素
为了在遍历过程中快速查找某个元素之前出现的位置,我们使用一个哈希表 unordered_map<int, int>,其中键为元素的值,值为该元素最近一次出现的下标加 1 (这样做的目的是为了用 0 表示该元素尚未出现过,避免与下标 0 混淆)。首先,将数组的第一个元素 nums[0] 存入哈希表,即 hash[nums[0]] = 1,表示该元素已出现,其实际下标为 0。
二、遍历剩余元素
从下标 i = 1 开始遍历数组到末尾,对于每个元素 nums[i],执行以下操作:
-
检查元素是否已出现过 :通过
hash[nums[i]] != 0判断。如果该值不为 0,说明之前已经出现过该元素,且其最近一次出现的实际下标为hash[nums[i]] - 1。 -
计算索引差并判断 :用当前下标
i减去之前的下标(即hash[nums[i]] - 1),得到两者之差的绝对值(由于下标递增,差值为正,但代码中用abs更安全)。如果这个差值小于等于 k ,则说明找到了两个相同元素且索引差满足条件,直接返回true。 -
更新或插入:
-
如果差值大于 k ,说明当前这个元素虽然出现过,但距离太远,不符合要求。此时我们需要将哈希表中该元素对应的下标更新为当前下标加 1 (即
hash[nums[i]] = i + 1),这样后续再遇到相同元素时,比较的是更近的一次出现。 -
如果元素之前从未出现过(
hash[nums[i]] == 0),则直接将其存入哈希表,值为i + 1。
-
三、返回结果
如果遍历完整个数组都没有返回 true,说明不存在满足条件的两个相同元素,最后返回 false。
四、关键细节
-
下标加 1 存储 :这是为了用 0 表示"不存在",简化判断逻辑。否则,如果直接存储下标,需要额外判断哈希表中是否有该键,或者使用
find方法。加 1 后只需检查值是否为 0 即可。 -
更新策略:当遇到相同元素但距离不满足时,必须更新为当前下标,因为后续可能出现更近的相同元素,只有保留最近的下标才能保证找到最小的距离。