文章目录
- [Linux 系统编程 进程篇(一)](#Linux 系统编程 进程篇(一))
-
- 1.冯诺依曼体系结构
-
- [1.1 介绍](#1.1 介绍)
- [1.2 数据流动](#1.2 数据流动)
- [2. 操作系统](#2. 操作系统)
-
- [2.1 概念](#2.1 概念)
- [2.2 设计操作系统的目的](#2.2 设计操作系统的目的)
- [2.3 理解操作系统](#2.3 理解操作系统)
- [2.4 理解系统调用](#2.4 理解系统调用)
- [3. 进程](#3. 进程)
-
- [3.1 进程的基本概念与操作](#3.1 进程的基本概念与操作)
-
- [3.1.2 进程描述](#3.1.2 进程描述)
- [3.1.3 进程查看](#3.1.3 进程查看)
- [3.1.4 创建子进程](#3.1.4 创建子进程)
Linux 系统编程 进程篇(一)
1.冯诺依曼体系结构
1.1 介绍
要了解什么是进程,我们就要先在之前的基础上,深入了解一下操作系统。要想深入了解一操作系统,首先,就要先了解一些冯诺依曼体系结构。
我们常见的计算机,像是笔记本,服务器,大多数都遵循冯诺伊曼体系结构
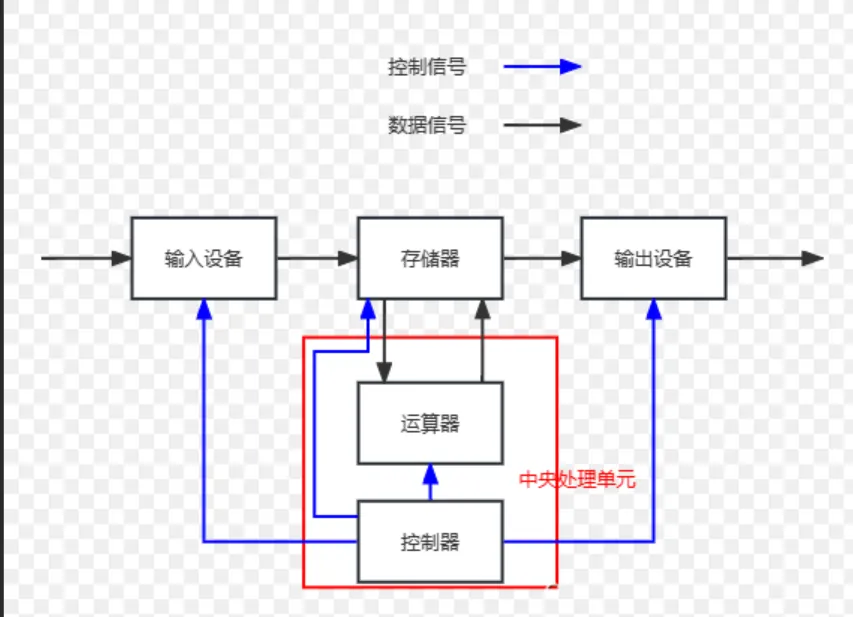
这就是冯诺依曼体系结构,总共由五大部件组成,输入输出设备,储存器,运算器,控制器,下面我们详细一个个地介绍。截至目前,我们所认识的计算机都是由一个个的硬件组成的。
输入设备,比如说像键盘,鼠标,触控板,磁盘,网卡。
输出设备,比如说像显示器,磁盘,网卡,打印机
这里暂停一下,可以看到这里的输入输出设备是有交叉的。
我们常说的CPU,也就是中央处理器,就是 运算器 + 控制器。 控制器是用来协调这些部件工作的,运算器顾名思义就是执行运算工作的。
储存器,是什么呢?这个很重要,储存器,就是我们常说的内存。这里就要和磁盘区分一下了,上述的输入输出设备总的来说叫做外设,所以,此磁盘我们叫做外存。
或许大家之前听说过一个概念叫I/O,也就是input和output,站在内存的角度来说,I 就是把数据加载到内存,如果说输入设备是磁盘的话,数据就从磁盘拷贝内存。 O 就是把数据从内存再加载到磁盘,也是一种数据的拷贝转移。
或许大家之前或多或少都听过,软件运行,必须先加载到内存,为什么?因为冯诺依曼体系结构规定的。补充一句,在没有加载到内存前,这些可执行程序都是磁盘中的文件。
那么冯诺伊曼体系结构为什么这么规定呢?
首先,我们得先知道,CPU运行我们的程序,本质上实在访问我们数据,而CPU的获取,写入只能从内存中来进行。
刚才我们也提到过,I/O的过程,是数据的拷贝,从一个设备到另一个设备,这里的加载也是同理。那么,这个程序执行的速度就和这个数据拷贝到CPU和从CPU处理完以后再拷贝回来的速度高度关联。
铺垫了这么多,还要再引入一个概念,其实,计算机里面的数据存储是分级来存储的,如下图:
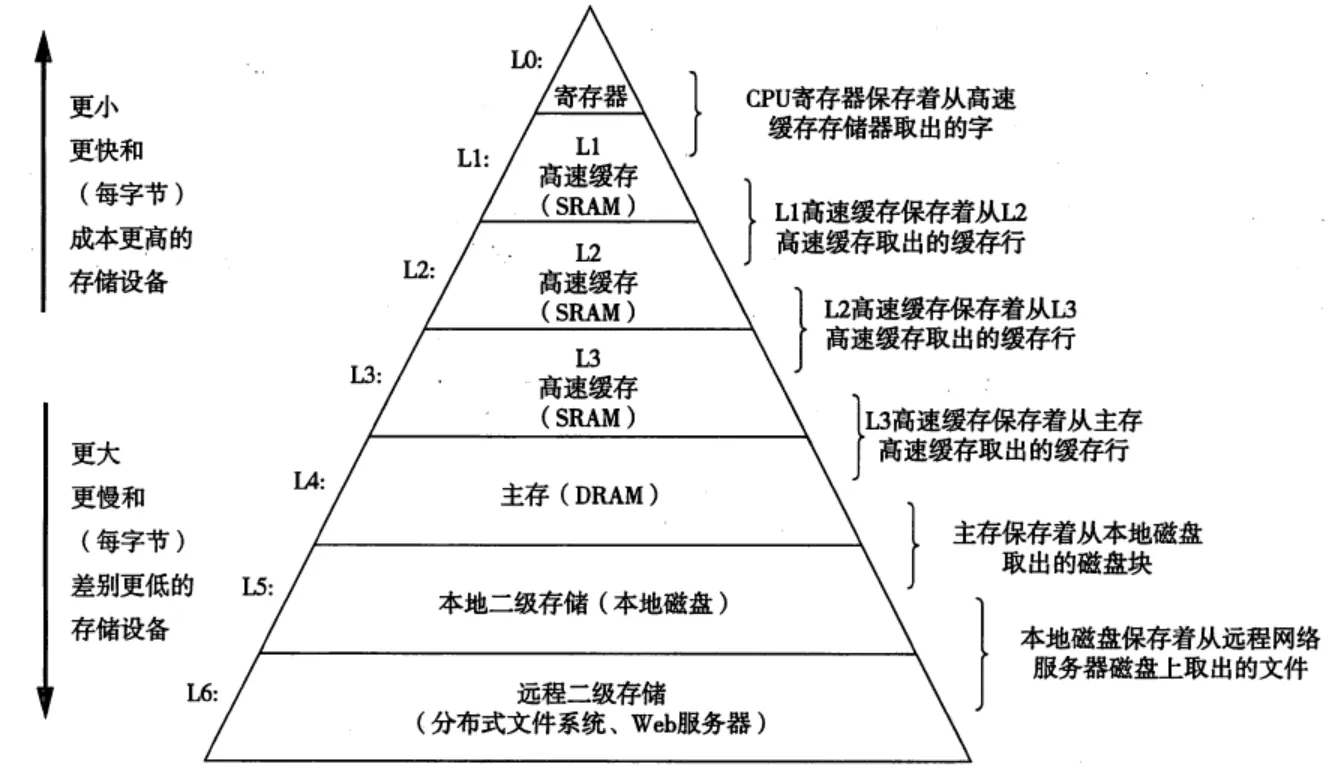
为什么要分级存储,因为CPU运算的速度太快了,是文件从磁盘拷贝到CPU的速度的一千倍吧好像,这和这个芯片技术的发展和这个摩尔定律有关。还有由于木桶效应的存在,程序执行的速度是和最慢的一步相近的,也就是拷贝的这一步。
我们肯定是不想这么搞的,肯定是越快越好。于是就搞出来这个内存分级,越往上,数据拷贝的速度就更快,可以存储的空间就更小,同时,造价也越贵。有的哥们说寄存器最快了,为什么不全用寄存器来存储,富哥们儿可以试试。话说回来,越往下,速度就越慢,但是存储容量大,造价也相对亲民。
所以,为了解决这个数据传输慢的和这个价格的痛点,所以,冯诺依曼体系结构就规定了,不考虑高速缓存的情况,任何的设备都只能直接地和内存打交道。就像冯诺依曼体系结构图那样,输入输出设备之和内存打交道,CPU同理。
可以看到,主存,也就是我们的内存,再这个磁盘上面,所以这个速度就会快一些。这时,有哥们可能会问,这不也没差多少嘛,短板还是短板。事实确实这样,但还有很重要的一点就是当代计算机是性价比的产物,冯诺伊曼体系结构的意义就是让我们普通人,也可以用上计算机。涉及到我之前说的造价问题,不再赘述。
1.2 数据流动
理解什么叫数据流动也是非常重要的。我们之前理解的数据流动几乎都是从软件层面来理解的,比如说用QQ发消息之类的。
下面,我带大家从这个硬件角度,也就是冯诺依曼体系结构的这个大框架开始理解数据流动。
比如说,我现在北京,我要给南京的一个兄弟QQ传个文件。
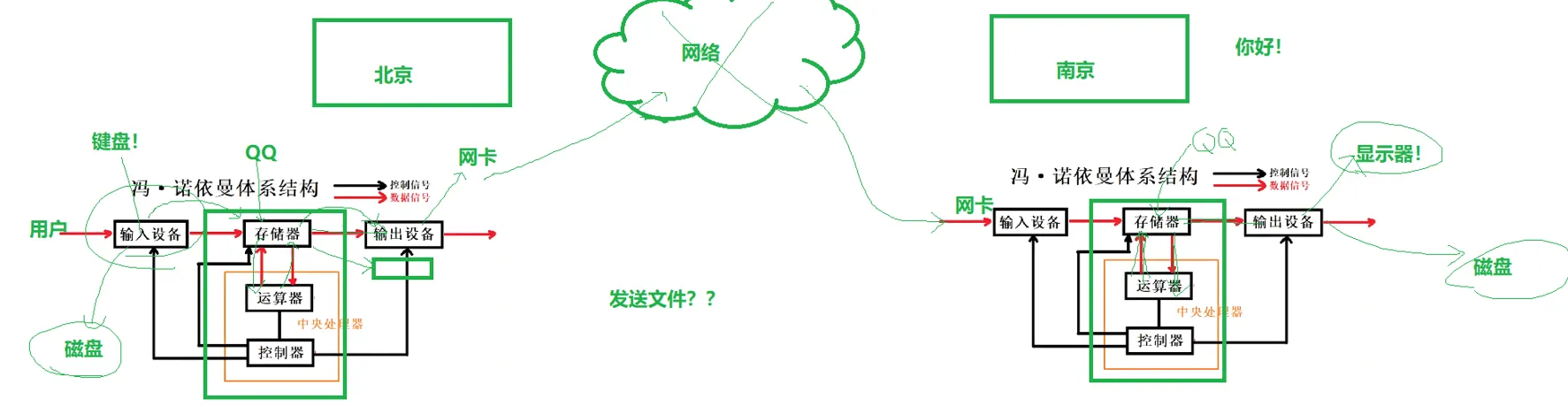
这里网络的细节问题我们还没学,所以模糊处理就好,影响不大。
我在北京,首先我要把我的文件从磁盘加载到内存,磁盘就是输入设备,然后通过这个网卡,把文件通过网络送到南京兄弟的网卡。这里面,我的网卡,对于我来说是输出设备,南京兄弟的网卡是他的输入设备。然后他那边,文件从网卡加载到内存,然后在出现在显示器上,他能看见。数据就从我这边,去了南京兄弟那么,这就是数据的流动。
2. 操作系统
2.1 概念
我们主要从三个方面来讲,是什么,为什么,怎么做,重心放在前两个,这个怎么做后面会有更详细的介绍的。
什么叫操作系统,一个基本程序的集合,称为操作系统,操作系统是一款进行软硬件管理的软件。
操作系统包括内核(进程管理,内存管理,文件管理,驱动管理), 和其他程序(例如库函数,shell程序等等)
操作系统的概念是有狭义和广义之分的,狭义的操作系统就是kernel内核, 而广义的操作系统就是在内核的基础上,加上外壳shell, 库 ,预装的软件,还有基于操作系统做的开发,这些的总和就是广义的操作系统。
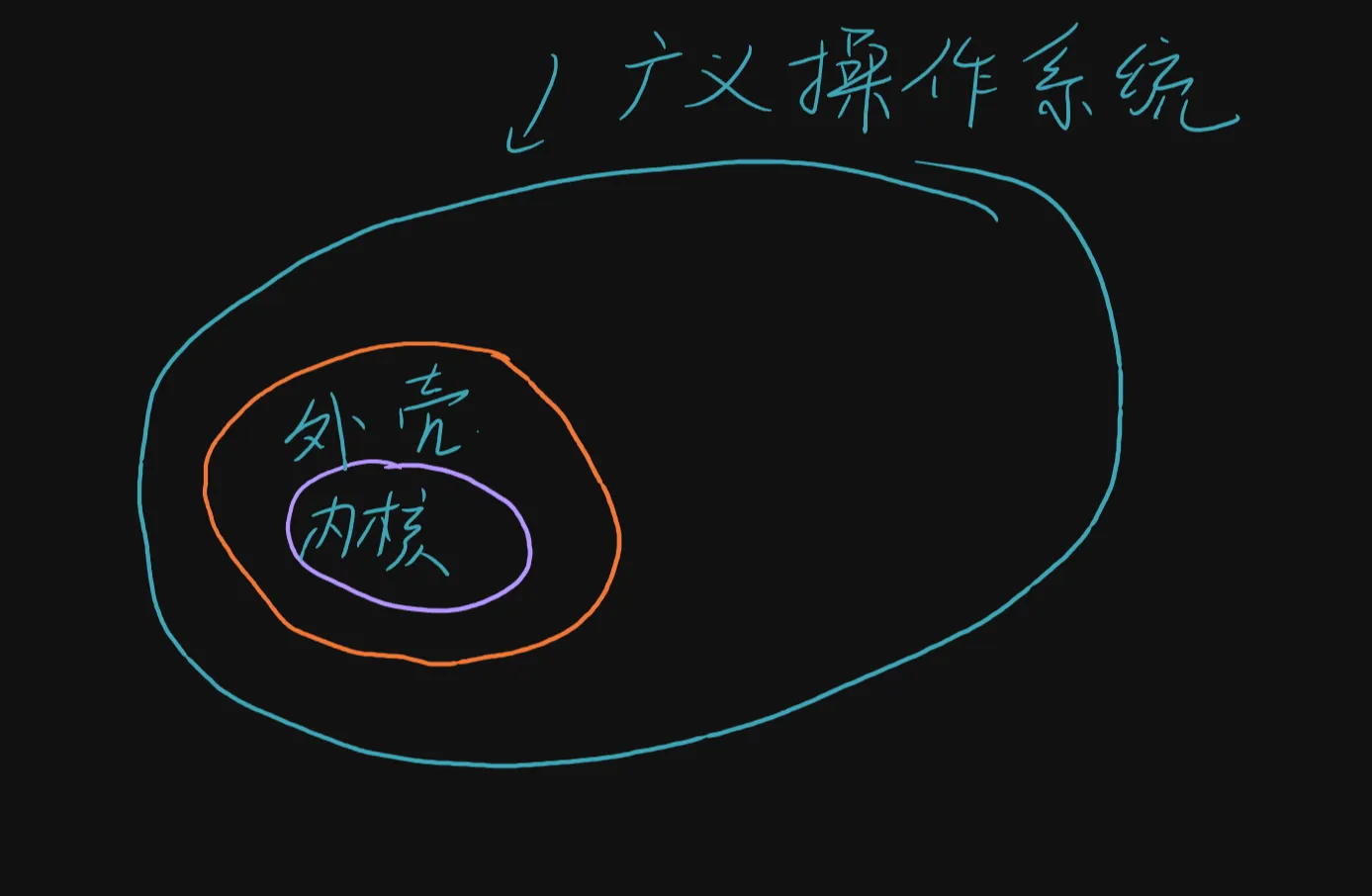
如果没有特别说明,我下面提到的都是狭义操作系统。
2.2 设计操作系统的目的
上述我们提到,操作系统是一款进行软硬件管理的软件。
对上,设计操作系统的目的就是为了让用户程序有一个良好的执行环境。这是目的。
而对下,操作系统与硬件交互,管理硬件资源。注意,这个不是目的,是手段。
有的同学或许有疑问,对上和对下是什么意思,为什么有上下之分。这里就不得不提到这个软硬件的层状结构了:
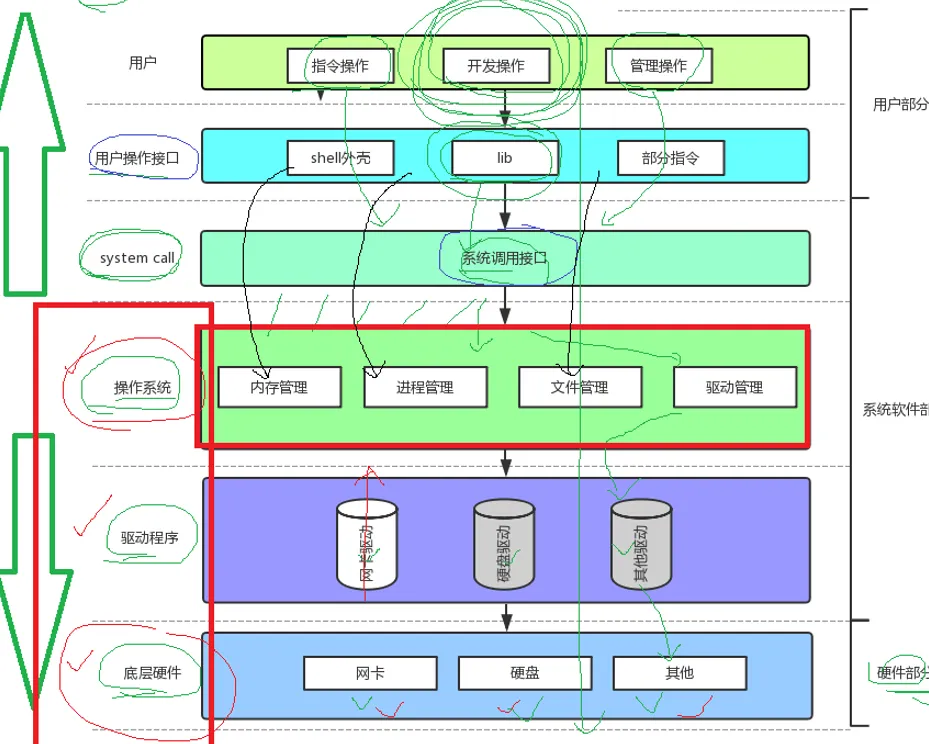
可以看到这个层状结构由上到下分别是用户,用户操作接口,系统调用接口。然后往下就是操作系统和驱动和底层硬件。
底层硬件也就遵循冯诺依曼体系结构。
有层状结构的存在,代表用户想要访问操作系统美酒必须使用系统调用。系统调用其实就是函数,只不过是系统提供的。
我们的程序,只要你判断它访问了硬件,那么它就必须贯穿整个软硬件体系结构。
还有一点,我们使用printf可以在显示器上显示,换句话说这里是把数据写到了硬件上,那么他就必须贯穿整个层状结构。
这也证实了,库函数里面可能在底层封装了系统调用。
2.3 理解操作系统
在软硬件体系结构中,操作系统的定位是一款纯正的"搞管理的软件"。
那么,如何"管理" ? 举个例子,
假设现在在一个大学里面,有校长,辅导员,和同学。校长毋庸置疑就是管理者,学生是被管理者。那么,导员是什么?
我们知道,一个事情要完成,就必须先决策,然后执行。
所以,我们再严谨一些,校长身为管理者,有的权力是决策权,而导员有的是执行权,把决策执行中学生们身上。
校长1.0呢,是校长,要管理学校里面的学生,那么这个校长就少不了学生们的信息,比如说一个excel表格。上面有行是姓名,列是各种指标。好,到这里,暂停一下。
1.我们发现,校长管理学生,其实不需要和学生见面,也就是管理者和被管理者,可以不需要见面。
2.不见面怎么管理,答案是通过学生的信息,也就是数据。
3.数据从哪里来,当然是从中间层,也就是导员,或者说驱动程序来。
校长管理学生,只需要管理他的excel表格就好,对表格进行增删查改。
但是,这个校长慢慢就不满意了,因为每次找一个学生的信息都要遍历整张表格,校长有点不爽。
校长之前是程序猿,于是,校长想到了新的办法,校长2.0诞生。
校长2.0怎么办呢?校长2.0搞了一个结构体来描述每一个学生。这个结构体里面存着学生们的姓名,年龄,籍贯,绩点之类的,还有指向下一个学生的指针。
校长把这些学生们都串成一个链表,管理学生的工作变成了管理链表的增删查改。这个过程其实就是一个建模的过程。
总结为一句话,就是对任何场景建模都要先描述,再阻止。描述就用一个类或者结构体,而组织就用到了数据结构。
换句话说,操作系统是来管理的,那它其中肯定充斥着很多数据结构。因为管理管理对象,就是管理管理对象的数据,对对象先描述再建模,所以,操作系统最终通过数据结构来管理起数据。
所以,这样体现了数据结构的重要性,体现了STL的重要性。
2.4 理解系统调用
要理解系统调用,我们就要知道操作系统的功能和特点:
操作系统要向上给用户提供对应的服务,但是操作系统不信任任何人。
或许这有些奇怪,我们举个例子,比如说银行。客户可以拿着身份证银行卡来柜台取钱,但是客户不能直接进入金库。
就想这个例子说的,用户想要使用操作系统提供的操作,必须经过像银行柜台一样的东西,这个,就叫做系统调用。
在开发角度,操作系统对外表现为一个整体,但是回暴露自己的部分接口,供用户使用,这部分接口就叫做系统调用。
系统调用本质就是函数,而且是C语言写的。用户通过调用这个函数,给操作系统传值,操作系统处理完了以后,再给用户返回一个结果, 本质上就是供用户和操作系统见进行数据交换。

但是,这样就完了吗?肯定不是,延用上述银行的例子。如果,来取钱的是一个年纪比较大的老头老太太,到了银行之后这个什么也不会操做,但是,银行里面有大堂经理,大堂经历就会带着老年人去柜台,然后指挥柜台的服务员给他办了。
就像上述例子里面说的,系统调用在使用上功能比较基础,而且对用户的要求也高,所以,有心的开发者就把系统调再套一层,封装成一个简单好用的库函数,来方便用户使用。这样就形成了库。
所以,库和系统调用就是一个上下级的关系。
3. 进程
3.1 进程的基本概念与操作
先引用课本上的原话:进程是程序的一个执行实例,正在执行的程序等
内核观点:担当分配系统资源(CPU时间,内存)的实体。
3.1.2 进程描述
光讲上面两个观点这个非常的晦涩难懂,下面我们详细说说。先提出一个问题,是不是加载到内存里面的程序就是一个进程?
我们从这么几个角度来看,
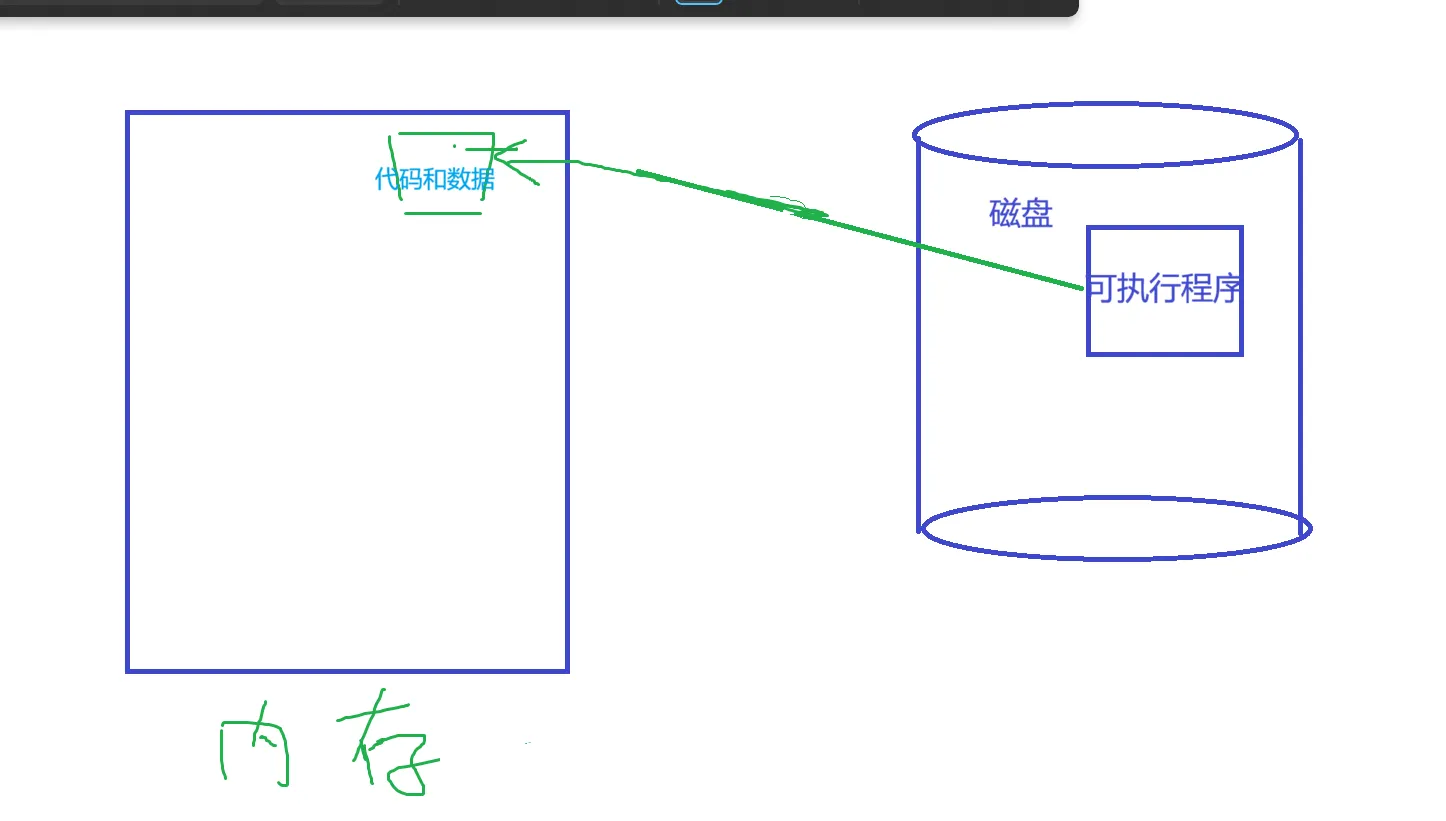
可执行程序加载到内存里面,就是把他的代码和数据加载到内存里面,的但是,在我们的自定义的可执行程序加载到内存之前,已经有一个东西早早地就在内存里面了,就是操作系统。
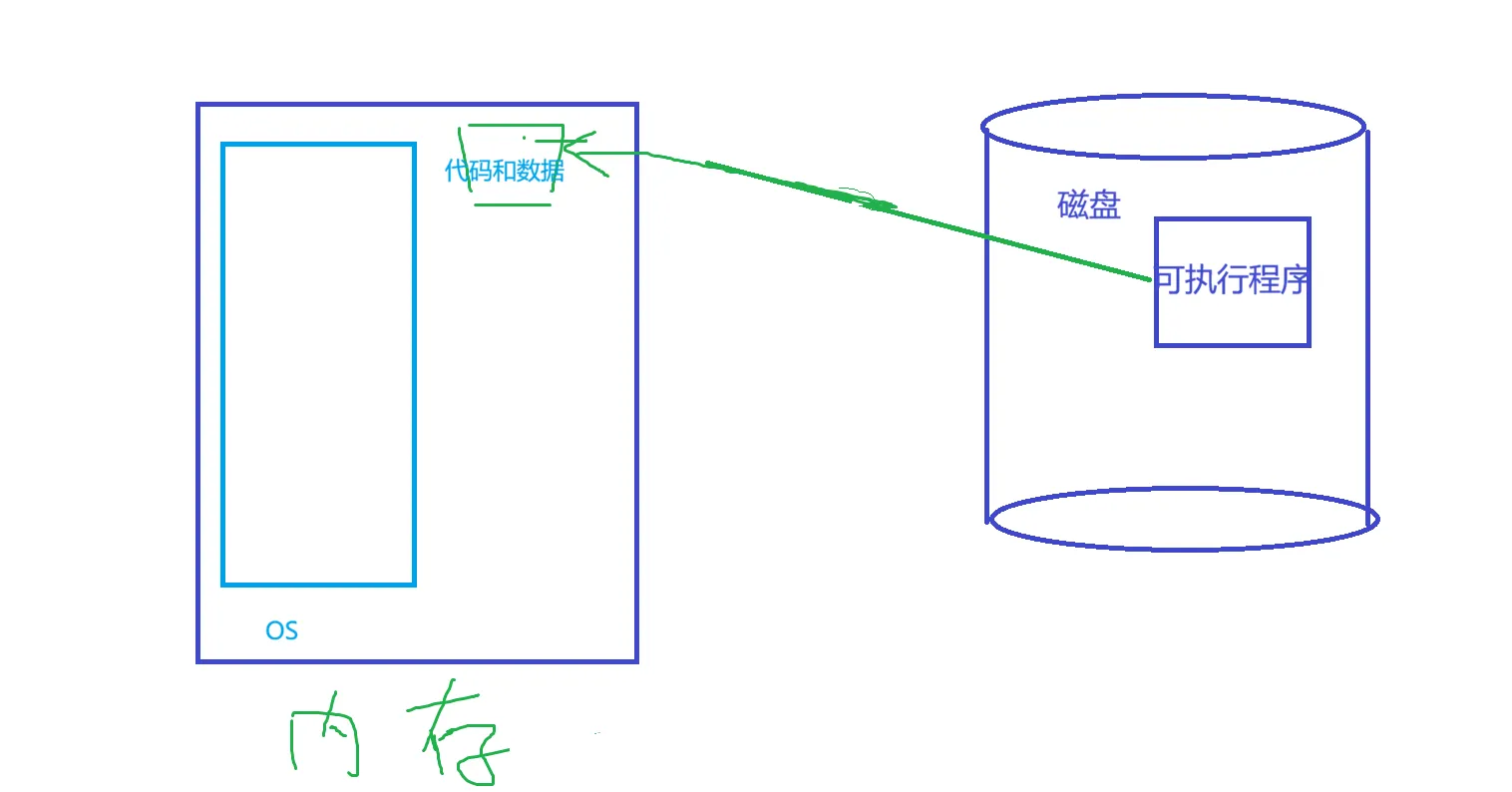
承接我们上文说到的操作系统的作用,作用有一条就是进行进程管理,调度进程去CPU执行。就像我们上文说的,校长管理学生,要先描述再组织。先看这个图,如果只是这样单单加载进去的话,操作系统其实是管理不了的,必须要先对加载到内存里面的可执行程序进行一个描述,把基本信息放在内核的一个结构体里面。操作系统可以根据结构体信息来找到相应的可执行程序这是先描述。
但是操作系统只是对一个可执行程序来管理吗?当然不是,肯定还有很多可执行程序需要被管理,这些可执行程序都有自己的描述信息,内核里面存着这些结构体信息来管理,结构体和结构体之间用一个链表存下来。
这就是先描述,再组织。
所以,整个图就该变成这样:
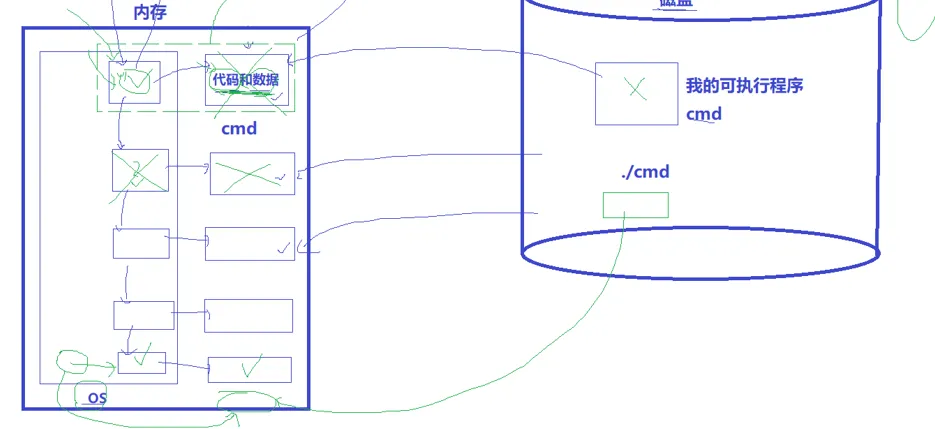
由此,我们可以得到我们的第一个结论,
进程就是 内核里面的结构体信息 + 自己的代码和数据。 注意是加载到内存里面的噢。
下面,我们来重点看一下这个结构体,这个结构体里面因为是对应程序来的,还要串成链表,所以,里面一定有,这个代码的地址,数据包的地址,id, 优先级, 状态 以及 指向下一个节点的指针。
而这个结构体,有自己特殊的名字,叫,进程控制块 PCB.

所以,我们就可以进一步完善刚才得到的结论,就是,进程 = PCB + 自己的代码和数据。
PCB里面就含着这个可执行程序的所有属性,操作系统里面存着的,也是这个进程控制块,然后按照顺序,把这个进程控制块送到CPU,CPU根据信息找到对应的可执行程序来执行。
因为有这个链表结构,操作系统对进程的管理,就变成了对链表的增删查改。
在linux里面,这个PCB有个自己的名字 叫 task_struct 即:
c++
struct task_struct
{
}进程中所有属性,都可以直接或者间接地通过task_struct来找到。这个task_struct在linux的内核源代码里面是找得到的。
因为我们学linux,所以,就这个来讲讲这个task_struct。那么这个里面都有什么呢?这里先简单介绍,后面再挨个详细地说。如图:

标识符就是这个进程的id,其实叫pid马上就要谈到。
3.1.3 进程查看
光描述进程还是有些干巴,下面我们实操一下,来演示一下进程。
在演示之前,我们先来明确一下,我们历史上执行的所有命令,工具,自己的程序,运行起来,全部都是进程!!
那么我们要怎么演示进程呢?当然是通过这个标识符,也就是pid来演示了。首先我们先来介绍两个系统调用,
getpid 和 gitppid
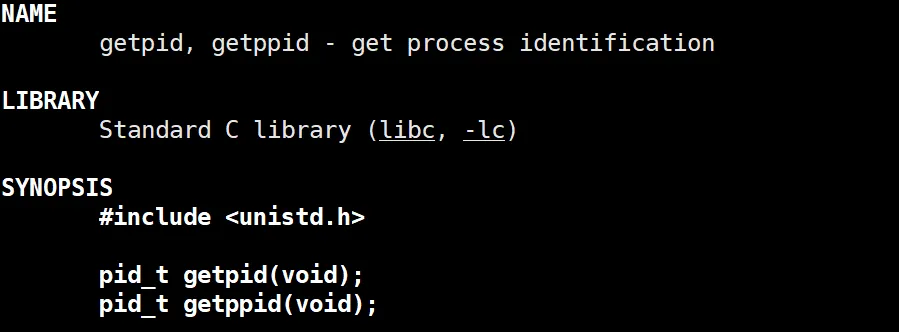
man一下可以看到,这两个函数就是系统调用,在C语言标准库里面。getpid的作用就是返回这个进程的pid,getppid就是返回这个进程的父进程pid。 这个pid_t其实就是一个来描述pid的正整数,和size_t的原理是一样的。
有了这个以后,我们就可以写代码验证一下进程的存在了,首先:

这就是一段很简单的代码,然后,我们开始运行它,再打开一个Xshell窗口,查看这个进程。
这里介绍两个命令,一个是top 还有 一个是ps ajx。 但是,如果我们只执行其中一个的话,会看到好多进程,而不是我们想看的所以,grep过滤一下。当然,表头不能落下,所以还要head一下。
顺带一提,如果我们要一次运行两天命令的话,用 ; 或者 && 分隔
综上,我们查看出来的就是这样:
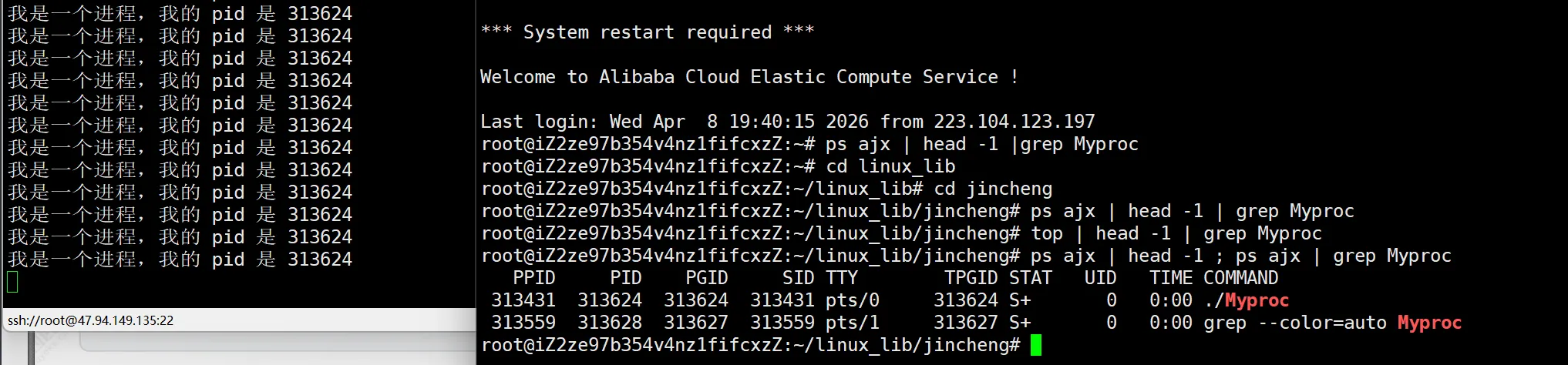
可以看到,这个进程的pid是313624,只看右边的话,pid同样是313624,这就是这个进程。
这时有同学就要问了,为什么查出来两个,因为 grep 本身也是个进程,按名字查的时候,里面也有Myproc,所以就带出来了,如果不想要的话,可以 -v 反向过滤一下。
那如果我们 ctrl + c 一下呢?

可以看到。操作完了以后这个313624的进程消失了,所以,我们就知道了 ctrl + c 的作用就是杀掉进程
这里再补充一下 kill 这个指令也可以沙杀掉进程, 这里涉及到信号哪里的知识,就简单演示一下

可以看到,新进程启动, 313641. 然后我们kill一下。

可以看到这个进程就被杀掉了, -9 就是这个信号,意思就是杀进程。
除了上述查看进程的办法之外呢,还有别的办法查看进程。就是可以通过查看 /proc系统文件来查看进程。如图:
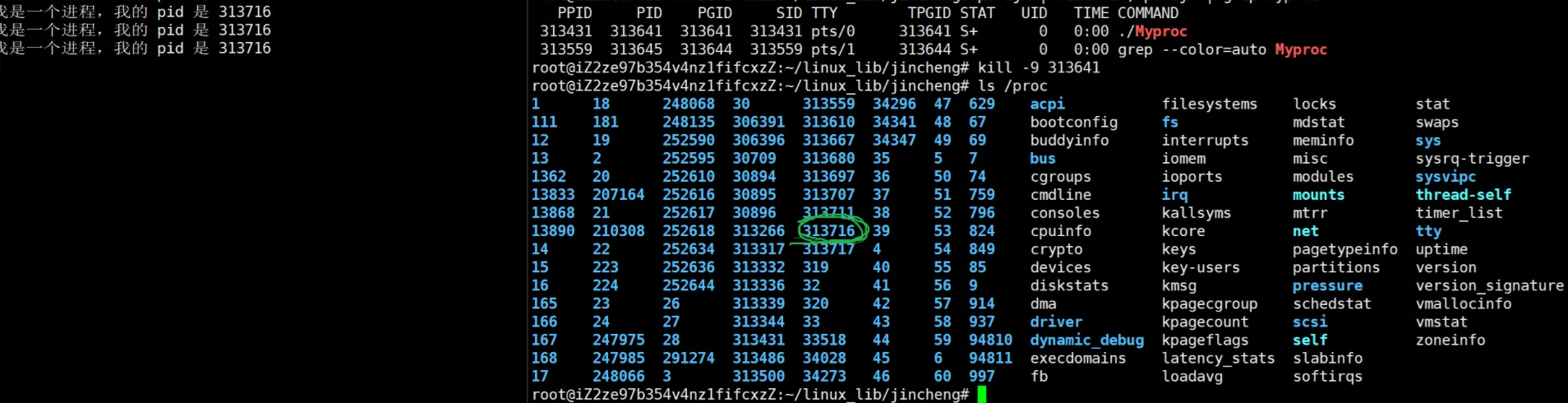
可以看到,列出这个目录下面的文件以后,就出现了和这个进程pid一样的文件,这个文件就是这个进程。
那么这个东西的原理说什么呢,这里简单介绍一下,后面详细说,因为这个/proc目录下面的文件都是加载到内存里面的文件,这个进程在内存里,所以就可以看到。
我们进去看一下,里面有什么,
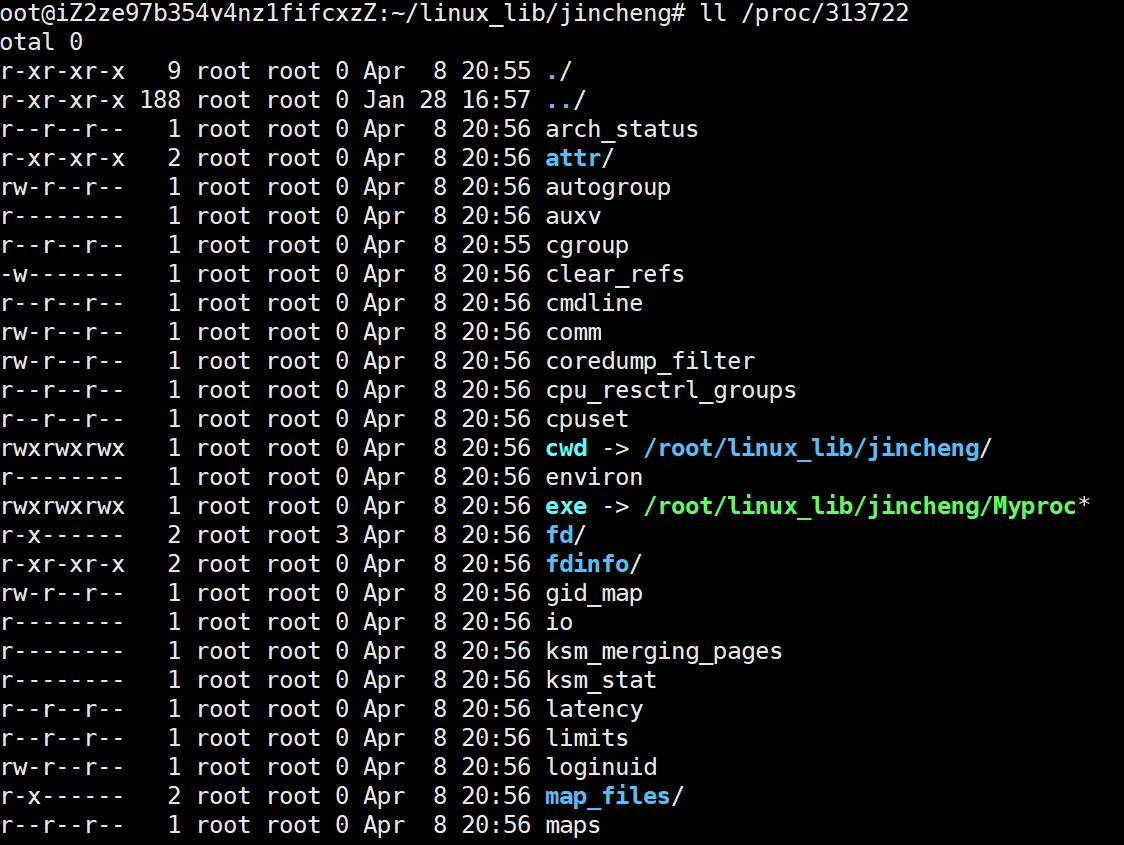
这里我关掉重新启动了一下,所以,这里变成了313722,这个目录里面就是这个进程的详细信息,大概看一下就好,主要为了演示一下。
来看这张图,有两个重要的东西:
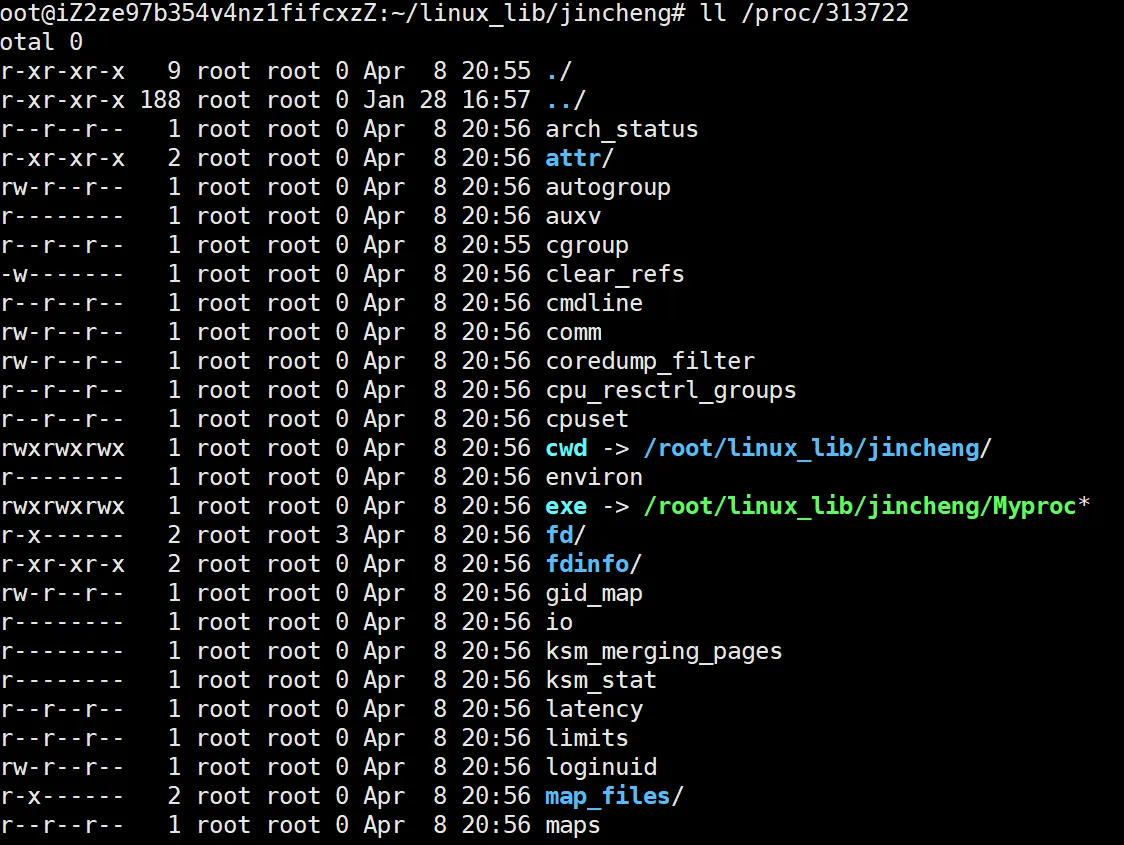
就是这个浅蓝色的 cwd 和 exe 。这两个是什么呢?
首先来看exe,这个exe后面跟着一串完整的路径,是这个Myproc可执行程序所在的位置,说明这个进程是可以找到这个可执行程序的。
再来看这个cwd,cwd是什么呢?也是一个路径,和这个Myproc在同一个目录下。这个就牵扯到一个遗留问题,我们在学习C语言的fopen的时候,如何选择了 "w"选项,而文件不存在的话,是不是会在当前路径下新建一个同名文件。
当时没说为什么可以这样,它是怎么找到这个路径的,原因就在这个cwd上,这个进程里面就保存这个可执行程序的目录。
说完上述两个知识后,我们在往下走。有没有发现,我们从这个演示进程开始的时候,每次中断然后再打开,这个进程的pid都是在变化的。 linux里面这个pid的分配是整数大小逐渐递增的,至于为什么不是连续的,因为这个操作系统里面很多进程,有一些把这个位置挤占了。
但是,这个进程的父进程,也就是ppid,会变吗? 我们来看:
可以看到,父进程的ppid是不变的?那么这是为什么呢?我们可以根据这个ppid来查找一下父进程到底是谁

可以看到,这个父进程其实就是 bash。 bash是什么?bash就是命令行解释器, 这个 - 的意思是远程链接啊,因为我这是云服务器。
所以,我们就可以肯定,命令行解释器,本质也是一个进程。这里就要回想一下王婆和实习生的例子。
bash就是网盘,用户输入命令,然后bash分配进程去完成,所以 我们的ls pwd mkdir 等等命令的父进程都是这个 bash。
那么,同学们,为什么我们在没有输入命令的时候,会有一个光标卡在这里,

原因就是这个 bash里面有scanf等待用户输入指令。
这里再补充一个知识点:操作系统会给每一个用户分配一个bash。
3.1.4 创建子进程
刚才提到了父子进程的概念,那么我们要怎么来创建子进程呢?
这里我们就要知道下一个系统调用 就是 fork() .
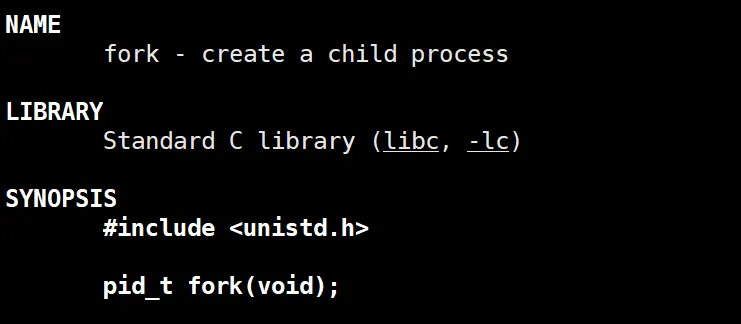
可以看到,这个fork的作用,写着就是创建子进程。

可以看到这里fork一下以后,子进程就创建了。那么这个子进程到底是怎么样的呢?
其实,是这样的,再fork之前,父进程有自己的有自己的task_struct,还有自己的代码和数据。创建子进程后,子进程首先就要有自己的task_struct,因为,目前没有程序新加载,所以,子进程没有自己的数据和代码,子进程的代码和数据是和父进程一样的。 总结就是,父子进程公用父进程的数据和代码。
这也就解释了,为什么会打印两遍我是子进程,父进程执行到fork的地方,子进程从fork开始执行,两个公用下面的代码,所以就打了两遍。
话说回来,我们再来研究一下fork函数,man 一下 ,看看他的返回值:

可以看到,这个fork如果创建成功子进程的话,给父进程返回子进程的pid, 子进程返回零, 创建失败返回 -1.
有没有发现华点?这里的fork返回了两个值。从我们一起的学习经验来看,函数的返回值只有一个,因为等到了return语句的时候,函数的逻辑以及走完了,功能实现了。 那这里为什么会返回两个值呢?
不着急解释,我们来看,有这个返回不同值给不同的进程,我们可以做到什么?也印证一下这个结论,
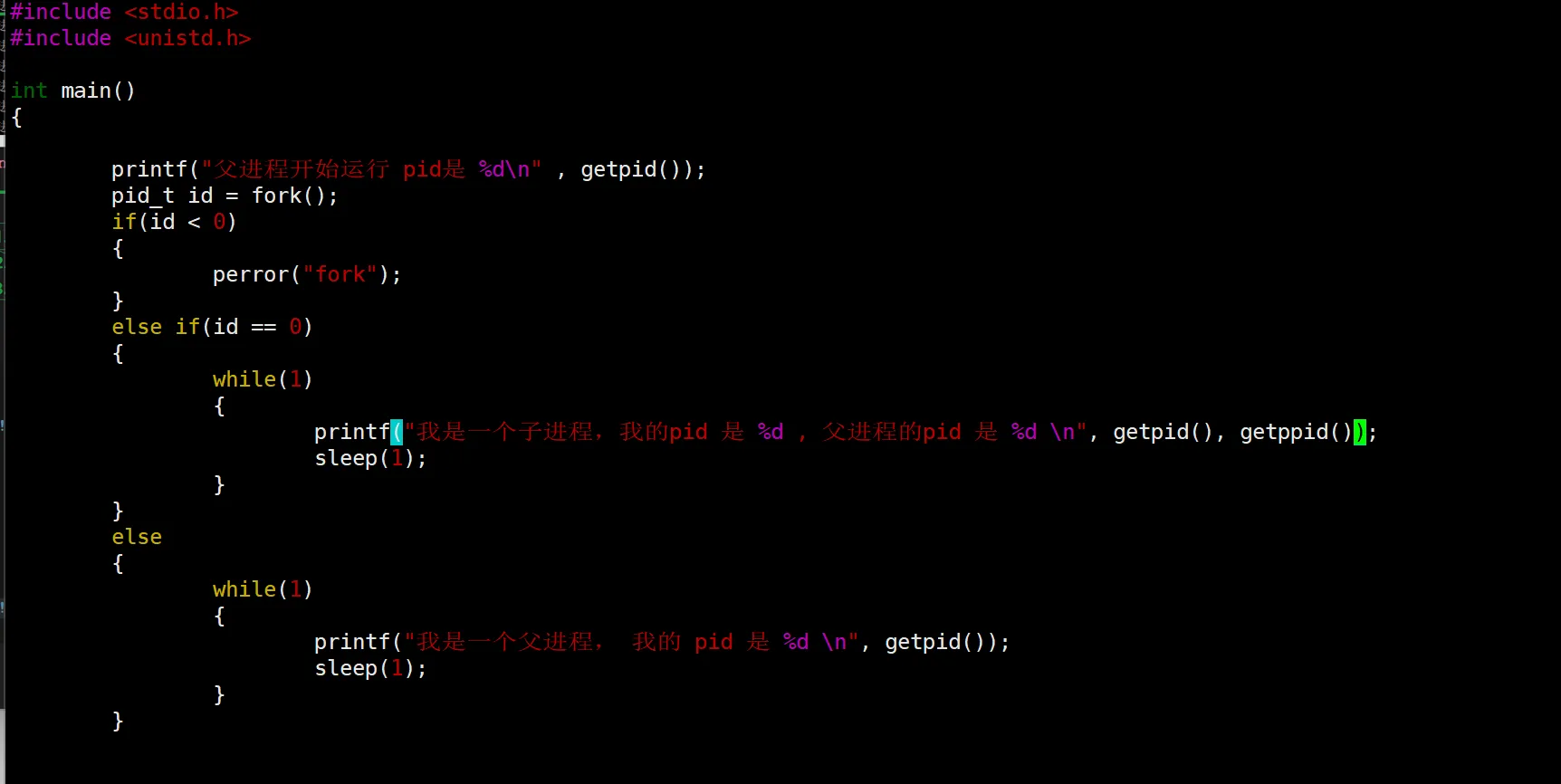
可以看到这里我们用了一个 if else,按照我们以往的经验,这一组语句里面只会执行一个,但是,我们看结果:
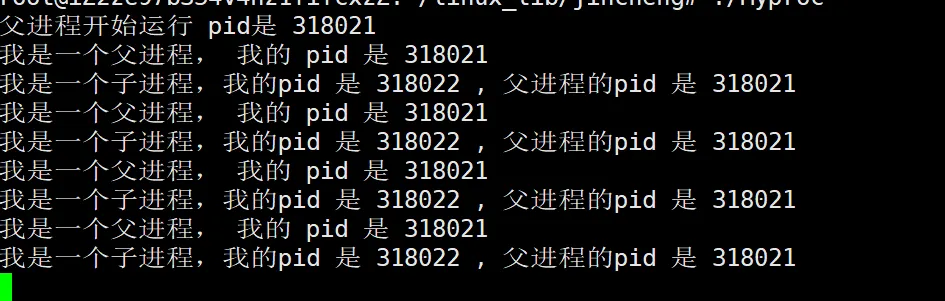
可以看到,这里的if和else都执行了,也就是说,父子进程执行了不同的逻辑,因为fork的返回值是不同的,返回两个值。
到这里,我们总结一下现有的疑问:
首先第一个就是为什么fork给父子返回不同的值,然后是为什么一个函数会返回两次,还有为什么一个变量,既等于零,又大于零,导致if else同时成立。
我们从第一个开始,因为父进程和子进程是一对多的关系,一个父进程会有多个子进程,所以,为了方便父进程管理,要把子进程的pid返回给父进程。
再来解释一下第三个吧,从第三个来看第二个,大家先记住一个结论,就是进程具有独立性。
为什么进程要有独立性,设想一下,如果两个进程没有独立性,黏糊在一起,如果这个进程想用一下 a + b 的结果,但是这个第二个进程正好把这个结果给改了,那肯定是不行的。所以,进程之间必须相互独立。
那么我们是怎么做到的呢?刚才提到过,父子进程共用父进程的代码和数据,代码是只读的,所以没问题。数据是怎么实现独立的呢?答案是写实拷贝,相当于子进程里面拷贝了一份数据,这个子进程改自己的一份,父进程改他自己的一份。
换句话说就是,把父子任何一方进行数据修改的时候,OS把这个被修改的数据在底层拷贝一份,让目标进程修改这个拷贝,这个就是写实拷贝。写实拷贝牵扯到后面许多的知识,这里只是把这个定义抛出来,不做更多解释。
所以,大家明白为什么id在父进程和子进程里面不一样了吧?在执行fork的时候,父进程有一个父进程的id,子进程有一个子进程的id ,因为这个fork的返回值不同,而且父子进程共用代码,所以,父子进程会执行不同的if else,所以这个程序就执行了不同的逻辑。
再来看第二个问题, 就像之前提到过的,如果一个函数走到return了,那它的逻辑就执行完了。
再来看fork函数,fork函数首先要申请一个pcb给子进程,然后拷贝父进程给子进程,因为共用嘛,然后把子进程的pcb孤岛list里面,甚至放到调度队列里面。
怎么实现独立的呢?答案是写实拷贝,相当于子进程里面拷贝了一份数据,这个子进程改自己的一份,父进程改他自己的一份。
换句话说就是,把父子任何一方进行数据修改的时候,OS把这个被修改的数据在底层拷贝一份,让目标进程修改这个拷贝,这个就是写实拷贝。写实拷贝牵扯到后面许多的知识,这里只是把这个定义抛出来,不做更多解释。
所以,大家明白为什么id在父进程和子进程里面不一样了吧?在执行fork的时候,父进程有一个父进程的id,子进程有一个子进程的id ,因为这个fork的返回值不同,而且父子进程共用代码,所以,父子进程会执行不同的if else,所以这个程序就执行了不同的逻辑。
再来看第二个问题, 就像之前提到过的,如果一个函数走到return了,那它的逻辑就执行完了。
再来看fork函数,fork函数首先要申请一个pcb给子进程,然后拷贝父进程给子进程,因为共用嘛,然后把子进程的pcb孤岛list里面,甚至放到调度队列里面。
当fork走到return这个语句的时候, return的本质也是不是在写入变量?当然是的,父进程返回父进程的,子进程返回子进程的,修改两个进程的变量因为有写实拷贝所以得到的id结果也是不同的。