近年来,视觉 - 语言 - 动作模型(Vision-Language-Action Models, VLA) 凭借从互联网尺度视觉 - 语言表征中继承的强大泛化能力,成为机器人具身智能与自主导航的主流技术路线。然而,随着模型规模不断扩大,推理速度与实时控制之间的矛盾愈发尖锐:大参数量 VLA 算力需求极高、推理延迟长,无法直接部署在算力有限的机器人边缘端;若将其放在远端工作站运行,网络通信延迟又会进一步拉长控制周期,导致机器人在动态障碍、遮挡、弱网等真实场景中反应迟钝、极易碰撞。
如何在保留大模型强大语义与视觉理解能力的同时,让机器人在边缘端实现高频、实时、鲁棒的导航控制,成为大模型机器人落地的核心难题。
本文要精读的 AsyncVLA ,正是为解决这一矛盾提出的异步双回路控制框架 。它将大模型的高层语义推理与边缘端的实时动作执行彻底解耦,通过轻量化边缘适配器、动态轨迹加权与端到端联合训练,让机器人在最高 6 秒通信延迟 下仍能稳定导航,在真实动态场景中成功率较现有最优方法提升40%。
原文链接:AsyncVLA: An Asynchronous VLA for Fast and Robust Navigation on the Edge
代码链接:NHirose/AsyncVLA: Official code repository for AsyncVLA project
沐小含持续分享前沿算法论文,欢迎关注...
一、研究背景与问题提出
1.1 大模型 VLA 的能力与困境
视觉 - 语言 - 动作模型(VLA)由大规模视觉 - 语言模型(VLM)在机器人数据上微调而来,能够直接理解语言指令、目标图像、2D 目标位姿等多模态目标,并输出连续动作,在开放世界导航中展现出极强的泛化性。但随着模型规模攀升至数十亿乃至上百亿参数,一系列致命问题随之出现:
- 推理延迟高:大模型无法在 Jetson 等边缘计算平台上实时运行,控制频率被严重拉低。
- 控制回路滞后:动作基于过时观测生成,在动态环境中失去反应能力。
- 通信延迟叠加:远端部署引入 WiFi 波动,延迟可达秒级,直接破坏实时性。
- 功耗与续航受限:边缘端运行大模型功耗过高,大幅缩短机器人工作时间。
1.2 现有解决方案的局限
针对 VLA 部署效率问题,现有研究主要沿三条路径展开:
- 轻量化 / 量化:直接缩小模型或降低精度,虽提升速度,但显著损失语义与视觉能力。
- 异步推理优化:仅能补偿毫秒级推理延迟,无法应对秒级网络波动。
- 快慢双架构:多面向机械臂静态操作,未考虑移动机器人的动态障碍与复杂环境。
这些方法均无法同时满足:大模型能力保留 + 边缘实时执行 + 高网络延迟鲁棒三大要求。
1.3 本文核心科学问题
如何在边缘机器人上部署大规模具身基础模型,同时不受其计算成本与通信延迟的限制?
AsyncVLA 的答案是:构建异步解耦架构,用 "大模型慢决策、小模型快执行" 实现分层控制。
二、核心思想:异步双回路嵌套控制
AsyncVLA 的设计灵感来自认知科学双系统理论 (快系统 / 慢系统)与机器人经典级联分层控制:
- 慢回路(外层):由大规模 VLA 在远端工作站运行,负责高层视觉与语言语义理解。
- 快回路(内层):由超轻量 Edge Adapter 在机器人边缘端运行,负责高频实时动作修正。
推理阶段两者完全异步,训练阶段则通过端到端方式对齐,弥合延迟带来的信息流错位。最终实现:大模型能力不打折、边缘控制低延迟、整体系统抗波动。
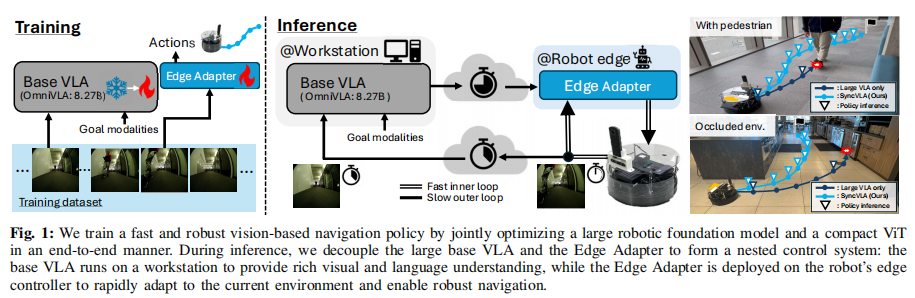
整体流程可概括为:
- 训练:联合优化大尺寸基座 VLA 与轻量化 ViT 结构,以端到端方式学习互补能力。
- 推理:基座 VLA 在工作站低速提供语义指导;Edge Adapter 在机器人端高速融合最新观测,输出安全动作。
这一架构让大模型不再受限于边缘算力,也让轻量模型不再受困于语义理解不足。
三、网络架构
AsyncVLA 基于 OmniVLA(8.27B) 作为基座 VLA,搭配轻量化 Edge Adapter(76M)形成完整架构。
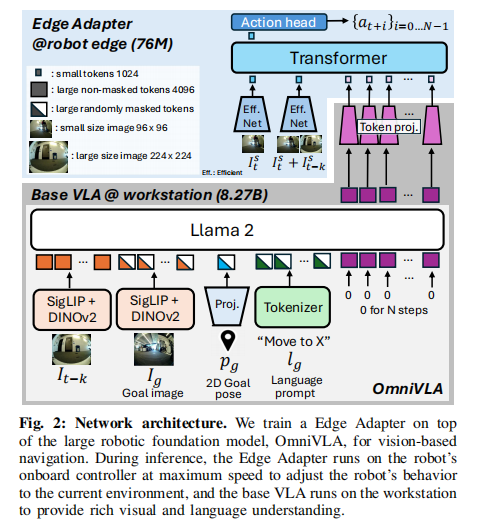
基座 VLA(远端工作站)
- 主干:OmniVLA 多模态导航大模型。
- 视觉编码器:SigLIP + DINOv2,提供强视觉特征。
- 语言编码器:LLaMA 2,理解自然语言指令。
- 输入:语言指令、2D 目标位姿、目标图像、历史观测图像。
- 输出:高维动作 Token 嵌入,经压缩后发送至机器人端。
Edge Adapter(机器人边缘端)
- 视觉编码器:EfficientNet-B0,轻量高效。
- 主干:轻量化 ViT 结构,处理多源 Token 输入。
- 图像分辨率:96×96(仅为基座 VLA 的 1/4)。
- 动作头:4 层 MLP,输出 2D 位姿动作块。
- 部署:NVIDIA Jetson Orin 30W 模式,实时运行。
整体信息流
- 机器人实时采集图像,上传至远端工作站。
- 工作站运行基座 VLA,生成并压缩动作 Token,回传至机器人。
- 机器人缓存历史图像,按时间戳匹配滞后观测。
- Edge Adapter 融合三类输入,生成实时动作。
- 动作经 PD 控制器转换为速度指令,驱动机器人运动。
四、技术原理
AsyncVLA 的核心创新由三大紧密耦合的技术模块构成。
4.1 Edge Adapter 架构设计:延迟感知的轻量实时策略
Edge Adapter 是 AsyncVLA 实现实时性 与抗延迟 的核心组件,论文中将其定义为运行在机器人端、仅 76M 参数的轻量 ViT 策略网络,承担 "将滞后的高层语义指导,校正为当前观测下安全动作" 的关键任务。
4.1.1 延迟问题的形式化定义
论文中明确给出延迟带来的核心矛盾:若系统存在 步延迟 ,机器人执行动作
时,实际依据的是
时刻的观测
,而非当前时刻
的观测
。在动态环境中,这一滞后会直接导致碰撞与任务失败。
Edge Adapter 的设计目标,就是在接收 对应的滞后语义信号前提下,始终输出基于
的最优动作。
4.1.2 多源输入结构
Edge Adapter 共接收三组输入,缺一不可:
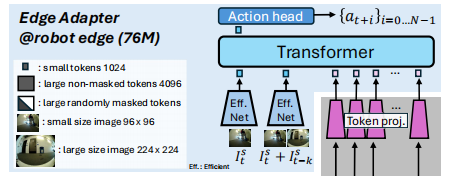
-
基座 VLA 压缩后的动作 Token 嵌入
- 来源:基座 VLA(OmniVLA)最后一层动作特征,经 Token Projector 压缩。
- 信息:包含高层语义、目标理解、全局规划信息,但时间滞后。
- 维度:压缩为 8×1024,适配轻量网络计算。
-
当前时刻低分辨率图像特征
- 分辨率:96×96(远小于基座 VLA 的 224×224)。
- 作用:捕捉机器人当下最实时的局部环境,包括突然出现的行人、动态障碍。
- 编码:由轻量编码器 EfficientNet‑B0 提取为1024 维 Token。
-
时序差分图像特征(
与
- 结构:将当前图像 与滞后图像在通道维度拼接,编码为单一 1024 维 Token。
- 作用:显式建模延迟窗口 t−k, t 内机器人位姿变化、环境动态变化、障碍出现 / 消失。
- 意义:让模型 "知道信号滞后了多少、环境发生了什么变化"。
4.1.3 Token Projector 压缩机制
基座 VLA 原始输出 Token 维度极高:8×4×4096(动作块数量 8,动作本身维度 4, embedding 特征维度 4096),无法直接在边缘端使用。论文专门设计了Token Projector对其进行压缩:
- 结构:两层 MLP ResNet 块。
- 功能:将 4×4096 维 高维嵌入 → 压缩为1024 维。
- 目的:
- 降低边缘设备计算量。
- 减少工作站→机器人的 WiFi 传输数据量。
- 保留语义与动作信息完整性。
4.1.4 动作输出与滞后屏蔽机制
为了彻底杜绝滞后信息污染当前动作,论文在输出层做了关键约束:
- Edge Adapter 输出 N 步动作块 ,但仅将对应当前观测
- 动作头为 4 层 MLP ,输出机器人局部坐标系下的 2D 位姿序列,与 OmniVLA、ViNT 等经典导航模型保持一致。
- 最终动作仅由当前观测主导,滞后语义信息仅作为 "方向指导",不控制实时避障。
4.2 反应性轨迹加权策略:自动强化动态避障行为
论文明确指出:常规数据集里动态避障、急停、避让行人等反应性行为样本极少,直接训练会导致模型在危险场景失效。因此提出自动轨迹加权****(Trajectory Re‑weighting),精准提升关键样本的学习强度。
4.2.1 核心思想
识别出机器人在一个动作块内突然改变行为 的片段(如为了避障急转、减速),并对这些片段提升训练权重。
4.2.2 严格数学定义
-
从训练数据中提取两组动作块参考:
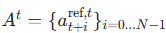 :
: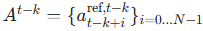 :
:
-
判定规则:若两段轨迹最终位姿的欧氏距离 超过预设阈值
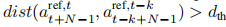
-
加权策略:
- 满足上式 → 大幅提升该样本权重。
- 论文实验中
- 同时对 SACSoN 数据集中含行人的帧做额外优先采样,强化社交导航能力。
4.2.3 设计目的
- 让模型优先学习避障、急停、避让行人等安全关键行为。
- 解决真实导航数据中动态交互样本稀疏的问题。
- 使 Edge Adapter 在突发障碍面前具备人类级反应速度。
4.3 两阶段端到端训练:对齐异步双模型信息流
AsyncVLA 由基座 VLA(慢)与 Edge Adapter(快)两个异步模块组成,必须通过联合训练 实现语义对齐,否则会出现 "指导滞后、动作混乱" 的问题。论文采用两阶段训练 + 统一损失函数,完全遵循可微端到端机制。
4.3.1 模型前向传播公式
-
基座 VLA 前向:
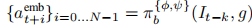
- 输出:动作 Token 嵌入。
-
Edge Adapter 前向:
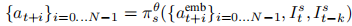
- 输入:滞后 Token、当前图像、滞后图像。
- 输出:最终可执行动作块。
4.3.2 整体训练损失函数
总损失为模仿损失 与动作平滑损失之和:
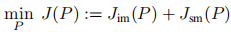
-
模仿损失
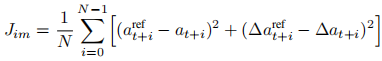
- 第一项:监督绝对位姿 ,保证朝向目标。
- 第二项:监督相对位移,保证局部动作精准、反应快速。
-
动作平滑损失
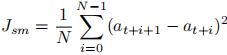
- 约束动作连续无突变,提升机器人运动平稳性与安全性。
4.3.3 两阶段训练流程
-
第一阶段:固定基座 VLA,训练 Adapter 与 Projector
- 初始化:
- 训练:
- 目的:不破坏大模型能力,让小模型先学会 "校正滞后信号"。
- 初始化:
-
第二阶段:全模型端到端微调
- 解冻
- 目的:深度对齐快慢回路,让基座 VLA 的输出更适配 Edge Adapter 的校正机制。
- 训练技巧:对基座 VLA 使用LoRA,仅训练~5% 参数,节省显存并提升稳定性。
- 解冻
五、系统部署与异步推理流程
5.1 硬件部署方案
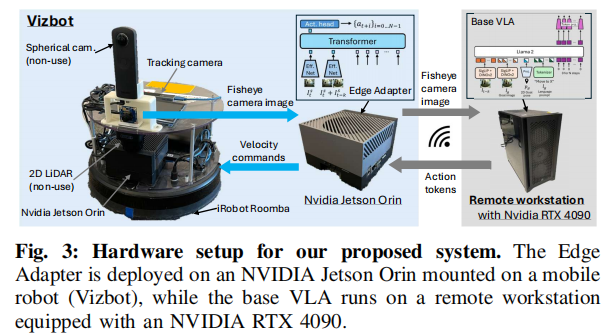
- 远端工作站:配备 NVIDIA RTX 4090,运行基座 VLA,推理频率约 5Hz。
- 机器人平台:Vizbot 移动机器人,搭载 NVIDIA Jetson Orin,运行 Edge Adapter,推理频率 8Hz。
- 通信方式 :WiFi,实际延迟在0.28 秒~6 秒之间剧烈波动。
5.2 异步推理算法(Algorithm 1)

系统采用双循环异步执行:
- 边缘端高频循环:持续采集最新图像、缓存历史帧、接收 Token、计算动作、下发速度指令。
- 工作站低频循环:接收滞后图像、运行基座 VLA 推理、回传压缩 Token 与时间戳。
通过时间戳匹配与图像缓存,系统能够稳定处理大幅波动的网络延迟。
六、实验设计与结果分析
AsyncVLA 在真实机器人平台上开展了全面的定量与定性实验,验证其在位姿导航、语言导航、动态障碍、高延迟等场景下的优势。
6.1 实验任务
- 2D 位姿条件导航:目标距离 12~30 米,覆盖室内 / 室外、杂乱环境、行人干扰场景。
- 语言条件导航:目标距离 5~20 米,包含分布外(OOD)复杂指令。
6.2 对比基线
- OmniVLA-edge:108M 轻量版,纯边缘运行。
- OmniVLA:8.26B 完整版,纯远端运行。
- Ours w/o E2E:无 antry 端到端训练的 AsyncVLA。
- Ours (workstation):全模型置于远端,无边缘解耦。
6.3 评估指标
- SR(Success Rate)↑:无碰撞到达目标的成功率
- Time ↓:到达目标平均耗时(秒)
- Static Col. ↓:平均静态障碍物碰撞次数
- Dynamic Col. ↓:平均动态行人碰撞次数
- Lan. follow ↑:语言指令遵循成功率(含 OOD 指令)
6.4 核心定量结果
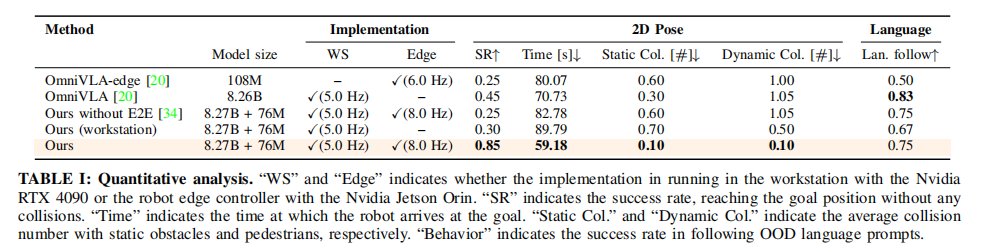
关键结论:
- AsyncVLA 成功率达到 0.85 ,较最优基线 OmniVLA 提升 40%,验证异步架构的显著优势。
- 静态碰撞、动态碰撞均降至最低(0.10),证明 Edge Adapter 可实时处理突发障碍与延迟干扰。
- 耗时最短(59.18s),说明系统不会因避障过度绕路,规划更高效。
- 语言遵循率保持 0.75,接近大模型 OmniVLA(0.83),远高于轻量模型,说明完整保留语义能力。
各基线失效原因分析:
- OmniVLA-edge:模型太小,语义与环境理解不足,频繁撞障。
- OmniVLA:大模型远端推理延迟高,动作基于过时观测,动态环境几乎必撞。
- Ours w/o E2E:无双阶段端到端对齐,大模型与小模型特征错位,校正失效。
- Ours (workstation):无边缘解耦,受网络延迟影响极大,反应迟缓。
6.5 延迟鲁棒性实验

研究团队人工设置0.2s、2.0s、5.0s三档工作站延迟:
- 随着延迟升高,OmniVLA 性能快速崩塌,频繁碰撞、偏离路径。
- AsyncVLA 在5 秒高延迟下仍保持高成功率,轨迹稳定、避障及时。
这一结果证明,AsyncVLA 从架构层面具备抵抗通信波动的能力。
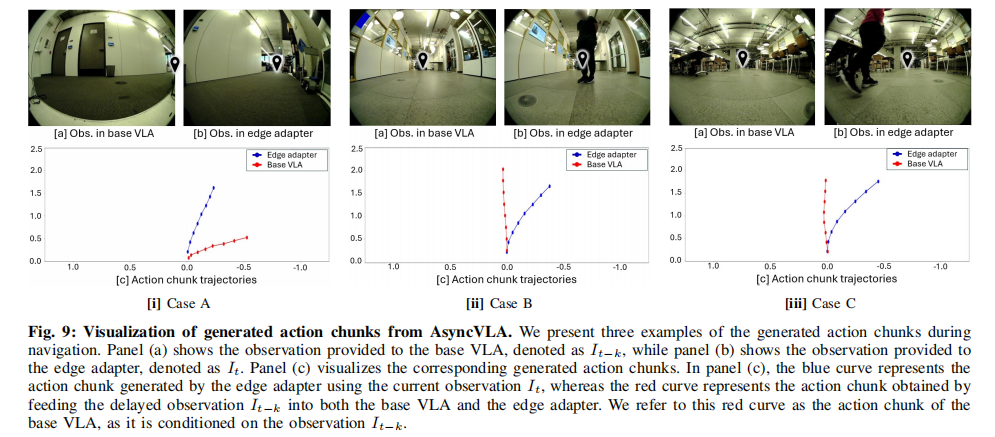
6.6 动态避障与语言导航可视化
-
行人避让:AsyncVLA 可主动礼让行人,安全通过;OmniVLA 因延迟直接碰撞。

-
语言导航:AsyncVLA 保留大模型语义能力,能准确执行复杂语言指令,显著优于轻量模型。

-
动作块校正: Edge Adapter 会主动偏离不安全的原始轨迹,实时修正避障,而不破坏整体目标方向。
七、结论、局限与未来展望
7.1 核心贡献总结
- 提出 AsyncVLA 异步控制框架,首次将大 VLA 的语义推理与边缘实时执行彻底解耦。
- 设计 76M 超轻量 Edge Adapter,在边缘端实现高频、低耗、稳健的动作校正。
- 提出 动态反应轨迹加权策略,强化动态障碍避让等关键行为。
- 设计 两阶段端到端训练,对齐快慢双回路信息流。
- 在真实机器人上验证:6 秒延迟下仍稳健导航,成功率较 SOTA 提升 40%。
7.2 研究局限
- 依赖可端到端微调的开源 VLA 权重,适配闭源模型难度较高。
- 现有动态交互数据量仍有限,限制极端场景性能。
7.3 未来研究方向
- 进一步解耦基座 VLA 与 Edge Adapter,实现仅训练 Edge Adapter 即可快速适配新平台。
- 引入人类视频等大规模数据,扩充动态交互训练样本。
- 扩展至多机器人协同、室外非结构化地形、长距离导航等复杂场景。
<工程落地启示>
- 大模型不必上车:语义推理放在远端,实时控制放在边缘,是性价比最高的部署方案。
- 延迟不可怕,架构可补偿:通过训练对齐与双回路设计,秒级延迟依然可控。
- 动态样本必须加权:导航模型的安全性,取决于对 rare 应急行为的学习程度。
- 边缘小模型够用:轻量 ViT + 低分辨率图像足以完成实时校正,不必追求大而全。
- 弱网环境优先架构优化:比单纯提升网络质量更可靠、成本更低。