最近在几个项目中都用到了LoRA,所以决定回来读一下这篇经典...
2021年,在通用预训练 + 下游任务适配 已经成为自然语言处理领域的标准范式背景下,微软团队提出了LoRA(Low-Rank Adaptation),以极简优雅的设计,彻底改写了大模型高效微调的格局,成为如今几乎所有大模型部署与适配的标配技术。
大模型预训练后适配下游任务,是 NLP 落地的关键环节。但全参数微调需要更新全部权重,在 GPT-3 175B 这类超大规模模型上,会带来难以承受的存储、显存与部署成本。为破解这一难题,文章提出低秩适配(LoRA) 方法:
- 冻结预训练模型全部权重,仅在 Transformer 层中注入可训练的低秩分解矩阵,大幅削减下游适配的参数量;
- 在 GPT-3 175B 场景下,可训练参数减少10000 倍 ,显存占用降低3 倍,训练效率显著提升;
- 在 RoBERTa、DeBERTa、GPT-2、GPT-3 等一系列模型上,效果持平甚至超越全参数微调;
- 相比 Adapter 类方法,无额外推理延迟;相比 Prompt Tuning,不占用有效序列长度、优化更稳定;
- 从实验角度验证:语言模型在适配过程中,权重更新本身具有极低的本征秩,为 LoRA 的有效性提供了坚实依据。
原文链接:2106.09685 LoRA: Low-Rank Adaptation of Large Language Models
沐小含持续分享前沿算法论文,欢迎关注...
一、大模型微调的困局与破局思路
(一)全参数微调的三大致命痛点
过去,预训练模型配合全参数微调,在小模型时代高效且稳定。但当模型规模攀升至百亿、千亿级别,痛点被无限放大,主要体现在:
- 存储成本爆炸:每适配一个任务,就要保存一份完整模型权重,GPT-3 175B 单任务存储就高达数百 GB,多任务部署几乎不可行;
- 显存需求天价 :使用 Adam 等自适应优化器时,需要同时存储参数、梯度、动量、方差,GPT-3 训练显存占用可达1.2TB,普通硬件完全无法支撑;
- 部署极其僵硬:任务切换需要加载完整模型权重,切换成本高、速度慢,无法满足在线服务快速迭代的需求。
(二)现有高效适配方案的先天缺陷
为降低微调成本,学界先后提出下面两类主流方案,但都存在无法回避的短板:
- Adapter 层 :在 Transformer 模块中插入小型子网络,仅训练少量参数。但 Adapter 是串行结构 ,推理时必须额外计算,会引入不可消除的延迟,在小批量、短序列的在线场景中,延迟增幅最高可达30%;
- Prompt Tuning(Prefix/Soft Prompt) :仅优化输入侧的连续提示向量,不改动模型主体。但这类方法极难优化,性能随参数变化非单调增长,同时会挤占输入序列长度,压缩模型处理任务的有效空间。
正如文中所言,现有方案都被迫在效率与性能 之间做妥协,而 LoRA 的目标,是彻底跳出这一权衡,同时实现高效率、高性能、零推理延迟。
(三)LoRA 的核心灵感与创新假设
LoRA 的思想源于一个关键发现:过参数化的深度网络,其学习到的权重分布天然落在低维子空间中。
基于此,论文提出了核心思想:
深度神经网络中大量的全连接层(dense layer) 都执行矩阵乘法运算,这些层的预训练权重矩阵
通常是满秩的。但在下游任务适配时,权重的增量
这一思想,成为 LoRA 极简设计、高效性能的根本来源。
二、问题定义:用极小参数表示大模型的适配变化
文中将预训练自回归语言模型表示为:
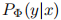
其中 是模型全部参数。传统全微调会将参数从
更新为
,优化目标为:
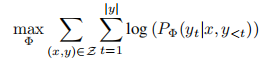
的规模与原模型完全一致,这正是成本高昂的根源。
LoRA 的目标非常明确:用一组远小于原模型规模的小参数集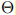 ,来表示适配所需的参数更新
,来表示适配所需的参数更新 ,即
 , 优化目标调整为:
, 优化目标调整为:
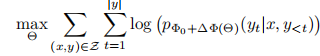
在 GPT-3 175B 场景中, 的规模可以低至原模型的0.01%,用极小的代价实现高质量适配。
三、LoRA 核心技术原理
3.1 核心结构与示意图
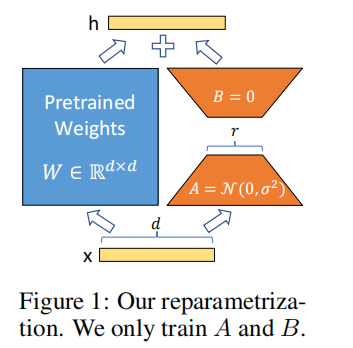
LoRA 重参数化结构: 预训练权重
3.2 数学定义与公式推导
设某一层的预训练权重矩阵为: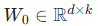
在全微调中,权重会被更新为: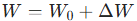 ,其中
,其中 与
同维度,是满秩、高参数量的矩阵。
LoRA 对增量 做低秩分解约束:
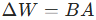 ,其中:
,其中:
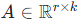
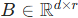
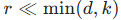 :LoRA 的秩,是一个远小于模型维度的超参数(如 1、2、4、8)
:LoRA 的秩,是一个远小于模型维度的超参数(如 1、2、4、8)
因此,LoRA 下的权重为: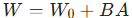
对应的前向传播公式: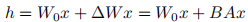
- 两者逐元素相加,得到最终输出
整个过程中, 始终冻结,不参与梯度更新 ,只有
、
两个矩阵可训练。
3.3 初始化规则
为了让 LoRA 在训练开始时不破坏预训练模型的输出分布,论文设定了明确的初始化方式:
- 矩阵 A :使用高斯分布随机初始化
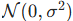
- 矩阵 B :初始化为全零矩阵
这意味着:训练初始阶段 ,模型输出与原始预训练模型完全一致,训练稳定、无偏移。
3.4 缩放因子 / :稳定训练、简化调参的关键设计
这是文中的一个关键缩放技巧 ,用于平衡不同秩 下的输出尺度:
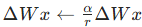
其中:
在使用时,论文中明确说到:
使用 Adam 优化器时,只要初始化尺度合适,调整
这一设计的意义:
- 避免因
- 大幅减少超参搜索成本;
- 让不同秩的 LoRA 模型可以在相近学习率下稳定训练。
3.5 与全微调的关系:LoRA 是更泛化的适配形式
LoRA 是全参数微调的一种泛化形式,而非简化版。
- 当把 LoRA 应用到所有权重矩阵 ,并将秩
- Adapter 类方法最终只能收敛到一个 MLP 结构,表达能力受限;
- Prefix 类方法会损失序列长度,无法处理长文本。
这从理论上保证了LoRA 不会因为低秩约束而损失表达上限。
3.6 零推理延迟的理论保证:权重可融合
这是 LoRA 最关键的工程性质,论文给出严格结论:
部署时可将
融合后:
推理时直接使用 ,与全微调模型计算图完全相同。
任务切换时:
- 用
- 加上
整个过程仅涉及矩阵加减,速度极快、存储开销极小。
3.7 LoRA 在 Transformer 中的具体应用位置
作者团队在经过大量的 ablation 实验后指出,只在 Transformer 自注意力层的投影矩阵上使用 LoRA是最优的,包括:
同时:
- MLP 层全部冻结
- LayerNorm 层全部冻结
- 偏置项全部冻结
3.8 可训练参数量计算公式
当只对注意力层施加 LoRA 时,每层可训练参数总量为: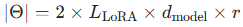
符号含义:
- 乘 2:因为每个 LoRA 模块包含 A、B 两个矩阵
以 GPT-3 175B 为例:
- 仅对
- 总层数 96
可训练参数仅约:35MB ,相比原模型缩小10000 倍。
四、LoRA 的核心优势与局限
(一)四大不可替代的优势
- 极致的参数与显存节省GPT-3 175B 场景下,可训练参数减少 10000 倍,训练显存从 1.2TB 降至 350GB,模型 checkpoint 从 350GB 压缩至 35MB。
- 训练速度更快 无需计算冻结参数的梯度,也无需维护大量参数的优化器状态,GPT-3 训练吞吐量提升25%。
- 真正的零推理延迟权重可提前融合,推理行为与全微调模型完全一致,不增加任何计算开销。
- 多任务部署灵活低成本共享一个基座模型,仅切换不同任务的 LoRA 权重,就能实现秒级任务切换,大幅降低服务成本。
(二)客观存在的局限
- 权重融合后,单批次无法同时处理不同任务的样本;
- 极端跨域任务(如语言完全切换),过小的秩
五、实验验证:从小模型到千亿模型全覆盖
文章在自然语言理解(NLU)、自然语言生成(NLG)、超大规模模型三个维度,进行了最全面的对比验证,覆盖 RoBERTa、DeBERTa、GPT-2、GPT-3 175B 等主流模型。
(一)对比基线说明
- FT:全参数微调(黄金标准);
- BitFit:仅训练偏置项;
- AdapterH/AdapterL/AdapterP:不同结构的 Adapter 微调;
- PrefixEmbed/PrefixLayer:两类提示微调方法;
- LoRA:本文提出的低秩适配。
(二)NLU 任务:GLUE 基准实验
在 RoBERTa Base/Large、DeBERTa XXL 上的 GLUE benchmark 结果显示:
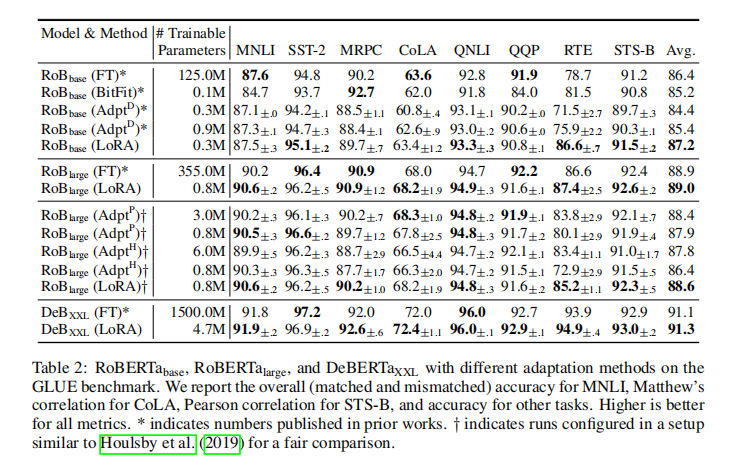
- LoRA 仅用0.3M~4.7M 参数 ,效果就超过或持平全参数微调(参数量相差数百倍);
- 同参数规模下,LoRA 大幅领先 Adapter、BitFit 等所有基线;
- 即便在 15 亿参数的 DeBERTa XXL 上,LoRA 依然保持稳定优势。
(三)NLG 任务:GPT-2 生成任务
在 E2E NLG Challenge、WebNLG、DART 等生成任务中:
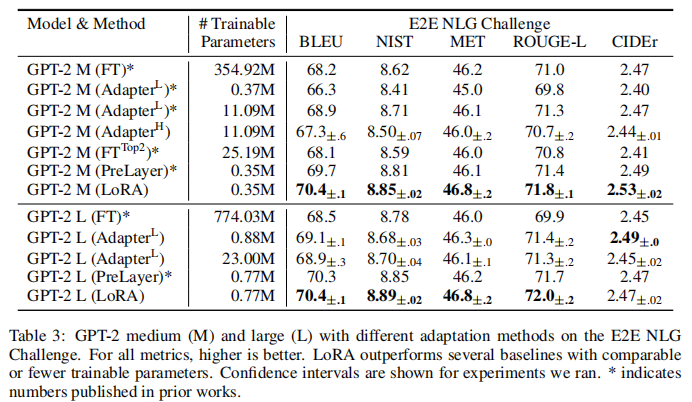
- LoRA 在 BLEU、NIST、ROUGE-L、CIDEr 等核心指标上全面领先所有对比方法;
- 可训练参数仅 0.35M~0.77M,远小于全微调的数亿参数,实现了 "小参数、强生成"。
(四)终极压力测试:GPT-3 175B
在 WikiSQL、MNLI、SAMSum 三大任务上,LoRA 展现了压倒性优势:
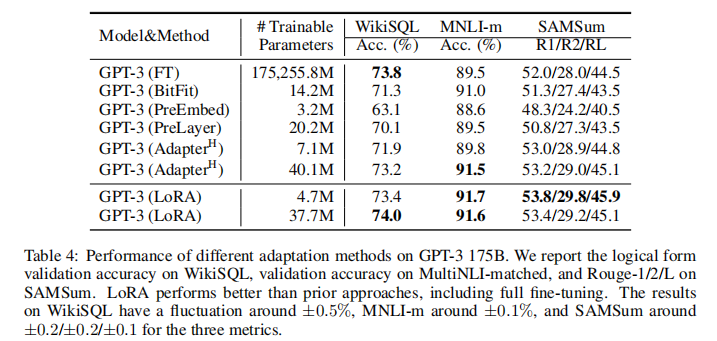
- 仅用4.7M 参数 (不足原模型的 0.002%),效果超越全参数微调;
- 相比 Adapter、Prompt Tuning,在各项指标上均取得最优成绩;
- 训练成本、显存占用、速度全面优于传统方案,成为千亿模型适配的最优解。
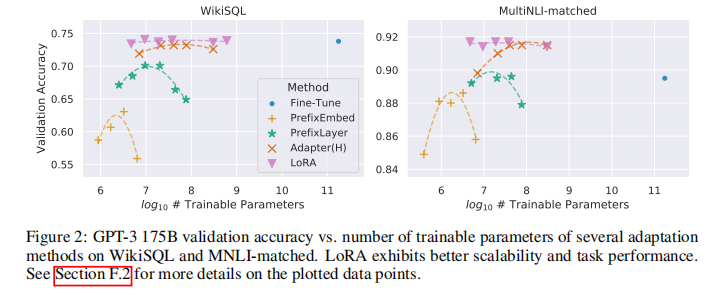
从参数 - 性能曲线可以清晰看到:LoRA 在所有方法中斜率最优,参数量越少,相对优势越明显。
六、低秩更新的内在机理剖析
为了充分解释LoRA为什么 "效果好",文章从数学与实证角度,通过对三个核心问题进行剖析来揭示 LoRA 有效的本质。
(一)Transformer 中哪些权重最适合加 LoRA?
固定参数预算为 18M,对比不同权重组合的效果:
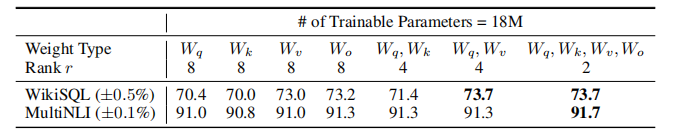
- 仅适配
- 同时适配
- 同时适配
工程结论 :只对注意力层的 、
投影矩阵加 LoRA,性价比最高。
(二)最优秩 到底有多小?
实验给出了颠覆认知的结果:
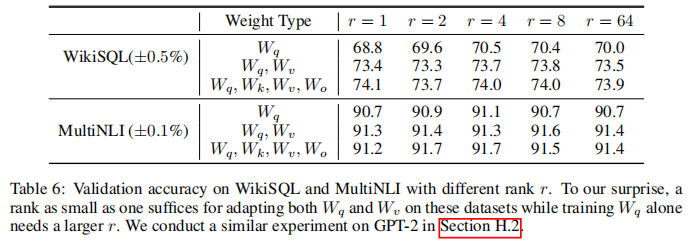
- 即便在 GPT-3 175B 这种超大规模模型上,极小的秩就足以表达任务适配所需的权重更新;
- 直接证实:大模型适配的权重更新
(三) 与原权重 的关系:放大被忽略的任务特征
通过奇异值分解与子空间投影分析,论文发现:

- 放大倍数极高:
这意味着:大模型预训练时已经学到了任务所需的大部分知识,适配只需要强化极少数关键特征方向,而 LoRA 精准做到了这一点。
七、结论与未来研究方向
(一)核心结论
LoRA 以极简的低秩更新设计,完美解决了大模型适配的三大痛点:
- 冻结预训练权重,仅训练低秩矩阵,成本降低万倍;
- 权重可融合,零推理延迟,部署友好;
- 效果超越全微调,适配稳定、通用性强;
- 从实证角度验证了大模型适配的低秩本质,为后续高效微调研究提供了核心思路。
(二)未来研究方向
- 将 LoRA 与其他高效微调方法深度融合,进一步提升性能;
- 深入研究微调与 LoRA 的特征演化机制,揭开大模型适配的底层逻辑;
- 设计自动化策略,智能选择适配层与最优秩
- 探索预训练权重本身的低秩性,实现模型压缩与适配一体化。
全文总结
LoRA(2106.09685)是大模型高效微调领域的里程碑式工作,它没有复杂的结构设计,仅依靠 "低秩更新" 这一朴素思想,就破解了全微调成本高、Adapter 有延迟、Prompt 难优化的行业难题。如今,LLaMA、Qwen、GLM、Baichuan 等几乎所有主流开源大模型,都已原生支持 LoRA,足以证明这篇论文的前瞻性与实用性。