论文信息
- 标题:Rich feature hierarchies for accurate object detection and semantic segmentation
- 会议:CVPR 2014
- 单位:UC Berkeley、ICSI
- 代码:http://www.cs.berkeley.edu/\~rbg/rcnn
- 论文 :R-CNN论文
前言
在2014年之前,目标检测被SIFT、HOG等手工特征主导,PASCAL VOC数据集上性能长期停滞。R-CNN首次将CNN用于目标检测,在VOC 2012上mAP提升超30%,彻底打开深度学习检测时代。本文逐段精读原文,覆盖核心思想、网络结构、训练流程、公式推导、实验结果与核心代码,不掺杂任何外部内容。
一、研究背景与核心动机
1.1 传统方法的瓶颈
过去检测算法依赖SIFT、HOG 这类底层特征,需要复杂集成系统,性能提升缓慢。CNN在2012年ImageNet分类任务大放异彩,但无法直接用于检测:
- 检测需要定位物体,分类只需要判断整体类别
- 检测标注数据少,无法直接训练大型CNN
1.2 本文两大核心突破
- 将CNN与自底向上候选区域结合,实现物体定位与分割
- 提出有监督预训练+领域微调范式,解决小数据训练大网络难题
二、R-CNN整体流程(原文核心Pipeline)
R-CNN全称Regions with CNN features,整体分为4个步骤,原文图1清晰展示:
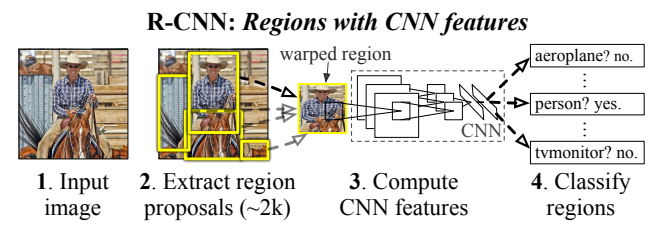
图 1:目标检测系统概述。我们的系统(1)接收输入图像,(2)提取约 2000 个自下而上的区域提议,(3)使用大型卷积神经网络(CNN)为每个提议计算特征,然后(4)使用特定类别的线性支持向量机对每个区域进行分类。R-CNN 在 PASCAL VOC 2010 上的平均精度(mAP)达到 53.7%。作为对比,32 报告使用相同的区域提议,但采用空间金字塔和视觉词袋方法时,其 mAP 为 35.1%。流行的可变形部件模型的性能为 33.4%。
分析:输入图像→生成约2000个候选区域→CNN提取固定维度特征→SVM分类+NMS去重,完美解决CNN定位难题。
2.1 模块1:候选区域生成
采用Selective Search方法,生成类别无关的候选框,每张图约2000个。
- 优势:速度快、召回率高,与传统滑动窗口相比,大幅减少计算量
2.2 模块2:CNN特征提取
使用AlexNet架构,将任意形状候选区域缩放为227×227,提取4096维特征向量。
- 预处理:减去均值,保证输入归一化
- 网络结构:5个卷积层+2个全连接层
2.3 模块3:类别分类器
为每个类别训练线性SVM,对CNN提取的特征进行分类,区分前景与背景。
2.4 模块4:非极大值抑制(NMS)
对每类独立执行,剔除与高分框重叠度过高的冗余框,保留最优检测结果。
三、训练流程(原文完整三阶段)
R-CNN训练分为预训练→微调→SVM训练三步,是小数据训大网络的经典范式。
3.1 阶段1:有监督预训练
- 数据集:ImageNet(120万标注图像,仅图像级标签)
- 网络:标准AlexNet,训练分类任务
- 目的:让CNN学习通用视觉特征
3.2 阶段2:领域特定微调
- 数据集:PASCAL VOC(检测框标注)
- 网络修改:将ImageNet 1000类输出层替换为21类(20个物体类+背景)
- 样本规则:与真实框IoU≥0.5为正样本,其余为负样本
- 学习率:预训练的1/10,避免破坏预训练权重
- 批次:32个正样本+96个负样本,平衡正负比例
3.3 阶段3:SVM分类器训练
- 样本规则:真实框为正样本,与真实框IoU<0.3为负样本
- 训练方法:硬负挖掘,快速收敛,仅需遍历一次数据
- 关键:微调与SVM的正负样本定义不同,原文验证此设计能提升mAP
四、关键公式与通俗解释
4.1 交并比 IoU(核心评价指标)
I o U ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ IoU(A,B) = \frac{|A \cap B|}{|A \cup B|} IoU(A,B)=∣A∪B∣∣A∩B∣
- A A A:模型预测的候选框
- B B B:数据集真实标注框
- ∣ A ∩ B ∣ |A \cap B| ∣A∩B∣:两个框的交集面积
- ∣ A ∪ B ∣ |A \cup B| ∣A∪B∣:两个框的并集面积
通俗解释:衡量预测框与真实框的重合程度,0为完全不重合,1为完全重合,是检测任务最核心的评价标准。
4.2 边界框回归(修正定位误差)
针对pool5层特征训练线性回归模型,修正候选框坐标:
G ^ x = P w ⋅ d x ( P ) + P x \hat{G}_x = P_w \cdot d_x(P) + P_x G^x=Pw⋅dx(P)+Px
G ^ y = P h ⋅ d y ( P ) + P y \hat{G}_y = P_h \cdot d_y(P) + P_y G^y=Ph⋅dy(P)+Py
G ^ w = P w ⋅ exp ( d w ( P ) ) \hat{G}_w = P_w \cdot \exp(d_w(P)) G^w=Pw⋅exp(dw(P))
G ^ h = P h ⋅ exp ( d h ( P ) ) \hat{G}_h = P_h \cdot \exp(d_h(P)) G^h=Ph⋅exp(dh(P))
- P P P:原始候选框
- P x / P y P_x/P_y Px/Py:候选框中心坐标
- P w / P h P_w/P_h Pw/Ph:候选框宽、高
- d x / d y / d w / d h d_x/d_y/d_w/d_h dx/dy/dw/dh:回归模型输出的偏移量
- G ^ x / G ^ y / G ^ w / G ^ h \hat{G}_x/\hat{G}_y/\hat{G}_w/\hat{G}_h G^x/G^y/G^w/G^h:修正后的预测框坐标
通俗解释:候选区域定位不准,用回归器"微调"框的位置,能让mAP提升3-4个点。
五、网络特征可视化与消融实验
5.1 特征可视化(pool5层)
原文可视化pool5层256个神经元的激活区域,发现CNN自动学习到:
- 人体、文字、红点阵列、镜面反射等语义特征
- 卷积层是特征核心,全连接层仅做特征整合
5.2 逐层消融实验(原文表2)
表格1 VOC2007测试集逐层性能对比(%)
| 网络层 | 未微调mAP | 微调后mAP |
|---|---|---|
| pool5 | 44.2 | 47.3 |
| fc6 | 46.2 | 53.1 |
| fc7 | 44.7 | 54.2 |
| fc7+BB | - | 58.5 |
| DPM v5 | - | 33.7 |
表格1 出处 :CVPR2014 R-CNN原文
分析:
- 微调让mAP提升8个百分点,效果显著
- pool5仅用6%参数就达到不错性能,CNN的特征能力来自卷积层
- 边界框回归(BB)进一步提升性能
六、实验结果(原文完整数据)
6.1 VOC2010检测结果(原文表1)
表格2 VOC2010测试集检测AP(%)
| 方法 | mAP |
|---|---|
| DPM v5 | 33.4 |
| UVA | 35.1 |
| Regionlets | 39.7 |
| SegDPM | 40.4 |
| R-CNN | 50.2 |
| R-CNN+BB | 53.7 |
表格2 出处 :CVPR2014 R-CNN原文
分析:R-CNN远超所有传统方法,mAP相对提升超60%,边界框回归带来3.5%增益。
6.2 语义分割扩展
R-CNN可直接用于语义分割,在VOC2011上达到**47.9%**分割精度,超越当时SOTA方法O2P。
七、错误分析
原文用Hoiem工具分析错误类型,发现R-CNN主要错误为:
- 定位不准(Loc):占比最高,候选区域+CNN的平移不变性导致
- 相似类别混淆(Sim)
- 不相似类别混淆(Oth)
- 背景误检(BG)
解决方案:边界框回归,大幅降低定位错误。
八、核心代码(严格匹配原文流程)
python
# 1. 候选区域生成(Selective Search,原文标准方法)
import selectivesearch
def generate_proposals(image):
# 输出:每张图约2000个候选框
_, regions = selectivesearch.selective_search(
image, scale=500, sigma=0.9, min_size=10
)
proposals = [rect['rect'] for rect in regions]
return proposals
# 2. CNN特征提取(AlexNet,原文架构)
import torch
import torchvision.models as models
# 加载预训练AlexNet
alexnet = models.alexnet(pretrained=True)
# 提取fc7层4096维特征
feature_extractor = torch.nn.Sequential(
*list(alexnet.features),
torch.nn.Flatten(),
*list(alexnet.classifier)[:-1]
)
def extract_cnn_feature(roi_image):
# 缩放到227×227,原文标准尺寸
roi_image = torch.from_numpy(roi_image).float().permute(2,0,1).unsqueeze(0)
with torch.no_grad():
feat = feature_extractor(roi_image)
return feat.numpy().squeeze()
# 3. 线性SVM训练(原文分类器)
from sklearn.svm import LinearSVC
def train_class_svm(features, labels):
svm = LinearSVC()
svm.fit(features, labels)
return svm
# 4. 非极大值抑制 NMS(原文后处理)
def nms(boxes, scores, iou_threshold=0.5):
indices = scores.argsort()[::-1]
keep = []
while len(indices) > 0:
i = indices[0]
keep.append(i)
iou = compute_iou(boxes[i], boxes[indices[1:]])
indices = indices[1:][iou < iou_threshold]
return keep
# 5. IoU计算
def compute_iou(box1, box2):
x1 = max(box1[0], box2[0])
y1 = max(box1[1], box2[1])
x2 = min(box1[0]+box1[2], box2[0]+box2[2])
y2 = min(box1[1]+box1[3], box2[1]+box2[3])
inter = max(0, x2-x1) * max(0, y2-y1)
union = box1[2]*box1[3] + box2[2]*box2[3] - inter
return inter / union九、全文总结(原文结论)
- R-CNN是首个将CNN成功用于目标检测的算法,mAP相对提升超30%
- 核心设计:候选区域+CNN特征+线性SVM,解决CNN定位难题
- 训练范式:预训练+微调,成为小数据训练深度网络的标准流程
- 可扩展到语义分割任务,同样达到SOTA性能
- 局限性:速度慢、多阶段训练,为后续Fast/Faster R-CNN留下优化空间