前言:排序算法算是我们大多数人接触到的第一个算法了就比如大一上C语言教的冒泡排序,算是梦开始的地方了,排序算法除了冒泡排序还有很多种有像冒泡一样简单的也有一些难度比较高的比如快速排序、希尔排序等等。还需要注意的是我们学习排序不一定非要关注它有没有用,有些排序算法虽然相比其他排序比较慢但是还是很有教育意义的可以扩宽我们的思维
下面的排序我都以排升序为目标讲解,反过来也是一样的原理
1.插入类排序
1.1直接插入排序
相信大家都玩过扑克牌的斗地主模式,当发完牌了之后我们会整理牌方便后面的对局,如果按从左往右的顺序小的牌放在左边时我们遇到一张位置不合法的牌时我们会让这张牌从它原本的位置向左依次和左边的牌作比较,当遇到比它小的牌时我们就在那张比较大的牌后面插入那张不合法的牌:
而我们的插入排序的核心思想就很像这个过程,我们来看看插入排序的动图演示这个排序其实是比较简单的排序,但对我们理解后面比较难的希尔排序有很大的铺垫作用:
插入排序的核心思想就是假设一个指针从左往右开始遍历数组的元素,在遍历的过程我我们要保证指针左边的区间是有序的?相信这幅动图已经非常的直观了那就是每遍历到一个元素我们让这个元素从右往左依次与指针左边的元素做比较,假如我们想要一个 升序的序列那当我们从右往左遍历到比这个不合法的元素小的元素时我们就把这个不合法的元素插入到这个元素的右边让这个元素给合法起来。
下面是代码演示:
cpp
//插入排序
void InsertSort(SortDataType* a, int n)
{
assert(a);
for (int i = 0; i < n - 1; i++)
{
//指针指向的位置
int end = i + 1;
//保存它原本的值因为后面移动大的元素会被覆盖
int tem = a[end];
while (end > 0)
{
//升序
if (a[end - 1] > tem)
{
a[end] = a[end - 1];
end--;
}
else
{
//满足就退出
break;
}
}
a[end] = tem;
}
}很明显当未排序前的数列是逆序(从大到小)时是最坏的情况,因此我们可以分析出这个算法的时间复杂度为1 + 2 + 3 。。。 +(n - 1) 次也也就是n * (n - 1) / 2才能让数列重新有序,所以时间复杂度为 O (n ^ 2),就时间复杂度而言这个算法貌似和冒泡排序差不多但其实这个算法还是要比冒泡排序优秀的,因为原本的数列里的数字接近有序时那插入排序就会变得非常快,而且冒泡排序每操作一次要借助临时变量需要操作3次,而插入排序仅仅需要1次即可所以插入排序在操作效率上也比冒泡排序要优秀。
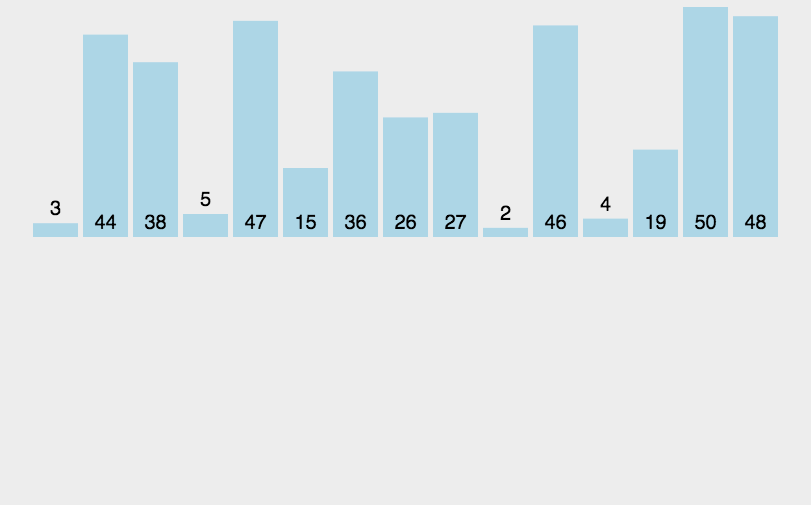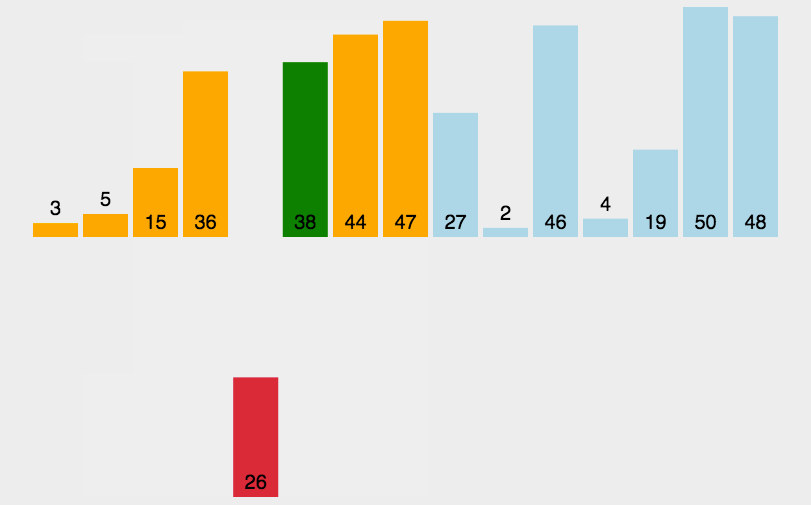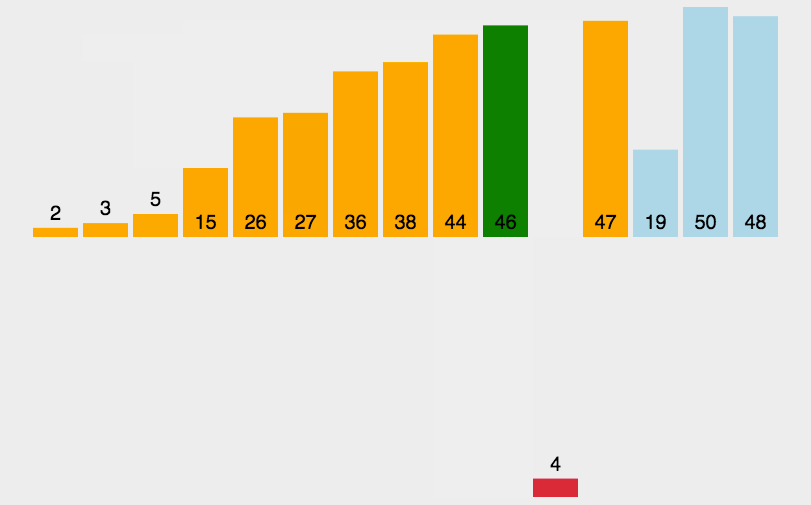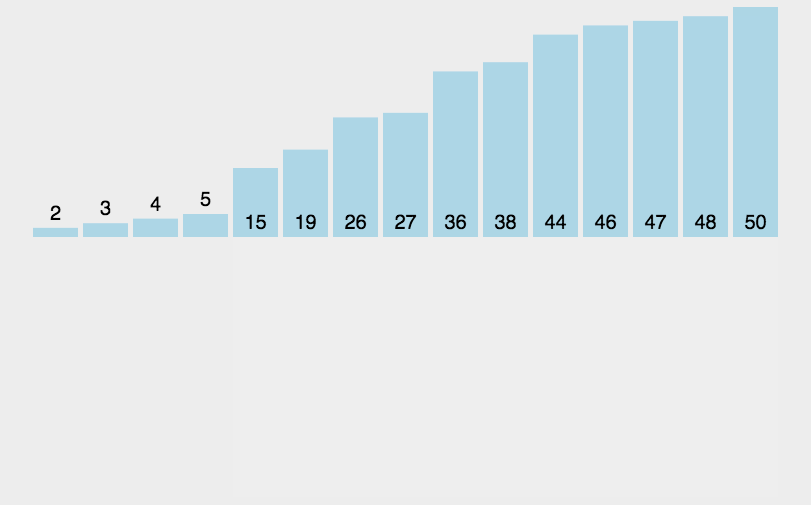
我们可以写一个测试函数来对比一下这两个排序在数据量为10w下的速度差别:
cpp
void CmpSort()
{
int n = 100000;
srand((unsigned int)time(0));
HeapDataType* a1 = (HeapDataType*)malloc(sizeof(HeapDataType) * n);
SortDataType* a2 = (SortDataType*)malloc(sizeof(SortDataType) * n);
SortDataType* a3 = (SortDataType*)malloc(sizeof(SortDataType) * n);
SortDataType* a4 = (SortDataType*)malloc(sizeof(SortDataType) * n);
SortDataType* a5 = (SortDataType*)malloc(sizeof(SortDataType) * n);
if (a1 == NULL) return;
if (a2 == NULL) return;
if (a3 == NULL) return;
if (a4 == NULL) return;
if (a5 == NULL) return;
for (int i = 0; i < n; i++)
{
a1[i] = rand() + i;
a2[i] = a1[i];
a3[i] = a1[i];
a4[i] = a1[i];
a5[i] = a1[i];
}
int begin1 = clock();
//HeapSort(a1, n);
int end1 = clock();
int begin2 = clock();
InsertSort(a2, n);
int end2 = clock();
int begin3 = clock();
BubbleSort(a3, n);
int end3 = clock();
int begin4 = clock();
//ShellSort(a4, n);
int end4 = clock();
int begin5 = clock();
//SelectSort(a5, n);
int end5 = clock();
//printf("HeapSort->%d\n", end1 - begin1);
printf("InsertSort->%d\n", end2 - begin2);
printf("BubbleSort->%d\n", end3 - begin3);
//printf("ShellSort->%d\n", end4 - begin4);
//printf("SelectSort->%d\n", end5 - begin5);
free(a1);
free(a2);
free(a3);
free(a4);
free(a5);
a1 = a2 = a3 = a4 = a5 = NULL;
}运行程序:
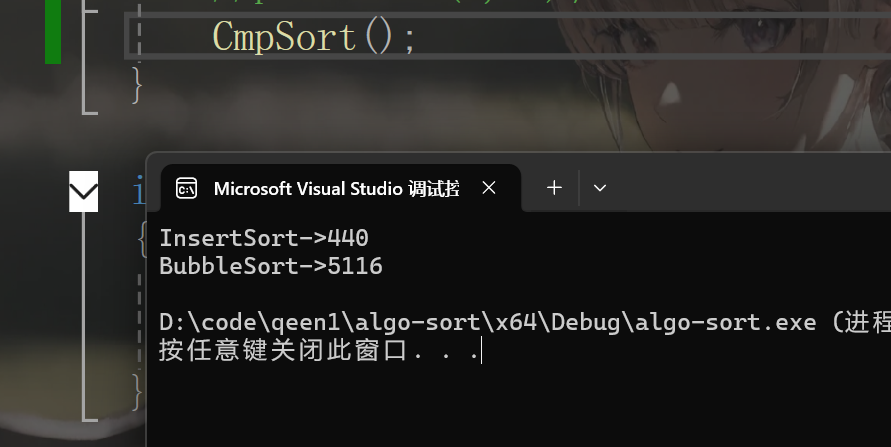
再多运行几次也几乎是一样的结果,所以插入还是要比冒泡来的好的
1.2希尔排序
希尔排序有点像是插入排序的PRO MAX 版,前面我们也提到过,当这个数列原本就比较的接近有序时再去使用插入排序就会变得非常快,时间复杂度可以认为是变成了O(n)级别的。那插入排序和希尔排序到底有什么联系呢?
希尔排序相比于插入排序多了对原数列的预处理的过程,让这个数列变得接近有序。我们会定义一个变量gap,把数列分别gap组,每组里间隔gap个元素(下标从0开始),然后对每个gap组进行插入排序的逻辑最后让gap逐渐收紧,当gap为1时很明显就变成了我们的插入排序,但次此时数组已经变得接近有序了这个时候再去使用插入排序就会变得非常的快。
比如我这里有一个数组a, 当gap == 3时我们会把数列分别三组每组间隔gap个数据,这里我就用不同的颜色来区别不同组别:

紧接着我们开始我们分别对组内的元素进行插入排序,只不过这次组内间隔为gap,假如我对紫色那一组进行一次插入排序那么就会变成:
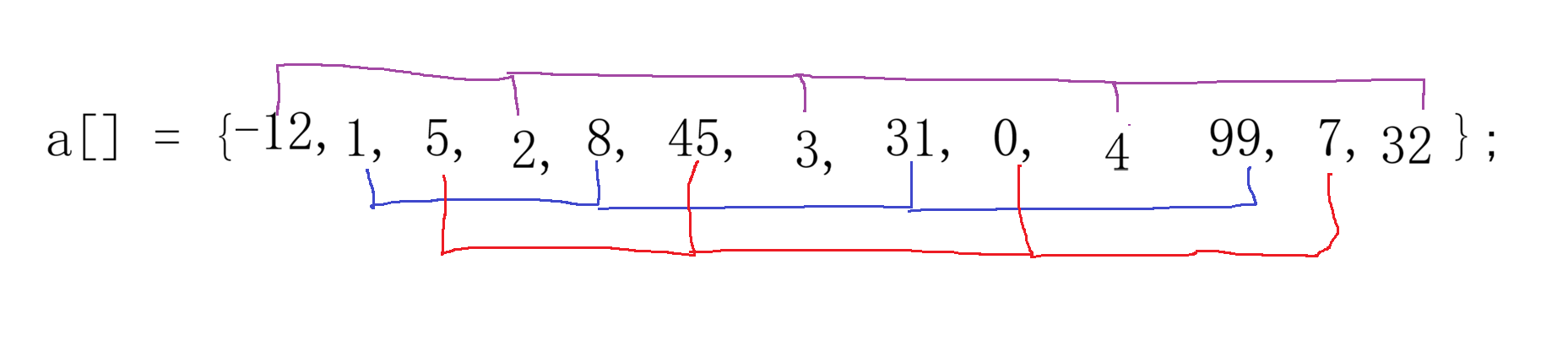
我们可以写程序来验证验证我们的推理结果,现在不需要知道原理是什么只需要知道这是针对紫色这一组进行插入排序即可:
cpp
int gap = 3;
for (int i = 0; i < 1; i++)
{
for (int j = i; j < n - gap; j += gap)
{
int end = j;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}运行程序与我们的推理做对比:
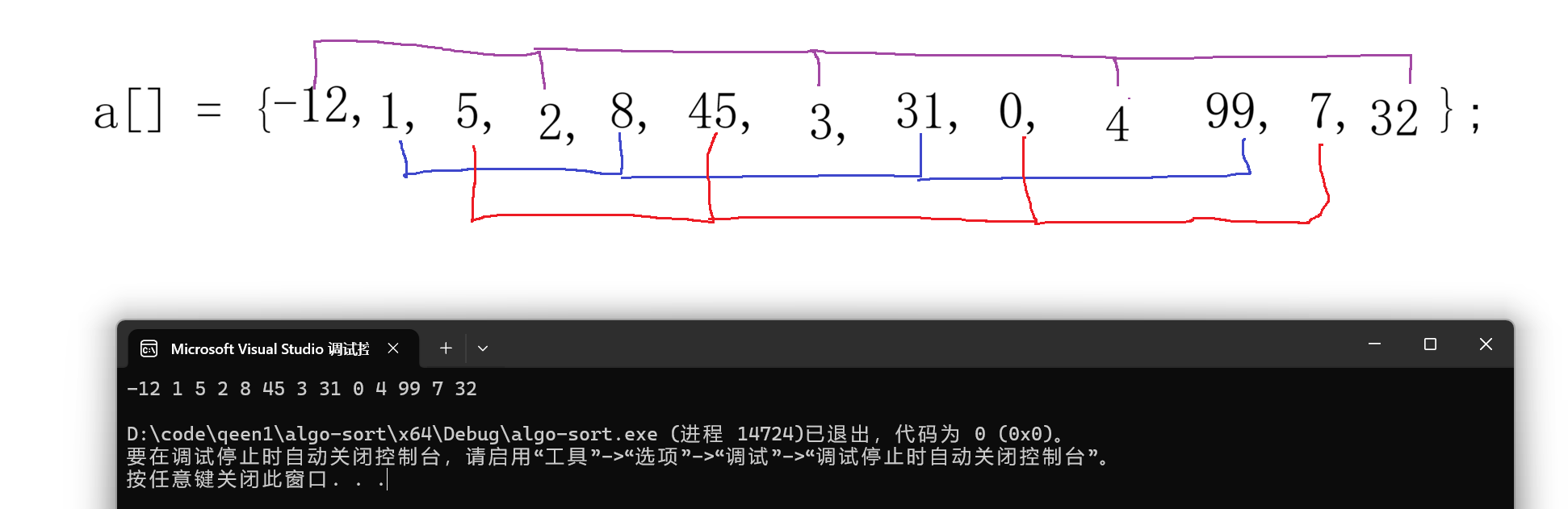
可以看到完美的符合我们的预期。
那么还有一个问题,就是我们的gap该怎么取呢?这里我引用殷人昆老师在《数据结构(用面向对象方法与 C++ 语言描述)》的原话:

我只是一个计科专业的普通大学生数学水平是肯定不够证明得了的,但我一般喜欢吧希尔排序的平均时间复杂度记为O(n ^ 1.3)。
希尔排序的代码实现方式一般有两种,当gap确定后我们可以选择一组一组的完成也可以选择多组一起完成,一组一组完成的代码比较方便我们理解希尔排序但我个人更喜欢第二种写法,这两者的逻辑和时间复杂度是完全一样的所以你可以选择自己喜欢的来写:
一组一组:
cpp
void ShellSort(SortDataType* a, int n)
{
//一组一组的完成
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;
for (int i = 0; i < gap; i++)
{
for (int j = i; j < n - gap; j += gap)
{
int end = j;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
}多组一起:
cpp
void ShellSort(SortDataType* a, int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}有关gap的取值我这里使用的是 / 3 + 1的方式,当gap == 1时就是我们的插入排序是,这样经过插入排序这个数组肯定就是有序的,程序就自然的退出了
希尔排序时间复杂度个人不严谨证明(看个乐)
希尔排序的时间复杂度O(n ^ 1.3)的证明对数学水平的要求很高,至少我的水平肯定是差了十万八千里,但我这里就用俺寻思之力来看看
当这个为逆序时是最坏的情况,gap的取值因为+1的影响不大所以这里我就忽略了这个1,我们假设gap == 3, 那么对于当前gap下的这一轮来说有:
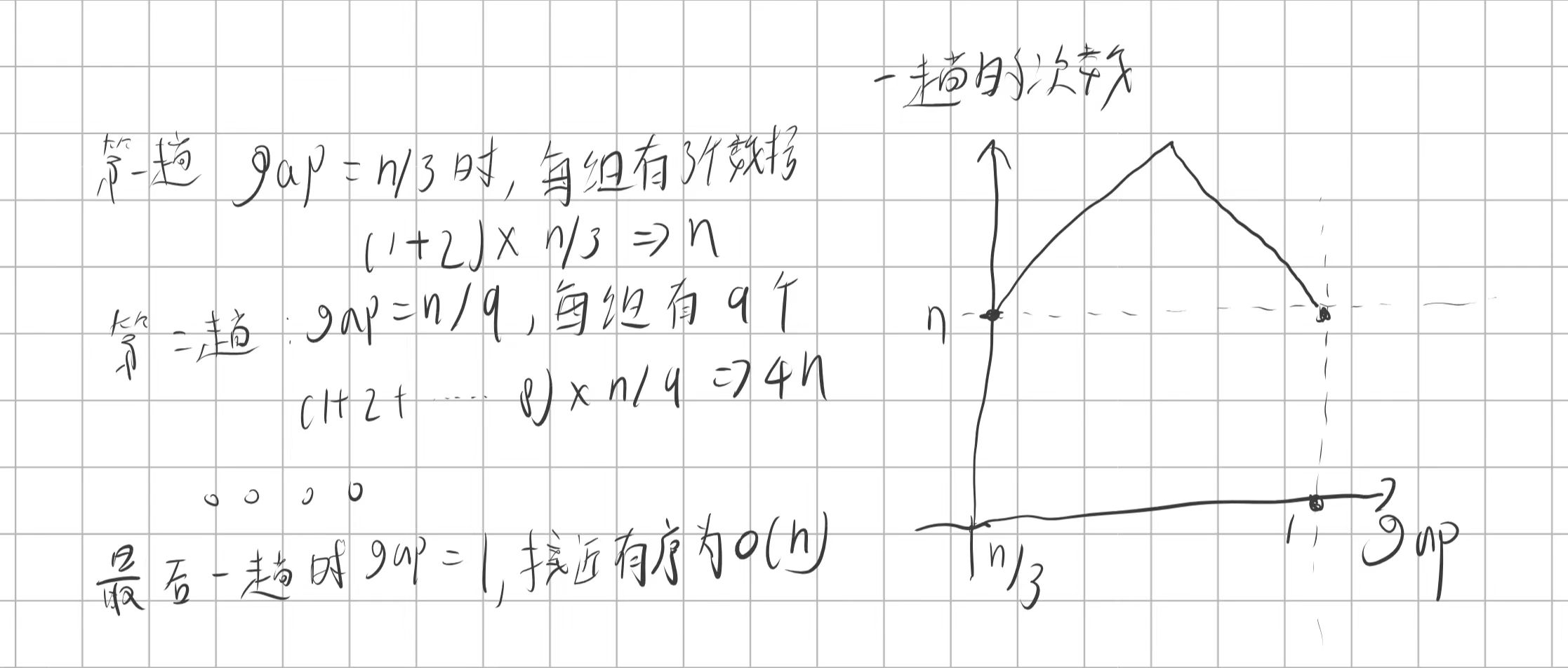 字很丑。。。 真实的图像肯定不是这样的我只是猜一下而已
字很丑。。。 真实的图像肯定不是这样的我只是猜一下而已
接下来我们对比一下希尔排序与插入排序和冒泡排序的速度,数据量同样为10w:
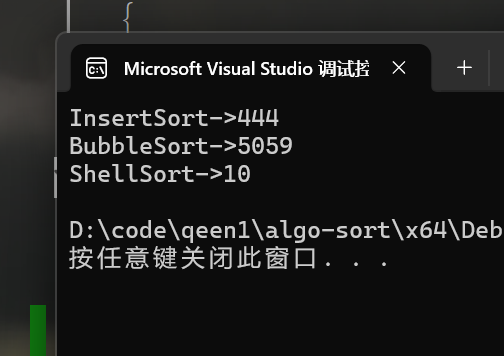
可以看到希尔排序的速度对比那两个哥们来说快点不是一点半点,有时候甚至可以和理论更快的堆排序O(N * log N)更快,能想出来这个排序的哥们也太厉害了吧
2.选择类排序
2.1堆排序
堆排序其实很简单,关于建堆和向下调整算法的讨论在我之前的文章【数据结构】建堆的时间复杂度讨论与TOP-K问题and【数据结构】二叉树基本概念及堆的C语言模拟实现
有过讨论所以我这里就不在赘述了,当我们向对一个数列进行升序时,我们可以建一个大堆并定义一个变量指向最后一个元素,这样堆顶的元素的元素就是最大的,我们把这个堆顶交换到最后面,让这个变量减减,接着再从堆顶进行一次向下调整算法让这个数组重新符合堆的结构,这个循环往复就实现了升序:
堆排序实现,请原谅我这个交换的函数名写错了写成了Sawp应该是Swap才对,但是因为C语言没有堆我这个堆还是我之前写的,虽然这个拼写错的函数用得比较多也不影响我就懒得改了
cpp
void CreateHeap(HeapDataType* a, int n)
{
//向下调整建堆
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, i, n);
}
}
void HeapSort(HeapDataType* a, int n)
{
assert(a);
CreateHeap(a, n);
int end = n - 1;
while (end > 0)
{
Sawp(&a[end], &a[0]);
AdjustDown(a, 0, end);
end--;
}
}当有n个元素时,因为向下调整建堆的时间复杂度为(long n)所以这个排序的时间复杂度为 O(n * long n),有关时间复杂度的讨论在我之前的文章里
我们来看看速度的对比(这次的数据量为100w):
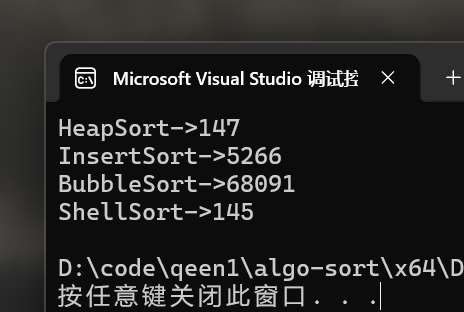
堆排序虽然理论上比希尔排序更快但影响排序的因素还有很多,比如缓存命中率或者数据移动次数等等。但堆排序还是一个很优秀的排序
2.2选择排序
选择排序对比前几个排序简单得很多,我们先来看看动图演示:
简单的说遍历一遍这个数组,选择最小的数然后放到在边下一轮再选出次小的数放在之前放的位置的右边这样循环往复就可以让数组变成升序序列,所以他的时间复杂度显然为O(N ^ 2),但我们不一定非要单单从一段开始,我们可以从两边开始,分别选出最大的数与最小的数的下标,然后通过交换函数让大的放右边小的放左边也可以。
但是需要注意的是这个小优化仍然改变不了这个排序算法的时间复杂度,因为我们计算时间复杂度时1/2 n 与 n对我们来说是一样的
下面是代码实现比较的简单我就直接给了:
cpp
void SelectSort(SortDataType* a, int n)
{
int begin = 0, end = n - 1;
while (begin < end)
{
int mini = begin, maxi = end;
for (int i = begin + 1; i <= end; i++)
{
if (a[i] < a[mini])
{
mini = i;
}
if (a[i] > a[maxi])
{
maxi = i;
}
}
Sawp(&a[mini], &a[begin]);
if (maxi == begin)
{
maxi = mini;
}
Sawp(&a[maxi], &a[end]);
begin++;
end--;
}
}下面我们来对比一下这四个排序的速度,都统一为10w的数据量:
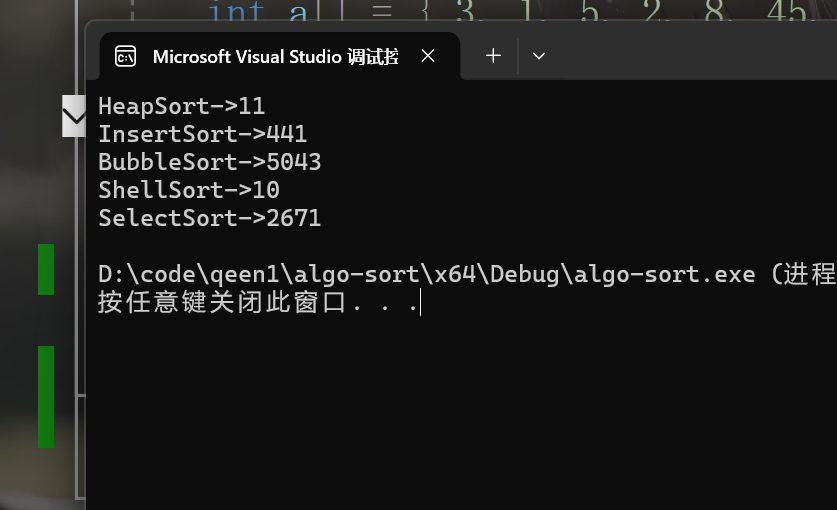
可以看到选择排序和冒泡其实也差不了多少,但是和冒泡一样还是很有教学意义的排序
完