Python微博舆情分析项目实战:基于K-means聚类算法+NLP爬虫可视化推荐系统设计与实现(毕业设计/课程设计/源码)
项目亮点导读
如果你正在准备 毕业设计、课程设计、Python 项目实战、NLP 文本分析、舆情监测系统、数据分析可视化项目 ,这篇项目文章很适合拿来做参考。它不是单纯讲一个爬虫脚本,也不是只放几张图表,而是把 微博数据采集、文本处理、情感分析、K-means 聚类、可视化展示、推荐逻辑 串成了一套完整系统,更接近真实项目展示和答辩材料需要的结构。
该系统基于 Python 实现微博舆情数据采集与分析,使用 requests 完成数据抓取,结合 NLP 文本处理、SnowNLP 情感分析、TF-IDF 特征提取、K-means 聚类推荐、词云与图表可视化,形成一套微博舆情数据分析推荐方案。
目录
- 一、项目简介
- 二、项目背景与研究意义
- 三、系统需求分析
- 四、技术选型说明
- 五、系统总体架构设计
- 六、功能模块设计
- 七、数据库设计
- 八、核心功能实现
- 九、数据采集、数据处理、算法分析与可视化实现
- 十、系统运行效果展示
- 十一、项目特色与创新点
- 十二、适用场景
- 十三、项目部署与运行说明
- [十四、常见问题 FAQ](#十四、常见问题 FAQ)
- 十五、项目总结
- 十六、源码、文档、部署与定制开发说明
- 十七、项目展示截图汇总
一、项目简介
本项目是一套 基于 Python 的微博舆情数据爬虫可视化分析推荐系统。系统核心围绕以下能力展开:
- 微博舆情数据采集
- 热词统计与舆情统计
- 文章分析、IP 分析、评论分析
- SnowNLP 情感分析
- 基于 K-means 聚类算法 的推荐逻辑
- 词云图与图表可视化展示
相比只做"微博数据爬虫"或只做"文本情感分析"的单点项目,这个系统的优势在于它把 数据抓取、NLP 分析、聚类推荐、可视化表达 串联成了一条完整链路。对于 大数据分析、NLP 项目、聚类算法项目、毕业设计、课程设计 来说,这类项目更容易体现综合能力。
项目定位概览
| 维度 | 内容 |
|---|---|
| 项目名称 | 基于 K-means 聚类算法 + NLP 的微博舆情数据爬虫可视化分析推荐系统 |
| 项目类型 | Python 项目实战 / NLP 项目 / 舆情分析系统 / 毕业设计 |
| 核心方向 | 微博舆情采集、情感分析、文本聚类、推荐与可视化 |
| 主要技术 | Python、requests、TF-IDF、K-means、SnowNLP、词云、图表可视化 |
| 主要价值 | 舆情监测、文本分析、热点发现、推荐展示 |
| 适合用途 | 毕设、课设、项目答辩、技术博客、项目包装 |
二、项目背景与研究意义
微博等社交媒体平台每天都会产生大量文本内容,其中包含了用户态度、热点事件、地域信息、评论互动和舆论趋势。对于个人学习者而言,这是一类非常适合做 NLP 文本分析与数据可视化 的数据源;对于项目展示而言,它又天然具备"热点、趋势、可分析、可推荐"的特点,因此很适合包装成完整系统。
从项目主题出发,这类微博舆情分析系统的研究意义主要体现在以下几个方面。
1. 舆情数据价值高
微博数据不是普通文本数据,它具备:
- 时效性强
- 热点集中
- 情绪表达明显
- 用户互动丰富
- 适合做主题发现与情感分析
这意味着它非常适合拿来做:
- 舆情监测
- 热点分析
- 情感分析
- 聚类推荐
- 可视化展示
2. 能覆盖多个技术模块
这个项目不是单一算法实验,而是能覆盖完整工程链路:
- 爬虫采集
- 文本预处理
- NLP 特征提取
- 情感分析
- K-means 聚类
- 推荐逻辑
- 数据可视化
因此,它比只做"算法 notebook"更适合用来做 课程设计或毕业设计。
3. 项目可展示性强
舆情项目的一个天然优势是展示效果好。比如:
- 热词统计图
- 舆情分布图
- 词云图
- 评论分析图
- 聚类结果图
- IP 区域分布图
这些图表不仅能提高文章观感,也非常适合答辩时讲解项目逻辑。
4. 推荐模块提升了项目深度
其中一个亮点是使用 K-means 聚类算法 做推荐逻辑。它让项目从"只做舆情展示"升级为"具有聚类分析与个性化推荐能力"的综合型项目。
如果你正在做 NLP 项目、聚类算法项目、微博舆情分析系统、毕业设计、课程设计,这种项目方向是很有参考价值的。
三、系统需求分析
3.1 功能需求分析
系统主要需要实现以下能力:
- 采集微博相关数据
- 对微博文本进行预处理
- 统计热词与舆情趋势
- 对文本做情感分析
- 基于 K-means 做聚类分析与推荐
- 展示文章分析、评论分析、IP 分析等结果
- 输出词云、图表和可视化看板
3.2 非功能需求分析
除功能本身外,系统还应满足:
- 稳定性:采集过程要具备一定异常处理能力
- 可读性:图表和分析页面要足够清晰
- 可扩展性:后续可增加新的情感模型或推荐策略
- 可维护性:模块之间边界清晰,便于继续开发
- 展示性:适合放到技术博客、答辩 PPT 和项目案例中
3.3 可行性分析
技术可行性
该项目采用的技术路线都比较成熟:
requests负责数据采集TF-IDF负责文本向量化K-means负责无监督聚类SnowNLP负责情感分析- 词云与图表负责结果展示
这套方案比较适合教学型项目和展示型项目。
应用可行性
舆情项目本身有较强的现实意义,既能用于热点事件分析,也能用于企业品牌口碑分析、话题趋势分析和兴趣内容推荐研究。
系统角色表
| 用户角色 | 可使用功能 | 权限说明 |
|---|---|---|
| 普通用户 | 查看舆情分析、热词统计、情感图表、推荐结果 | 以浏览和分析为主 |
| 数据分析用户 | 查看更细粒度的文本分析、评论分析、IP 分析、词云结果 | 更关注数据层面 |
| 项目维护者 | 采集数据、清洗数据、调整聚类参数、优化展示模块 | 负责系统运行和模型维护 |
四、技术选型说明
技术栈表
| 技术类别 | 使用技术 | 主要作用 | 选择原因 |
|---|---|---|---|
| 开发语言 | Python | 实现爬虫、文本分析、聚类算法与推荐逻辑 | NLP 与数据分析生态成熟 |
| 数据采集 | requests | 抓取微博相关数据 | 简单直接,适合原型实现 |
| 文本处理 | 分词、停用词过滤、TF-IDF | 将微博文本转为可聚类的特征向量 | 是文本聚类常见方案 |
| 聚类算法 | K-means | 对微博文本内容聚类 | 经典无监督算法,适合教学项目 |
| 情感分析 | SnowNLP | 进行微博文本情感倾向评分 | 中文文本处理较常见 |
| 可视化 | 词云、统计图表 | 展示热词、舆情趋势、评论分布等 | 可读性强,适合答辩与博客 |
| 开发工具 | Python 环境、本地调试工具 | 代码开发、测试、运行 | 成本低、复现方便 |
选型解读
1. 为什么用 K-means
K-means 是典型的无监督学习算法,逻辑清晰,结果易展示,很适合在 毕业设计、课程设计、算法项目实战 中承担"核心算法模块"的角色。
2. 为什么用 TF-IDF
微博文本属于短文本场景,TF-IDF 作为经典文本特征提取方法,足够支撑这类项目的聚类与推荐演示。
3. 为什么加入 SnowNLP
系统不仅做了聚类,还做了情感分析。SnowNLP 的加入使项目从"主题聚类"扩展到了"情绪判断",显著增强了项目的分析维度。
五、系统总体架构设计
系统整体可以拆分为以下几个核心层次:
- 数据采集层
- 文本处理层
- 算法分析层
- 展示推荐层
5.1 架构说明
数据采集层
负责抓取微博文本及相关信息,如热词、文章内容、评论信息、IP 信息等。
文本处理层
负责对原始文本进行清洗、分词、去噪、特征提取,为后续聚类与情感分析提供可计算输入。
算法分析层
主要包含:
- SnowNLP 情感分析
- TF-IDF 特征提取
- K-means 聚类分析
展示推荐层
负责将分析结果以图表、词云、聚类推荐结果等形式展示出来。
5.2 生成架构图
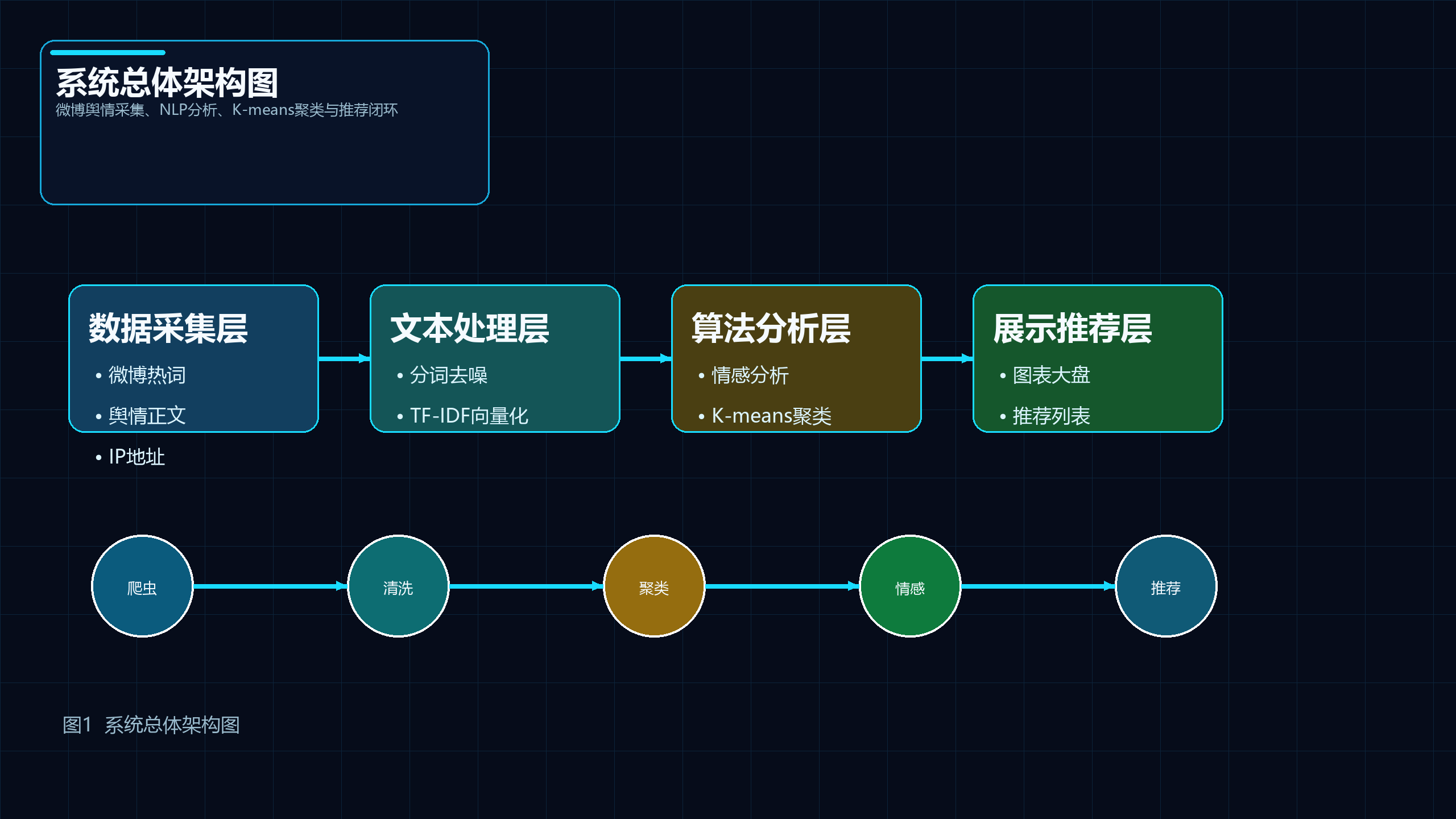
图1 说明: 展示微博舆情项目从数据采集、文本处理、算法分析到展示推荐的整体分层结构。
5.3 业务流程图
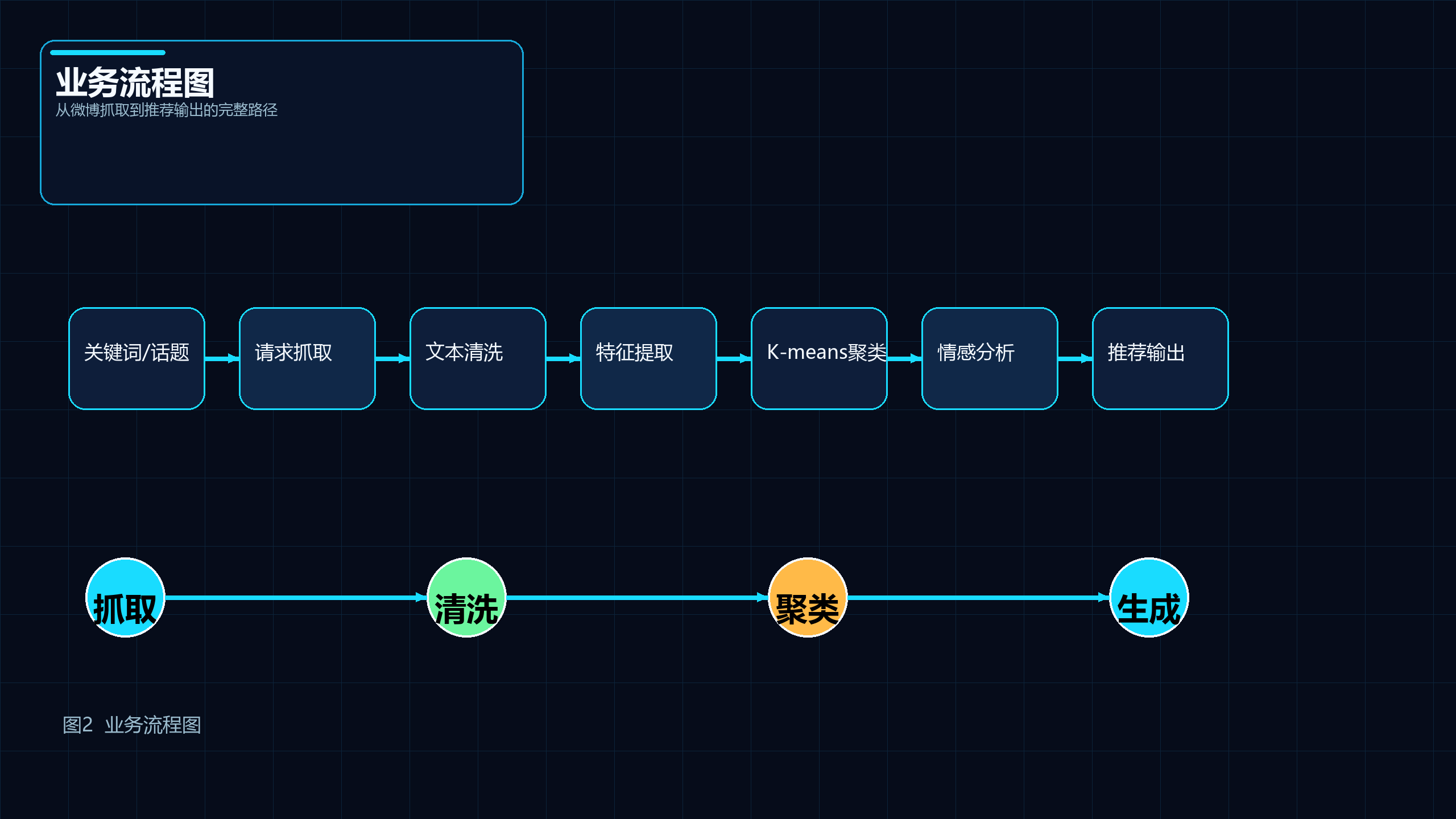
图2 说明: 展示系统从话题输入、数据抓取、预处理、聚类分析、情感分析到推荐输出的完整业务流程。
六、功能模块设计
功能模块表
| 模块名称 | 核心功能 | 主要技术 | 用户价值 |
|---|---|---|---|
| 数据采集模块 | 抓取微博热词、正文、评论、IP 等信息 | requests | 提供原始舆情数据来源 |
| 文本处理模块 | 文本清洗、分词、特征向量化 | 分词、TF-IDF | 将非结构化文本转为可分析数据 |
| 舆情统计模块 | 统计热点与趋势 | 统计分析 | 帮助发现热点事件 |
| 情感分析模块 | 识别文本情感倾向 | SnowNLP | 判断舆论情绪分布 |
| 聚类推荐模块 | 基于 K-means 做内容聚类与推荐 | K-means | 增强项目算法亮点 |
| 可视化模块 | 输出词云、统计图、分析看板 | 图表与词云 | 提升可读性与展示性 |
6.1 数据采集模块
该模块负责从微博平台抓取用户感兴趣的数据,是整个系统的数据入口。系统已经具备抓取与解析微博数据的基础逻辑。
6.2 文本处理模块
由于微博文本属于短文本,往往包含符号、重复内容、无关停用词等,因此系统需要先进行清洗和特征化,才能支持聚类和情感分析。
6.3 情感分析模块
该模块基于 SnowNLP 对文本进行情感倾向评分,并可将结果划分为积极、消极和中性等类别。
6.4 K-means 聚类推荐模块
这是项目的算法亮点模块。通过将文本表示成向量后做聚类,可以把语义上相近的话题或内容分配到同一簇,从而支持个性化推荐或相似内容发现。
6.5 可视化分析模块
该模块承担项目的"展示面",通过热词图、情感图、评论统计图、词云图等将分析结果以更直观方式呈现。
七、数据库设计
数据库设计可围绕以下数据对象展开:
- 微博正文数据
- 评论数据
- 热词统计结果
- IP 地址/地区数据
- 情感分析结果
- 聚类结果或推荐结果
核心表设计表
| 表名 | 主要字段 | 功能说明 |
|---|---|---|
weibo_post |
标题/正文、发布时间、话题等 | 存储微博主体文本数据 |
weibo_comment |
评论内容、评论时间、关联正文等 | 存储评论分析数据 |
weibo_ip_region |
地区/IP 相关字段 | 存储地域分布分析依据 |
sentiment_result |
文本、情感得分、情感标签 | 存储情感分析结果 |
cluster_result |
文本 ID、簇编号、聚类标签 | 存储 K-means 聚类结果 |
注:由于项目未展示完整真实表结构,这里按已知功能做概括说明。
八、核心功能实现
8.1 微博数据采集实现
系统通过 requests 进行微博数据采集,并通过合理的请求头、参数和解析逻辑完成抓取。
8.2 文本特征提取实现
在文本聚类任务中,最关键的一步是把微博文本转换成向量表示。这里使用 TF-IDF,这是一个经典且适合教学项目的方案。
8.3 K-means 聚类实现
核心代码片段如下:
python
documents = df['content']
def preprocess_text(text):
# Add your preprocessing steps here
return text
processed_documents = [preprocess_text(doc) for doc in documents]
vectorizer = TfidfVectorizer(max_df=0.8, min_df=2, stop_words='english')
X = vectorizer.fit_transform(processed_documents)
num_clusters = 15
kmeans = KMeans(n_clusters=num_clusters, random_state=42)
kmeans.fit(X)这段代码说明了项目的聚类主链路:
- 读取微博文本
- 进行预处理
- 转换成 TF-IDF 向量
- 训练 K-means 模型
- 输出簇分配结果
8.4 情感分析实现
项目使用 SnowNLP 对微博文本做情感分析,其输出目标包括:
- 文本情感得分
- 情感类别划分
- 与舆情统计结果做组合分析
8.5 可视化实现
系统最终重点包括:
- 热词统计
- 舆情统计
- IP 地域分析
- 评论分析
- 词云分析
- 情感分布分析
- 聚类推荐展示
九、数据采集、数据处理、算法分析与可视化实现
9.1 数据采集流程
系统通过微博数据抓取模块获取原始文本,为舆情分析与推荐模块提供输入。该流程应重点关注:
- 请求构造
- 页面或接口响应解析
- 数据抽取
- 异常处理
- 结构化存储
9.2 K-means 聚类流程图
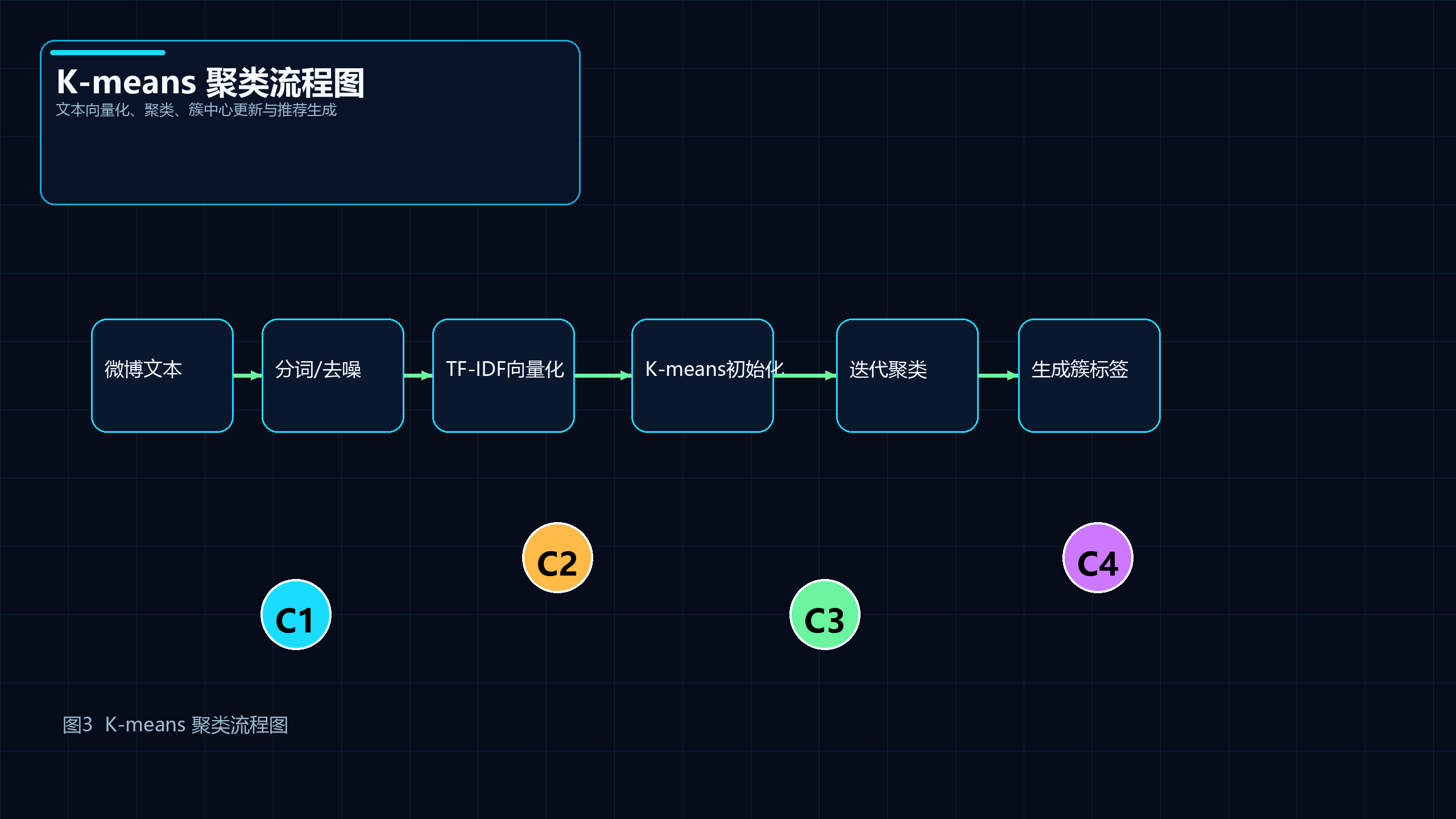
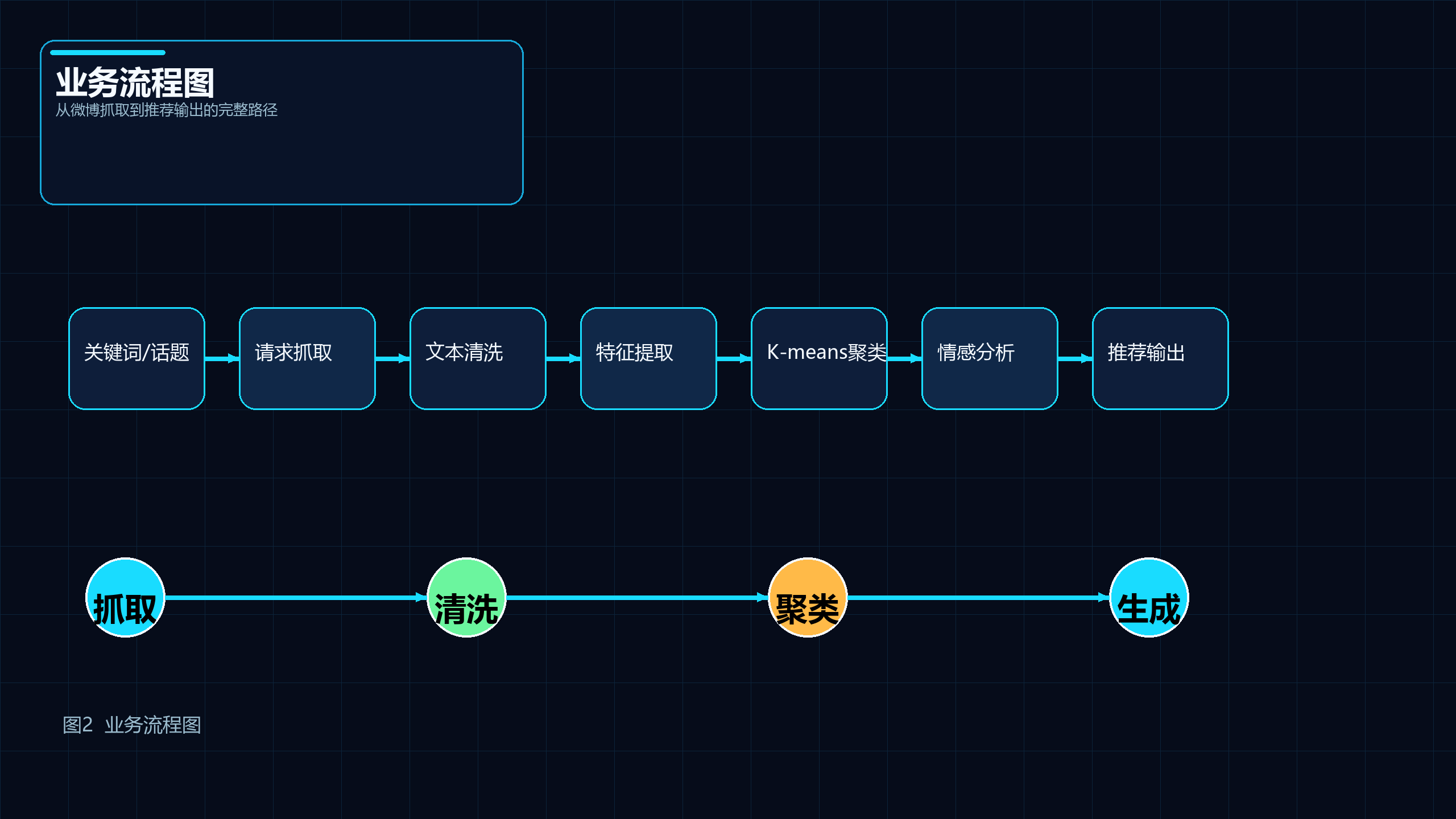
图4 说明: 展示微博文本从向量化到聚类、簇标签生成与推荐输出的算法链路。
9.3 情感分析流程图
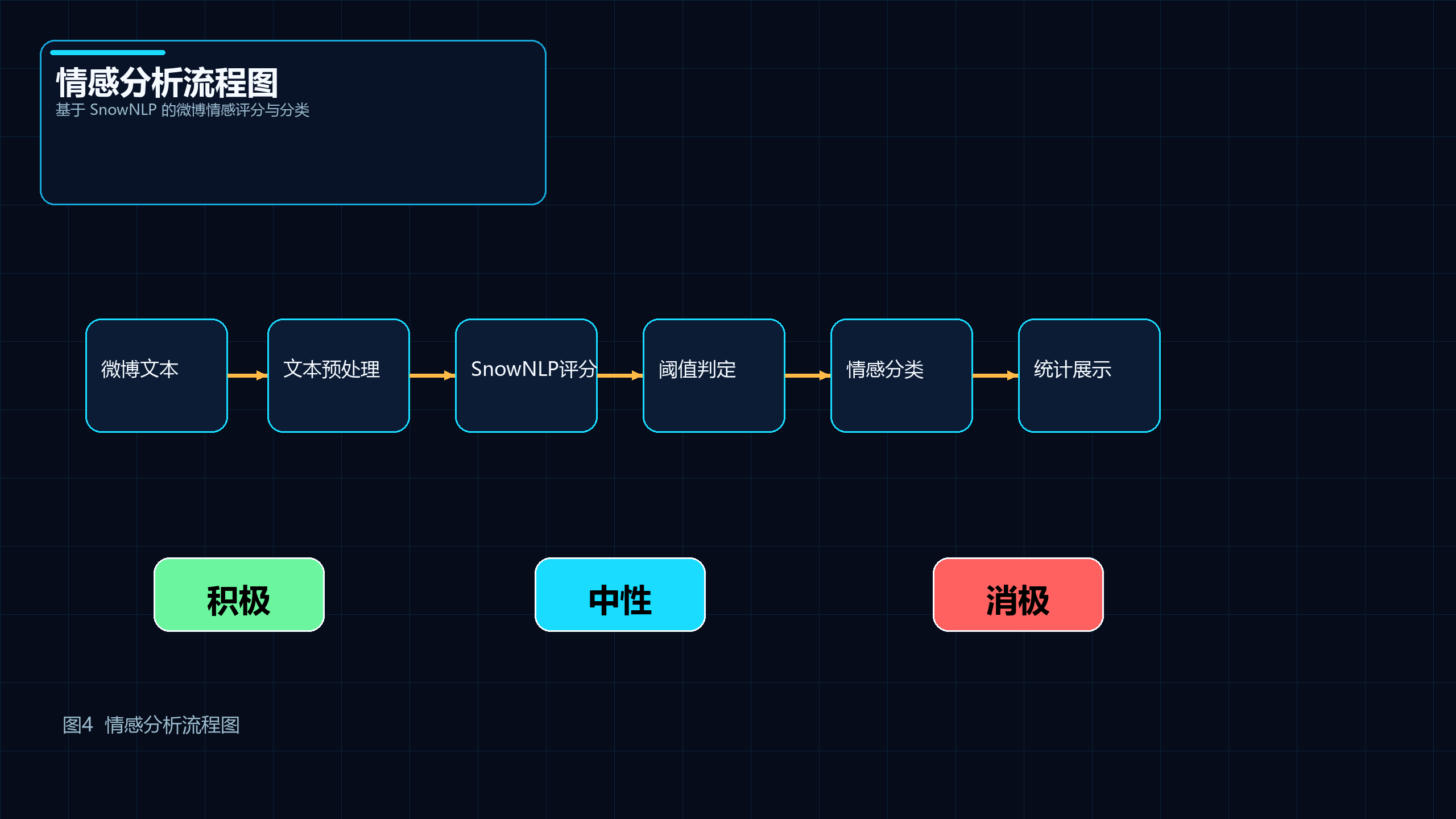
图5 说明: 展示基于 SnowNLP 的微博情感评分、分类与统计过程。
9.4 情感分析模块说明
情感分析模块主要通过 SnowNLP 对文本情绪倾向进行评分,再根据阈值划分积极、中性和消极类别。这个模块的价值在于:
- 识别舆论整体偏向
- 发现热点事件的情绪倾向
- 与评论量、热度等指标联动分析
9.5 推荐逻辑说明
与普通情感分析项目不同,这个项目加入了 K-means 聚类推荐。它的项目价值主要体现在:
- 从文本相似性角度组织内容
- 为用户输入匹配更相似的内容集合
- 提升项目的算法展示深度
合规说明: 本项目中的微博数据采集仅用于学习研究和技术交流。数据抓取应遵守目标平台规则、服务条款和相关法律法规,不得用于非法采集、商业滥用或侵犯他人权益。
十、系统运行效果展示
(1)系统首页-数据概况


(2)热词统计

(3)舆情统计

(4)舆情文章分析


(5)IP地址分析

(6)评论分析

(7)舆情分析

(8)文章内容词云分析


十一、项目特色与创新点
项目亮点表
| 亮点 | 说明 | 实际价值 |
|---|---|---|
| 舆情分析链路完整 | 从抓取、处理、分析到展示形成闭环 | 适合做毕业设计和课程设计 |
| 聚类算法加入项目流程 | 使用 K-means 做文本聚类和推荐 | 提升项目的算法亮点 |
| 情感分析维度完整 | 使用 SnowNLP 识别情感倾向 | 增强舆论判断能力 |
| 可视化展示丰富 | 热词、情感、IP、评论、词云等都有展示空间 | 展示效果强,适合答辩 |
| 项目主题贴近现实 | 微博舆情本身具备高话题性 | 更容易吸引读者与老师关注 |
十二、适用场景
适用场景表
| 场景 | 适合人群 | 使用价值 |
|---|---|---|
| 计算机毕业设计 | 本科、大专、培训项目学员 | 能体现爬虫、NLP、聚类、可视化综合能力 |
| 课程设计/综合实训 | 数据分析、Python、人工智能课程学生 | 适合作为综合型课程项目 |
| NLP 入门项目 | 想做中文文本分析的人 | 可实践情感分析与文本聚类 |
| 推荐系统项目展示 | 需要算法亮点的项目作者 | 聚类推荐模块更有展示性 |
| 技术博客与项目包装 | 需要项目案例展示的人 | 适合做成 CSDN 高质量项目文章 |
十三 、源码文档等
本项目围绕微博舆情数据的采集、处理、分析与推荐,构建了一套功能完善的技术系统。通过将K-Means聚类算法与NLP自然语言处理技术相结合,实现了基于内容相似度的个性化新闻推荐;通过SnowNLP情感分析和多维可视化,实现了对微博舆情的全面、直观监测。
在技术层面,项目涵盖了数据爬虫、文本预处理、特征工程、无监督学习、情感分析和前端可视化等多个技术方向,具有较强的综合性和实践性。在应用层面,该系统可为政府部门的舆情监测、企业的品牌管理、媒体的内容推荐等场景提供有效的技术支撑。
如需项目源码、部署文档、功能解析、二次开发、界面优化、项目定制、课程设计或毕业设计辅导,可通过评论区、私信或个人主页方式交流。支持全栈系统开发与技术咨询。