背景
传统推荐模型
以Embedding+深度网络为主,通过拟合用户反馈信号提升推荐效果,主要特点:
- 模型相对较小,时间空间开销低;
- 可以充分利用用户反馈信号;
- 只能利用数据集内的知识;
- 缺乏语义信息和深度意图推理。
LLM大语言模型
通过大规模预训练语料和自监督训练提升通用语义理解和生成能力,这里的LLM包括Bert、T5、GPT2等语言模型。LLM主要特点:
- 引入外部开放世界知识,语义信号丰富;
- 具备跨域推荐能力,适合冷启动场景;
- 用户反馈信号缺失;
- 计算复杂度高,难以处理海量样本。
LLM与推荐的结合
业界关于LLM与推荐的探索,根据LLM与推荐系统的耦合强弱,概括起来有两种建模范式:
LLM+推荐 与 LLM as 推荐
(1)LLM + 推荐
将语言模型视为特征提取器,将物品和用户的原始信息(比如商品的标题/属性/类目、用户的点击序列/上下文)设计成prompt,输入到LLM中并输出相应的embedding或者语义summary信息,后续作为特征或者通过LLM语义挖掘用户潜在的兴趣偏好,最终将这些整合到推荐系统的决策过程中。
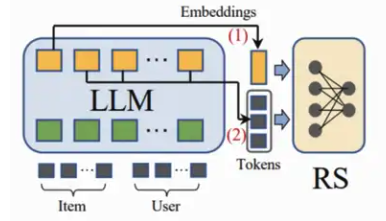
代表性工作:GENRE新闻推荐、大型语言模型增强叙事驱动推荐
(2)LLM as 推荐
直接将预训练的LLM转换为一个强大的推荐模型,用来替换推荐系统(召回->粗排->精排->重排)的一个或者全部模块。输入序列通常包括任务指令、任务描述、用户和物品信息等,输出就是最终的推荐结果。
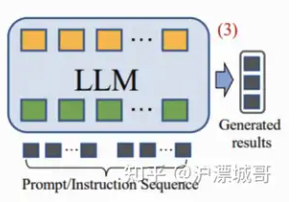
代表性工作:Chat-Rec、zero-shot对话推荐器
ChatGPT前
1.Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm
统一的预训练、个性化提示和预测范式(代表性工作)
- 用统一的大语言模型在不同的推荐任务上进行预训练,针对不同任务使用不同推荐模版;
- 用自然语言为桥梁,规范不同推荐场景的输入输出,并在跨域样本上进行预训练,具备新场景下的zero-shot迁移能力。
P5统一建模的5类推荐任务(序列推荐、评分预测、推荐理由、评论、直接推荐)如下图所示:
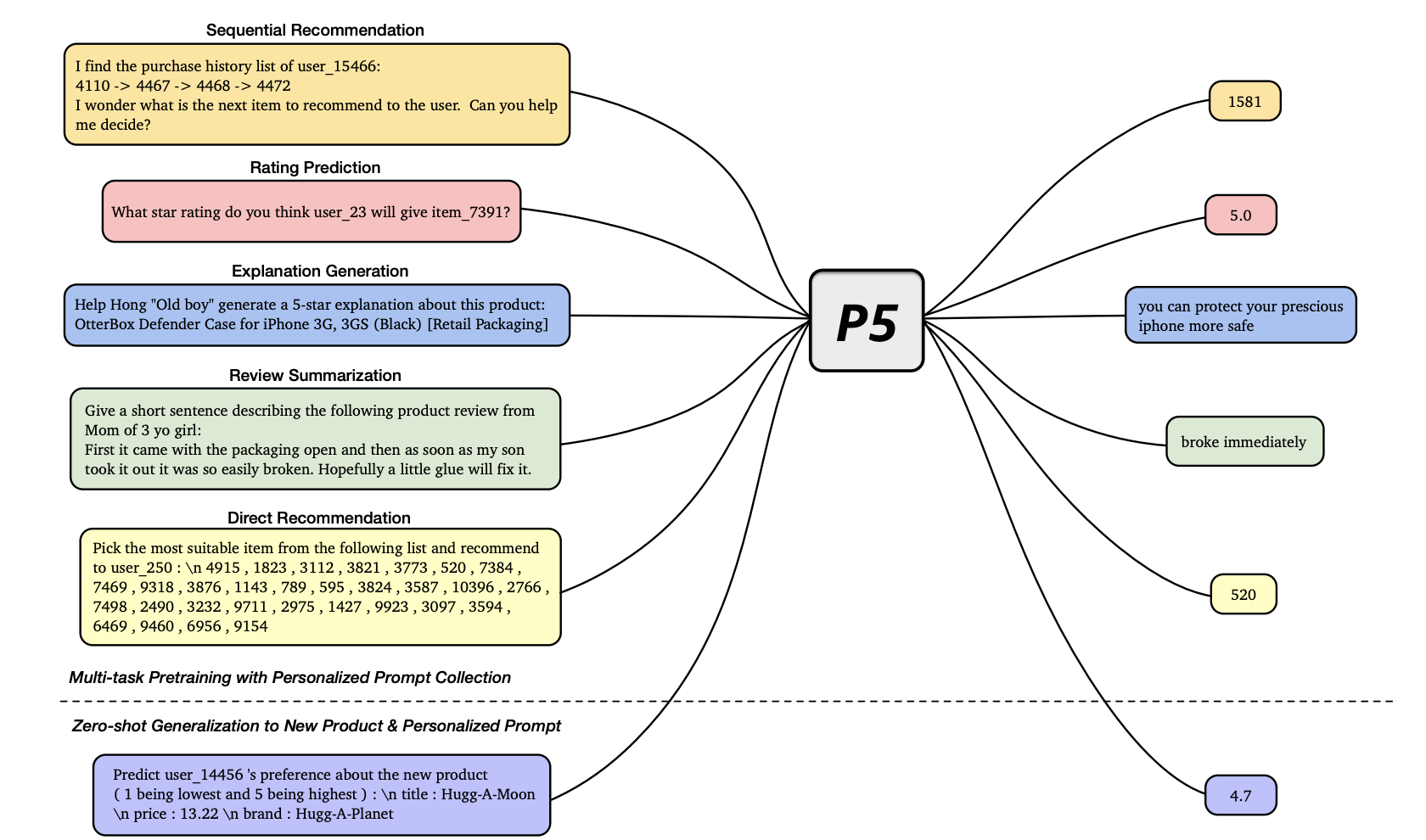
不同任务的prompts模板设计方式不一样,比如:
-
评分预测任务:包含3类,(a)给定关于user和item的信息,直接预测评分(1~5);(b)预测user是否会对item产生评分,即:yes or no;(c)预测user对item是否喜欢(>4分喜欢,否则不喜欢)
Input template: Which star rating will user_{{user_id}} give item_{{item_id}}?
Target template: {{star_rating}} -
序列推荐任务:包含3类,(a)直接基于交互历史,来预测下一次交互;(b)给定交互历史和候选item集合,从中选出某个item作为预测结果;(c)给定交互历史以及某个item,预测这个item用户是否下一次会进行交互。
-
推荐理由任务:包含2类,(a) 基于user和item的特征,直接生成推荐理由。(b) 将某个特征作为hint提示,生成推荐理由。
-
评论任务:包含2类,(a)对长评论进行摘要生成。(b)给定评论,预测对应的评分。
-
直接推荐:最常见的类型,类似TopK推荐。包含2类,(a) 预测是否要把某个item推荐给某个用户,yes or no。(b) 从候选集合中,选出某个item推荐给用户。
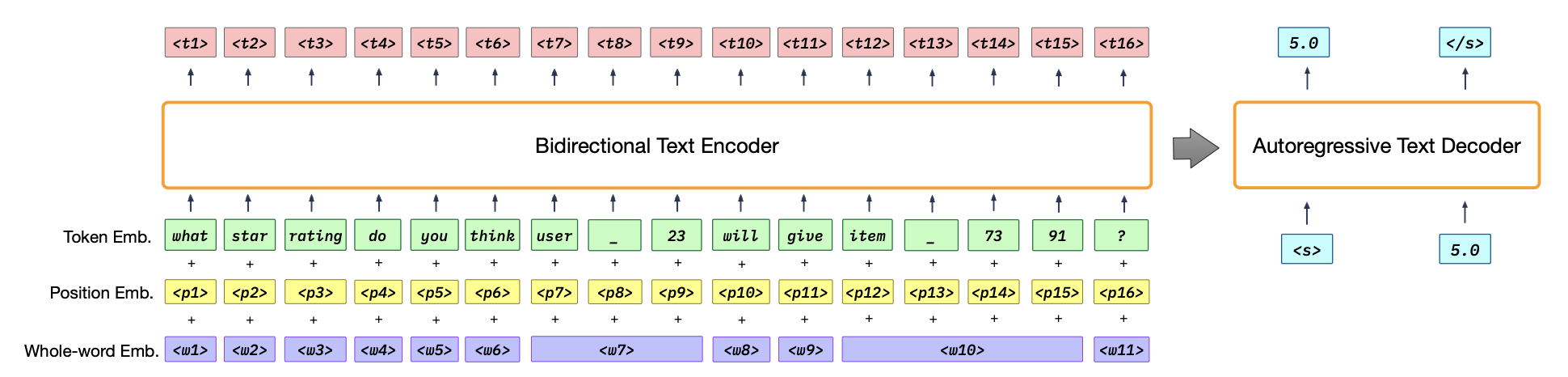
P5模型结构采用了Encoder-Decoder结构,核心组成是Transformers:
ChatGPT后
1.Chat-REC:Towards Interactive and Explainable LLMs-Augmented Recommender System
面向交互式和可解释的LLM增强推荐系统
**简述:**论文提出了一种名为Chat-Rec的新范式,通过将用户个人资料和历史交互转换为提示,增强了LLMs,用于构建对话式推荐系统。Chat-Rec能够有效地学习用户偏好,并通过上下文学习建立用户与产品之间的联系,使推荐过程更具交互性和可解释性。实验结果表明,Chat-Rec提高了前k个推荐的精度,并在zero-shot评级预测任务(rating prediction task)中表现更好。

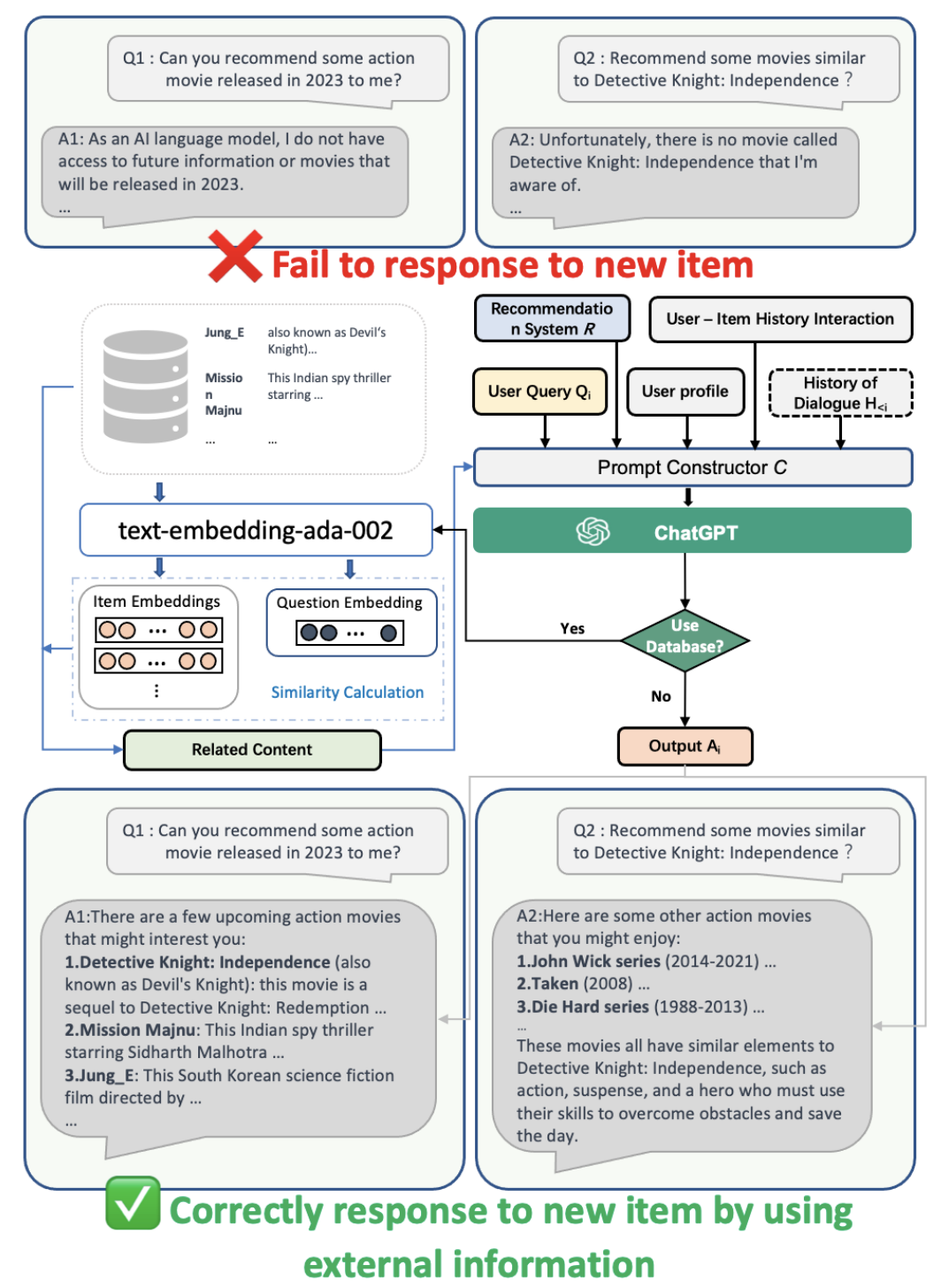
基于ChatGPT增强式推荐系统(电影推荐场景):
- 输入
(1)user-item交互历史:指的是用户过去与物品的交互,例如他们点击、购买或评级的物品
(2)用户画像:用户的年龄、性别、地点和兴趣
(3)当前query:
(4)对话历史:用户与系统之前的对话,了解用户查询的上下文
(5)item候选集合:由推荐系统R产出,若无,系统将做生成和解释性任务
- prompt构造器
接受多个输入,并来生成可以捕获用户查询和推荐信息的描述段落
- chatGPT
推荐、生成和解释性任务
- RecSys
chatGPT生成的中间答案用于细化提示构造器并生成优化的提示,以进一步压缩和细化候选集。 所得到的推荐和简短的解释被输出给用户。

Chat-Rec范式应用于推荐系统中:
a) 精排:缩小候选集合
b) 冷启动推荐:
c) 跨领域推荐
依据:LLM预训练语料包含多领域的知识。 除了一个领域的目标item之外,LLM不仅对许多其他领域的item有广泛的了解,而且还了解上述领域中item之间的关系。

比如LLM根据用户的电影偏好,继续推荐各种选择,如书籍、电视剧、播客和视频游戏。这证明了LLM能够将用户的偏好从电影转移到其他项目,从而产生跨域推荐。
2.TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation(2023 ACM推荐系统会议)
用于将大型语言模型与推荐系统对齐的有效且高效的调优框架
**简述:**论文介绍了一种名为TALLRec的框架,用于将大型语言模型与推荐系统对齐。作者认为,由于LLM训练任务和推荐任务之间存在差异以及缺乏足够的推荐数据,导致LLMs在推荐任务中表现不佳。因此,作者提出了通过调优LLMs来构建大型推荐语言模型的方法。

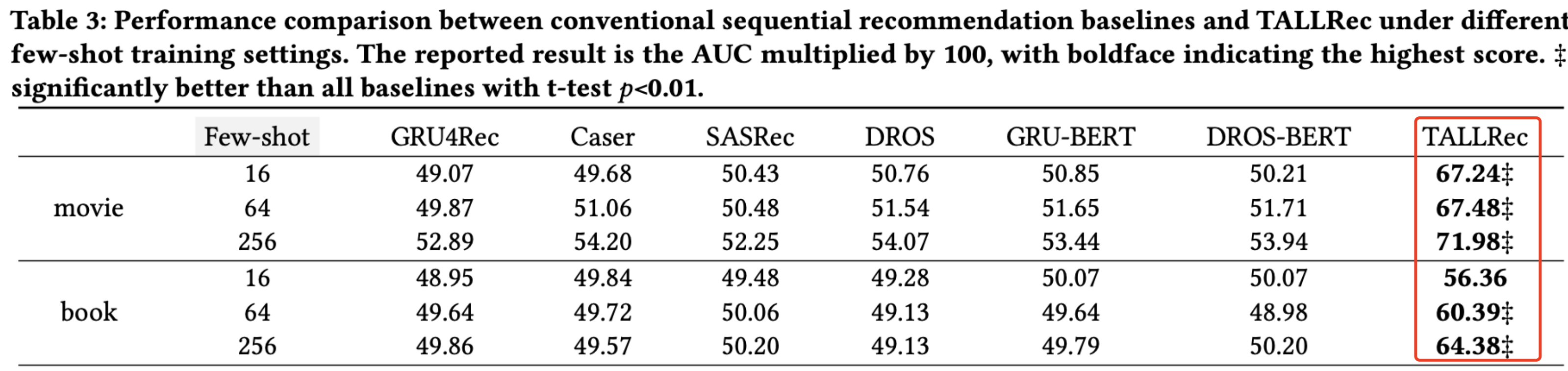
在对电影和书籍推荐任务,根据用户的交互历史,LLM可以通过上下文学习来预测用户是否会喜欢新item,要么拒绝回答,要么总是给出积极的预测。如果忽略被拒绝的答案并计算剩余样本的 AUC,就会发现LLM与随机猜测的表现类似(AUC=0.5)。
因此,作者提出了TALLRec框架:

两个微调阶段
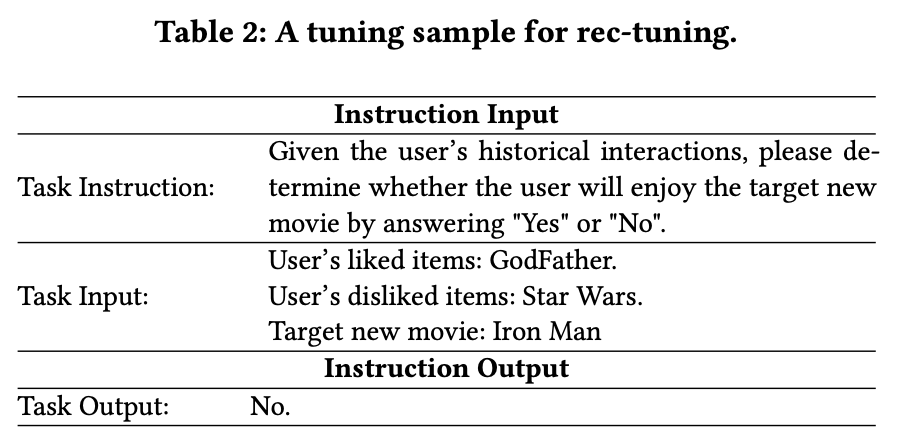
(1)alpaca tuning:采用LoRA轻量级微调,预测下一个token
(2)rec-tuning :使用由推荐数据构造的指令输入和输出的rec-tuning样本
实验结果:
证明了TALLRec框架可以显著提高LLMs在电影和图书领域的推荐能力,并且具有高效的执行速度能力。
3.Large Language Models as Zero-Shot Conversational Recommenders(2023ACM信息与知识管理国际会议 )
大型语言模型作为zero-shot对话推荐器
**简述:**论文介绍了使用大型语言模型进行对话推荐任务的实证研究,主要贡献有以下三点:(1)构建了一个与推荐相关的对话数据集;(2)发现即使没有微调,大型语言模型也可以优于现有的微调后的对话推荐模型;(3)提出了探测任务来研究大型语言模型在对话推荐中出色表现的背后机制。

实验结果(new item):
- 三个数据集:INSPIRED、ReDIAL、Reddit(论文构建)
- 传统模型:ReDIAL、KBRD、KGSF、UniCRS;
- 大模型LLM:BAIZE(白泽)、Vicuna、GPT-3.5-turbo、GPT-4
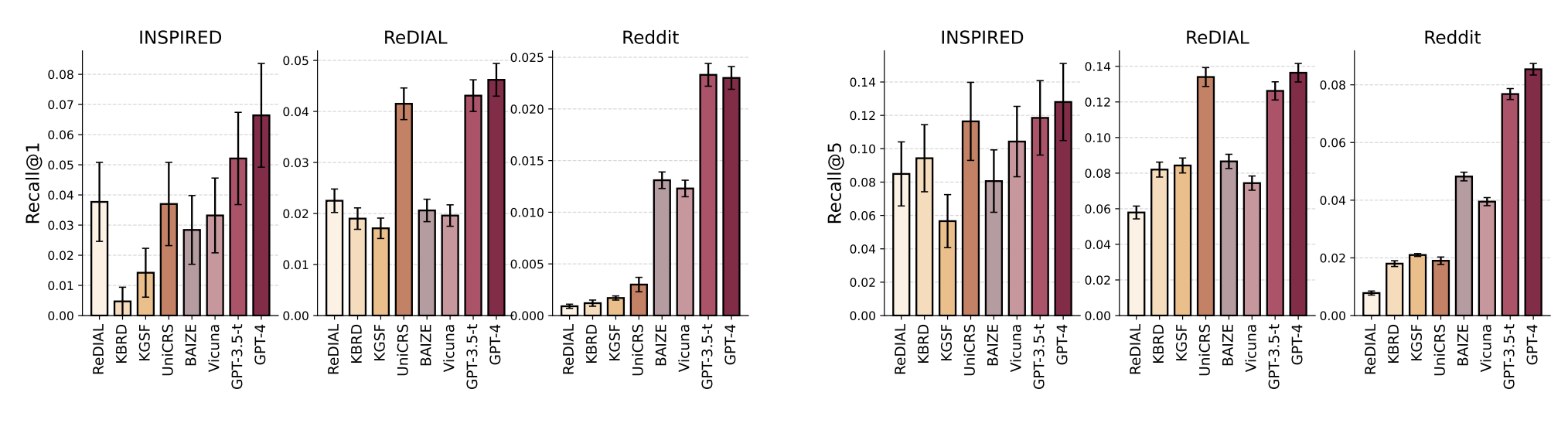
LLM虽然没有经过微调,但在所有数据集上都具有最好性能
BAIZE和Vicuna性能远远低于GPT-3.5-turbo,论文认为通过imitation learning蒸馏的较小模型(BAIZE和Vicuna)不能完全继承较大模型在下游任务上的能力
4.LlamaRec: Two-Stage Recommendation using Large Language Models for Ranking
使用大型语言模型进行两阶段推荐排名
**简述:**论文介绍了一种名为LlamaRec的两阶段框架,使用大型语言模型进行基于排名的推荐系统。作者提出了一种使用小型序列推荐器根据用户交互历史检索候选项的方法,然后将历史和检索到的项目通过精心设计的提示模板以文本形式输入到LLM中。该框架不生成长文本,而是将输出转换为候选项目的概率分布,从而高效地对项目进行排名。

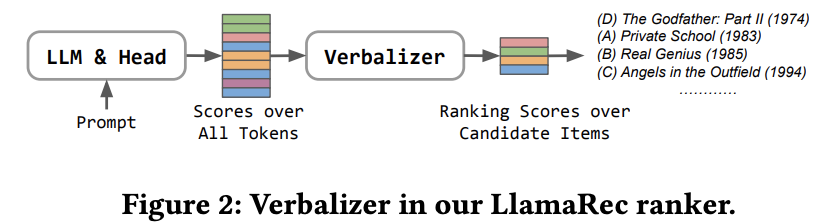
(1) retrieval:LRURec检索模型,选出top-k推荐候选集,作为下一阶段的输入
(2)LLM rank:论文用的是Llama 2,利用一个简单的语言转换器verbalizer,将 LLM 的输出(即所有标记的输出分数)转换为对候选项目的分数排名
5.Large Language Model Augmented Narrative Driven Recommendations
大型语言模型增强叙事驱动推荐
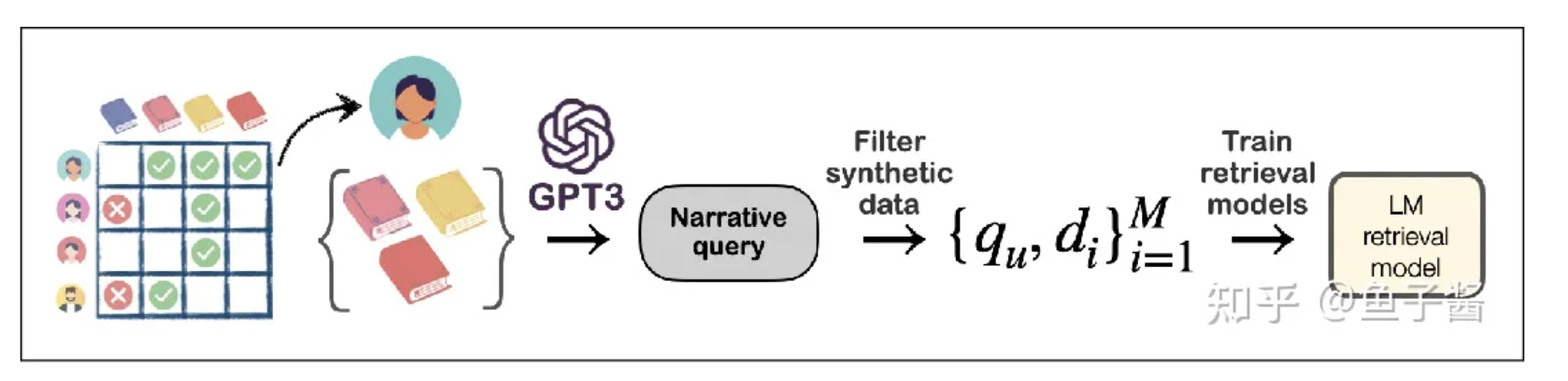
**简述:**论文探讨了使用大型语言模型(LLM)进行数据增强的方法来训练叙事驱动推荐(NDR)模型。作者使用LLM从用户-物品交互中通过少样本提示生成合成叙述查询,并在合成查询和用户-物品交互数据上训练检索模型。实验结果表明,这种方法对于训练小型参数检索模型是有效的,其性能优于其他检索和LLM基线方法。
6.ONCE: Boosting Content-based Recommendation with Both Open- and Closed-source Large Language Models(2023)
首次探索基于LLM的生成式新闻推荐,出自香港理工大学
**简述:**论文介绍了一种基于LLM的生成式新闻推荐框架GENRE,利用预训练语言模型中的语义知识来丰富新闻数据。该框架旨在提供灵活和统一的新闻推荐解决方案,包括个性化新闻生成、用户画像和新闻摘要。
GENRE 基于GPT3.5进行新闻推荐:
- 内容理解:输入新闻标题、摘要、类目信息,生成简短内容描述;
- 用户理解:输入用户历史行为数据,生成用户感兴趣的话题 和区域;
- 样本生成:对于历史行为数据稀疏的用户,基于少量行为样本生成相似的伪样本,用于扩充用户表征输入。
GENRE框架示意图:基于已生成伪样本增强用户理解,然后再生成更准确的伪样本。
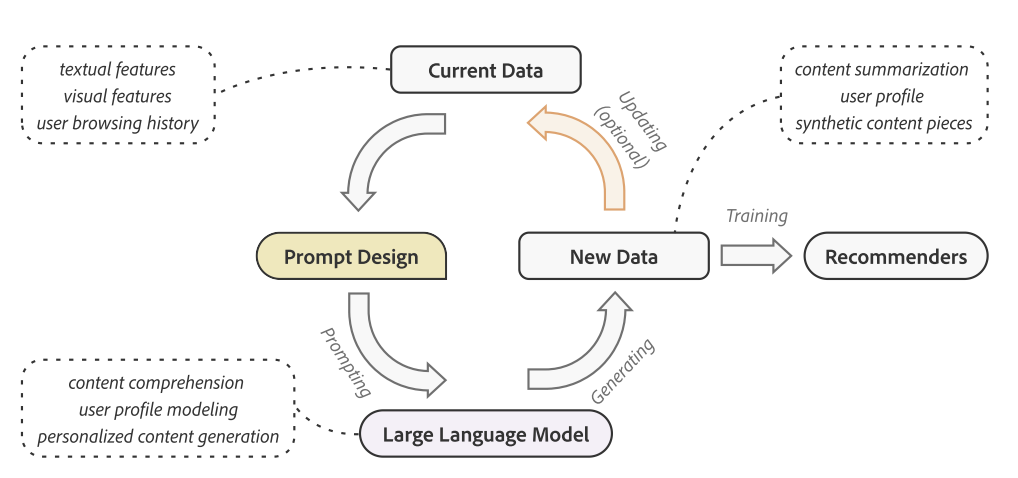
通过prompting增强样本的过程示意:
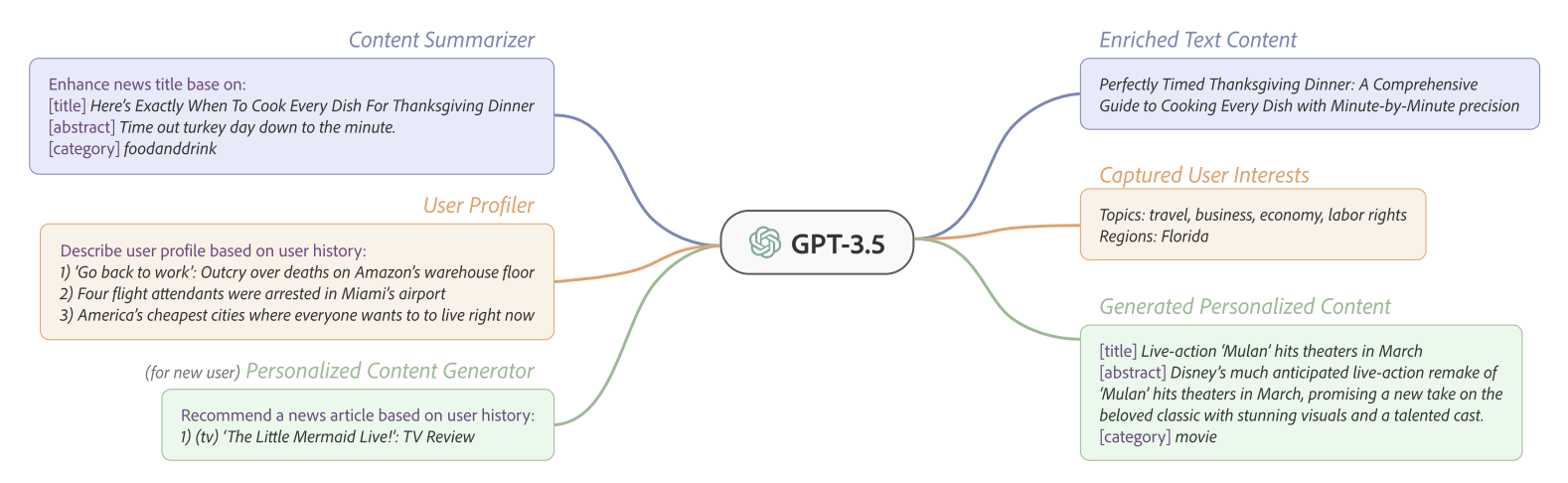
整体架构:
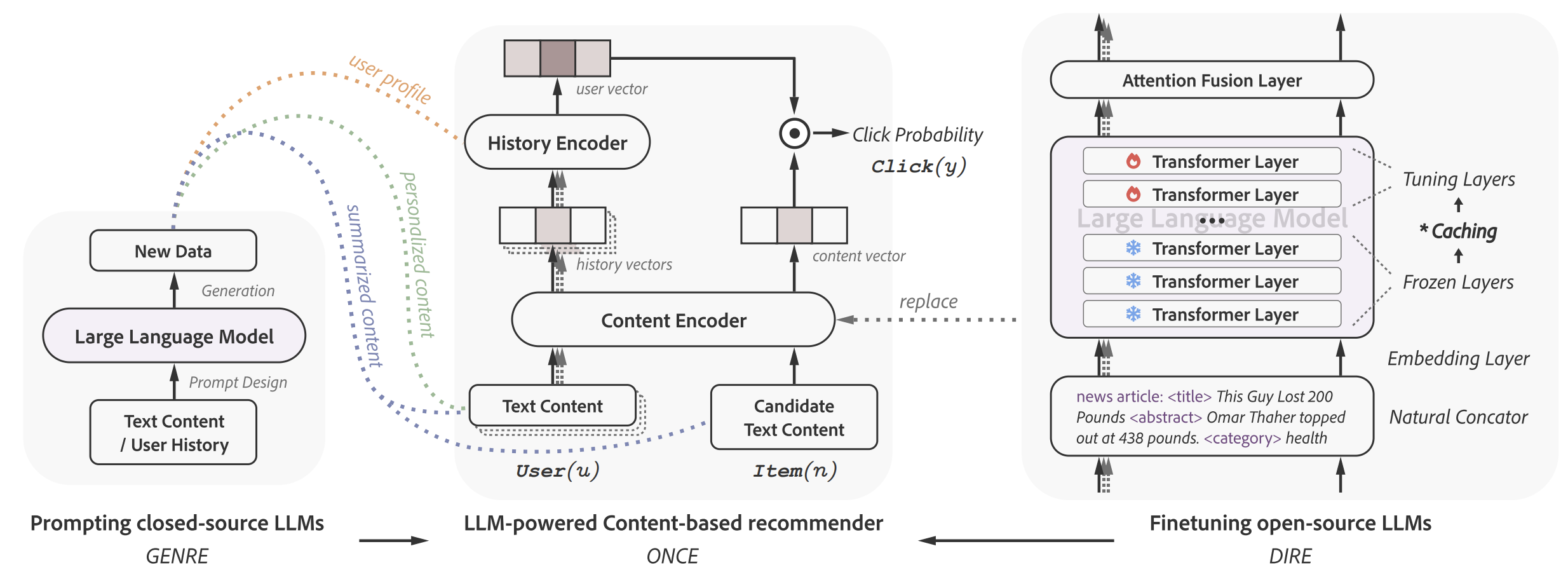
总结:GENRE是在特征工程上使用LLM作用
7.RecMind: Large Language Model Powered Agent For Recommendations
基于大型语言模型的推荐代理
**简述:**论文介绍了一种名为RecMind的基于大型语言模型的自主推荐代理,能够通过仔细的计划、使用获取外部知识的工具和利用个人数据来提供精确的个性化推荐。作者提出了一种新的算法Self-Inspiring,以提高LLM代理的规划能力。实验表明,RecMind在不同的推荐任务中优于现有的基于LLM的推荐方法,并在与最近需要完全预训练的P5模型竞争的任务中取得了有竞争力的性能。
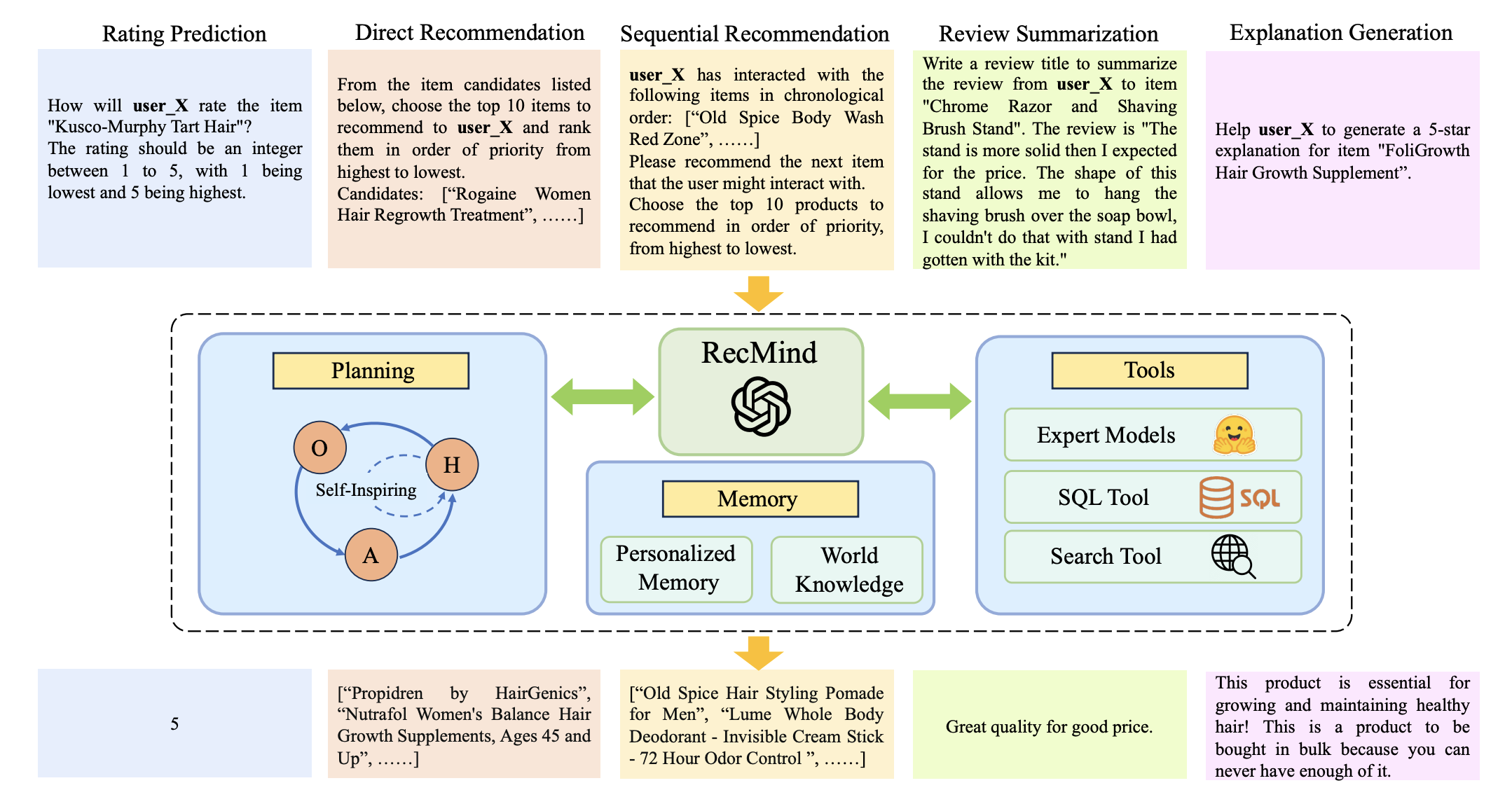
Planning:将任务分解为更小的、可管理的子目标,以处理复杂的任务。H :thought,A :action, O: observation

7.ls ChatGPT Fair for Recommendation? Evaluating Fairness in Large Language Model Recommendation
评估大型语言模型推荐中的公平性
**简述:**大型语言模型(LLM)在推荐系统中的应用带来了新的范式。然而,LLM可能包含社会偏见,因此需要评估其推荐的公平性。作者提出了一种新的基准(FaiRLLM),用于评估通过LLM进行推荐的公平性。这种基准包括精心设计的指标和涵盖多个敏感属性的数据集。使用FaiRLLM基准,作者发现ChatGPT在生成推荐时对某些敏感属性仍然表现出不公平。
8.ls ChatGPT a Good Recommender? A Preliminary Study
ChatGPT是一个好推荐器吗?
**简述:**本文探索了ChatGPT作为通用推荐模型,将其从大规模语料库中获得的知识转移到推荐场景中的潜力。通过设计提示,评估了ChatGPT在五个推荐场景中的性能,发现它在某些任务中表现良好,能够达到基准水平。此外,人类评估表明ChatGPT可以真正理解提供的信息并生成更清晰、更合理的结果。
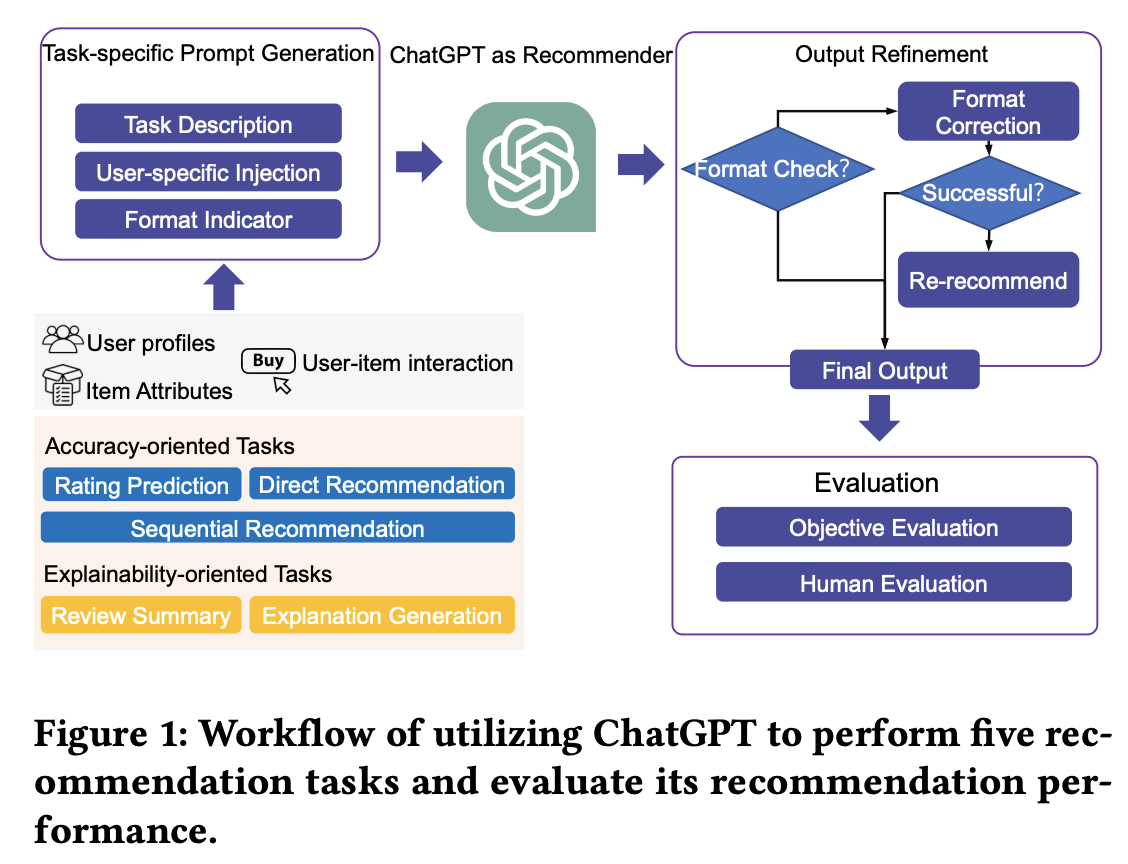
9.Recommender Systems in the Era of Large Language Model(综述)📎Recommender_Systems_in_the_Era_of_Large_Language_Models_LLMs.pdf

LLM在电商推荐系统的探索与实践
(1)LLM搭配类目
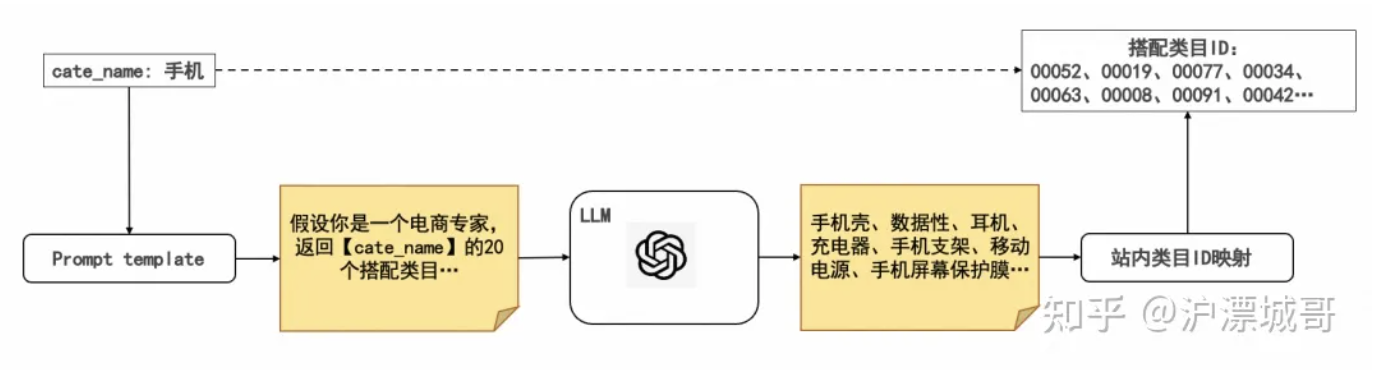
整体生产链路如图所示,主要包括三个部分:
- 基于站内类目体系,设计prompt template;
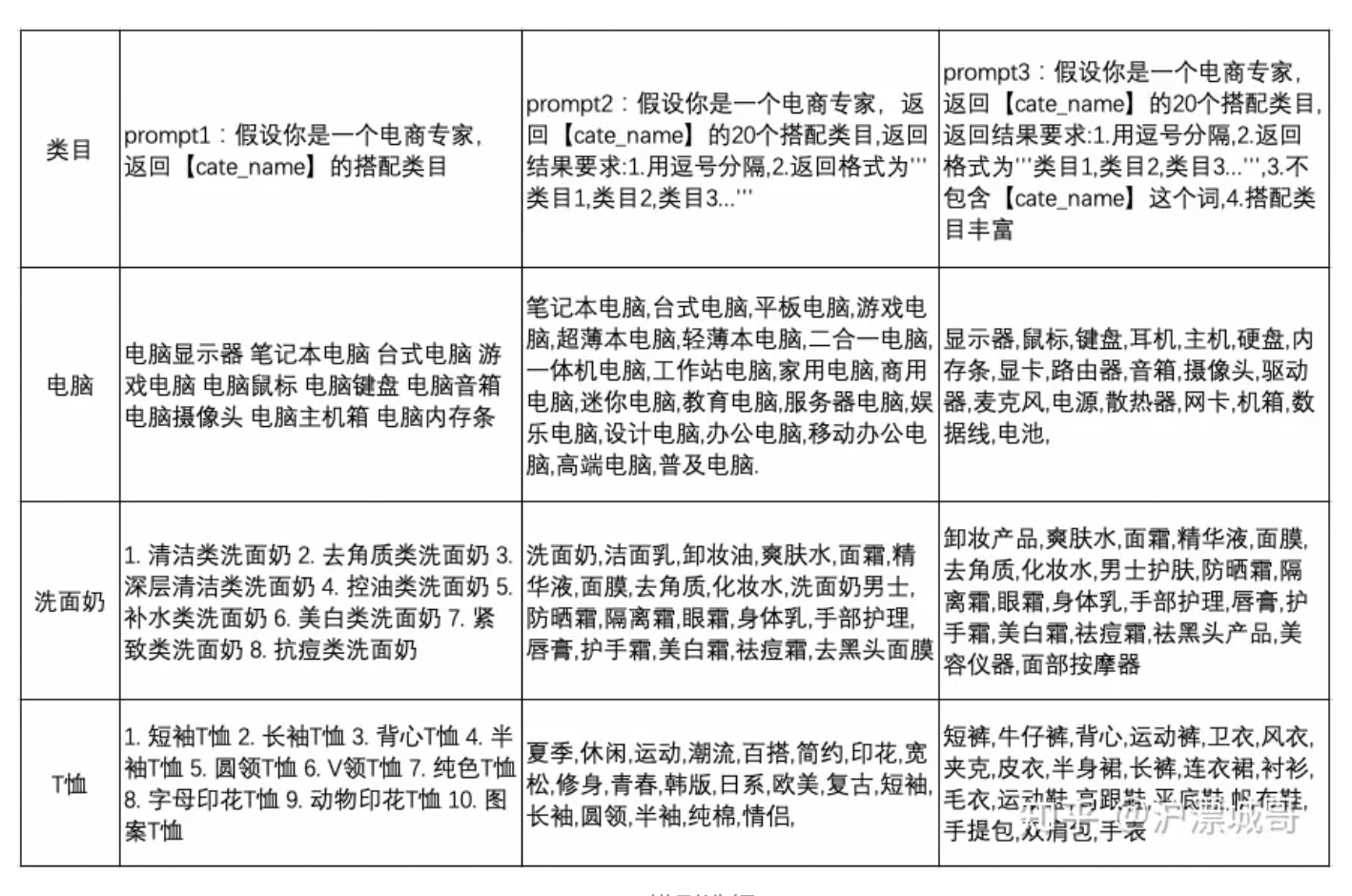
-
批量调用LLM模型,请求LLM知识;
-
进行知识抽取和站内类目ID映射。
由于LLM模型返回的是通用知识信息,存在与站内的类目体系无法完全对应的情况。站内类目ID映射可以采用以下两种方法:
-
- 基于文本相关性的向量召回。将LLM搭配类目和站内类目分别表征成文本embedding向量,然后通过向量召回的方式,选取与LLM搭配类目距离空间最近的top站内类目进行映射。
- 基于站内后验统计的query2cate映射。将搭配类目作为query,根据电商平台搜索query2cate的统计数据,使用该query下top的点击cate作为映射类目,实现LLM搭配到站内ID的映射。
主要应用:兴趣扩展-序列建模中
(2)商品语义表征
- 对于商品类目以及属性信息,采用mutli-hot形式对商品属性进行编码可拓展性不高,存在数据稀疏问题。
- 商家在命名商品标题时通常会添加一些与商品本身无关的修饰词(比如"特价"、"爆款"等),同时也包含一些冗余的类目词。商品标题语义上并不连贯,信息凌乱,直接进行mutli-hot或者文本编码难以得到很好的嵌入表示。
基于此,利用LLM对商品标题进行正则化,得到语义连贯的文本描述,再对其进行编码,从而丰富商品的特征。
具体方案:
a.先将商品标题进行分词得到描述词列表,同时结合商品的属性列表,限制LLM选出关键词输出商品的简短描述
你现在是一个买家。给定商品的描述词【A】以及各种属性【B】,请根据关键词和关键属性描述出商品是什么。
要求是只需要回答是什么,不要补充其他内容,尽量从A和B中选出词语进行描述,字数不超过40,
回答模版为:这个商品是...。
比如当A=['giyo', '公路', '山地车', '专用', '自行车', '单车', '专业', '骑行', '手套', '半指', '夏季', '男', '硅胶', '减震', '女'],
B=['尺码': 'XXL', '类目': '自行车手套', '适用对象': '通用', '颜色分类': '弧光半指-黄色-双面透气+GEL硅胶+劲厚掌垫', '上市时间': '2016年夏季', '货号': '1183', '品牌': 'GIYO/集优', '款式': '半指手套'],
输出:这个商品是GIYO牌的自行车半指手套。现在A=...,B=...
b. 商品语义向量-引入排序模型