好的数据可视化作品都是通过不断的数据对比分析实战出来的。
今天给大家带来一篇大数据工程师干货,从多角度解析做数据可视化的重要性,并解读一些适用的应用场景。大数据工程师们刷到这篇文章时一定要进来看看,满满的干货。
目录
-
- [1. 什么是数据可视化](#1. 什么是数据可视化)
- [2. 数据可视化的重要性](#2. 数据可视化的重要性)
-
- [2.1 提高理解效率](#2.1 提高理解效率)
- [2.2 支持决策](#2.2 支持决策)
- [2.3 发现潜在模式和趋势](#2.3 发现潜在模式和趋势)
- [2.4 增强数据的说服力](#2.4 增强数据的说服力)
- [3. 数据可视化的应用场景](#3. 数据可视化的应用场景)
-
- [3.1 市场分析](#3.1 市场分析)
- [3.2 产品设计](#3.2 产品设计)
- [3.3 运营管理](#3.3 运营管理)
- [3.4 科学研究](#3.4 科学研究)
- [4. 如何做好数据可视化](#4. 如何做好数据可视化)
-
- [4.1 选择合适的图表类型](#4.1 选择合适的图表类型)
- [4.2 保持简洁明了](#4.2 保持简洁明了)
- [4.3 注重色彩搭配](#4.3 注重色彩搭配)
- [4.4 提供交互功能](#4.4 提供交互功能)
- [5. 数据可视化工具推荐](#5. 数据可视化工具推荐)
-
- [5.1 Tableau](#5.1 Tableau)
- [5.2 Power BI](#5.2 Power BI)
- [5.3 D3.js](#5.3 D3.js)
- [5.4 ECharts](#5.4 ECharts)
- [5.5 Plotly](#5.5 Plotly)
- [6. 结论](#6. 结论)
大数据工程师在工作中经常会遇到下面这种情况:自己辛辛苦苦、加班加点、没日没夜做出来的数据分析报告交到 boss 们手上,结果却看不懂,全程黑人问号脸。原因就在于,自己埋头苦干做出来的数据分析结果,没有用能够让别人一目了然、清晰明了的呈现方式展示出来,努力全白费。
为了让大家对数据可视化不再束手无措,希望通过这篇文章和大家一起交流学习,解决一些我们共同的问题。
1. 什么是数据可视化
数据科学的大力发展,让信息科学领域面临一个巨大挑战:数据爆炸。然而,人类分析数据的能力已经远远落后于获取数据的能力。
数据量越来越大、越多元化,数据内容的噪声让人们在庞杂的数据世界中倍感枯燥繁琐,理解成本较高。这个挑战不仅在于如何从海量数据中提取出有用知识,还在于如何将数据转化成使人快速理解的知识。
如何从海量数据中提取知识是数据处理和数据挖掘的范畴,而如何让数据转化成使人快速理解的知识则需要数据可视化。
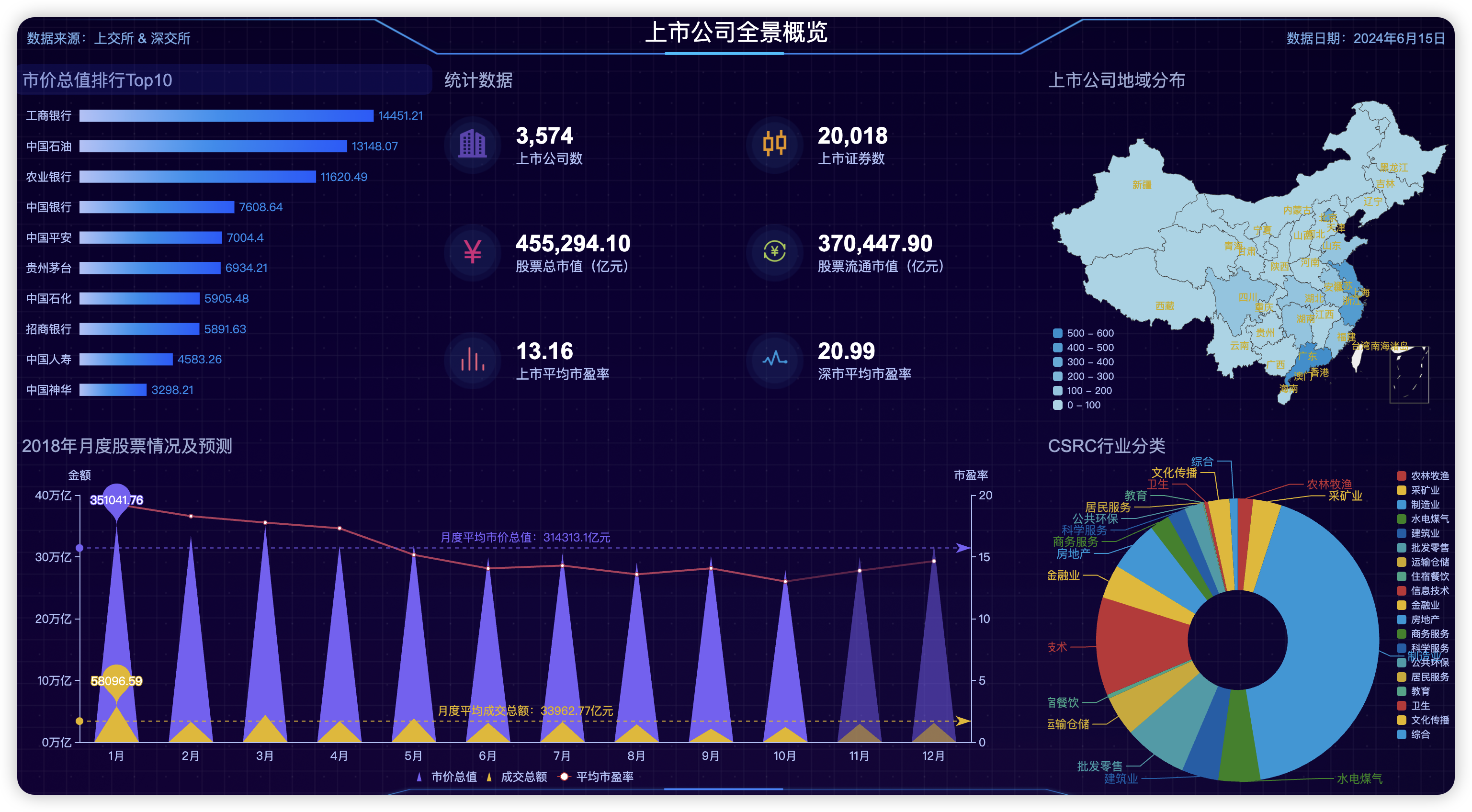
相比单纯的数字,图形形式可以让人更容易洞察到数据的分布、趋势、关系以及异常点,从而帮助决策者快速决策。数据可视化就是将数据转换成易读、易懂、易操作的图或表,以一种简洁明了、通俗易懂的方式展现和呈现数据。
2. 数据可视化的重要性
2.1 提高理解效率
图形化的数据展示可以极大地提高信息的传递效率。复杂的数据通过图形、图表等形式展示,可以使非专业人员也能快速理解数据背后的含义。
2.2 支持决策
在企业管理中,决策层往往需要在短时间内做出重要决策。数据可视化可以帮助决策者快速获取所需信息,支持他们做出准确的判断和决策。
2.3 发现潜在模式和趋势
通过图形和图表,工程师和分析师可以更容易地发现数据中的潜在模式和趋势,从而挖掘出更多有价值的信息,指导业务发展。
2.4 增强数据的说服力
视觉化的展示方式往往更具说服力。清晰直观的数据展示可以让观众更容易理解和接受数据背后的观点和结论。
3. 数据可视化的应用场景
3.1 市场分析
市场分析需要处理大量的销售数据、市场趋势和消费者行为数据。通过数据可视化,可以更清晰地展示市场变化趋势,帮助企业制定更精准的市场策略。
3.2 产品设计
在产品设计过程中,工程师需要分析用户反馈、使用数据等。通过数据可视化,可以更好地理解用户需求,优化产品设计,提高用户满意度。
3.3 运营管理
企业运营管理涉及各个方面的数据,如生产数据、物流数据、财务数据等。通过数据可视化,可以全面监控运营状况,提高管理效率。
3.4 科学研究
科学研究中,数据分析是必不可少的一环。通过数据可视化,研究人员可以更直观地展示实验结果、数据趋势,从而更有效地进行学术交流和成果展示。
4. 如何做好数据可视化
4.1 选择合适的图表类型
根据数据的特点和展示需求,选择合适的图表类型,如柱状图、折线图、饼图等。不同的图表类型适用于不同的数据展示场景。
4.2 保持简洁明了
数据可视化的目的是让观众快速理解数据背后的信息,因此在设计图表时要保持简洁明了,避免过多的装饰和复杂的设计。
4.3 注重色彩搭配
合理的色彩搭配可以增强图表的可读性和美观度。在选择颜色时,要考虑色彩的对比度和统一性,使图表更加易读。
4.4 提供交互功能
交互式的图表可以提高用户的参与感和理解深度。通过添加筛选、缩放、点击等交互功能,使用户可以更深入地探索数据。
5. 数据可视化工具推荐
为了帮助大数据工程师更好地进行数据可视化,以下是一些常用的数据可视化工具推荐:
5.1 Tableau
Tableau 是一种强大的数据可视化工具,适用于各种规模的企业。它支持多种数据源,并提供丰富的图表类型和交互功能,用户可以通过简单的拖拽操作创建复杂的可视化图表。
5.2 Power BI
Power BI 是微软推出的数据分析和可视化工具,特别适合与 Office 365 和 Azure 环境集成。它提供了强大的数据处理和分析功能,以及丰富的可视化选项,适用于从小型企业到大型企业的各种需求。
5.3 D3.js
D3.js 是一个基于 JavaScript 的数据可视化库,适用于前端开发者。它允许开发者通过代码自定义和创建复杂的可视化图表,并与网页内容无缝集成。
5.4 ECharts
ECharts 是由百度开源的一个可视化库,适用于前端开发者。它提供了丰富的图表类型和灵活的定制能力,适合需要高性能和高交互性的可视化项目。
5.5 Plotly
Plotly 是一个支持多种编程语言(如 Python、R 和 JavaScript)的数据可视化工具,适用于科学计算和数据分析领域。它提供了丰富的图表类型和交互功能,并支持在线分享和协作。
python
import plotly.express as px
import pandas as pd
# 创建一个虚拟数据集
df = pd.DataFrame({
'Category': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J'],
'Value1': [10, 15, 13, 17, 19, 12, 11, 18, 20, 14],
'Value2': [16, 5, 11, 9, 13, 10, 7, 6, 15, 12],
'Size': [40, 60, 80, 60, 50, 70, 90, 100, 60, 50]
})
fig = px.scatter(df, x='Value1', y='Value2', size='Size', color='Category',
title='漂亮的气泡图示例',
labels={'Value1': 'X 轴值', 'Value2': 'Y 轴值'},
size_max=100, template='plotly_dark')
fig.update_layout(title_font_size=24, title_x=0.5,
xaxis=dict(title_font_size=18),
yaxis=dict(title_font_size=18))
fig.show()工具太多了,在工具中常用的可能就是BI工具,比如帆软的,要是自己可以用代码绘图,那当然更好
6. 结论
数据可视化不仅仅是一个展示数据的工具,更是一个理解数据、挖掘数据背后价值的重要手段。对于大数据工程师来说,掌握数据可视化技能,选择合适的工具和方法,不仅能提升工作效率,更能提高数据分析的准确性和决策的科学性。希望通过这篇文章,能够帮助大家更好地理解和应用数据可视化,让数据真正服务于业务和决策。
小结
数据可视化是大数据工程师必备的一项技能,它不仅能够提升数据分析的效率和准确性,还能够帮助团队和决策者更好地理解数据,做出更科学的决策。通过选择合适的工具和方法,掌握数据可视化技能,大数据工程师们将能够在数据分析的道路上走得更远。
希望这篇文章能够帮助大家更好地理解和应用数据可视化。如果你有任何问题或建议,欢迎在评论区留言,与我们一起交流学习。