在人工智能的辉煌编年史中,语言模型(LMs)的崛起标志着自然语言处理领域的一个巨大飞跃。随着技术的进步,这些模型不仅在规模上日益庞大,更在性能上不断刷新着人们的认知边界。它们在问答、翻译、文本摘要等任务上展现出的卓越能力,被赋予了一个颇具神秘色彩的名称------"突现能力"。这些能力曾一度被认为是只有大型模型才能够解锁的黑匣子,但最新的研究却向这一观点提出了挑战。一些研究者开始质疑,是否只有庞大的模型才能拥有这些能力,或者小型模型在得到适当的训练后也能展现出类似的智能。
本文将深入探讨这一问题,从一个新的角度------预训练损失------来审视语言模型的这些神秘能力。预训练损失,作为衡量模型在预训练阶段学习效率的关键指标,可能隐藏着解锁模型性能的秘密。通过对不同规模的模型进行细致的预训练,并在一系列下游任务上评估它们的表现,研究者发现了一些令人惊讶的现象:预训练损失与模型的下游任务表现之间存在着密切的联系。这一发现不仅挑战了我们对模型规模的传统认知,更为我们理解语言模型的内在机制提供了新的视角。
预训练损失是否预测任务表现?
研究者们为了深入理解预训练损失与任务表现之间的关系,精心挑选了一系列中英文数据集,覆盖了多样化的任务类型。这些任务包括问答、常识推理、阅读理解、指代消解和数学问题解答等。每种任务都设计有特定的提示类型,如少次提示(few-shot)和零次提示(zero-shot),以及思维链提示(chain-of-thought prompting),以模拟模型在实际应用中可能遇到的情境。答案形式包括开放式答案和多项选择,以适应不同任务的需求。评价指标则涵盖准确率、期望匹配(Exact Match, EM)等,这些指标能够量化模型输出与真实答案之间的一致性。
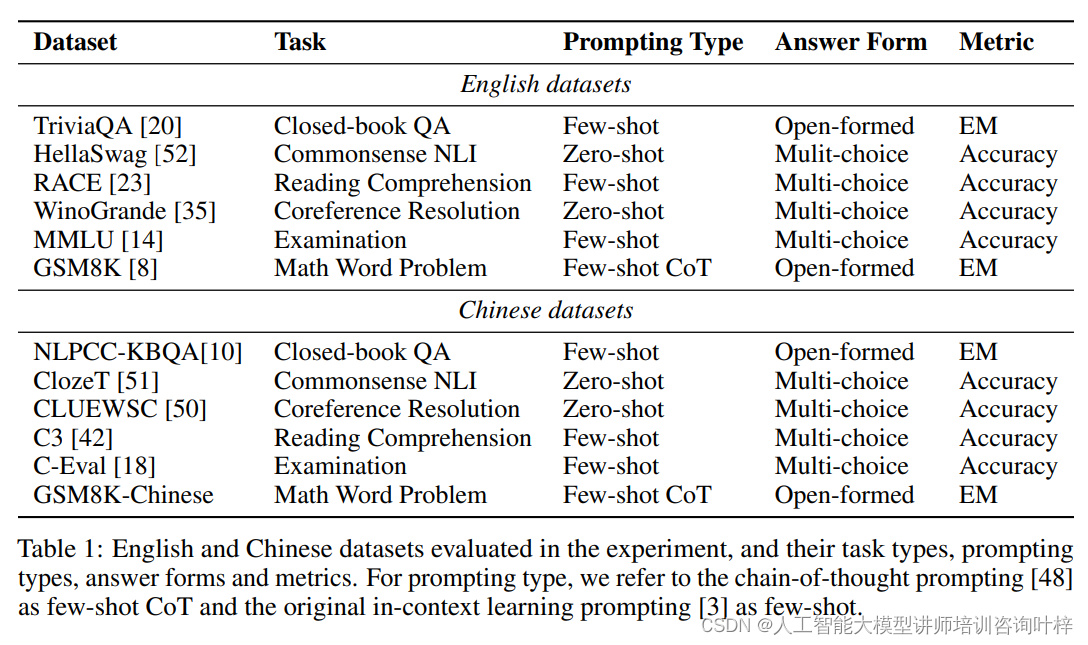 验中评估的中英文数据集,包括它们的任务类型、提示类型、答案形式和评价指标
验中评估的中英文数据集,包括它们的任务类型、提示类型、答案形式和评价指标
参与实验的模型都在统一的预训练设置下进行训练。研究者们采用了一个混合了英文和中文的语料库,该语料库由网页、维基百科、书籍和论文组成,其中英文与中文的比例为4:1。为了确保数据的一致性,使用了字节对编码(Byte Pair Encoding, BPE)算法进行分词处理。模型架构方面,采用了与LLaMA相似的设计,但根据实验需求进行了适当的调整,例如使用分组查询注意力替代多查询注意力,并在查询和键向量的一半维度上应用了旋转位置嵌入。
在实验的初步阶段,研究者们专注于分析预训练损失与模型在下游任务上表现之间的直接联系。通过对不同规模的模型进行训练,并在训练过程中保存中间检查点,研究者们能够评估模型在各个阶段的性能。实验结果显示,随着预训练损失的降低,模型在多项任务上的表现普遍得到提升。这一趋势在不同规模的模型中均有所体现,表明预训练损失是一个能够跨模型尺寸预测任务表现的有效指标。
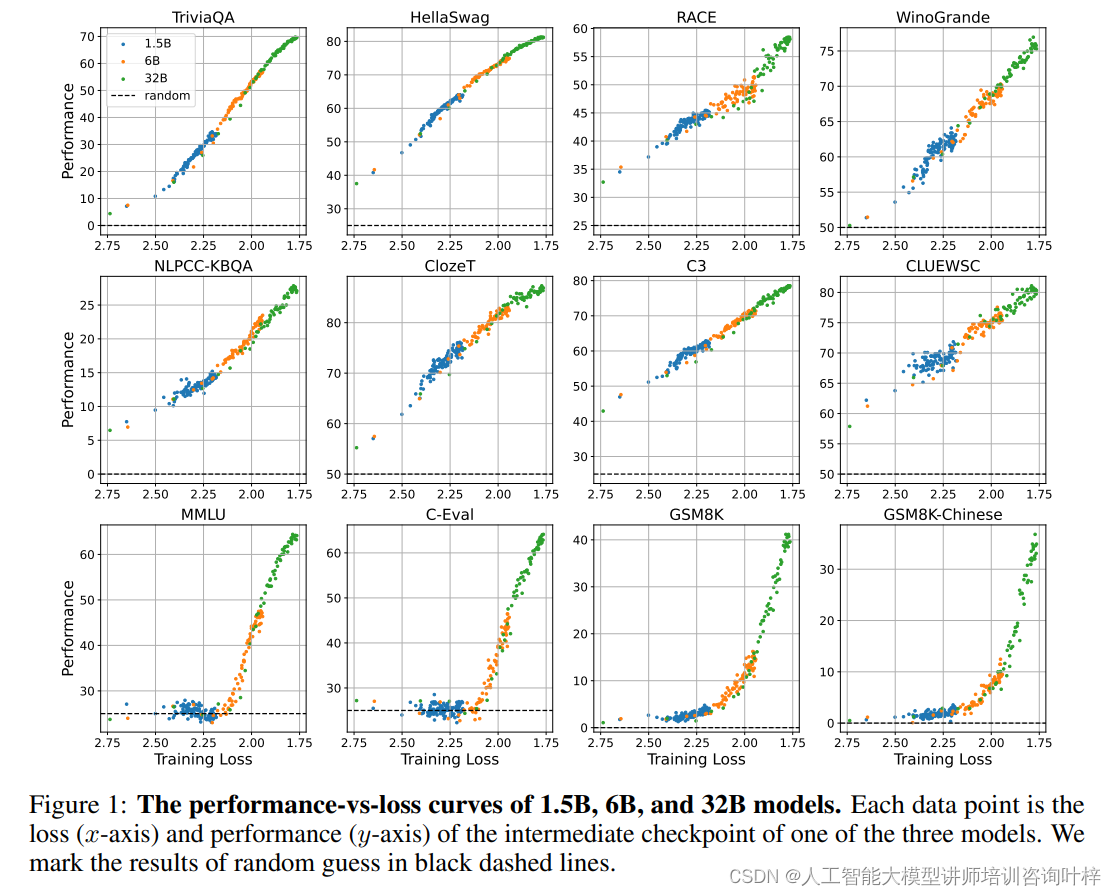 1.5B、6B和32B参数模型在不同训练阶段的损失与任务表现之间的关系曲线。每个数据点代表一个中间检查点的损失和表现
1.5B、6B和32B参数模型在不同训练阶段的损失与任务表现之间的关系曲线。每个数据点代表一个中间检查点的损失和表现
在探究训练令牌数量对模型表现的影响中究者们训练了一系列较小规模的模型,这些模型在不同数量的训练令牌上进行了预训练。结果显示,即使在模型尺寸和训练数据量不同的情况下,只要预训练损失相同,不同模型在下游任务上的表现也趋于一致。这进一步证实了预训练损失而非模型尺寸或数据量是决定模型表现的关键因素。
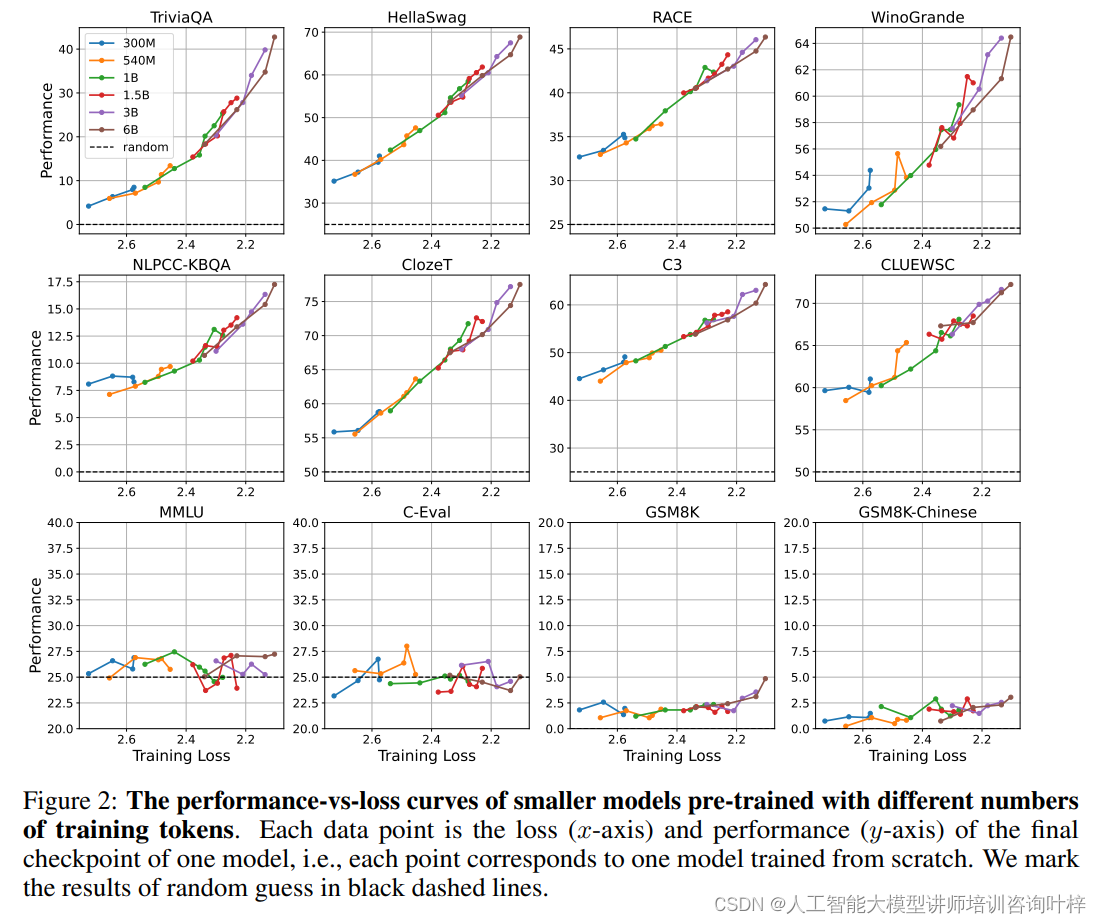 使用不同数量训练令牌预训练的较小模型的最终检查点的损失与表现关系曲线
使用不同数量训练令牌预训练的较小模型的最终检查点的损失与表现关系曲线
为了验证观察结果的普遍性,研究者们还分析了公开信息较为完整的LLaMA模型系列。尽管LLaMA模型在预训练语料、框架和架构上与研究者们训练的模型存在差异,但分析结果依然显示,不同规模的LLaMA模型在预训练损失与下游任务表现之间呈现出一致的趋势。这些发现强化了预训练损失作为预测模型表现的普适性指标的观点,即便在不同模型架构和训练设置中也是如此。
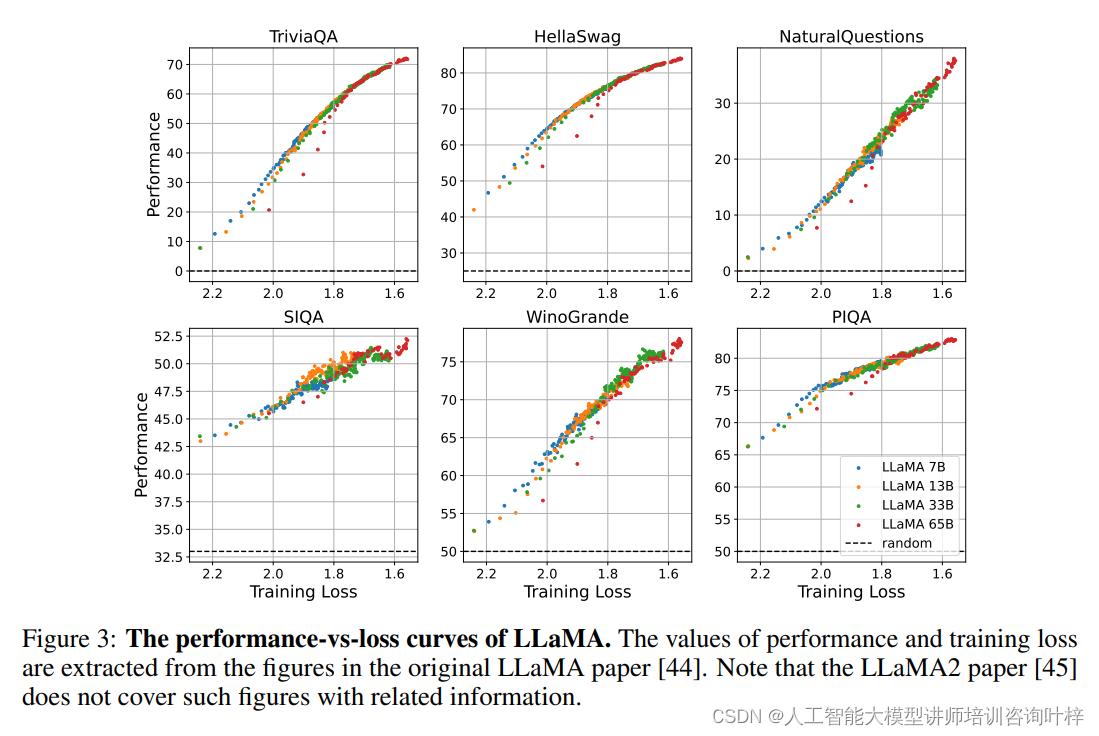 不同大小的LLaMA模型(7B、13B、33B、65B)的损失与表现关系曲线,数据点从原始LLaMA论文中的图表中提取
不同大小的LLaMA模型(7B、13B、33B、65B)的损失与表现关系曲线,数据点从原始LLaMA论文中的图表中提取
不同任务和指标的分析
在分析了不同数据集的表现趋势后,研究者们发现了一些关键的模式。特别是,当模型的预训练损失低于一个特定的阈值时,模型在某些任务上的表现会从随机猜测的水平显著提升。例如,在MMLU、C-Eval、GSM8K和GSM8K-Chinese这些数据集上,模型的准确率在预训练损失降至大约2.2以下时开始显著提高。这表明,对于这些任务,存在一个性能提升的临界点,只有当模型的预训练损失低于这个点时,模型才可能展现出超越随机猜测的性能。
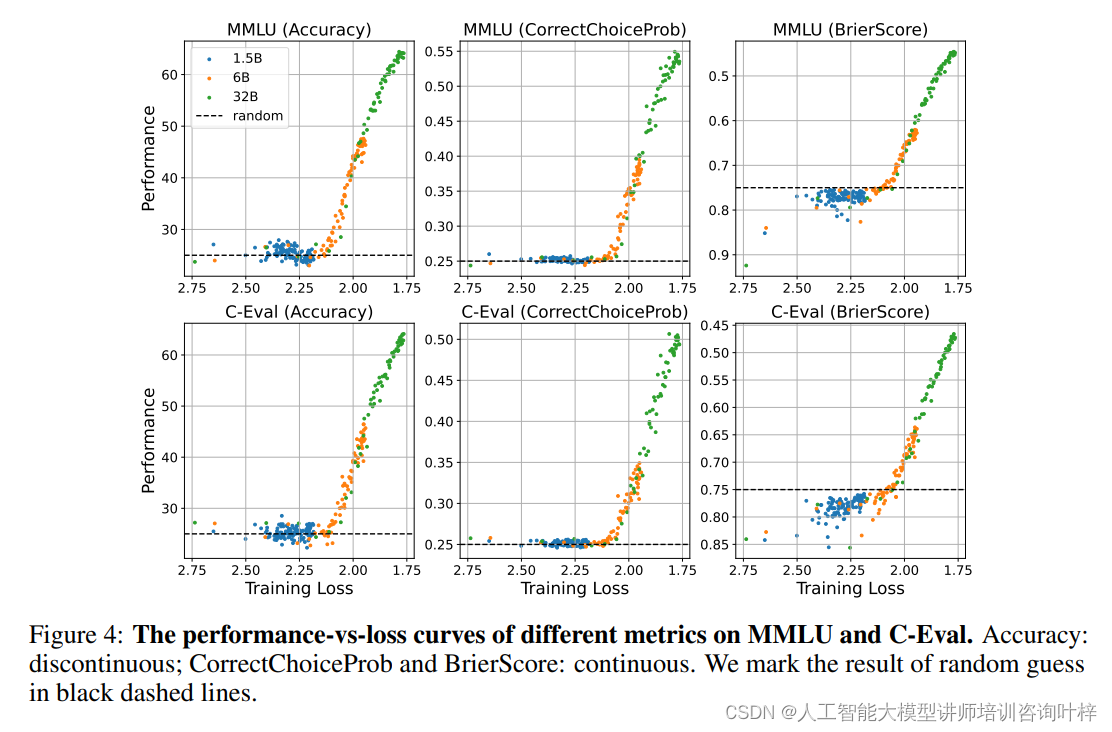 使用不同评价指标(准确率、正确选择概率、Brier分数)在MMLU和C-Eval数据集上的表现与损失关系曲线
使用不同评价指标(准确率、正确选择概率、Brier分数)在MMLU和C-Eval数据集上的表现与损失关系曲线
对于那些任务难度较低的数据集,如HellaSwag和RACE,模型的表现从一开始就随着预训练损失的降低而平稳提高。这种平稳的提升与那些需要通过特定阈值才能提升的任务形成了鲜明对比,暗示了任务难度可能是影响模型表现趋势的一个重要因素。
评价指标的选择对于观察和理解模型的突现能力至关重要。研究者们探讨了连续性和非连续性指标对模型表现评估的影响。非连续性指标,如准确率,提供了一个明确的成功或失败的度量,而连续性指标,如预测正确答案的概率(CorrectChoiceProb)和Brier Score,提供了一个更为细致的性能评估。
研究者们发现,即使在使用连续性指标的情况下,模型在特定任务上的性能提升仍然表现出了突现的特点。当预训练损失低于特定阈值时,连续性指标所衡量的性能同样会从接近随机猜测的水平提升到一个更高的水平。这一发现反驳了之前一些研究的观点,即突现能力可能仅仅是由于评价指标的非线性或不连续性所导致的假象。
Brier Score作为一个例子,它考虑了模型对所有可能选项的预测概率,而不仅仅是正确选项。研究者们发现,即使在使用Brier Score这样的连续性指标时,模型在预训练损失低于特定阈值时,其性能同样会有所提升。这表明,模型的突现能力并不仅仅依赖于评价指标的选择,而是模型学习能力的内在体现。
从损失角度定义突现能力
在探讨语言模型的突现能力时,研究者们提出了一种新颖的定义方法,这一方法基于模型在预训练阶段的损失表现。传统上,突现能力被认为是大型模型的专利,但新的视角提供了不同的见解:突现能力实际上是与模型的预训练损失紧密相关的现象。
通过对多个数据集和任务的分析,研究者们观察到一个共同的模式:当模型的预训练损失降低到特定的阈值以下时,模型在某些任务上的表现会突然从随机猜测的水平提升到一个显著更高的水平。这一发现引导研究者们将突现能力定义为一种仅在预训练损失低于特定阈值时才会显现的现象。
这种定义不仅挑战了以往关于突现能力与模型规模直接相关的假设,而且突出了预训练损失在模型学习能力中的核心作用。它表明,即使是小型模型,只要其预训练损失足够低,也有可能解锁那些被认为只有大型模型才具备的能力。
这种定义还为模型的训练和评估提供了新的指导。训练者现在可以更加关注模型在预训练阶段的损失表现,并将其作为优化模型性能的关键指标。通过调整训练策略以降低预训练损失,可以有效地促进模型突现能力的显现。
这一新的定义也对语言模型的研究领域产生了深远的影响。它鼓励研究者们进一步探索预训练损失与模型能力之间的关系,并利用这一关系来设计更有效的模型训练和评估方法。同时,也为理解语言模型的深层次工作原理提供了新的理论基础,推动了对模型智能本质的更深入理解。
尽管本研究提供了对语言模型突现能力的新见解,但仍存在一些限制,例如模型架构和训练算法的差异可能影响结果的普适性。未来的工作可以进一步探索这些因素如何影响模型的突现能力,以及如何通过不同的训练策略来促进这些能力的获得。