实时了解业内动态,论文是最好的桥梁,专栏精选论文重点解读热点论文,围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。
视觉转换器(ViT)架构已经广受欢迎,并广泛用于计算机视觉应用。然而,随着 ViT 模型规模的扩大,可训练参数直线上升,从而影响了部署和性能。因此如何进行有效的优化成为热点领域,各种的研究方向层出不穷。下图左一为基本的ViT块,左二到左五代表着紧凑架构优化法、剪枝优化法、知识蒸馏法和量化优化法。橙色虚线的部分代表每个领域重点优化的组件。
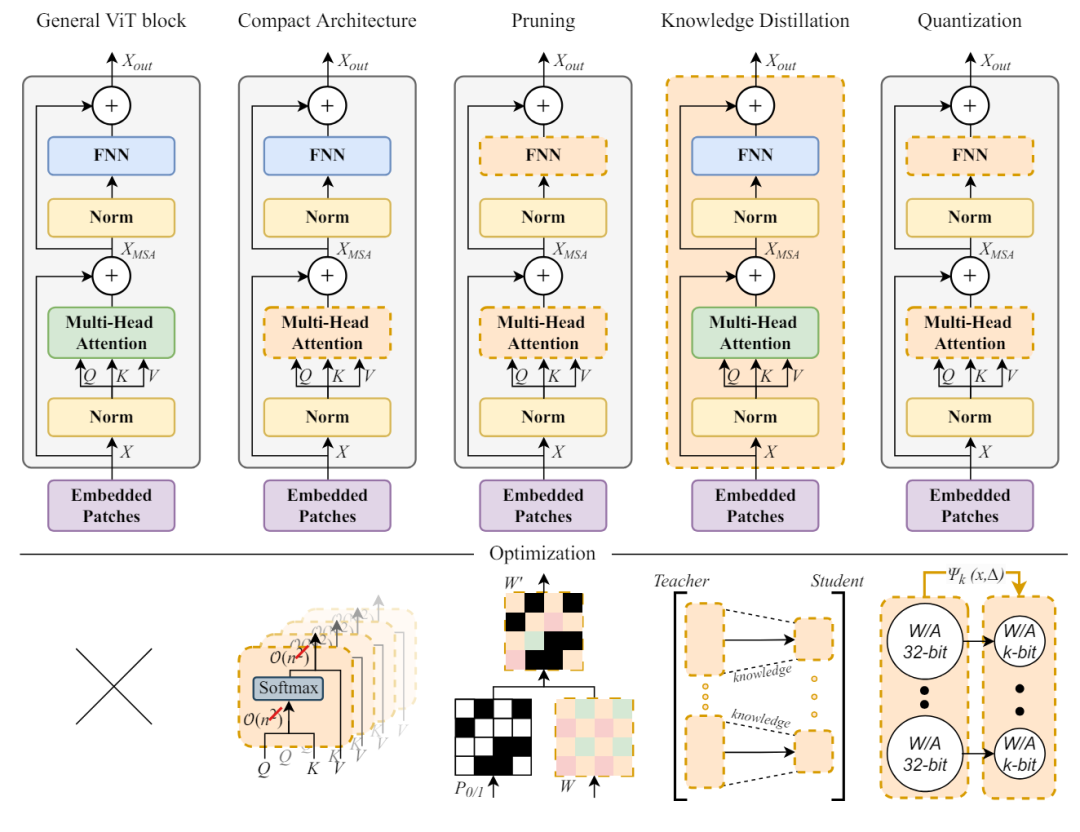
本文先来看看Pruning的优化方向。修Pruning的主要思路在于视觉转换器模型中删除不太重要的权重,通常分为非结构化修剪、结构化修剪和混合修剪技术。

Saliency显著性
在实际中,权重和显著性在神经网络的训练和优化过程中扮演着重要角色,特别是在权重修剪(pruning)中。权重修剪的目的是通过移除冗余或不重要的权重来减少模型的复杂性,提高推理速度,降低内存使用,同时尽量保持模型的性能。显著性通常通过一些评估标准(如梯度、Hessian 矩阵、费舍尔信息矩阵等)来计算。
Hessian 矩阵(海森矩阵)是一个方阵,包含了函数二阶偏导数的信息。

在神经网络中,Hessian矩阵用于描述损失函数(对标上图的f)在参数空间(对标x1,......,xn)中的曲率。它在评估权重显著性和权重修剪中有重要应用。使用 Hessian 矩阵的对角线元素评估每个参数的重要性。对角线元素代表了每个参数的二阶导数,反映了损失函数曲率的大小。曲率大的参数对模型性能影响较大,曲率小的参数影响较小。
费舍尔信息矩阵(Fisher Information Matrix, FIM)是衡量模型参数对数据概率分布敏感性的一种工具。它在神经网络权重修剪和模型优化中有重要应用。下面是费舍尔信息矩阵的定义和计算方法。

在实际中,对于每个样本计算参数θ的梯度gi(x为样本),然后通过外积求和来近似得到最终的数值:
|-----------------------------------------------------------------------------------|-----------------------------------------------------------------------------------|
| 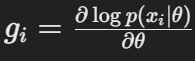 |
| 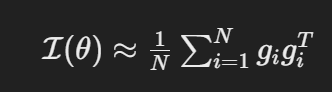 |
|
费舍尔信息矩阵和Hessian矩阵一样,也是评估每个权重的重要性。一般较大的对角线元素表示该参数对模型输出的影响较大,因此姑且称之为更重要。

非结构化修剪
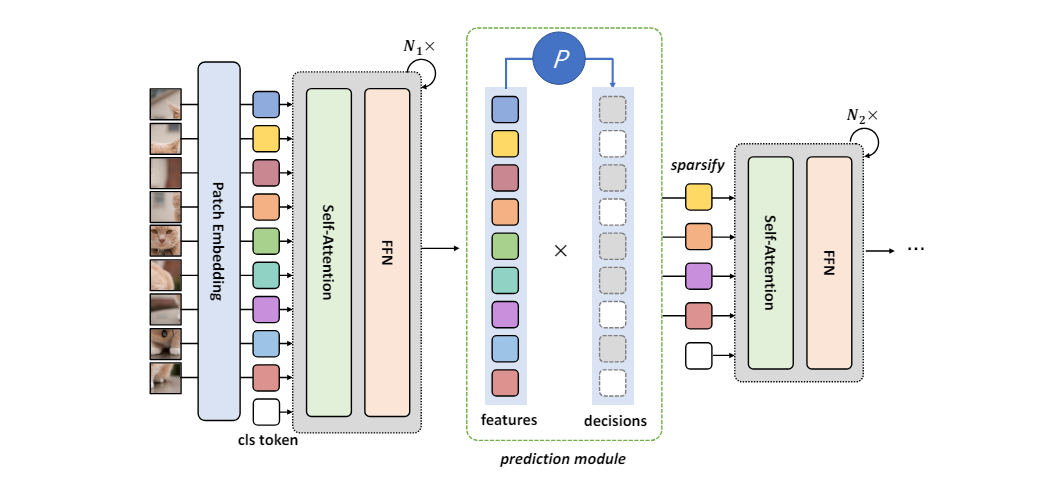
Rao引入了一个动态Token稀疏化框架,用于基于输入对冗余Token进行渐进式和自适应修剪,集成了轻量级预测模块来估计Token的重要性分数,并采用注意力屏蔽策略来区分令牌交互并以端到端的方式优化预测模块。
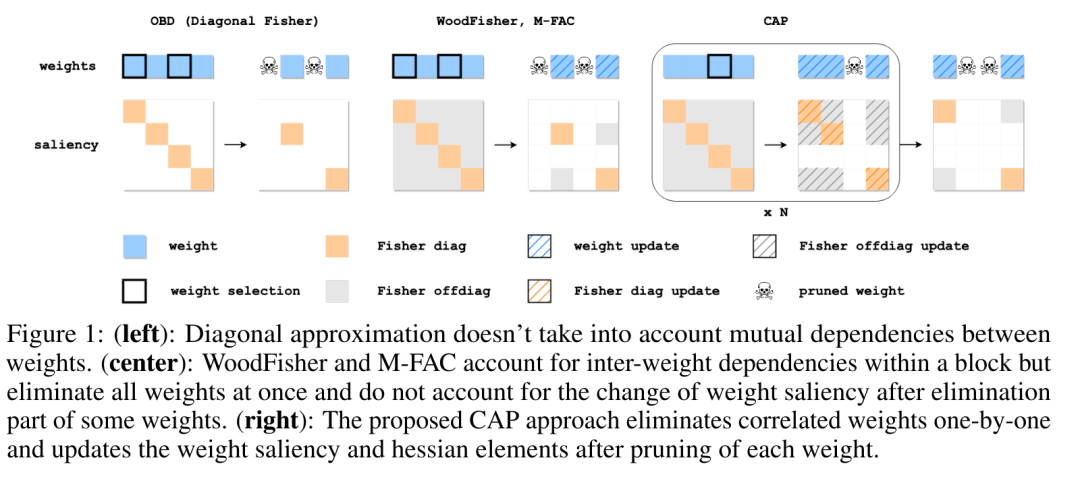
Cap提出了一种新型的理论基础修剪器,能够在修剪过程中准确有效地处理复杂的参数相关性。上图展示了三种不同的参数修剪方法:OBD(对角费舍尔)、WoodFisher/M-FAC和CAP,并比较了它们在处理参数之间的相互依赖关系上的不同之处。
说白了,第一种在减掉参数的时候,没有考虑到参数之间的依赖性。第二种虽然考虑到了,当时它的操作是一次性的。而CAP则是逐步的消除参数,同时在每一步每个参数被剪枝之后还会重新再次计算Saliency。
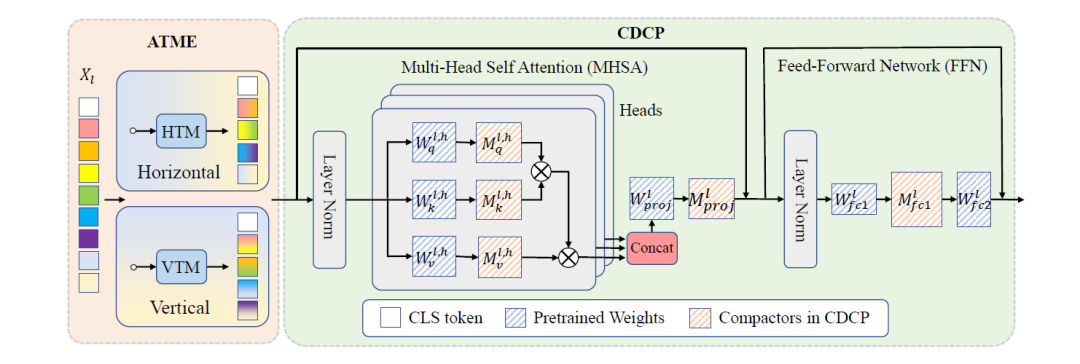
Cait引入了非对称标记合并,上图的HTM和VTM。在保留空间结构的同时有效地整合相邻标记,并结合一致的动态通道修剪。

Cait在图像输入Transformer的时候进行垂直和水平的压缩,在Vision Transformers中对不重要的通道进行统一修剪,增强了模型压缩。

结构化修剪
这种方法主要根据预定义的标准去除结构组件,例如注意力头或层。例如,WDPruning使用二进制掩码来根据参数的大小来识别无关紧要的参数。
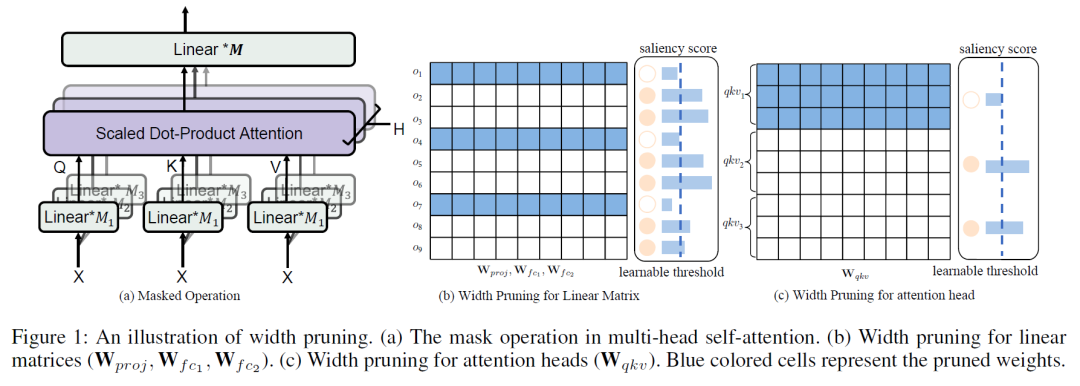
上图为宽度剪枝,从QKV的转化矩阵,到多头的注意力剪枝,其中蓝色部分为被修剪的参数。
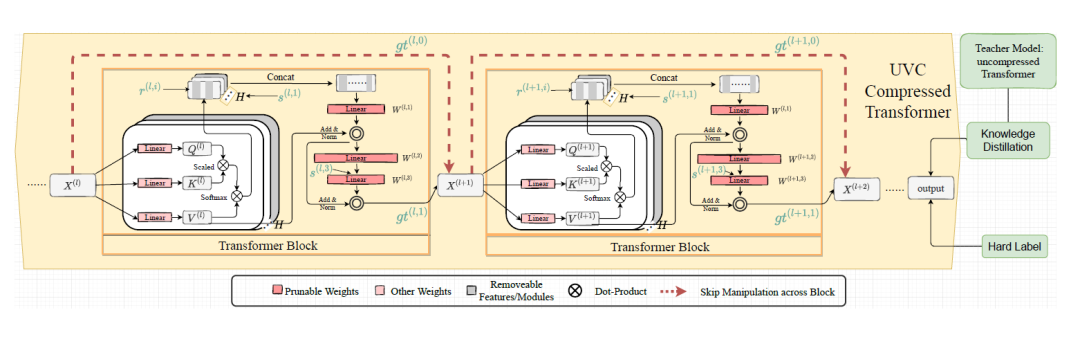
上图为Yu提出的了统一的框架,集成了修剪以生成紧凑型变压器。粉色为会被修剪的参数,虚线为连接跳跃修剪。
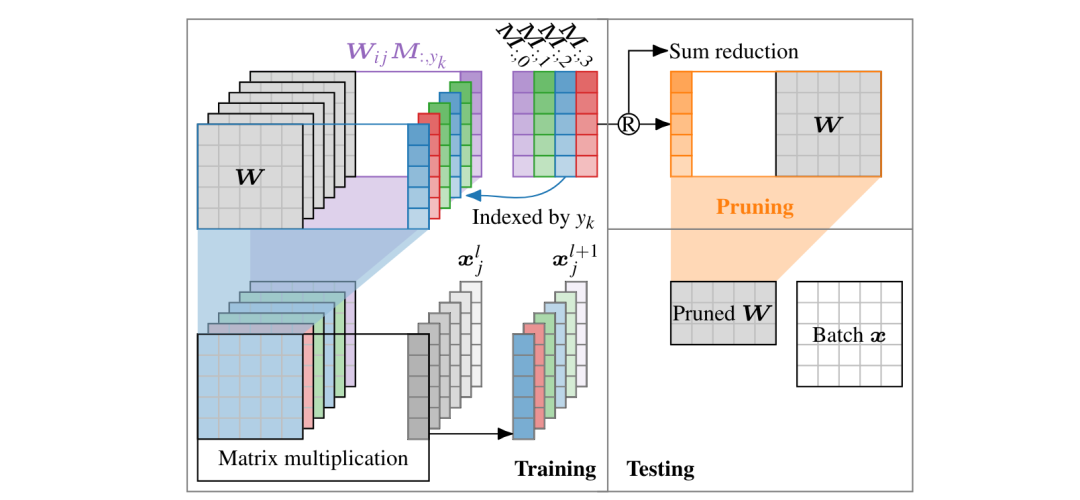
X-Pruner则是利用端到端的学习可解释性感知掩码来测量每个单元对预测目标类别的贡献,并自适应地搜索逐层阈值,以在确定修剪率的同时保留信息量最大的单元。整个修剪的过程如下:首先使用所提出的可解释性感知掩码训练一个Transformer,目标是量化每个单元对预测每个类别的贡献。然后在预定义的成本约束下探索逐层修剪阈值。最后对修剪后的模型再次执行微调。<请逆时针观察图片!>

混合修剪
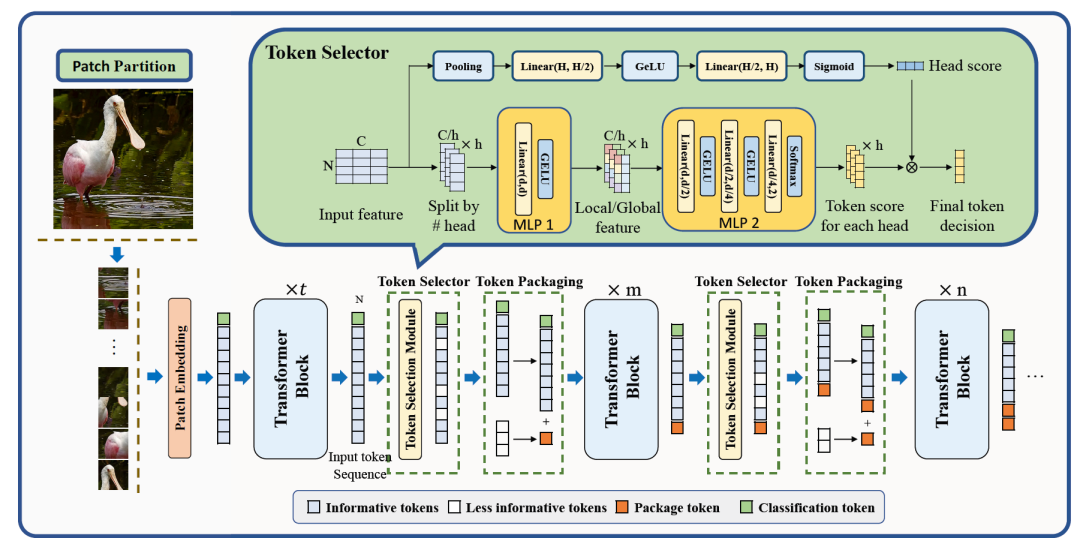
SPViT开发了一种基于动态注意力的多头令牌选择器,用于自适应实例级Token选择,同时使用软修剪技术将信息量较小的Token合并到包Token。
ViT-Slim利用具有预定义因子的可学习和统一的稀疏性约束来表示连续搜索空间中各个维度的全局重要性。在上一章节已经介绍过了。