随着人工智能技术的飞速发展,大型视觉语言模型(LVLMs)在多模态应用领域取得了显著进展。然而,现有的多模态评估基准测试在跟踪LVLMs发展方面存在不足。为了填补这一空白,本文介绍了MMT-Bench,这是一个全面的多模态基准测试,旨在评估LVLMs在需要专家知识和深思熟虑的视觉识别、定位、推理和规划的大量多模态任务上的表现。
MMT-Bench的构建
MMT-Bench是一个精心设计的多模态基准测试,用于全面评估大型视觉语言模型(LVLMs)在多任务理解方面的表现。MMT-Bench的构建过程分为两个主要部分:任务的分层结构和数据收集流程。
任务的分层结构
MMT-Bench的设计始于一个分层的任务结构,这有助于确保广泛的多模态任务得到覆盖。这个过程通过去重和筛选,最终确定了32个核心元任务。这些元任务进一步被细分为162个子任务,每个子任务都旨在评估模型在特定领域内的具体能力。
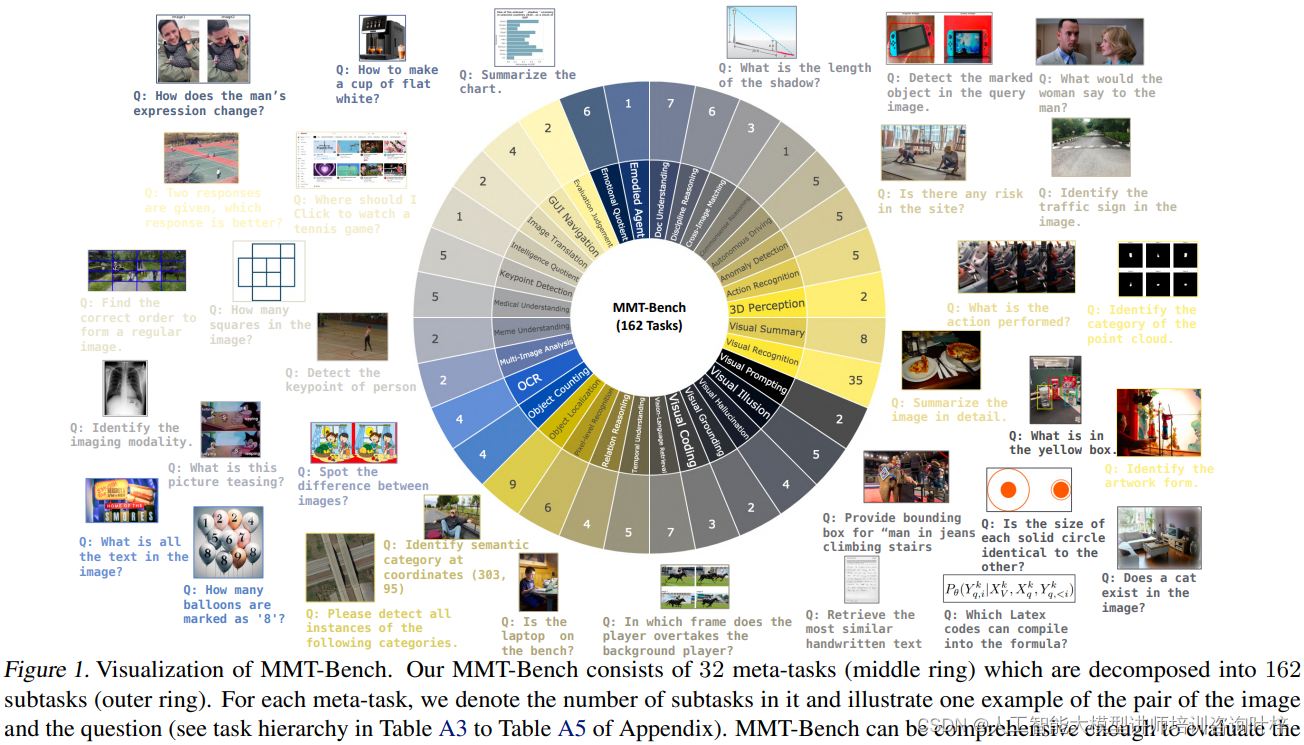
Figure 1 MMT-Bench的可视化内容展示了MMT-Bench由32个元任务(middle ring)组成,这些元任务进一步分解为162个子任务(outer ring)。
- 元任务的表示(Meta-tasks): Figure 1 中间层的环展示了32个元任务,这些元任务代表了多模态理解中的高层次分类。每个元任务都是围绕多模态处理和理解的一个特定领域,如视觉识别、文本理解、场景分析等。
- 子任务的分解(Subtasks): 外层环进一步将每个元任务细分为子任务。总共有162个子任务,这些子任务是评估模型在更具体、更细分领域能力的方式。例如,视觉识别元任务可能会被细分为物体检测、图像分类等子任务。
- 任务数量: 对于每个元任务,图中标注了包含的子任务数量,这提供了对每个领域内评估的深度和广度的直观理解。
- 图像和问题示例: 每个元任务旁边都展示了一个图像和问题对的例子,这有助于理解每个任务的具体内容和评估的类型。例如,一个问题可能要求模型识别图像中的物体或者解释图像中的场景。

MMT-Bench中包含的13种图像类型,如Figure 2所示这些图像类型要求模型能够解释各种视觉输入。这13种图像类型包括自然场景、合成图像、深度图、文本丰富的图像、绘画、截图、点云、医学图像等。
为了确保子任务的质量和相关性,研究团队制定了三个选择标准:子任务是否测试基本的多模态能力、是否对当前LVLMs构成挑战、以及测试样本是否可以公开获取。这些子任务覆盖了从视觉识别和定位到更复杂的推理和规划等多种能力。
数据收集流程
研究团队进行了数据集搜索,使用Google、Paper With Code、Kaggle和ChatGPT等多种来源,基于子任务的名称寻找相关的数据集。一旦确定了合适的数据集,团队就会下载并仔细评估它们的适用性,以确保它们能够用于评估特定的子任务。
接下来,研究团队构建了元数据(metadata),这是一种统一格式,用于整理下载的数据集。元数据包括图像和元信息,元信息包含了生成问题和答案所需的必要信息,如手动注释的所需能力和视觉提示类型。为了提高评估效率,在每个任务中,团队通过随机抽样的方式,将样本数量限制在200个以内。
研究团队为每个子任务生成了多选视觉问题和答案。这一步骤涉及到根据具体任务手动设计规则或使用ChatGPT生成问题和选项。例如,在草图到图像检索任务中,使用相应的图像作为正确答案,并从元数据中随机抽样生成其他选项。
MMT-Bench包含了31,325个多选视觉问题,涵盖了自然场景、合成图像、文本丰富的图像、医学图像等13种输入图像类型。这些问题覆盖了32个核心元任务和162个子任务,用于评估视觉识别、定位、推理、OCR、计数、3D感知、时间理解等14种多模态能力。
通过这一详尽的数据收集和任务设计流程,MMT-Bench能够全面评估LVLMs在多模态多任务理解方面的能力,为研究者提供了一个强大的工具,以推动多模态人工智能领域的发展。
实验
研究团队挑选了30种不同的公开可用模型,包括专有模型和开源模型,进行了深入的测试和分析。
这些模型中,包括了GPT-4V、GeminiProVision和InternVL-Chat等知名模型。GPT-4V和GeminiProVision作为专有模型,以其先进的性能和专有技术而闻名。而InternVL-Chat作为一个开源模型,代表了社区驱动的模型开发和协作精神。这些模型被选中是因为它们在视觉语言任务中展现出了卓越的能力,并且能够代表当前LVLMs的不同发展水平。
评估过程中,研究者采用了MMT-Bench中的多选视觉问题对这些模型进行了测试。这些问题覆盖了广泛的多模态任务,要求模型不仅要有出色的视觉识别能力,还需要有理解、推理和规划的能力。通过对模型在所有子任务上的表现进行综合评分,研究者能够得出每个模型的整体性能。
结果显示,即使是这些先进的模型,在MMT-Bench上的准确率也仅在63.4%到61.6%之间。InternVL-Chat以63.4%的准确率略微领先,而GPT-4V和GeminiProVision分别以62.0%和61.6%的准确率紧随其后。这一发现揭示了即便是当前最顶尖的模型,也有很大的提升空间,特别是在多任务智能方面。
研究者还探讨了不同提示方法对模型性能的影响。提示方法是指在向模型提出问题时所采用的措辞和指令的方式。研究发现,某些任务在采用特定的提示方法时,模型的表现会有所提升。这表明,问题的表述方式对于模型的理解能力和最终的输出结果有着直接的影响。
例如,在视觉推理任务中,如果提示能够更精确地引导模型关注图像中的关键部分,模型的推理能力可能会得到增强。在图像描述任务中,开放式的提示可能会鼓励模型生成更丰富、更详细的描述。这些发现对于未来设计更有效的人机交互界面和改进模型的训练方法具有重要意义。
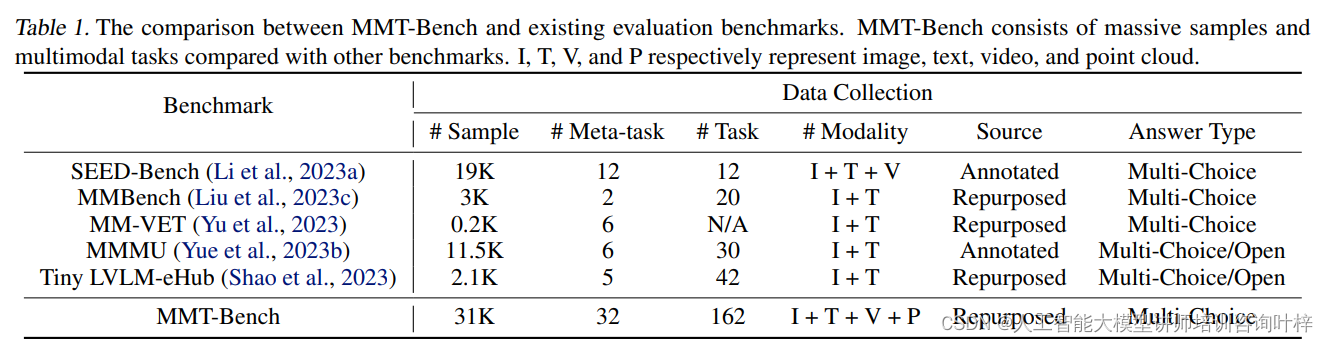
Table 1 比较了MMT-Bench与其他现有评估基准在OCR(光学字符识别)相关任务上的样本数据。表格中列出了不同基准的样本数量、任务类型、平均单词数、最小值、中位数、最大值以及标准差。它还提供了每个基准的元任务数量、任务数量、模态类型(如图像I、文本T、视频V、点云P)和答案类型(如多选题)。
例如,MME基准有40个样本,任务类型为1,平均单词数为2.5,最小值为1,最大值为5,标准差为1.6。相比之下,MMT-Bench有600个样本,平均单词数为14.8,最小值为1,最大值为103,标准差为22.7。这表明MMT-Bench在样本数量和单词数上都显著高于其他基准,意味着它提供了更丰富的数据集来评估模型的OCR能力。
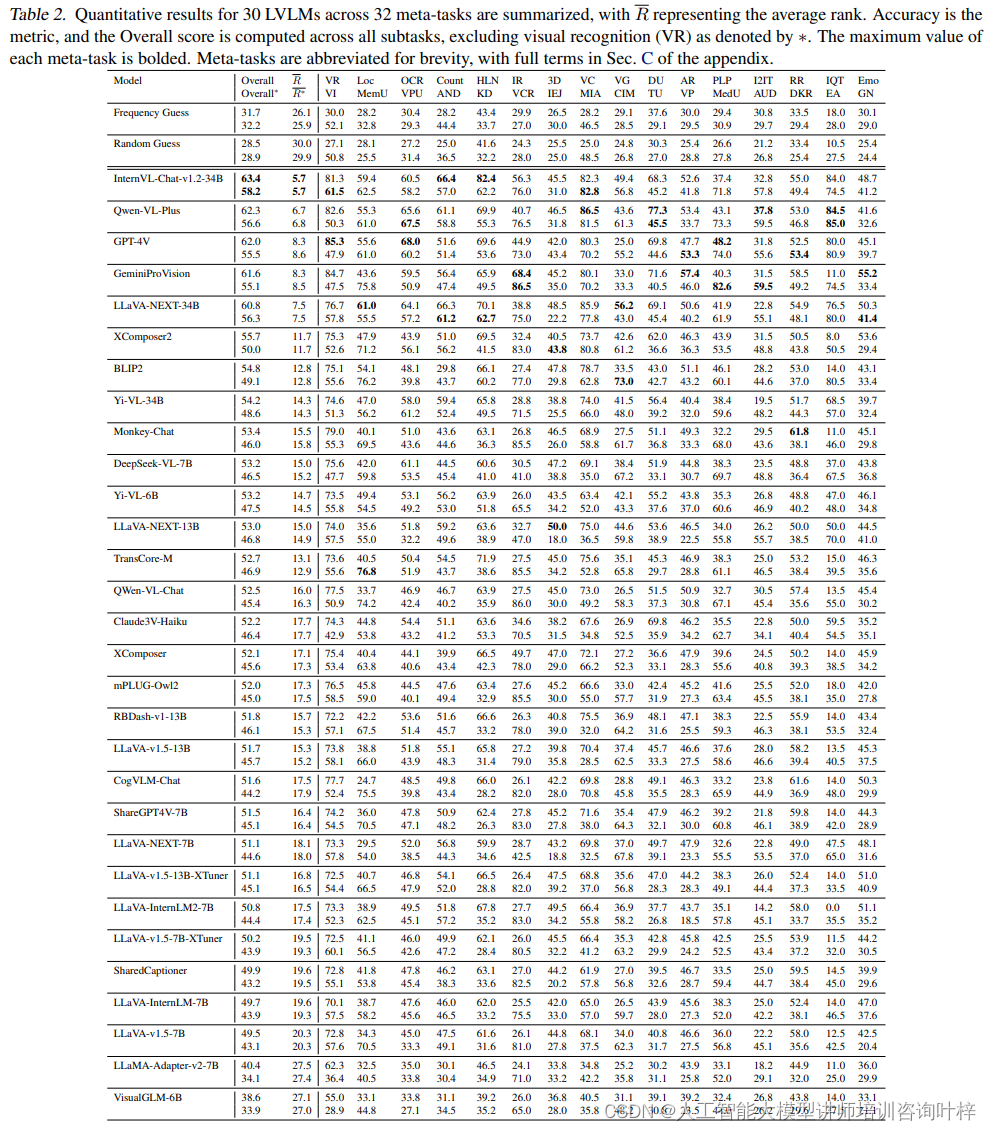
Table 2 汇总了30种不同的大型视觉语言模型(LVLMs)在MMT-Bench的32个元任务上的性能。表格列出了每个模型的总体准确率(Overall Accuracy)以及在每个元任务上的表现,包括视觉识别(VR)、定位(Loc)、OCR、计数(Count)、3D识别(3D)、视觉字幕(VC)等。
例如,InternVL-Chat-v1.2-34B模型在所有子任务上的总体准确率为63.4%,在视觉识别任务上达到了81.3%的准确率,而在文档理解(Doc Understanding)任务上准确率为58.7%。这些数据提供了对模型在不同任务类型上性能的深入洞察。
任务分析
任务分析部分利用MMT-Bench的广泛任务覆盖,对LVLMs进行了任务映射评估。
任务向量和Kendall's tau相关性度量
为了量化任务之间的关系,研究者采用了任务向量的概念。每个任务通过一个向量在高维空间中表示,这个向量基于模型在该任务上的微调权重与初始权重之间的差异。通过计算这些向量之间的余弦相似度,可以确定任务之间的接近程度。Kendall's tau是一种统计方法,用来衡量两组排名之间的相关性。在这项研究中,它被用来衡量模型在不同任务上的性能排名的相关性。
实验过程
研究者首先使用了一个预训练的模型作为探测模型,并针对每个子任务构建了任务数据集。然后,通过微调探测模型来获得每个任务的任务向量。这些向量随后被用于构建任务图,任务图上的每个点代表一个任务,点与点之间的距离表示任务之间的相似度。
结果分析
通过任务图,研究者观察到当两个任务在图上的距离较近时,模型在这些任务上的性能排名更为一致。这意味着如果两个任务在多模态能力上相似,模型在这些任务上的表现也应该相似。这种一致性为理解模型的多模态能力提供了有价值的见解,并可以帮助识别模型在特定类型的任务上可能存在的弱点。
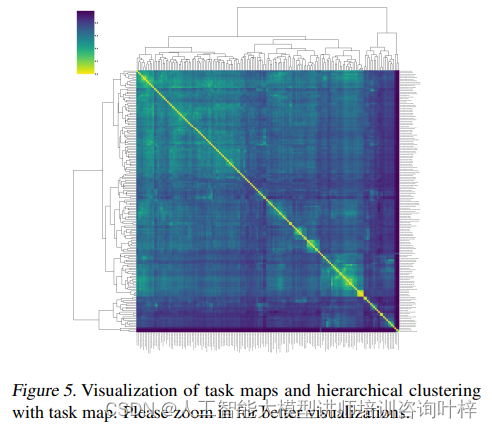
如图,研究者利用MMT-Bench广泛的任务覆盖,通过任务图来评估LVLMs的多模态性能。通过分析任务之间的关系,可以系统地解释不同任务在多模态能力中的作用。研究者使用了任务向量和Kendall's tau相关性度量来量化任务之间的关系和模型在不同任务上的性能排名。结果表明,当两个任务在任务图上距离较近时,模型在这些任务上的性能排名更为一致。通过这个图,可以观察到任务是如何被分组的,以及这些组与模型性能之间的相关性。
任务图和任务向量的分析不仅帮助研究者理解了不同任务之间的关系,而且还可以用来预测模型在新任务上的表现。如果一个新任务与任务图上的某个任务相近,那么可以预测模型在这个新任务上也可能有类似的表现。这种方法为模型的选择和优化提供了一种基于数据的决策支持。
MMT-Bench作为一个评估多模态多任务理解的全面基准测试,为衡量在多任务通用人工智能(AGI)发展道路上的进展提供了重要工具。通过这一基准测试,研究者可以识别当前LVLMs的强项和弱点,并为未来的模型改进和应用开发提供指导。我们期待MMT-Bench能够激励社区进一步推动LVLMs的研究与开发,使我们更接近真正智能的多模态系统的实现。