|------|-------|---|---|-------|
| 专业 | 小四号宋体 | 班级 || 小四号宋体 |
| 姓名 | 小四号宋体 | 学号 || 小四号宋体 |
| 指导教师 | 小四号宋体 ||||
| 题目 | 基于大数据的B站广告投放分析及可视化 ||||
| (1.内容包括:课题的来源及意义,国内外发展状况,本课题的研究目标、内容、方法、手段及进度安排、实验方案的可行性分析和已具备的实验条件、具体参考文献等。2.撰写要求:字体为宋体、小四号,字数不少于1500字,1.5倍行距。) 课题的来源及意义 来源 随着互联网的快速发展和数字化转型,广告行业面临着诸多挑战和变革,传统的广告投放方式难以满足市场需求。在当今大数据时代,广告投放的效率和效果对于企业的营销策略至关重要。传统的广告投放方式往往缺乏对投放效果的数据分析和精准把握,因此,利用大数据技术对广告投放进行分析和优化具有重要的实际意义和应用价值。 意义 * 提高广告投放效果:通过对海量的数据进行深度挖掘和分析,可以实现对受众的精准定位和分类,从而提高广告的投放效果和投资回报率。 * 降低广告成本:精准的广告投放可以避免广告在不相关受众中浪费,减少广告成本,并使有限的广告预算得到更有效地利用。 * 提升用户体验:精准的广告投放可以向用户推送符合其个人兴趣和需求的广告内容,提升用户体验,增强用户对广告的认同感。 * 促进广告行业创新:基于大数据的广告精准投放分析为广告行业的创新提供了新的思路和方法,推动了广告行业向智能化、个性化的方向发展。 国内外发展状况 国内发展状况: 在国内,随着互联网和移动设备的普及,大数据技术在广告行业的应用也得到了快速发展。一些大型的互联网公司,如阿里巴巴、腾讯等,也利用大数据技术进行广告精准投放。他们通过分析用户的搜索记录、浏览记录、购买行为等信息,以实现更精确的广告推送。此外,一些专门的大数据分析和广告优化公司,如字节跳动等,也提供了基于大数据的广告投放分析和优化服务。 国外发展状况: 在国外,大数据技术在广告投放领域的应用已经非常普遍。一些知名的互联网公司,如Google、Facebook、Twitter等,都利用大数据技术进行广告精准投放。他们通过收集和分析用户的行为数据、兴趣爱好、地理位置等信息,以实现更精确的广告推送。此外,一些专门的大数据分析和广告优化公司,如DoubleClick等,也提供了基于大数据的广告投放分析和优化服务。 综上所述,国内外都在基于大数据的广告精准投放领域取得了一定的成果。未来的研究方向包括进一步提高数据处理效率、加强用户行为分析、优化广告投放策略,以及开发更先进和实用的可视化分析工具。 本课题的研究目标 研究目标一:建立广告投放数据收集和分析系统 在课题研究中,首要的研究目标是建立广告投放数据的收集和分析系统。这一系统能够有效地收集和存储广告投放数据,并运用大数据技术进行深入的分析。通过该系统,我们可以获取广告的展示次数、点击次数、转化率等关键指标,为后续的投放优化提供数据支持。 研究目标二:挖掘用户行为和兴趣,实现精准投放 在完成数据收集和分析系统的构建后,课题将进一步研究如何挖掘用户行为和兴趣,以实现广告的精准投放。通过分析B站用户的行为信息,我们可以了解用户的兴趣爱好和需求,从而将广告准确地推送给目标用户。这种精准投放方式能够提高广告的点击率和转化率,提升投放效果。 研究目标三:优化广告投放策略,提高投放效果 课题的最终研究目标是优化广告投放策略,提高投放效果。通过分析和挖掘广告投放数据,我们可以根据用户的反馈调整和优化广告投放策略。例如,我们可以通过分析不同时间段的广告点击率,了解用户在一天中的活跃时间段,从而调整广告的投放时间。此外,我们还可以根据用户的地理位置、年龄、性别等信息进行更精细化的投放策略调整。 内容 * 数据采集:使用Python等编程语言和相关库,采集B站的广告相关数据,包括广告主、广告投放时间、广告投放位置、广告费用、广告点击量等。采集B站用户的行为数据,包括视频观看记录、点赞、评论、搜索记录等,以及用户的个人信息和标签数据。 * 数据预处理:收集到的数据可能存在缺失值、异常值或者格式不一致的情况,对采集到的数据进行清洗、去重、缺失值处理、异常值处理等预处理工作,以确保数据的准确性和完整性。 * 数据存储和处理:在获取到数据后,需要妥善处理和存储数据,确保数据的安全和隐私保护。 * 数据分析和挖掘:利用大数据分析技术,对收集到的数据进行分析,包括广告投放效果的分析、受众群体特征的挖掘、广告点击与转化的关联分析等,以发现潜在的规律和趋势。 * 可视化展示:将分析结果以可视化的形式展示出来,包括图表、报告、动态展示等,以便于决策者和用户理解和应用分析结果。为用户提供个性化的视频推荐,或者为广告主提供精准的广告投放服务。 方法、手段 * 数据采集:通过B站API接口或Python爬虫爬取B站广告投放数据、用户行为数据、视频内容数据。 * 数据存储:使用Hive构建离线数据仓库存储采集到的数据。 * 数据分析:用spark实时计算收集到的数据,建立分析模型主要用于分析自变量如广告内容、广告投放时间、用户画像等与因变量如用户点击率、转化率、广告收益等之间的关系。 * 数据可视化:搭建Flask框架方便实现对数据及操作过程的管理,用Echarts可视化最终结果 进度安排 1.选题开题 选题阶段:2023年09月04日---2023年10月31日 开题阶段:2023年11月01日---2023年11月15日 2.设计制作 初步设计阶段:2023年11月16日---2023年12月15日 整体设计阶段:2023年12月16日---2024年01月15日 完成系统设计:2024年01月16日---2024年02月10日 3.撰写论文 论文初稿:2024年02月11日---2024年2月底 论文二稿:2024年03月01日---2024年3月31日 论文终稿:2024年04月01日---2024年4月20日 4.毕业答辩 毕业答辩时间:2024年4月底 实验方案的可行性分析 1.经济可行性:该项目所需技术在本人计算机上均可进行,无较多成本。 2. 技术可行性:B站作为一个拥有海量用户数据的视频分享平台,提供了丰富的数据来源,可以支持大数据分析和可视化的需求。建立强大的数据处理能力,包括数据清洗、整合、分析和可视化的技术能力,以应对海量数据的处理需求。 3. 法律可行性:在进行数据爬取和处理的过程中,需要遵守相关的法律法规,特别是涉及个人隐私和数据安全的方面。需要评估项目是否符合数据保护法规、网络安全法规、知识产权法规等相关法律法规,是否需要进行信息披露和取得用户授权等。 已具备的实验条件 * 笔记本:配置有完整Python开发环境、大数据环境。 * 知识点:查阅并研读了相关论文文献,理清了本项目的基本思路,正在学习大数据、Python相关知识能够完成项目开发。 * 技术支援:通过github搜集开源案例可用于研究开发。 具体参考文献 1王波, 王俊. 大数据时代的广告精准投放J. 计算机与现代化, 2017(10): 19-23. 2张晨光. 基于大数据的广告投放优化研究J. 现代商业, 2018(2): 17-20. 3刘鹏, 王伟. 大数据在广告投放中的应用与研究J. 现代商业, 2019(3): 9-12. 4张素雅. 基于大数据的广告精准投放案例分析J. 信息技术与应用, 2020(1): 14-18. 5王晓明. 大数据时代广告投放的精准策略J. 科技视界, 2021(3): 12-15. 6周小玲, 王明宇. 基于大数据的广告投放效果评估与优化J. 现代商业, 2022(4): 34-38. 7刘建华. 大数据在广告精准投放中的应用及发展J. 信息技术与应用, 2023(1): 18-22. |||||
河北传媒学院
本科 毕业 论文开题报告
|------|-------|---|---|-------|
| 专业 | 小四号宋体 | 班级 || 小四号宋体 |
| 姓名 | 小四号宋体 | 学号 || 小四号宋体 |
| 指导教师 | 小四号宋体 ||||
| 题目 | 基于大数据的B站广告投放分析及可视化 ||||
| (1.内容包括:课题的来源及意义,国内外发展状况,本课题的研究目标、内容、方法、手段及进度安排、实验方案的可行性分析和已具备的实验条件、具体参考文献等。2.撰写要求:字体为宋体、小四号,字数不少于1500字,1.5倍行距。) 课题的来源及意义 来源 随着互联网的快速发展和数字化转型,广告行业面临着诸多挑战和变革,传统的广告投放方式难以满足市场需求。在当今大数据时代,广告投放的效率和效果对于企业的营销策略至关重要。传统的广告投放方式往往缺乏对投放效果的数据分析和精准把握,因此,利用大数据技术对广告投放进行分析和优化具有重要的实际意义和应用价值。 意义 * 提高广告投放效果:通过对海量的数据进行深度挖掘和分析,可以实现对受众的精准定位和分类,从而提高广告的投放效果和投资回报率。 * 降低广告成本:精准的广告投放可以避免广告在不相关受众中浪费,减少广告成本,并使有限的广告预算得到更有效地利用。 * 提升用户体验:精准的广告投放可以向用户推送符合其个人兴趣和需求的广告内容,提升用户体验,增强用户对广告的认同感。 * 促进广告行业创新:基于大数据的广告精准投放分析为广告行业的创新提供了新的思路和方法,推动了广告行业向智能化、个性化的方向发展。 国内外发展状况 国内发展状况: 在国内,随着互联网和移动设备的普及,大数据技术在广告行业的应用也得到了快速发展。一些大型的互联网公司,如阿里巴巴、腾讯等,也利用大数据技术进行广告精准投放。他们通过分析用户的搜索记录、浏览记录、购买行为等信息,以实现更精确的广告推送。此外,一些专门的大数据分析和广告优化公司,如字节跳动等,也提供了基于大数据的广告投放分析和优化服务。 国外发展状况: 在国外,大数据技术在广告投放领域的应用已经非常普遍。一些知名的互联网公司,如Google、Facebook、Twitter等,都利用大数据技术进行广告精准投放。他们通过收集和分析用户的行为数据、兴趣爱好、地理位置等信息,以实现更精确的广告推送。此外,一些专门的大数据分析和广告优化公司,如DoubleClick等,也提供了基于大数据的广告投放分析和优化服务。 综上所述,国内外都在基于大数据的广告精准投放领域取得了一定的成果。未来的研究方向包括进一步提高数据处理效率、加强用户行为分析、优化广告投放策略,以及开发更先进和实用的可视化分析工具。 本课题的研究目标 研究目标一:建立广告投放数据收集和分析系统 在课题研究中,首要的研究目标是建立广告投放数据的收集和分析系统。这一系统能够有效地收集和存储广告投放数据,并运用大数据技术进行深入的分析。通过该系统,我们可以获取广告的展示次数、点击次数、转化率等关键指标,为后续的投放优化提供数据支持。 研究目标二:挖掘用户行为和兴趣,实现精准投放 在完成数据收集和分析系统的构建后,课题将进一步研究如何挖掘用户行为和兴趣,以实现广告的精准投放。通过分析B站用户的行为信息,我们可以了解用户的兴趣爱好和需求,从而将广告准确地推送给目标用户。这种精准投放方式能够提高广告的点击率和转化率,提升投放效果。 研究目标三:优化广告投放策略,提高投放效果 课题的最终研究目标是优化广告投放策略,提高投放效果。通过分析和挖掘广告投放数据,我们可以根据用户的反馈调整和优化广告投放策略。例如,我们可以通过分析不同时间段的广告点击率,了解用户在一天中的活跃时间段,从而调整广告的投放时间。此外,我们还可以根据用户的地理位置、年龄、性别等信息进行更精细化的投放策略调整。 内容 * 数据采集:使用Python等编程语言和相关库,采集B站的广告相关数据,包括广告主、广告投放时间、广告投放位置、广告费用、广告点击量等。采集B站用户的行为数据,包括视频观看记录、点赞、评论、搜索记录等,以及用户的个人信息和标签数据。 * 数据预处理:收集到的数据可能存在缺失值、异常值或者格式不一致的情况,对采集到的数据进行清洗、去重、缺失值处理、异常值处理等预处理工作,以确保数据的准确性和完整性。 * 数据存储和处理:在获取到数据后,需要妥善处理和存储数据,确保数据的安全和隐私保护。 * 数据分析和挖掘:利用大数据分析技术,对收集到的数据进行分析,包括广告投放效果的分析、受众群体特征的挖掘、广告点击与转化的关联分析等,以发现潜在的规律和趋势。 * 可视化展示:将分析结果以可视化的形式展示出来,包括图表、报告、动态展示等,以便于决策者和用户理解和应用分析结果。为用户提供个性化的视频推荐,或者为广告主提供精准的广告投放服务。 方法、手段 * 数据采集:通过B站API接口或Python爬虫爬取B站广告投放数据、用户行为数据、视频内容数据。 * 数据存储:使用Hive构建离线数据仓库存储采集到的数据。 * 数据分析:用spark实时计算收集到的数据,建立分析模型主要用于分析自变量如广告内容、广告投放时间、用户画像等与因变量如用户点击率、转化率、广告收益等之间的关系。 * 数据可视化:搭建Flask框架方便实现对数据及操作过程的管理,用Echarts可视化最终结果 进度安排 1.选题开题 选题阶段:2023年09月04日---2023年10月31日 开题阶段:2023年11月01日---2023年11月15日 2.设计制作 初步设计阶段:2023年11月16日---2023年12月15日 整体设计阶段:2023年12月16日---2024年01月15日 完成系统设计:2024年01月16日---2024年02月10日 3.撰写论文 论文初稿:2024年02月11日---2024年2月底 论文二稿:2024年03月01日---2024年3月31日 论文终稿:2024年04月01日---2024年4月20日 4.毕业答辩 毕业答辩时间:2024年4月底 实验方案的可行性分析 1.经济可行性:该项目所需技术在本人计算机上均可进行,无较多成本。 2. 技术可行性:B站作为一个拥有海量用户数据的视频分享平台,提供了丰富的数据来源,可以支持大数据分析和可视化的需求。建立强大的数据处理能力,包括数据清洗、整合、分析和可视化的技术能力,以应对海量数据的处理需求。 3. 法律可行性:在进行数据爬取和处理的过程中,需要遵守相关的法律法规,特别是涉及个人隐私和数据安全的方面。需要评估项目是否符合数据保护法规、网络安全法规、知识产权法规等相关法律法规,是否需要进行信息披露和取得用户授权等。 已具备的实验条件 * 笔记本:配置有完整Python开发环境、大数据环境。 * 知识点:查阅并研读了相关论文文献,理清了本项目的基本思路,正在学习大数据、Python相关知识能够完成项目开发。 * 技术支援:通过github搜集开源案例可用于研究开发。 具体参考文献 1王波, 王俊. 大数据时代的广告精准投放J. 计算机与现代化, 2017(10): 19-23. 2张晨光. 基于大数据的广告投放优化研究J. 现代商业, 2018(2): 17-20. 3刘鹏, 王伟. 大数据在广告投放中的应用与研究J. 现代商业, 2019(3): 9-12. 4张素雅. 基于大数据的广告精准投放案例分析J. 信息技术与应用, 2020(1): 14-18. 5王晓明. 大数据时代广告投放的精准策略J. 科技视界, 2021(3): 12-15. 6周小玲, 王明宇. 基于大数据的广告投放效果评估与优化J. 现代商业, 2022(4): 34-38. 7刘建华. 大数据在广告精准投放中的应用及发展J. 信息技术与应用, 2023(1): 18-22. |||||

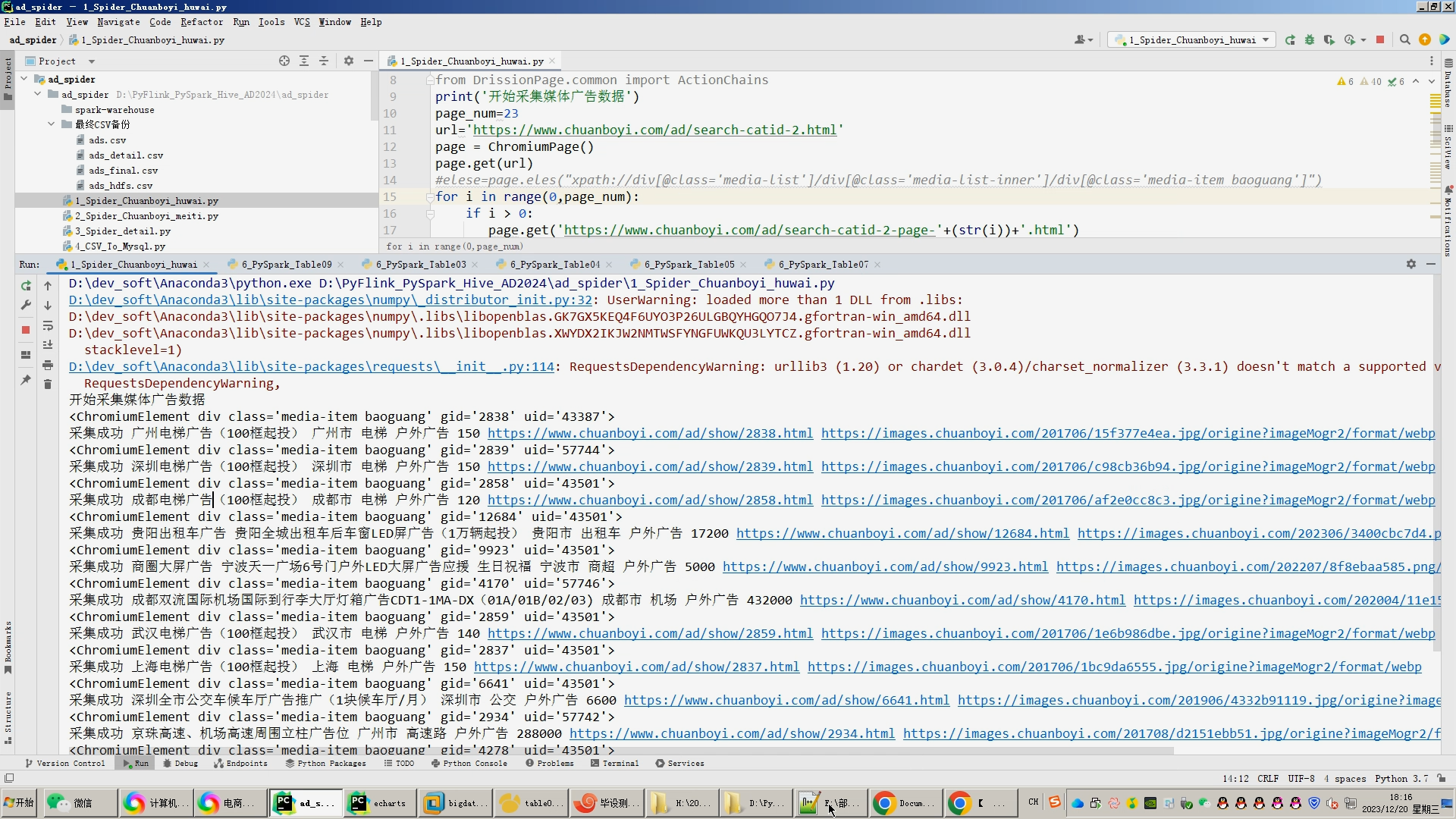
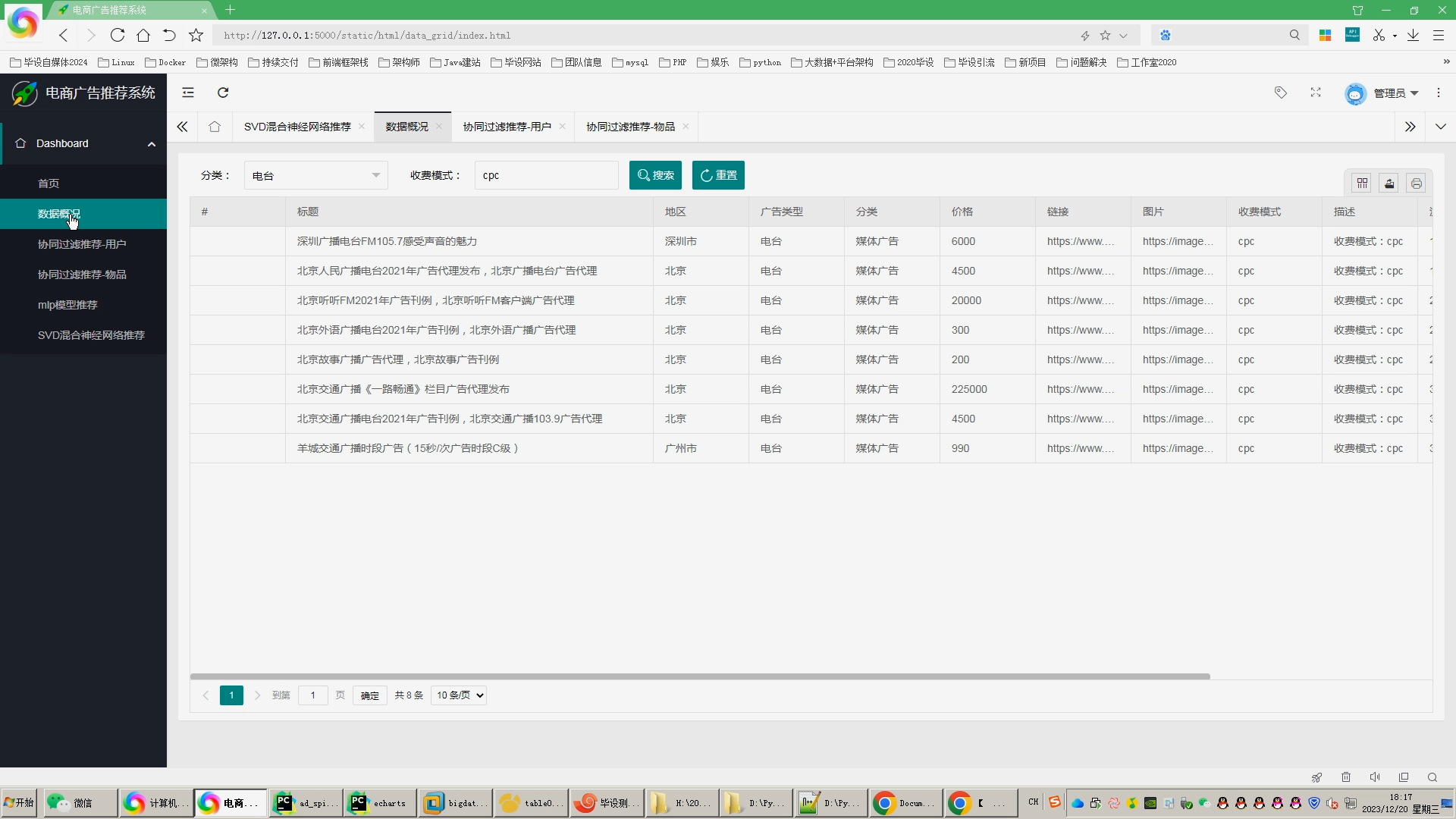
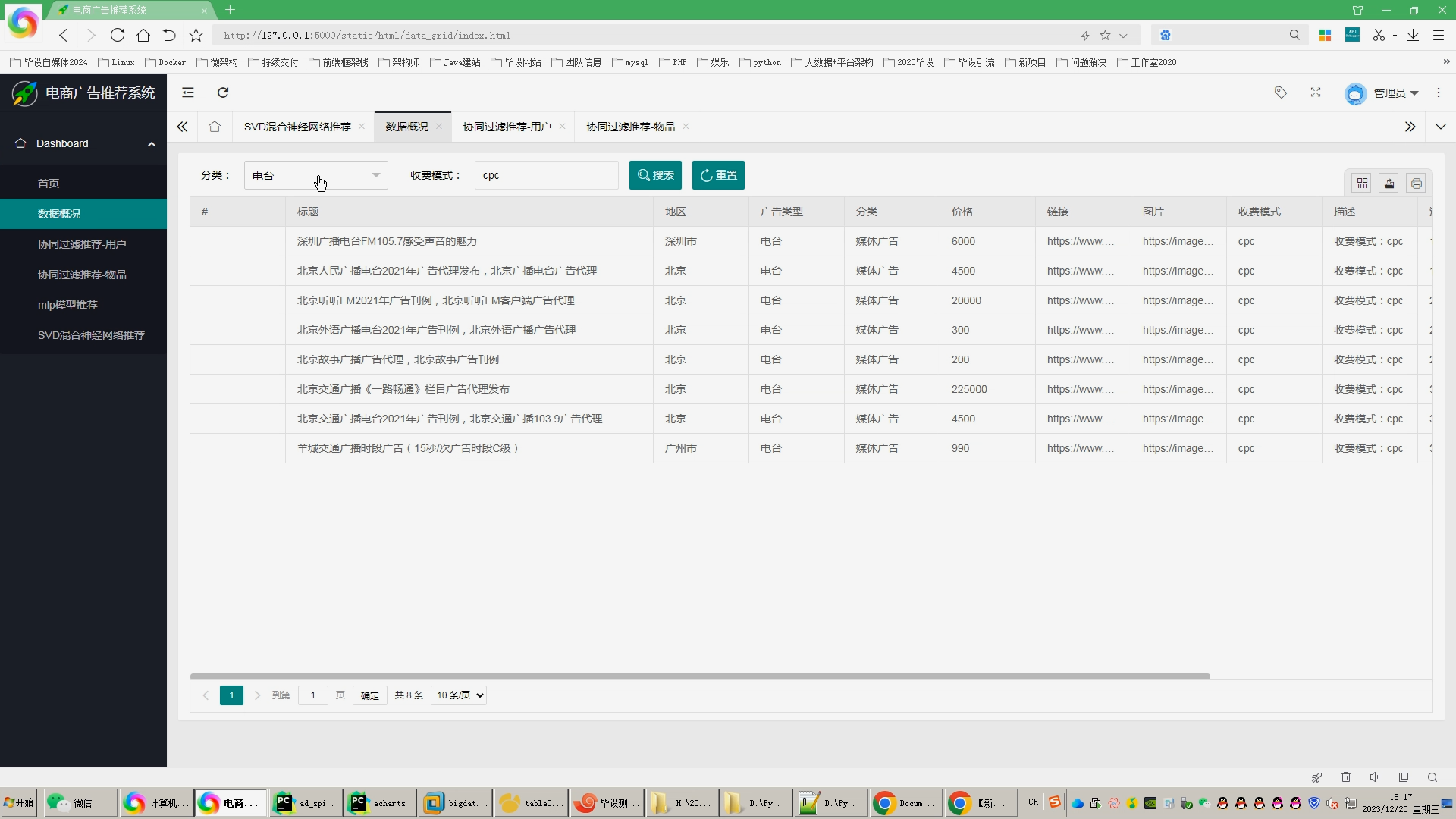
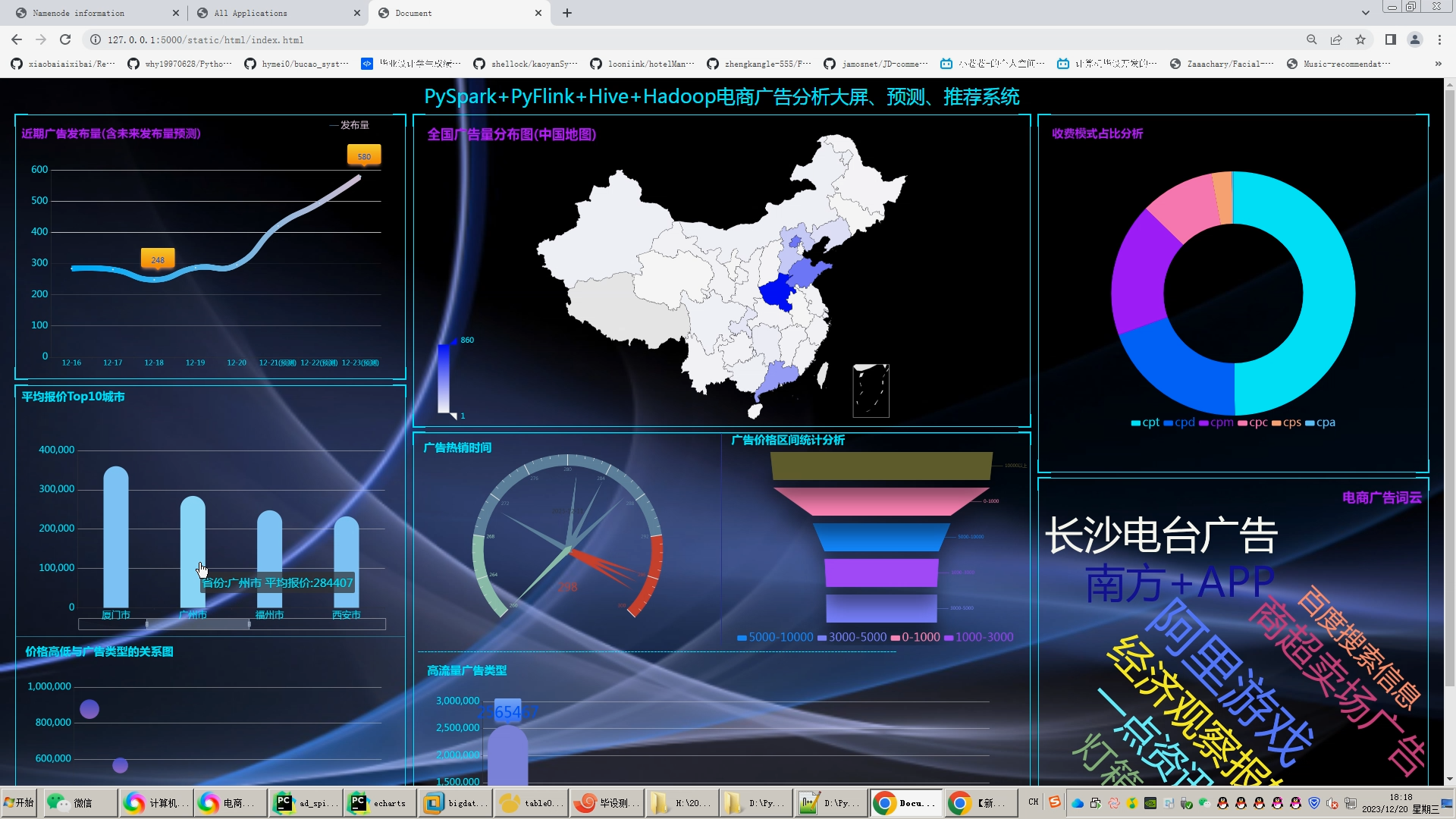
核心算法代码分享如下:
python
import pymysql
from flask import Flask, request, jsonify
import json
from flask_mysqldb import MySQL
import random
import sys
import math
from operator import itemgetter
import pymysql
import SVD
import UserCF
from ItemCF import recommend
#from mlp import als_mlp_predict
from rate import Rate
import db
# 创建应用对象
app = Flask(__name__)
app.config['MYSQL_HOST'] = 'bigdata'
app.config['MYSQL_USER'] = 'root'
app.config['MYSQL_PASSWORD'] = '123456'
app.config['MYSQL_DB'] = 'hive_ads'
mysql = MySQL(app) # this is the instantiation
@app.route('/tables01')
def tables01():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table01''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['province','num'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables02')
def tables02():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table02 ORDER BY stime asc ''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['stime','num'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables03')
def tables03():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table03 order by avg_price desc''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['area','avg_price'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables04')
def tables04():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table04''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['small_type','sum_flow'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route("/getmapcountryshowdata")
def getmapcountryshowdata():
filepath = r"D:\\hadoop_spark_hive_mooc2024\\server\\data\\maps\\china.json"
with open(filepath, "r", encoding='utf-8') as f:
data = json.load(f)
return json.dumps(data, ensure_ascii=False)
@app.route('/tables05')
def tables05():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table05''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['fee_mode','num'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables06')
def tables06():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table06''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['title','flow'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables07')
def tables07():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table07''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['ctime','num'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables08')
def tables08():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table08''')
#row_headers = [x[0] for x in cur.description] # this will extract row headers
row_headers = ['name','num'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/tables09')
def tables09():
cur = mysql.connection.cursor()
cur.execute('''SELECT * FROM table09''')
row_headers = [x[0] for x in cur.description] # this will extract row headers
#row_headers = ['car_name','score'] # this will extract row headers
rv = cur.fetchall()
json_data = []
#print(json_data)
for result in rv:
json_data.append(dict(zip(row_headers, result)))
return json.dumps(json_data, ensure_ascii=False)
@app.route('/data',methods=['GET'])
def data():
limit = int(request.args['limit'])
page = int(request.args['page'])
page = (page-1)*limit
conn = pymysql.connect(host='bigdata', user='root', password='123456', port=3306, db='hive_ads',
charset='utf8mb4')
cursor = conn.cursor()
if (len(request.args) == 2):
cursor.execute("select count(*) from tb_ads");
count = cursor.fetchall()
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute("select * from tb_ads limit "+str(page)+","+str(limit));
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field)
else:
small_type = str(request.args['small_type'])
fee_mode = str(request.args['fee_mode']).lower()
if(small_type=='不限'):
cursor.execute("select count(*) from tb_ads where fee_mode like '%"+fee_mode+"%'");
count = cursor.fetchall()
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute("select * from tb_ads where fee_mode like '%"+fee_mode+"%' limit " + str(page) + "," + str(limit));
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field)
else:
cursor.execute("select count(*) from tb_ads where fee_mode like '%"+fee_mode+"%' and small_type = '"+small_type+"'");
count = cursor.fetchall()
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute("select * from tb_ads where fee_mode like '%"+fee_mode+"%' and small_type = '"+small_type+"' limit " + str(page) + "," + str(limit));
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field)
table_result = {"code": 0, "msg": None, "count": count[0], "data": data_dict}
cursor.close()
conn.close()
return jsonify(table_result)
@app.route('/rec_item',methods=['GET'])
def rec_item():
#print(request.get_json())
limit = 10
page = 1
param1 = str(random.choice([1,2,3,4,5,6]))
result = recommend(int(param1))
list = []
for r in result:
list.append(dict(iid=r[0], rate=r[1]))
print(list)
iids=[]
for iid in list :
iids.append(str(iid['iid']))
conn = pymysql.connect(host='bigdata', user='root', password='123456', port=3306, db='hive_ads',
charset='utf8mb4')
print(iids)
iids_str=','.join(iids)
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute( "select * from tb_ads where id in (" + iids_str + ")");
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field)
table_result = {"code": 0, "msg": None, "count": len(result), "data": data_dict}
cursor.close()
conn.close()
return jsonify(table_result)
@app.route('/rec_user',methods=['GET'])
def rec_user():
#print(request.get_json())
limit = 10
page = 1
param1 = str(random.choice([1,2,3,4,5,6]))
param1 = "1"
result = UserCF.recommend(int(param1))
list = []
for r in result:
list.append(dict(iid=r[0], rate=r[1]))
print(list)
print(list)
iids=[]
for iid in list :
iids.append(str(iid['iid']))
conn = pymysql.connect(host='bigdata', user='root', password='123456', port=3306, db='hive_ads',
charset='utf8mb4')
print(iids)
iids_str=','.join(iids)
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute( "select * from tb_ads where id in (" + iids_str + ")");
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field)
table_result = {"code": 0, "msg": None, "count": len(result), "data": data_dict}
cursor.close()
conn.close()
return jsonify(table_result)
# @app.route('/mlp',methods=['GET'])
# def mlp():
# #print(request.get_json())
# limit = 10
# page = 1
# param1 = str(random.choice([1,2,3,4,5,6]))
# result = als_mlp_predict(int(param1), 55, 4)
# list = []
# # print(result)
# for r in result:
# list.append(dict(iid=r['iid'], rate=r['score']))
# print(list)
# print(list)
# print(list)
# iids=[]
# for iid in list :
# iids.append(str(iid['iid']))
# conn = pymysql.connect(host='bigdata', user='root', password='123456', port=3306, db='hive_ads',
# charset='utf8mb4')
# print(iids)
# iids_str=','.join(iids)
# cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
# cursor.execute( "select * from tb_ads where id in (" + iids_str + ")");
# data_dict = []
# result = cursor.fetchall()
# for field in result:
# data_dict.append(field)
# table_result = {"code": 0, "msg": None, "count": len(result), "data": data_dict}
# cursor.close()
# conn.close()
# return jsonify(table_result)
@app.route('/svd',methods=['GET'])
def svd():
#print(request.get_json())
limit = 10
page = 1
param1 = str(random.choice([1,2,3,4,5,6]))
#param1 = 1
predictions = SVD.recommend(int(param1),10)
# print(predictions)
res = []
for p in predictions:
# print(p)
d = dict(iid=p, rate=0.9)
res.append(d)
print(res)
print(res)
print(res)
print(res)
iids=[]
for iid in res :
iids.append(str(iid['iid']))
conn = pymysql.connect(host='bigdata', user='root', password='123456', port=3306, db='hive_ads',
charset='utf8mb4')
print(iids)
iids_str=','.join(iids)
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute( "select * from tb_ads where id in (" + iids_str + ")");
data_dict = []
result = cursor.fetchall()
for field in result:
data_dict.append(field)
table_result = {"code": 0, "msg": None, "count": len(result), "data": data_dict}
cursor.close()
conn.close()
return jsonify(table_result)
if __name__ == "__main__":
app.run(debug=False)