每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

Meta推出Meta AI的目标是为人们提供利用生成式AI(GenAI)提升生产力和激发创造力的新方式。然而,GenAI也伴随着规模化的挑战。当Meta在部署新的GenAI技术时,Meta也专注于尽可能快速且高效地向人们提供这些服务。
Meta AI的动画生成功能允许用户生成短动画,并且在这一方面Meta面临着独特的挑战。为了在大规模应用中实现此功能,Meta的图像动画生成模型必须能够服务于使用Meta产品和服务的数十亿用户,并且做到快速生成、极少出错且资源高效。
以下是Meta如何通过延迟优化、流量管理和其他新颖技术成功部署Meta AI动画生成功能的过程。
优化生成图像动画的延迟
在将动画生成功能推向Meta应用家族和Meta AI网站之前,使动画模型的运行速度变得更快是Meta的首要任务之一。Meta希望用户能够体验到仅需几秒钟就能看到动画生成的魔力。这不仅从用户角度重要,而且模型越快、效率越高,Meta就能使用更少的GPU,从而实现可持续的规模化发展。Meta在创建带有视频扩散的动画贴纸、加速图像生成的Imagine Flash、以及通过块缓存加速扩散模型方面的工作帮助Meta开发出实现大幅度延迟优化的新技术。
减半浮点精度
这些优化技术之一是将浮点精度减半。Meta将模型从float32转换为float16,这加快了推理时间,主要有两个原因。首先,模型的内存占用减少了一半。其次,16位浮点运算比32位运算速度更快。对于所有模型,Meta使用bfloat16,一种用于训练和推理的float16变体,以获取这些优势。
改进时序注意力扩展
第二项优化是改进了时序注意力扩展。时序注意力层在时间轴和文本条件之间进行注意力计算,需要将上下文张量复制以匹配时间维度或帧数。以前,这是在传递到交叉注意力层之前完成的。然而,这导致了性能提升不理想。Meta选择的优化实现通过利用重复张量是相同的这一事实,在通过交叉注意力线性投影层之后进行扩展,从而减少计算和内存消耗。
利用DPM-Solver减少采样步骤
第三项优化使用了DPM-Solver。扩散概率模型(DPMs)是一种功能强大且有影响力的模型,能够生成高质量的结果,但其速度较慢。其他可能的解决方案,如去噪扩散隐式模型或去噪扩散概率模型,虽然可以提供高质量的生成,但需要更多的采样步骤。Meta利用了DPM-Solver和线性对数信噪比时间,将采样步骤减少到15步。
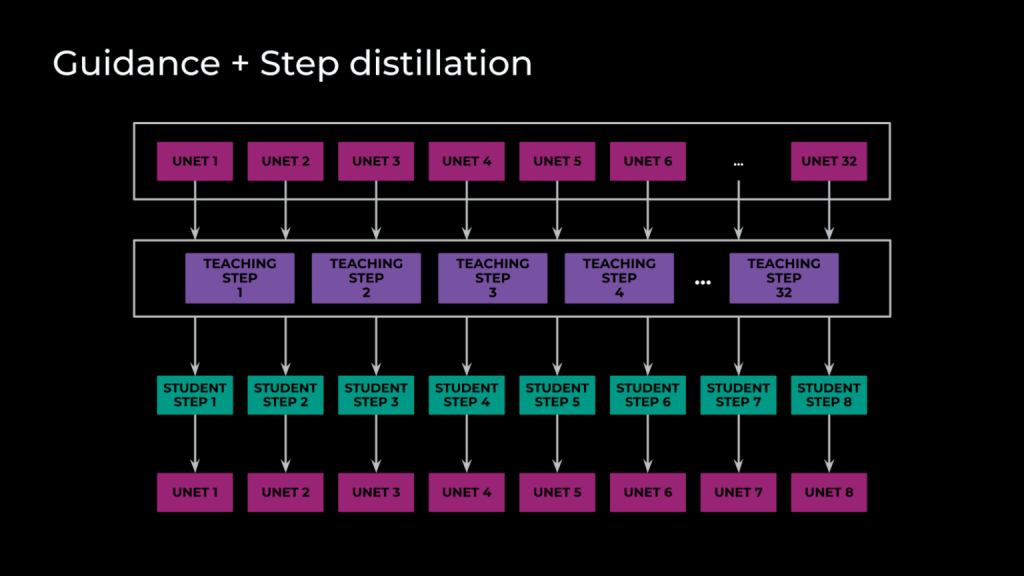
结合引导和步骤蒸馏
Meta实施的第四项优化是结合引导和步骤蒸馏。通过初始化教师和学生权重相同的模型,Meta进行了步骤蒸馏,训练学生模型在单步内模仿教师模型的多个步骤。引导蒸馏方面,Meta通过无分类器引导的方式实现了条件图像生成。这要求每个求解步骤都进行有条件和无条件的前向传递。然而,在Meta的场景中,每步有三个前向传递:无条件、图像条件和完整的文本与图像条件。通过引导蒸馏,Meta将这三个前向传递合并为一个,使推理时间缩短了三倍。最后,通过训练学生模型同时模仿无分类器引导和多步骤操作,Meta的最终模型只需八步求解,每步只需要一次通过U-Net。
PyTorch优化
最后一项优化涉及部署和架构,包含两项转化。首先是利用TorchScript进行脚本化和冻结。通过将模型转换为TorchScript,Meta获得了许多自动优化,包括连续折叠、多个操作的融合以及减少计算图的复杂性。这三项优化帮助Meta提高了推理速度,而冻结技术通过将图中的动态计算值转化为常量,进一步减少了总操作数。
虽然这些优化对于Meta的初次发布至关重要,但Meta还在持续突破界限。例如,Meta将所有媒体推理从TorchScript迁移到基于PyTorch 2.0的解决方案,这为Meta带来了多项提升。通过在组件级别利用pytorch.compile进行优化,以及在新架构中启用上下文并行和序列并行等高级优化技术,Meta实现了从减少高级功能的开发时间到改进跟踪、支持多GPU推理的全面胜利。
在大规模部署图像动画
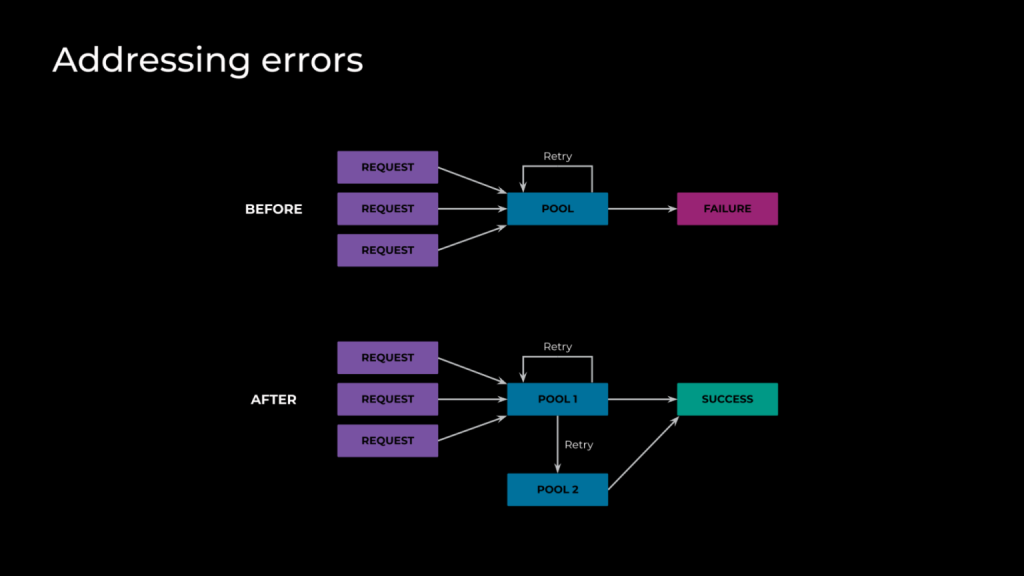
在完全优化模型后,Meta面临的新挑战是如何在全球范围内运行此模型,支持来自世界各地的流量,同时保持快速的生成时间,尽量减少故障,并确保GPU可以用于公司内的其他重要用例。
Meta首先查看了以前AI生成媒体的流量数据,包括其发布时和随时间推移的流量情况。Meta使用这些信息来估算可以预期的请求数量,并利用模型速度的基准测试来确定需要多少GPU来容纳这些请求。在扩大规模后,Meta开始进行负载测试,以查看是否可以处理各种流量水平,解决各种瓶颈,直到Meta能够处理发布时预计的流量为止。
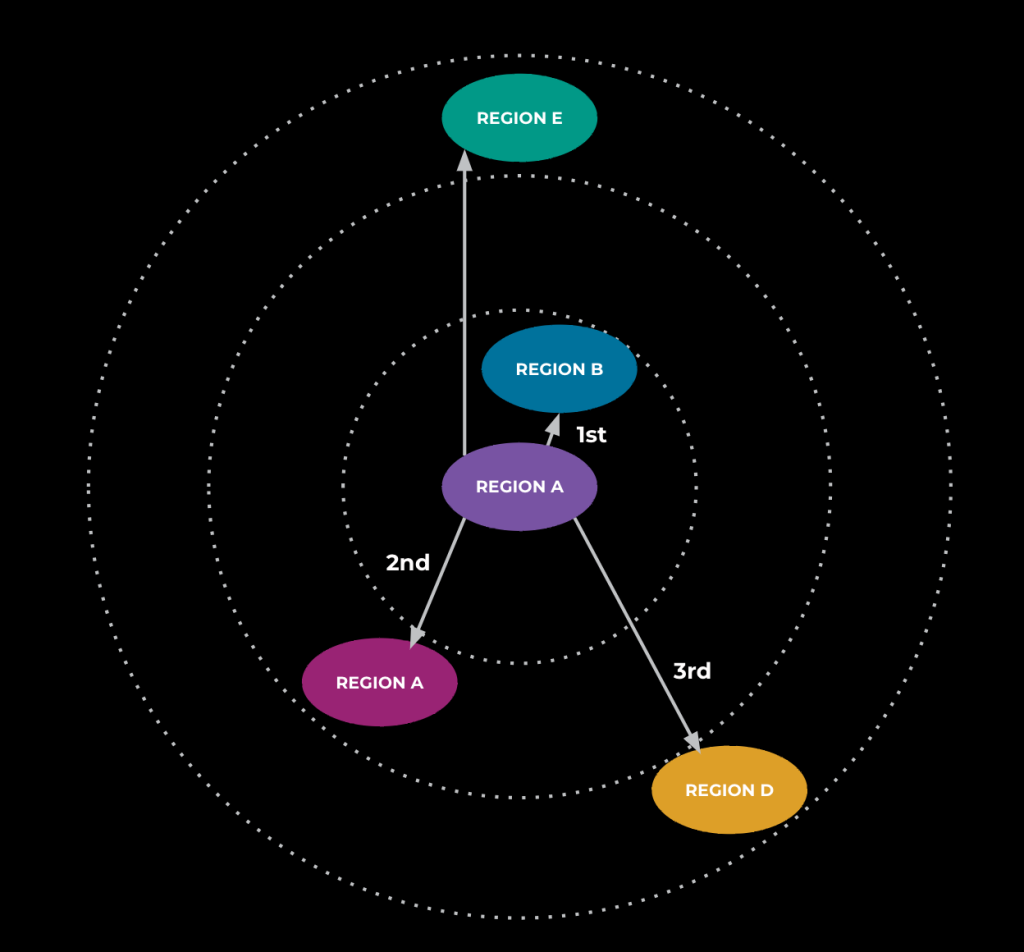
在测试过程中,Meta注意到动画请求的端到端延迟比预期高,并且高于Meta在构建上述所有优化后看到的情况。调查显示,流量在全球范围内被路由,导致显著的网络和通信开销,增加了生成时间。为了解决这个问题,Meta利用了流量管理系统,该系统获取服务的流量或负载数据并使用这些数据计算路由表。