内容导读
使用Selenium模拟登录
使用Cookies登录网站
模拟表单登录网站
爬虫识别简单的验证码
实例解析
一、使用Selenium模拟登录
1、为什么要模拟登录
在互联网上存在大量需要登录才能访问的网站,要爬取这些网站,就需要学习爬虫的模拟登录。对于一个需要登录才能访问的网站,它的页面在登录前和登录后可能是不一样的。
如果直接使用requests去获取源代码,只能得到登录以前的页面源代码。接下来我们使用pyhton实现网络的模拟登录与注册,最终达到爬取网站内容的目的。
示例分析如下:
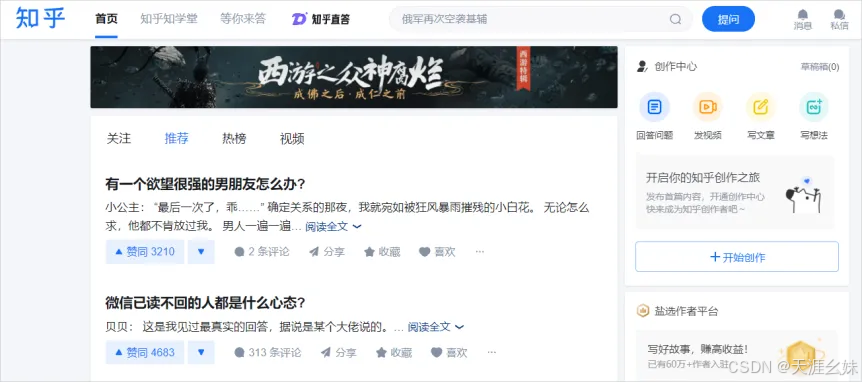
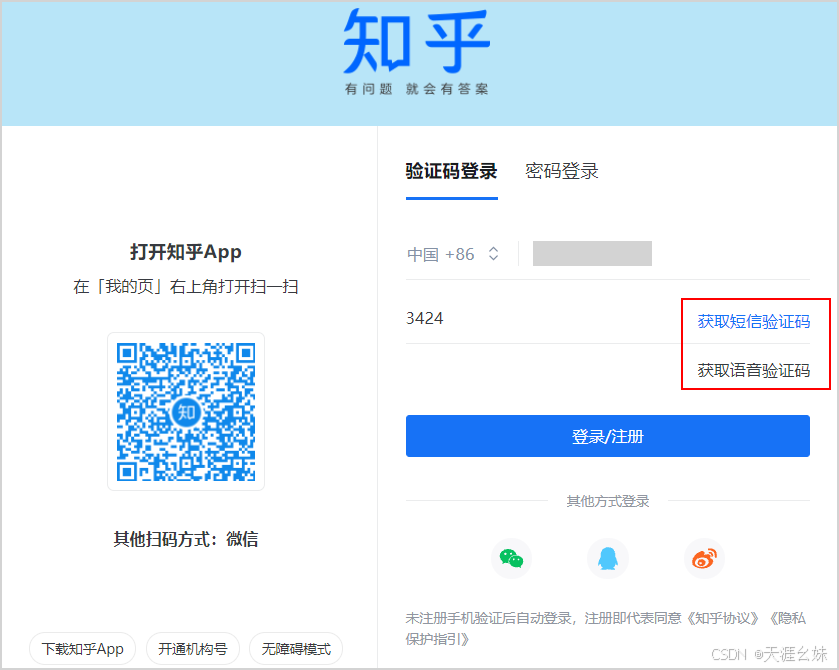
但是如果没有登录,访问知乎首页会自动跳转到登录页面,看到的是如图所示页面。
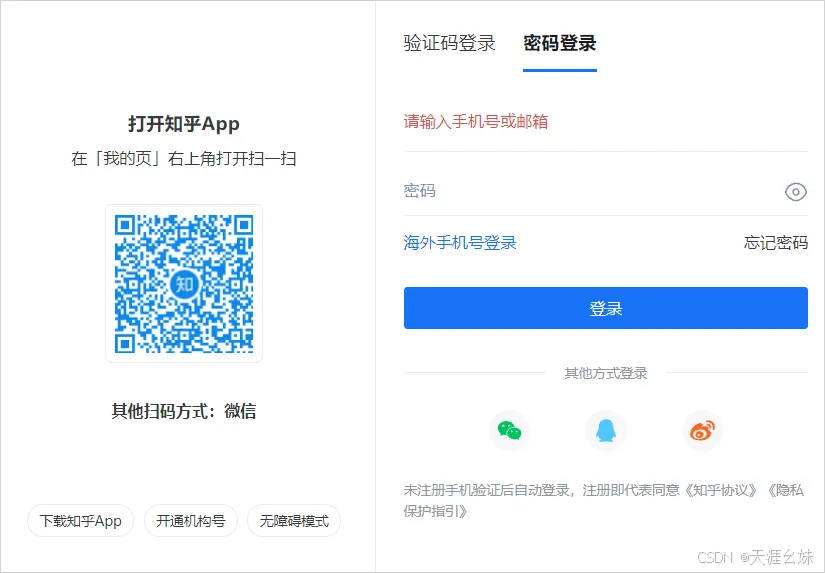
如果使用requests直接获取知乎首页,可以看到源代码明显是未登录状态的,如上图所示。
模拟登录有多种实现方法,使用Selenium操作浏览器登录和使用Cookies登录虽然简单粗暴,但是有效。使用模拟提交表单登录虽然较为麻烦,但可以实现自动化。
2、使用Selenium模拟登录
使用Selenium来进行模拟登录,整个过程非常简单。流程如下。
(1)初始化ChromeDriver。
(2)打开知乎登录页面。
(3)找到用户名的输入框,输入用户名。
(4)找到密码输入框,输入用户名。
(5)手动单击验证码。
(6)按下Enter键。
以上过程,若使用Selenium,一般情况下只需要不到20行代码就可以完成!
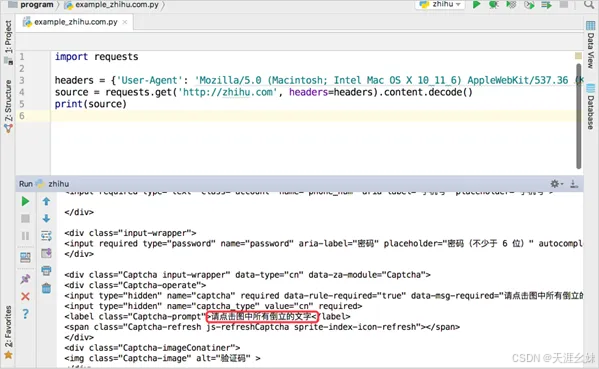
根据本站分享的Selenium的用法,这里的代码看起来就很轻松了。
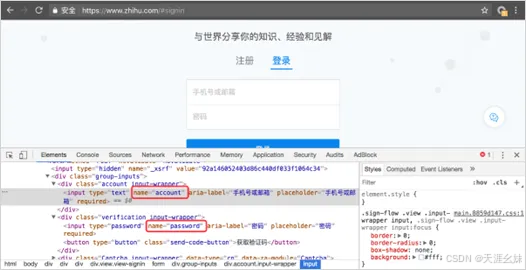
程序首先打开知乎的登录页面,然后使用"find_element_by_ name"分别找到输入账号和密码的两个输入框。
这两个输入框的name属性值分别为"account"和"password",如图所示。
在Selenium中可以使用send_keys()方法往输入框中输入字符串。
在输入了密码以后,验证码框就会弹出来。知乎使用的验证码为点击倒立的文字,这种验证码不容易自动化处理,因此在这个地方让爬虫先暂停,手动点击倒立文字。
爬虫中的input()语句会阻塞程序,直到在控制台按下Enter键,爬虫才会继续运行,如图所示。
接下来,爬虫模拟按下Enter键的动作,触发知乎的登录行为,实现登录。登录成功以后,界面如图所示。

二、使用Cookies登录
Cookie是用户使用浏览器访问网站的时候网站存放在浏览器中的一小段数据。Cookie的复数形式Cookies用来表示各种各样的Cookie。
它们有些用来记录用户的状态信息;有些用来记录用户的操作行为;还有一些,具有现代网络最重要的功能:记录授权信息,即用户是否登录以及用户登录哪个账号。
为了不让用户每次访问网站都进行登录操作,浏览器会在用户第一次登录成功以后放一段加密的信息在Cookies中。下次用户访问,网站先检查Cookies有没有这个加密信息,如果有并且合法,那么就跳过登录操作,直接进入登录后的页面。
通过已经登录的Cookies,可以让爬虫绕过登录过程,直接进入登录以后的页面。
在已经登录知乎的情况下,打开Chrome的开发者工具,定位到"Network"选项卡,然后刷新网页,在加载的内容中随便选择一项,然后看右侧的数据,从Request Headers中可以找到Cookie,如图所示。
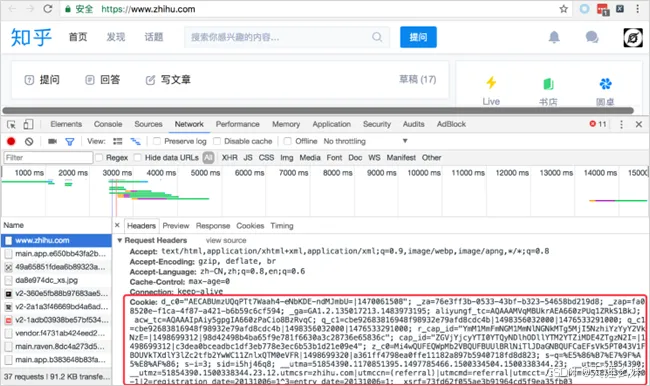
**请注意:**这里一定是"Request Headers",不要选成了"Response Headers"。
只要把这个Request Headers的内容通过requests提交,就能直接进入登录以后的知乎页面了,如图所示。
由于登录以后的知乎页面的HTML代码全部缩在了一行,所以在PyCharm里面看起来不太方便。不过从输出的部分文字可以证明,确实已经是登录以后的页面。
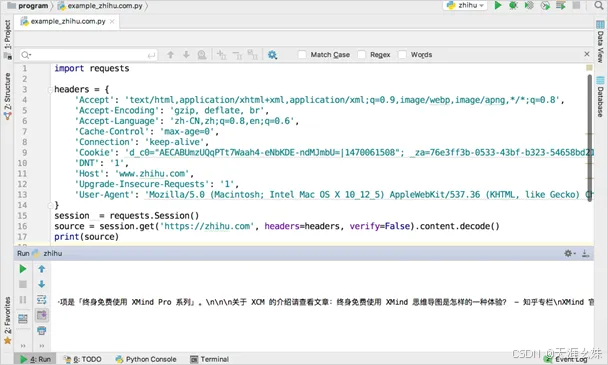
可以看到,使用Cookie来登录网页,不仅可以绕过登录步骤,还可以绕过网站的验证码。
在如上图所示的代码中,使用了requests的Session模块。
所谓Session,是指一段会话。网站会把每一个会话的ID(Session ID)保存在浏览器的Cookies中用来标识用户的身份。requests的Session模块可以自动保存网站返回的一些信息。
其实在前面章节中使用的requests.get(),在底层还是会先创建一个Session,然后用Session去访问。
对于HTTPS的网站,在requests发送请求的时候需要带上verify=False这个参数,否则爬虫会报错。
带上这个参数以后,爬虫依然会报一个警告,这是因为没有HTTPS的证书。
不过这个警告不会影响爬虫的运行结果。对于有强迫症的读者,可以参考相关内容为requests设置证书,从而解除这个警告。
三、模拟表单登录
在本站其它已介绍通过POST提交请求解决了AJAX版登录页面的爬取。但是在现实中,有更多的网站是使用表单提交的方式来进行登录的。
这里将要讲解如何解决表单登录的问题,首先打开练习页会自动打开登录页面,如图所示。
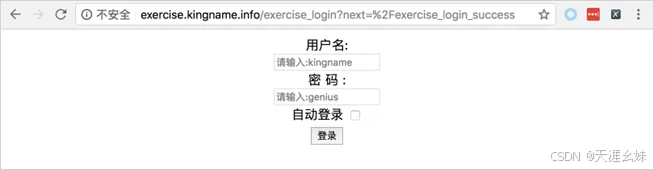
这个登录页面与之前介绍的AJAX登录的页面非常相似。但是这里多了一个"自动登录"复选框。
输入用户名kingname,密码genius,勾选"自动登录"复选框并单击"登录"按钮,可以看到登录成功后的页面,如图所示。
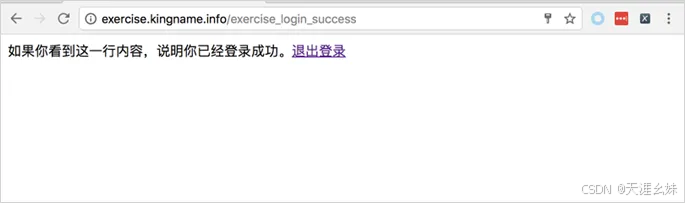
根据前面的经验,遇到这种问题应首先打开Chrome的开发者工具并监控登录过程。
然而,仔细观察会发现登录请求的那个网址只会在"Network"选项卡中存在1s,然后就消失了。
"Network"选项卡下面只剩下登录成功后的页面所发起的各种网络请求,如图所示。
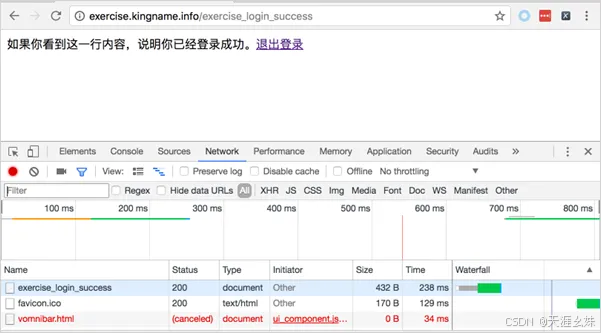
这是因为表单登录成功以后会进行页面跳转,相当于开了一个新的网页,于是新的请求就会直接把旧的请求覆盖。
为了避免这种情况,需要在Chrome的开发者工具的"Network"选项卡中勾选"Preserve log"复选框,再一次登录就可以看到登录过程,如图所示。
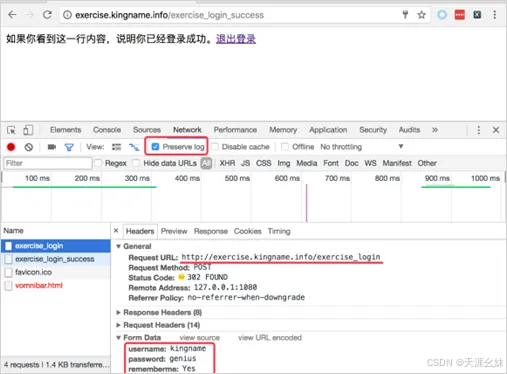
此时可以看到Status Code是302,说明这里有一个网页跳转,也就证明了之前为什么登录以后看不到登使用requests的Session模块来模拟这个登录,其运行结果如图所示。
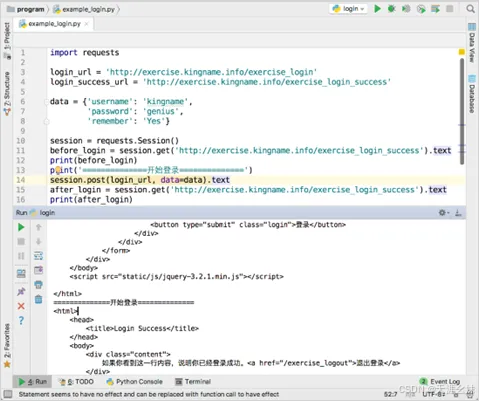
四、爬虫识别简单的验证码
4.1 肉眼打码
对于一次登录就可以长时间使用的情况,只需要识别一次验证码即可。
这种情况下,与其花时间开发一个自动识别验证码的程序,不如直接肉眼识别。肉眼识别验证码有两种情况,借助浏览器与不借助浏览器。
1、借助浏览器
在模拟登录中讲到过Cookies,通过Cookies能实现绕过登录,从而直接访问需要登录的网站。因此,对于需要输入验证码才能进行登录的网站,可以手动在浏览器登录网站,并通过Chrome获取Cookies,然后使用Cookies来访问网站。这样就可以实现人工输入一次验证码,然后很长时间不再登录。
2、不借助浏览器
对于仅仅需要识别图片的验证码,可以使用这种方式------先把验证码下载到本地,然后肉眼去识别并手动输入给爬虫。
手动输入验证码的一般流程如下。
(1)爬虫访问登录页面。
(2)分析网页源代码,获取验证码地址。
(3)下载验证码到本地。
(4)打开验证码,人眼读取内容。
(5)构造POST的数据,填入验证码。
(6)POST提交。
需要注意的是,其中的(2)、(3)、(4)、(5)、(6)步是一气呵成的,是在爬虫运行的时候做的。绝对不能先把爬虫程序关闭,肉眼识别验证码以后再重新运行。
打开验证码练习页面http://exercise.kingname.info/exercise_captcha.html(如果没有,可以创建一个网页),可以看到在这个页面需要输入验证码,如图所示。
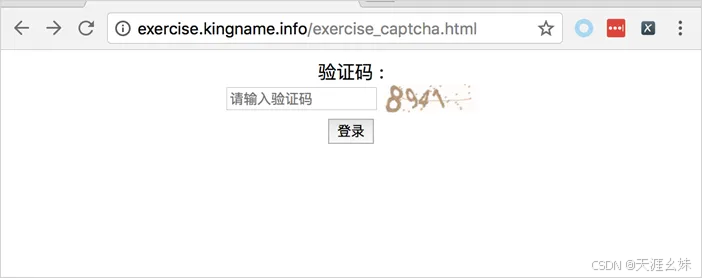
打开源代码页面,可以看到验证码的地址,如图所示。
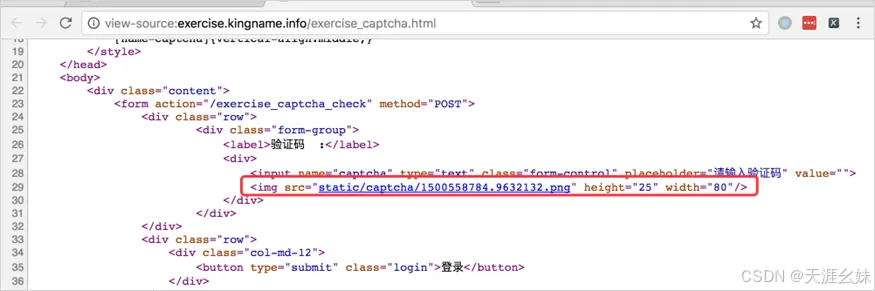
源代码给出的是一个相对路径,所以图片的实际网址为网站域名+相对路径,即http://exercise.kingname.info/static/captcha/1500558784. 9632132.png。
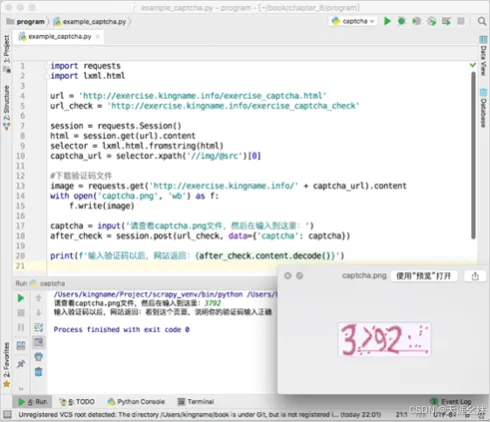
文件名一看就是使用Python的time.time()生成的时间戳。在知道了图片的网址以后,就可以使用requests将验证码下载下来,再肉眼识别。一旦验证码被识别了出来,那么剩下的工作就和一般的POST提交没有什么两样了。
识别验证码的完整代码如下图所示。
4.2 自动打码
1、Python图像识别
Python的强大,在于它有非常多的第三方库。
对于验证码识别,Python也有现成的库来使用。
开源的OCR库pytesseract配合图像识别引擎tesseract,可以用来将图片中的文字转换为文本。
这种方式在爬虫中的应用并不多见。因为现在大部分的验证码都加上了干扰的纹理,已经很少能用单机版的图片识别方式来识别了。
所以如果使用这种方式,只有两种情况:网站的验证码极其简单工整,使用大量的验证码来训tesseract。
(1)安装tesseract
Windows系统中:下载安装包 https://github.com/ tesseract-ocr/tesseract/wiki/Downloads,
在"3rd party Windows exe's/ installer"下面可以找到.exe安装包。
Mac系统中:可以通过Homebrew安装:brew install tesseract
Ubuntu系统中:可以直接通过apt-get安装:sudo apt-get install tesseract-orc
(2)安装Python库
要使用tesseract来进行图像识别,需要安装两个第三方库:
pip install Pillow
pip install pytesseract
其中,Pillow是Python中专门用来处理图像的第三方库,pytesseract是专门用来操作tesseract的第三方库。
(3)tesseract的使用
tesseract的使用非常简单。
① 导入pytesseract和Pillow。
② 打开图片。
③ 识别。
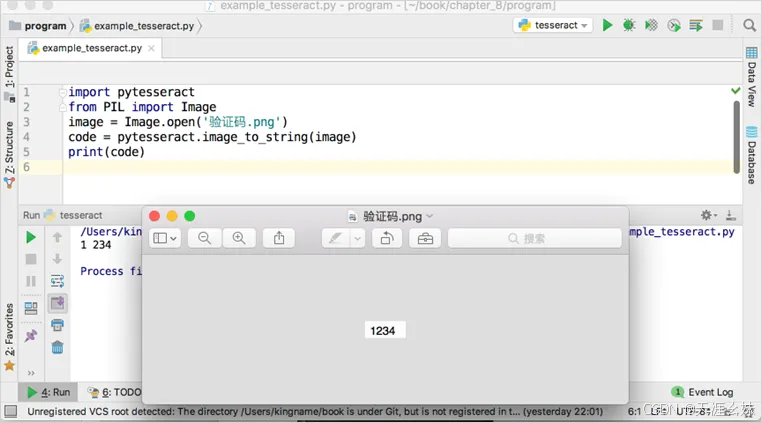
通过以下代码来实现最简单的图片识别:
import pytesseract
from PIL import Image
image = Image.open('验证码.png')
code = pytesseract.image_to_string(image)
print(code)
运行结果如图所示。
如果使用Mac OS,并且使用Homebrew安装tesseract,那么有可能程序会报以下错误:
FileNotFoundError: Errno2 No such file or directory: 'tesseract'
这是因为Homebrew没有把tesseract加入到系统的环境变量的缘故。
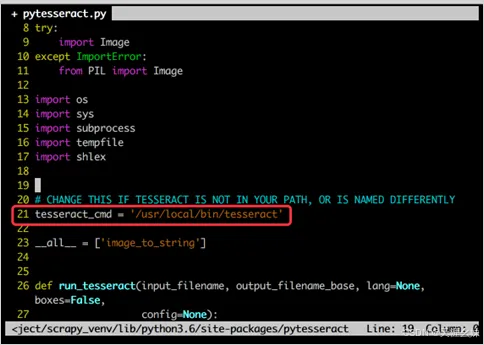
要解决这个问题,需要修改Python安装文件夹下面的lib/site-packages/pytesseract文件夹中的pytesseract.py文件,将第21行的代码:
tesseract_cmd = 'tesseract'
修改为:
tesseract_cmd = '/usr/local/bin/tesseract'
修改代码如下图所示。
要找到这个文件,最简单的办法是在PyCharm中先使用import导入pytesseract。
在Windows和Linux系统中按下Ctrl键并单击"pytesseract"即可。
使用Mac OS系统的读者按下Command键并单击"pytesseract"即可。
这样,PyCharm就会自动打开这个文件。
2、打码网站
(1)打码网站介绍
在线验证码识别的网站,简称打码网站。这些网站有一些是使用深度学习技术识别验证码,有一些是雇佣了很多人来人肉识别验证码。
网站提供了接口来实现验证码识别服务。使用打码网站理论上可以识别任何使用输入方式来验证的验证码。
这种打码网站的流程一般是这样的。
① 将验证码上传到网站服务器。
② 网站服务器将验证码分发给打码工人。
③ 打码工人肉眼识别验证码并上传结果。
④ 网站将结果返回。
(2)使用在线打码
在百度或者谷歌上面搜索"验证码在线识别",就可以找到很多提供在线打码的网站。但是由于一般这种打码网站是需要交费才能使用的,所以要注意财产安全。
这里使用一个名称为"云打码"的网站来进行测试。如果此时不能打开此网站,可以从网络搜索其他打码网站。
注册账号以后,需要交费购买才能正常使用。
这个网站虽然提供了各种语言的SDK,但是版本都比较旧了,所以建议使用HTTP接口。
虽然HTTP 接口文档给出了上传的地址,但是不要去看它提供的"PythonHTTP调用示例",因为这个示例有问题。
它的HTTP接口的正确使用步骤如下:
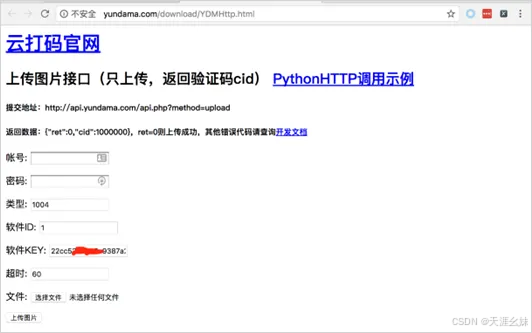
① 首先访问http://yundama.com/download/YDMHttp.html,获得软件KEY,如图所示。
② 使用POST方式上传图片,并接收返回信息。
③ 网速足够好的时候,立刻就可以从返回的信息中得到验证码。如果返回的数据没有验证码,转步骤④。
④ 获取cid,并使用GET方式反复访问http://api.yundama.com/api.php? cid= <cid>&method=result,直到获取到验证码为止。
注意事项:
如果此打码网站不可使用,可通过搜索引擎寻找其他的打码网站。
通过看打码网站的文档来学习怎么使用,根据网站的说明把打码网站的接口集成到爬虫当中。
由于这种打码网站鱼龙混杂,而且小网站众多,因此在选择网站的时候,需要注意以下几点:
① 拒绝实名制,不要选择任何需要提供手机号及身份证照片的网站。
② 注册邮箱请使用小号,单独使用密码。
③ 如果要交费,注意交费地址。
④ 只使用支付宝扫二维码或者微信扫二维码支付,反复确认交费金额,不要在网站上输入密码。
⑤ 一次交费不要超过10元。
⑥ 尽量不要使用百度。
五、实例解析
模拟登录并验证并爬取网站内容。
1、需求分析
目标网站:果壳网 https://www.guokr.com。
目标内容:个人资料设置界面源代码。
使用模拟登录与验证码识别的技术实现自动登录果壳网。
果壳网的登录界面有验证码,请使用人工或者在线打码的方式识别验证码,并让爬虫登录。
登录以后可以正确显示"个人资料设置"界面的源代码。
涉及的知识点:
(1)爬虫识别验证码。
(2)爬虫模拟登录。
2、核心代码构建
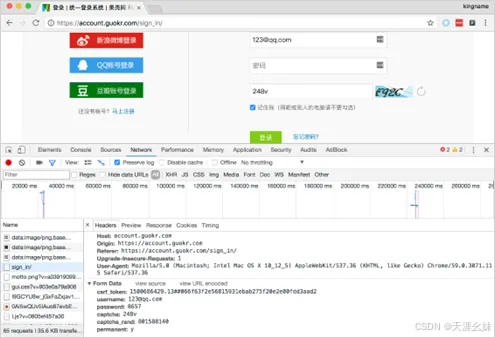
在模拟登录果壳网的时候,POST提交的数据有两个参数:csrf_token和captcha_ rand。
这两个参数需要使用XPath或者正则表达式从网页源代码中获取。登录果壳网所需要的参数如图所示。
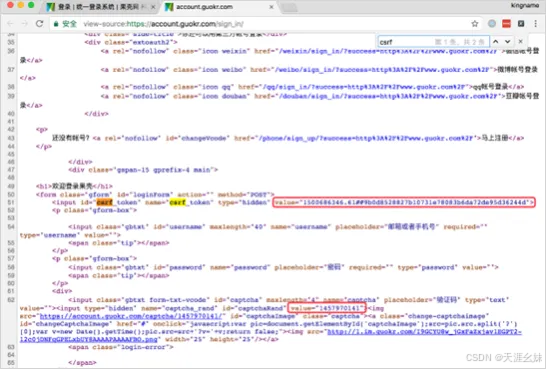
获取的csrf_token和captcha_rand位置如图。
3、运行与调试
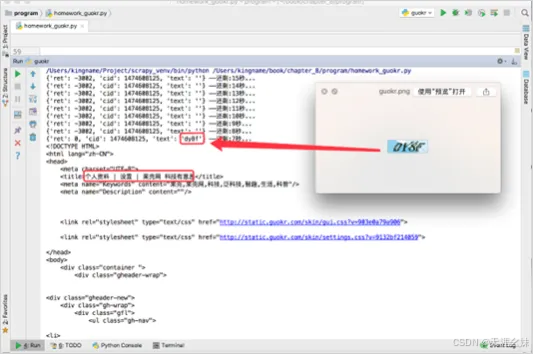
代码运行以后的结果如图。
从图中也可以看到,使用在线打码的方式,验证码没有即时返回每一秒去打码网站查询的过程。
最后打开的源代码HTML标题为"个人资料",说明已经成功登录。
好了,关于模拟登录与验证就讲到这里。
更多精彩内容请继续关注本站!