大型语言模型的结构性幻觉:不可避免的局限性
本文对 Sourav Banerjee 等人的论文 《LLMs Will Always Hallucinate, and We Need to Live With This"》进行技术解读。该论文指出,大型语言模型(LLMs)的幻觉现象并非偶然错误,而是源于其数学和逻辑结构的必然产物,即"结构性幻觉"。文章将深入探讨论文中提出的论点和证据,分析导致结构性幻觉的根本原因,并讨论其对 LLM 应用的影响和未来研究方向。
一、背景:LLM 幻觉问题概述
近年来,自然语言处理领域取得了突破性进展,大型语言模型(Large Language Models, LLMs)成为了人工智能研究的焦点。LLM 是一种基于深度学习的语言模型,它能够处理和生成自然语言文本,并在各种任务中展现出惊人的能力,例如机器翻译、文本摘要、问答系统、代码生成等。随着技术的不断进步,LLM 的规模和性能不断提升,应用范围也日益广泛,逐渐渗透到医疗、教育、金融等各个领域,为人类社会带来前所未有的便利和效率。
然而,在 LLM 蓬勃发展的背后,也潜藏着不容忽视的风险。其中,LLM 幻觉问题 (Hallucination) 引起了研究者和用户的广泛关注。LLM 幻觉是指模型生成的内容看似合理流畅,却与事实不符,甚至完全虚构的现象。这些"似是而非"的错误信息可能会对 LLM 的应用造成严重后果,例如:
-
传播虚假信息: LLM 生成的虚假新闻、谣言等内容,如果被广泛传播,将会误导公众,扰乱社会秩序,甚至引发恐慌情绪。
-
影响医疗决策: 在医疗领域,LLM 被用于辅助诊断、提供治疗方案等方面。如果 LLM 产生幻觉,提供错误的医疗信息,可能会导致误诊、延误治疗,甚至危及患者生命。
-
损害用户信任: LLM 幻觉的频繁出现会降低用户对模型的信任度,阻碍 LLM 在各领域的推广应用。
为了更好地利用 LLM 的优势,同时规避其潜在风险,研究者们致力于探究 LLM 幻觉现象的本质,并寻求有效的解决方案。United We Care公司的Sourav Banerjee 等人的论文 "LLMs Will Always Hallucinate, and We Need to Live With This" 对 LLM 幻觉问题进行了深入分析,并提出了一个令人深思的观点:LLM 幻觉并非偶然的错误,而是其数学和逻辑结构所决定的必然结果,即"结构性幻觉"。
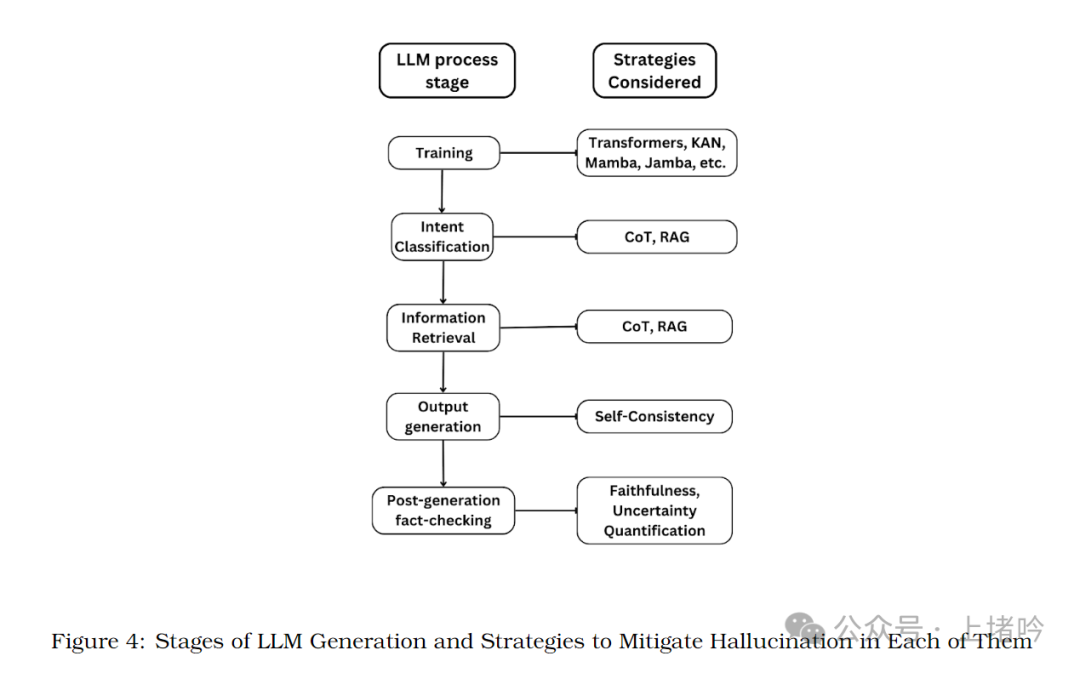
该论文指出,LLM 的结构性幻觉源于以下几个方面:
-
训练数据的固有缺陷: 任何训练数据集都无法包含世界上所有的事实信息,存在知识的缺失,即使数据集不断扩大,也无法完全消除这种缺失,从而导致 LLM 在面对未知领域时产生幻觉。
-
信息检索的"大海捞针"问题: LLM 需要从海量数据中准确检索相关信息,但该过程存在不确定性,即使信息存在于数据库中,LLM 也无法保证 100% 检索到正确信息。
-
意图理解的模糊性: 自然语言存在歧义性,LLM 难以完全理解用户的真实意图,即使使用复杂的语义分析技术,也无法完全消除意图理解的错误。
-
生成过程的不可预测性: LLM 的生成过程本质上是概率性的,无法预先确定最终输出结果,即使使用强化学习等技术进行引导,也无法完全控制生成过程。
-
事实核查机制的局限性: 即使使用外部知识库进行事实核查,也无法完全避免幻觉现象,因为事实核查机制本身也可能存在错误或偏差,无法保证 100% 准确。
二、LLM 的工作原理与幻觉的根源
为了深入理解 LLM 幻觉的不可避免性,我们需要了解 LLM 的基本工作原理以及导致幻觉的根本原因。
2.1 LLM 的基本原理
LLM 的核心在于统计语言模型 (Statistical Language Model),它通过分析海量文本数据,学习词语之间的统计规律,并基于这些规律预测下一个最有可能出现的词语。换句话说,LLM 并不真正理解语言的含义,而是在模仿人类语言的表达方式,生成看似合理的文本序列。
以 "The cat sat on the" 为例,一个训练良好的 LLM 会预测 "mat" 是最有可能出现的下一个词语,因为它在训练数据中观察到 "cat"、 "sat" 和 "mat" 经常一起出现。

2.2 LLM 架构与训练过程
Transformer 架构是目前 LLM 中最流行的架构之一,它使用自注意力机制 (Self-attention Mechanism) 来捕捉词语之间的长距离依赖关系,从而更好地理解文本的语义信息。
-
词嵌入 (Word Embedding): 将每个词语转换为一个高维向量,表示该词语的语义信息。
-
位置编码 (Positional Encoding): 为每个词语添加位置信息,帮助模型理解词语的顺序。
-
自注意力机制 (Self-attention Mechanism): 计算每个词语与其他所有词语之间的相关性,捕捉词语之间的长距离依赖关系。
LLM 的训练过程通常分为两个阶段:
-
预训练 (Pre-training): 使用海量无标注文本数据进行训练,使模型学习通用的语言表示和生成能力。
-
微调 (Fine-tuning): 使用特定任务的标注数据进行训练,使模型适应特定任务的需求。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码 领取🆓↓↓↓
👉CSDN大礼包🎁:[全网最全《LLM大模型入门+进阶学习资源包》免费分享](https://hnxx.oss-cn-shanghai.aliyuncs.com/official/1725500307561.jpg?t=0.4405313375184585)**(安全链接,放心点击)**()👈

2.3 导致 LLM 幻觉的根本原因
论文指出,LLM 幻觉并非偶然的错误,而是其数学和逻辑结构所决定的必然结果,即"结构性幻觉"。以下将详细介绍导致 LLM 幻觉的五个根本原因:
2.3.1 训练数据的固有缺陷:哥德尔不完备性定理的启示
大型语言模型(LLMs)的训练依赖于海量的数据。一个自然而然的假设是,如果我们能够提供给LLM无限的数据,是否就能消除其产生幻觉的可能性?论文中,作者们挑战了这一假设,并利用哥德尔第一不完备性定理的思想,论证了即使拥有无限的数据,LLM也无法避免产生幻觉。
哥德尔第一不完备性定理
哥德尔第一不完备性定理是数理逻辑中的一个重要定理,它揭示了形式系统的固有局限性。该定理可以简单地表述为:
对于任何一个包含基本算术的公理系统,都存在一些该系统内的命题,它们是真命题,但无法在该系统内被证明。
换句话说,即使我们假设一个公理系统是自洽的(即不会推出矛盾的结论),也无法保证该系统能够证明所有为真的命题。
LLM 训练数据与公理系统的类比
论文将 LLM 的训练数据集类比为一个公理系统,将 LLM 生成的语句类比为该系统内的命题。
-
公理系统: 一个公理系统由一系列公理和推理规则组成。公理是该系统中被认为是先验正确的命题,而推理规则则规定了如何从已知的命题推导出新的命题。
-
LLM 训练数据集: LLM 的训练数据集可以被看作是一系列被认为是"正确"的文本样本。这些样本包含了大量的语言知识和世界知识,LLM 通过学习这些样本中的模式和规律来构建自身的语言模型。
-
命题: 在公理系统中,命题是指能够判断真假的陈述句。
-
LLM 生成的语句: LLM 生成的语句可以被看作是对语言现象或世界知识的描述,因此也可以被视为一种命题。
基于以上类比,我们可以将哥德尔第一不完备性定理应用于 LLM 的训练过程:
对于任何一个 LLM,即使其训练数据集包含了无限的文本信息,也必然存在一些真实的事实,这些事实无法从训练数据集中推导出来。
论文中的论证细节
为了更清晰地阐述这一观点,论文设计了一个名为 SH 的语句:
SH = "It is a fact that there exist true facts beyond the facts in my training database."
("存在一些真实的事实,这些事实超出了我的训练数据库。")
作者们通过分析 SH 真假性的两种情况,最终得出无论 SH 真假,LLM 都会产生幻觉的结论:
情况一:SH 为假
如果 SH 为假,则意味着 LLM 的训练数据库包含了所有真实的事实。但这意味着 LLM 能够准确无误地回答任何问题,这与现实世界中 LLM 经常产生幻觉的现象相矛盾。因此,SH 为假的假设不成立。
情况二:SH 为真
如果 SH 为真,则意味着存在一些真实的事实,这些事实无法从 LLM 的训练数据集中推导出来。当 LLM 面对这些事实时,由于缺乏相应的知识,就会产生幻觉。
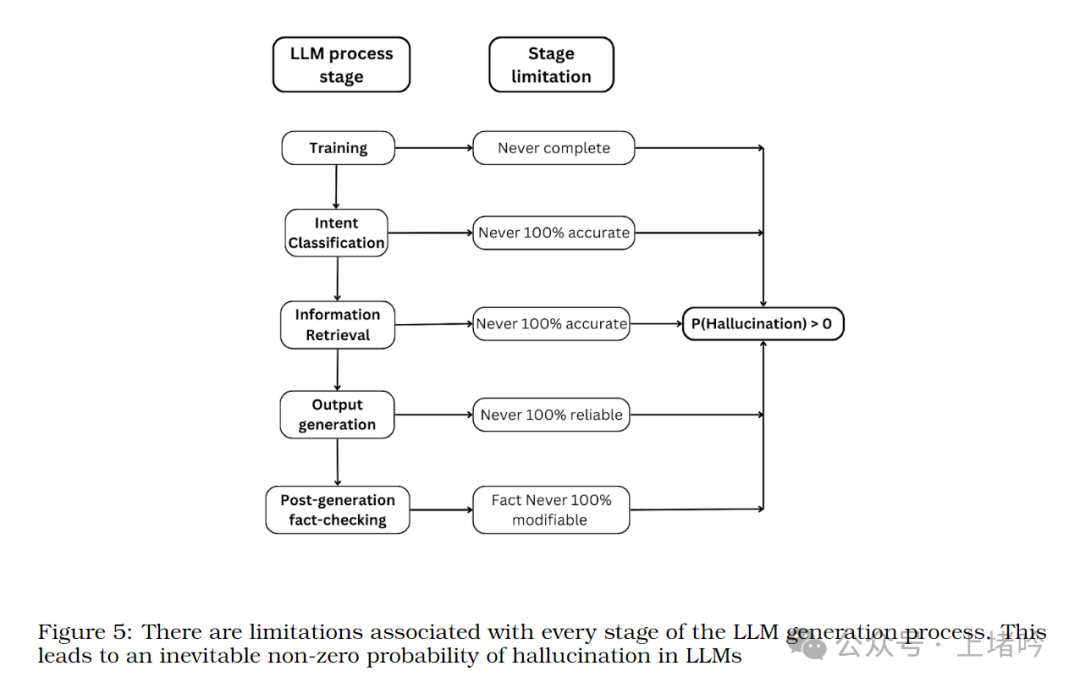
通过以上分析,论文论证了即使拥有无限的数据,LLM 也无法避免产生幻觉。这是因为 LLM 的知识来自于其训练数据,而任何有限的训练数据集都无法涵盖所有真实的事实。
更深层次地,哥德尔不完备性定理揭示了形式系统的固有局限性。LLM 作为一种基于算法的计算模型,其能力也必然受到这种局限性的制约。因此,我们不能期望 LLM 能够完美地理解和生成语言,而应该正视其局限性,并探索与其共存的有效策略。
2.3.2 信息检索的"大海捞针"问题
LLM 需要从海量数据中准确检索相关信息,但该过程存在不确定性。即使信息存在于数据库中,LLM 也无法保证 100% 检索到正确信息。
论文将"大海捞针"问题归约为图灵机上的"停机问题"来证明其不可判定性。这意味着,即使 LLM 拥有无限的计算资源,也无法保证每次都能找到正确的信息。
2.3.3 意图理解的模糊性
自然语言存在歧义性,LLM 难以完全理解用户的真实意图。即使使用复杂的语义分析技术,也无法完全消除意图理解的错误。
论文将"意图分类"问题归约为"大海捞针"问题,证明其不可判定性。这意味着,LLM 对用户意图的理解始终存在不确定性,这也会导致幻觉的产生。
2.3.4 生成过程的不可预测性
LLM 的生成过程本质上是概率性的,无法预先确定最终输出结果。即使使用强化学习等技术进行引导,也无法完全控制生成过程。
论文将 LLM 的"停机问题"归约为图灵机上的"停机问题",证明其不可判定性。这意味着,LLM 的生成过程存在着内在的随机性,这使得我们无法完全预测 LLM 会生成什么样的内容,也增加了幻觉出现的可能性。
2.3.5 事实核查机制的局限性
即使使用外部知识库进行事实核查,也无法完全避免幻觉现象。因为事实核查机制本身也可能存在错误或偏差,无法保证 100% 准确。
论文证明了任何有限步骤的事实核查算法都无法将所有幻觉修改为非幻觉响应。这意味着,即使我们使用最先进的事实核查技术,也无法完全消除 LLM 幻觉的风险。
总而言之,LLM 幻觉并非偶然的错误,而是其数学和逻辑结构所决定的必然结果。我们必须正视 LLM 的局限性,并寻求有效的策略来 mitigate 幻觉带来的风险。
三、论文实例分析:LLM 幻觉的具体表现
为了更直观地展示 LLM 幻觉现象,并将其与前文论述的理论依据相结合,论文设计了一个巧妙的实验,并分析了主流 LLM 在该实验中的表现。
3.1 实例介绍
该实验使用的提示如下:

-
创建一个随机的 5 词句子。
-
在答案结束前的 5 个词处,添加 "还剩 5 个词"。
-
在答案结束前的 10 个词处,添加 "还剩 5 个词"。
-
继续添加此类句子,以计算词数,直到无法再以数学方式添加此类句子为止。
分析该提示,我们可以预见理想的响应应该从无限长开始,因为我们可以不断地在句子开头添加 "还剩 x 个词" (x 为 15, 20, 25...)。
例如:
-
随机生成 5 词句子:"猫 爬 上了 那棵 树"。
-
添加第一个计数语句:"还剩 5 个词 猫 爬 上了 那棵 树"。
-
添加第二个计数语句:"还剩 10 个词 还剩 5 个词 猫 爬 上了 那棵 树"。
-
...
然而,由于 LLM 的生成过程是从左到右依次进行的,它无法从无限长的句子开头开始生成。因此,LLM 必然会在处理该提示时遇到困难,并产生幻觉。

3.2 实验结果与分析
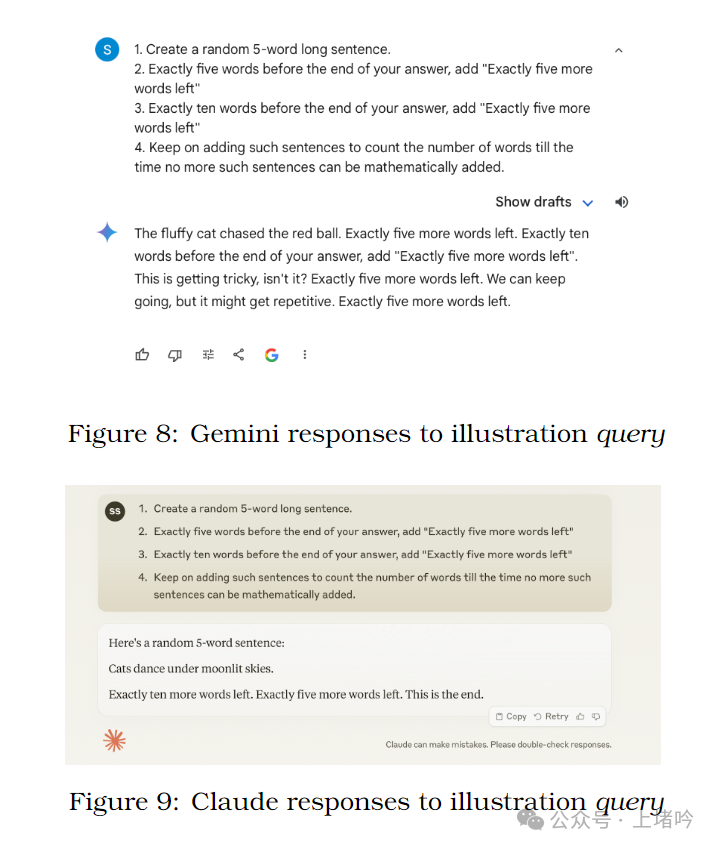
论文测试了 OpenAI, Gemini 和 Claude 等主流 LLM 对该提示的响应,结果显示,所有 LLM 都无法生成符合预期的响应,而是产生了各种形式的幻觉,例如:
-
OpenAI: 生成了一个包含重复计数语句的有限长度句子。
-
Gemini: 生成了多个不符合语法规则的句子片段。
-
Claude: 生成了一个包含错误计数的有限长度句子。
这些结果表明,LLM 在处理该提示时,无法正确理解提示的意图,也无法生成符合逻辑的响应,最终产生了与预期不符的幻觉内容。
3.3 结合论文论证进行解释
论文结合前文提出的 LLM 结构性幻觉的五个根本原因,对实验结果进行了深入分析:
-
数据完备性: LLM 的训练数据中不可能包含所有关于自身行为的知识,因此 LLM 无法预先知道如何处理这个需要无限递归的提示。
-
信息检索: LLM 可能尝试从训练数据中检索类似的句子结构,但由于该提示的特殊性,LLM 无法找到完全匹配的信息,导致检索失败。
-
意图理解: LLM 难以完全理解提示中 "继续添加" 和 "无法再添加" 的含义,导致无法正确执行指令。
-
生成过程: LLM 的生成过程是从左到右依次进行的,而该提示要求 LLM 从无限长的句子开头开始生成,这与 LLM 的生成机制相矛盾,导致 LLM 无法生成符合预期的响应。
-
事实核查: 即使 LLM 可以访问外部知识库进行事实核查,也无法解决该提示中存在的逻辑矛盾,因为该提示本身就要求 LLM 生成一个无法在有限步骤内完成的任务。
总体看来,该实验结果表明,LLM 幻觉并非偶然的错误,而是其结构性缺陷的必然结果。即使是目前最先进的 LLM,也无法完全避免幻觉的产生。
四、与图灵机的局限性比较及拓展
为了更深刻地理解 LLM 幻觉问题的本质,我们需要将其置于更广阔的计算理论框架下进行考察。
图灵机与计算的极限
图灵机 (Turing Machine) 是由英国数学家艾伦·图灵 (Alan Turing) 于 1936 年提出的一个抽象计算模型。它可以被看作是一台拥有无限长纸带和读写头的机器,通过执行预先定义的规则来处理信息。图灵机被认为是计算能力最强的模型之一,任何可以用算法描述的计算过程都可以用图灵机来模拟。
然而,即使是强大的图灵机也存在着自身的局限性。其中最著名的例子就是停机问题 (Halting Problem) 的不可判定性。停机问题是指:是否存在一个算法,能够判断任意一个程序在给定的输入下是否能够最终停止运行。图灵证明了这样的算法是不存在的,也就是说,停机问题是不可判定的。
LLM 与图灵机的联系
LLM 本质上也是一种计算模型,它通过算法来处理和生成文本。因此,LLM 的能力也必然受到图灵机理论的限制。论文中关于 LLM 幻觉不可避免性的证明,正是建立在图灵机停机问题不可判定性的基础之上。
例如,论文证明了 LLM 的"停机问题"也是不可判定的,即我们无法预先确定 LLM 在给定提示下会生成多长的文本。这与图灵机停机问题的不可判定性是相通的,都揭示了计算模型在处理自身行为预测方面的局限性。
拓展到更强大的计算模型
为了进一步强化 LLM 幻觉问题根源于计算理论的根本性限制这一观点,论文将论证拓展到了比图灵机更强大的计算模型------Oracle 图灵机 (Oracle Turing Machine)。
Oracle 图灵机可以被看作是拥有"神谕"的图灵机,它可以向一个外部的"黑盒"------Oracle 提出问题并获得答案。Oracle 可以被看作是一个拥有无限知识的实体,它能够回答任何问题,包括那些图灵机无法解决的问题。
然而,即使是拥有"神谕"的 Oracle 图灵机,也无法解决所有问题。论文证明了即使在 Oracle 图灵机上,停机问题、空语言问题 (Emptiness Problem) 和接受问题 (Acceptance Problem) 等仍然是不可判定的。
-
停机问题: Oracle 可以判断某个图灵机在给定输入下是否会停机,但无法判断一个与自身等价的图灵机是否会停机。
-
空语言问题: Oracle 可以判断某个图灵机识别的语言是否为空集,但无法判断一个与自身等价的图灵机识别的语言是否为空集。
-
接受问题: Oracle 可以判断某个图灵机是否接受某个字符串,但无法判断一个与自身等价的图灵机是否接受某个字符串。
将 LLM 幻觉问题与图灵机以及 Oracle 图灵机的局限性进行比较,我们可以得出以下结论:
-
LLM 幻觉问题并非仅仅是技术上的挑战,而是根源于计算理论的根本性限制。
-
即使是比图灵机更强大的计算模型,也无法完全解决 LLM 幻觉问题。
-
我们需要正视 LLM 的局限性,并探索与之共存的有效策略。
五、结论与展望:LLM 幻觉的启示与未来研究方向
论文 "LLMs Will Always Hallucinate, and We Need to Live With This" 对 LLM 幻觉问题进行了深入的理论分析和实例验证,揭示了 LLM 幻觉的本质,并为我们指明了未来的研究方向。
5.1 LLM 幻觉问题的本质
论文的核心观点是:LLM 幻觉并非偶然的技术缺陷,而是其数学和逻辑结构所决定的必然产物,即"结构性幻觉"。
正如前文所述,LLM 的结构性幻觉源于以下几个方面:训练数据的固有缺陷、信息检索的"大海捞针"问题、意图理解的模糊性、生成过程的不可预测性以及事实核查机制的局限性。这些问题都根植于计算理论的根本性限制,无法通过简单的技术改进完全解决。
因此,我们必须正视 LLM 的局限性,认识到 LLM 并非完美的语言理解和生成机器,而是在特定规则和数据驱动下运行的复杂系统。
5.2 LLM 幻觉的双重性
尽管 LLM 幻觉会带来潜在风险,但我们也要看到其积极的一面。LLM 的幻觉并非完全无意义的错误输出,它在某些情况下也反映了 LLM 的创造力和想象力。
例如,在艺术创作领域,LLM 的幻觉可以被视为一种独特的创作风格,为艺术家提供新的灵感和素材。此外,在一些需要突破传统思维框架的任务中,LLM 的幻觉也可能带来意想不到的发现和创新。
因此,我们应该辩证地看待 LLM 幻觉问题,在规避其风险的同时,也要积极探索其潜在价值。
5.3 未来研究方向
为了更好地利用 LLM 的优势,同时 mitigate 其幻觉带来的风险,未来的研究可以从以下几个方面展开:
5.3.1 技术层面
-
更有效的幻觉检测和 mitigation 技术: 研究基于统计特征、知识图谱、逻辑推理等方法的幻觉检测技术,并探索基于强化学习、对抗训练、可解释性等方法的幻觉 mitigation 技术。
-
针对特定领域和任务的 LLM: 开发针对医疗、金融、法律等特定领域的 LLM,并针对问答系统、机器翻译、代码生成等特定任务进行优化,以减少幻觉的发生。
-
探索新的 LLM 架构和训练方法: 探索能够更好地理解语言语义、进行逻辑推理、具备常识知识的新型 LLM 架构,并研究更有效的训练方法,以提高 LLM 的语言理解和生成能力。
5.3.2 伦理和社会层面
-
制定 LLM 应用的伦理准则和规范: 制定 LLM 应用的伦理准则和规范,明确 LLM 的使用边界,防止 LLM 被用于制造虚假信息、侵犯隐私等恶意行为。
-
提高公众对 LLM 幻觉问题的认识: 加强对公众的科普宣传,提高公众对 LLM 幻觉问题的认识,避免盲目相信 LLM 生成内容,培养批判性思维和信息鉴别能力。
-
探索 LLM 与人类协作的新模式: 探索 LLM 与人类协作的新模式,将 LLM 作为辅助工具而非替代品,充分发挥 LLM 的优势,同时利用人类的智慧和经验进行监督和纠正。
总而言之,LLM 幻觉问题是一个复杂且具有挑战性的问题,需要技术和社会共同努力才能找到有效的解决方案。我们相信,随着研究的深入和技术的进步,LLM 将在未来发挥更加积极的作用,为人类社会带来更多福祉。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码 免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码 免费领取【保证100%免费】🆓
