
🐇明明跟你说过:个人主页
🏅个人专栏:《深度探秘:AI界的007》 🏅
🔖行路有良友,便是天堂🔖
目录
[1、什么是Lang Chain](#1、什么是Lang Chain)
[1、文档加载(Document Loading)](#1、文档加载(Document Loading))
[2、文本切分(Text Splitting)](#2、文本切分(Text Splitting))
[3、向量化存储(Embedding + Vector Store)](#3、向量化存储(Embedding + Vector Store))
[4、智能问答(RAG: Retrieval-Augmented Generation)](#4、智能问答(RAG: Retrieval-Augmented Generation))
[三、构建问答系统:LangChain RAG 实战项目](#三、构建问答系统:LangChain RAG 实战项目)
[2、读取 Word 文件内容](#2、读取 Word 文件内容)
[3、切分文本为 chunks](#3、切分文本为 chunks)
[4、向量化 + 存储到 FAISS 数据库](#4、向量化 + 存储到 FAISS 数据库)
[5、构建问答链(Retrieval + LLM)](#5、构建问答链(Retrieval + LLM))
一、引言
1、什么是Lang Chain
你有没有想过,让 AI 不仅能回答问题,还能主动思考、查资料、记忆上下文、执行任务 ?
这就是 LangChain 的魔力所在!✨
🧠 LangChain 是什么?
简单来说,LangChain 是一个帮你构建 "智能 Agent(智能体)" 的工具库 。
它就像是给大模型(比如 GPT)加上了"手脚 + 大脑",让它能真正动起来,不再只是个"回答机"。
🛠️ 它能做什么?
| 功能 | 通俗解释 | 举个例子 |
|---|---|---|
| 🗃️ 记忆(Memory) | 模型可以"记住"你之前说过的话 | 连续聊天时不再重复自我介绍 😅 |
| 🔗 工具调用(Tools) | 模型能调用其他工具,如搜索、计算器 | "帮我查一下北京明天的天气" 🌤️ |
| 📚 知识库(Retrieval) | 模型能查找文档或数据库内容 | "根据公司手册,告诉我请假流程" 📄 |
| 📋 多步骤任务(Chain) | 模型可以分步骤执行复杂任务 | 写报告 → 查资料 → 汇总 → 输出 📊 |
| 🤖 智能 Agent | 像个 AI 助理,能自己决策、自己行动 | "每天早上 9 点给我发个日报提醒" ⏰ |
🏗️ 工作原理(简单比喻)
把 LangChain 想成搭积木:
-
📦 大模型(比如 GPT)是积木核心
-
🔧 工具(如搜索、数据库)是积木配件
-
🧩 LangChain 是连接一切的拼装架构
通过 LangChain,你可以把这些积木灵活组合,搭出属于你自己的 AI 应用!
🧑🍳 举个生活中的例子:做一顿饭
用传统大模型(没 LangChain):
你问:"鸡蛋怎么煮?"它告诉你方法,但没法动手 🤷
用 LangChain 构建的 AI 助理:
它不仅告诉你怎么煮,还能帮你:
-
查询冰箱里有什么 🧊
-
推荐菜谱 🍳
-
自动下单缺的食材 🛒
-
给你发做饭步骤提醒 📱
是不是一下子聪明多了?😎

2、文档问答的典型应用场景
文档问答系统 = 把 AI + 自己的文档整合起来,让 AI 自动"看文档 + 回答问题"
是不是很像一个不会请假的 AI 同事?🤖
💼 企业内部知识问答
🧠 员工问答助手
场景:新员工入职、老员工查询制度
💬 举例:
-
"年假怎么请?"
-
"公司 VPN 怎么配置?"
📝 对应文档:员工手册、制度文件、操作指南
🎯 效果:不用再翻厚厚的文档,直接问 AI!
🏥 医疗领域
📋 医学资料问答系统
场景:医生或患者查询疾病、药品说明
💬 举例:
-
"这个药物有啥副作用?"
-
"手术后的恢复流程是怎样的?"
📝 对应文档:医疗手册、临床指南、药品说明书
🎯 效果:快速查阅,避免误读、节省时间 🩺
⚖️ 法律服务
📘 法规/合同文档问答
场景:律师事务所、法务部门、合同管理
💬 举例:
-
"这份合同的付款条款是怎么规定的?"
-
"劳动法对加班时间有啥要求?"
📝 对应文档:合同文本、法律法规文库
🎯 效果:快速定位法律条款,不用手动 Ctrl+F 疯狂找 😵
🧰 客服和产品说明
🛠️ 产品说明 / 用户手册问答
场景:用户使用产品遇到问题
💬 举例:
-
"这个打印机怎么连接 Wi-Fi?"
-
"为什么启动时出现错误代码 E203?"
📝 对应文档:产品说明书、FAQ、故障手册
🎯 效果:减少人工客服压力,让用户自助解决 🧑🔧
💡 总结一句话:
文档问答 = 把"静态文档"变成"可对话知识库",让你问一句,它答一句,效率翻倍 🚀
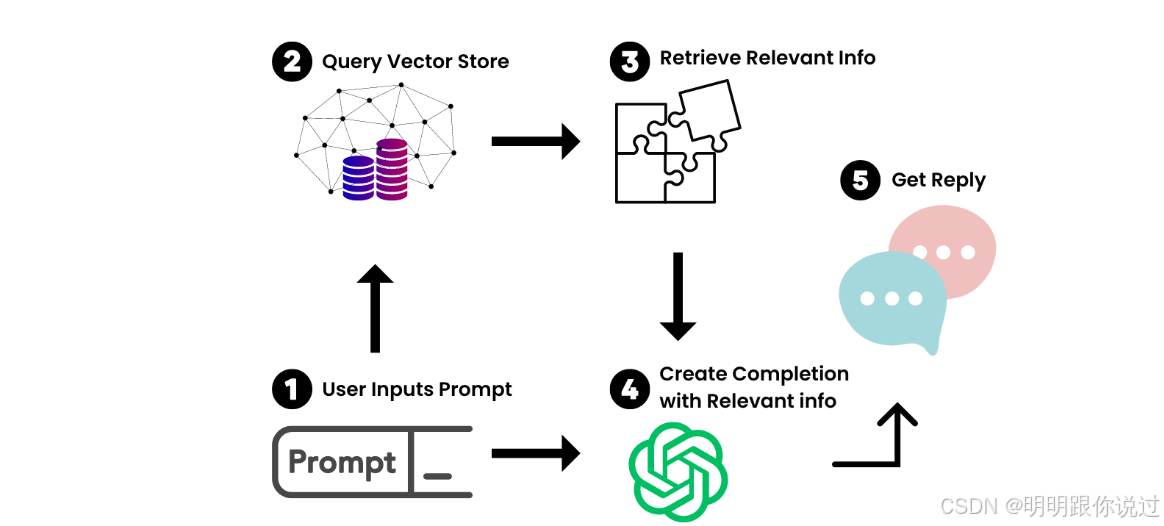
二、文档处理的核心流程全景图
1、文档加载(Document Loading)
把各种格式的文档,读进来变成文本
🧩 用到的 LangChain 模块:DocumentLoader
📂 支持格式广泛:
-
PDF
-
HTML、网页链接
-
TXT、Markdown
-
CSV、Notion、微信公众号......等等
💬 举例:
python
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("report.pdf")
documents = loader.load()✨ 目的:从"文件"变成"字符串文本",让后续处理成为可能!
2、文本切分(Text Splitting)
把长文档切成小块,模型吃得下才有输出
🧩 用到的模块:TextSplitter(比如 RecursiveCharacterTextSplitter)
📦 原因:
-
大模型有输入长度限制(token 限制)
-
分块后更利于建立向量索引,提升检索效果
💬 举例:
python
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
docs = splitter.split_documents(documents)✨ 目的:文档变成一堆"小语段",每段都能独立处理、检索
3、向量化存储(Embedding + Vector Store)
把文本转成向量,用来快速查找"语义相近"的内容
🧩 用到的模块:
-
Embeddings(如 OpenAIEmbeddings) -
VectorStore(如 FAISS、Chroma、Milvus、Pinecone 等)
💬 举例:
python
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(docs, embeddings)📌 每段文本会被转换为一个"语义向量",然后保存到向量数据库中。
✨ 目的:为后面的智能问答做准备,确保能根据问题找对相关内容!
4、智能问答(RAG: Retrieval-Augmented Generation)
根据问题检索相关片段,然后交给大模型生成答案
🧩 用到的模块:
-
Retriever:检索器,从向量数据库中找相似文本 -
LLM:大语言模型,用于回答问题 -
QA Chain:如RetrievalQA或ConversationalRetrievalChain
💬 举例:
python
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(
llm=ChatOpenAI(),
retriever=vectorstore.as_retriever()
)
result = qa_chain.run("Q3 营收是多少?")🧠 底层流程:
用户提问 → 检索相关片段 → 送入大模型 → 生成答案 → 响应用户
✨ 目的:结合"上下文 + 问题",给出准确、有依据的回答 ✅
流程图示意:
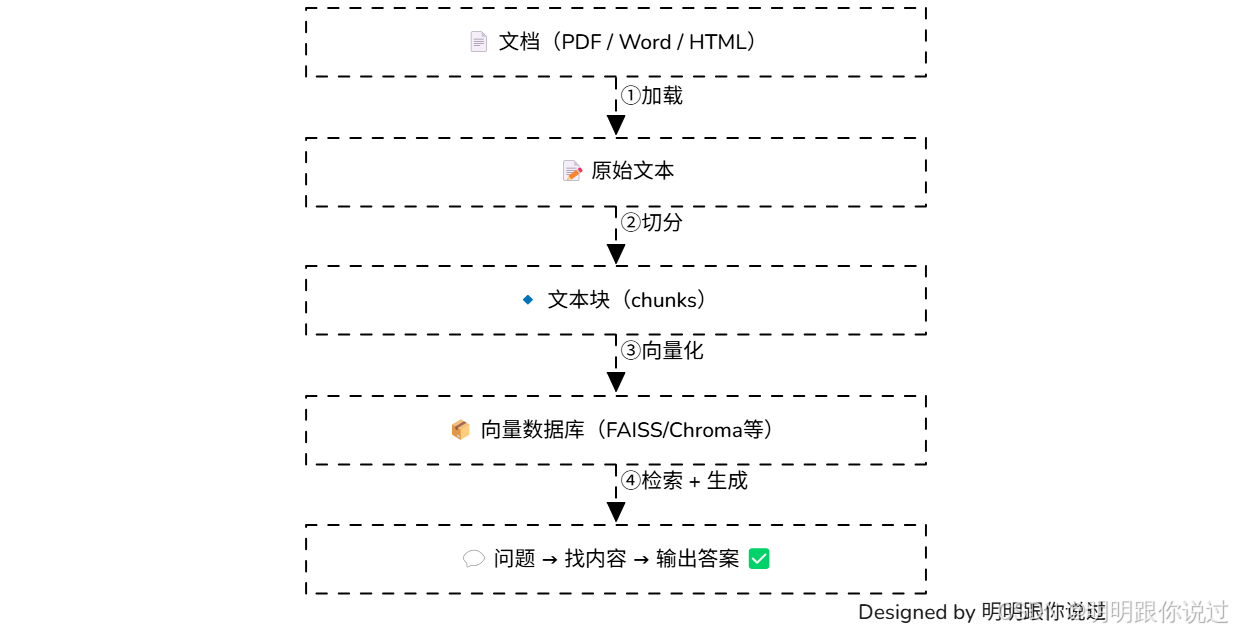
💡 总结一句话:
LangChain 文档问答 = 读文档 + 分片段 + 建索引 + 智能问答,打造属于你的 ChatPDF! 💬📄🤖
三、构建问答系统:LangChain RAG 实战项目
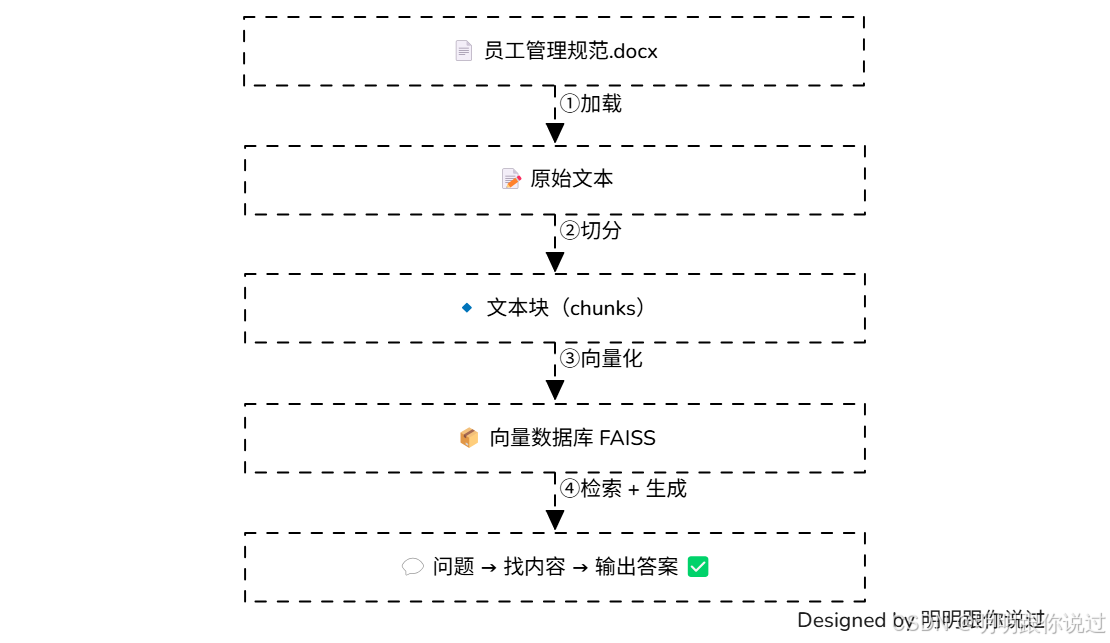
上面的技术相信你已经了解了,接下来我们动手做一个小实验,
我有一个员工管理规范的word,现在,我要将它提取分块后,写入到本地数据库FAISS中
当用户发起聊天时,基于员工管理规范回答用户的问题
流程如下:
1、安装依赖
首先,安装该项目的依赖,在终端执行下面的命令:
python
pip install docx langchain openai faiss-cpu 2、读取 Word 文件内容
LangChain 没有直接提供 Word 加载器,我们使用 python-docx:
python
from docx import Document
def load_word_file(path):
doc = Document(path)
content = "\n".join([para.text for para in doc.paragraphs if para.text.strip()])
return content这段代码的作用是:读取指定路径的 Word 文件,提取出其中所有有效的文本段落,并将它们拼接成一个以换行符分隔的大字符串。我们可以通过调用这个函数,方便地获取文档的全部文本内容,以便后续的处理(如切分、向量化等)。
3、切分文本为 chunks
python
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.docstore.document import Document as LCDocument
# 加载文本
raw_text = load_word_file("C:/Users/LMT/Desktop/员工管理规范.docx")
# 创建 LangChain Document 对象
doc = LCDocument(page_content=raw_text)
# 切分
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
docs = splitter.split_documents([doc])这段代码的总体目标是:
-
加载文档:首先,从指定路径加载 Word 文件,并提取文本内容。
-
封装文档 :将文本内容封装到 LangChain 的
LCDocument对象中,方便后续操作。 -
切分文本 :使用
RecursiveCharacterTextSplitter将长文本按字符数切分为多个较小的片段,每个片段最多 500 个字符,并允许 100 个字符的重叠部分。
最终,docs 变量将包含一个由多个切分后的 LCDocument 对象组成的列表,这些对象分别代表了文档的不同片段,准备好进行向量化、存储或者其他处理。
4、向量化 + 存储到 FAISS 数据库
python
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
# 创建嵌入模型(你也可以换成 HuggingFaceEmbeddings 或其他)
embeddings = OpenAIEmbeddings()
# 向量化 & 构建 FAISS 向量数据库
vectorstore = FAISS.from_documents(docs, embeddings)
# 可选:保存到本地
vectorstore.save_local("faiss_index")这段代码的功能是:
-
创建嵌入模型:利用 OpenAI 的 GPT 模型将文档内容转换为嵌入向量(每个文档块都会有一个高维的向量表示,捕捉它的语义)。
-
向量化并构建 FAISS 向量数据库:利用 FAISS 库将这些嵌入向量存储在一个高效的向量数据库中,便于后续进行相似度搜索。
-
保存向量数据库:将构建的 FAISS 向量数据库保存到本地磁盘,方便后续加载和使用。
最终,这样的存储和向量化过程,使得后续的问答系统能够非常高效地从文档中检索出相关信息,以便生成准确的答案。
5、构建问答链(Retrieval + LLM)
python
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# 加载本地向量库(如需要)
vectorstore = FAISS.load_local("faiss_index", embeddings, allow_dangerous_deserialization=True)
# 构建问答链
qa = RetrievalQA.from_chain_type(
llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"),
retriever=vectorstore.as_retriever(),
return_source_documents=True
)
# 用户提问
query = "我是一名工龄10年的员工,我每年有多少年假?"
result = qa(query)
# 打印结果
print("🤖 答案:", result['result'])
print("📄 来源片段:")
for doc in result['source_documents']:
print("-", doc.page_content[:100])这段代码实现了以下功能:
-
加载本地 FAISS 向量数据库:从磁盘加载之前保存的向量数据库。
-
构建问答链:创建一个基于 OpenAI GPT 模型和 FAISS 向量数据库的问答系统。
-
用户提问:用户输入问题,系统会通过 FAISS 检索相关文档,并通过 GPT 生成答案。
-
打印答案和来源片段:显示生成的答案以及相关的文档片段,帮助用户了解模型如何得出答案。
📦 补充说明:
| 模块 | 功能 |
|---|---|
python-docx |
读取 Word 文档内容 |
RecursiveCharacterTextSplitter |
将长文本拆成多个小块 |
OpenAIEmbeddings |
文本嵌入向量生成器 |
FAISS |
本地向量数据库(快 + 离线可用) |
RetrievalQA |
从向量库中取回内容+交给 LLM 回答问题 |
6、完整代码
python
from docx import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.docstore.document import Document as LCDocument
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
def load_word_file(path):
doc = Document(path)
content = "\n".join([para.text for para in doc.paragraphs if para.text.strip()])
return content
# 加载文本
raw_text = load_word_file("C:/Users/LMT/Desktop/员工管理规范.docx")
# 创建 LangChain Document 对象
doc = LCDocument(page_content=raw_text)
# 切分
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
docs = splitter.split_documents([doc])
# 创建嵌入模型(你也可以换成 HuggingFaceEmbeddings 或其他)
embeddings = OpenAIEmbeddings()
# 向量化 & 构建 FAISS 向量数据库
vectorstore = FAISS.from_documents(docs, embeddings)
# 可选:保存到本地
vectorstore.save_local("faiss_index")
embeddings = OpenAIEmbeddings()
# 加载本地向量库(如需要)
vectorstore = FAISS.load_local("C:/Users/LMT/PycharmProjects/AI/LangChain/Document_Q&A/faiss_index", embeddings, allow_dangerous_deserialization=True)
# 构建问答链
qa = RetrievalQA.from_chain_type(
llm=ChatOpenAI(temperature=0, model="gpt-3.5-turbo"),
retriever=vectorstore.as_retriever(),
return_source_documents=True
)
# 用户提问
query = "我是一名工龄10年的员工,我每年有多少年假"
result = qa(query)
# 打印结果
print("🤖 答案:", result['result'])
print("📄 来源片段:")
for doc in result['source_documents']:
print("-", doc.page_content[:100])7、测试运行
提问 "我是一名工龄10年的员工,我每年有多少年假"
执行结果如下:
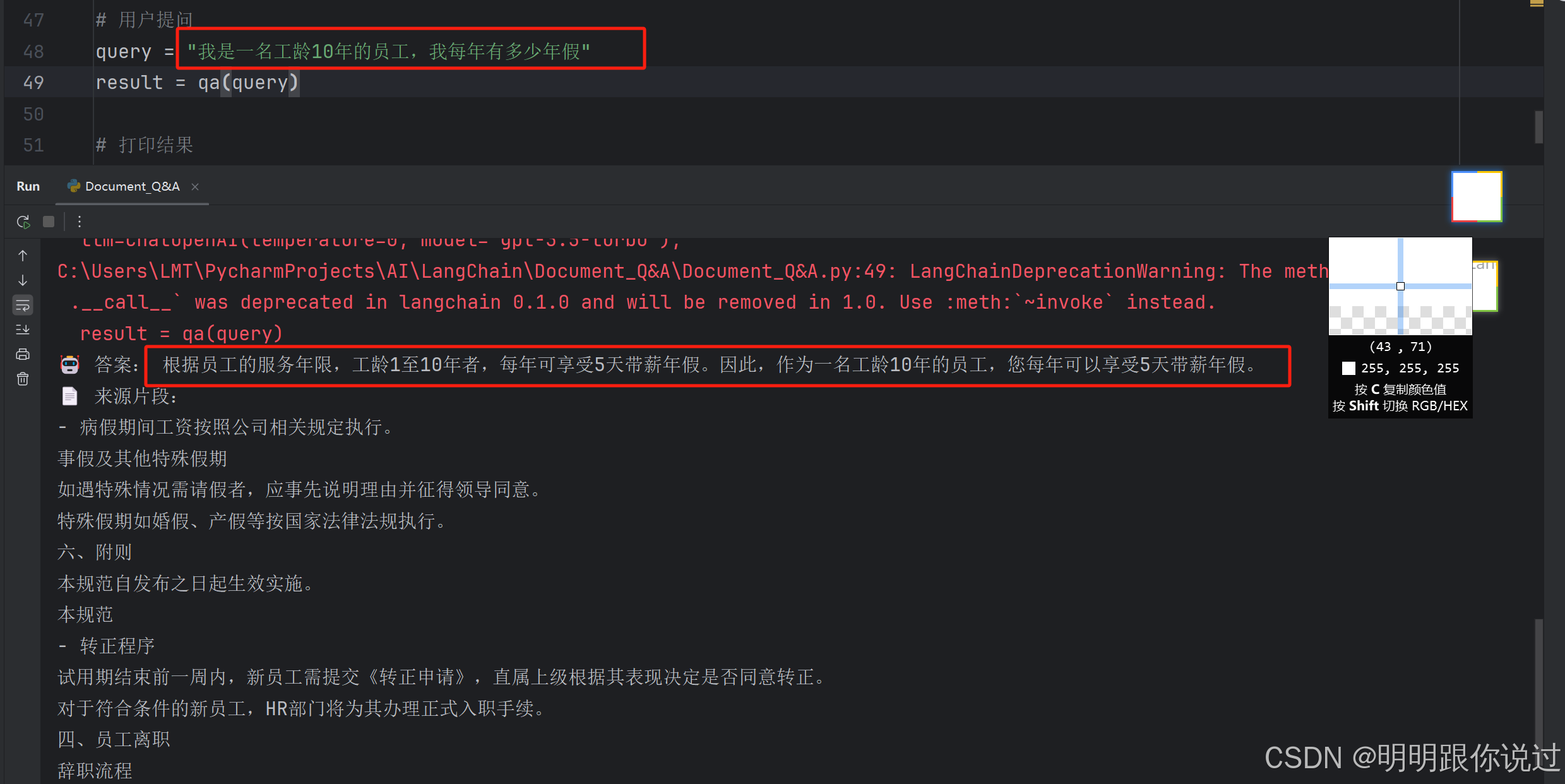
答案来源:
员工管理规范.docx
8、优化建议
🚀 BONUS:可选优化方向:
| 优化点 | 说明 |
|---|---|
使用 HuggingFaceEmbeddings |
免费本地化 Embedding 模型 |
使用 Chroma |
替代 FAISS,支持持久化更方便 |
| 构建前端 | 用 Gradio / Streamlit 做个简单问答界面 |
| 上下文记忆 | 增强多轮提问体验 |
| 文档多语种支持 | 支持英文/中英混合文档 |
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!