在当今人工智能飞速发展的时代,深度学习框架成为了研究人员和开发者们不可或缺的工具。PyTorch作为其中的佼佼者,凭借其简洁易用的API、灵活的动态计算图和强大的社区支持,吸引了众多开发者。本文将带你从零开始,一步步搭建一个简单的神经网络,让你快速入门PyTorch。
一、PyTorch简介
PyTorch是一个开源的机器学习库,基于Torch,主要用于应用如计算机视觉和自然语言处理等人工智能领域。它由Facebook的人工智能研究团队发布,支持张量计算(类似NumPy)和自动求导系统,非常适合动态图的构建和调试。
二、环境搭建
在开始之前,你需要安装PyTorch。访问PyTorch官网(https://pytorch.org/),根据你的系统配置选择合适的安装命令。例如,如果你使用的是Python 3.9版本,可以通过以下命令安装PyTorch:

安装完成后,你可以通过以下代码测试PyTorch是否安装成功:

如果能够正常输出版本号,说明安装成功!
三、搭建神经网络
(一)数据准备
在深度学习中,数据是至关重要的。这里我们使用PyTorch自带的`torchvision`库中的MNIST数据集,这是一个手写数字识别的经典数据集,包含60,000张训练图像和10,000张测试图像。
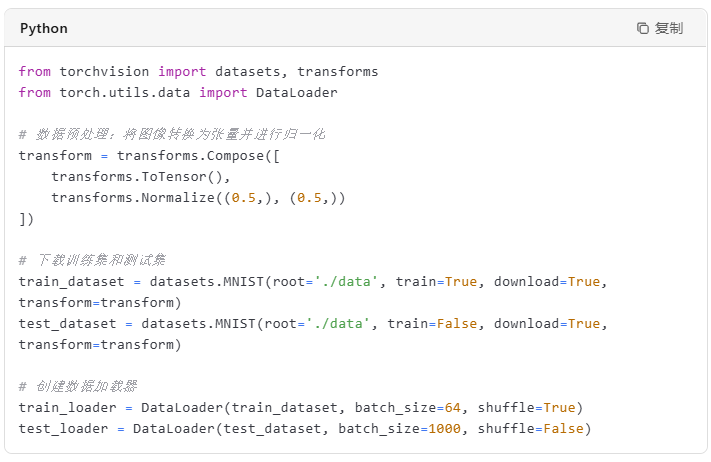
(二)定义神经网络模型
接下来,我们定义一个简单的全连接神经网络。PyTorch提供了`torch.nn.Module`类,所有神经网络模型都继承自这个类。
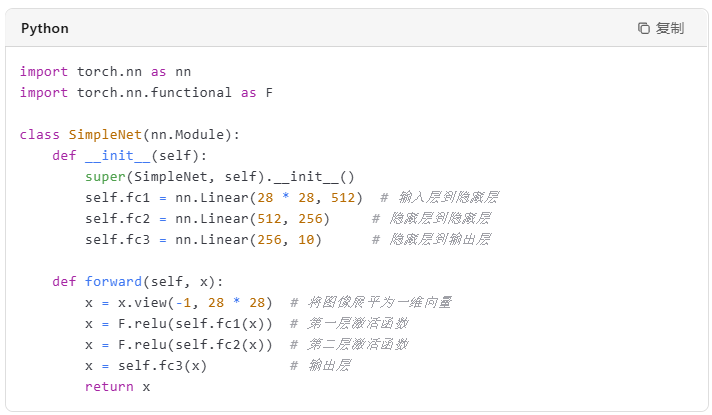
(三)训练模型
定义好模型后,我们需要设置损失函数和优化器。这里我们使用交叉熵损失函数和随机梯度下降(SGD)优化器。
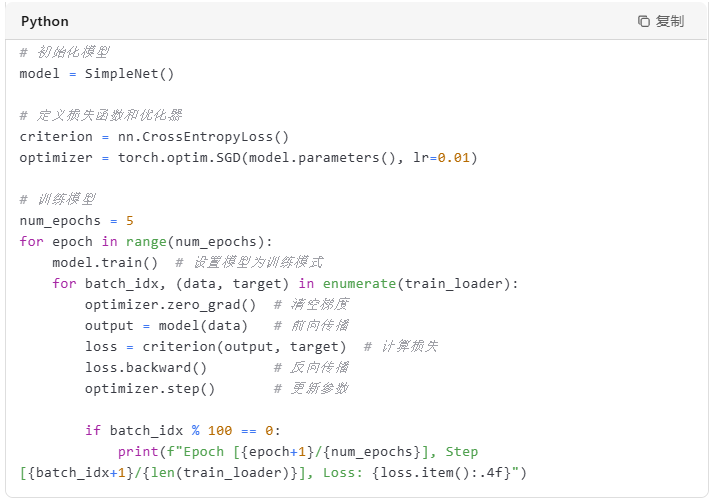
(四)测试模型
训练完成后,我们需要在测试集上评估模型的性能。
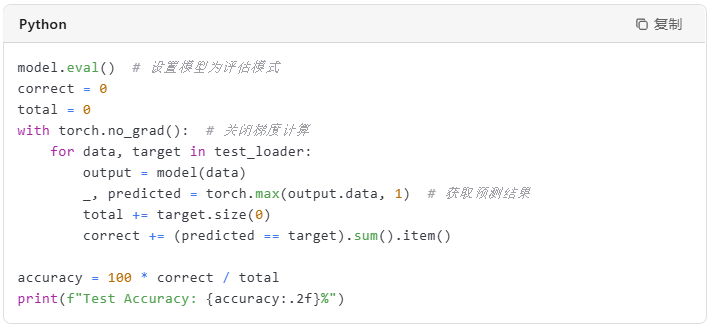
四、总结
通过本文的介绍,你已经成功搭建了一个简单的神经网络,并完成了训练和测试。PyTorch的灵活性和易用性使得深度学习的入门变得非常容易。当然,这只是PyTorch的冰山一角,它还支持卷积神经网络(CNN)、循环神经网络(RNN)等多种复杂的网络结构,以及GPU加速、模型保存和加载等功能。
希望这篇文章能帮助你迈出深度学习的第一步,开启你的AI之旅!如果你对PyTorch有更多兴趣,可以参考PyTorch官方文档(https://pytorch.org/docs/stable/index.html),里面包含了丰富的教程和API文档。