25年3月来自 UC Riverside、U Wisconsin 和 TAMU 的论文"UniOcc: A Unified Benchmark for Occupancy Forecasting and Prediction in Autonomous Driving"。
UniOcc 是一个全面统一的占用预测基准(即基于历史信息预测未来占用)和基于摄像头图像的当前帧占用预测。UniOcc 整合来自多个真实数据集(例如 nuScenes、Waymo)和高保真驾驶模拟器(例如 CARLA、OpenCOOD)的数据,提供带有逐体素流标注的 2D/3D 占用标签,并支持协作自动驾驶。在评估方面,与依赖次优伪标签进行评估的现有研究不同,UniOcc 采用不依赖于真实占用的全新指标,从而能够对占用质量的其他方面进行稳健评估。通过对最先进模型进行大量实验,证明大规模、多样化的训练数据和明确的流信息可显著提升占用预测和预报性能。
UniOcc 概述如图所示:
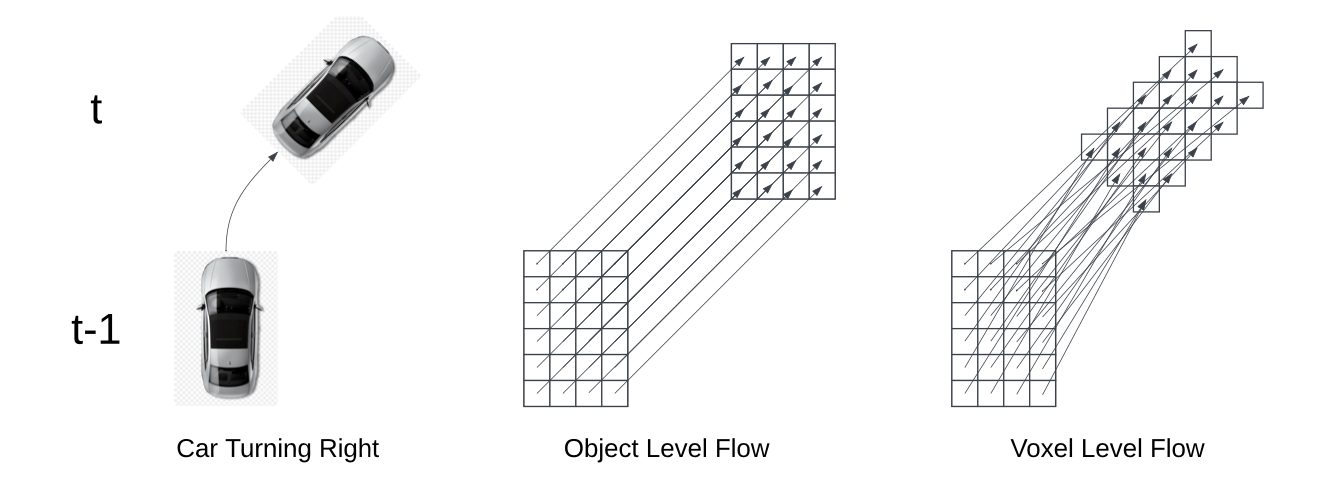
如下表所示:UniOCC和其他占用数据集的比较

统一的数据格式和特征
基准测试支持各种以占用为中心的任务,包括占用预测、单帧占用预测和流量估计。该框架定义以下与任务无关的数据格式:
语义占用标签。将场景表示为一个 3D 体素网格 G ∈ {0,...,C},其中 C 表示类别数,L、W、H 分别表示网格沿自车航向轴、横轴和纵轴的尺寸。该网格以自车为中心,+x 轴与行驶方向对齐,+y 轴向左,+z 轴向上。对于某些 2D 任务(例如,运动规划),通过优先级方案(例如,行人 > 汽车 > 道路)折叠高度维度,使得每个垂直柱采用其最高优先级体素的标签。这种方法可以防止重要目标类别(例如行人)被同一网格列中优先级较低的标签遮挡,从而确保后续任务能够获得有意义的表示。
摄像机图像。将原始 RGB 图像存储在四维张量 I ∈ {0,...,255} 中,K_cam 表示机载摄像机的数量,每幅图像的分辨率为 Img_x × Img_y。
摄像机视场 (FOV) 掩码。二元的三维张量 U ∈ {0, 1} 表示哪些体素位于每个摄像机的可观察视锥体内(U = 1 表示可见体素,U = 0 表示其他体素)。对于需要明确描绘遮挡区域或未观察空间的基于摄像机占用方法而言,此掩码至关重要。
摄像机内参和外参。将相机内参表示为 Int,而外部变换(从每个相机到自身坐标系)则表示为 Ext,其中 SE(3) 表示一组三维齐次变换。这些参数统一从三维自身坐标系到二维图像平面的投影。
自身到世界坐标系的变换。齐次变换矩阵 T_e^w 表示自身车辆在全局世界坐标系中的姿态,从而能够精确地对齐来自多个传感器和坐标系的数据。
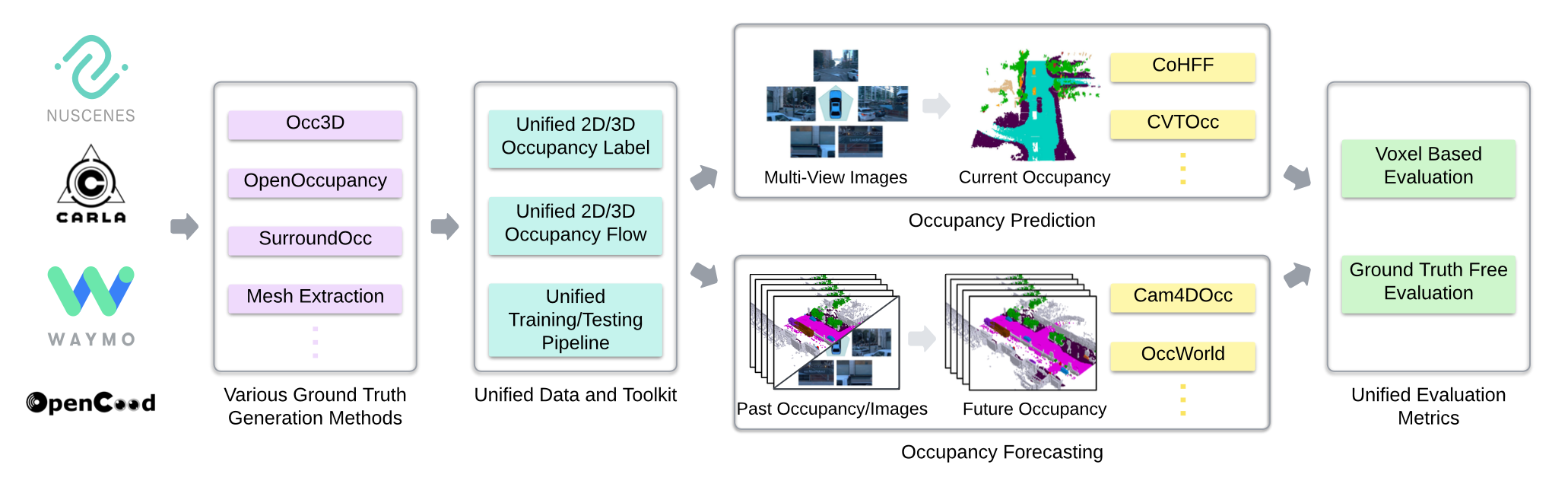
前向占用流。定义一个四维张量 F,用于记录每个体素的前向运动矢量。与之前的方法 49 为物体的所有体素分配单一速度(因此忽略物体的旋转)不同,该方法计算单个体素流,同时捕捉平移和旋转。分别计算动态前景目标(例如汽车、行人)和静态背景环境(例如道路、植被)的光流,并将动态和静态光流合并到 F_n^t 中。如图所示,这种体素级光流捕捉完整的三维运动,包括旋转。
后向占用光流。与前向光流类似,定义一个四维张量 B 来捕捉后向运动矢量。不是计算每个体素从 t 到 t + 1 的位移,而是评估从 t 到 t − 1 的运动。这种后向光流对于那些受益于逆-时间监督或多个-未来训练策略的模型尤其有用 24。
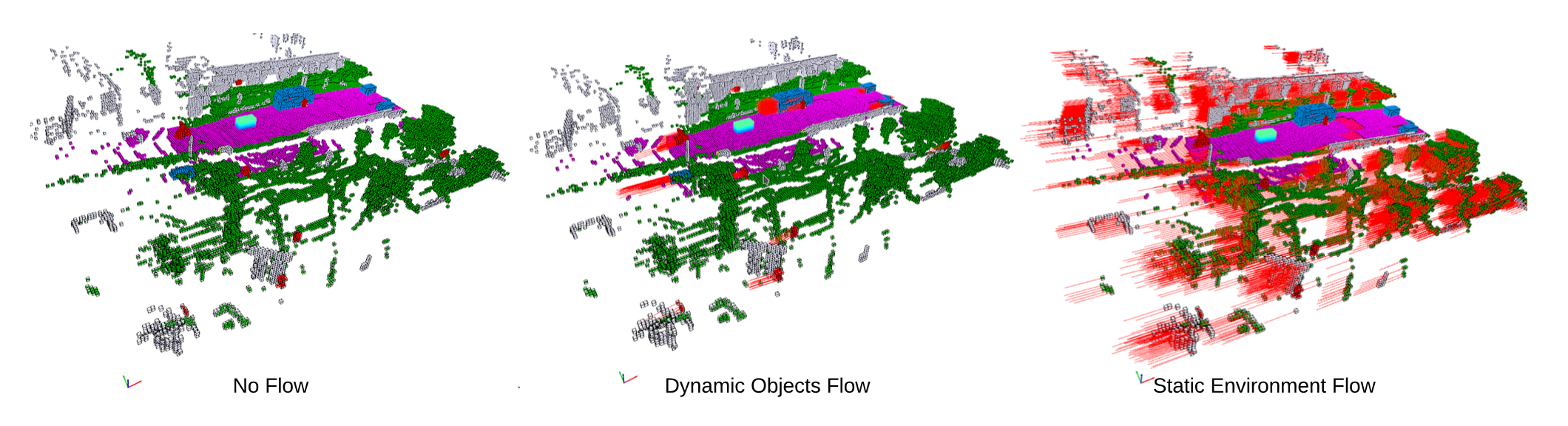
如图所示目标级和体素级流示意图(二维),表示一辆汽车右转。目标级流为所有体素分配相同的速度矢量,从而忽略汽车的旋转。
目标注释。还以字典列表的形式提供目标级注释,每个字典包含:(1) 智体到自车的转换。变换矩阵 T_a^e 将智体的局部坐标系映射到自车框架。这可以捕捉智体相对于自车的位置和方向。(2) 尺寸。一个 3D 向量 d,描述智体的边框尺寸(长、宽、高)。(3) 类别。目标的语义类别标签,定义见如下表:
任务类别
统一的输入支持广泛的以占用为中心的任务,涵盖静态预测和动态预测。通过在多个领域采用统一的表示,简化了跨数据集训练,并允许公平地比较解决不同子问题的方法。下面,概述三个代表性任务:
占用预测 。在此,模型使用过去 W_obs 个相机帧 {It−W_obs,...,t},以及它们的视场掩码 {Ut−W_obs,...,t} 和相机参数(内参 Int,外参 Ext)。输出是当前的 3D 占用网格 G^t,它捕获时间 t 的场景。
使用可选流进行占用预测 。在预测设置中,输入是 W_obs 个帧的历史数据------体素网格 {Gt−W_obs,...,t} 或相机图像 {It−W_obs,...,t}。该模型预测未来的占用 {Gt,...,t+W_fut},并可选择以细粒度的自车轨迹 T_e^w, t: t+W_fut^ 或高级驾驶意图(例如,右转)为条件。对于某些用例,预测方法还可以生成未来流 F^t: t+W_fut^ 或未来自车运动 T_e^w,t: t+W_fut。这种联合占用和流预测方案,有助于捕捉随时间推移的复杂运动模式。流场默认位于自车坐标系中,但可选择为旋转不变模型提供以智体为中心的流变型 44, 63。
基于可选流的协作占用预测和预报 。在协作设置下,多辆车联网车辆 (CAV) 通过共享图像或占用数据进行协作。从自车的角度来看,它接收共享的历史观测值 {I_CAVt−W_obs,...,t} 或 {G_CAV^t−W_obs,...,t},以及将 CAV 帧映射到自我帧的变换。输出保持不变(即单-自车占用或预测),但增加的视点覆盖范围可以减轻遮挡并提升整体场景理解。
统一数据集
从以下来源构建统一数据集:
• nuScenes 3 和 Waymo 35。这两个数据集都提供摄像头图像、激光雷达扫描数据和目标级标注。由于它们均未直接包含 3D 占用标签,通过三个伪标签流程------Occ3D 36、OpenOccupancy 43 和 SurroundOcc 48------来合成占用真值。这种多工具方法提高标签输出的鲁棒性和多样性。
• CARLA 5。使用 CARLA 的仿真引擎生成无限多样的虚拟驾驶场景,从中提取"完美"的 3D 占用标签(网格、目标状态等)。这些逼真且可控的场景已公开发布,可轻松进行大规模训练。该框架支持生成任意长度的数据。
• OpenCOOD 54。OpenCOOD 基于 CARLA 构建,提供多车协作场景。扩展其数据生成脚本,以便从模拟网格导出 3D 占用信息,从而通过协作驾驶示例扩展数据集。
统一占用处理工具包
大多数基于占用信息的方法仅专注于生成占用网格,但提供的下游处理或运动分析工具有限。为了弥补这一缺陷,其框架包含一个工具包,用于直接在体素空间内进行目标分割和跟踪,从而支持更高级的任务,例如形状分析或运动规划。
目标识别
给定一个占用网格 G ∈ {0, ..., C },按照以下步骤识别和分割相关目标,如图所示:

- 目标分割。按类别(例如,汽车、行人)提取体素,然后通过广度优先搜索实现 6 连通域标记 (CCL):
L = CCL(G), t ∈ {0,1,...,T}, (1)
其中 L ∈ {1,...,N} 为每个连通域分配一个唯一的目标 ID,N 为目标总数。
- 体素提取。对于每个目标 ID n,收集其体素坐标 V_n:
V_n = {< x,y,z > | L(x,y,z) = n}, (2)
-
横轴边框。体素预测可能不完整(如图所示),因此直接测量边框(长度、宽度、高度)并不可靠。因此,使用旋转卡尺法(rotating calipers) 38 在水平面上拟合一个边界矩形,其目标体素数量为 O(n^2),假设每个目标平行于地面运动。这将得到一个二维最小边界矩形,由此可以恢复航向和平面大小。
-
维度提取。将矩形的长和宽作为内部的平面尺寸,然后根据体素的垂直范围计算高度。所有尺寸均按体素分辨率 ε 缩放,转换为公制单位。
目标跟踪
利用体素预测的前向占用光流,还提供一种简单的基于占用光流的目标跟踪算法:
- 目标体素提取。对于第 t 帧占用网格中已识别的每个目标,检索其体素坐标 V_nt(2)和相应的光流矢量 F_n^t。
- 步长预测。通过添加流来估计下一帧体素位置 ~V_n^t+1:
~V_nt+1 = V_nt + F_n^t,(3)
- 质心提取。令 ~c_nt+1 为预测体素集 ~V_nt+1 的质心。还计算第 t + 1 帧的真实目标体素 V _nt+1 及其质心 c_n^t+1。
- 二分关联。使用匈牙利算法将预测质心 {~c_pt} 与观测质心 {c_q^t+1} 进行匹配,以最小化成对距离。
上述过程产生跨帧关联,可以统一随时间变化的目标身份,从而能够直接在体素空间中进行运动解释和分析。
目标对齐
最后,将追踪目标的体素集对齐,以便进行形状分析或一致性检查:
- 平移对齐。将每个目标的体素坐标平移至原点中心,即 V ̄_n^t。
- 旋转对齐。将主成分分析 (PCA) 应用于每帧的体素集,以解析出一个规范的方向。为了保持一致性,调整新主轴的符号,使其与前一帧的方向对齐。最终旋转后的体素坐标表示为 ˆV_n^t。通过这些步骤,可以在占用网格域内进行完全以目标为中心的分析(例如,测量形状变化或旋转一致性),而无需参考真值标签或注释。
统一评估指标
基准测试包含多个用于评估生成或预测占用网格质量的指标。
基于体素的评估
基于先前的占用预测 57 和预测 2, 42, 47, 61 研究,采用两个标准指标:几何 IoU(或简称为 IoU_geo)和 mIoU(跨语义类别的平均交并比)。具体来说,对于预测的占用网格 G_pred 和真实网格 G_gt,
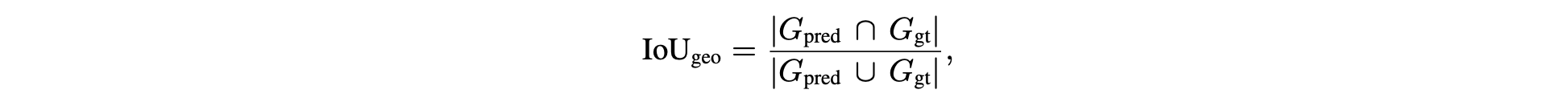
对于多类别占用(总共 C 个类别),mIoU 的计算方式如下:
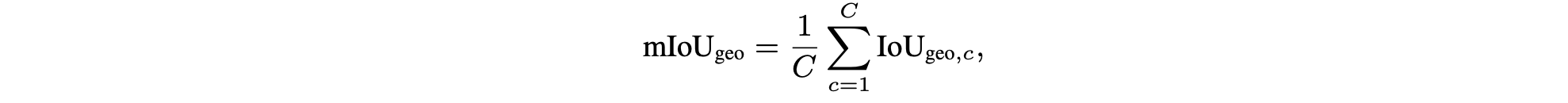
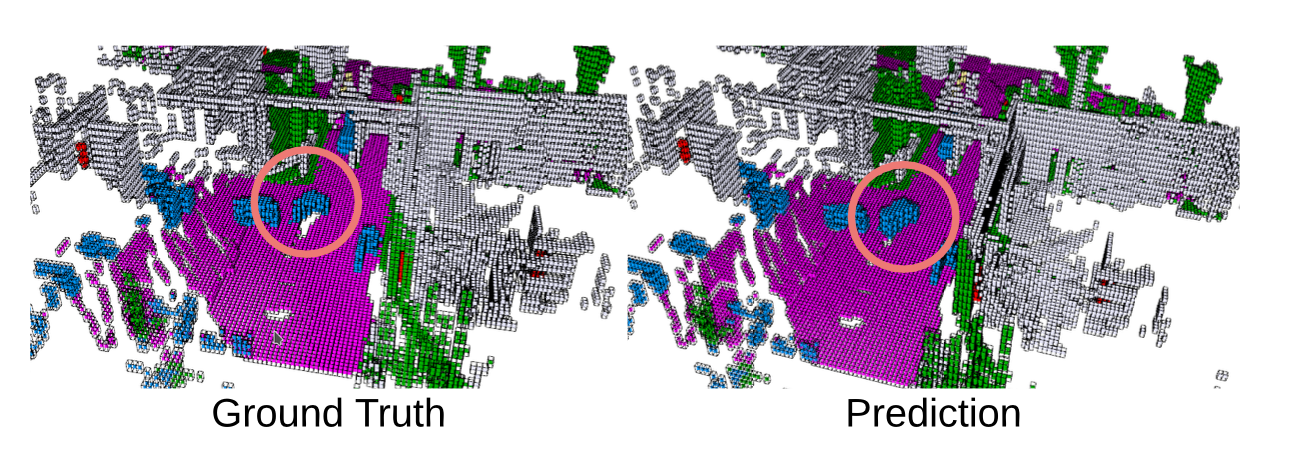
虽然这些基于体素的指标很简单,但它们可能会惩罚超过伪真实值的预测(如图所示)。此外,像多模态预测这样的任务,可能会产生许多单一参考标签无法捕捉的合理未来结果。出于这些原因,本文提出一些不需要完美真实值的评估策略。
无真值评估
除了依赖标签的 IoU 之外,其提出一些无需参考单一真值场景即可评估几何合理性的指标。这些指标对于多模态生成或真值标签不完整的情况尤其有用。
关键目标的维度概率。给定一个预测目标的边框 < l, w, h>,并将其归类为类别 c,通过计算高斯混合模型 (GMM) 的似然来评估其合理性。具体来说,每个类别 c 都有一个预训练的 GMM,记为 GMM_c,该模型是从统一数据集中的真实或合成数据中学习而来的。在推理时,使用目标的尺寸来查询 GMM_c。这个查询概率 P_n 可以启发式地判断该目标是否具有与其报告类别相符的实际尺寸。使用经验值 ρ = 0.5 作为阈值来确定该形状是否真实存在。
时域前景目标形状一致性。对于跨多帧预测的动态目标,通过随时间序列对齐每个目标的体素并计算体素交集而非并集来测量形状一致性 IoU_object。较高的 IoU_object 表示从 t 帧到 t + 1 帧的形状几何形状稳定。然后,在每个类别中计算这些 IoU 的平均值,以评估整体的随时间序列一致性。
时域背景环境一致性 。对于静态背景区域,预期在重叠视野内的连续帧之间持续占用。令 V_et 为时间 t 时的环境体素,~V_e^t+1 为它们在 t + 1 时的投影坐标(使用已知的自车运动)。舍弃超出边界的体素,并计算重叠部分的二值 IoU,即 IoU_bg。即使没有完美的真实标签,较高的 IoU_bg 也表明跨帧的静态背景一致。
总体而言,这些无真实值的指标补充标准 IoU,能够更深入地洞察场景真实性和时间连贯性,这对于生成性或多模态占用任务尤其有价值。