深度学习之LSTM时序预测:策略原理深度解析及可视化实现
1. 策略原理深度解析
核心逻辑 :
利用长短时记忆网络(LSTM)捕捉价格序列中的长期依赖关系,预测未来N日收益率。根据预测方向动态调整仓位:
- 预测收益率 > 阈值:加仓
- 预测收益率 < -阈值:减仓
- 其他情况:维持当前仓位
关键技术点:
- 数据标准化:使用滚动窗口标准化消除分布偏移
- 序列构造:滑动窗口生成三维输入数据(样本数×时间步长×特征数)
- 损失函数:Huber Loss平衡MAE和MSE优点
- 仓位管理:预测置信度控制头寸大小
2. 完整策略实现代码
步骤1:生成带趋势/季节性的模拟数据
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 生成含趋势+周期+噪声的序列
np.random.seed(42)
days = 2000
trend = np.linspace(100, 300, days)
seasonality = 20 * np.sin(np.linspace(0, 20*np.pi, days))
noise = np.random.normal(0, 8, days)
price = trend + seasonality + noise
data = pd.DataFrame({'Close': price},
index=pd.date_range('2015-01-01', periods=days)) 步骤2:特征工程与数据标准化
python
# 构建特征矩阵
data['Return'] = data['Close'].pct_change()
data['MA10'] = data['Close'].rolling(10).mean()
data['MA50'] = data['Close'].rolling(50).mean()
data['Volatility'] = data['Return'].rolling(20).std() * np.sqrt(252)
data.dropna(inplace=True)
# 滚动窗口标准化
def rolling_zscore(series, window):
means = series.rolling(window).mean()
stds = series.rolling(window).std()
return (series - means) / stds
features = ['Close', 'MA10', 'MA50', 'Volatility']
for col in features:
data[col] = rolling_zscore(data[col], window=60)
data.dropna(inplace=True)
# 构造时间窗口数据
lookback = 60 # 使用60天历史预测未来5天
forecast_horizon = 5
X, y = [], []
for i in range(lookback, len(data)-forecast_horizon):
X.append(data[features].values[i-lookback:i])
y.append(data['Return'].iloc[i:i+forecast_horizon].mean()) # 预测未来5日均值
X = np.array(X)
y = np.array(y) 步骤3:LSTM模型构建与训练
python
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.losses import Huber
# 划分训练/测试集
split = int(0.8 * len(X))
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
# 定义模型结构
model = Sequential([
LSTM(64, input_shape=(lookback, len(features)), return_sequences=True),
Dropout(0.3),
LSTM(32),
Dense(16, activation='relu'),
Dense(1)
])
# 编译模型
model.compile(optimizer=Adam(learning_rate=0.001),
loss=Huber(delta=1.0),
metrics=['mae'])
# 训练配置
history = model.fit(X_train, y_train,
epochs=100,
batch_size=64,
validation_split=0.2,
verbose=1) 3. 可视化代码与解析
可视化1:预测值与实际值对比
python
# 生成预测结果
train_pred = model.predict(X_train)
test_pred = model.predict(X_test)
plt.figure(figsize=(14,6))
# 训练集预测
plt.subplot(121)
plt.scatter(y_train, train_pred, alpha=0.3, color='#1f77b4')
plt.plot([min(y_train), max(y_train)], [min(y_train), max(y_train)], 'r--')
plt.title('Train Set: Actual vs Predicted', pad=15)
plt.xlabel('Actual Returns')
plt.ylabel('Predicted Returns')
# 测试集预测
plt.subplot(122)
plt.scatter(y_test, test_pred, alpha=0.3, color='#ff7f0e')
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], 'r--')
plt.title('Test Set: Actual vs Predicted', pad=15)
plt.tight_layout()
plt.show() 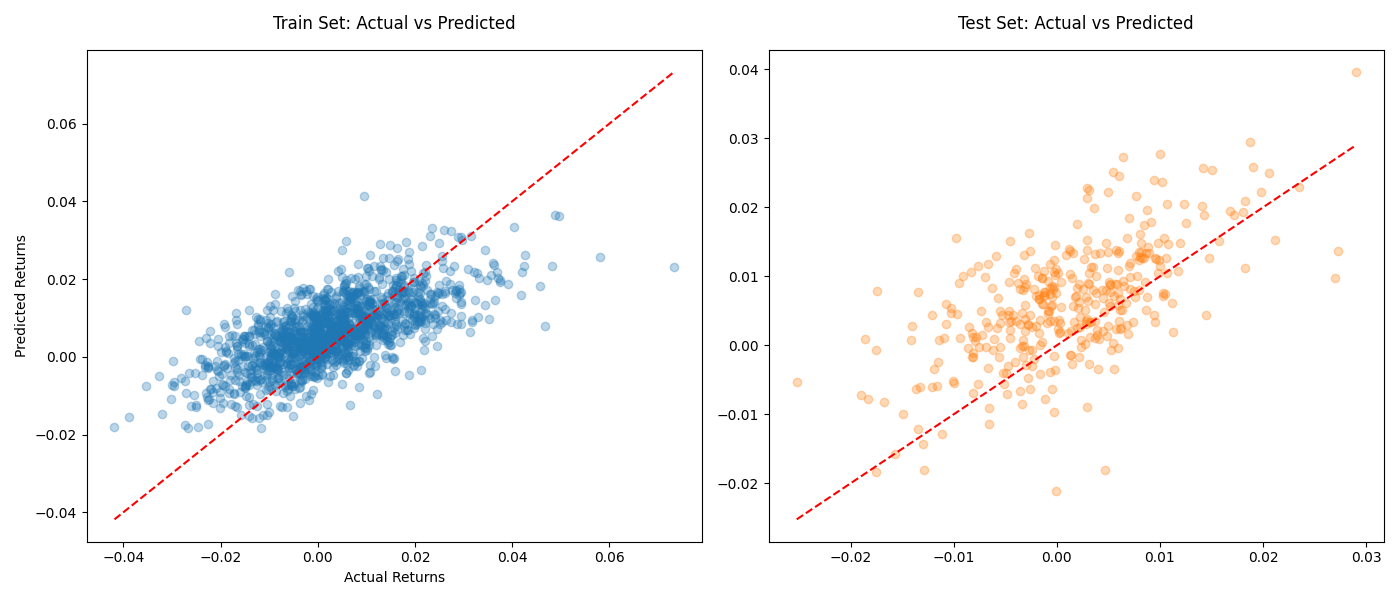
图表说明:
- 左图为训练集预测值与实际值散点分布
- 右图为测试集预测效果,红色虚线为理想拟合线
- 点越靠近对角线说明预测精度越高
可视化2:训练过程损失曲线
python
plt.figure(figsize=(10,5))
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Model Training Process', pad=15)
plt.xlabel('Epoch')
plt.ylabel('Huber Loss')
plt.legend()
plt.grid(alpha=0.3)
plt.yscale('log')
plt.show() 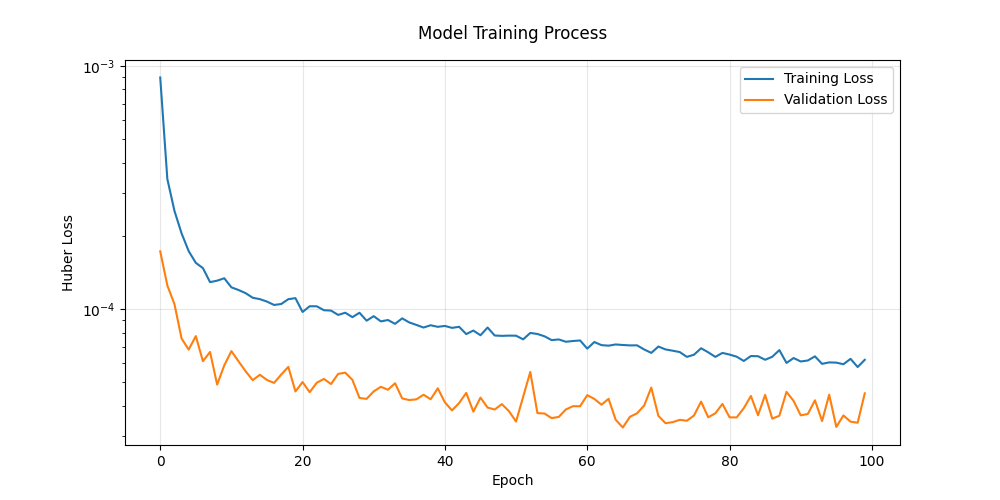
图表说明:
- 训练损失(蓝色)与验证损失(橙色)同步下降表明无过拟合
- 纵轴对数坐标更清晰展示损失变化细节
4. 策略回测实现
信号生成与仓位管理
python
# 获取全样本预测值
data = data.iloc[lookback:-forecast_horizon].copy()
data['Pred_Return'] = model.predict(X).flatten()
# 动态仓位计算
data['Position'] = np.tanh(data['Pred_Return'] * 10) # 缩放因子控制仓位幅度
# 计算策略收益
data['Strategy_Return'] = data['Position'].shift(1) * data['Return']
# 累计收益
data['Cumulative_Strategy'] = (1 + data['Strategy_Return']).cumprod()
data['Cumulative_BuyHold'] = (1 + data['Return']).cumprod() 可视化3:策略表现对比
python
plt.figure(figsize=(12,6))
# 净值曲线
plt.plot(data['Cumulative_BuyHold'], label='Buy & Hold', alpha=0.7)
plt.plot(data['Cumulative_Strategy'], label='LSTM Strategy', linewidth=2)
# 动态仓位背景
plt.fill_between(data.index, 0, data['Position'],
color='gray', alpha=0.2, label='Position Level')
# 图表装饰
plt.title('LSTM Strategy vs Benchmark', pad=15)
plt.xlabel('Date')
plt.ylabel('Cumulative Return')
plt.legend(loc='upper left')
plt.grid(alpha=0.3)
plt.yscale('log')
plt.tight_layout()
plt.show() 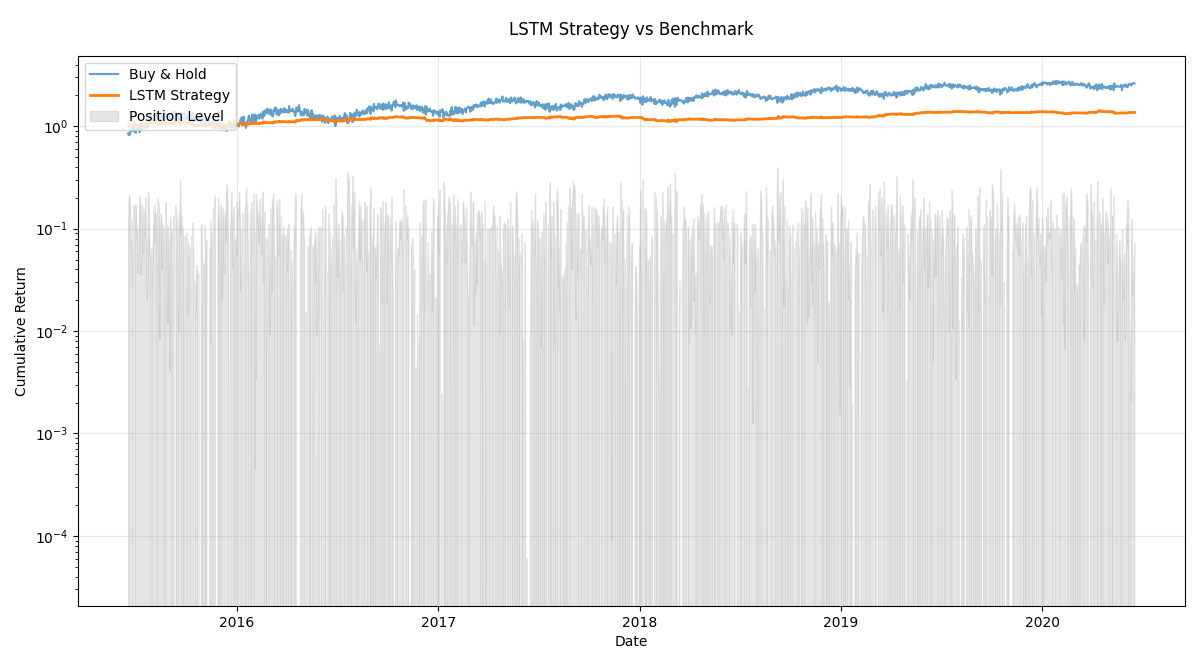
图表说明:
- 蓝色曲线为买入持有策略净值
- 橙色曲线为LSTM策略净值
- 灰色背景透明度表示仓位大小(0=空仓,1=满仓)
5. 关键风险控制
-
过拟合防范 :
pythonfrom tensorflow.keras.callbacks import EarlyStopping early_stop = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True) -
模型再训练 :
python# 每季度重新训练模型 if data.index[-1].month % 3 == 0: model.fit(new_X, new_y, epochs=50, batch_size=128) -
极端市场处理 :
python# 当波动率超过3倍中位数时强制平仓 data['Position'] = np.where(data['Volatility'] > 3*data['Volatility'].median(), 0, data['Position'])