论文来源:ICCV(2023)
项目地址:https://github.com/six6607/AGER.git
1.研究背景
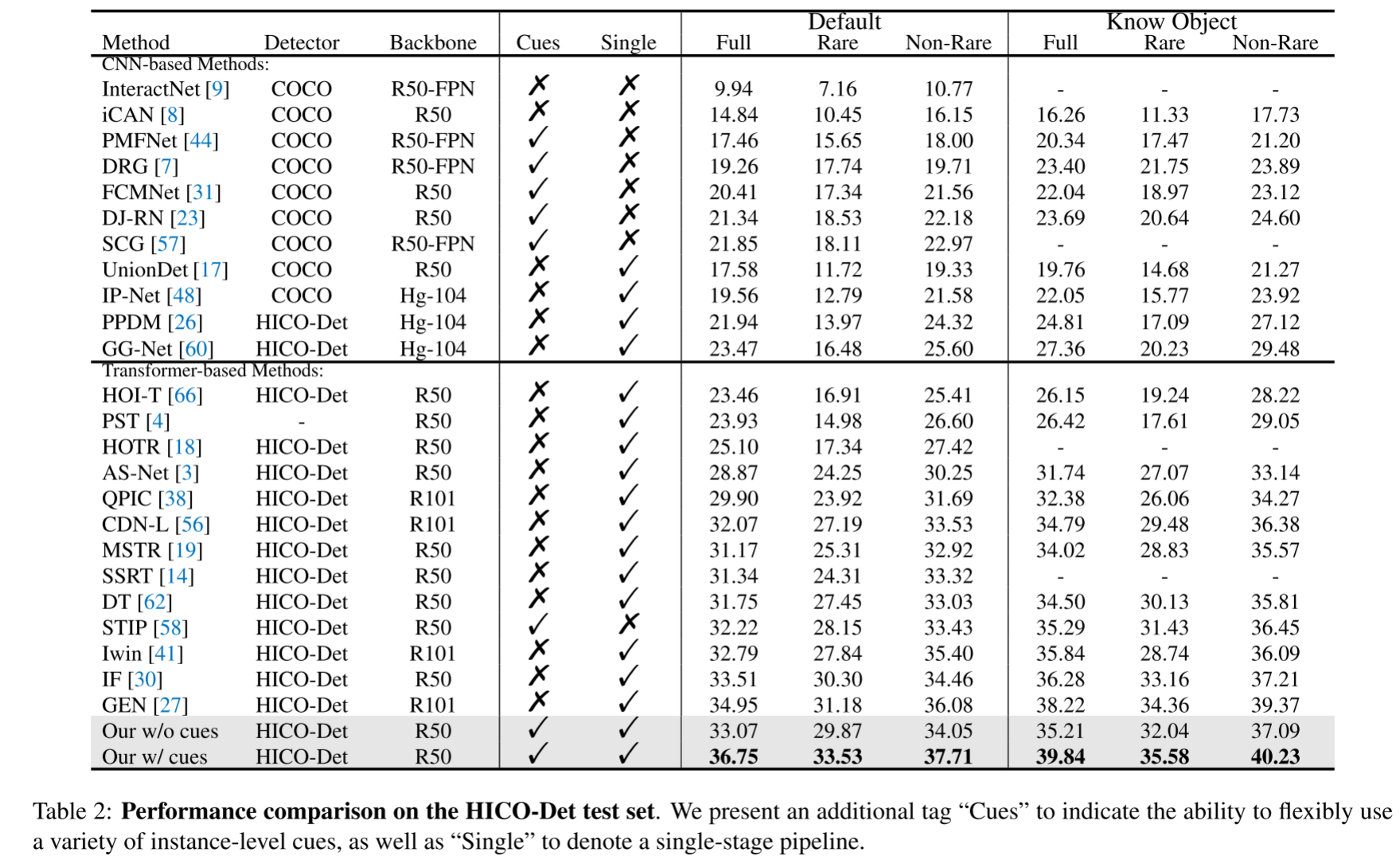
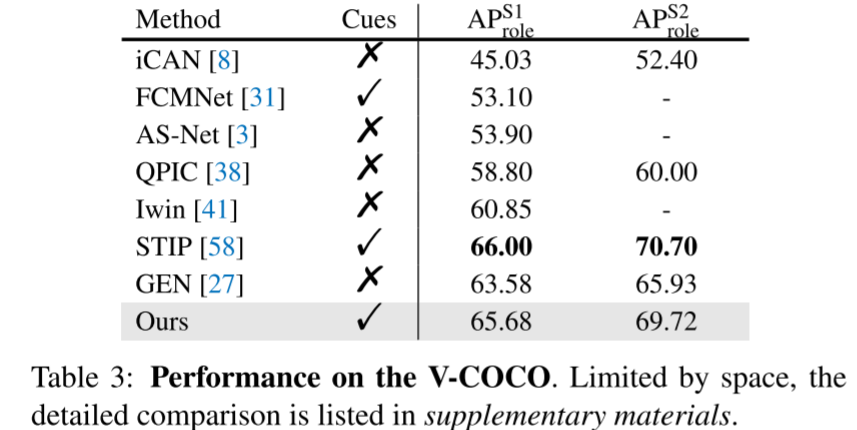
人机交互(HOI)检测 需要同时定位人与物体对并识别其交互关系,核心挑战在于区分相似交互的细微视觉差异 ,这依赖于实例级线索 (如人体姿势、注视方向、物体类别等)。传统方法采用两阶段框架 (如先使用目标检测器生成实例提案),效率低下且难以灵活提取多类型线索。基于 Transformer 的方法(如实例查询)存在任务偏差,仅关注部分特征区域,导致线索提取不完整。
2.主要创新点
2.1 动态聚类生成实例令牌(Instance Tokens)
提出聚合 Transformer(AGER) ,通过文本引导的动态聚类机制 将图像块令牌逐步聚合为实例令牌 ,确保每个令牌包含实例的完整判别特征区域(如图 1 所示),解决传统方法中实例查询仅关注局部区域的问题。
聚类过程与 Transformer 编码器结合,无需额外目标检测器或实例解码器,实现单阶段端到端学习。

2.2 多线索灵活提取与高效性
实例令牌的完整性支持通过轻量级 MLP 并行提取多种实例级线索(如人体姿势、空间位置、物体类别),避免传统方法中多阶段或定制化模型的复杂性。
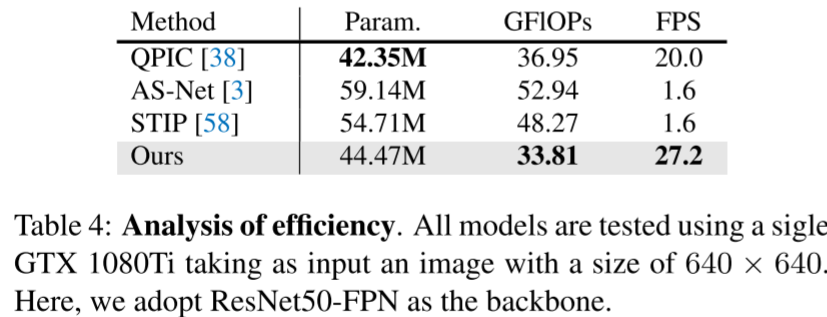
动态聚类减少冗余计算,相比基线方法(如 QPIC),GFLOPs 降低 8.5%,FPS 提升 36%,且图像分辨率越高,效率优势越明显。
2.3 文本引导的语义对齐
利用 CLIP 预训练模型生成文本表示,通过余弦相似性和分类概率引导实例令牌与真实实例语义对齐,增强表示的泛化性,避免任务偏差。
3.总体框架
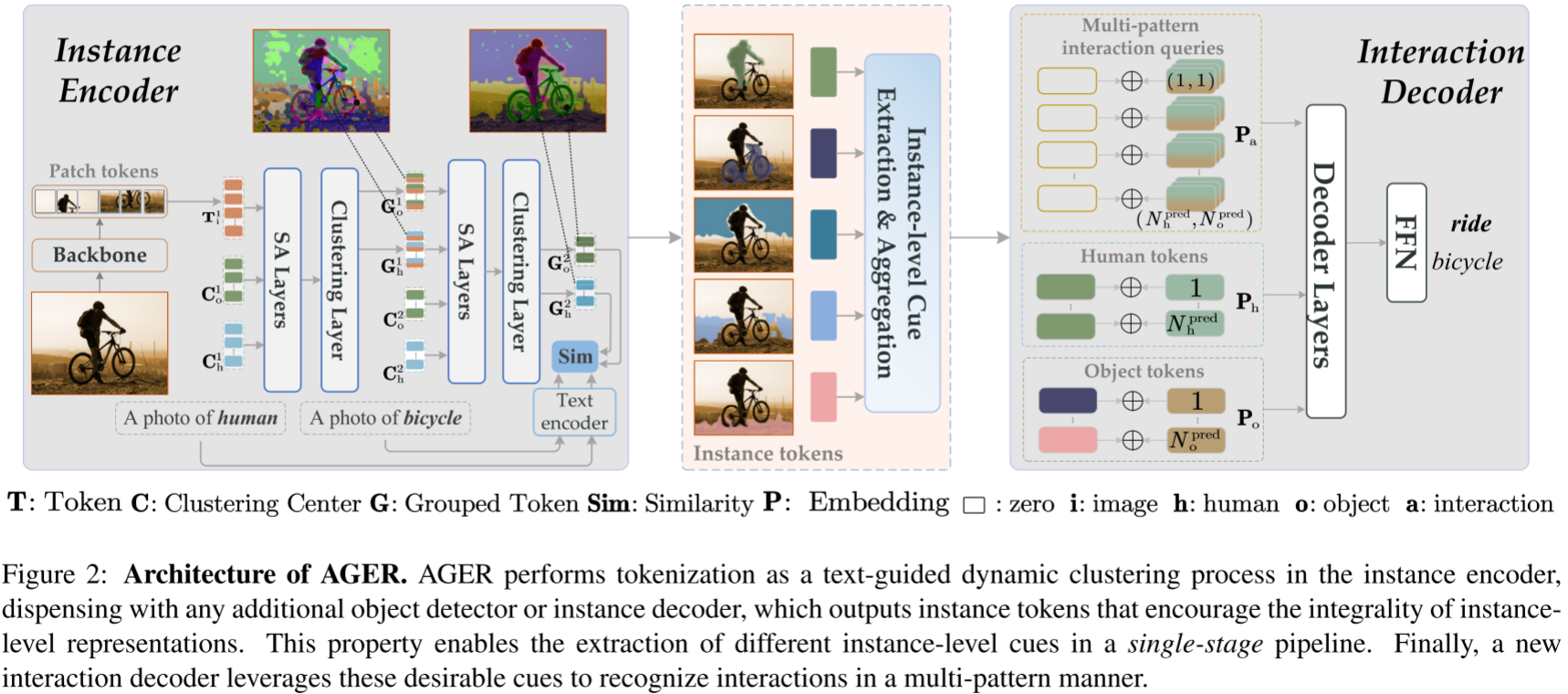
3.1 实例编码器(Instance Encoder)
分层 Transformer 结构:包含两个阶段,每个阶段由自注意力层和聚类层组成。
动态聚类机制:
初始化可学习的聚类中心(分为人类和物体),通过自注意力更新表示。
使用 Gumbel-Softmax 计算聚类中心与图像块的相似性,将语义相关的块聚合为更大的令牌,最终生成包含完整实例特征的令牌(如图 2 所示)。
文本引导通过 CLIP 文本编码器生成类别文本表示,与视觉令牌的余弦相似性损失优化聚类过程。
3.2 线索提取与聚合(Cues Extraction & Aggregation)
从实例令牌中提取三种线索:
人体姿势(P):5 层 MLP 预测 17 个关键点坐标。
空间位置(S):3 层 MLP 预测边界框。
物体类别(T):1 层 FFN 预测类别概率,结合 Word2Vec 文本嵌入。
聚合线索时通过置信度阈值(γ=0.7)过滤噪声,与实例令牌拼接后投影到统一特征空间。
3.3 交互解码器(Interaction Decoder)
采用 3 层 Transformer 解码器,枚举所有可能的人-物对,通过多模式位置嵌入处理同一对的多种交互标签。
交互查询结合人体与物体的位置嵌入,通过交叉注意力和自注意力识别交互类别。
4.损失函数
交互识别损失:焦点损失。
线索提取损失:L2 损失(姿势和位置回归)。
实例令牌生成损失:结合分类概率和文本 - 视觉余弦相似性,通过匈牙利算法匹配真实实例与生成令牌。
5.实验
5.1 计算要求
未提及
5.2 实验结果