Transformer实战(13)------从零开始训练GPT-2语言模型
0. 前言
在自然语言处理领域,GPT-2 作为 Transformer 架构的重要代表,展现了强大的文本生成能力。本节以 GPT-2 为例,介绍如何在自定义的文本数据集上预训练语言模型,并将其用于自然语言生成 (Natural Language Generation, NLG) 等任务。我们将以简·奥斯汀的经典小说《爱玛》作为训练语料,通过 Hugging Face 的 transformers 库,详细介绍从数据准备、分词器训练到模型训练和文本生成的全流程。
1. 语言模型训练
在本节中,我们将学习如何训练语言模型。我们将从 GPT-2 开始,深入了解如何使用 transformers 库进行训练。
1.1 数据准备
在本节中,我们使用简·奥斯汀的《爱玛》(Emma) 作为语料库来训练 GPT-2。也可以使用更大的语料库进行训练,以便生成更为通用的语言。
需要注意的是,所有 Hugging Face 模型都可以直接使用 TensorFlow 或 PyTorch 进行训练,在本节中,我们将使用 TensorFlow 的原生训练函数。
(1) 首先,下载《爱玛》的原始文本。
1.2 分词器训练
(1) 在用于训练 GPT-2 的语料库上训练 BytePairEncoding (BPE) 分词器。从 tokenizers 库中导入 BPE 分词器:
python
from tokenizers import ByteLevelBPETokenizer
import tensorflow as tf
import numpy as np
from tokenizers.models import BPE
from tokenizers import Tokenizer
from tokenizers.decoders import ByteLevel as ByteLevelDecoder
from tokenizers.normalizers import NFKC, Sequence, Lowercase
from tokenizers.pre_tokenizers import ByteLevel
from tokenizers.trainers import BpeTrainer(2) 通过增加更多功能(如 Lowercase() 标准化)来训练一个更先进的分词器:
python
tokenizer = Tokenizer(BPE())
tokenizer.normalizer = Sequence([
Lowercase()
])
tokenizer.pre_tokenizer = ByteLevel()
tokenizer.decoder = ByteLevelDecoder()以上代码通过 BPE 分词器类创建分词器对象,对于标准化部分,添加 Lowercase() 处理,并将 pre_tokenizer 属性设置为 ByteLevel,以确保输入为字节 (bytes)。同时,decoder 属性也必须设置为 ByteLevelDecoder,以便能够正确解码。
(3) 接下来,设置最大词汇量为 50000,并使用 ByteLevel 的初始字母表来训练分词器,同时,添加特殊词元:
python
trainer = BpeTrainer(vocab_size=50000, inital_alphabet=ByteLevel.alphabet(), special_tokens=[
"<s>",
"<pad>",
"</s>",
"<unk>",
"<mask>"
])
tokenizer.train(["austen-emma.txt"], trainer)(4) 在保存分词器时,需要先创建一个目录:
python
import os
os.mkdir('tokenizer_gpt')通过使用以下代码保存分词器:
python
tokenizer.save("tokenizer_gpt/tokenizer.json")1.3 数据预处理
分词器保存后,对语料库进行预处理,使用已保存的分词器为 GPT-2 训练做好准备。
(1) 首先,需要导入所需模块:
python
from transformers import GPT2TokenizerFast, GPT2Config, TFGPT2LMHeadModel(2) 使用 GPT2TokenizerFast 加载分词器:
python
tokenizer_gpt = GPT2TokenizerFast.from_pretrained("tokenizer_gpt")(3) 添加特殊词元和其对应的标记:
python
tokenizer_gpt.add_special_tokens({
"eos_token": "</s>",
"bos_token": "<s>",
"unk_token": "<unk>",
"pad_token": "<pad>",
"mask_token": "<mask>"
})(4) 通过运行以下代码检查分词器是否正确:
python
tokenizer_gpt.eos_token_id
# 2可以看到,输出句子结束 (EOS) 词元的标识符 (ID),当前分词器的 EOS 词元 ID 是 2。
(5) 通过执行以下代码测试分词器:
python
tokenizer_gpt.encode("<s> this is </s>")
# [0, 265, 157, 56, 2]在输出中,0 表示句子的开始,265、157 和 56 与句子本身相关,而 EOS 词元 ID 为 2,表示 </s>。
1.4 模型训练
(1) 创建配置对象 config,并初始化 GPT-2 的 TensorFlow 版本:
python
config = GPT2Config(
vocab_size=tokenizer_gpt.vocab_size,
bos_token_id=tokenizer_gpt.bos_token_id,
eos_token_id=tokenizer_gpt.eos_token_id
)
model = TFGPT2LMHeadModel(config)(2) 运行配置对象后,可以看到以字典格式显示的配置:
python
config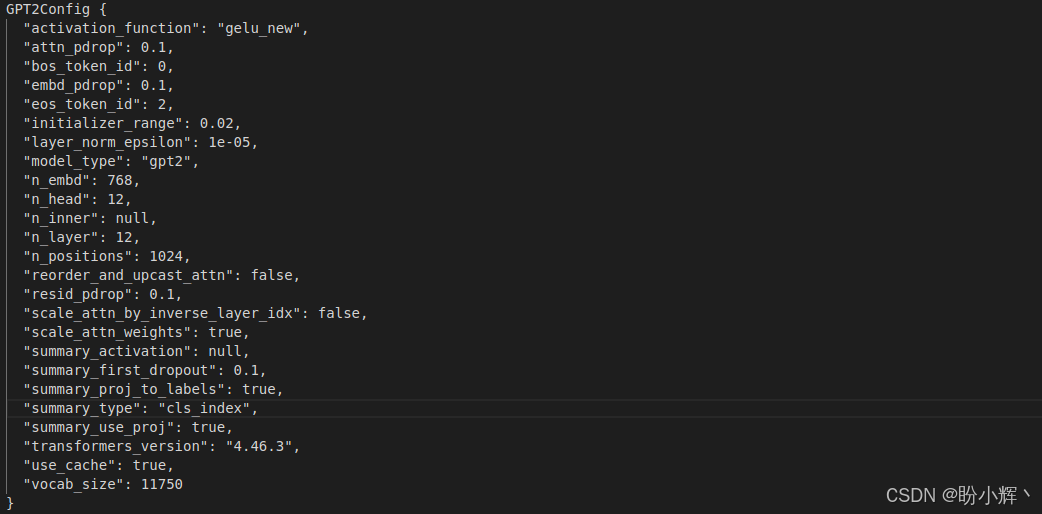
可以看到,其他设置保持不变,关键在于 vocab_size 值为 11750。原因是我们将最大词汇量设置为 50000,但语料库中的词汇较少,字节对编码 (Byte Pair Encoding, BPE) 分词生成了 11750 个词元。
(3) 准备语料库进行预训练:
python
with open("austen-emma.txt", "r", encoding='utf-8') as f:
content = f.readlines()(4) content 包含从原始文件中提取的所有文本,需要去掉每行的 \n 字符,并且删除少于 10 个字符的行:
python
content_p = []
for c in content:
if len(c)>10:
content_p.append(c.strip())
content_p = " ".join(content_p)+tokenizer_gpt.eos_token删除较短的行可以确保模型能够在较长的序列上进行训练,以便生成更长的序列。最终 content_p 包含了连接后的原始文件,并且在末尾添加了 eos_token。也可以采用不同的策略,例如,在每一行的末尾添加 </s>,这将帮助模型识别句子何时结束。但本节的目标是使模型能够处理更长的序列,而不遇到 EOS:
python
tokenized_content = tokenizer_gpt.encode(content_p)GPT 分词器将对整个文本进行分词,并将其转换为一个完整的长序列词元 ID。
(5) 为模型训练创建样本,将每个样本的大小设置为 100,从给定文本的某一部分开始,到 100 个词元后结束:
python
examples = []
block_size = 100
BATCH_SIZE = 12
BUFFER_SIZE = 1000
for i in range(0, len(tokenized_content)):
examples.append(tokenized_content[i:i + block_size])(6) 在 train_data 中,每个样本的序列大小为 99,从序列的起始位置到第 99 个 token,而 labels 是包含从第 1 个 token 到第 100 个 token 的序列:
python
train_data = []
labels = []
for example in examples:
train_data.append(example[:-1])
labels.append(example[1:])(7) 为了加速训练,需要将数据转换为 TensorFlow 数据集的形式:
python
dataset = tf.data.Dataset.from_tensor_slices((train_data[:1000], labels[:1000]))
dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)buffer 是用于数据打乱的缓冲区大小,batch_size 是训练的批大小,drop_remainder=True 表示在剩余样本小于 16 (即批大小)时将这些样本丢弃。
(8) 指定优化器、损失函数和度量标准,编译模型:
python
optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08, clipnorm=1.0)
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metric = tf.keras.metrics.SparseCategoricalAccuracy('accuracy')
model.compile(optimizer=optimizer, loss=[loss, *[None] * model.config.n_layer], metrics=[metric])(9) 模型编译后进行训练,训练的 epoch 数根据需要设置:
python
num_epoch = 10
history = model.fit(dataset, epochs=num_epoch)我们已经学习了如何训练自然语言生成 (Natural Language Generation, NLG) 模型,在下一节中,我们将介绍如何利用 NLG 模型进行语言生成。
2. 自然语言生成
我们已经学习了如何在自定义的语料库上训练自回归 (Autoregressive, AR) 模型 GPT-2,在本节中,我们将介绍如何使用训练完成的 GPT-2 模型进行语言生成。
(1) 首先,使用训练后的模型生成句子:
python
def generate(start, model):
input_token_ids = tokenizer_gpt.encode(start, return_tensors='tf')
output = model.generate(
input_token_ids,
max_length = 500,
num_beams = 5,
temperature = 0.7,
no_repeat_ngram_size=2,
num_return_sequences=1
)
return tokenizer_gpt.decode(output[0])generate 函数接受一个起始字符串,并根据该字符串生成后续序列,我们可以使用其他参数观察效果,比如将 max_length 设置为更小的序列大小,或者将 num_return_sequences 设置为生成不同的序列。
(2) 使用一个空字符串作为起始字符串进行生成:
python
generate(" ", model)输出结果如下所示:

从以上输出看到的,尽管文本的语义可能并不完美,但多数情况下,语法是正确的,生成了较长的文本。
(3) 尝试使用不同的起始字符串,其中 weston 是小说中的一个角色,将 max_length 设置为较小的值:
python
def generate(start, model):
input_token_ids = tokenizer_gpt.encode(start, return_tensors='tf')
output = model.generate(
input_token_ids,
max_length = 30,
num_beams = 5,
temperature = 0.7,
no_repeat_ngram_size=2,
num_return_sequences=1
)
return tokenizer_gpt.decode(output[0])
generate("wetson was very good", model)
# "wetson was very good the of her. the was a, and a of miss taylor; and had, but of a had been a friend3. 模型的保存与加载
(1) 可以使用以下代码保存模型,以便在不同应用中使用:
python
os.mkdir('my_gpt-2')
model.save_pretrained("my_gpt-2/")(2) 通过加载模型,验证模型是否正确保存:
python
model_reloaded = TFGPT2LMHeadModel.from_pretrained("my_gpt-2/")本地文件夹中保存了两个文件,一个配置文件和一个 model.h5 文件,后者是用于 TensorFlow 的文件。
(3) Hugging Face 还规定了文件名标准,标准文件名可以通过以下方式导入:
python
from transformers import WEIGHTS_NAME, CONFIG_NAME, TF2_WEIGHTS_NAME, AutoModel, AutoTokenizer但在使用 save_pretrained 函数时,并不需要指定文件名------只需提供目录即可。
(4) Hugging Face 还提供了 AutoModel 和 AutoTokenizer 类用于加载模型,但需要手动完成一些配置。首先是将分词器保存为 AutoTokenizer 可以使用的正确格式,可以使用 save_pretrained 来完成:
python
tokenizer_gpt.save_pretrained("tokenizer_gpt_auto/")输出结果如下所示:
shell
('tokenizer_gpt_auto/tokenizer_config.json',
'tokenizer_gpt_auto/special_tokens_map.json',
'tokenizer_gpt_auto/vocab.json',
'tokenizer_gpt_auto/merges.txt',
'tokenizer_gpt_auto/added_tokens.json',
'tokenizer_gpt_auto/tokenizer.json')在指定目录中显示了文件列表,但 tokenizer_config 必须手动修改才能使用。首先,需要将其重命名为 config.json,其次,需要在 JSON (JavaScript Object Notation) 格式中添加一个属性,表明 model_type 属性为 gpt2:
shell
{"model_type":"gpt2",
...
}(5) 准备就绪后,可以使用以下代码加载模型和分词器:
python
model = AutoModel.from_pretrained("my_gpt-2/", from_tf = True)
tokenizer = AutoTokenizer.from_pretrained("tokenizer_gpt_auto")在本节中,我们学习了如何使用 TensorFlow 和 transformers 完成预训练并保存自定义文本生成模型,并了解了如何训练 AR 模型。
小结
在本节中,我们在自定义语料库上训练了 GPT-2,并将其用于文本生成,学习了如何保存模型并使用 AutoModel 加载模型。还深入了解了如何使用 tokenizers 库训练和使用字节对编码 (Byte Pair Encoding, BPE)。
系列链接
Transformer实战(1)------词嵌入技术详解
Transformer实战(2)------循环神经网络详解
Transformer实战(3)------从词袋模型到Transformer:NLP技术演进
Transformer实战(4)------从零开始构建Transformer
Transformer实战(5)------Hugging Face环境配置与应用详解
Transformer实战(6)------Transformer模型性能评估
Transformer实战(7)------datasets库核心功能解析
Transformer实战(8)------BERT模型详解与实现
Transformer实战(9)------Transformer分词算法详解
Transformer实战(10)------生成式语言模型 (Generative Language Model, GLM)
Transformer实战(11)------从零开始构建GPT模型
Transformer实战(12)------基于Transformer的文本到文本模型
Transformer实战(14)------微调Transformer语言模型用于文本分类
Transformer实战(15)------使用PyTorch微调Transformer语言模型