✨作者主页 :IT研究室✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
文章目录
一、前言
系统介绍:
基于大数据的国家药品采集药品数据可视化分析系统是一个综合性的药品集中采购数据处理与分析平台,该系统采用Hadoop+Spark大数据框架作为核心数据处理引擎,结合HDFS分布式存储技术实现海量药品采购数据的高效存储与计算。系统后端采用Django/Spring Boot框架支持,前端基于Vue+ElementUI构建用户交互界面,集成Echarts图表库实现数据的多维度可视化展示。通过Spark SQL和Pandas、NumPy等数据处理工具,系统能够对国家药品集采数据进行深度挖掘和分析,提供竞争分析、价格趋势分析、供应链分析、特殊药品分类统计等核心功能模块。系统支持Python/Java语言开发环境,采用MySQL作为关系型数据库存储结构化数据,通过大数据可视化大屏实时展示药品采购市场动态,为医疗机构、药企和监管部门提供科学的决策支持工具,有效提升药品采购透明度和市场监管效率。
选题背景:
国家药品集中采购制度作为医疗卫生体制改革的重要组成部分,旨在通过集中议价降低药品价格,减轻患者医疗负担。随着集采政策的深入实施,药品采购数据呈现爆发式增长态势,涉及药品种类、价格波动、供应商竞争、地区分布等多维度信息。传统的数据处理方式难以应对如此庞大且复杂的数据体量,亟需借助大数据技术进行有效整合和分析。当前药品集采数据分析主要依赖人工统计和简单的表格处理,缺乏系统性的数据挖掘和可视化展示手段,导致决策者难以从海量数据中快速获取有价值的洞察信息。药品市场的复杂性和多变性要求建立一套智能化的数据分析系统,以便更好地监控市场动态、识别价格趋势、评估供应风险,为相关部门制定更加科学合理的采购策略提供数据支撑。
选题意义:
本系统的建设能够为药品集采数据的规范化管理和深度应用提供技术支撑,通过大数据分析技术帮助相关部门更准确地把握药品市场变化规律。对于医疗机构而言,系统提供的价格分析和供应预测功能有助于优化采购决策,合理控制医疗成本;对于药品生产企业,竞争分析和市场趋势展示功能能够辅助其调整经营策略,提升市场竞争力。从监管角度看,系统的可视化分析能力有助于监管部门及时发现市场异常波动,加强对药品流通环节的监督管理。虽然作为毕业设计项目,系统规模和功能相对有限,但其探索性尝试为药品集采数据的数字化处理提供了一种可行的技术路径。通过将理论知识与实际应用相结合,不仅锻炼了大数据技术的实践应用能力,也为后续相关领域的深入研究奠定了基础,具有一定的学习价值和参考意义。
二、开发环境
- 大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
- 开发语言:Python+Java(两个版本都支持)
- 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
- 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
- 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
- 数据库:MySQL
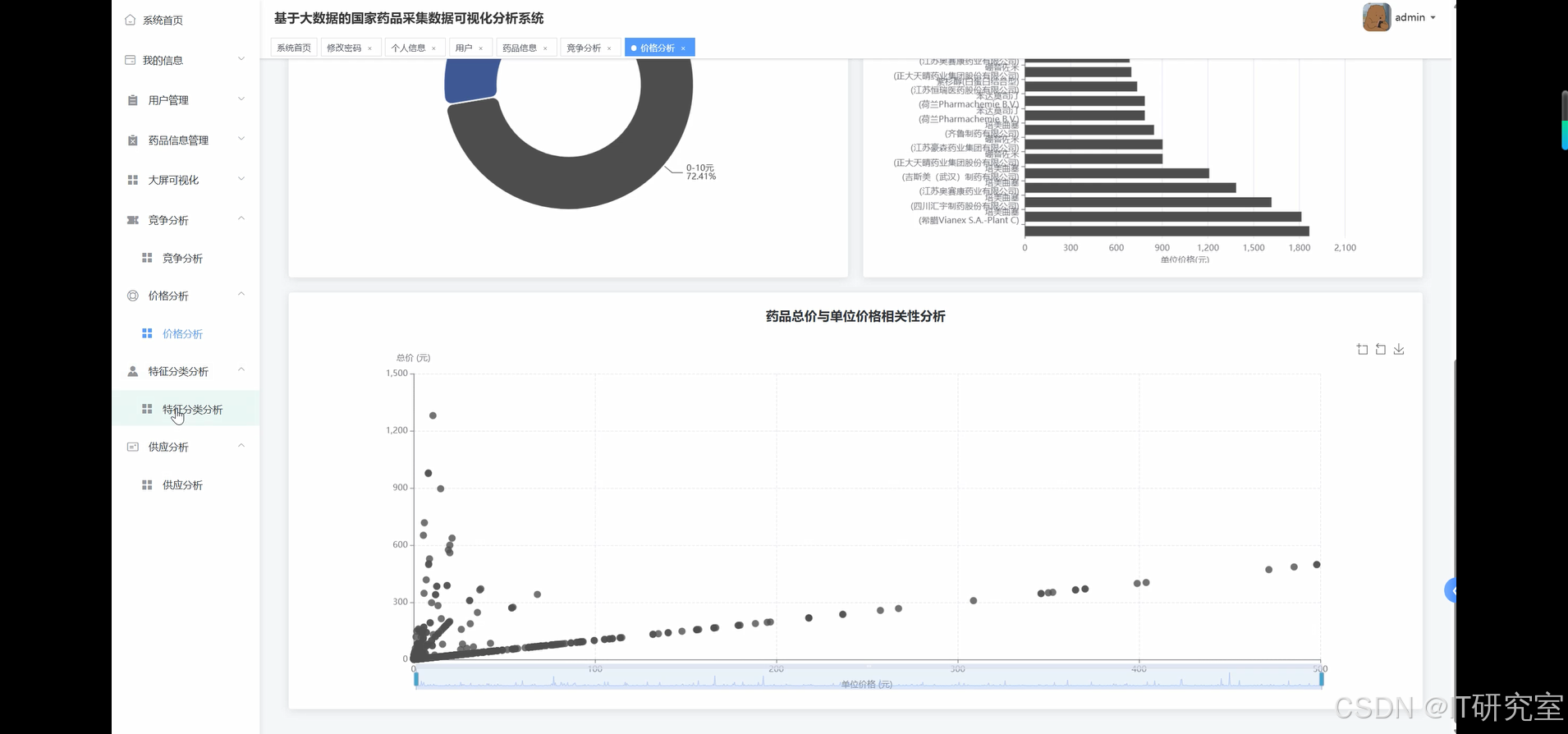
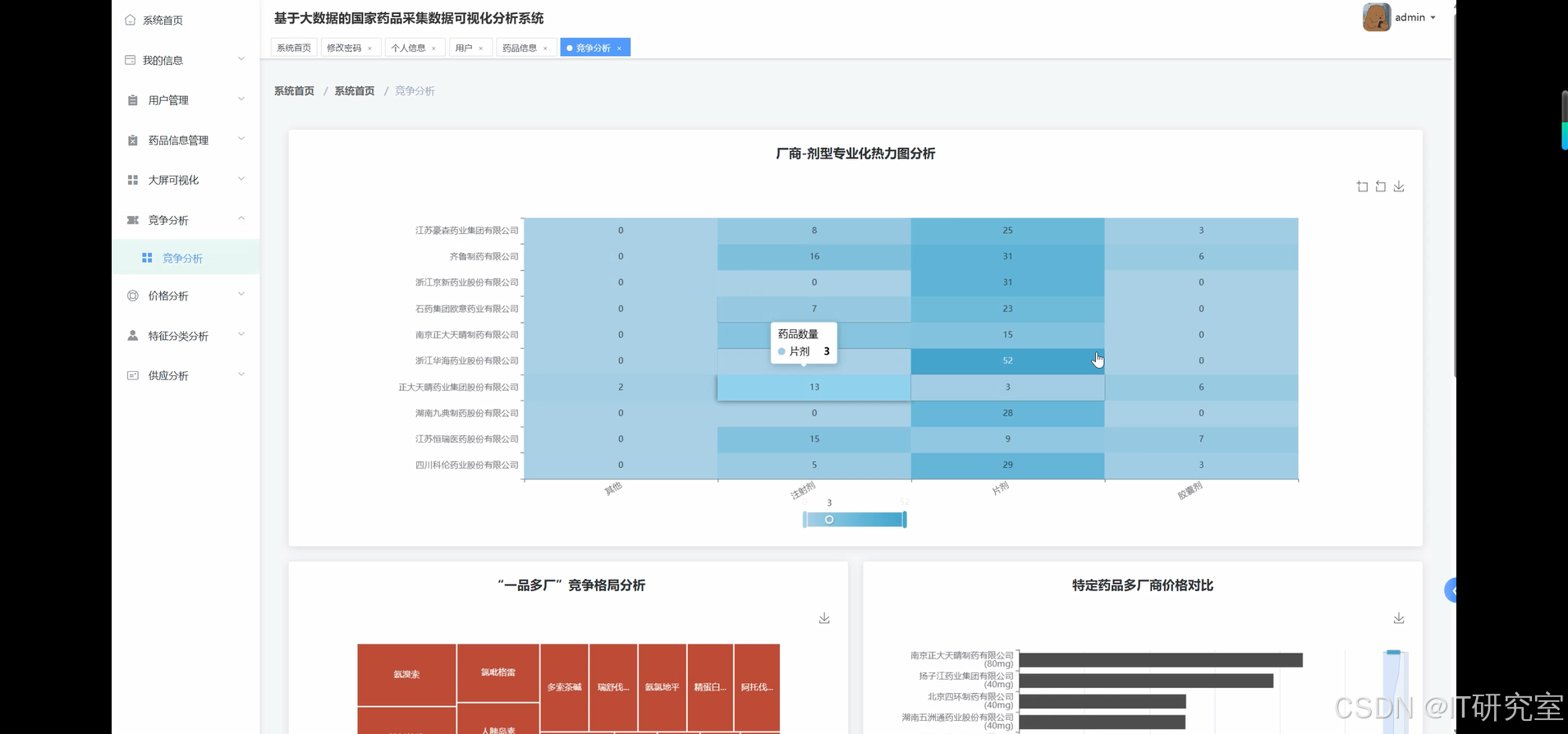
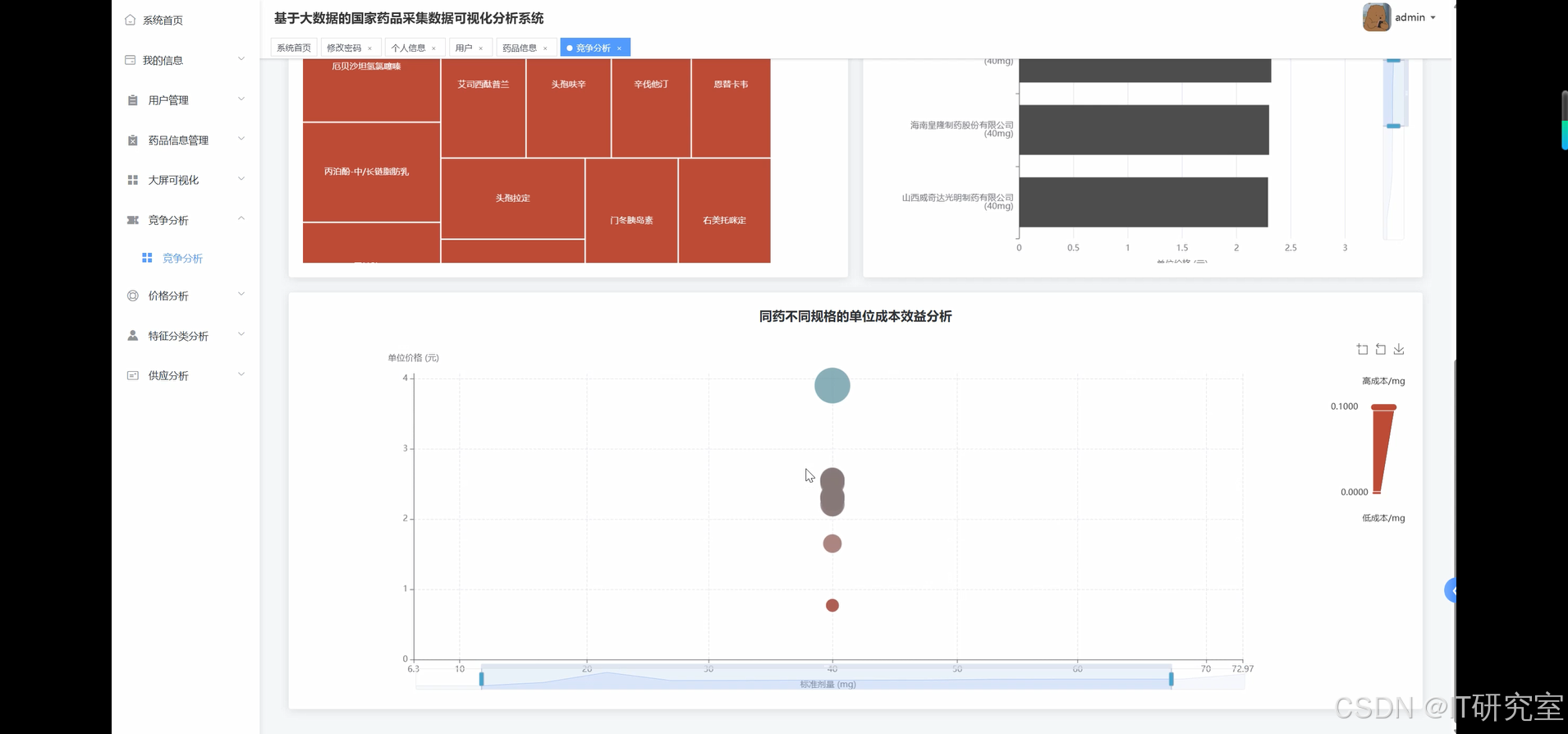
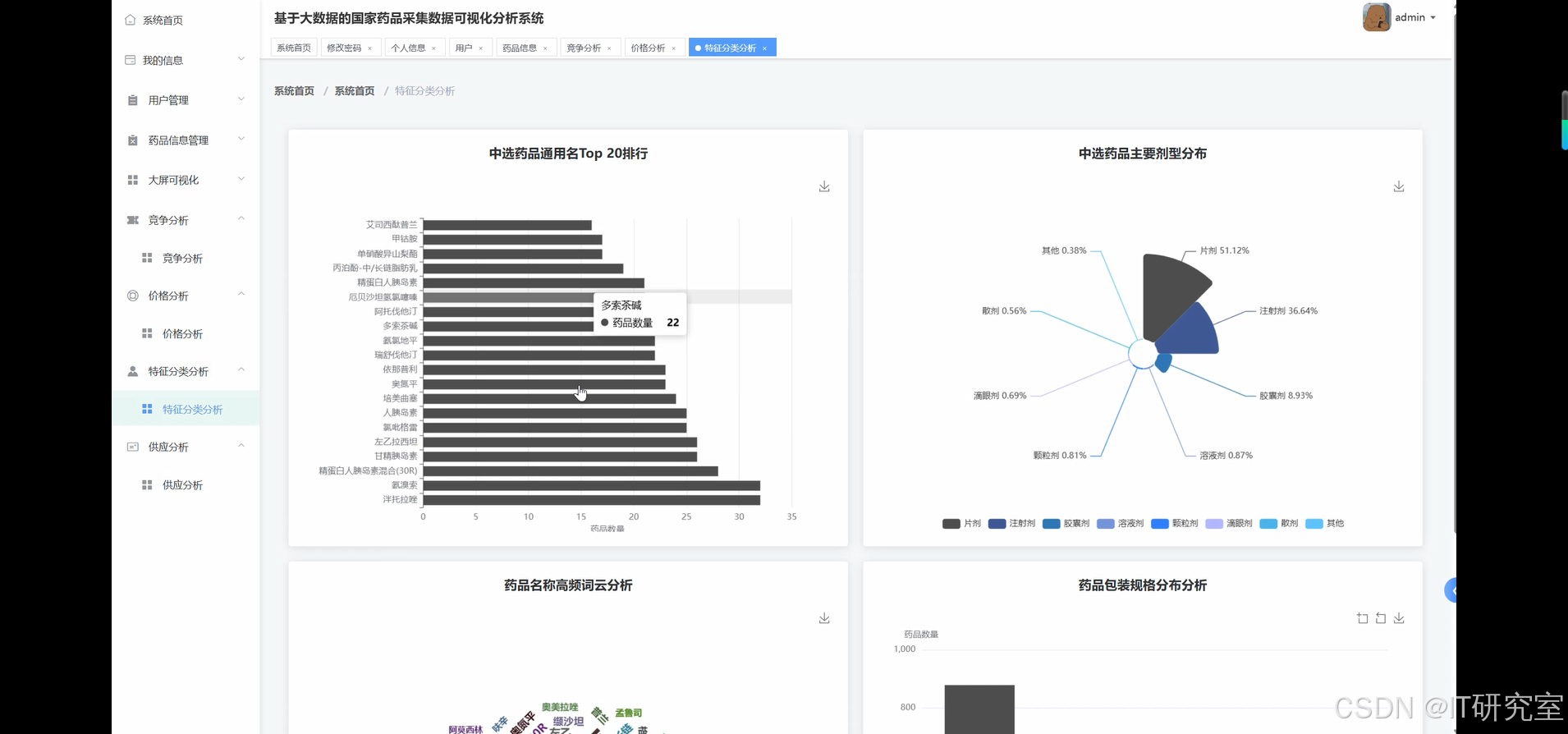
三、系统界面展示
- 基于大数据的国家药品采集药品数据可视化分析系统界面展示:
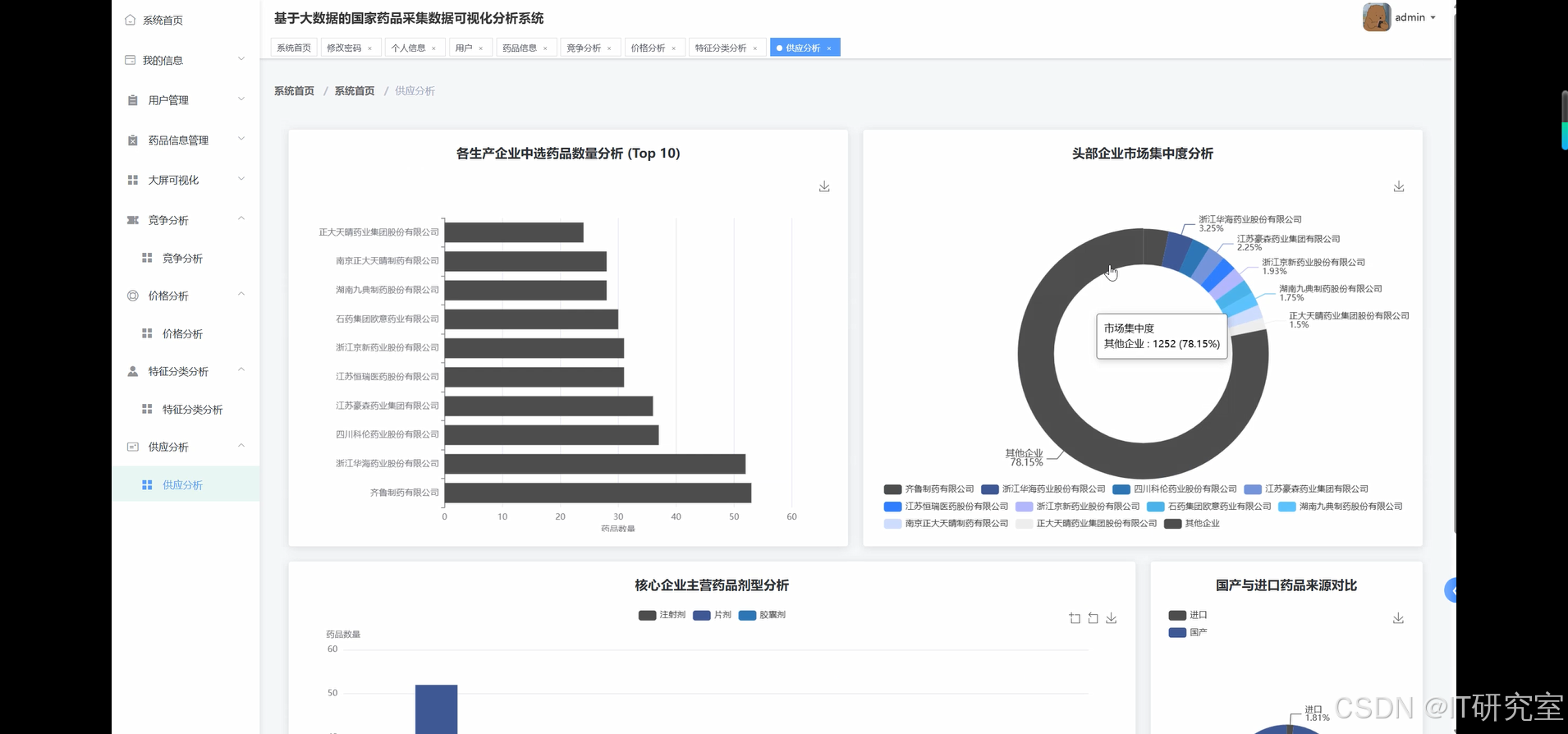
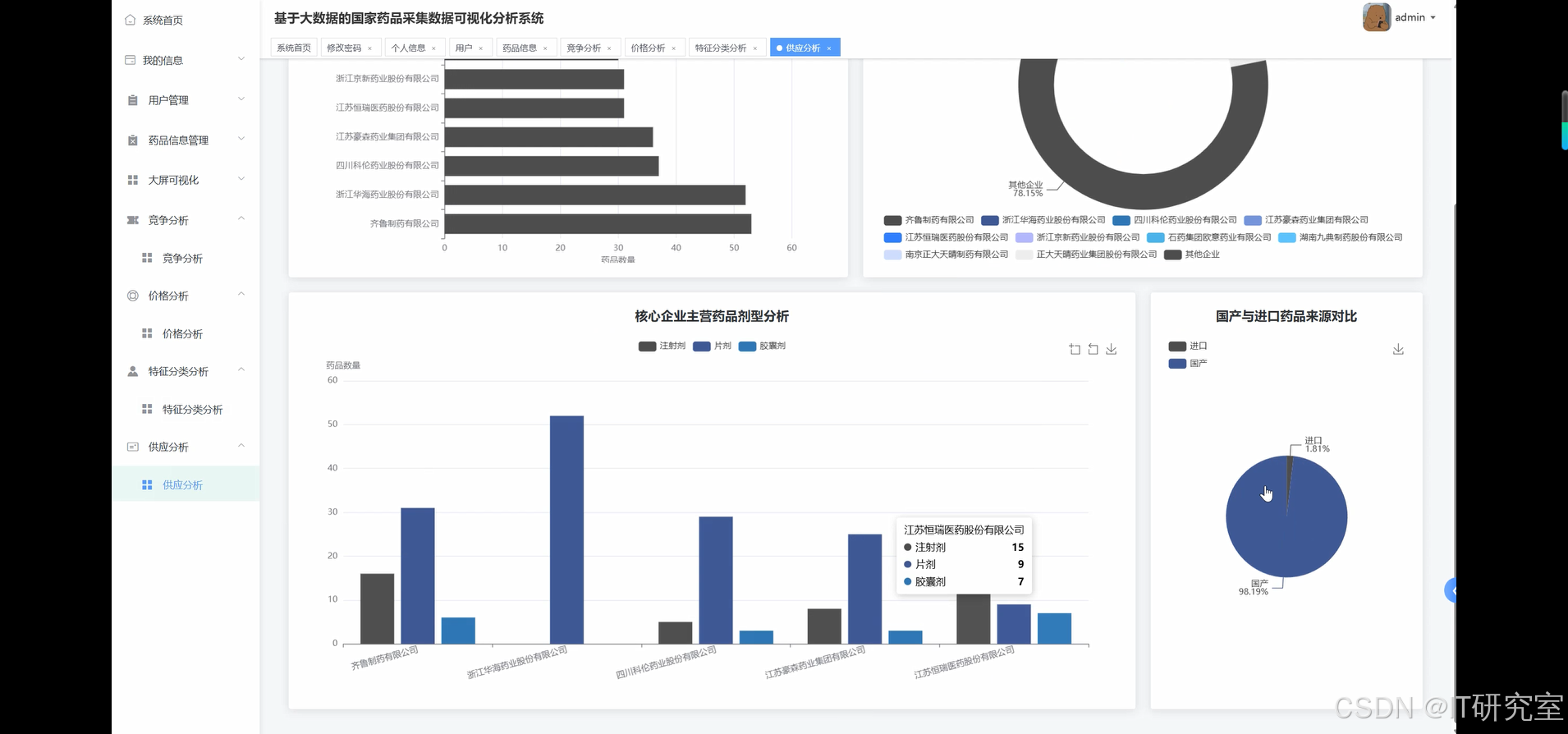
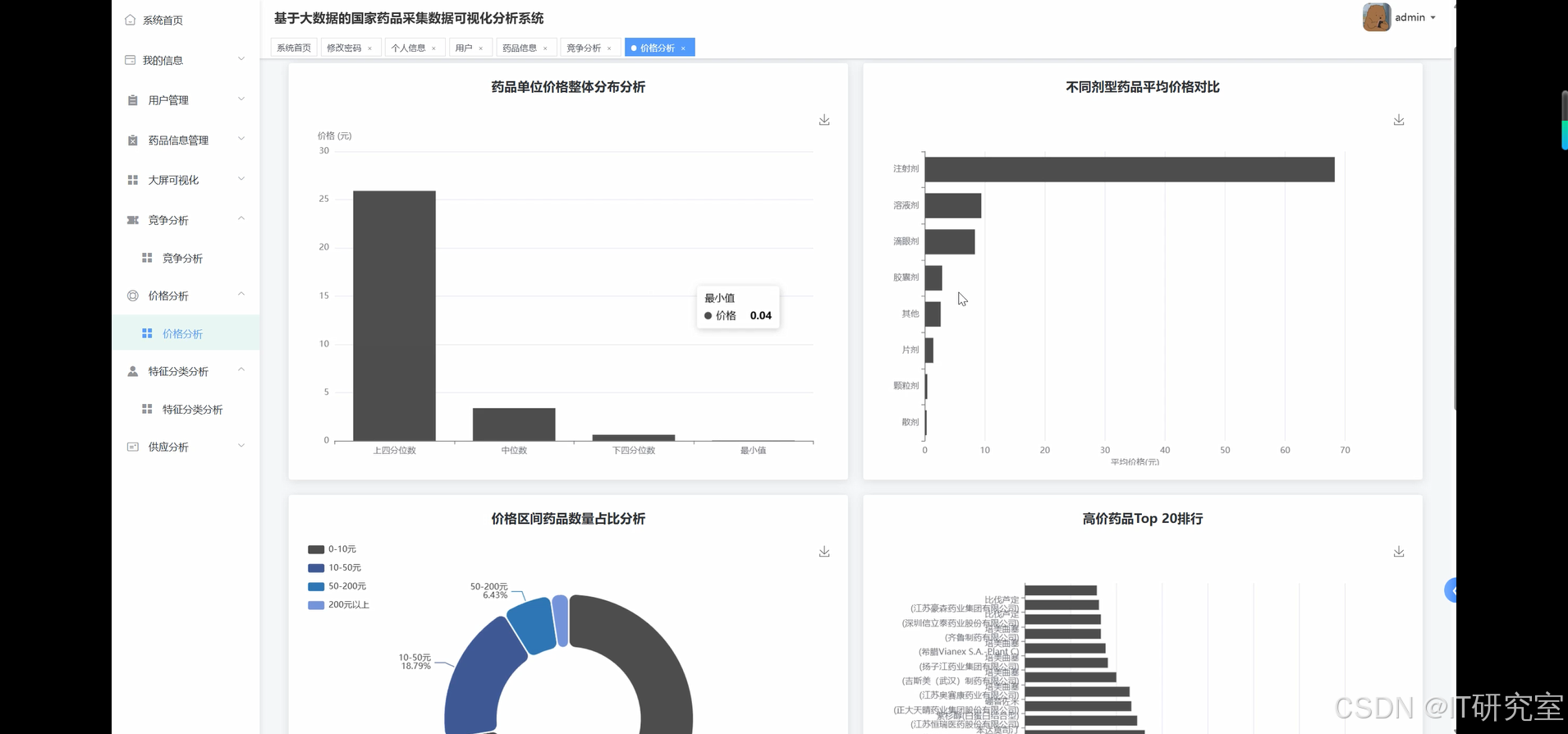
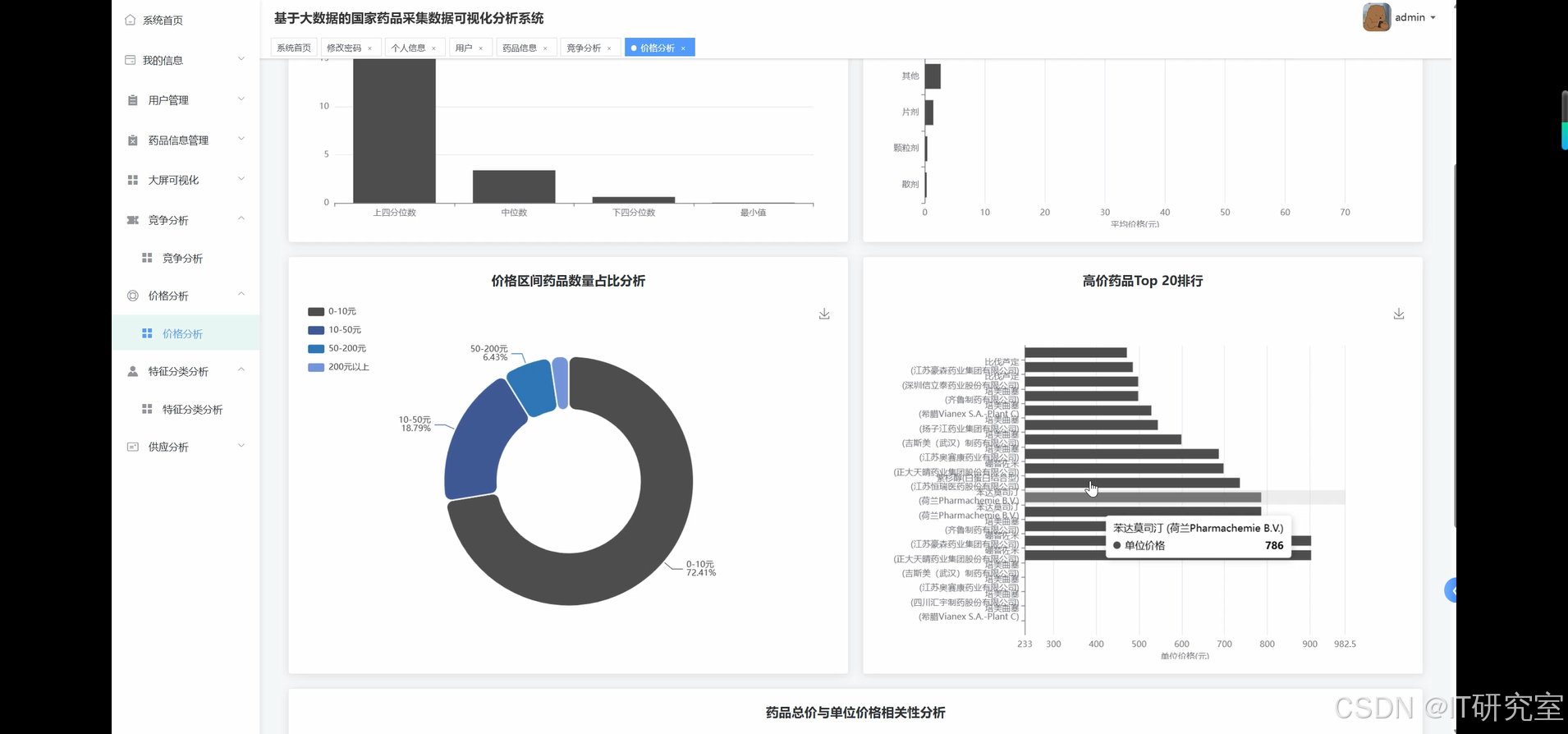
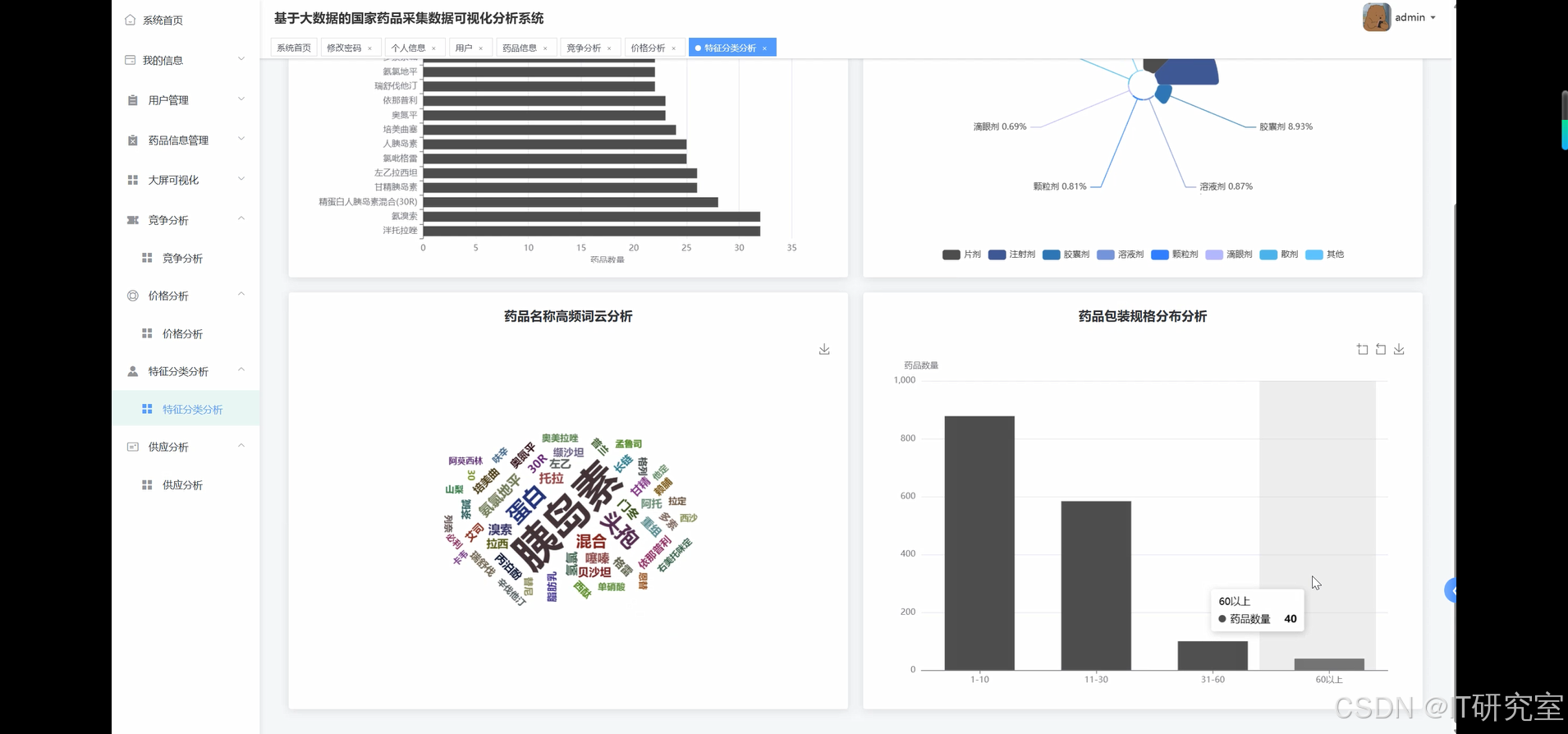
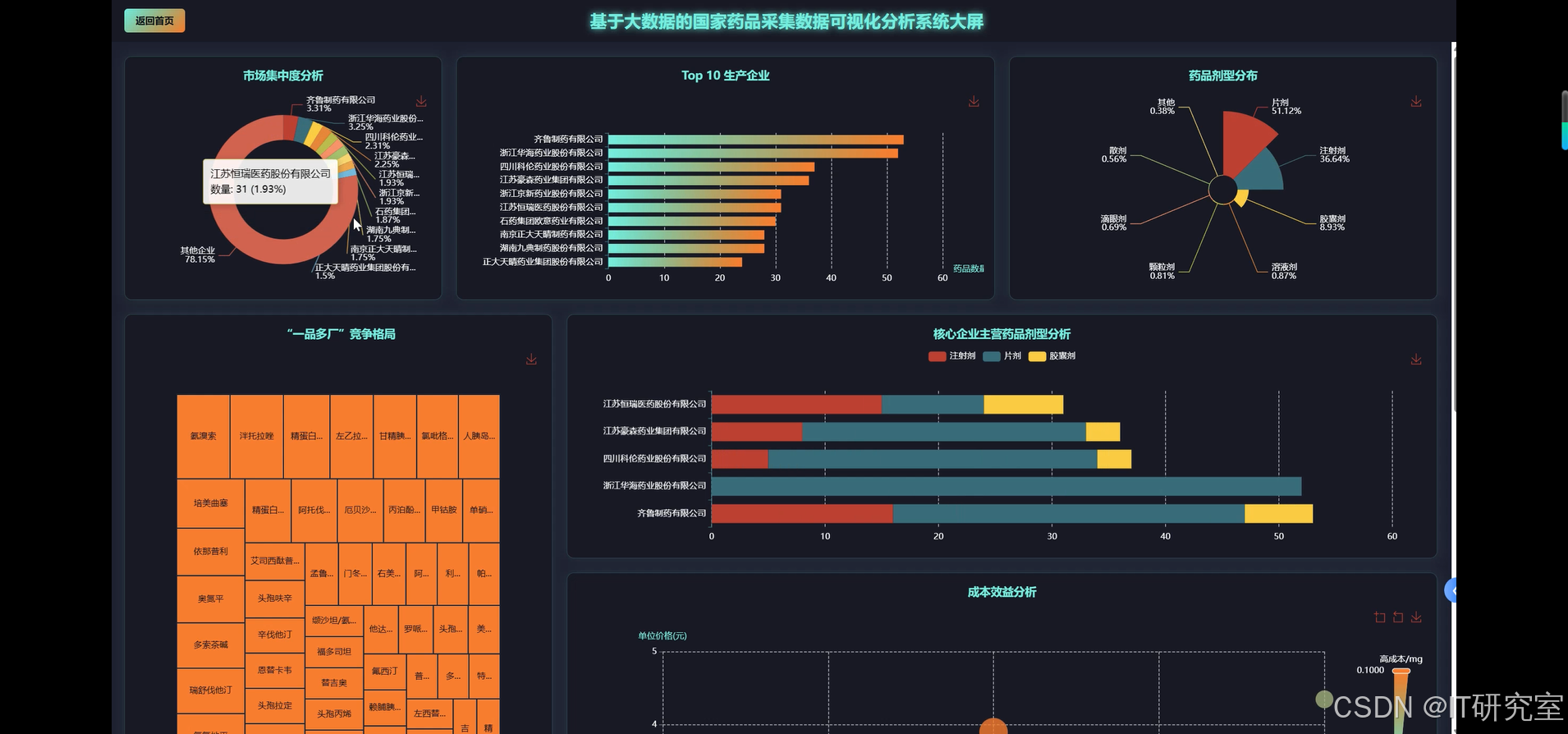
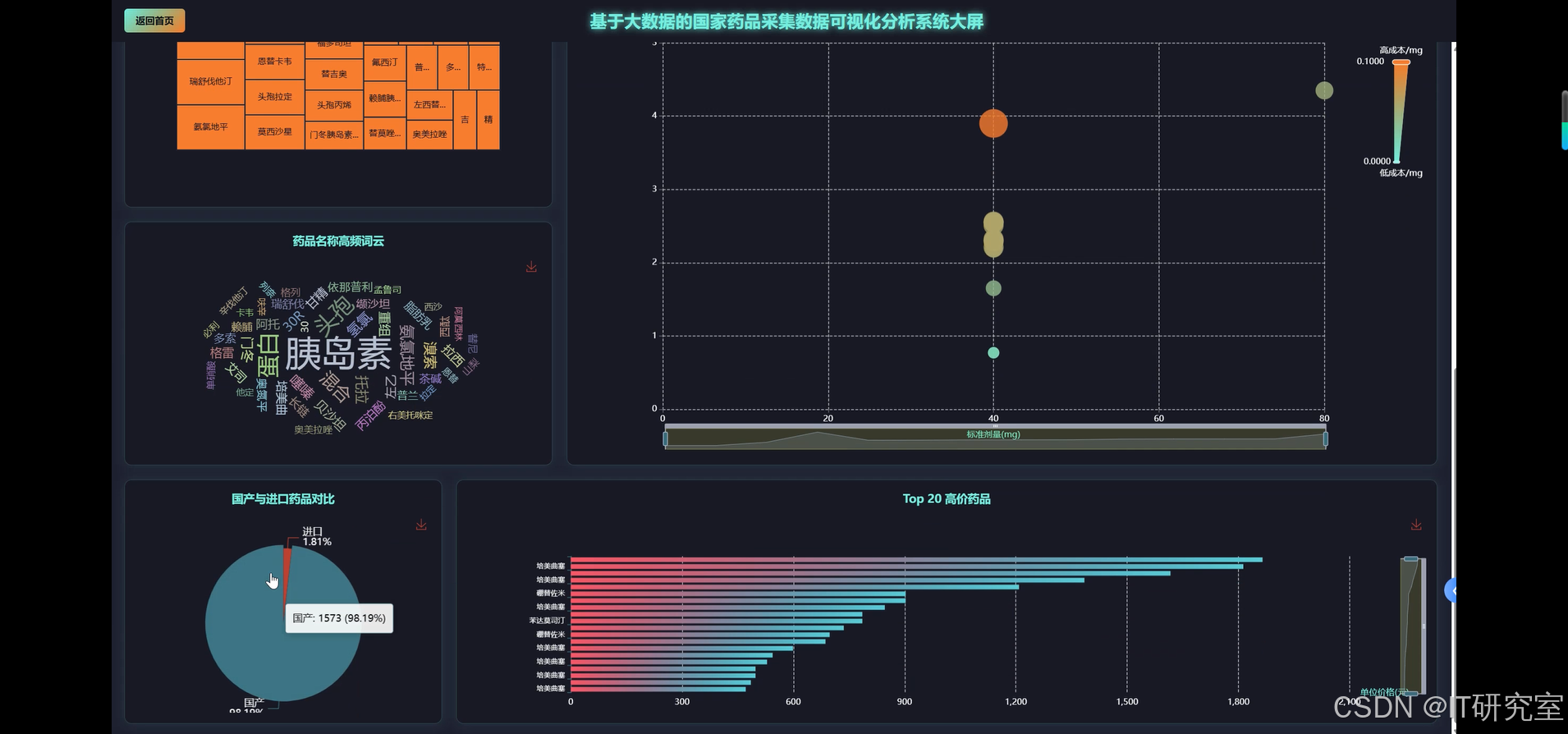
四、代码参考
- 项目实战代码参考:
java(贴上部分代码)
spark = SparkSession.builder.appName("DrugAnalysisSystem").config("spark.sql.adaptive.enabled", "true").getOrCreate()
drug_df = spark.read.csv("hdfs://namenode:9000/drug_data/national_drug_procurement.csv", header=True, inferSchema=True)
drug_df.createOrReplaceTempView("drug_procurement")
price_trend_sql = "SELECT drug_name, procurement_date, avg_price, LAG(avg_price) OVER (PARTITION BY drug_name ORDER BY procurement_date) as prev_price FROM drug_procurement WHERE procurement_date >= '2023-01-01'"
price_trend_df = spark.sql(price_trend_sql)
price_change_df = price_trend_df.withColumn("price_change_rate", (col("avg_price") - col("prev_price")) / col("prev_price") * 100)
monthly_stats = price_change_df.groupBy("drug_name", date_format("procurement_date", "yyyy-MM").alias("month")).agg(avg("avg_price").alias("monthly_avg_price"), stddev("avg_price").alias("price_volatility"))
abnormal_price_df = monthly_stats.filter(col("price_volatility") > 0.3)
price_forecast_data = price_change_df.select("drug_name", "procurement_date", "avg_price").orderBy("drug_name", "procurement_date")
drug_groups = price_forecast_data.groupBy("drug_name").agg(collect_list("avg_price").alias("price_history"))
forecast_results = drug_groups.rdd.map(lambda row: self.predict_price_trend(row["drug_name"], row["price_history"])).collect()
competitor_sql = "SELECT supplier_name, COUNT(DISTINCT drug_name) as drug_count, SUM(procurement_volume) as total_volume, AVG(bid_price) as avg_bid_price FROM drug_procurement WHERE procurement_date >= '2023-01-01' GROUP BY supplier_name"
competitor_df = spark.sql(competitor_sql)
market_share_df = competitor_df.withColumn("market_share", col("total_volume") / competitor_df.agg(sum("total_volume")).collect()[0][0] * 100)
competitive_analysis = market_share_df.withColumn("competitive_strength", when(col("market_share") > 15, "高竞争力").when(col("market_share") > 5, "中等竞争力").otherwise("低竞争力"))
supplier_performance = competitor_df.join(drug_df.groupBy("supplier_name").agg(avg("quality_score").alias("avg_quality"), avg("delivery_rate").alias("avg_delivery")), "supplier_name")
risk_assessment = supplier_performance.withColumn("supplier_risk", when((col("avg_quality") < 80) | (col("avg_delivery") < 0.9), "高风险").when((col("avg_quality") < 90) | (col("avg_delivery") < 0.95), "中风险").otherwise("低风险"))
supply_chain_sql = "SELECT drug_name, supplier_name, procurement_volume, inventory_level, delivery_time FROM drug_procurement dp JOIN inventory_data id ON dp.drug_id = id.drug_id WHERE dp.procurement_date >= '2023-01-01'"
supply_df = spark.sql(supply_chain_sql)
inventory_turnover = supply_df.withColumn("turnover_rate", col("procurement_volume") / col("inventory_level"))
supply_shortage_risk = supply_df.filter((col("inventory_level") < 1000) & (col("delivery_time") > 7))
critical_drugs = supply_shortage_risk.groupBy("drug_name").agg(count("supplier_name").alias("supplier_count"), avg("inventory_level").alias("avg_inventory"))
supply_diversification = supply_df.groupBy("drug_name").agg(countDistinct("supplier_name").alias("supplier_diversity"), stddev("delivery_time").alias("delivery_variance"))
supply_optimization = supply_diversification.join(critical_drugs, "drug_name").withColumn("supply_stability", when(col("supplier_diversity") >= 3, "稳定").when(col("supplier_diversity") >= 2, "一般").otherwise("不稳定"))五、系统视频
基于大数据的国家药品采集药品数据可视化分析系统项目视频:
大数据毕业设计选题推荐-基于大数据的国家药品采集药品数据可视化分析系统-Spark-Hadoop-Bigdata
结语
大数据毕业设计选题推荐-基于大数据的国家药品采集药品数据可视化分析系统-Spark-Hadoop-Bigdata
想看其他类型的计算机毕业设计作品也可以和我说~ 谢谢大家!
有技术这一块问题大家可以评论区交流或者私我~
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:⬇⬇⬇