文章目录
- [1 概述](#1 概述)
- [2 模块](#2 模块)
-
- [2.1 SelectiveIGEV和IGEV的差异](#2.1 SelectiveIGEV和IGEV的差异)
- [2.2 上下文空间注意力](#2.2 上下文空间注意力)
-
- [2.2.1 通道注意力](#2.2.1 通道注意力)
- [2.2.2 空间注意力](#2.2.2 空间注意力)
- [2.3 SRU](#2.3 SRU)
- [3 效果](#3 效果)
- 参考资料
1 概述
本文主要结合代码对Selective的创新点进行针对性讲解,相关的背景知识可以参考我写的另两篇文章论文阅读-RaftStereo和论文阅读-IGEV。
SelectiveStereo的创新点总结来说就只有一项,在RaftStereo和IGEV的基础上,提出了分别提取图像高频信息和低频信息并融合的迭代算子SRU(Selective Recurrent Unit),另一个Contextual Spatial Attention(CSA)模块是为其服务的。
SelectiveStereo对RaftStereo和IGEV都进行了改进,下面以IGEV为例进行具体说明。
2 模块
2.1 SelectiveIGEV和IGEV的差异
从代码上看,SelectiveStereo和IGEV的差异只有两处。一处是在计算inp_list的时候,SelectiveStereo用到了通道注意力self.cam,并使用空间注意力self.sam进一步得到了注意力图att;另一处是在使用self.update_block进行计算的时候,SelectiveIGEV额外多了att作为输入。
SelectiveStereo的相关代码为
python
class IGEVStereo(nn.Module):
def forward(self, image1, image2, iters=12, flow_init=None, test_mode=False):
# 此处省略部分代码...
cnet_list = self.cnet(image1, num_layers=self.args.n_gru_layers)
net_list = [torch.tanh(x[0]) for x in cnet_list]
inp_list = [torch.relu(x[1]) for x in cnet_list]
# 不同点1
inp_list = [self.cam(x) * x for x in inp_list]
att = [self.sam(x) for x in inp_list]
# 此处省略部分代码...
for itr in range(iters):
disp = disp.detach()
geo_feat = geo_fn(disp, coords)
with autocast(enabled=self.args.mixed_precision, dtype=getattr(torch, self.args.precision_dtype, torch.float16)):
# 不同点2
net_list, mask_feat_4, delta_disp = self.update_block(net_list, inp_list, geo_feat, disp, att)IGEV的相关代码为
python
class IGEVStereo(nn.Module):
def forward(self, image1, image2, iters=12, flow_init=None, test_mode=False):
# 此处省略部分代码...
cnet_list = self.cnet(image1, num_layers=self.args.n_gru_layers)
net_list = [torch.tanh(x[0]) for x in cnet_list]
inp_list = [torch.relu(x[1]) for x in cnet_list]
# 不同点1
inp_list = [list(conv(i).split(split_size=conv.out_channels//3, dim=1)) for i,conv in zip(inp_list, self.context_zqr_convs)]
# 此处省略部分代码...
for itr in range(iters):
disp = disp.detach()
geo_feat = geo_fn(disp, coords)
with autocast(enabled=self.args.mixed_precision, dtype=getattr(torch, self.args.precision_dtype, torch.float16)):
# 不同点2
net_list, mask_feat_4, delta_disp = self.update_block(net_list, inp_list, geo_feat, disp, iter16=self.args.n_gru_layers==3, iter08=self.args.n_gru_layers>=2)2.2 上下文空间注意力
为实现不同感受野和频率信息的融合,上下文空间注意力(Contextual Spatial Attention,简称CSA)模块通过提取上下文信息作为引导的多层级注意力图谱。如图2-1所示,CSA可划分为两个子模块:通道注意力增强(Channel Attention Enhancement,简称CAE)和空间注意力提取器(Spatial Attention Extractor,简称SAE)。这两个子模块源自CBAM框架,作者进行了简化以更好地适配立体匹配任务。
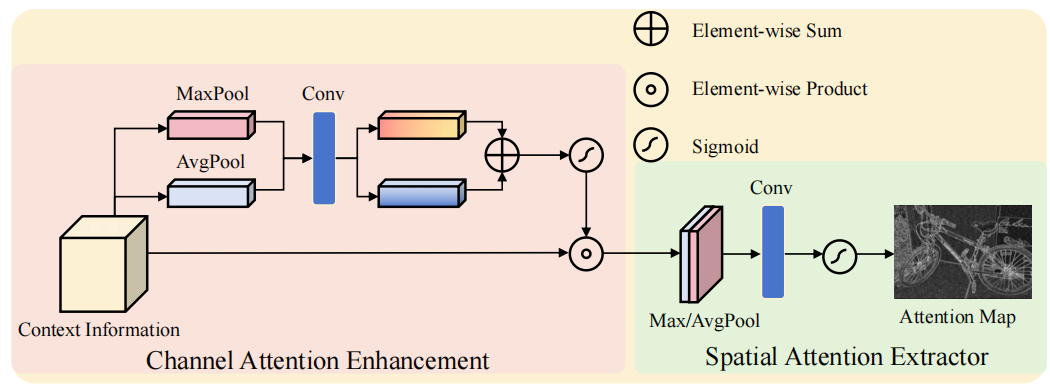
图2-1 上下文注意力示意图
2.2.1 通道注意力
通道注意力的代码实现如下所示,结合图2-1左侧的示意图应该比较容易理解。在给定上下文信息图 c ∈ R C × H × W c∈R^{ C×H×W} c∈RC×H×W 的情况下,首先对空间维度进行平均池化和最大池化操作,分别得到两个特征图 f a v g f_{avg} favg和 f m a x ∈ R C × 1 × 1 f_{max}∈R^{C×1×1} fmax∈RC×1×1。接着通过两个独立的卷积层对这些特征图进行特征变换,也就是代码中的self.fc,是一个bottleneck结构,如果改成残差的形式就和yolo中的bottleneck一致了。随后将这两个特征图相加,并使用sigmoid函数将其转换为0到1之间的权重 M c ∈ R C × 1 × 1 M_c∈R^{C×1×1} Mc∈RC×1×1。最后通过逐元素乘积运算,初始特征图能够捕捉哪些通道具有数值高的特征值需要增强,哪些通道具有数值低的特征值需要抑制。
python
class ChannelAttentionEnhancement(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttentionEnhancement, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc = nn.Sequential(
nn.Conv2d(in_planes, in_planes // 16, 1, bias=False),
nn.ReLU(),
nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
out = avg_out + max_out
return self.sigmoid(out)回看2.1节中SelectiveStereo对应的代码,self.cam生成了inp_list,而IGEV中是通过简单的卷积生成的inp_list,因此SelectiveStereo的inp_list特征表达能力会更强一些。
那么这个inp_list的作用是什么呢?看过我的另一篇博客论文阅读-IGEV的话可以知道inp_list对应于ConvGRU中的偏置项,而在SelectiveStereo中,作者选择使用了RaftConvGRU,那么inp_list就不是偏置项了,直接作为卷积的输入了。我觉得作者应该是认为经过sigmoid的结果作为偏置项不太合适才选择了RaftConvGRU。
这里也把ConvGRU和RaftConvGRU的代码放出来,方便读者查看。
RaftConvGRU代码如下,inp_list被concat在x当中。
python
class RaftConvGRU(nn.Module):
def __init__(self, hidden_dim=128, input_dim=256, kernel_size=3, dilation=1):
super(RaftConvGRU, self).__init__()
self.convz = nn.Conv2d(hidden_dim+input_dim, hidden_dim, kernel_size, padding=(kernel_size+(kernel_size-1)*(dilation-1))//2, dilation=dilation)
self.convr = nn.Conv2d(hidden_dim+input_dim, hidden_dim, kernel_size, padding=(kernel_size+(kernel_size-1)*(dilation-1))//2, dilation=dilation)
self.convq = nn.Conv2d(hidden_dim+input_dim, hidden_dim, kernel_size, padding=(kernel_size+(kernel_size-1)*(dilation-1))//2, dilation=dilation)
def forward(self, h, x):
hx = torch.cat([h, x], dim=1)
z = torch.sigmoid(self.convz(hx))
r = torch.sigmoid(self.convr(hx))
q = torch.tanh(self.convq(torch.cat([r*h, x], dim=1)))
h = (1-z) * h + z * q
return hConvGRU代码如下,inp_list就是[cz, cr, cq]。
python
class ConvGRU(nn.Module):
def __init__(self, hidden_dim, input_dim, kernel_size=3):
super(ConvGRU, self).__init__()
self.convz = nn.Conv2d(hidden_dim+input_dim, hidden_dim, kernel_size, padding=kernel_size//2)
self.convr = nn.Conv2d(hidden_dim+input_dim, hidden_dim, kernel_size, padding=kernel_size//2)
self.convq = nn.Conv2d(hidden_dim+input_dim, hidden_dim, kernel_size, padding=kernel_size//2)
def forward(self, h, cz, cr, cq, *x_list):
x = torch.cat(x_list, dim=1)
hx = torch.cat([h, x], dim=1)
z = torch.sigmoid(self.convz(hx) + cz)
r = torch.sigmoid(self.convr(hx) + cr)
q = torch.tanh(self.convq(torch.cat([r*h, x], dim=1)) + cq)
h = (1-z) * h + z * q
return h2.2.2 空间注意力
空间注意力的代码如下所示,结合图2-1右侧的示意图应该比较容易理解。采用和通道注意力相同的池化操作,但这次将池化维度调整为通道维度,对应于代码中的avg_out和max_out。随后将这些池化结果拼接成 R 2 × H × W R^{2×H×W} R2×H×W的图像,并通过带有sigmoid函数的卷积层生成最终注意力图。回顾之前的处理流程可以发现,该注意力图在需要高频信息的区域具有高权重值,因为这些信息在上下文信息中具有较高的特征价值。而对需要低频信息的区域则赋予较低权重。总体而言,该注意力图能明确区分不同频率信息需求的区域。这个图有点像边缘图,物体的边缘即使图像中的高频信息区域。
python
class SpatialAttentionExtractor(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttentionExtractor, self).__init__()
self.samconv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.samconv(x)
return self.sigmoid(x)2.3 SRU
SRU看代码就非常容易理解了,它设计了两个GRU。一个GRU的kernel_size小,捕获图像中的高频信息,只需要小的感受野,如边缘,最终的结果和表示图像中高频区域的注意力att相乘;另一个GRU的kernel_size大,捕获图像中的低频信息,如平面,最终的结果和表示图像中低频区域的注意力1-att相乘。如果既不是高频也不是低频的,att就会趋于0.5,那么就会结合self.small_gru和self.large_gru两者的信息。
python
class SelectiveConvGRU(nn.Module):
def __init__(self, hidden_dim=128, input_dim=256, small_kernel_size=1, large_kernel_size=3):
super(SelectiveConvGRU, self).__init__()
self.small_gru = RaftConvGRU(hidden_dim, input_dim, small_kernel_size)
self.large_gru = RaftConvGRU(hidden_dim, input_dim, large_kernel_size)
def forward(self, att, h, *x):
x = torch.cat(x, dim=1)
h = self.small_gru(h, x) * att + self.large_gru(h, x) * (1 - att)
return hSRU的示意图如下图2-2所示。
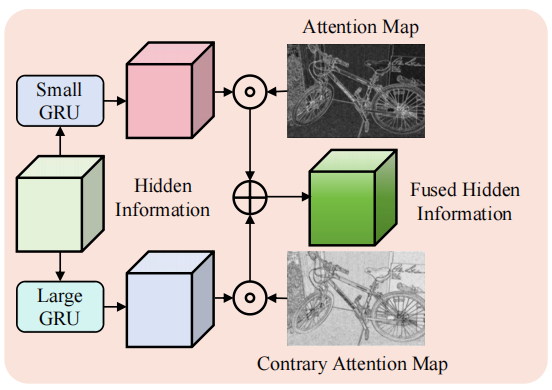
图2-2 SRU示意图
3 效果
加入SelectiveStereo之后,RaftStereo和IGEV的效果在不同的update次数下都有提升,如下表3-1所示。
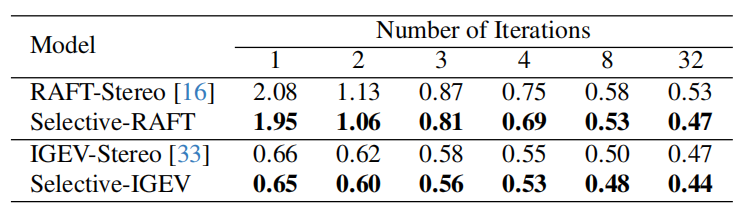
表3-1 不同update次数下SelectiveStereo的效果
IGEV和SelectiveIGEV可视化效果对比如下图3-1所示,SelectiveIGEV的细节部分效果明显更好。
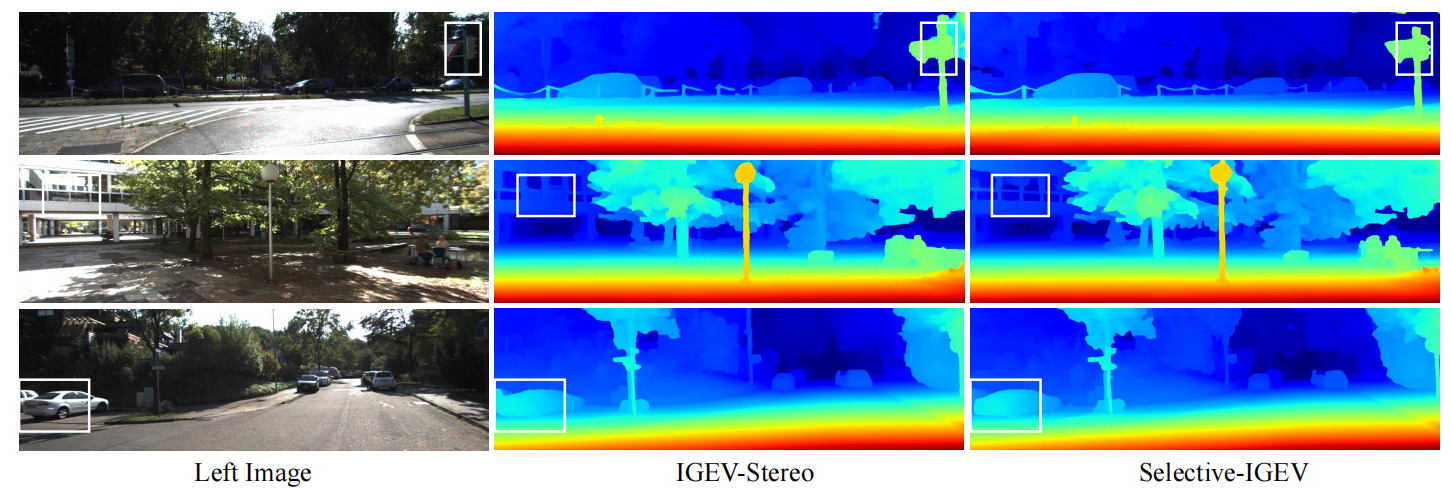
图3-1 IGEV和SelectiveIGEV可视化效果对比
SelectiveStereo在SceneFlow数据集和不同模型的EPE指标对比如下表3-2所示。
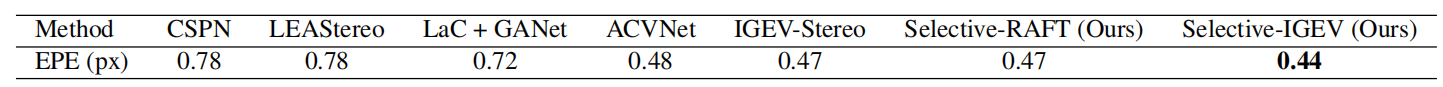
表3-2 SelectiveStereo在SceneFlow数据集和不同模型的EPE指标对比
SelectiveStereo在KITTI数据集和不同模型的EPE指标对比如下表3-3所示。
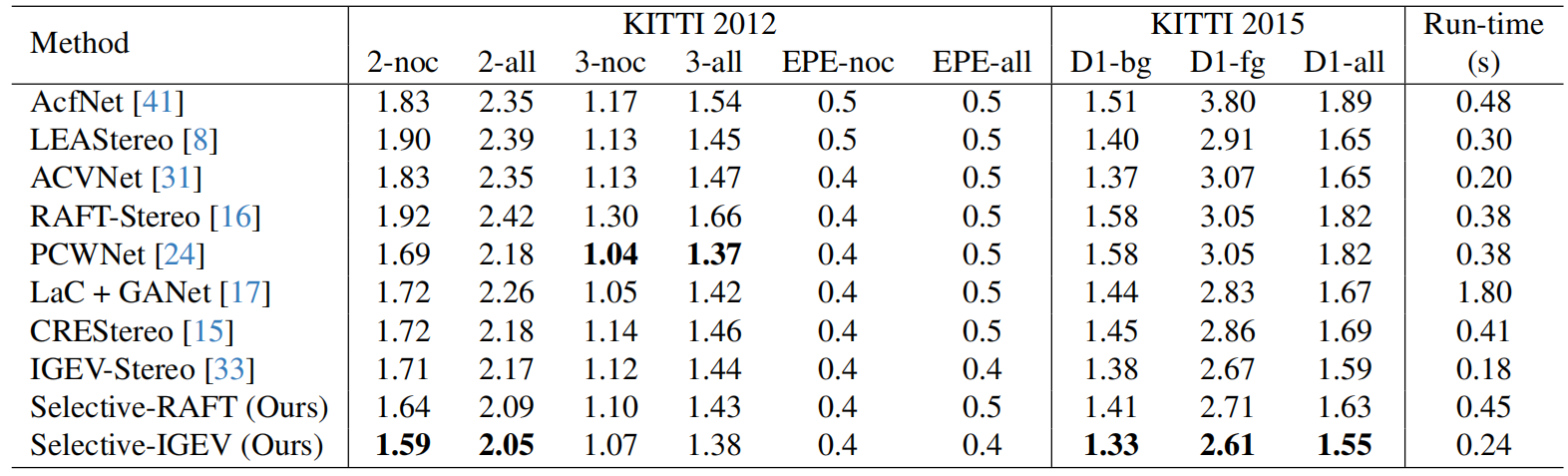
表3-3 SelectiveStereo在KITTI数据集和不同模型的EPE指标对比
整体来说,使用了SelectiveStereo后效果方面会得到全方面的提升,不过速度方面是会下降的,因为引入了把一个GRU标成了大小两个GRU,且多了注意力的计算步骤。
参考资料
1 Selective-Stereo: Adaptive Frequency Information Selection for Stereo Matching