在端到端自动驾驶领域,BEV 计算昂贵、动作多样性不足及复杂场景次优决策是关键挑战。RB 团队(Bosch、清华大学等联合)提出 DiffVLA 框架,融合 VLM 引导、混合稀疏 - 稠密感知与扩散规划模块,在 NavSim v2 私有测试集获 45.0 扩展 PDMS,2025 自动驾驶挑战赛表现优异,为端到端自动驾驶提供高效解决方案。
原文链接:https://arxiv.org/pdf/2505.19381
沐小含持续分享前沿算法论文,欢迎关注...
一、引言
1.1 研究背景与意义
端到端(End-to-End)自动驾驶因其全可微设计,能够将感知、预测、规划等模块化任务深度融合,通过统一优化追求最终驾驶目标,已成为自动驾驶领域极具潜力的研究方向。随着大规模人类驾驶示范数据的积累,从数据中学习类人驾驶策略的可能性大幅提升。
现有端到端方法如 UniAD、VAD 等,已实现将传感器数据直接输入模型并输出单模态轨迹,但仍面临三大核心挑战:
- BEV(鸟瞰图)计算成本高昂,难以在实时场景中高效部署;
- 忽略驾驶行为的内在不确定性和多模态特性,无法覆盖复杂场景下的多样化决策需求;
- 在真实复杂场景中易出现次优决策,闭环评估下的鲁棒性和泛化能力不足。
本文提出的 DiffVLA(Vision-Language Guided Diffusion Planning)框架,通过融合视觉语言模型(VLM)、混合稀疏 - 稠密感知与扩散规划,针对性解决上述问题,在 2025 年自动驾驶挑战赛(Autonomous Grand Challenge 2025)及 NavSim v2 数据集的闭环评估中展现出卓越性能。
1.2 相关工作回顾
(1)端到端自动驾驶基础模型
早期端到端方法以单模态轨迹回归为核心,UniAD 通过规划导向的设计实现了感知 - 预测 - 规划的端到端整合;VAD 则采用矢量化场景表示提升计算效率。SparseDrive 进一步探索稀疏表示,提出对称稀疏感知模块和并行运动规划器,但未解决驾驶行为的多模态建模问题。
(2)扩散模型在规划中的应用
扩散模型凭借强大的生成能力,已被用于建模驾驶行为的多模态分布。部分研究通过锚定高斯分布设计加速去噪过程,提升扩散效率,但在多源信息融合和闭环鲁棒性上仍有提升空间。
(3)VLM 与自动驾驶的结合
近年来,研究开始将视觉语言模型引入端到端自动驾驶,如 Senna-VLM、OpenDriveVLA 等,通过多模态信息融合提升轨迹规划的准确性,但现有方法对 VLM 输出与场景信息的深层交互挖掘不足。
1.3 本文核心贡献
本文的创新点集中在三个维度,形成了完整的技术闭环:
- 提出混合稀疏 - 稠密扩散策略,兼顾感知效率与表示能力,解决 BEV 计算成本与场景理解精度的矛盾;
- 设计VLM 命令引导模块,通过深度交互 agent、地图实例与 VLM 输出,强化轨迹生成的语义指导;
- 构建分层信息编码的截断扩散规划器,以多模态锚点为先验,缩短扩散调度,提升规划效率与准确性。
在 NavSim v2 数据集的私有测试集上,该方法实现了 45.0 的扩展 PDMS(Planning and Driving Measurement Score),验证了其在复杂真实场景和反应式合成场景中的优越性。
二、整体框架设计
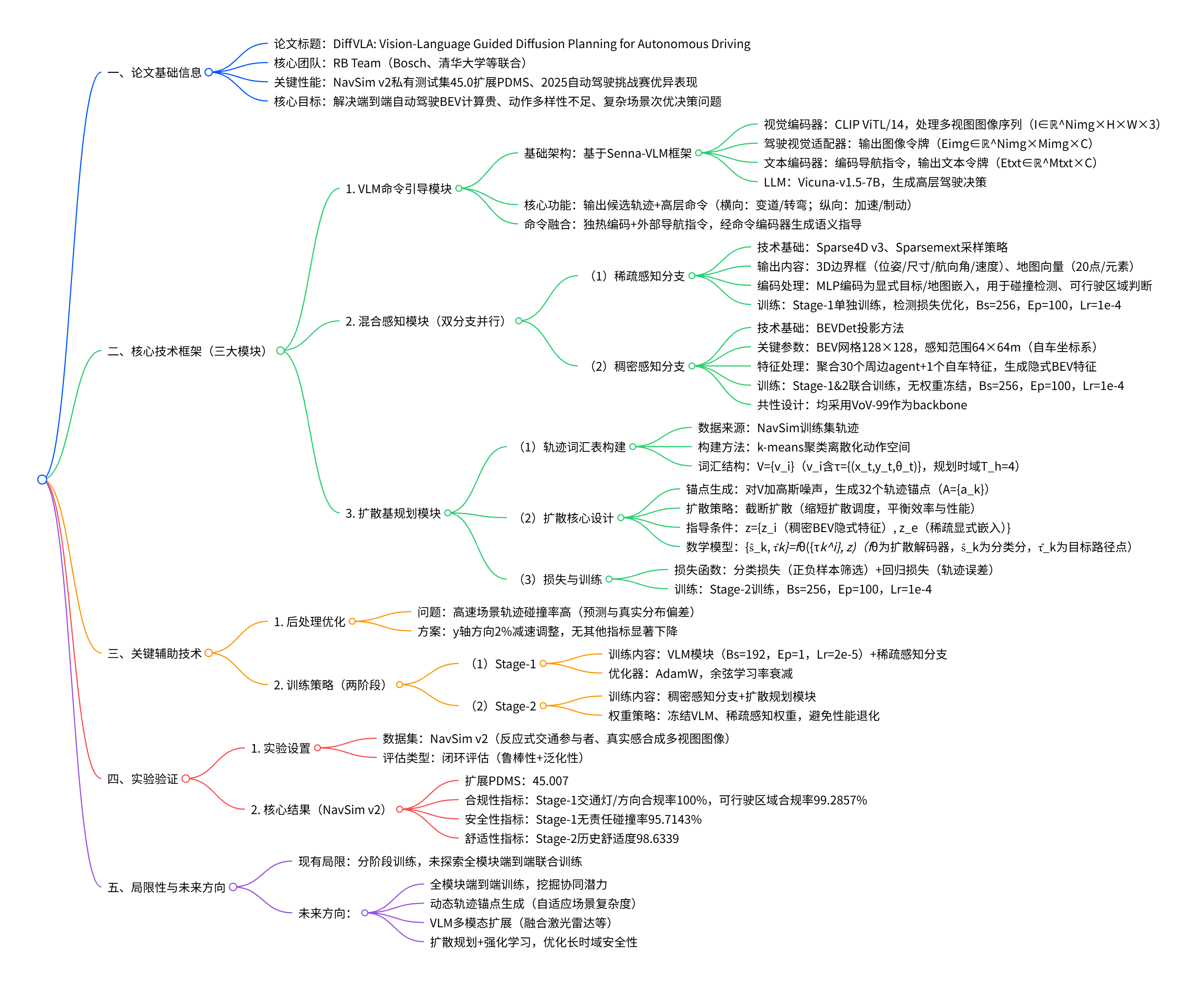
DiffVLA 的核心框架由三大模块构成:VLM 引导模块、混合感知模块、扩散基规划模块,各模块协同完成从多源输入到安全轨迹输出的全流程。框架整体结构如图 1 所示:
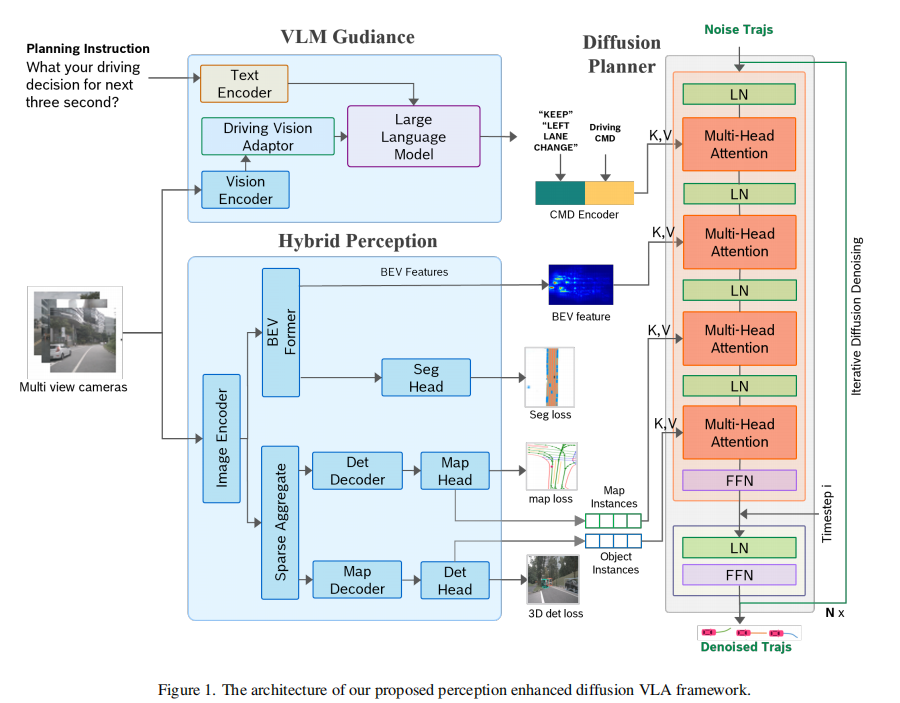
模块间数据流向:
- 多视图图像、导航指令等原始输入分别送入 VLM 引导模块和混合感知模块;
- VLM 引导模块输出高层驾驶命令,与外部导航指令融合后传入扩散规划模块;
- 混合感知模块的稀疏分支和稠密分支分别输出显式场景信息和隐式 BEV 特征,共同作为规划模块的环境感知输入;
- 扩散规划模块基于融合后的指导信息和感知特征,生成多模态候选轨迹,经后处理后输出最终驾驶轨迹。
三、感知模块(Perception)
感知是自动驾驶的基础,其核心目标是精准获取智能体(agent)和地图信息,为后续规划提供可靠的场景表征。DiffVLA 采用双分支并行设计,同时挖掘显式特征与隐式特征,突破单一感知方法的局限。
3.1 设计理念
传统感知方法分为两c类:
- 基于投影的稠密 BEV 构建方法:能捕捉环境隐式特征,但对显式目标(如障碍物、车道线)的定位精度不足;
- 基于采样的稀疏感知方法:可精准提取显式实例信息,但缺乏对环境全局语义的理解。
本文的混合感知模块通过双分支设计,实现 "显式 + 隐式" 特征的互补融合,既保证目标检测和地图结构的准确性,又保留环境全局语义信息。
3.2 稀疏感知分支(Sparse Perception Branch)
(1)核心功能
负责提取显式场景信息,包括 3D 目标检测结果和在线地图生成数据,具体输出:
- 3D 边界框:包含目标的位姿、尺寸、航向角、速度等属性;
- 地图向量:每个地图元素(车道边界、中心线、停止线等)用 20 个地图点表示。
(2)技术实现
采用 Sparse4D v3 和 Sparsemext 中的采样策略,实现高效的 3D 目标检测和高清地图构建。输出结果经 MLP 编码后,生成显式目标嵌入(explicit object embedding)和地图嵌入(map embedding),用于后续碰撞检测、可行驶区域判断等规划约束检查。
3.3 稠密感知分支(Dense Perception Branch)
(1)核心功能
构建隐式 BEV 特征表示,为规划模块提供全局环境语义信息。
(2)技术实现
采用 BEVDet 中的 BEV 特征投影方法,将多视图图像特征投影到鸟瞰图空间。关键参数设置:
- BEV 网格尺寸:128×128;
- 感知范围:在自车坐标系下,x 轴和 y 轴方向各 64 米;
- 特征聚合:融合 30 个周围智能体和 1 个自车的特征,为轨迹扩散过程提供隐式指导。
3.4 训练策略
感知模块采用两阶段训练流程,确保各分支的独立优化与协同适配:
- 第一阶段:单独训练稀疏感知分支,采用 3D 目标检测损失和地图元素检测损失,优化显式信息提取精度;
- 第二阶段:在稀疏分支训练完成后,将稠密感知分支与后续轨迹头(trajectory head)联合训练;
- backbone 选择:两个分支均采用 VoV-99 作为特征提取骨干网络,保证特征提取能力的一致性。
四、VLM 引导模块(VLM Command Guidance Module)
4.1 设计目标
解决多模态信息融合问题,将视觉场景理解与自然语言指令(如导航指令)结合,生成高层驾驶命令,为规划模块提供语义级指导,弥补纯视觉感知在意图理解上的不足。
4.2 技术架构
基于 Senna-VLM 框架构建,包含四大核心组件,实现 "图像 - 文本 - 驾驶命令" 的端到端转换:
视觉编码器(Vision Encoder)
功能描述:处理多视图图像序列,提取图像特征
技术细节:采用 CLIP 的 ViTL/14 模型,输入为 NavSim 数据集的多视图图像序列 (
为图像数量,H/W 为图像高/宽)
驾驶视觉适配器(Driving Vision Adaptor)
功能描述:编码并压缩图像特征,生成适配 LLM 的图像tokens
技术细节:输出图像tokens (
为单图tokens数,C 为 LLM 特征维度)
文本编码器(Text Encoder)
功能描述:编码用户指令和导航命令
技术细节:输出文本tokens (
为文本令牌数)
大语言模型(LLM)
功能描述:融合图像与文本特征,生成高层驾驶决策
技术细节:采用 Vicuna-v1.5-7B 模型进行驾驶决策生成
4.3 输出与融合
(1)输出内容
VLM 模块输出两类关键信息:
- 候选轨迹:基于场景理解生成的初步轨迹建议;
- 高层驾驶命令:分解为横向控制(变道、转弯)和纵向控制(加速、制动)。
(2)命令融合
采用独热编码(one-hot encoding)将驾驶命令量化,与外部导航指令融合后,经命令编码器处理,生成语义指导信号,输入至扩散规划模块。
五、规划模块(Planning)
规划模块是 DiffVLA 的核心,通过截断扩散策略和分层信息编码,实现多模态、高效、安全的轨迹生成。
5.1 轨迹词汇表构建(Trajectory Vocabulary Construction)
为离散化自车的动作空间,构建轨迹词汇表 ,具体步骤:
- 数据采样:从 NavSim 训练集中提取所有轨迹数据;
- 聚类分组:采用 k-means 聚类算法,将轨迹划分为 N 个离散词汇;
- 词汇结构:每个词汇
包含一组路径点
5.2 扩散规划核心设计
(1)扩散锚点生成
借鉴 DiffusionDrive 的思路,对轨迹词汇表 V 添加高斯噪声,生成轨迹锚点 ,其中锚点数量
。锚点作为扩散过程的先验,为多模态轨迹生成提供初始候选。
(2)截断扩散策略(Truncated Diffusion Policy)
传统扩散模型需经过多步去噪过程,计算成本较高。本文采用缩短的扩散调度(shortened diffusion schedule),减少去噪步骤,同时保证轨迹生成质量,平衡效率与性能。
(3)分层信息编码与指导条件融合
规划模块的输入包含异质信息(隐式 BEV 特征、显式目标 / 地图嵌入、VLM 语义指导),采用分层信息编码策略整合为统一指导条件 :
- 隐式指导
- 显式指导
扩散模型的数学表达为:
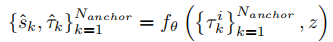
其中:
5.3 损失函数设计
轨迹头采用分类损失与回归损失结合的训练策略:
- 分类损失:基于正负样本选择策略(与 DiffusionDrive 一致),优化轨迹类别的区分能力;
- 回归损失:最小化预测轨迹与真实轨迹的路径点误差,保证轨迹精度。
六、后处理(Post Processing)
6.1 问题分析
观察到在高速行驶场景下,发现预测轨迹的碰撞率略高于其他场景,文中定位原因是高速场景下轨迹的预测分布与真实分布存在偏差。
6.2 解决方案
对预测轨迹实施 y 轴方向 2% 的减速调整(沿行驶方向的纵向减速)。该处理方式的优势:
- 有效降低高速场景下的碰撞风险;
- 对其他评估指标(如行驶进度、舒适性)影响极小,保证整体性能稳定。
七、实验设计与结果
7.1 实验设置
(1)数据集
采用 NavSim v2 数据集,该数据集的核心优势的在于提供闭环评估能力:
- 包含反应式背景交通参与者(reactive background traffic),模拟真实道路的动态交互;
- 提供真实感合成多视图相机图像,提升模型泛化能力;
- 支持鲁棒性和泛化性的全面评估。
(2)训练策略
采用两阶段训练流程,各模块的训练配置如表 1 所示:
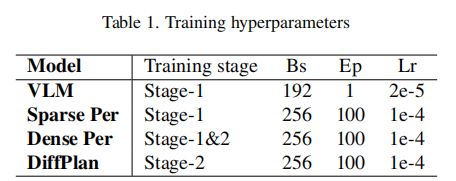
训练细节补充:
- 优化器:AdamW;
- 学习率调度:余弦学习率衰减;
- 模型冻结策略:Stage-2 训练时,冻结 VLM 引导模块和稀疏感知模块的权重,仅训练稠密感知模块和扩散规划模块,避免预训练好的特征提取能力退化。
7.2 实验结果
DiffVLA 在 NavSim v2 竞赛的私有测试集上取得 45.007 的扩展 PDMS 分数,各细分指标表现如表 2 所示:
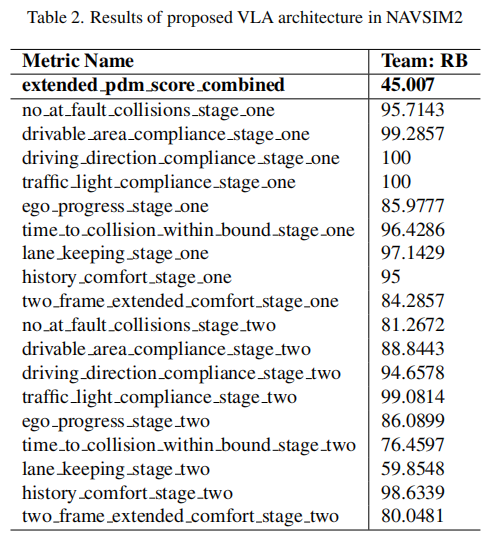
7.3 结果分析
(1)核心指标表现
扩展 PDMS 总分达到 45.007,在复杂闭环场景中展现出优异的综合性能,验证了混合感知、VLM 引导与扩散规划融合的有效性。
(2)细分指标解读
- 合规性指标:Stage-1 中交通灯合规率、行驶方向合规率均达到 100%,可行驶区域合规率 99.2857%,说明 VLM 引导模块能精准理解交通规则和导航指令;
- 安全性指标:Stage-1 无责任碰撞率 95.7143%,但 Stage-2 略有下降,推测是 Stage-2 引入更复杂的动态场景,后续可通过强化学习进一步优化;
- 舒适性指标:历史舒适度在 Stage-2 提升至 98.6339,说明扩散规划生成的轨迹平滑性较好;
- 进度指标:自车进度在两阶段中保持稳定(≈86),表明轨迹规划能有效平衡安全与效率。
八、局限性与未来展望
8.1 现有局限
受时间限制,本文采用分阶段独立训练 VLM、稀疏感知、稠密感知和规划头的方式,尚未探索将所有模块整合为端到端训练的可能性。端到端训练可能进一步挖掘模块间的协同潜力,提升整体性能。
8.2 未来方向
- 端到端联合训练:打破模块间的训练壁垒,实现感知 - 引导 - 规划的端到端优化;
- 动态锚点生成:根据场景复杂度自适应调整轨迹锚点数量,平衡计算成本与多模态覆盖度;
- 多模态 VLM 优化:扩展 VLM 的输入模态(如融合激光雷达数据),提升极端天气下的场景理解能力;
- 强化学习融合:将扩散规划与强化学习结合,进一步优化轨迹的安全性和长时域规划性能。
九、结论
DiffVLA 框架通过三大核心创新,构建了高效、鲁棒的端到端自动驾驶解决方案:
- 混合稀疏 - 稠密感知模块:兼顾显式目标定位与隐式语义理解,降低 BEV 计算成本;
- VLM 命令引导模块:实现图像、文本与驾驶指令的深度融合,提升复杂场景的意图理解能力;
- 截断扩散规划模块:以多模态锚点为先验,通过分层信息编码实现高效、安全的轨迹生成。
实验结果表明,该框架在 NavSim v2 的闭环评估中取得 45.0 的扩展 PDMS 分数,在安全性、合规性、舒适性等多维度指标上表现优异,为复杂真实场景下的自动驾驶提供了新的技术思路。未来通过端到端训练、多模态融合等方向的优化,有望进一步提升模型的鲁棒性和泛化能力。