各位读者大佬好,我是落羽!一个坚持不断学习进步的学生。
如果您觉得我的文章还不错,欢迎多多互三分享交流,一起学习进步!
也欢迎关注我的blog主页: 落羽的落羽

这里写目录标题
- 一、内存空间布局
- 二、进程地址空间
-
- [1. 虚拟地址](#1. 虚拟地址)
- [2. 虚拟地址空间与页表](#2. 虚拟地址空间与页表)
- 三、为什么要有虚拟地址
一、内存空间布局
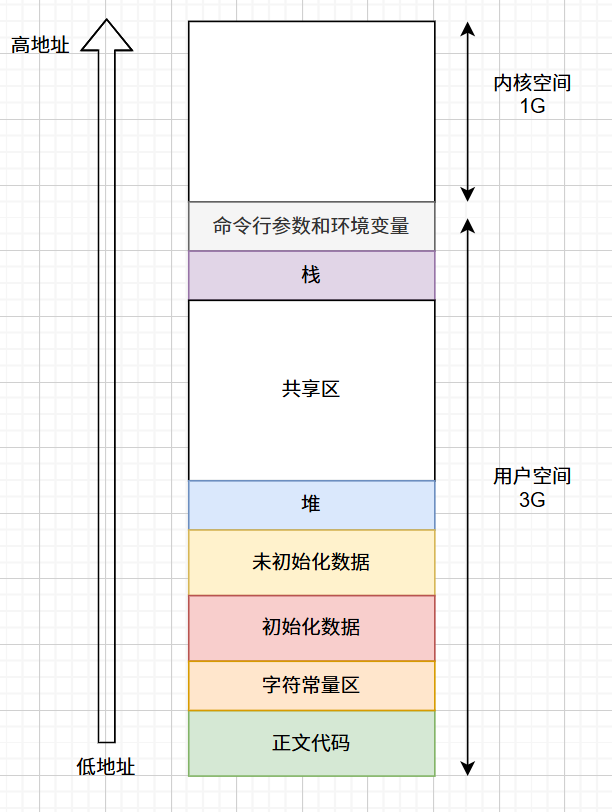
很久之前,我们浅浅谈过内存的空间布局:
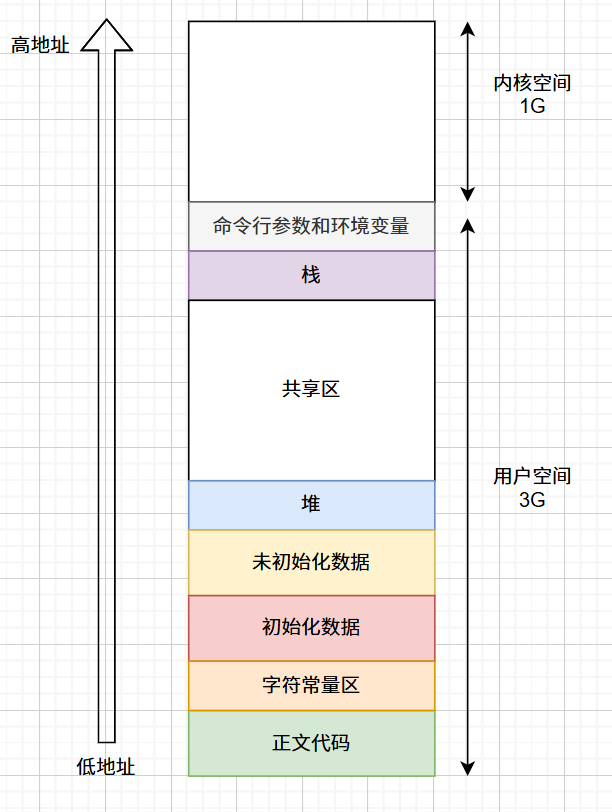
其中,初始化数据和未初始化数据指的是全局或静态变量。程序的局部变量开辟在栈区,malloc/new等申请的空间是在堆区。
堆区和栈区,是相对而生长的!栈区上开辟空间,是从高地址向低地址开辟的,而一个变量的地址,是他的最低字节的地址 。比如,我要开辟一个int变量,就在栈区的位置从高向低连续数出四个字节,最低字节的地址就是这个变量的地址了。至于在这四个字节内具体如何存放数据,还涉及到以前提到的大小端字节序。而堆区的申请空间,则是从低地址向高地址的。
证明一下,指针变量也是局部变量,指针变量存放在栈区,而它们指向的申请的空间在堆区:
c
#include<stdio.h>
#include<stdlib.h>
int main()
{
int* p1 = (int*)malloc(sizeof(int));
int* p2 = (int*)malloc(sizeof(int));
int* p3 = (int*)malloc(sizeof(int));
int* p4= (int*)malloc(sizeof(int));
int* p5 = (int*)malloc(sizeof(int));
printf("栈区:%p\n", &p1);
printf("栈区:%p\n", &p2);
printf("栈区:%p\n", &p3);
printf("栈区:%p\n", &p4);
printf("栈区:%p\n", &p5);
printf("堆区:%p\n", p1);
printf("堆区:%p\n", p2);
printf("堆区:%p\n", p3);
printf("堆区:%p\n", p4);
printf("堆区:%p\n", p5);
return 0;
}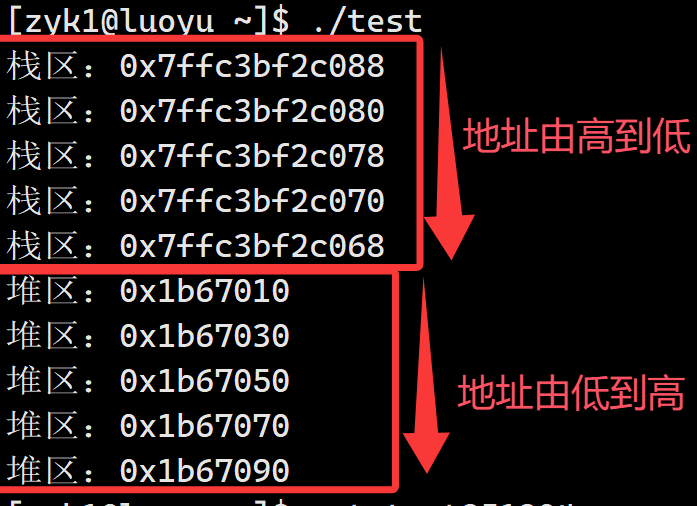
结果证明,栈区和堆区确实是相对生长的!
二、进程地址空间
1. 虚拟地址
以前讲过,fork创建子进程,在父进程中返回子进程pid,在子进程中返回0。今天,我们再看一个奇怪的现象:
c
#include<stdio.h>
#include<unistd.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
printf("子进程中,id:%d,地址%p\n", id, &id);
}
else
{
printf("父进程中,id:%d,地址%p\n", id, &id);
}
return 0;
}按照常理,在父子进程中id是不同的值,id应该是他们各自有一个吧。可是:

它们的id变量的地址一样?之前说到,父子进程默认共享数据和代码,但是显然这里id在父子进程中的值都不一样,这个id变量绝对不是共享一份的!
事实结论是:
- printf输出的地址不是物理地址!
- 我们用C/C++能得到的所有地址、指针,都不是物理地址!在Linux下,看到的是虚拟地址,而物理地址由操作系统统一管理!
2. 虚拟地址空间与页表
注意,我们下面谈的程序地址空间、进程地址空间、虚拟地址空间,其实指的都是一个东西。
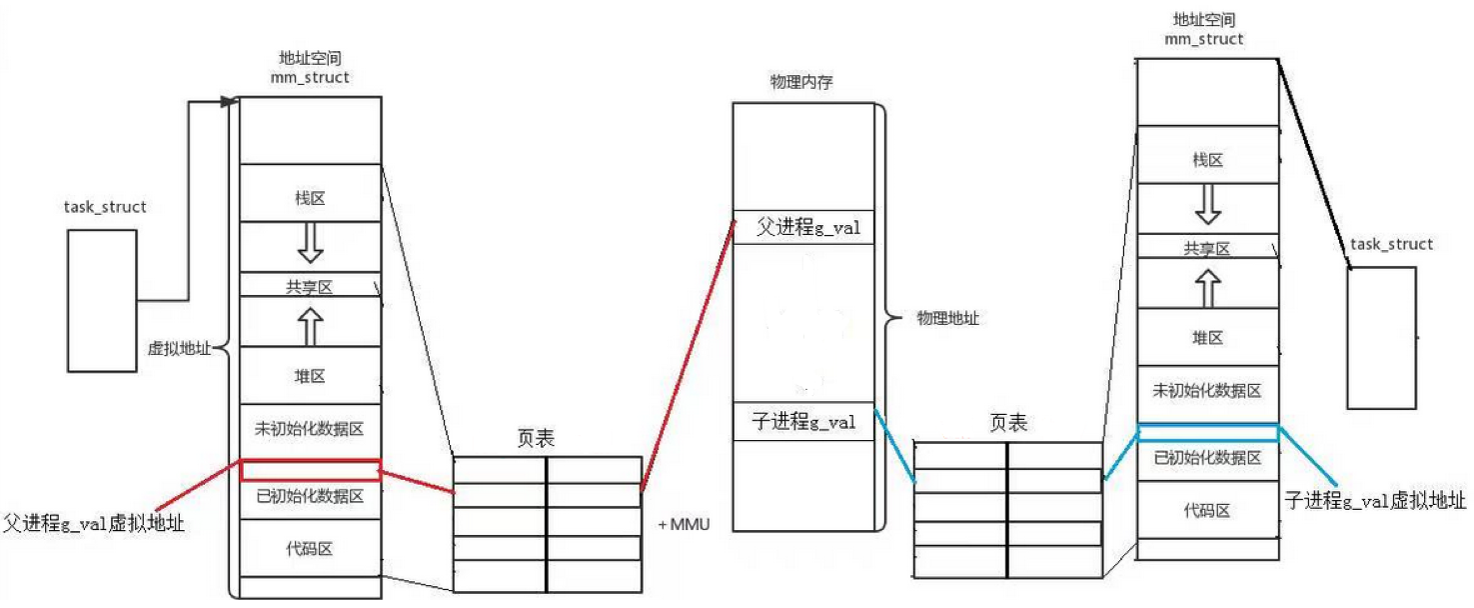
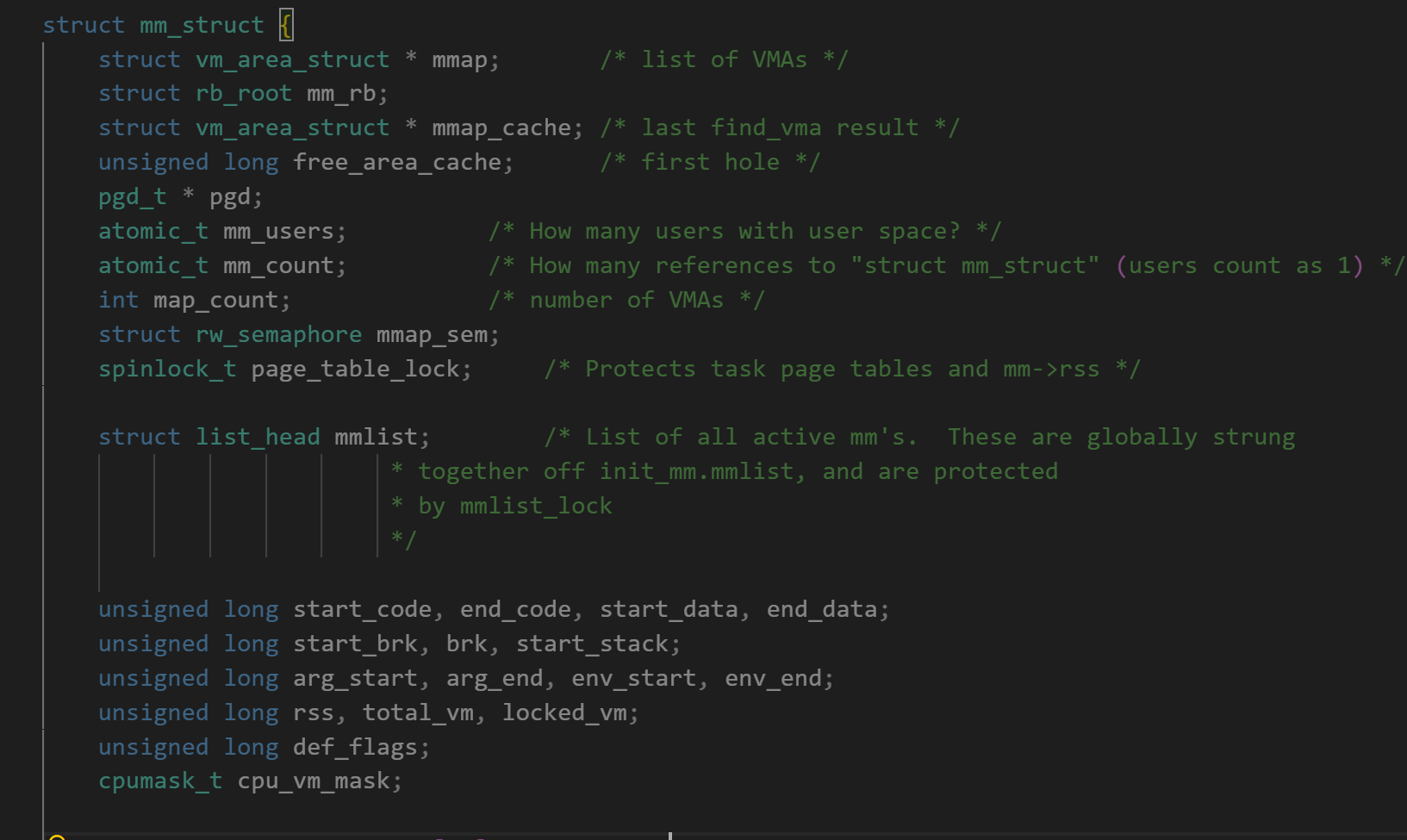
每个程序运行时,操作系统会给它分配一个虚拟地址空间,这个空间是逻辑上的、抽象的,不是真实的物理内存。在进程的task_struct中,描述虚拟地址空间的结构是mm_struct。

每个进程都拥有一套独立的、虚拟的地址编号,程序只知道自己的虚拟地址,不知道真实的物理地址。在32位机器中,虚拟地址是从0...000到F...FFF,共232个地址
与此同时,每个进程会有一套页表 。
程序使用虚拟地址,当然无法访问真实的内存,所以操作系统需要把虚拟地址翻译成物理地址,才能真正访问到物理内存 ------ 这个翻译的核心就是页表。
页表之中,记录着虚拟地址到物理地址的映射。子进程拷贝了父进程的页表,也会拷贝上面记录的内容,类似于发生浅拷贝,这就是父子进程默认共享代码和数据的本质!
所以,回到上面的例子中,父子进程的id变量地址相同,其实是他们的id的虚拟地址相同,而在各自的页表中,相同的虚拟地址映射的不同的物理地址,所以各自的id变量可以有不同的值!那么,物理地址由相同变不同的过程是什么呢?
OS规定:父子进程中任意一个想要对共享的内容进程修改,要发生写时拷贝。
在页表中,除了虚拟地址对物理地址的映射,还存在很多的标志位 ,如"权限"、"是否存在"等,用于进一步控制物理地址。其中,权限位就包括rwx,常量和代码是只读的,本质上是他们的权限标志位为r 。
fork之后,父子进程共享代码和数据。代码是只读的,父子进程都不会影响它。一旦一方要对数据进行修改(写入),操作系统内核首先对该数据进行权限的检查,补充应有的w权限,再自动为修改的一方开辟一块内存空间,存入修改的内容。这样,父子进程的该数据虚拟地址不再映射相同的物理地址,而是不同的物理空间不同的内容,完成了写实拷贝,类似于发生深拷贝!
三、为什么要有虚拟地址
如果程序可以直接操控物理内存,会有什么问题?
- 安全风险。每个进程都可以访问任意的内存空间,这也就意味着任意一个进程都能够去读写系统相关内存区域,如果是一个木马病毒,那么他就能随意的修改内存空间,让设备直接瘫痪。
- 地址不确定。众所周知,编译完成后的程序是存放在硬盘上的,当运行的时候,需要将程序搬到内存当中去运行,如果直接使用物理地址的话,我们无法确定内存现在使用到哪里了,也就是说拷贝的实际内存地址每一次运行都是不确定的。
- 效率低下。如果直接使用物理内存的话,一个进程就是作为一个整体(内存块)操作的,如果出现物理内存不够用的时候,我们一般的办法是将不常用的进程拷贝到磁盘的交换分区中,好腾出内存,但是如果是物理地址的话,就需要将整个进程一起拷走,这样,在内存和磁盘之间拷贝时间太长,效率较低。
虚拟地址空间和分页机制就能解决这些问题了!
地址空间和页表是 OS 创建并维护的!是不是也就意味着,凡是想使用地址空间和页表进行映射,也一定要在 OS 的监管之下来进行访问!也顺便保护了物理内存中的所有的合法数据,包括各个进程以及内核的相关有效数据!
因为有地址空间的存在和页表的映射的存在,我们的物理内存中可以对未来的数据进行任意位置的加载!物理内存的分配和进程的管理就可以区别,进程管理模块和内存管理模块就完成了解耦合。
因为有地址空间的存在,所以我们在C/C++语言上new , malloc 空间的时候,其实是在地址空间上申请的,物理内存可以甚至一个字节都不给你。而当你真正进行对物理地址空间访问的时候,才执行内存的相关管理算法,帮你申请内存,构建页表映射关系(延迟分配),这是由操作系统自动完成,用户包括进程完全0感知。这就是缺页中断引起的二次内存申请。
因为页表的映射的存在,程序在物理内存中理论上就可以任意位置加载。因为它可以将地址空间上的虚拟地址和物理地址进行映射,在进程视角所有的内存分布都可以是逻辑有序的,而实际物理空间中可以是无序的。
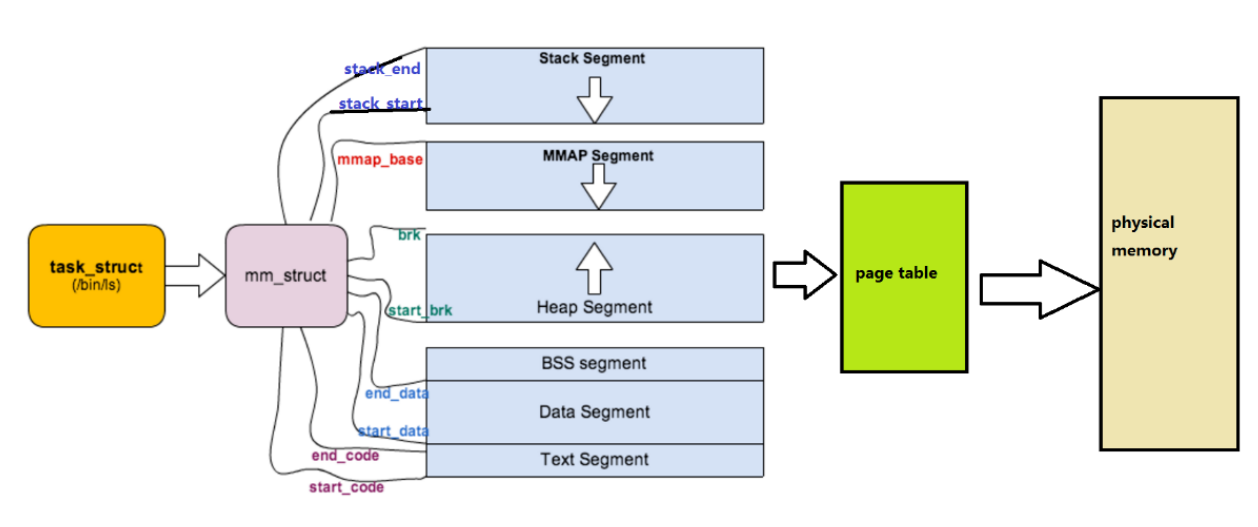
回到这张图,这张图其实展示的是虚拟地址空间的分布,而不是真实的物理内存分布!!
本篇完,感谢阅读!