一、引言
在自动驾驶领域,感知系统的核心目标是从多传感器数据中提取语义信息,并将其融合到统一的 "鸟瞰图(Bird's-Eye-View, BEV)" 坐标系中,为后续的运动规划模块提供决策依据。传统计算机视觉算法要么输出与坐标系无关的分类结果,要么在输入图像的同一坐标系中进行预测(如目标检测、语义分割等),这与自动驾驶中 "多传感器输入 - 统一 BEV 输出" 的需求存在本质脱节。
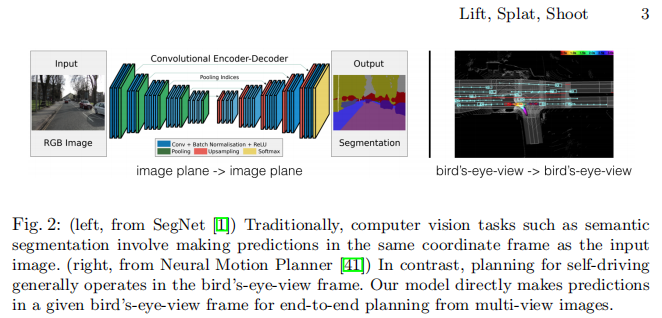
为解决这一问题,Jonah Philion 和 Sanja Fidler 提出了一种名为 "Lift, Splat, Shoot" 的端到端架构,能够直接从任意数量的相机图像中提取 BEV 场景表示。该架构通过 "Lift(提升)-Splat(泼洒)-Shoot(投射)" 三步核心流程,在保留多视图感知关键对称性的同时,实现了端到端可微分训练,其性能在多个 BEV 语义分割任务中超越现有基线,并支持可解释的端到端运动规划。

原文链接:https://arxiv.org/pdf/2008.05711
项目主页:https://research.nvidia.com/labs/toronto-ai/lift-splat-shoot/
代码链接:https://github.com/nv-tlabs/lift-splat-shoot
沐小含持续分享前沿算法论文,欢迎关注...
二、核心背景与问题定义
2.1 自动驾驶感知的核心矛盾
自动驾驶感知面临的核心挑战在于:
- 多传感器异构性:不同相机具有独立的坐标系(内参 + 外参),数据分布存在差异;
- 坐标系转换需求:感知结果需映射到 ego 车的 BEV 坐标系,才能被规划模块直接使用;
- 深度歧义性:单目相机缺乏直接深度信息,多视图融合需解决深度估计与跨相机信息融合的耦合问题。
传统多视图感知方法(如先单图检测再坐标转换)的缺陷的是:后处理阶段的坐标转换导致模型无法从 BEV 输出端反向传播梯度到原始传感器输入,无法通过数据驱动学习最优融合策略,也无法利用规划模块的反馈优化感知系统。
2.2 关键对称性要求
为保证多视图感知的鲁棒性,模型需满足以下三个核心对称性:
- 平移等变性(Translation Equivariance):图像像素坐标整体平移时,输出结果同步平移;
- 排列不变性(Permutation Invariance):相机输入顺序不影响最终 BEV 输出;
- Ego 帧等距等变性(Ego-frame Isometry Equivariance):Ego 车坐标系旋转 / 平移时,输出结果同步变换。
Lift, Splat, Shoot 架构通过设计天然满足这三个对称性,为多视图融合提供了坚实的结构基础。
三、相关工作综述
论文的相关工作主要围绕单目 3D 目标检测和 BEV 帧推理两大方向展开,其核心贡献在于整合并突破了现有方法的局限:
3.1 单目 3D 目标检测
现有方法可分为三类:
- 2D 检测 + 3D 回归:先通过 2D 检测器获取目标框,再回归 3D 位置与尺寸。这类方法依赖 2D 检测精度,且深度估计与边界框预测的误差难以解耦;
- 伪激光雷达(Pseudo-Lidar):先通过单目深度估计生成伪点云,再输入 BEV 网络进行检测。这类方法将深度估计与 BEV 检测解耦,利用了 BEV 坐标系中欧式距离的物理意义,但两步法同样存在梯度传播断裂问题;
- 3D 几何基元投影:通过生成 3D 体素或目标提案,投影到多相机图像中提取特征后进行检测。这类方法的缺陷是:像素特征与体素深度无关,导致深度歧义性影响融合效果。
3.2 BEV 帧直接推理
近年来直接在 BEV 帧进行推理的方法逐渐兴起:
- MonoLayout:通过单目图像推理 BEV 布局,利用对抗损失补全遮挡目标,但仅支持单相机输入,缺乏多视图融合能力;
- 金字塔占用网络(PON):采用 Transformer 架构将图像特征转换为 BEV 表示,但未充分利用相机的几何结构;
- FISHING Net:支持多视图 BEV 分割与未来预测,但在语义分割精度与泛化性上仍有提升空间。
Lift, Splat, Shoot 的创新点在于:通过 "隐式深度分布 + 几何约束融合",在端到端框架中同时解决深度估计与多视图融合问题,且天然满足多视图感知的对称性要求。
四、核心方法:Lift-Splat-Shoot 架构
论文提出的架构核心由三步组成:Lift(将图像提升到 3D 视锥体特征)、Splat(将多相机视锥体特征泼洒到 BEV 网格)、Shoot(将轨迹模板投射到 BEV 代价图进行运动规划)。整体流程如图 4 所示:
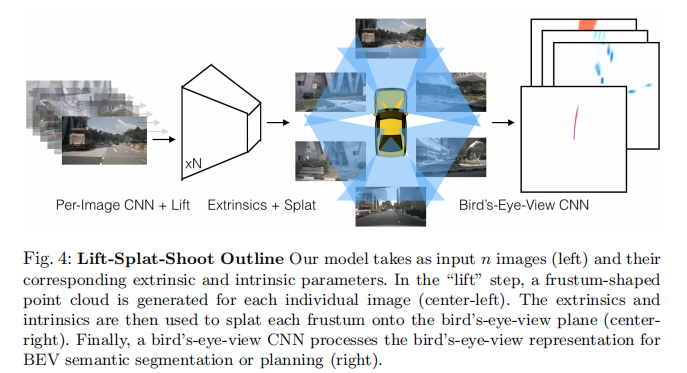
左:输入多相机图像及内参 / 外参;中左:Lift 步骤生成的视锥体点云;中右:Splat 步骤将点云映射到 BEV 平面;右:BEV CNN 输出语义分割或规划结果。
4.1 问题形式化定义
给定 张相机图像
,每张图像对应内参矩阵
和外参矩阵
(定义 3D 参考坐标到像素坐标的映射)。目标是输出 BEV 坐标系下的栅格化语义表示
(
为特征通道数,
为 BEV 网格尺寸),训练与测试阶段均不依赖激光雷达等深度传感器。
4.2 Lift:隐式深度分布的 3D 特征提升
Lift 步骤的核心目标是将单张 2D 图像提升到 3D 空间,生成包含深度信息的视锥体(Frustum)特征点云,解决单目相机的深度歧义性问题。
4.2.1 深度离散化与视锥体构建
对于每张图像的每个像素 ,定义一组离散深度值
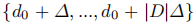
论文中 ,
,
,深度范围 4至45m。每个像素对应
个 3D 点
,所有像素的 3D 点构成该相机的视锥体点云(尺寸为
)。
该结构类似于 "多平面图像(Multi-Plane Image)",但区别在于:多平面图像存储 RGB 颜色与透明度,而此处存储抽象语义特征。
4.2.2 深度分布与特征加权
为解决深度歧义性,模型不为每个像素预测单一深度,而是预测一个深度分布 (
表示 simplex 空间,满足
)和一个上下文特征向量
。每个 3D 点
的最终特征为:
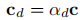
该设计的灵活性在于:
- 若
为 one-hot 向量,等价于伪激光雷达的 "硬深度分配";
- 若
- 模型可通过学习自动选择:深度明确时聚焦单一深度,深度模糊时(如远距离、遮挡区域)分散特征到多个深度。
4.2.3 特征提取网络
采用预训练的 EfficientNet-B0 作为骨干网络,对输入图像进行特征提取,输出每个像素的上下文向量 和深度分布
(通过 softmax 层归一化得到)。该网络在 ImageNet 上预训练,保证了特征的泛化能力。
Lift 步骤的可视化如图 3 所示:
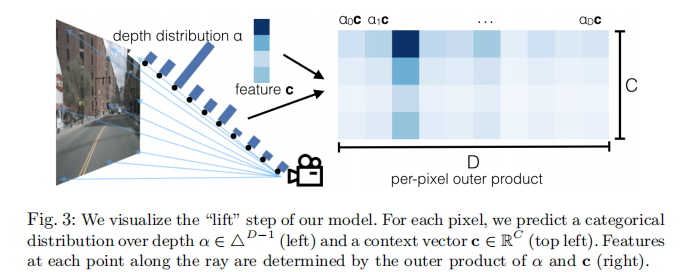
左:像素的深度分布 ;左上:上下文向量
;右:通过外积
得到的各深度特征。
4.3 Splat:柱体池化的多视图特征融合
Splat 步骤的核心是将所有相机的视锥体点云融合到统一的 BEV 网格中,通过柱体池化(Pillar Pooling)实现高效的特征聚合,并满足排列不变性与等变性要求。
4.3.1 柱体定义与点云映射
BEV 网格的尺寸为 (范围 -50m 到 50m,网格分辨率 0.5m × 0.5m)。定义 "柱体(Pillar)" 为 BEV 网格中沿高度方向无限延伸的立方体(即忽略 3D 点的高度信息,仅保留水平坐标
)。
利用相机内参 和外参
,将每个相机视锥体中的 3D 点
映射到 BEV 坐标系的
位置,进而分配到对应的柱体中。
4.3.2 高效柱体求和池化
为解决大规模点云的池化效率问题,论文采用 "累积和技巧(Cumulative Sum Trick)" 替代传统的填充 - 池化操作,步骤如下:
- 按柱体 ID 对所有点云特征排序;
- 对特征进行累积和计算;
- 通过柱体边界的累积和差值得到每个柱体的求和特征。
该方法的优势在于:
- 避免填充导致的内存浪费;
- 可推导解析梯度,训练速度提升 2 倍;
- 求和池化天然满足排列不变性(相机顺序不影响求和结果)。
最终,Splat 步骤输出 BEV 特征图(尺寸为 ),可直接输入 BEV CNN 进行语义推理。
4.4 Shoot:基于轨迹模板的端到端运动规划
Shoot 步骤的核心是利用 BEV 特征图学习空间代价函数,通过 "投射轨迹模板" 实现可解释的端到端运动规划,将感知与规划紧密结合。
4.4.1 轨迹模板生成
通过对大规模专家轨迹进行 K-Means 聚类(),生成 1000 个轨迹模板
,每个模板
表示一条 5 秒长(时间步长 0.25s)的 ego 车运动轨迹,如图 5 所示:
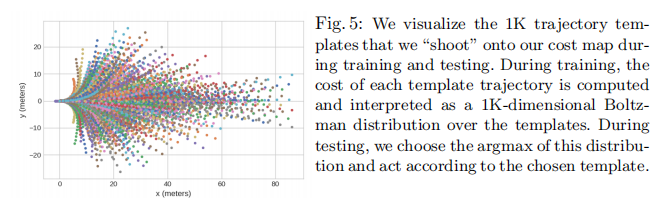
训练与测试阶段均使用该模板集合,通过代价函数选择最优轨迹。
4.4.2 代价函数与概率建模
将规划问题转化为轨迹模板的分类任务:给定 BEV 特征图预测的代价图 (
位置的通行代价),每条轨迹
的代价为其路径上所有 BEV 网格的代价之和。轨迹的概率分布定义为:
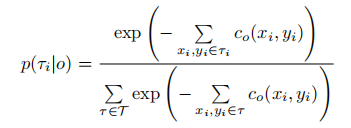
训练目标为最大化专家轨迹的对数概率:
- 对于每个样本,找到与 ground-truth 轨迹 L2 距离最近的模板作为正样本;
- 使用交叉熵损失优化模型,使网络学习到符合驾驶规则的代价函数(如车道边界代价高、障碍物区域代价高)。
该设计的优势在于:
- 可解释性:最优轨迹来自明确的模板集合,便于调试与安全验证;
- 端到端训练:代价图与轨迹选择共享梯度,感知与规划协同优化;
- 无需手动设计代价函数:通过数据驱动自动学习驾驶规则。
4.5 网络架构细节
整个模型的网络结构分为两部分:
- 图像骨干网络:EfficientNet-B0(预训练于 ImageNet),输出每个像素的上下文向量
- BEV 骨干网络:基于 ResNet-18 改进,流程为:
- 7×7 卷积(步长 2)+ BatchNorm + ReLU;
- ResNet-18 的前 3 个元层,得到 3 个不同分辨率的 BEV 特征图
- 最终上采样 2 倍,输出与原始 BEV 网格尺寸一致的特征图。
模型总参数量为 14.3M,在 Titan V GPU 上的前向推理速度为 35Hz,满足自动驾驶实时性要求。
五、实验与结果分析
论文在 nuScenes 和 Lyft Level 5 两个大型自动驾驶数据集上进行了全面实验,验证了模型在 BEV 语义分割、鲁棒性、泛化性和运动规划任务上的性能。
5.1 实验设置
- 数据集:
- nuScenes:1000 个场景(每个 20 秒),6 个相机(前、前左、前右、后左、后右、后),包含 3D 边界框和地图标注;
- Lyft Level 5:无标准训练 / 验证分割,手动划分 48 个场景作为验证集(6048 个样本),相机配置与 nuScenes 不同。
- 任务定义:
- 目标分割:车辆分割(nuScenes 包含 car 类;Lyft 包含 car、truck 等)、汽车分割(仅 car 类);
- 地图分割:可行驶区域分割、车道线分割;
- 运动规划:预测与 ground-truth 轨迹 L2 距离最近的模板(Top-5/10/20 准确率)。
- 训练细节:Adam 优化器(学习率 1e-3,权重衰减 1e-7),训练 300k 步,二元交叉熵损失(车道线分割正样本权重 5.0,其余为 1.0)。
5.2 BEV 语义分割结果
5.2.1 目标分割性能
表 1 展示了不同模型在 nuScenes 和 Lyft 数据集上的目标分割 IOU 结果:
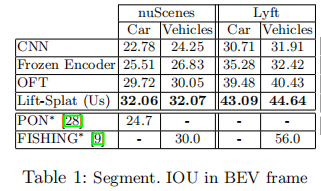
注:* 表示并发工作,Lyft 数据集的分割定义与本文不同,仅作参考。
关键结论:
- 本文模型在所有任务上超越 CNN 基线、冻结编码器和 OFT,验证了 "隐式深度分布 + 几何融合" 的有效性;
- 相比 OFT,本文模型通过深度分布加权解决了 "像素特征与深度无关" 的缺陷,提升显著;
- 并发工作 PON 和 FISHING 的性能低于本文模型,证明了架构设计的优越性。
5.2.2 地图分割性能
表 2 展示了地图分割任务的 IOU 结果:
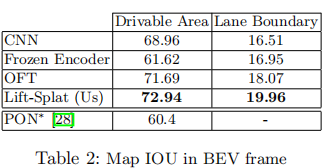
关键结论:
- 本文模型在可行驶区域分割(72.94)和车道线分割(19.96)上均达到最优;
- 车道线分割任务的绝对 IOU 较低,原因是车道线在 BEV 中占比小(长细结构),但本文模型相比基线仍有 3.45 个百分点的提升,证明了特征融合的有效性。
5.3 鲁棒性分析
5.3.1 传感器噪声与 dropout 鲁棒性
论文通过两个实验验证模型的鲁棒性:
- 外参噪声:训练时为相机外参添加不同程度的高斯噪声,测试时评估性能变化(图 6a);
- 相机 dropout:训练时随机丢弃 1 个相机,测试时评估不同数量相机缺失的性能(图 6b)。
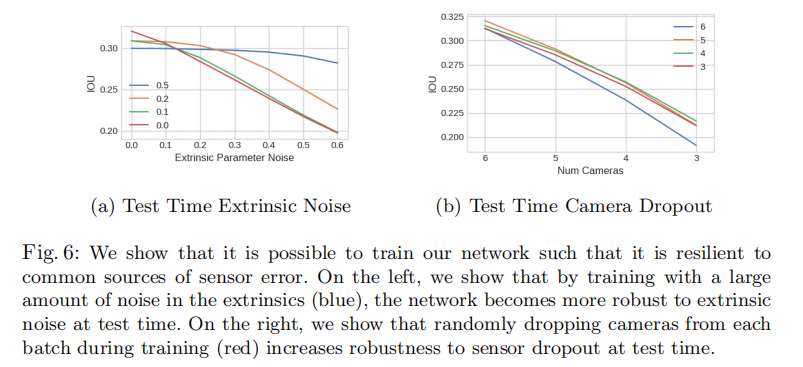
左:外参噪声鲁棒性;右:相机 dropout 鲁棒性。
关键结论:
- 训练时添加外参噪声的模型(蓝色曲线)在测试时面对高噪声时性能下降更少,证明模型可通过数据增强提升对校准误差的鲁棒性;
- 训练时随机丢弃相机的模型(红色曲线)在测试时相机缺失的情况下性能更优,类似 Dropout 正则化,强制模型学习跨相机特征相关性。
5.3.2 相机重要性分析
图 7 展示了单个相机缺失时汽车分割 IOU 的变化:

右侧 "full" 表示所有相机正常工作的性能,其余为单个相机缺失的性能。
关键结论:
- 后向相机(Backwards)缺失导致性能下降最显著,原因是其视野最广,覆盖 ego 车后方大范围区域;
- 前向相机(Forward)缺失后,模型可通过其他相机(如前左、前右)的部分视野 extrapolate 车道线和障碍物,性能下降相对较小(图 8 定性结果)。

从上到下:正常情况、前向相机缺失、后向相机缺失、前左相机缺失。缺失相机覆盖区域的预测结果变得模糊,但模型仍能部分补全。
5.4 泛化性分析
5.4.1 零样本相机 rig 迁移
实验 1:训练时仅使用 nuScenes 6 个相机中的 4 个,测试时添加未见过的相机(前左 / 后左),结果如表 3 所示:

关键结论:添加未训练过的相机后,性能持续提升,证明模型可零样本利用新增传感器的信息,无需重新训练。
实验 2:在 nuScenes 上训练,直接迁移到 Lyft 相机 rig(相机配置完全不同),结果如表 4 所示:

关键结论:
- 所有模型迁移后性能均下降,但本文模型的下降幅度最小,且领先基线的优势进一步扩大;
- 证明模型学习到的是相机几何与场景语义的通用关系,而非特定相机 rig 的特征,泛化性更强。
5.5 与激光雷达 Oracle 深度的对比
将本文模型与使用激光雷达真实深度的 PointPillars 模型对比,结果如表 5 所示:
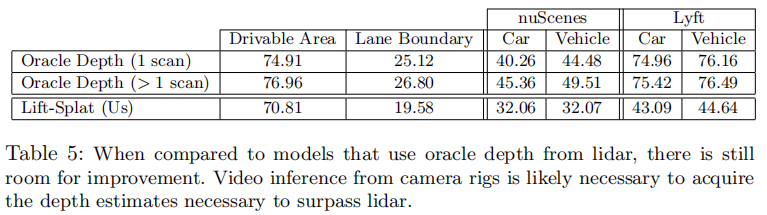
关键结论:
- 本文模型(纯视觉)在可行驶区域分割上接近激光雷达模型(70.81 vs 74.91),证明视觉融合可提取高精度的道路结构信息;
- 在目标分割上仍有差距(32.06 vs 40.26),原因是激光雷达提供精确的 3D 位置,而视觉深度分布存在不确定性;
- 多帧激光雷达的性能进一步提升,暗示未来可通过多帧视觉序列建模缩小差距。
5.5.1 性能随距离与天气的变化
图 10 展示了汽车分割 IOU 随目标距离和天气的变化:
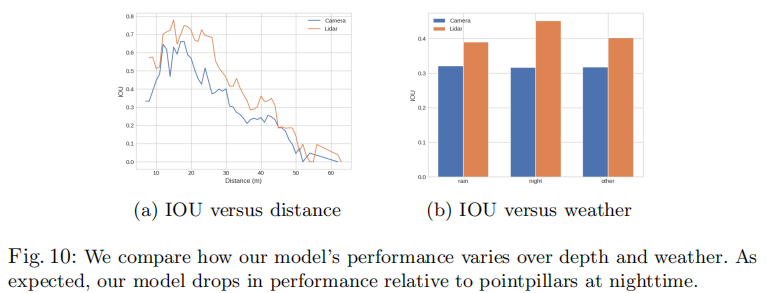
左:距离 ego 车的距离;右:天气条件(晴朗 / 多云 / 雨天 / 夜晚)。
关键结论:
- 随目标距离增加,本文模型与激光雷达模型的性能均线性下降,但本文模型下降更快,原因是远距离像素的深度歧义性更强;
- 夜晚场景中,本文模型性能下降显著(IOU 约 25),而激光雷达不受光照影响(IOU 约 35),证明光照是纯视觉感知的主要瓶颈。
5.6 运动规划结果
表 6 展示了运动规划任务的 Top-5/10/20 准确率:

关键结论:
- 本文模型性能低于激光雷达模型,但已能学习到基本的驾驶规则(如沿车道行驶、避让障碍物);
- 多帧激光雷达的性能提升显著,证明时序信息对规划至关重要,未来可通过多帧视觉融合进一步优化。
定性结果如图 11 所示:

红色为 Top-1 轨迹,蓝色为 Top-10 轨迹。模型能预测低速通过人行横道、跟随前车等合理轨迹。
六、结论与未来工作
6.1 核心贡献总结
Lift, Splat, Shoot 架构的核心贡献在于:
- 提出了 "Lift-Splat-Shoot" 三步流程,实现了从多视图相机到 BEV 语义表示的端到端可微分映射,天然满足多视图感知的三大对称性;
- 通过隐式深度分布(
- 设计了高效的柱体池化与累积和技巧,保证了模型的实时性;
- 首次将纯视觉 BEV 表示用于可解释的端到端运动规划,实现了感知与规划的协同优化。
6.2 局限性与未来方向
论文指出的局限性及未来改进方向:
- 纯视觉深度估计的精度不足,导致远距离目标分割性能落后于激光雷达,未来可融合多帧视觉序列提升深度估计精度;
- 夜晚等恶劣光照条件下性能下降显著,需结合夜视增强、多传感器融合(如毫米波雷达)解决;
- 运动规划依赖固定轨迹模板,灵活性不足,未来可探索动态轨迹生成与模板自适应更新。
6.3 行业影响
该论文为自动驾驶纯视觉感知提供了重要的技术范式,其核心思想已被后续众多工作借鉴(如 BEVFormer、PETR 等),推动了纯视觉 BEV 感知的快速发展。特别是在激光雷达成本较高的场景下,该架构为低成本自动驾驶方案提供了可行的技术路径。
七、附录:关键术语与公式汇总
7.1 关键术语
- BEV(Bird's-Eye-View):鸟瞰图坐标系,以 ego 车为中心的俯视图网格;
- 视锥体(Frustum):相机可观测的 3D 空间区域,由相机内参和外参定义;
- 柱体(Pillar):BEV 网格中沿高度方向无限延伸的立方体,用于聚合 3D 点云特征;
- 深度分布(Depth Distribution):每个像素的深度概率分布 \(\alpha\),用于加权生成 3D 特征。
7.2 核心公式
- 3D 点特征计算:
- 轨迹概率分布:
Lift, Splat, Shoot 论文在自动驾驶纯视觉 BEV 感知领域做出了突破性贡献。其架构设计既考虑了多视图几何约束,又通过端到端训练充分利用了数据驱动的优势,为后续相关研究提供了坚实的基础与丰富的启发。