C++ 并发双阶段队列设计原理与实现
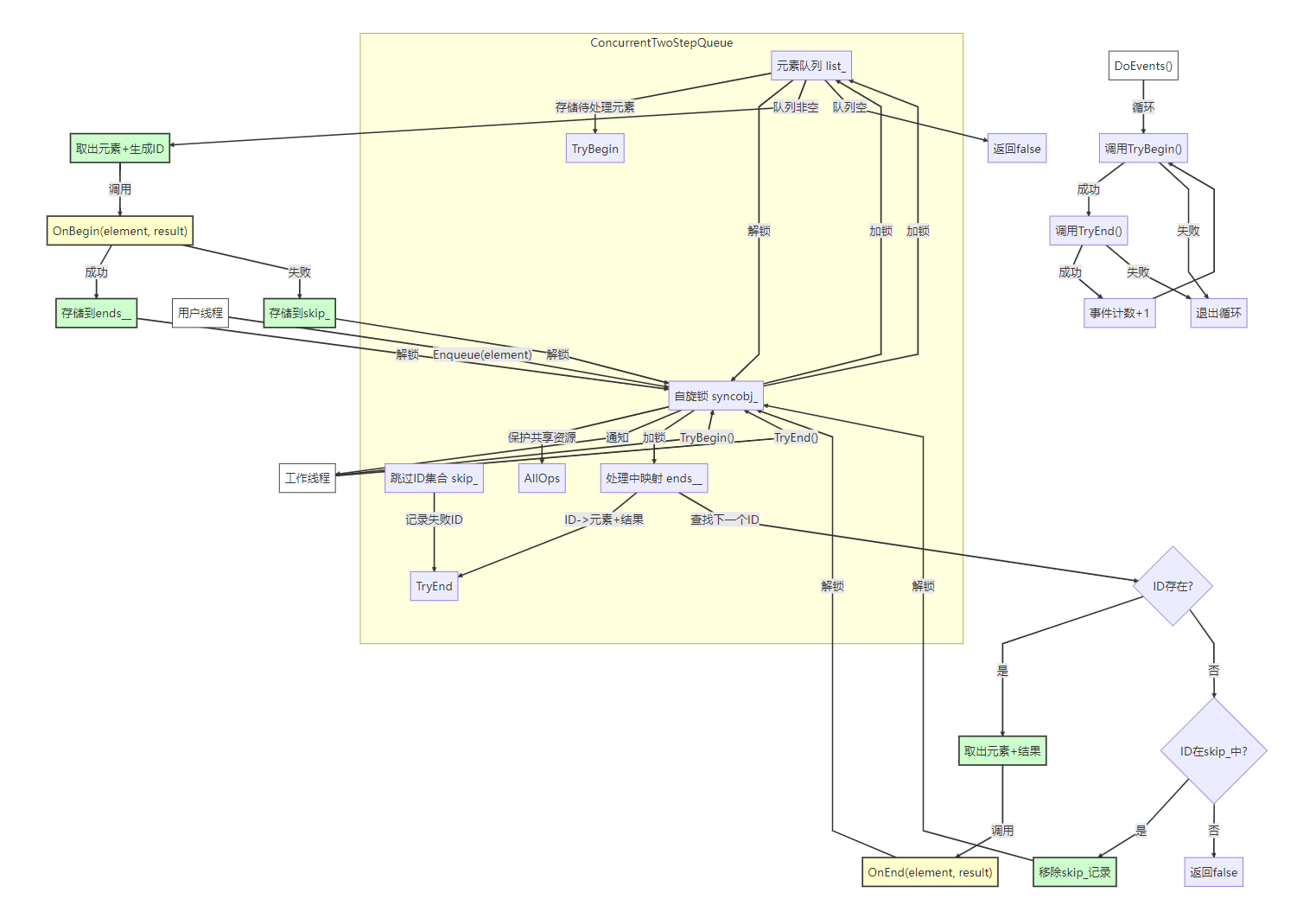
一、设计思想
该队列采用双阶段处理模型 ,通过锁机制实现线程安全,核心思想包含:
- 阶段隔离:入队(Enqueue)与处理(TryBegin/TryEnd)分离
- 原子操作:通过SpinLock保证关键段操作的原子性
- 状态跟踪:使用ID序列追踪任务处理状态
- 异常隔离:虚函数设计允许自定义处理逻辑
成功 成功 Enqueue 添加元素到list_ TryBegin 生成任务ID 保存到ends__ TryEnd 调用OnEnd处理
二、数据结构
1. 核心成员变量
| 成员变量 | 类型 | 作用 |
|---|---|---|
list_ |
chtrader::list<TElement> |
存储待处理元素 |
ends__ |
unordered_map<int, ConcurrencyEndValue> |
存储处理中的任务状态 |
skip_ |
unordered_set<int> |
记录失败的任务ID |
syncobj_ |
SpinLock |
同步控制对象 |
2. 状态流转图
Enqueue元素 TryBegin获取任务 TryEnd成功 OnBegin失败 跳过任务 Idle Processing Completed Failed
三、流程分析
1. 入队流程 (Enqueue)
cpp
virtual void Enqueue(TElement&& element) noexcept {
SynchronizeObjectScope scope(syncobj_);
list_.emplace_back(std::move(element));
}- 同步控制:通过SpinLock保护list_的push操作
- 无拷贝设计 :使用
std::move实现元素移动语义 - 线程安全:保证多线程环境下的入队操作安全
2. 任务获取流程 (TryBegin)
cpp
virtual bool TryBegin() noexcept {
TElement element;
int id;
for (SynchronizeObjectScope scope(syncobj_);;)
{
auto tail = list_.begin();
auto endl = list_.end();
if (tail == endl)
{
return false;
}
id = ++ends_id_inc_;
element = std::move(*tail);
list_.erase(tail);
break;
}
ConcurrencyEndValue value;
value.element = std::move(element);
if (!OnBegin(value.element, value.result))
{
SynchronizeObjectScope scope(syncobj_);
skip_.emplace(id);
return false;
}
for (SynchronizeObjectScope scope(syncobj_);;)
{
auto r = ends__.emplace(std::make_pair(id, std::move(value)));
return r.second;
}
}- 双重检查:通过自增ID确保任务唯一性
- 预处理机制:通过虚函数OnBegin实现自定义校验
- 异常处理:失败任务ID存入skip_集合
3. 任务处理流程 (TryEnd)
cpp
virtual bool TryEnd() noexcept {
ConcurrencyEndValue value;
for (SynchronizeObjectScope scope(syncobj_);;)
{
int next_id = ends_id_ + 1;
auto tail = ends__.find(next_id);
auto endl = ends__.end();
if (tail == endl)
{
auto skip_tail = skip_.find(next_id);
auto skil_endl = skip_.end();
if (skip_tail != skil_endl)
{
ends_id_ = next_id;
skip_.erase(skip_tail);
return true;
}
return false;
}
value = std::move(tail->second);
ends_id_ = next_id;
ends__.erase(tail);
break;
}
return OnEnd(value.element, value.result);
}- 顺序保证:通过ID自增保证处理顺序
- 状态清理:处理完成后立即删除记录
- 结果传递:通过引用参数返回处理结果
四、并发控制
1. 锁粒度
35% 45% 20% 锁粒度分布 list_操作 ends__操作 skip_操作
2. 优化点
- 批量处理:DoEvents()循环处理多个任务
- 内存预分配:list_使用连续内存存储
- 快速失败:skip_集合快速跳过无效任务
五、应用场景
Enqueue 生产者线程 ConcurrentTwoStepQueue 任务处理 IO密集型任务 计算密集型任务 异步存储 实时计算
六、源代码
cpp
#pragma once
// 包含预编译头文件(提高编译效率)
#include <chtrader/stdafx.h>
// 包含自旋锁实现(用于线程同步)
#include <chtrader/threading/SpinLock.h>
namespace chtrader
{
namespace collections
{
// 并发双阶段队列模板类
// TElement: 队列元素类型
// TResult: 处理结果类型
// SynchronizeObject: 同步机制类型(默认使用自旋锁)
template <typename TElement, typename TResult, class SynchronizeObject = chtrader::threading::SpinLock>
class ConcurrentTwoStepQueue
{
// 用于存储待处理元素及其处理结果的结构体
struct ConcurrencyEndValue
{
TElement element; // 原始元素
TResult result; // 处理结果
};
// 锁作用域类型别名(简化锁管理)
using SynchronizeObjectScope = std::lock_guard<SynchronizeObject>;
public:
// 默认构造函数
ConcurrentTwoStepQueue() noexcept { }
// 析构函数(确保所有事件被处理)
virtual ~ConcurrentTwoStepQueue() noexcept
{
Clear();
}
// 入队操作(线程安全)
void Enqueue(TElement&& element) noexcept
{
SynchronizeObjectScope scope(syncobj_); // 加锁
size_++;
list_.emplace_back(std::move(element)); // 移动元素到队列尾部
}
// 开始处理元素(尝试获取下一个元素)
bool TryBegin() noexcept
{
TElement element;
int sequence;
// 循环尝试获取元素
for (SynchronizeObjectScope scope(syncobj_);;)
{
auto tail = list_.begin(); // 获取队列头部迭代器
auto endl = list_.end(); // 获取队列尾部迭代器
if (tail == endl) // 队列为空时返回失败
{
return false;
}
sequence = ++ends_inc_; // 生成唯一ID
element = std::move(*tail); // 移动元素值
list_.erase(tail); // 从队列中移除元素
break; // 退出循环
}
// 存储待处理元素及其结果
ConcurrencyEndValue value;
value.element = std::move(element);
// 执行前置处理逻辑(需子类实现)
bool initiate = OnBegin(value.element, value.result);
if (unlikely(!initiate))
{
SynchronizeObjectScope scope(syncobj_);
auto r = skip_.emplace(sequence);
assert(r.second);
return r.second;
}
// 存储到处理中的队列
for (SynchronizeObjectScope scope(syncobj_);;)
{
auto r = ends__.emplace(std::make_pair(sequence, std::move(value)));
assert(r.second);
return r.second;
}
}
// 结束处理元素(尝试获取下一个待处理结果)
bool TryEnd() noexcept
{
ConcurrencyEndValue value;
for (SynchronizeObjectScope scope(syncobj_);;)
{
auto ack = ends_ack_.load(std::memory_order_acquire);
auto ends_tail = ends__.find(ack); // 查找对应ID的元素
if (ends_tail == ends__.end()) // 未找到时检查跳过集合
{
auto skip_tail = skip_.find(ack);
if (skip_tail != skip_.end()) // 存在跳过记录则移除
{
skip_.erase(skip_tail);
size_.fetch_sub(1, std::memory_order_release);
ends_ack_.fetch_add(1, std::memory_order_release);
return true; // 表示跳过成功
}
return false; // 队列空且无跳过项时返回失败
}
value = std::move(ends_tail->second); // 获取元素值
ends__.erase(ends_tail); // 从处理队列中移除
size_.fetch_sub(1, std::memory_order_release);
ends_ack_.fetch_add(1, std::memory_order_release);
// 执行后置处理逻辑(需子类实现)
OnEnd(value.element, value.result);
return true;
}
}
// 处理所有可用事件(批量处理)
int DoEvents() noexcept
{
for (int events = 0;;)
{
TryBegin();
if (TryEnd())
{
events++;
}
else
{
return events; // 返回处理的事件总数
}
}
}
// 清空队列
void Clear() noexcept
{
chtrader::unordered_map<int, ConcurrencyEndValue> ends;
chtrader::unordered_set<int> skip;
chtrader::list<TElement> list;
for (SynchronizeObjectScope scope(syncobj_);;)
{
list = std::move(list_);
skip = std::move(skip_);
ends = std::move(ends__);
list_.clear();
skip_.clear();
ends__.clear();
break;
}
}
int Count() noexcept { return size_.load(std::memory_order_acquire); }
protected:
// 前置处理回调(需子类实现具体逻辑)
virtual bool OnBegin(const TElement& element, TResult& output) noexcept = 0;
// 后置处理回调(需子类实现具体逻辑)
virtual void OnEnd(const TElement& element, const TResult& result) noexcept = 0;
private:
SynchronizeObject syncobj_; // 同步锁对象
chtrader::list<TElement> list_; // 底层元素队列
chtrader::unordered_set<int> skip_; // 跳过处理的ID集合
std::atomic<int> size_ = 0; // 数量
std::atomic<int> ends_ack_ = 1; // 当前处理的ID
std::atomic<int> ends_inc_ = 0; // ID递增计数器
chtrader::unordered_map<int, ConcurrencyEndValue> ends__; // 处理中的元素映射
};
}
}