abstract
分词转编号、词嵌入和位置编码
每个token其实是行向量,然后其实是E*WQ,不是WQ*E。
1 GPT中的Transformer架构
GPT是Generative Pre-trained Transformer单词的缩写,其中transformer是一种特定的神经网络,这里的单词是transformer不是transform.
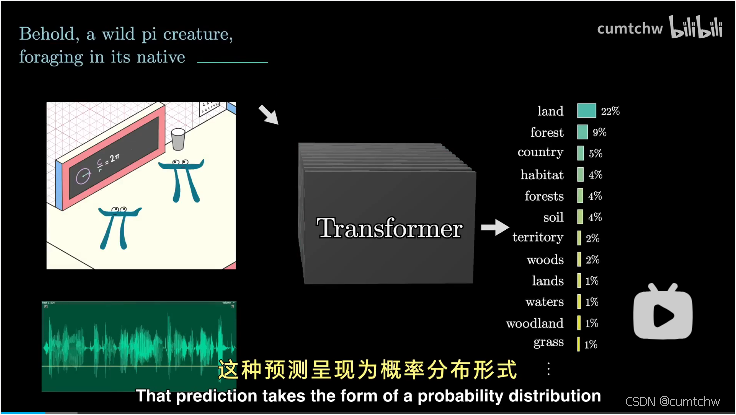
GPT其实就是输入一段文章,然后也可能包含了图像以及语音输入,然后预测接下来的下一个单词是什么,这样不断的预测下去,一直重复这个过程,就能生成一段文字或者回答。
当我们输入一段文字,然后让transformer去预测的时候,大体的要经历下面的几个过程。
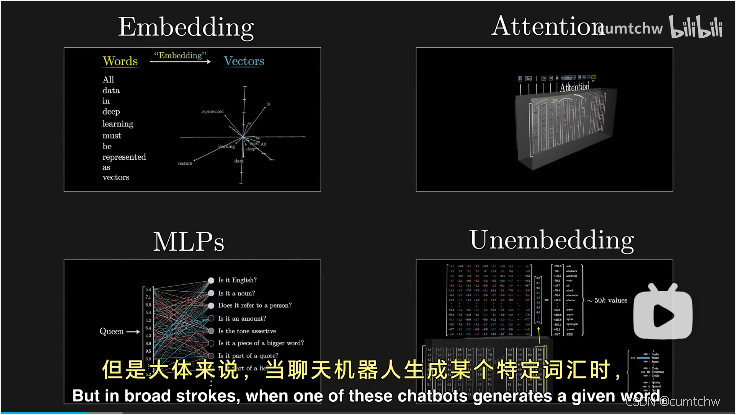
当聊天机器人生成某个特定词汇时,首先输入内容会被拆分成许多小片段,




如果输入是图像或者语音,那么token可能代表图像的一小块区域,或者语音的一个片段,

其实这里每个token对应的是行向量,因为后面实际计算注意力机制的时候,多个token组成一个矩阵E,然后E要去和查询矩阵Wq以及键矩阵Wk相乘,那么只有是行向量的时候,这样矩阵相乘的时候,E矩阵的一行正好对应着一个token向量,
视频中这里每个token对应的是一个列向量纯粹是为了方便表示,但是实际上计算的时候我们用的都是行向量。

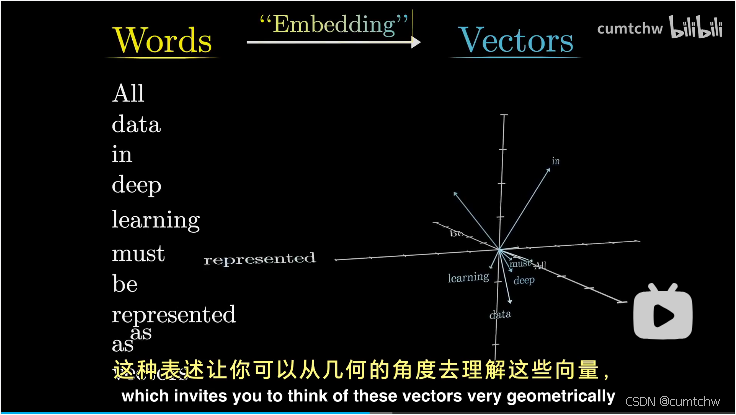
如果把这些向量看作是在一个高维空间中的坐标,那么含义相似的词汇倾向于彼此接近的向量上,

这些向量接下来会经过一个称为注意力块的处理过程,使得向量能够相互交流,


注意力模块的作用就是要确定上下文中哪些词对更新其他词的意义有关,以及应该如何准确地更新这些含义。比如说model这个单词在learning model和fashion model中的含义是不同的,注意力机制的作用的就是要确定上下文中哪些单词对更新其他词的意义有关,以及应该如何准确的更新这些含义。

词语的所谓含义完全通过向量中的数字来表达。然后这些向量会经过另一种处理,这个过程根据资料的不同,可能被称作多层感知机或者前馈层,这个阶段向量不在互相交流,而是并行地经历同一处理。
这个多层感知器其实就是
FFN(x) = W₂ · Activation(W₁ x + b₁) + b₂
其实就是先是经过线性变换,改变特征维度,然后引入激活函数,最后再通过线性变换将特征维度恢复到之前的维度。

然后实际网络中,这里的注意力机制和多层感知会有多层,也就是经历过很多个的注意力模块和多层感知机模块,然后对这最后一个向量进行特定操作,产生一个覆盖所有可能token的概率分布,


然后它就可以根据一小段文本预测下一步,给他一段初始文本,然后让他不断地进行预测下一步, 从概率分布中抽样,添加到现有文本, 然后不断地重复这个过程,就能生成一段文本。
将上面的工具转化为聊天机器人的一个简单方法就是准备一段文本,设定出用户与一个有帮助的AI助手交互的场景,这就是所谓的系统提示。
然后可以用用户的问题或者提示词作为开头,然后让他不断的生成相应的回答,
文本处理示例第一步:将输入分割成单词
模型拥有一个预设的词汇库,包含所有可能的单词,输入首先遇到一个矩阵叫做embedding嵌入矩阵,他为每个单词都分配了一个独立的列
视频中只是简单的说把单词转成向量,但是这里其实是有好几步的,
第一步先是分词,也就是将一个句子分成多个token,这里的token可能是一个单词,可能有的单词会被分成多个token,还有就是标点符号也被分成token,这是第一步分词
第二步是转编号,就是每个token要转成对应的ID,相当于有个字典,记录着ID和token的对应关系,这是第二步
第三步才是词嵌入,也就是根据ID将token转成向量表示,这里可以不用查表,比如可以直接嵌入矩阵的第0行就是ID为0的token对应的向量表示,
第四步其实还有个位置编码,就是每个token最终的实际向量表示出了他本身的嵌入向量以外,还会给他增加位置信息。

这些列定义了第一部中每个单词转换成的向量。
这里实际计算的时候用的是行,具体原因前面已经解释过了。

这些嵌入空间中的向量,不仅仅代表着单个单词,他们还携带了词汇位置的信息,这些词汇能吸纳并反映语境。
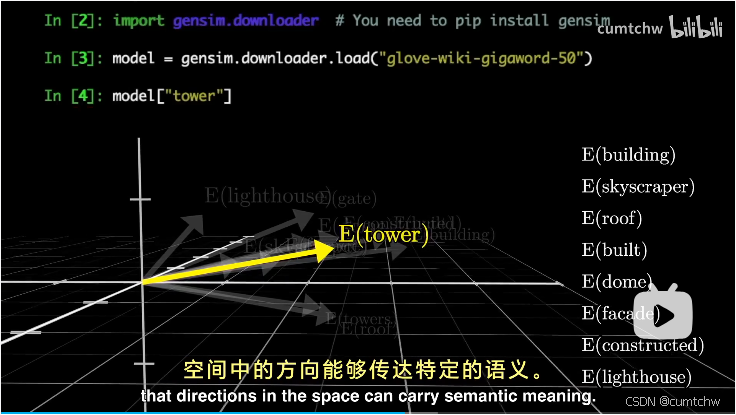
如果从几何层面去理解这些嵌入向量,模型训练时候调整嵌入向量的权重,就可以理解为训练完之后,在这个多维空间中,单词意思相近的嵌入向量,他们的向量方向更接近
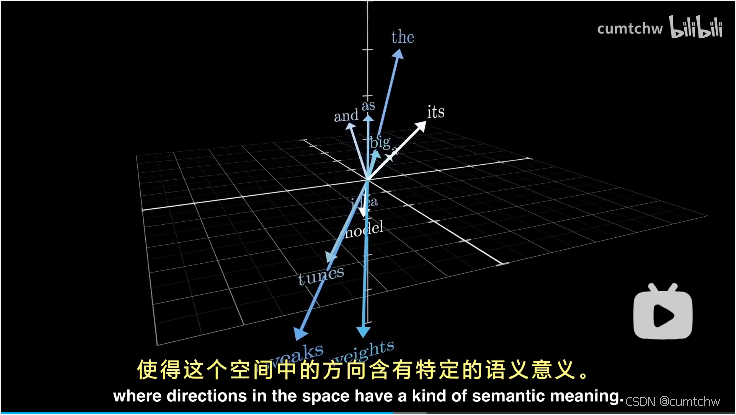
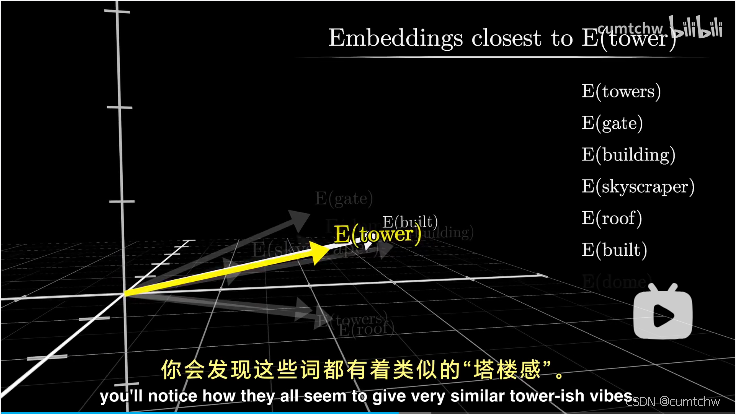
也就是理解成空间中方向代表着具体的语义含义
一个更具体的例子就是,如果计算男人和女人这两个向量差的话,那么这个差值跟国王和女王之间的差值很接近。

另外,这里还有一个比较重要的概念就是向量的点积,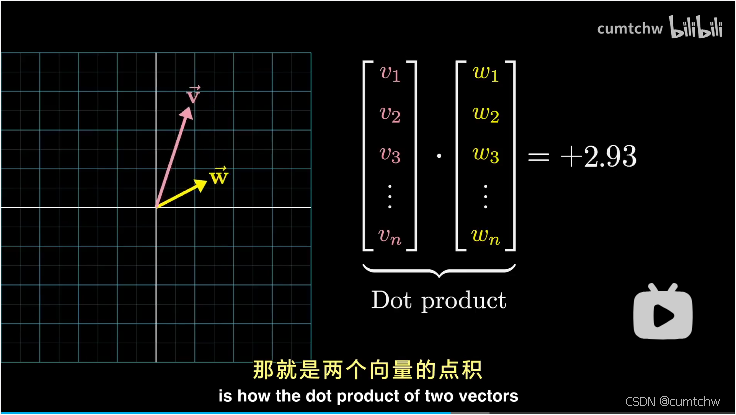
如果向量的点积结果大于0,那么说明两个向量指向相似方向;
如果向量的点积结果为0,那么说明两个向量垂直;
如果向量的点积结果小于0,那么说明两个向量方向相反;
参考文献:
图形化的理解GPT中的Transformer架构_哔哩哔哩_bilibili
什么是GPT?通过图形化的方式来理解 Transformer 中的注意力机制_哔哩哔哩_bilibili
https://www.bilibili.com/video/BV1Di4y1c7Zm?vd_source=ad92041b1b4452eed564be6b47d7237d