论文名称:Attention GhostUNet++: Enhanced Segmentation of Adipose Tissue and Liver in CT Images
> 论文原文 (Paper) :https://arxiv.org/abs/2504.11491
> 代码 (code) :https://github.com/MansoorHayat777/Attention-GhostUNetPlusPlus
GitHub 仓库链接(包含论文解读及即插即用代码) :https://github.com/AITricks/AITricks
哔哩哔哩视频讲解 :https://space.bilibili.com/57394501?spm_id_from=333.337.0.0
目录
-
- 论文精度:AttentionGhostUnet++
-
- [1. 核心思想](#1. 核心思想)
- [2. 背景与动机](#2. 背景与动机)
- [3. 主要贡献点](#3. 主要贡献点)
- [4. 方法细节](#4. 方法细节)
- [5. 即插即用模块的作用](#5. 即插即用模块的作用)
- [6. 实验结果总结与分析](#6. 实验结果总结与分析)
- [7. 获取即插即用代码关注 【AI即插即用】](#7. 获取即插即用代码关注 【AI即插即用】)
论文精度:AttentionGhostUnet++
1. 核心思想
- 本文提出了一种名为 Attention GhostUNet++ 的新型深度学习架构,专用于 CT 图像中腹部脂肪组织(SAT 和 VAT)与肝脏的精确分割。
- 其核心思想是将 GhostUNet++ (一种计算高效的 U-Net 变体)与一个新颖的三维注意力机制相结合。
- 具体的创新在于,模型将通道(Channel)、空间(Spatial)和深度(Depth)注意力机制并行地集成到了 Ghost UNet++ 网络的**瓶颈层(Bottleneck)**中。
- 这种设计旨在利用 Ghost 模块的计算效率 ,同时通过多维度的注意力来增强特征精炼 和上下文理解能力,从而在保持高效的同时,实现比基线模型更高的分割精度。
2. 背景与动机
-
准确分割腹部脂肪(皮下脂肪 SAT 和内脏脂肪 VAT)及肝脏,对于临床理解身体成分、评估和管理如 2 型 diabetes、心血管疾病等心脏代谢疾病 的风险至关重要。然而,手动分割 CT 图像耗时耗力,依赖专家经验,难以应用于大规模研究。因此,开发高效且精准的自动分割模型是临床亟需。
现有的深度学习模型(如 U-Net)在分割上取得了成功,但面临两大挑战:
- 计算效率低下: 传统 CNN 在生成高维特征图时计算量巨大。
- 特征表达局限: 简单的卷积操作可能无法充分捕捉复杂的解剖结构边界和上下文信息,尤其是在处理边界模糊的脂肪组织时。
GhostUNet 通过"幽灵模块"(Ghost Module)来减少特征图的冗余,解决了计算效率的问题,但其特征精炼能力仍有提升空间。
-
动机图解分析(Figure 1):
-
图表 A (Figure 1 - 整体架构图):问题(效率)与方案(结构)的融合
- "看图说话": 该图展示了一个 UNet++ 架构(具有嵌套和密集的跳跃连接,如灰色虚线所示)。这种结构本身就是为了通过多尺度特征融合来提升分割精度。
- 分析: 论文要解决的核心问题是效率 和精度 的平衡。
- 效率问题 (Efficiency Bottleneck): 架构图中的基础模块是
G-bneck(Ghost Bottleneck)和AG-bneck(Attention Ghost Bottleneck)。G-bneck(灰色块)源自 GhostNet,其设计(如论文公式 1-2 所述)旨在通过廉价的线性操作生成"幽灵特征图",从而大幅降低计算冗余和成本。 - 精度问题 (Accuracy Bottleneck): 仅仅高效是不够的。模型需要在关键位置(主干编码器和解码器路径)进行强力的特征提炼。
- 效率问题 (Efficiency Bottleneck): 架构图中的基础模块是
- 结论: 架构图(Figure 1 左侧)展示了如何将"效率"(Ghost)和"精度"(UNet++)结合。而图 1 右侧的
Attention Ghost Module则展示了解决"精度瓶颈"的核心创新 :它不是一个标准的 Ghost 模块,而是一个被注意力强化了的模块(AG-bneck)。
-
图表 B (Figure 1 - Attention Ghost Module):解决"精度瓶颈"
- "看图说话": 这是本文最核心的创新点图解。它展示了"注意力幽灵模块"的内部结构。
- 分析: 该模块接收"输入"(Input)特征,并将其并行 送入三个独立的注意力流:
Channel Attention(通道注意力):关注"什么"特征是重要的。Spatial Attention(空间注意力):关注"哪里"的特征是重要的。Depth Attention(深度注意力):(鉴于 CT 是 3D 数据)这很可能是一种沿着切片(Z轴)方向的注意力,关注"哪层"特征是重要的。
- 结论: 这三个流的输出( V c , V s , V d V_c, V_s, V_d Vc,Vs,Vd)被聚合并产生最终的"输出"(Output)。这清晰地表明了模型的动机:标准 Ghost 模块虽然高效,但在特征表达上是"被动"的;而
Attention Ghost Module是"主动 "的,它在保持高效的同时,从三个正交的维度(什么、哪里、哪层)上动态地重新校准(recalibrate)特征,从而极大地增强了特征的精炼能力和上下文理解能力。
-
3. 主要贡献点
- 提出 Attention GhostUNet++ 架构: 提出了一种新颖的分割网络,它将 Ghost UNet++ 的高效率与 U-Net++ 的强大多尺度融合能力相结合。
- 设计三维注意力幽灵模块 (AG-bneck): 这是核心创新。设计了一个新的瓶颈模块,该模块并行集成了通道(Channel)、空间(Spatial)和深度(Depth)注意力。这种设计使得模型能够以极高的计算效率,从三个维度全面精炼特征,抑制冗余信息。
- 实现了高精度与高效率的平衡: 该模型在实现 SOTA 级分割精度的同时,继承了 Ghost 模块的计算效率优势,使其成为一个适用于大规模临床和研究的鲁棒解决方案。
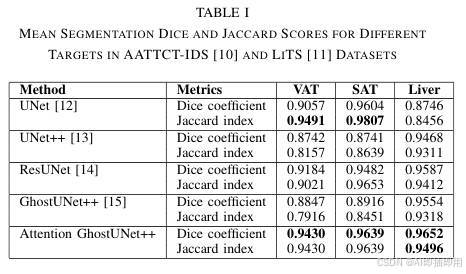
- 在多数据集上验证了 SOTA 性能: 在 AATTCT-IDS 和 LiTS 数据集上进行了评估,Attention GhostUNet++ 在 SAT、VAT 和肝脏分割任务上的 Dice 系数均达到了 0.94 以上,超越了 UNet、UNet++、ResUNet 和标准 GhostUNet++ 等基线模型。
4. 方法细节
-
整体网络架构(Figure 1 左侧):
- 模型名称: Attention GhostUNet++
- 数据流: 该架构是一个基于 U-Net++ 的嵌套编码器-解码器结构。
- 编码器(Contraction Path/Backbone): 位于架构的最左侧一列 (标记为
Backbone)。它由 L0 到 L4 的AG-bneck(Attention Ghost bottleneck)块组成,通过Down-Sampling(红色箭头)逐步降低分辨率、提取深层特征。 - 解码器(Expansion Path): 位于架构的最右侧一列 。它由 L3 到 L0 的
AG-bneck块组成,通过Up-Sampling(粉色箭头)逐步恢复分辨率。 - 嵌套跳跃连接(Skip Connection): 这是 UNet++ 的核心。除了标准 U-Net 的长跳跃连接(最外层),架构内部的灰色虚线和上采样(粉色箭头)构成了密集的嵌套连接 。
- 例如,
AG-bneck L1(第 1 行第 1 列)不仅从下面的AG-bneck L2(第 2 行第 0 列)接收上采样特征,还从右侧的AG-bneck L0(第 0 行第 2 列)接收特征。 - 关键细节: 如图例所示,本文的创新
AG-bneck(黑色块)主要用于主干编码器 和最终解码器 路径上。而用于中间嵌套融合的块(灰色块)则是标准的G-bneck(Ghost Bottleneck)。这是一种高效的设计:在关键的特征提取和重建路径上使用昂贵但强大的注意力模块,在内部融合路径上使用廉价的 Ghost 模块。
- 例如,
- 输入/输出: CT 图像
Input→ \rightarrow → 经过编码器、解码器和密集的嵌套融合 → \rightarrow →Output(SAT, VAT, Liver 的分割掩码)。
-
核心创新模块详解(Figure 1 右侧):
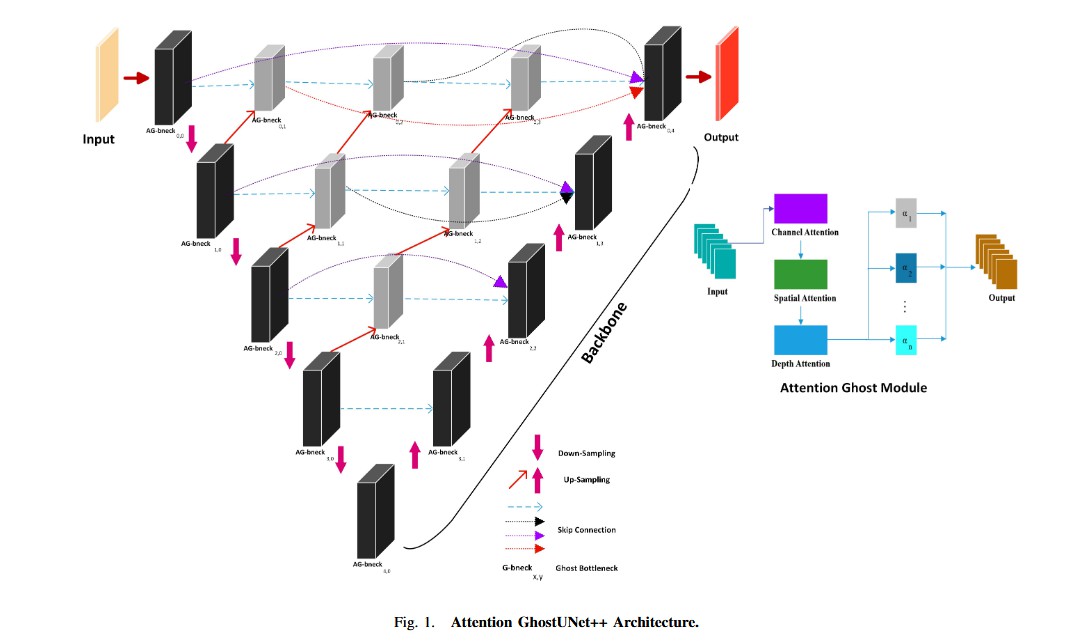
- 模块 A:Attention Ghost Module
- 理念: 这是
AG-bneck的核心。它不是一个单独的层,而是对标准 Ghost 瓶颈模块的增强 。其目的是对 Ghost 模块生成的(高效但可能粗糙的)特征进行多维度的主动精炼。 - 内部结构: 这是一个三分支并行注意力结构。
- 数据流:
Input:来自 Ghost 瓶颈层的特征图。- 并行处理: 输入特征被同时 送入三个独立的注意力机制:
Channel Attention:计算不同通道(特征)之间的相关性,生成一个通道权重向量 V c V_c Vc。它回答了"什么特征更重要?"的问题。Spatial Attention:计算特征图上不同空间位置的相关性,生成一个空间权重图 V s V_s Vs。它回答了"哪里的区域更重要?"的问题。Depth Attention:计算不同深度(CT 切片)之间的相关性,生成一个深度权重向量 V d V_d Vd。它回答了"哪张切片(或哪层特征)更重要?"的问题。
- 聚合: 三个注意力分支的输出( V c , V s , V d V_c, V_s, V_d Vc,Vs,Vd)在蓝色方块处被聚合(通常是元素相加或相乘)。
Output:聚合后的注意力权重被施加到原始输入特征上,得到最终的精炼特征图。
- 设计目的: 标准卷积(包括 Ghost 卷积)在聚合信息时是"被动"的。该模块通过并行引入三种注意力,使得网络能够在保持 Ghost 模块效率的同时,主动地 、动态地学习并强调最重要的特征(从通道、空间和深度三个维度),同时抑制无关的噪声和冗余信息。
- 理念: 这是
- 模块 A:Attention Ghost Module
-
理念与机制总结:
- Ghost Module 机制(基础): 论文首先回顾了 Ghost 模块(公式 1-2)。它的核心是,为了生成 N N N 个特征图,它只用标准卷积生成 N / 2 N/2 N/2 个"内在特征图"( F i F_i Fi),然后通过廉价的线性操作 (如 Ghost 卷积 W ∗ F i W*F_i W∗Fi)来生成另外 N / 2 N/2 N/2 个"幽灵特征图"。这极大地降低了计算成本。
- Attention GhostUNet++ 机制(创新): 本文的架构(公式 3-6)将这一理念与 UNet++ 和注意力结合。
F_o = A(G(F_i, \Theta))(公式 3):输出 F o F_o Fo 是对 Ghost 模块 G G G 的输出应用注意力 A A A 的结果。F_l = P(G(F_{l-1})) + U(G(F_{l+1}))(公式 4, 简化版):这描述了 UNet++ 的嵌套结构,每一层的特征 F l F_l Fl 都融合了来自编码器(下采样 P P P)和解码器(上采样 U U U)的特征。
- 核心: 创新点在于将 A A A (Attention Ghost Module) 集成到了 G G G (Ghost Bottleneck) 中,并将其作为 U-Net++ 架构(Figure 1 左侧)的主要构建块(
AG-bneck)。
-
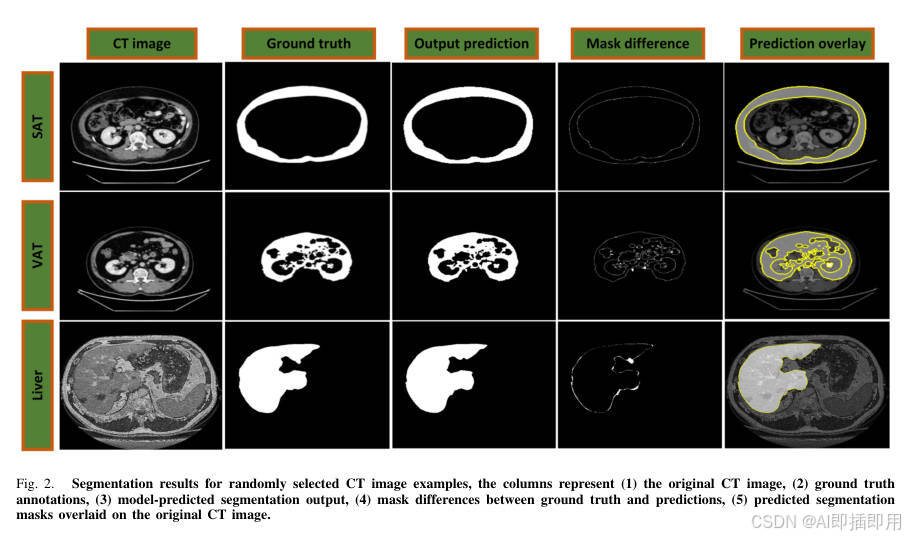
图解总结:
- Figure 2 展示了最终的分割结果(SAT, VAT, Liver),证明了模型的高精度,尤其是"Mask difference"(掩码差异)列显示了模型预测与真实标签之间的误差非常小。
- Figure 1 解释了如何 实现这一点的:
- 为了解决计算效率 问题,采用了
Ghost模块(G-bneck)。 - 为了解决多尺度融合 和精度问题,采用了
UNet++的嵌套架构(Figure 1 左侧)。 - 为了最大化特征精炼能力 (解决 Ghost 模块可能带来的精度损失),设计了
Attention Ghost Module(Figure 1 右侧),通过 Channel、Spatial 和 Depth 三重注意力来强化特征。
- 为了解决计算效率 问题,采用了
- 最终,Attention GhostUNet++(Figure 1)通过将这三者(Ghost + UNet++ + Tri-Attention)结合,协同解决了医学分割中"效率"和"精度"的核心矛盾。
5. 即插即用模块的作用
-
本文的核心创新是
Attention Ghost Module(如图 Figure 1 右侧所示的三分支注意力模块)。 -
这是一个高度通用的特征精炼插件(plug-and-play refinement block)。
-
适用场景 1:提升现有"高效"CNN架构的性能
- 应用: 可将其插入到任何为效率而设计的轻量级网络(如 GhostNet、MobileNet、ShuffleNet、EfficientNet)的瓶颈层或关键层之后。
- 目的: 在不显著增加计算负担的前提下(注意力计算本身是轻量级的),大幅提升这些高效模型的特征表达和精炼能力,使其在保持速度优势的同时,在分割或分类任务上达到更高精度。
-
适用场景 2:改进任何 2D/3D 分割网络(如 U-Net, UNet++)
- 应用: 用本文的
AG-bneck(即 Ghost Bottleneck + Tri-Attention 模块)替换 标准 U-Net 架构中的标准Conv-BN-ReLU块,尤其是在编码器和解码器的主干路径上。 - 目的: 如本文所示,这可以显著提升模型的分割性能(如 Dice 和 Jaccard),同时可能降低模型的总体 GFLOPs 和参数量。
- 应用: 用本文的
-
适用场景 3:处理 3D 容积数据(如 MRI、视频)
- 应用: 该模块明确包含
Depth Attention,使其天然适用于 3D 数据。 - 目的: 在处理 3D MRI 扫描、CT 容积数据或视频帧序列时,该模块可以被插入到 3D CNN 中,以显式地建模跨深度/时间的上下文关系,这对于理解 3D 结构或动作至关重要。
- 应用: 该模块明确包含
-
适用场景 4:多模态特征融合
- 应用: 当需要融合来自不同模态的特征时(例如 CT 和 MRI),
Channel Attention分支可以帮助网络动态地权衡不同模态特征的重要性。 - 目的: 实现更智能、自适应的多模态特征融合。
- 应用: 当需要融合来自不同模态的特征时(例如 CT 和 MRI),
6. 实验结果总结与分析
本研究使用 AATTCT-IDS 和 LiTS 两个 CT 图像数据集评估了 Attention GhostUNet++ 模型在分割皮下脂肪组织 (SAT)、内脏脂肪组织 (VAT) 和肝脏 (Liver) 方面的性能。
-
性能表现: 实验结果(如表格 1 所示)表明,Attention GhostUNet++ 在所有目标区域的分割精度上均优于 UNet、UNet++、ResUNet 和 GhostUNet++ 等基线模型。具体而言:
- VAT 分割: Dice 系数 (DC) 达到 0.9430 ,Jaccard 指数 (JI) 为 0.9430。
- SAT 分割: Dice 系数达到 0.9639 ,Jaccard 指数为 0.9639。
- 肝脏分割: Dice 系数达到 0.9652 ,Jaccard 指数为 0.9496。
- 该模型不仅在数值指标上领先,在定性视觉对比中(如图 2 所示)也展现出更优越的边界贴合度和区域分割准确性,特别是在 SAT 和 VAT 边界模糊的挑战性区域,以及肝脏的不规则轮廓分割上表现出色。
-
优势分析: 模型通过引入通道、空间和深度注意力机制,显著增强了特征提取能力,能够更精准地关注目标区域并抑制背景噪声。同时,Ghost 模块的引入有效降低了计算冗余,保证了模型的高效性。
-
局限性: 尽管整体性能卓越,但在 SAT 和 VAT 的精细边界分割上仍有微小提升空间,部分指标略低于 UNet 的某些特例表现(如 SAT 的 JI)。
到此,所有的内容就基本讲完了。如果觉得这篇文章对你有用,记得点赞、收藏并分享给你的小伙伴们哦😄。