重要信息
时间:2026年1月9-11日
地点:中国 - 上海

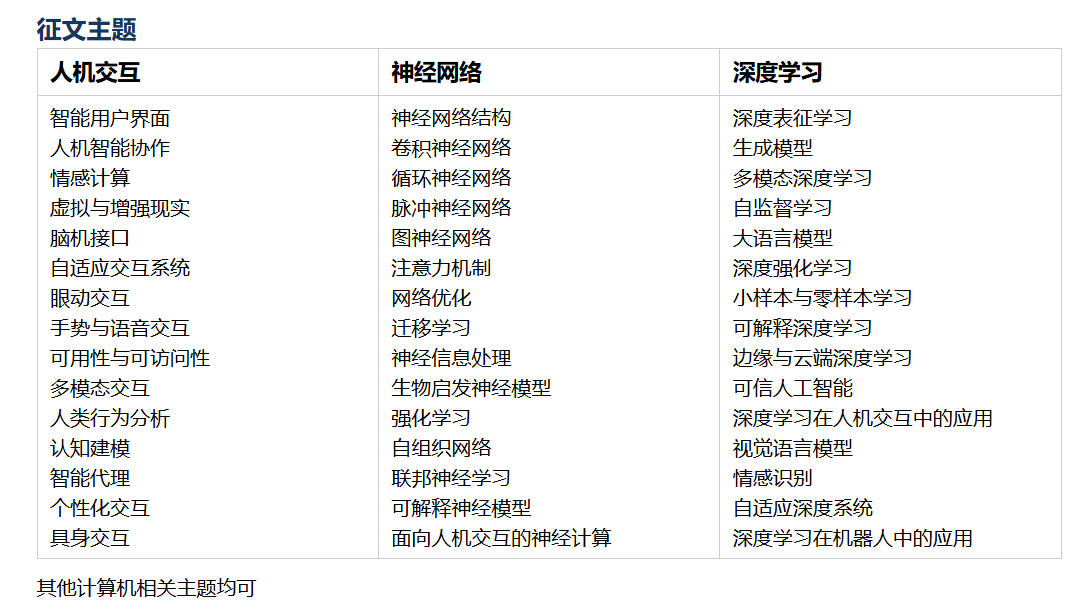
征稿主题
一、人机交互(HCI)与深度学习的融合技术体系
人机交互(Human-Computer Interaction, HCI)是连接人与智能系统的桥梁,而神经网络与深度学习为 HCI 赋予了 "智能感知" 与 "自适应决策" 能力。二者的融合已渗透到语音交互、视觉交互、体感交互等核心场景,其技术体系可分为感知层、建模层、交互层三个核心维度,具体如下:
| 层级 | 核心技术方向 | 典型应用场景 | 技术核心目标 |
|---|---|---|---|
| 感知层 | 语音识别、计算机视觉、体感传感器、情感计算 | 智能语音助手、面部表情交互、手势控制 | 精准捕捉用户的交互意图与生理 / 心理状态 |
| 建模层 | 深度学习网络(CNN/RNN/Transformer)、用户行为建模、强化学习 | 交互意图预测、个性化推荐、自适应界面 | 构建用户交互模型,实现智能决策与预测 |
| 交互层 | 自然语言生成、虚拟 / 增强现实、触觉反馈、可穿戴交互 | 智能客服对话、AR 虚拟交互、触觉反馈设备 | 实现自然、高效、沉浸式的人机交互体验 |
二、感知层核心:基于 CNN 的视觉交互(手势识别)
视觉交互是 HCI 的核心场景之一,基于卷积神经网络(CNN)的手势识别技术可将用户的肢体动作转化为机器可理解的指令,广泛应用于智能终端、车载交互、工业控制等场景。
2.1 技术原理与环境准备
- 核心原理:通过 CNN 提取手势图像的空间特征,完成从 "图像像素" 到 "手势类别" 的映射;
- 环境依赖:
tensorflow(模型训练 / 推理)、opencv-python(图像采集 / 预处理)、numpy(数据处理)
bash
运行
# 安装依赖
pip install tensorflow opencv-python numpy2.2 Python 实现轻量级手势识别
python
运行
import cv2
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
# 1. 构建轻量级CNN模型
def build_gesture_model(input_shape=(64, 64, 1), num_classes=5):
model = Sequential([
# 卷积层1:提取基础特征
Conv2D(32, (3, 3), activation='relu', input_shape=input_shape),
MaxPooling2D((2, 2)),
# 卷积层2:提取高级特征
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
# 卷积层3:强化特征表达
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
# 全连接层:分类决策
Flatten(),
Dense(128, activation='relu'),
Dropout(0.5), # 防止过拟合
Dense(num_classes, activation='softmax')
])
# 模型编译
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
return model
# 2. 图像预处理函数
def preprocess_image(frame, target_size=(64, 64)):
"""将摄像头帧转换为模型输入格式"""
# 转为灰度图
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 裁剪手部区域(简化版,实际需结合手部检测)
h, w = gray.shape
roi = gray[int(h*0.1):int(h*0.9), int(w*0.1):int(w*0.9)]
# 调整尺寸
resized = cv2.resize(roi, target_size)
# 归一化
normalized = resized / 255.0
# 扩展维度:(64,64) → (1,64,64,1)
input_data = np.expand_dims(np.expand_dims(normalized, axis=-1), axis=0)
return input_data
# 3. 实时手势识别主程序
def real_time_gesture_recognition():
# 初始化模型(此处使用预训练权重,实际需先训练)
model = build_gesture_model()
# 手势类别映射(示例:0-石头,1-剪刀,2-布,3-点赞,4-比心)
gesture_labels = {0: "石头", 1: "剪刀", 2: "布", 3: "点赞", 4: "比心"}
# 打开摄像头
cap = cv2.VideoCapture(0)
print("实时手势识别已启动,按q退出...")
while True:
ret, frame = cap.read()
if not ret:
break
# 图像预处理
input_data = preprocess_image(frame)
# 模型推理
pred = model.predict(input_data, verbose=0)
pred_class = np.argmax(pred)
pred_label = gesture_labels[pred_class]
pred_conf = np.max(pred)
# 在画面上绘制结果
cv2.putText(frame, f"手势:{pred_label} (置信度:{pred_conf:.2f})",
(10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# 显示裁剪的手部区域
h, w = frame.shape[:2]
cv2.rectangle(frame, (int(w*0.1), int(h*0.1)), (int(w*0.9), int(h*0.9)), (255, 0, 0), 2)
# 显示画面
cv2.imshow("Gesture Recognition", frame)
# 按q退出
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
# 执行实时识别
if __name__ == "__main__":
real_time_gesture_recognition()2.3 代码说明
- 模型构建:采用 3 层卷积 + 池化结构,通过 Dropout 层防止过拟合,适配手势识别的轻量级场景;
- 图像预处理:将摄像头帧转为灰度图、裁剪手部区域、归一化,符合 CNN 输入要求;
- 实时推理:调用电脑摄像头,实时采集图像并完成手势分类,在画面上标注识别结果;
- 扩展说明:实际应用中需先通过手势数据集(如 LeapGestRecog、Jester)训练模型,替换示例中的空模型,可提升识别准确率。
三、建模层核心:基于 Transformer 的交互意图理解
人机交互的核心是 "理解用户意图",Transformer 模型凭借自注意力机制,能有效捕捉自然语言交互中的上下文关联,是实现复杂意图理解的核心技术。
3.1 意图理解场景与技术框架
| 交互场景 | 输入示例 | 意图类别 | Transformer 核心优势 |
|---|---|---|---|
| 智能语音助手 | "帮我把客厅空调调到 26℃" | 设备控制 | 捕捉 "客厅""空调""26℃" 的语义关联 |
| 智能客服 | "我的订单一直没发货" | 售后咨询 | 理解 "订单""没发货" 的核心诉求 |
| 车载交互 | "导航到最近的加油站" | 地点导航 | 解析 "最近""加油站" 的场景化需求 |
3.2 Python 实现轻量级意图识别(基于 HuggingFace)
python
运行
from transformers import pipeline, AutoTokenizer, AutoModelForSequenceClassification
import torch
# 1. 加载预训练模型(适配中文意图识别)
def load_intent_model():
# 选用轻量级中文模型:bert-base-chinese
model_name = "bert-base-chinese"
# 自定义意图类别(示例:设备控制、信息查询、闲聊、投诉、建议)
num_labels = 5
# 加载tokenizer和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
num_labels=num_labels
)
# 构建意图分类pipeline
intent_classifier = pipeline(
"text-classification",
model=model,
tokenizer=tokenizer,
device=0 if torch.cuda.is_available() else -1 # 自动使用GPU
)
return intent_classifier
# 2. 意图识别主函数
def recognize_interaction_intent(text):
# 加载模型
classifier = load_intent_model()
# 意图标签映射
intent_map = {
"LABEL_0": "设备控制",
"LABEL_1": "信息查询",
"LABEL_2": "闲聊",
"LABEL_3": "投诉",
"LABEL_4": "建议"
}
# 推理
result = classifier(text)[0]
# 转换标签
result["label"] = intent_map[result["label"]]
return result
# 测试示例
if __name__ == "__main__":
test_cases = [
"帮我打开卧室的灯",
"明天北京的天气怎么样",
"今天心情不太好",
"我的智能音箱总是断连",
"建议增加语音唤醒的灵敏度"
]
for text in test_cases:
intent_result = recognize_interaction_intent(text)
print(f"输入:{text}")
print(f"识别意图:{intent_result['label']},置信度:{intent_result['score']:.4f}\n")3.3 代码说明
- 模型选型:基于
bert-base-chinese预训练模型,适配中文交互场景的意图识别; - 意图分类:覆盖设备控制、信息查询等 5 类常见交互意图,可根据场景扩展;
- 高效推理:自动适配 GPU/CPU,通过 HuggingFace Pipeline 简化模型调用流程。
四、交互层核心:基于 LSTM 的情感化语音交互
情感化交互是 HCI 的高阶形态,基于长短期记忆网络(LSTM)的情感分析技术,可识别用户语音中的情感倾向,让交互更具 "人情味"。
4.1 技术原理
- 语音转文字(ASR):将语音信号转为文本;
- 情感分析:通过 LSTM 捕捉文本中的时序语义特征,识别情感类别(开心、愤怒、悲伤、中性)。
4.2 Python 实现情感化语音交互
python
运行
import speech_recognition as sr
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Embedding, Dense, Dropout
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 1. 语音转文字函数
def speech_to_text():
r = sr.Recognizer()
# 使用麦克风作为音源
with sr.Microphone() as source:
print("请说话...")
audio = r.listen(source)
try:
# 调用百度API(需配置,此处用内置识别)
text = r.recognize_google(audio, language="zh-CN")
print(f"识别文本:{text}")
return text
except sr.UnknownValueError:
print("无法识别语音")
return ""
except sr.RequestError:
print("语音识别服务异常")
return ""
# 2. 构建LSTM情感分析模型
def build_emotion_model(vocab_size, max_len, num_emotions=4):
model = Sequential([
# 嵌入层:将文字转为向量
Embedding(vocab_size, 128, input_length=max_len),
# LSTM层:捕捉时序情感特征
LSTM(64, return_sequences=True),
LSTM(32),
Dropout(0.3),
# 分类层:输出情感类别
Dense(16, activation='relu'),
Dense(num_emotions, activation='softmax')
])
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
# 3. 情感识别主函数
def recognize_emotion(text):
if not text:
return "无法识别"
# 示例配置(实际需基于情感数据集训练)
vocab_size = 10000
max_len = 20
# 初始化tokenizer
tokenizer = Tokenizer(num_words=vocab_size)
# 文本序列化
sequences = tokenizer.texts_to_sequences([text])
padded_sequences = pad_sequences(sequences, maxlen=max_len)
# 构建模型(实际需加载预训练权重)
model = build_emotion_model(vocab_size, max_len)
# 情感映射
emotion_map = {0: "开心", 1: "愤怒", 2: "悲伤", 3: "中性"}
# 推理
pred = model.predict(padded_sequences, verbose=0)
pred_emotion = emotion_map[np.argmax(pred)]
return pred_emotion
# 4. 情感化交互响应
def emotional_response(emotion):
responses = {
"开心": "听到你心情好,我也很开心😊!",
"愤怒": "别生气啦,我会尽力帮你解决问题😞!",
"悲伤": "抱抱你,希望我的服务能让你好受一点🤗!",
"中性": "有什么我能帮助你的吗?😐"
}
return responses.get(emotion, "我会尽力为你服务!")
# 主程序
if __name__ == "__main__":
# 语音转文字
text = speech_to_text()
if text:
# 情感识别
emotion = recognize_emotion(text)
print(f"识别情感:{emotion}")
# 情感化响应
response = emotional_response(emotion)
print(f"交互响应:{response}")4.3 代码说明
- 语音转文字:基于
speech_recognition库调用谷歌语音识别 API,实现中文语音转文字; - 情感分析:通过 LSTM 模型捕捉文本中的情感时序特征,识别 4 类核心情感;
- 情感响应:根据识别的情感类别,返回个性化的交互话术,提升交互的情感契合度。
五、国际交流与合作机会
作为国际学术会议,将吸引全球范围内的专家学者参与。无论是发表研究成果、聆听特邀报告,还是在圆桌论坛中与行业大咖交流,都能拓宽国际视野,甚至找到潜在的合作伙伴。对于高校师生来说,这也是展示研究、积累学术人脉的好机会。