
🧔 这里是九年义务漏网鲨鱼,研究生在读,主要研究方向是人脸伪造检测,长期致力于研究多模态大模型技术;国家奖学金获得者,国家级大创项目一项,发明专利一篇,多篇论文在投,蓝桥杯国家级奖项、妈妈杯一等奖。
✍ 博客主要内容为大模型技术的学习以及相关面经,本人已得到B站、百度、唯品会等多段多模态大模型的实习offer,为了能够紧跟前沿知识,决定写一个"从零学习 RL"主题的专栏。这个专栏将记录我个人的主观学习过程,因此会存在错误,若有出错,欢迎大家在评论区帮助我指出。除此之外,博客内容也会分享一些我在本科期间的一些知识以及项目经验。
🌎 Github仓库地址:Baby Awesome Reinforcement Learning for LLMs and Agentic AI
📩 有兴趣合作的研究者可以联系我:yirongzzz@163.com
文章目录
-
- 前言
-
- [一、 QLoRA](#一、 QLoRA)
-
- [🧠 1.1 QLoRA 和普通 LoRA 的本质区别是什么?(真实面试问题)](#🧠 1.1 QLoRA 和普通 LoRA 的本质区别是什么?(真实面试问题))
- [二 量化知识恶补](#二 量化知识恶补)
- [三、QLoRA 量化细节](#三、QLoRA 量化细节)
-
- [🧠 1.2 两次压缩可以等价为一次粗scale压缩吗(笔者疑问)](#🧠 1.2 两次压缩可以等价为一次粗scale压缩吗(笔者疑问))
- [四、QLoRA 工程配置要点](#四、QLoRA 工程配置要点)
- [五、QLoRA-CLIP 图文检索微调示例](#五、QLoRA-CLIP 图文检索微调示例)
前言
前面QLoRA主要在讲"怎么在全精度模型上优雅地加一个低秩增量 ΔW"。工业界真实场景里依然存在着两个很常见的问题:
- 显存实在不够,8B / 14B 模型都快撑不住了,LoRA微调依然爆显存,如何进一步解决?
- LoRA 只是往权重上"加一个低秩偏移",能不能把"方向 和 幅度 拆开来,控制得更精细一点?
这两个问题分别对应了的两条主线:
- QLoRA:在 LoRA 之外,把 base 模型本身做 4bit 量化,真正做到"显存抠到极致,还不怎么掉点";
- DoRA :把权重拆成 方向 × 标量幅度,把"往哪儿改"与"改多大"解耦。
在本文文章中,主要对这两个系列的微调原理及实现进行讲解。
一、 QLoRA
最简单的理解就是:在量化模型的基础上进行LoRA微调,听上去似乎就不是什么高大上的技术进步,事实就是如此:QLoRA = 4bit 量化基座 + 全精度 LoRA 适配器。
训练时:
- 前向:用低比特 W 0 W_0 W0 参与计算 + LoRA 分支的浮点增量;
- 反向:只对 LoRA 权重(A、B)求梯度, W 0 W_0 W0 不更新。
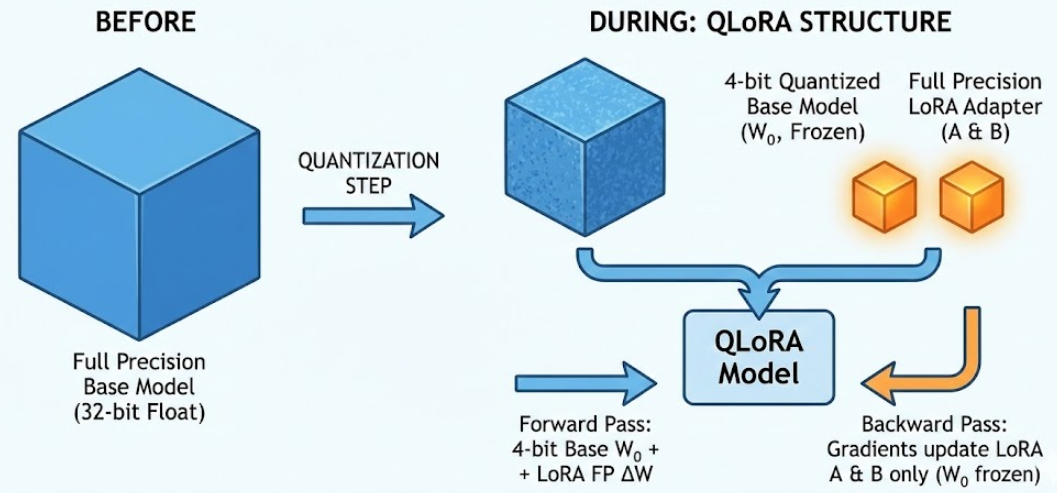
🧠 1.1 QLoRA 和普通 LoRA 的本质区别是什么?(真实面试问题)
可以粗暴理解成三点:
-
普通 LoRA:
- 基座模型 W 0 W_0 W0 用 fp16 / bf16 常规加载;
- 显存占用基本和标准 finetune 差不多(只是梯度少了很多)。
-
QLoRA:
-
把 W 0 W_0 W0 量化到 4bit(NF4) 存储;
-
前向时做一次解量化到 fp16 参与计算,但不存梯度,显存占用大幅下降;
-
只在 LoRA 分支上保留 fp16/bf16,参数量很少。
-
二 量化知识恶补
可能有些读者对于量化还不是特别熟悉,这里可以先简短学习一下量化知识。通俗来讲,就是将高精度的浮点型变为低精度的整数型。量化可以分为对称量化以及分为对称量化和非对称量化
⚙️ 区别
- 对称量化(Symmetric Quantization)
X i n t = r o u n d ( X f l o a t s c a l e ) , s c a l e = m a x ( ∣ X ∣ ) 2 n − 1 − 1 X_{int}=round(\frac{X_{float}}{scale}), scale = \frac{max(|X|)}{2^{n-1}-1} Xint=round(scaleXfloat),scale=2n−1−1max(∣X∣)
- 非对称量化(Affine Quantization)
X i n t = r o u n d ( X f l o a t s c a l e ) + z e r o _ p o i n t , s c a l e = m a x x − m i n ) x 2 n − 1 X_{int}=round(\frac{X_{float}}{scale}) + zero\point, scale = \frac{max_x-min)x}{2^{n}-1} Xint=round(scaleXfloat)+zero_point,scale=2n−1maxx−min)x
z e r o _ p o i n t = r o u n d ( − m i n ( x ) s c a l e ) zero\_point = round(\frac{-min(x)}{scale}) zero_point=round(scale−min(x))
| 特性 | 对称量化(Symmetric Quantization) | 非对称量化(Affine Quantization) |
|---|---|---|
| 零点位置 | 固定为0 | 动态计算(zero_point) |
| 数值范围 | [-127, 127] (int8) |
[0, 255] (uint8) |
| 计算开销 | 更低(无需zero_point计算) | 更高 |
| 精度损失 | 对偏斜分布敏感 | 更鲁棒,能更好处理数据分布偏斜的情况 |
| 典型应用 | 权重量化(正负均衡) | 激活值量化 |
| 硬件支持 | 广泛支持(如GPU/TPU) | 需要额外处理zero_point |
三、QLoRA 量化细节
如果你仔细阅读过原文,你会发现,QLoRA 论文里的关键点不是"随便 4bit 一量就完了",而是有几层工程小心机:
1️⃣ NF4:不是"粗暴等分",而是"按权重习性切块"
先说直觉上熟悉的"Uniform 4bit":
- 把一个区间均匀切成 16 份(4bit → 16 个格子);
- 不管权重实际长什么样,只要落在区间里,就强行映射到这 16 个格子中的一个。
问题是:神经网络的权重分布不是均匀的,而是接近"钟形曲线"(高斯分布附近),绝大多数数都挤在 0 附近,离得远的极大/极小值很少。如果用 "均匀量化" 去切,可能会出现:
🔴 中间这段(权重密集的区域)被切得很粗;
🔴 两边(几乎没什么值)却分配了不少格子,浪费。
NF4(NormalFloat4 / NormalFloat-4)这个"按高斯分布定制的 4bit 量化格式",最早是作为一种适配"近似正态分布权重"的 4bit 数据类型提出的。本质上是:
先假设权重接近高斯分布,然后专门为"高斯形状"设计一套 4bit 刻度表,让中间密集区域的刻度更密,两侧稀疏区域刻度更稀。
你可以类比成:
- Uniform 4bit:把 0--100 的温度每 6.25°C 一格,不管你常用的是 20--30°C 还是别的;
- NF4:知道你日常只关心 15--35°C,于是中间这段 15--35°C 刻度超密,两边的极端温度(-20 或 80°C)刻度就粗放一点。
所以,在"权重真正密集的地方",NF4 给了更多精度 ,这就是为什么在 4bit 这么粗的比特下,QLoRA 还能保证精度比较好。QLoRA 证明了:在大规模 LLM 上,用 NF4 这种 4bit 格式 + Double Quantization + PagedOptimizer,再配合 LoRA,只训练低秩增量,就可以在几乎不掉点的前提下,大幅降低显存/存储成本。
2️⃣ Double Quantization
❌ 普通块量化:
- 对每个 block 的权重做 4bit / 8bit 量化,需要一个
scale(甚至还要zero_point)来还原; - 这些
scale一般用 fp16/fp32 存,虽然数量比权重少很多,但单个很"贵"。
✔️ QLoRA 的 Double Quantization:
- 第一级:对每个 block 做 4bit 量化,得到:
- 一个 4bit 的 codeᵢ 列表;
- 一个"粗略的 scaleᵢ"集合。
- 第二级:把所有 scaleᵢ 本身当成数据再看一眼 ,发现它们其实也不是乱分布的:
- 有点像"每个班的平均分",班与班之间也有结构,不是任意乱跳;
- 所以再对
{scaleᵢ}做一次 8bit / 更低比特的量化,得到{scale_codes, global_scale}。
因此,最终的存储结构会变成:
- 权重 block 的 4bit code(第一层);
- 再加上"被量化过的 scale code"(第二层);
- 以及用于还原 scale 的全局 scale 等小量数据。
这里的关键区别在于:
单层量化:只在"块内"做压缩 ;
Double Quantization:先做块内压缩,再在"块与块之间"对 scale 做二次压缩。
🧠 1.2 两次压缩可以等价为一次粗scale压缩吗(笔者疑问)
如果直接"一次性量化"整个大矩阵 W,想做到类似的压缩率,就会遇到两个问题:
- 要么范围设太广:
- 需要覆盖所有 block 的极值 → 刻度变得很稀疏;
- 中间密集区域的精度会牺牲得很厉害,误差非常大。
- 要么范围设太窄:
- 兼顾不了所有 block 的分布 → 有些 block 会被严重截断,loss 会炸。
而块量化 + Double Quantization 正是通过这两层结构:
- 第一层 block 内量化,让每块自己选一个合适的 scale 范围,局部精度高;
- 第二层对 scale 的低比特压缩,是对这些"局部 scale 参数"再做一个结构化压缩,减少存储开销;
四、QLoRA 工程配置要点
在 HuggingFace 生态里,一般是这样一个栈:
bitsandbytes提供 4bit / 8bit 量化 + 高效算子;transformers+peft管 LoRA 注入。
配置示例:
python
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model, TaskType
model_name = "meta-llama/Llama-3-8b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 1) 4bit 量化配置
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype="bfloat16", # 计算时用 bf16
bnb_4bit_use_double_quant=True, # double quantization
bnb_4bit_quant_type="nf4", # NF4 或 FP4
)
# 2) 加载量化后的基座模型
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto",
)
# 3) LoRA 配置(和普通 LoRA 一样)
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=8,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
)
# 4) 注入 LoRA
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()五、QLoRA-CLIP 图文检索微调示例
- 环境准备
python
pip install "transformers>=4.44.0" "datasets" "accelerate" "peft>=0.8.0" \
"bitsandbytes>=0.45.0" "torch" "torchvision" "Pillow"- 数据集自定义
python
import os
from PIL import Image
from torch.utils.data import Dataset
class ImageTextDataset(Dataset):
def __init__(self, ann_file, image_root, processor):
self.samples = []
self.image_root = image_root
self.processor = processor
with open(ann_file, "r", encoding="utf-8") as f:
for line in f:
line = line.strip()
if not line:
continue
img_rel, text = line.split("\t", 1)
self.samples.append((img_rel, text))
def __len__(self):
return len(self.samples)
def __getitem__(self, idx):
img_rel, text = self.samples[idx]
img_path = os.path.join(self.image_root, img_rel)
image = Image.open(img_path).convert("RGB")
return {"image": image, "text": text}- 4bit 量化加载 CLIP
python
import torch
from torch.utils.data import DataLoader
import torch.nn.functional as F
from transformers import (
CLIPModel,
CLIPProcessor,
BitsAndBytesConfig,
get_scheduler,
)
from peft import LoraConfig, get_peft_model, TaskType
from dataset_clip_qlora import ImageTextDataset
device = "cuda" if torch.cuda.is_available() else "cpu"
model_name = "openai/clip-vit-base-patch32"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16, # 计算用 bf16/fp16 均可
bnb_4bit_use_double_quant=True, # Double Quantization
bnb_4bit_quant_type="nf4", # NF4 量化
)
model = CLIPModel.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto",
)
processor = CLIPProcessor.from_pretrained(model_name)- 注入 LoRA
python
for name, module in model.named_modules():
if "q_proj" in name or "v_proj" in name:
print(name, "->", module.__class__.__name__)
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type=TaskType.FEATURE_EXTRACTION,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"out_proj",
],
)
model = get_peft_model(model, lora_config)
model.print_trainable_parameters()- dataloader
python
BATCH_SIZE = 32
MAX_LENGTH = 64
train_dataset = ImageTextDataset(
ann_file="data/train.tsv",
image_root="data/images",
processor=processor,
)
def collate_fn(batch):
images = [item["image"] for item in batch]
texts = [item["text"] for item in batch]
encoding = processor(
text=texts,
images=images,
padding=True,
truncation=True,
max_length=MAX_LENGTH,
return_tensors="pt",
)
return {
"pixel_values": encoding["pixel_values"], # [B, 3, H, W]
"input_ids": encoding["input_ids"], # [B, L]
"attention_mask": encoding["attention_mask"], # [B, L]
}
train_loader = DataLoader(
train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4,
collate_fn=collate_fn,
)- 训练代码
python
global_step = 0
for epoch in range(EPOCHS):
for step, batch in enumerate(train_loader):
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(
input_ids=batch["input_ids"],
attention_mask=batch["attention_mask"],
pixel_values=batch["pixel_values"],
return_loss=False,
)
logits_image = outputs.logits_per_image
logits_text = outputs.logits_per_text
batch_size = logits_image.size(0)
labels = torch.arange(batch_size, device=device)
loss_i = F.cross_entropy(logits_image, labels)
loss_t = F.cross_entropy(logits_text, labels)
loss = (loss_i + loss_t) / 2.0
loss = loss / GRAD_ACCUM
loss.backward()
if (step + 1) % GRAD_ACCUM == 0:
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
global_step += 1
if global_step % 50 == 0:
print(f"Epoch {epoch} | step {step} | loss {loss.item():.4f}")