PyTorch实战(16)------基于LSTM实现音乐生成
0. 前言
本节我们将介绍音乐生成,利用 PyTorch 构建能够创作类古典音乐的机器学习模型。在本节中,我们将采用长短期记忆网络 (Long Short-Term Memory, LSTM)来处理序列化音乐数据。训练数据选自莫扎特的古典音乐作品,每首乐曲将被分解为钢琴音符序列。读取以 MIDI (Musical Instrument Digital Interface) 格式存储的音乐数据,MIDI 是一种跨设备、跨环境读写音乐数据的通用标准格式。
在将 MIDI 文件转换为钢琴音符序列(即钢琴卷帘谱,piano roll)后,我们将用这些数据来训练一个"下一音符预测"系统。该系统基于 LSTM 构建分类器,根据给定的前置音符序列(共 88 种可能,对应标准钢琴的 88 个琴键)预测后续音符。
接下来,介绍构建人工智能音乐生成模型的完整流程,重点展示 PyTorch 在数据加载、模型训练和音乐样本生成中的应用。
1. 加载 MIDI 音乐数据
首先,我们将加载 MIDI 格式的音乐数据,介绍如何处理 MIDI 数据,并将其转换为 PyTorch 数据加载器。
(1) 首先,导入所需库,skimage 用于可视化由模型生成的音乐样本序列,struct 和 io 用于将 MIDI 音乐数据转换为钢琴卷帘谱的处理过程:
python
import os
import sys
import numpy as np
import random
import skimage.io as io
from struct import pack, unpack
from io import StringIO, BytesIO
from matplotlib import pyplot as plt
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.utils.data as data(2) 接着编写辅助类和函数,用于加载 MIDI 文件并将其转换为可输入 LSTM 模型的钢琴音符序列(矩阵)。首先定义一些 MIDI 常量(限于篇幅,完整常量列表参考GitHub 代码),用于配置音高、通道、序列起始/结束等音乐控制参数:
python
NOTE_MIDI_OFF = 0x80
NOTE_MIDI_ON = 0x90
A_TOUCH = 0xA0
CONT_CONTROL = 0xB0
PATCH_CHG_MIDI = 0xC0
CHNL_PRESS = 0xD0
# ...(3) 接下来,我们将定义一系列处理 MIDI 数据的类,包括输入/输出流处理、MIDI 数据解析器等组件(限于篇幅,完整辅助类定义参考GitHub 代码:
python
class MOStrm:
def __init__(self):
self._abs_t = 0
self._rel_t = 0
self._cur_trk = 0
self._run_stat = None
def time_update(self, t_new=0, rel_flag=1):
if rel_flag:
self._rel_t = t_new
self._abs_t += t_new
else:
self._rel_t = t_new - self._abs_t
self._abs_t = t_new
def t_reset(self):
self._rel_t = 0
self._abs_t = 0
def t_rel(self):
return self._rel_t
def t_abs(self):
return self._abs_t
def set_cur_trk(self, trk_new):
self._cur_trk = trk_new
# ...(4) 定义两个关键函数:一个用于将读取的 MIDI 文件转换为钢琴卷帘谱,另一个用于用空音符填充钢卷帘谱(以标准化数据集中的音乐片段长度):
python
def md_fl_to_pio_rl(md_fl):
md_d = MidiDataRead(md_fl, dtm=0.3)
pio_rl = md_d.pio_rl.transpose()
pio_rl[pio_rl > 0] = 1
return pio_rl
def pd_pio_rl(pio_rl, mx_l=132333, pd_v=0):
orig_rol_len = pio_rl.shape[1]
pdd_rol = np.zeros((88, mx_l))
pdd_rol[:] = pd_v
pdd_rol[:, - orig_rol_len:] = pio_rl
return pdd_rol(5) 定义 PyTorch 数据集类:
python
class NtGenDataset(data.Dataset):
def __init__(self, md_pth, mx_seq_ln=1491):
self.md_pth = md_pth
md_fnames = os.listdir(md_pth)
self.mx_seq_ln = mx_seq_ln
md_fnames_ful = map(lambda fname: os.path.join(md_pth, fname),md_fnames)
self.md_fnames_ful = list(md_fnames_ful)
if mx_seq_ln is None:
self.mx_len_upd()
def mx_len_upd(self):
seq_lens = map(lambda fname: md_fl_to_pio_rl(fname).shape[1],self.md_fnames_ful)
mx_l = max(seq_lens)
self.mx_seq_ln = mx_l
def __len__(self):
return len(self.md_fnames_ful)
def __getitem__(self, index):
md_fname_ful = self.md_fnames_ful[index]
pio_rl = md_fl_to_pio_rl(md_fname_ful)
seq_len = pio_rl.shape[1] - 1
ip_seq = pio_rl[:, :-1]
gt_seq = pio_rl[:, 1:]
ip_seq_pad = pd_pio_rl(ip_seq, mx_l=self.mx_seq_ln)
gt_seq_pad = pd_pio_rl(gt_seq,mx_l=self.mx_seq_ln,pd_v=-100)
ip_seq_pad = ip_seq_pad.transpose()
gt_seq_pad = gt_seq_pad.transpose()
return (torch.FloatTensor(ip_seq_pad),
torch.LongTensor(gt_seq_pad), torch.LongTensor([seq_len]))(6) 除了数据集类之外,还需添加一个辅助函数,用于将训练数据批次中的音乐序列后处理为三个独立列表:包括输入序列列表、输出序列列表和按序列长度降序排列的长度列表:
python
def pos_proc_seq(btch):
ip_seqs, op_seqs, lens = btch
ip_seq_splt_btch = ip_seqs.split(split_size=1)
op_seq_splt_btch = op_seqs.split(split_size=1)
btch_splt_lens = lens.split(split_size=1)
tr_data_tups = zip(ip_seq_splt_btch,
op_seq_splt_btch,
btch_splt_lens)
ord_tr_data_tups = sorted(tr_data_tups,
key=lambda c: int(c[2]),
reverse=True)
ip_seq_splt_btch, op_seq_splt_btch, btch_splt_lens = zip(*ord_tr_data_tups)
ord_ip_seq_btch = torch.cat(ip_seq_splt_btch)
ord_op_seq_btch = torch.cat(op_seq_splt_btch)
ord_btch_lens = torch.cat(btch_splt_lens)
ord_ip_seq_btch = ord_ip_seq_btch[:, -ord_btch_lens[0, 0]:, :]
ord_op_seq_btch = ord_op_seq_btch[:, -ord_btch_lens[0, 0]:, :]
tps_ip_seq_btch = ord_ip_seq_btch.transpose(0, 1)
ord_btch_lens_l = list(ord_btch_lens)
ord_btch_lens_l = map(lambda k: int(k), ord_btch_lens_l)
return tps_ip_seq_btch, ord_op_seq_btch, list(ord_btch_lens_l)(7) 在本节中,使用莫扎特的作品集作为数据集,下载数据集后解压缩,文件夹包含 21 个 MIDI 文件,将把它们划分为 18 个训练文件和 3 个验证文件。下载的数据存储在 ./mozart/train 和 ./mozart/valid 文件夹下。下载完成后,可以读取数据并实例化训练和验证数据集加载器:
python
training_dataset = NtGenDataset('./mozart/train', mx_seq_ln=None)
training_datasetloader = data.DataLoader(training_dataset, batch_size=5,shuffle=True, drop_last=True)
X_train = next(iter(training_datasetloader))
X_train[0].shape
validation_dataset = NtGenDataset('./mozart/valid/', mx_seq_ln=None)
validation_datasetloader = data.DataLoader(validation_dataset, batch_size=3, shuffle=False, drop_last=False)
X_validation = next(iter(validation_datasetloader))
X_validation[0].shape输出结果如下所示:
python
torch.Size([3, 1515, 88])如图所示,第一个验证批次包含 3 个长度均为 1515 个音符的序列,每个序列被编码为 88 维向量(对应钢琴的 88 个琴键)。下图是验证集其中一个音乐文件前几个音符的乐谱:

我们也可以将音符序列可视化为 88 行的矩阵(每行对应一个琴键)。以下是上述旋律( 1515 个音符中的前 300 个)的矩阵可视化:

接下来,定义 LSTM 模型和训练流程。
2. 模型定义
加载 MIDI 数据集并创建了训练集与验证集的数据加载器后。接下来,定义 LSTM 模型架构,以及模型训练循环中的训练与评估流程。
(1) 首先,定义模型架构。本节中,我们将使用LSTM 模型,该模型包含一个编码器层------该层将输入数据在时间序列每个步长的 88 维表征编码为 512 维隐藏层表征。编码器之后连接两个 LSTM 层,再接全连接层,最后通过 softmax 层输出 88 个钢琴琴键类别对应的概率值。这是一个多对一的序列分类任务,其中输入是从时间步长 0 到时间步长 t 的整个序列,输出是时间步长 t+1 处的 88 个琴键类别之一:
python
class MusicLSTM(nn.Module):
def __init__(self, ip_sz, hd_sz, n_cls, lyrs=2):
super(MusicLSTM, self).__init__()
self.ip_sz = ip_sz
self.hd_sz = hd_sz
self.n_cls = n_cls
self.lyrs = lyrs
self.nts_enc = nn.Linear(in_features=ip_sz, out_features=hd_sz)
self.bn_layer = nn.BatchNorm1d(hd_sz)
self.lstm_layer = nn.LSTM(hd_sz, hd_sz, lyrs)
self.fc_layer = nn.Linear(hd_sz, n_cls)
def forward(self, ip_seqs, ip_seqs_len, hd=None):
nts_enc = self.nts_enc(ip_seqs)
nts_enc_rol = nts_enc.permute(1,2,0).contiguous()
nts_enc_nrm = self.bn_layer(nts_enc_rol)
nts_enc_nrm_drp = nn.Dropout(0.25)(nts_enc_nrm)
nts_enc_ful = nts_enc_nrm_drp.permute(2,0,1)
pkd = torch.nn.utils.rnn.pack_padded_sequence(nts_enc_ful, ip_seqs_len)
op, hd = self.lstm_layer(pkd, hd)
op, op_l = torch.nn.utils.rnn.pad_packed_sequence(op)
op_nrm = self.bn_layer(op.permute(1,2,0).contiguous())
op_nrm_drp = nn.Dropout(0.1)(op_nrm)
lgts = self.fc_layer(op_nrm_drp.permute(2,0,1))
lgts = lgts.transpose(0, 1).contiguous()
rev_lgts = (1 - lgts)
zero_one_lgts = torch.stack((lgts, rev_lgts), dim=3).contiguous()
flt_lgts = zero_one_lgts.view(-1, 2)
return flt_lgts, hd(2) 模型架构定义完成后,定义训练流程。使用带有梯度裁剪的 Adam 优化器,以避免过拟合。此外,dropout 层也是应对过拟合的重要措施:
python
def lstm_model_training(lstm_model, lr, ep=10, val_loss_best=float("inf")):
list_of_losses = []
list_of_val_losses =[]
model_params = lstm_model.parameters()
opt = torch.optim.Adam(model_params, lr=lr)
grad_clip = 1.0
for curr_ep in range(ep):
lstm_model.train()
loss_ep = []
for batch in training_datasetloader:
post_proc_b = pos_proc_seq(batch)
ip_seq_b, op_seq_b, seq_l = post_proc_b
op_seq_b_v = Variable(op_seq_b.contiguous().view(-1).cpu())
ip_seq_b_v = Variable(ip_seq_b.cpu())
opt.zero_grad()
lgts, _ = lstm_model(ip_seq_b_v, seq_l)
loss = loss_func(lgts, op_seq_b_v)
list_of_losses.append(loss.item())
loss_ep.append(loss.item())
loss.backward()
torch.nn.utils.clip_grad_norm_(lstm_model.parameters(), grad_clip)
opt.step()
tr_ep_cur = sum(loss_ep)/len(training_datasetloader)
print(f'ep {curr_ep} , train loss = {tr_ep_cur}')
vl_ep_cur = evaluate_model(lstm_model)
print(f'ep {curr_ep} , val loss = {vl_ep_cur}\n')
list_of_val_losses.append(vl_ep_cur)
if vl_ep_cur < val_loss_best:
torch.save(lstm_model.state_dict(), 'best_model.pth')
val_loss_best = vl_ep_cur
return val_loss_best, lstm_model(3) 同样,定义模型评估过程,在此过程中,模型执行一次前向传播,且其参数保持不变:
python
def evaluate_model(lstm_model):
lstm_model.eval()
vl_loss_full = 0.0
seq_len = 0.0
for batch in validation_datasetloader:
post_proc_b = pos_proc_seq(batch)
ip_seq_b, op_seq_b, seq_l = post_proc_b
op_seq_b_v = Variable( op_seq_b.contiguous().view(-1).cpu() )
ip_seq_b_v = Variable( ip_seq_b.cpu() )
lgts, _ = lstm_model(ip_seq_b_v, seq_l)
loss = loss_func(lgts, op_seq_b_v)
vl_loss_full += loss.item()
seq_len += sum(seq_l)
return vl_loss_full/(seq_len*88)接下来,训练并测试音乐生成模型。
3. 模型训练与测试
接下来,训练 LSTM 模型,并运用训练完成的音乐生成模型创作可聆听分析的乐曲样本。
(1) 实例化模型并启动训练流程。采用分类交叉熵作为损失函数。模型训练参数设定为学习率 0.01,共进行 10 个训练 epoch:
python
loss_func = nn.CrossEntropyLoss().cpu()
lstm_model = MusicLSTM(ip_sz=88, hd_sz=512, n_cls=88).cpu()
val_loss_best, lstm_model = lstm_model_training(lstm_model, lr=0.01, ep=10)输出结果如下所示:

(2) 获得"下一音符预测器"后,即可将其转化为音乐生成器。只需提供一个起始音符作为提示,模型就能在时间序列中递归预测后续音符------将时间步t的预测结果追加到时间步 t+1 的输入序列中。
(3) 编写一个音乐生成函数,它接受训练好的模型对象、预期生成的音乐长度、序列的起始音符和温度系数 (temperature),温度系数是对分类层 softmax 函数的数学调控参数,通过扩展或压缩 softmax 概率分布来调整输出多样性:
python
def generate_music(lstm_model, ln=100, tmp=1, seq_st=None):
if seq_st is None:
seq_ip_cur = torch.zeros(1, 1, 88)
seq_ip_cur[0, 0, 40] = 1
seq_ip_cur[0, 0, 50] = 0
seq_ip_cur[0, 0, 56] = 0
seq_ip_cur = Variable(seq_ip_cur.cpu())
else:
seq_ip_cur = seq_st
op_seq = [seq_ip_cur.data.squeeze(1)]
hd = None
for i in range(ln):
op, hd = lstm_model(seq_ip_cur, [1], hd)
probs = nn.functional.softmax(op.div(tmp), dim=1)
seq_ip_cur = torch.multinomial(probs.data, 1).squeeze().unsqueeze(0).unsqueeze(1)
seq_ip_cur = Variable(seq_ip_cur.float())
op_seq.append(seq_ip_cur.data.squeeze(1))
gen_seq = torch.cat(op_seq, dim=0).cpu().numpy()
return gen_seq(4) 最后,调用以上函数生成音乐作品:
python
seq = generate_music(lstm_model, ln=100, tmp=0.8, seq_st=None).transpose()
midiwrite('generated_music.mid', seq.transpose(), dtm=0.25)(5) 以上将创建音乐片段并将其保存为当前目录下的 MIDI 文件。可以查看生成音乐的矩阵可视化结果:
python
plt.imshow(seq)输出结果如下所示:
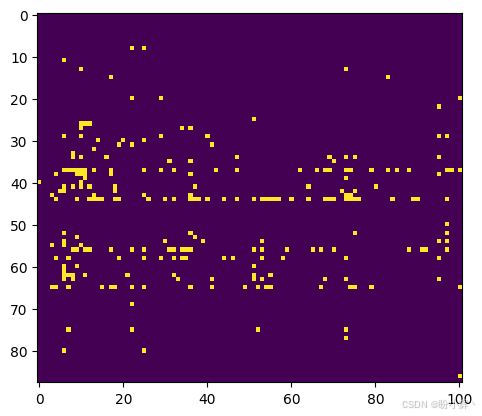
可以看到生成的旋律似乎没有莫扎特的原始作品那样富有旋律感。不过仍能观察到模型已学习到某些音符组合的规律性特征。通过使用更多训练数据或增加训练 epoch,生成音乐的质量还能得到显著提升。
小结
在本节中,我们介绍了如何利用现有音乐数据从头开始训练音符预测模型,并运用训练好的模型进行音乐创作。实际上,这种生成式模型的理念可以拓展至任何类型的数据样本生成。
系列链接
PyTorch实战(1)------深度学习(Deep Learning)
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络
PyTorch实战(6)------模型微调详解
PyTorch实战(7)------循环神经网络
PyTorch实战(8)------图像描述生成
PyTorch实战(9)------从零开始实现Transformer
PyTorch实战(10)------从零开始实现GPT模型
PyTorch实战(11)------随机连接神经网络(RandWireNN)
PyTorch实战(12)------图神经网络(Graph Neural Network,GNN)
PyTorch实战(13)------图卷积网络(Graph Convolutional Network,GCN)
PyTorch实战(14)------图注意力网络(Graph Attention Network,GAT)
PyTorch实战(15)------基于Transformer的文本生成技术