目录
[1. 数据质量逼近算法性能上限](#1. 数据质量逼近算法性能上限)
[2. 本文定义的关键点](#2. 本文定义的关键点)
[3. 本文训练时使用的数据集](#3. 本文训练时使用的数据集)
[3.1 COCO2017-pose](#3.1 COCO2017-pose)
[3.2 MPII转15kpt](#3.2 MPII转15kpt)
[3.3 Kaggle上数据](#3.3 Kaggle上数据)
[3.4 业务数据](#3.4 业务数据)
[3.5 数据增强](#3.5 数据增强)
[4. 模型训练](#4. 模型训练)
[5. 模型压缩](#5. 模型压缩)
[6. yolov8s-pose结果可视化(图片)](#6. yolov8s-pose结果可视化(图片))
[7. yolov8s-pose结果可视化(视频)](#7. yolov8s-pose结果可视化(视频))
[8. 总结](#8. 总结)
前言
训练一个可落地的2D人体姿态估计YOLO模型。
人体关键点检测相比行人检测,额外提供了肢体的关键点信息,这有助于下游的算法设计与优化。例如,在目标跟踪中,检测框重叠时,引入关键点距离,可以减少ID switch情况;在简单行为判断中,可以根据关键点距离变化,设计逻辑规则,实现对摔倒、深蹲和举手等动作;在基于关键点的行为识别中,关键点的质量直接决定行为识别的性能。
在实时性 和准确率 具有较高要求的实际应用中,基于YOLO的人体关键点检测模型,相比行人检测,推理消耗几乎一致。但目前开源算法大都在COCO-pose和MPII 上训练得到,由于开源数据集 通常存在大量的错标 和漏标 ,导致训练得到的算法在实际部署中准确率和召回率不能满足需求。
关于YOLO训练,无论是 yolov5~12,还是后续将出的yolo26,本质上没有区别,对模块的改进,除了水论文,远不如剪枝和蒸馏带来的性能提升。所以难点还是在数据预处理上,因为没有足够的钱和时间去做人工标注,必须考虑低成本获取高质量人体关键点检测数据集。
1. 数据质量逼近算法性能上限
当前YOLO算法的性能已经趋近饱和,从yolov8~yolov12,模型优化带来的性能提升不如清洗数据带来的大。
如下图,前文做的人体关键点检测,仅使用6W张高质量数据,训练得到的yolov8s-pose号模型在检出率上就已经超越v8m/11L等模型。该姿态估计模型甚至可以直接作为行人检测使用。

2. 本文定义的关键点

**本文定义的15个关键点就是COCO-pose定义的17个点去除了左右耳朵。**去除耳朵两个点的原因有:
1.最最最主要的就是减少标注和清洗成本。
2.便于将COCO-pose、MPII都映射到这15个点。四肢属于最基本的关键点,而面部关键点也容易获取。可以将不同格式的标注数据对齐到这15个点。
3.实际应用中,主要使用的还是四肢关键点,如果需要对头部进行分析,还会引入其他算法。
4.在UCF101上,使用yolov8s-pose进行基于关键点的行为识别算法实验表明,去除这两个点的准确率相差在1%以内(自研行为识别算法在UCF101的split1划分上,yolov8s-pose取得74%准确率,v8m为76%,v8l为77%,v8x为79%,faster-rcnn+hrnet为80%,混合训练的v8x为81%,该结果已经超过PoseC3D的79%)。
3. 本文训练时使用的数据集
人体关键点数据,无法仅通过代码来实现数据清洗和标注,必须引入人工审核和矫正!
3.1 COCO2017-pose
清洗数据中发现,COCO-pose一张图最多13个目标,因此存在大量错标和漏标,且标注框误差较大(应该是不同标注人员导致的,有些标的很准,有些标注很随意)。
(1)漏标注
如下图,1.使用已有的行人检测模型,对图片中所有的人进行打码;2.将原本检测框放大2/3的patch赋值给原图(检测框和目标框不一致,以及标注不准,多保留区域,便于后续调整);3.将其余无效的人手动打码。

最终实现效果,类似下图这样:

(2)错标注
当人物重合时,下面这种将关键点标注成同一个人的错误大量存在,通过p图去除。

(3)调整框和关键点
可以使用标注软件调,我是直接算坐标来调整的。
**总结:**该数据集就是删人(打码)和删框(去除无效标注),55K张图片处理后获取了48K张图,已经足够训练一个较好的人体姿态估计模型了。
3.2 MPII转15kpt
**MPII的关键点标注质量较高,我们只需要补上行人框和脸部关键点即可。**不过该数据集较为简单(比如人都是站着的,也没啥重叠),被COCO场景给覆盖了,主要选取一些姿态较为少见的样本(比如瑜伽动作),用于帮助关键点的预测。
(1)建立MPII到COCO-pose的关键点映射
MPII和COCO-pose的关键点定义不同,但四肢上是一致的,我们先只用原数据来尽可能建立MPII到COCO-pose的映射:
python
MPII_keypoint_map_to_COCO2017 = {
0: 14, 1: 12, 2: 10, 3: 9, 4: 11, 5: 13, 6: -1, 7: -1,
8: -1, 9: -1, 10: 8, 11: 6, 12: 4, 13: 3, 14: 5, 15: 7
}其中,-1表示MPII中不存在到COCO点的映射,需要后期补上。同时,MPII有脸部框,这方便我们使用脸部关键点检测来获取关键点,我们对身体计算有效关键点的最大最小值,这样可以获取一个大概的人体检测框,可视化后就是:

(2)引入行人检测,获取检测框
可以直接全图检测,但我选择更耗时的做法,将(1)中关键点框放大两倍后检测,然后计算IOU,选择最匹配的框用于矫正。如下图,较好的结果(这里就只差脸部关键点了):

不过上下图中都还有无关的行人,用COCO-pose中处理的打码方式就行。MPII还有预估出不可见关键点的,我结合COCO的标注,选择漏出多少标注多少,所以部分关键点还需要删除,同时检测框也有不准确的。这些都要以来后期的手工调整。

(3)获取脸部关键点
可以使用yolo-pose获取,但我使用了DB-Face(更快更准),根据(1)中得到的头部框,秩序对框中检测即可。DB-Face检测结果示例如下:

(4)整合所有结果
简单图片如下所示,已经可以看做比较好的标注了:

(5)打码操作
类似COCO-pose中对无关行人的打码操作,最终获取结果如下:

**总结:**整个过程还挺麻烦的,但是比直接手动标注还是高效很多的。最终还是离不开人工审核和校验,最后只选择性获取了750多张。
3.3 Kaggle上数据
cctv-human-pose-estimation-dataset ,如下图所示,主要是监控视角下的(不过看起来是用模型预标注的,也需要手动微调),总共获取420张。

3.4 业务数据
使用公开数据集训练后,针对业务数据进行预标注获取,约800张,并使用旋转数据增强。实验结果表明300张业务数据+公开数据集训练,即可满足实际业务需求。
3.5 数据增强
使用旋转,顺时针/逆时针旋转90度,用于提升关键点的预测准确性,特别是针对摔倒、平板支撑等动作。
增强图片选择:除了眼睛和鼻子,其余关键点至多只有一个不可见点,如下图所示:

4. 模型训练
最终获取的数据总共约6W条,其中验证集均来自COCO2017-pose-val。没有引入负样本,针对特定的误检,可以引入该类型负样本改善:

训练过程参考文章:
YOLOv8-pose(1)- 关键点检测数据集格式详解+快速训练+预测结果详解![]() https://blog.csdn.net/qq_40387714/article/details/140562299 修改一下,关键点形状和翻转设置:
https://blog.csdn.net/qq_40387714/article/details/140562299 修改一下,关键点形状和翻转设置:
bash
# Keypoints
kpt_shape: [15, 3] # number of keypoints, number of dims (2 for x,y or 3 for x,y,visible)
flip_idx: [0, 2, 1, 4, 3, 6, 5, 8, 7, 10, 9, 12, 11, 14, 13]使用预训练模型,学习率从1e-2降至1e-4,总共学习300轮。
|----------|---------------|------------|-------------------|----------|----------|--------------|------------|----------|----------|--------------|------------|
| 模型尺寸 | params(M) | GFLOPs | train time(h) | P(B) | R(B) | mAP50(B) | mAP(B) | P(P) | R(P) | mAP50(P) | mAP(P) |
| v8n | 3.25 | 9.0 | 16.52 | 0.946 | 0.904 | 0.964 | 0.756 | 0.913 | 0.856 | 0.890 | 0.573 |
| 11n | 2.82 | 7.2 | 17.97 | 0.948 | 0.908 | 0.965 | 0.761 | 0.920 | 0.856 | 0.891 | 0.568 |
| v8s | 11.55 | 29.9 | 22.33 | 0.963 | 0.940 | 0.978 | 0.803 | 0.940 | 0.912 | 0.936 | 0.685 |
| 11s | 9.84 | 22.8 | 23.35 | 0.960 | 0.939 | 0.979 | 0.805 | 0.940 | 0.918 | 0.937 | 0.672 |
| v8m | 26.41 | 80.9 | 36.52 | 0.963 | 0.952 | 0.982 | 0.829 | 0.949 | 0.941 | 0.957 | 0.744 |
| 11m | 20.89 | 71.4 | 43.71 | 0.967 | 0.952 | 0.982 | 0.829 | 0.951 | 0.940 | 0.953 | 0.732 |
| v8l | 44.47 | 168.6 | | | | | | | | | |
| 11l | 26.1 | 90.3 | | | | | | | | | |
[不同尺寸模型性能对比]
对比发现,同size的yolo11-pose虽然比yolov8-pose参数量和浮点数计算次数更少,但推理速度并没有更快,而且显存占用明显更大;其检测结果好于v8,关键点结果较差。
5. 模型压缩
可以进一步对模型优化,采用剪枝和蒸馏,参考文章:
YOLOv8源码修改(4)- YOLOv8剪枝(实现任意YOLO模型的简单剪枝)![]() https://blog.csdn.net/qq_40387714/article/details/145394774YOLOv8源码修改(5)- YOLO知识蒸馏(上)添加蒸馏代码:以yolov8-pose为例
https://blog.csdn.net/qq_40387714/article/details/145394774YOLOv8源码修改(5)- YOLO知识蒸馏(上)添加蒸馏代码:以yolov8-pose为例![]() https://blog.csdn.net/qq_40387714/article/details/148203432YOLOv8源码修改(5)- YOLO知识蒸馏(下)设置蒸馏超参数:以yolov8-pose为例
https://blog.csdn.net/qq_40387714/article/details/148203432YOLOv8源码修改(5)- YOLO知识蒸馏(下)设置蒸馏超参数:以yolov8-pose为例![]() https://blog.csdn.net/qq_40387714/article/details/148207938
https://blog.csdn.net/qq_40387714/article/details/148207938
6. yolov8s-pose结果可视化(图片)
实时应用中,大都使用n和s号模型,m号以上延迟过大都较少使用(主要用来预标注)。这里主要测试yolov8s-pose在不同场景中的效果。实验设置,输入图片最大边尺寸为640,置信度阈值为0.25,IOU阈值为0.7。
(1)经典bus.jpg
公交车内的驾驶员仍然没测出来,图片边缘检测框偏大(猜测这和没关马赛克增强有关,图片组合会产生截断,每次截断,边缘处框都会变大)。

(2)鱼眼相机视角
正常俯视视角可以,但倒立的人不行,未加入/增强相应数据。需根据场景加入相关数据,加入倒着的人,可能容易引起影子、倒影的误检。

(3)摔倒和俯卧
关键点大致准确,但仍然存在一定偏移和误差。提升性能需要针对性增加相关数据。

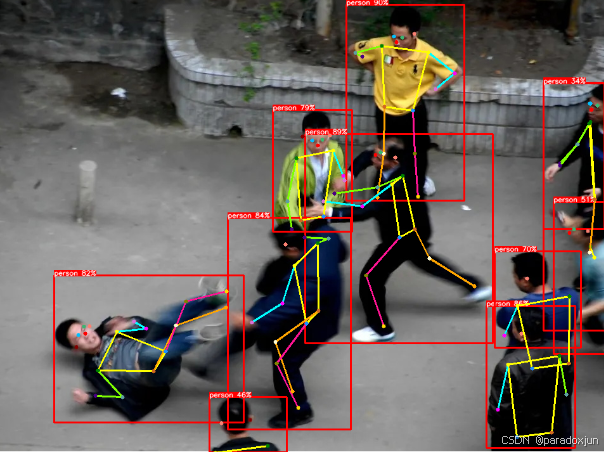
(4)复杂人体关系
还是做不到吗,这个也可能和IOU阈值有关,两个人的框有一个被删了,不过关键点预测也不准。

(5)密集人群
即使没有引入密集人群数据,也可以检测出。

大佬镇楼:

(6)常用的监控视角

7. yolov8s-pose结果可视化(视频)
(1)正面视角,人体特征明显,检测是最简单的。
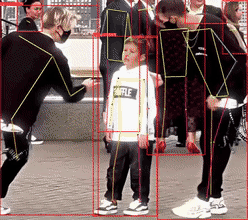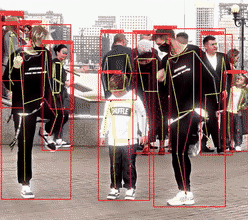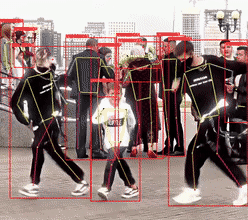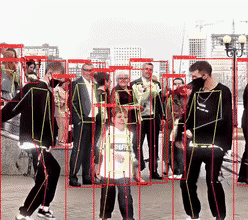
smoothest_1280x720_crf23
JWM_plot_video_720x1280_crf23
(2)监控视角,由于距离远,人物较小,检测相对困难,存在漏检
human_det_plot_720x1280_crf23
Merino_and_Saka_720x1280_crf23
(3)再给我两首歌的时间
gangnam_style_720x1280_crf23
fantastic_baby_1280x720_crf23
8. 总结
纯数据问题,就是提高标注效率,获取高质量数据。
COCO数据集还是太权威了,针对私有场景,只需引入少量图片即可获取一个较满意的结果。