一、访问元素
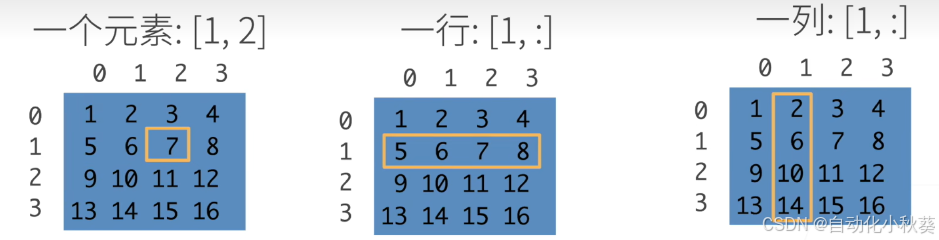
语法如图,第一列更正::,1 , 第x行,第y列
先学一下pytorch:本节内容全是基于pytorch的操作
1.导入pytorch
代码中使用torch而不是pytorch
import torch创建行向量arange
python
x = torch.arange(7)
x
#output
tensor([0,1,2,3,4,5,6])可以通过张量的shape属性来访问张量(沿每个轴的长度)的形状 。
torch.randn(3, 4) 随机生成三行四列的张量
torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])指定生成张量
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
在reshape函数中,使用元组来表示形状,因为形状通常由多个维度组成,而且形状是固定的,不需要修改。
例如:
-
(3, 4) 表示2维,3行4列。
-
(2, 3, 4) 表示3维,2个3x4矩阵。
为什么用元组而不是列表?
-
形状是固定的,不需要改变,所以用不可变的元组更合适。
-
元组在性能上略有优势,因为不可变,所以可以缓存。
# 创建元组 shape = (3, 4) # 在reshape中使用 X.reshape(shape) # 传递一个元组变量
torch.cat((X, Y), dim=0) - 沿着第0维拼接(行方向,垂直拼接)
torch.cat((X, Y), dim=1) - 沿着第1维拼接(列方向,水平拼接)
对张量中的所有元素进行求和,会产生一个单元素张量
X.sum()
tensor(66.)
广播机制
在上面的部分中,我们看到了如何在相同形状的两个张量上执行按元素操作。 在某些情况下,即使形状不同,我们仍然可以通过调用 广播机制(broadcasting mechanism)来执行按元素操作。 这种机制的工作方式如下:
-
通过适当复制元素来扩展一个或两个数组,以便在转换之后,两个张量具有相同的形状;
-
对生成的数组执行按元素操作。
a = torch.arange(3).reshape((3, 1)) b = torch.arange(2).reshape((1, 2)) a, b#输出
(tensor([[0], [1], [2]]), tensor([[0, 1]]))#操作
a + b#输出
tensor([[0, 1], [1, 2], [2, 3]])#都变成3行2列,通过复制自身行或者列
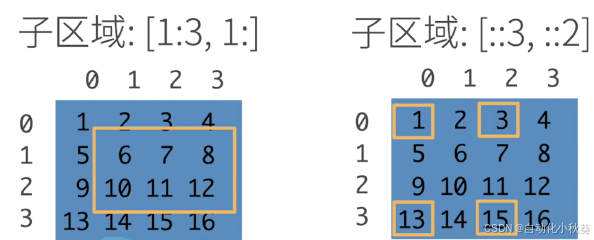
索引和切片
我们可以用[-1]选择最后一个元素,可以用[1:3]选择第二个和第三个元素:
除读取外,我们还可以通过指定索引来将元素写入矩阵。
X[1, 2] = 9 X#输出
tensor([[ 0., 1., 2., 3.], [ 4., 5., 9., 7.], [ 8., 9., 10., 11.]])第2行3列的元素变成9
更新张量内容:
可以使用X[:] = X + Y或X += Y来减少操作的内存开销。
要将大小为1的张量转换为Python标量,我们可以调用item函数或Python的内置函数。
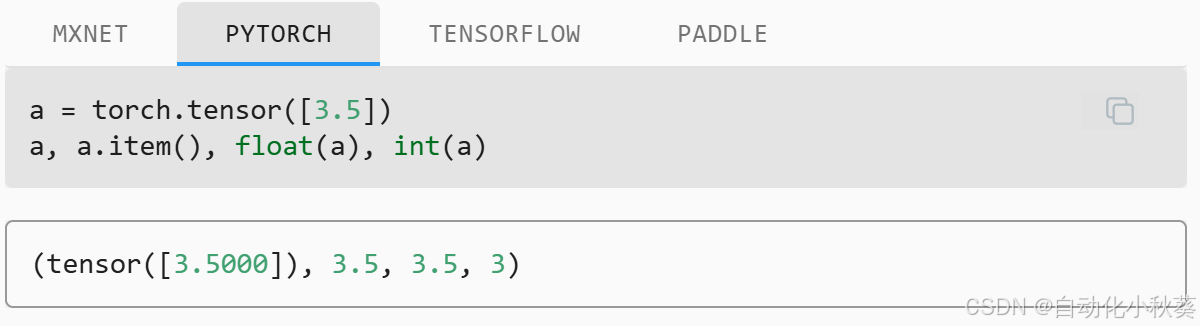
深度学习存储和操作数据的主要接口是张量