摘要 : 本文将详细介绍如何利用当前先进的深度学习目标检测算法 YOLOv12,结合强大的计算机视觉库 OpenCV,构建一个高效、准确的人脸情绪检测系统。我们将从环境搭建、数据准备、模型训练到最终的检测应用,手把手带你完成整个流程,为智能客服、驾驶员状态监控、心理健康评估、人机交互等场景提供实用的解决方案。
关键词: YOLOv12, OpenCV, 人脸情绪检测, 深度学习, 目标检测, Python
1. 引言
在人机交互、智能安防、车载系统及心理健康领域,实时识别人脸所表达的情绪状态具有重要价值。传统方法通常分为两步:先用人脸检测器(如 MTCNN)定位人脸,再用分类网络(如 ResNet)判断情绪。这种级联方式效率低、误差累积。而端到端的目标检测模型可同时完成人脸定位与情绪分类,大幅提升系统鲁棒性与实时性。
YOLO(You Only Look Once)系列算法以其高速度和高精度在目标检测领域独树一帜。最新的 YOLOv12 在继承前代优点的同时,进一步优化了架构和训练策略,性能更上一层楼 ,尤其适合处理人脸这类小目标且需细粒度分类的任务。OpenCV 作为最流行的开源计算机视觉库,提供了丰富的图像处理功能。本文将结合 YOLOv12 和 OpenCV,实现对人脸情绪的精准检测,支持以下 8 种基本情绪类别:
anger(愤怒)contempt(轻蔑)disgust(厌恶)fear(恐惧)happy(高兴)neutral(中性)sad(悲伤)surprise(惊讶)

2. 环境准备
2.1 软件依赖
首先,确保你的开发环境满足以下要求:
- Python: 推荐使用 Python 3.8 或更高版本。
- PyTorch: YOLOv12 基于 PyTorch 框架,需安装相应版本。
- YOLOv12 : 通过
ultralytics包安装。 - OpenCV: 用于图像处理和可视化。
- PyQT: 可视化UI(可选)。
安装命令:
bash
# 安装 PyTorch (根据你的CUDA版本选择)
pip install torch torchvision torchaudio
# 安装 YOLOv12
pip install ultralytics
# 安装 OpenCV
pip install opencv-python3. 数据集准备与标注
高质量的数据集是模型成功的关键。
3.1 数据收集
收集包含多样化人脸情绪的图像或视频帧,涵盖:
- 不同种族、年龄、性别
- 不同光照条件(室内、室外、背光、弱光)
- 不同姿态(正面、侧脸、低头、抬头)
- 不同遮挡情况(眼镜、口罩、头发)
- 真实场景 vs 实验室环境
推荐使用公开数据集:
- FER-2013
- AffectNet
- RAF-DB
- CK+
💡 注意:需将原始分类数据集转换为目标检测格式(每张图中每张人脸标注一个框+情绪标签)。
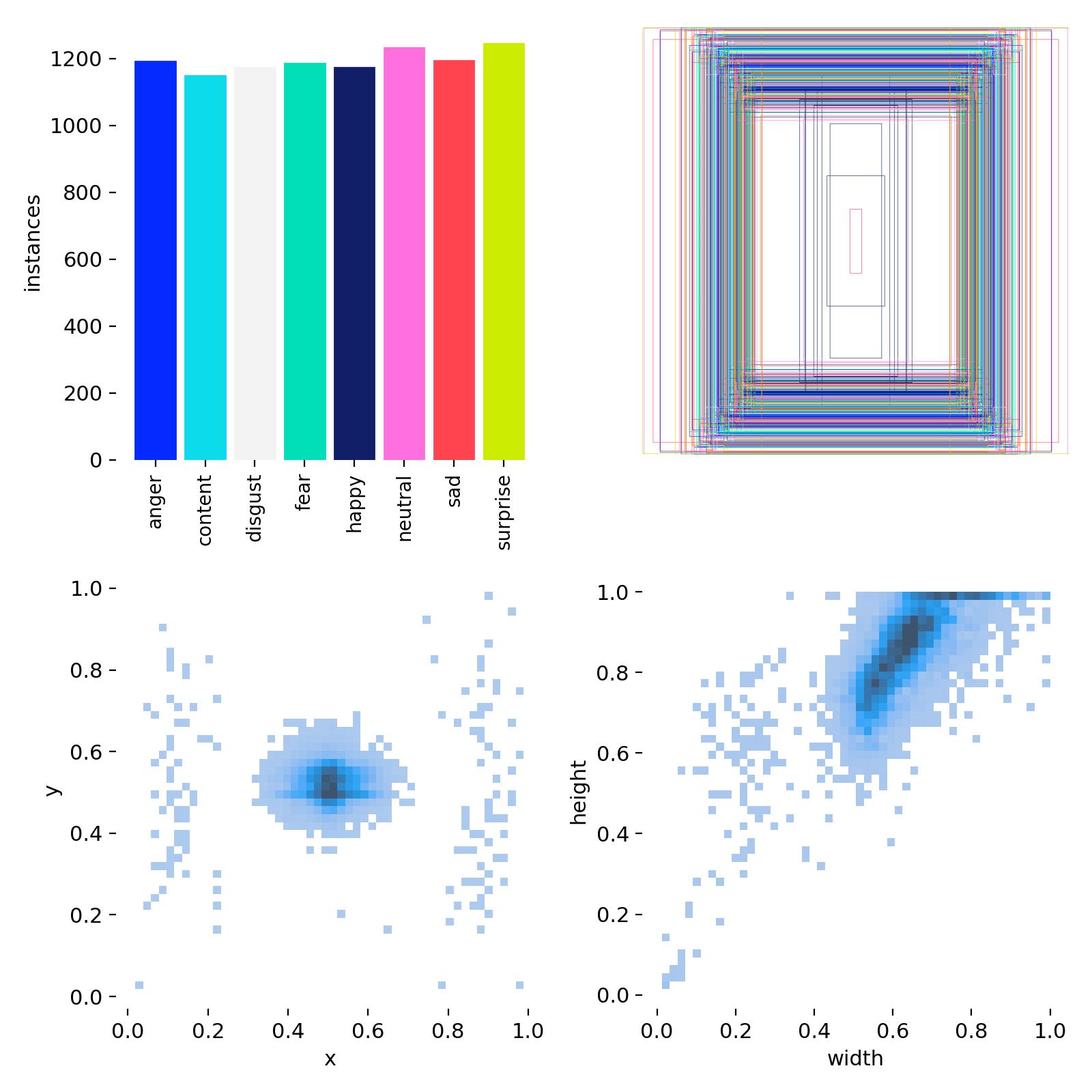
3.2 数据标注
使用标注工具(如 LabelImg, CVAT, Roboflow 等)对图像中的每一张人脸进行标注:
- 框出人脸边界(Bounding Box)
- 赋予对应的情绪类别标签(如
happy,neutral等)
标注格式 :YOLO 使用 .txt 文件存储标注信息,格式为:
txt
<class_id> <x_center> <y_center> <width> <height>所有坐标值都是相对于图像宽高的归一化值(0-1)。
类别 ID 映射示例:
| class_id | 情绪类别 |
|---|---|
| 0 | anger |
| 1 | contempt |
| 2 | disgust |
| 3 | fear |
| 4 | happy |
| 5 | neutral |
| 6 | sad |
| 7 | surprise |
3.3 数据集划分
将数据集划分为训练集(train)、验证集(val)和测试集(test),通常比例为 7:2:1 或 8:1:1。
3.4 数据集配置文件
创建一个 YAML 配置文件(如 facial_emotions.yaml),定义数据集路径和类别信息:
yaml
train: /path/to/dataset/images/train
val: /path/to/dataset/images/val
test: /path/to/dataset/images/test
# 类别数量
nc: 8
# 类别名称(顺序必须与 class_id 一致)
names: ['anger', 'contempt', 'disgust', 'fear', 'happy', 'neutral', 'sad', 'surprise']4. 模型训练
4.1 选择 YOLOv12 模型
YOLOv12 提供了多个预训练模型(yolov12n.pt, yolov12s.pt, yolov12m.pt, yolov12l.pt, yolov12x.pt)。对于人脸情绪检测(目标较小但需高分类精度),推荐使用 yolov12s.pt 或 yolov12m.pt。
4.2 开始训练
使用 ultralytics 提供的命令行工具或 Python API 进行训练。
命令行方式:
bash
yolo train data=facial_emotions.yaml model=yolov12s.pt epochs=100 imgsz=640Python API 方式:
python
from ultralytics import YOLO
# 加载预训练模型
model = YOLO('yolov12s.pt') # ✅ 关键:使用 yolov12s.pt
# 训练模型
results = model.train(data='facial_emotions.yaml', epochs=100, imgsz=640)
# 评估模型
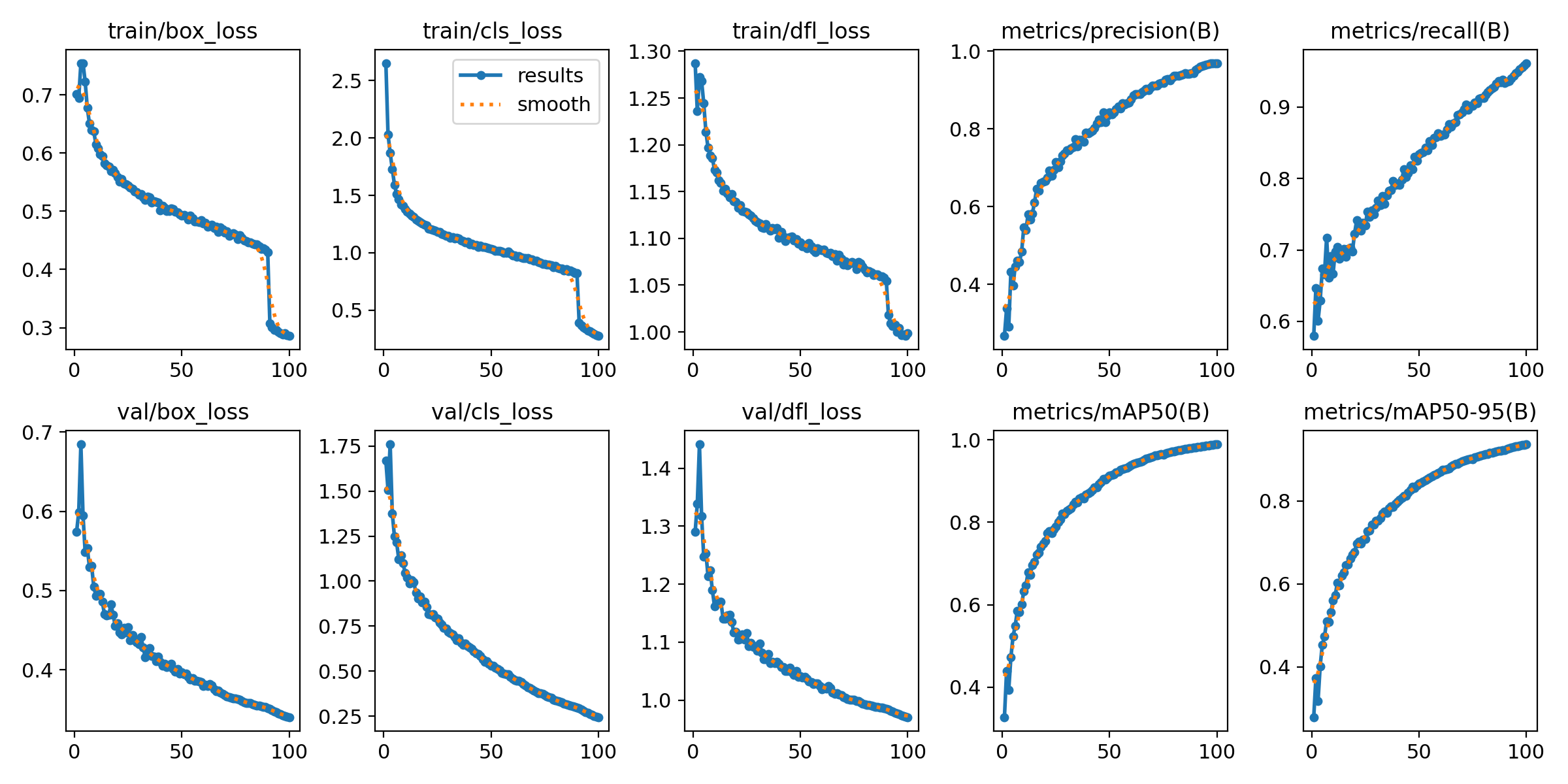
results = model.val()训练过程中,可监控损失函数、mAP(mean Average Precision)及各类别召回率,判断模型收敛情况。
5. 人脸情绪检测实现
训练完成后,使用训练好的模型进行实时检测。
5.1 加载模型
python
from ultralytics import YOLO
import cv2
# 加载训练好的模型
model = YOLO('runs/detect/train/weights/best.pt') # 替换为你的最佳权重路径5.2 图像检测
python
# 读取图像
img_path = 'group_photo.jpg'
img = cv2.imread(img_path)
# 使用模型进行预测
results = model(img)
# 解析结果
for result in results:
boxes = result.boxes # 获取边界框
for box in boxes:
# 提取坐标、置信度和类别
x1, y1, x2, y2 = box.xyxy[0].cpu().numpy().astype(int)
conf = box.conf.cpu().numpy()[0]
cls = int(box.cls.cpu().numpy()[0])
label = model.names[cls] # 如 'happy', 'neutral' 等
# 设置不同情绪的颜色(可选)
color_map = {
'anger': (0, 0, 255), # 红
'contempt': (255, 0, 255),# 紫
'disgust': (0, 255, 255), # 青
'fear': (255, 255, 0), # 黄
'happy': (0, 255, 0), # 绿
'neutral': (128, 128, 128),# 灰
'sad': (255, 0, 0), # 蓝
'surprise': (255, 165, 0) # 橙
}
color = color_map.get(label, (255, 255, 255))
# 在图像上绘制边界框和标签
cv2.rectangle(img, (x1, y1), (x2, y2), color, 2)
cv2.putText(img, f'{label} {conf:.2f}', (x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.9, color, 2)
# 显示结果
cv2.imshow('Facial Emotion Detection', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
5.3 视频流实时检测
可轻松应用于摄像头或视频文件,实现动态情绪分析:
python
cap = cv2.VideoCapture(0) # 0 表示默认摄像头
while True:
ret, frame = cap.read()
if not ret:
break
results = model(frame)
# ... (同上,处理结果并绘制)
cv2.imshow('Live Emotion Detection', frame)
if cv2.waitKey(1) == ord('q'):
break
cap.release()
cv2.destroyAllWindows()6. 结果与分析
- 精度 : 在 AffectNet 等大型数据集上,YOLOv12 通常能达到较高的 mAP@0.5,尤其对
happy、neutral、surprise等显著情绪识别效果好。 - 速度: YOLOv12 推理速度快,在 RTX 4070 上可达 60+ FPS(640x640 输入),满足实时交互需求。
- 鲁棒性: 模型对轻微遮挡、光照变化、非正脸具有一定适应能力。
挑战:
- 细微情绪区分 : 如
contempt与disgust外观相似。 - 文化差异: 情绪表达存在跨文化差异。
- 低质量图像: 模糊、低分辨率人脸影响识别。
优化方向:
- 使用 Mosaic 、MixUp 、Copy-Paste 等增强策略提升泛化性。
- 微调输入尺寸(如
imgsz=1280)以更好捕捉面部细节。 - 引入 注意力机制 或 知识蒸馏 提升小情绪类别性能。
- 结合时序信息(视频帧序列)提升稳定性。
7. 总结
本文详细介绍了基于 YOLOv12 和 OpenCV 实现人脸情绪检测的完整流程。通过端到端的目标检测框架,我们实现了人脸定位与8类情绪识别的一体化,避免了传统级联方法的复杂性与误差传递。该系统部署简单、响应迅速,可广泛应用于智能座舱、远程教育、虚拟现实、心理健康监测等前沿领域,为人机共情交互奠定技术基础。
🔒 伦理提醒:情绪识别技术涉及个人隐私与心理状态,使用时须遵守相关法律法规,获取用户知情同意,并避免用于歧视性或操纵性场景。