目录
[一. 指针是什么](#一. 指针是什么)
[💭 内存 :](#💭 内存 :)
[💬 问题:](#💬 问题:)
[⚡ 如何理解编址(拓展):](#⚡ 如何理解编址(拓展):)
[👉 指针 :](#👉 指针 :)
[📌 指针大小 :](#📌 指针大小 :)
[⭐ 总结 :](#⭐ 总结 :)
[二. 指针变量 和 指针类型](#二. 指针变量 和 指针类型)
[📏 指针变量:](#📏 指针变量:)
[🪐 指针变量和地址](#🪐 指针变量和地址)
[🚩 指针变量 ptr :](#🚩 指针变量 ptr :)
[🌎 指针类型:](#🌎 指针类型:)
[💫 指针类型的意义](#💫 指针类型的意义)
[⭐ 结论:](#⭐ 结论:)
[⭐ 总结 :](#⭐ 总结 :)
[🌊 指针 + - 整数](#🌊 指针 + - 整数)
[⭐ 结论:](#⭐ 结论:)
[❓ 问题:](#❓ 问题:)
[🌱 指针 - 指针](#🌱 指针 - 指针)
[⭐ 结论:](#⭐ 结论:)
[📚 应用场景:](#📚 应用场景:)
[🌴 指针的关系运算](#🌴 指针的关系运算)
[⭐ 总结 :编辑](#⭐ 总结 :编辑)
[四、const 修饰的指针](#四、const 修饰的指针)
[🛸 const 在 * 左边 :](#🛸 const 在 * 左边 :)
[🛸 const 在 * 右边 :](#🛸 const 在 * 右边 :)
[⭐ 结论 :](#⭐ 结论 :)
[🌌 野指针成因:](#🌌 野指针成因:)
[1. 指针未初始化](#1. 指针未初始化)
[2. 指针越界访问](#2. 指针越界访问)
[3. 指针指向的空间释放](#3. 指针指向的空间释放)
[💡 如何避免野指针](#💡 如何避免野指针)
[1. 指针初始化](#1. 指针初始化)
[2. 小心指针越界](#2. 小心指针越界)
[3. 指针指向空间释放,及时置NULL,指针使用之前检查有效性](#3. 指针指向空间释放,及时置NULL,指针使用之前检查有效性)
[4. 避免返回局部变量的地址](#4. 避免返回局部变量的地址)
[5. 指针使用之前检查有效性](#5. 指针使用之前检查有效性)
[⭐ 总结 :](#⭐ 总结 :)
[🧩 数组名的理解](#🧩 数组名的理解)
一. 指针是什么
💭 内存 :
要理解++指针++的概念,首先需要理解 内存和指针 的关系。
🔨 内存:
内存是电脑上特别重要的存储器,计算机中所有程序的运行都是在内存中进行的。所以为了有效的使用内存 ,就把内存划分成一个个小的内存单元 ,每个内存单元的大小是1个字节。 为了能够有效的访问 内存的每个单元 ,就给内存单元进行了编号 ,这些编号被称为该内存单元的地址。


💻 电脑分为 32位 和 64位 两种操作系统:




**64位:**同理 。
📋 注 :
32位 和 64位 :
这是根据 CPU 内的寄存器字长 来确定的 - 计算机内部数据都是二进制来呈现的
✦ 32 位的计算机 CPU 一次最多能处理 32 位的二进制数据
✦64 位的计算机 CPU 一次最多能处理 64 位的二进制数据
💬 问题:
1
1. 内存是怎么编号的?
因为有地址线,地址线通电时会产生电信号并转化为数字信号,对应的二进制序列就形成了地址。把地址作为编号分配给每一个内存单元,那么就会形成内存单元对应的地址(编号)。
1
2. 一个这样的内存单元是多大空间?
一个字节给一个对应的地址是比较合适的。
对于 32位 的机器,有 32根地址线,产生 2的32次方 个地址。 每个地址标识一个字节,那我们就可以给 (2^32Byte == 2^32 / 1024KB == 2^32 / 1024 / 1024MB == 2^32 / 1024 / 1024 / 1024GB == 4GB) 4GB 的空间进行编址。那么,2的32次方 个地址可以管理 4个G 的空间。
所以,一个内存单元是一个字节,然后分配地址的,一个字节给一个编号。
⚡ 如何理解编址(拓展):


地址总线传递过去就是地址信号,有了地址,就可以找到内存单元,拿到数据之后,再通过数据总线传回 CPU 内寄存器。
所以从硬件的角度来讲,这些地址是不需要存起来的,只要产生了一个地址,就可以通过地址很好的去访问内存单元。
🚀 我们知道计算上CPU(中央处理器)在处理数据的时候,需要的数据是在内存中读取的,处理后的数据也会放回内存中,那我们买电脑的时候,电脑上内存是 8GB / 16GB / 32GB 等,那么,如何高效的管理内存空间呢?
其实也是把内存划分为⼀个个的内存单元 ,每个内存单元的大小取 1 个字节。
💬 问题:
3. 当去访问一个内存空间的时候?
通过地址线产生一个地址信息,这时候把地址信息传递给内存,在内存上就可以找到该地址对应的数据,数据再通过数据总线传入CPU内寄存器。

到这里我们就可以明白:
👉 指针 :
指针是 内存中一个最小单元的编号 ,也就是 地址
平时说的指针,通常指的是 指针变量 ,是 用来存放内存地址的变量
附:
在计算机科学中,指针(Pointer)是编程语言中的一个对象,利用地址,它的值直接指向 (points to)存在电脑存储器中另一个地方的值。由于通过地址能找到所需的变量单元,可以说,地址指向该变量单元。因此,将地址形象化的称为"指针"。意思是通过它能找到以它为地址的内存单元。
📌 指针大小 :
一个比特位可以存储一个二进制数值,即 1 或 0
那么:
⭐ 注意:
指针变量的大小和类型是无关的,只要指针类型的变量,在相同的平台下,大小都是相同的。

⭐ 总结 :

相信看到这里,你对指针已经有了更深入的理解了~
那么,即然有了指针,该如何存放呢?指针有没有自己的类型呢?
二. 指针变量 和 指针类型
📏 指针变量:
首先,我们需要先来了解一下:
🪐 指针变量和地址

变量 a 对应的四个字节,这四个字节分别对应的地址:
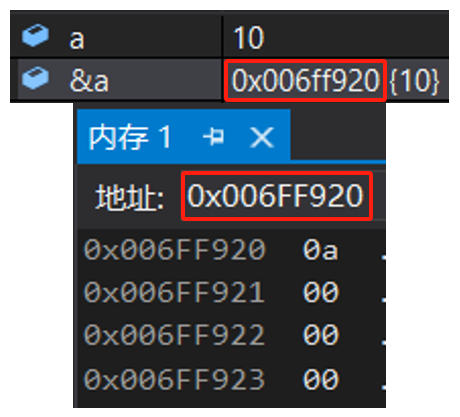
可以看到:一个字节对应一个地址
如何得到 a 的地址 ?
虽然整型变量占用 4 个字节,但只要知道第一个字节的地址,就能依次访问到 4 个字节的数据
|---------|--------------|
| & | 取地址操作符 |
| &a | 取出 a 的地址 |

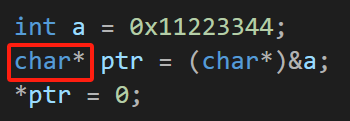
🚩 指针变量 ptr :
因为 prt 是 存放指针的变量 所以叫 指针变量
🌠 ptr 的类型是 int*
int* 该如何理解?
指针变量就是用来存放地址的,存在指针变量中的值,会被当成地址来使用



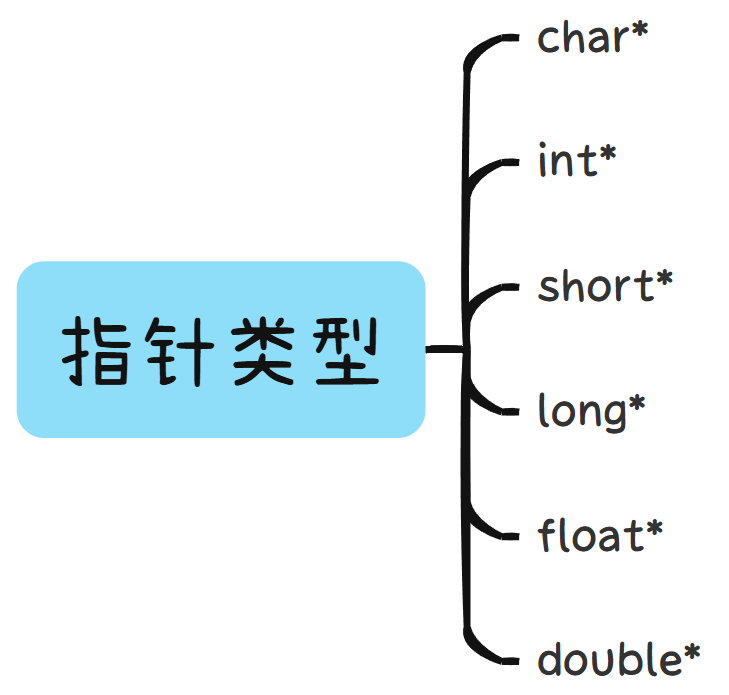
🌎 指针类型:
变量有不同的类型,整形,浮点型等。那指针有没有类型呢?
有的。
指针大小都一样 ,4 或 8 个字节(无论什么类型)但是划分为不同的类型。

( NULL 本质上是 0 )
%zu 是为 sizeof 准备的格式字符,打印用 %u 最合适( %zu 最准确 )
这里可以看到,指针的定义方式 是:type *( 类型* )
其实:
char* 类型的指针是为了存放 char 类型变量的地址。
short* 类型的指针是为了存放 short 类型变量的地址。
int* 类型的指针是为了存放 int 类型变量的地址。
💫 指针类型的意义
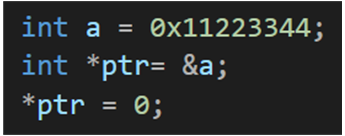
没改之前 a 的值 :

改之后 :把四个字节都改掉了
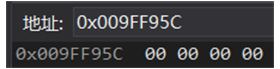
用 int* 的指针把四个字节都改了
改用另一种指针类型:
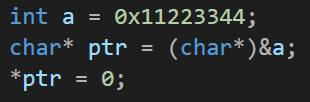
改之前:
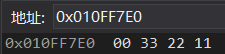
改之后:
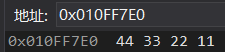
仅修改了一个字节
因为这里是 char* 的指针 访问的时候只访问了一个字节
所以,只更改了一个字节的值
而刚刚是 int* 的指针可以访问到四个字节,所以可以全部更改
⭐ 结论:
指针变量的类型 决定了 指针在被解引用时 能访问几个字节(指针的权限)
如果是int*的指针,解引用访问4个字节
如果是char*的指针,解引用访问1个字节
( 其他类型同理 )
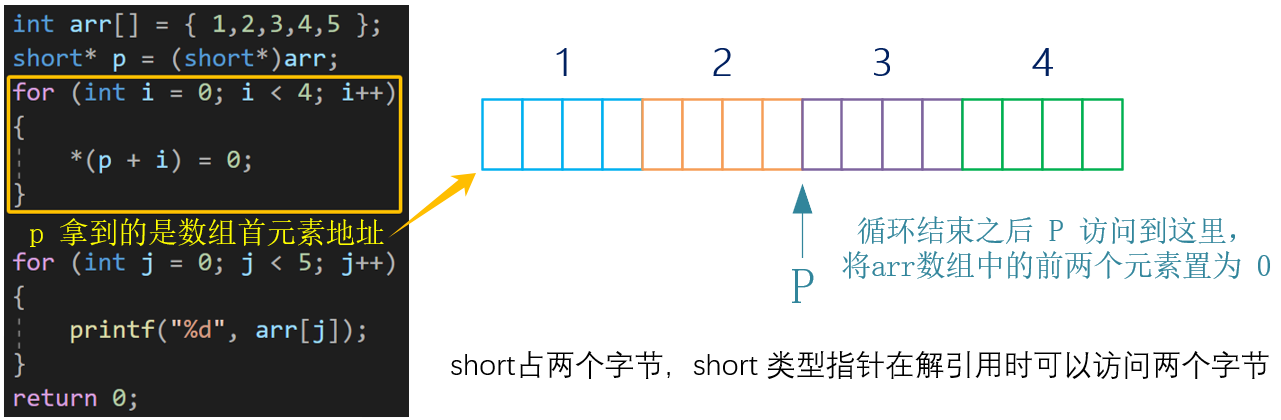
🌵 问题 :
最后打印的结果是 ?
📕 解析:解引用 4 次,一次两个字节,刚好把前八个字节置为 0 d
指针 p 的类型为 short* 类型 ,因此 p 每次只能访问两个字节
for 循环对数组中内容进行修改时,一次访问的是:
arr0 的低两个字节,arr0 的高两个字节,arr1 的低两个字节,arr1 的高两个字节
故最后打印:0 0 3 4 5

⭐ 总结 :

三、指针运算
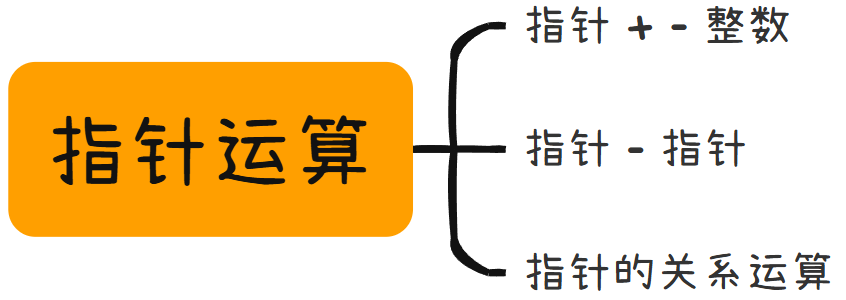
🌊 指针 + - 整数
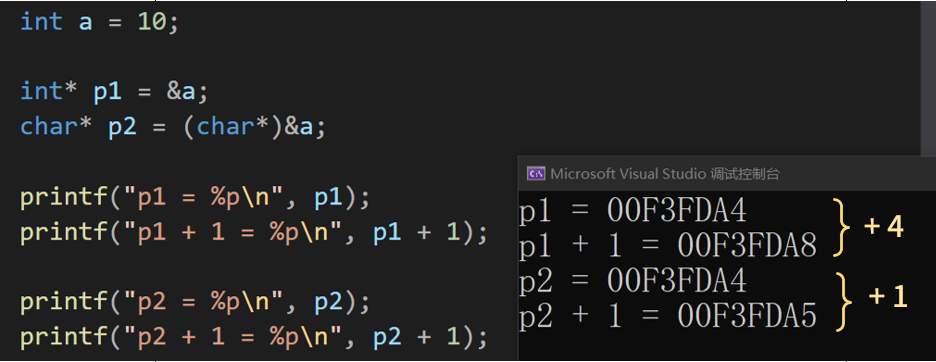
分别加了 4个字节 1个字节
⭐ 结论:
指针的类型 决定了 指针向前或者向后走一步有多大(距离)

char* 的指针 加一 跳过一个字节,加二 跳过两个字节......
int* 的指针 加一 跳过四个字节,加二 跳过八个字节.....
( 其他类型同理 )
❓ 问题:
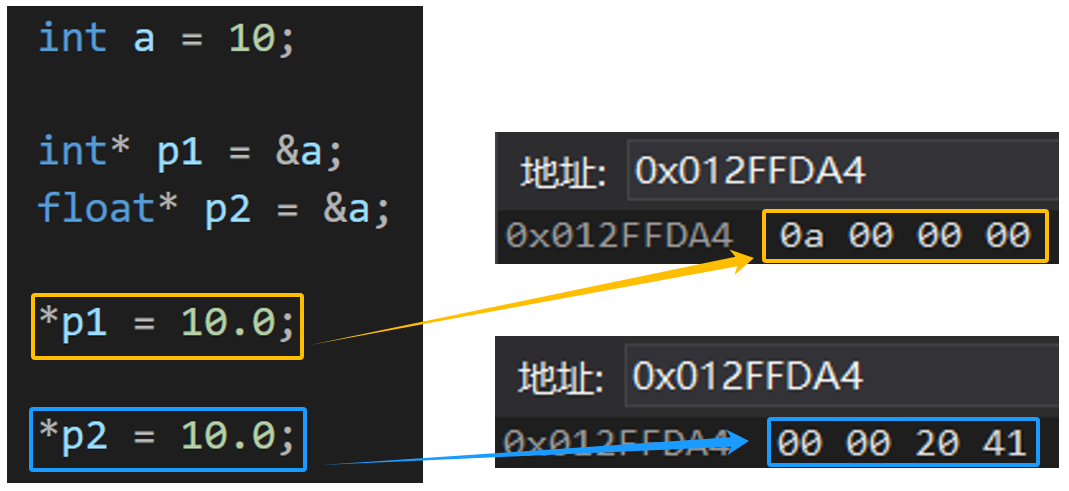
int* 和 float* 解引用都是访问 4 个字节,int* 和 float* 是不是就可以通用?
可以看到,在内存中是不一样的
float* 的指针认为指向内存中的数据是浮点数(int* 同理),浮点数和整数在内存中本质上存储方式是有所差异的
所以,即使 int* 和 float* 解引用都是访问 4 个字节,int* 和 float* 也不可以通用
🌱 指针 - 指针
前提:两个指针指向同一块空间
两个地址相减:
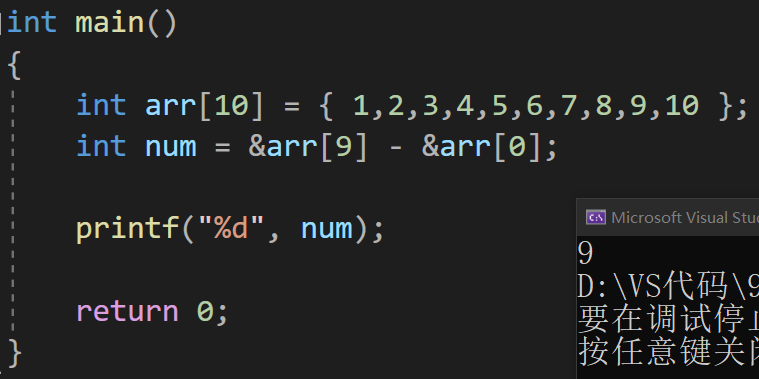
⭐ 结论:
指针 - 指针 = 指针与指针之间 的 元素个数
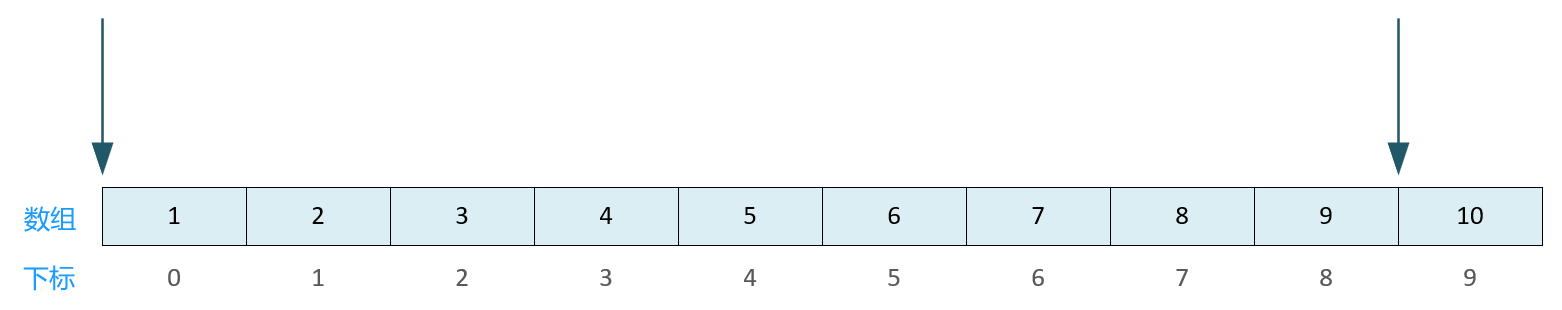
📚 应用场景:
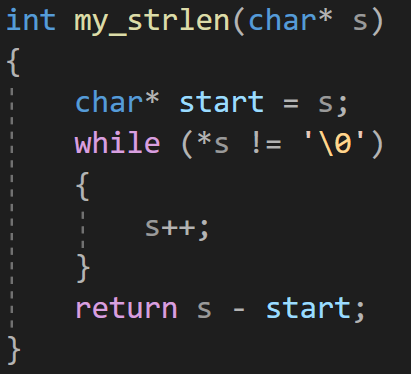
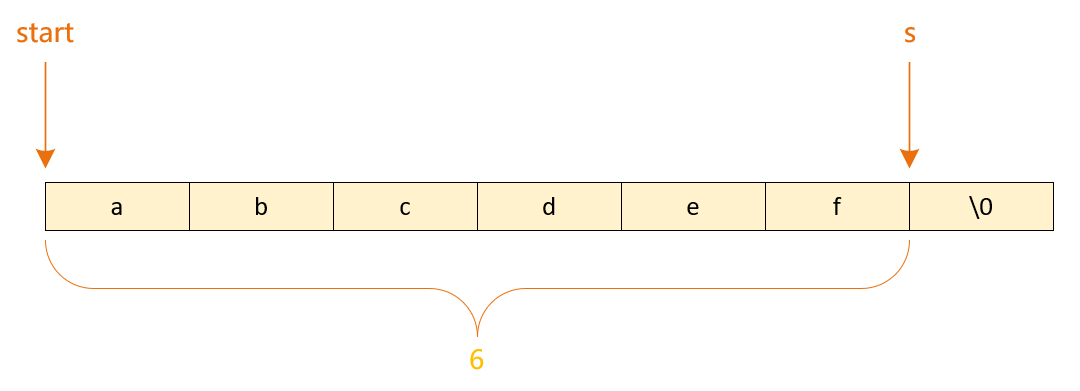
求字符串长度
\0 的地址 - 首元素地址 = 元素个数
🌴 指针的关系运算
指针比较大小 -- 地址比较大小

📝 规定:
允许 指向数组元素的指针 与 指向数组末尾之后的内存位置的指针 进行比较,但不允许与 指向数组起始位置之前 的内存位置的指针进行比较
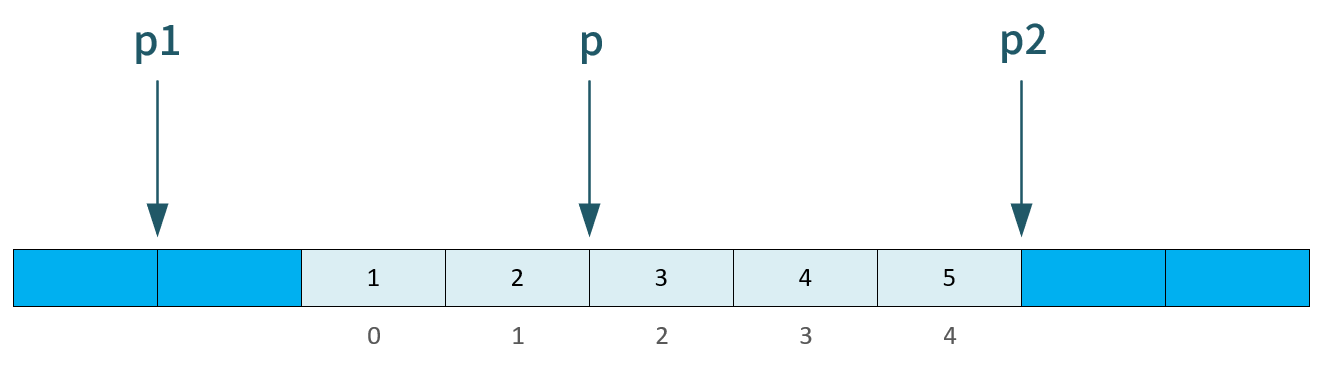
p 可以和 p2 比较,不可以和 p1 比较
⭐ 总结 :
四、const 修饰的指针
🛸 const 在 * 左边 :

当 const 放在 * 左边时,*p 无法修改, p 可以被修改
🛸 const 在 * 右边 :
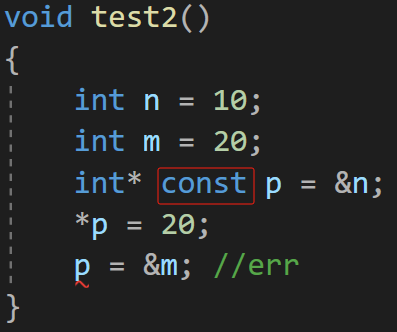
当 const 放在 * 右边时,*p 可以被修改,p 无法被修改
⭐ 结论 :
1
· const 修饰指针变量
1
- const 放在 * 的左边 ,修饰 的是 指针指向的内容 ,保证 指针指向的内容不能通过指针来改变, 但是 指针变量本身的内容可变
1
- const 放在 * 的右边 ,修饰 的是 指针变量本身 ,保证 指针变量的内容不能修改 ,但是 指针指向的内容,可以通过指针改变
1

五、野指针
定义:指针指向的位置是不可知的,可能是随机的、错误的或超出有效范围的
🌌 野指针成因:
1. 指针未初始化

局部变量不初始化,编译器会给它赋值一个随机值
2. 指针越界访问

下标范围在 0\~9
3. 指针指向的空间释放
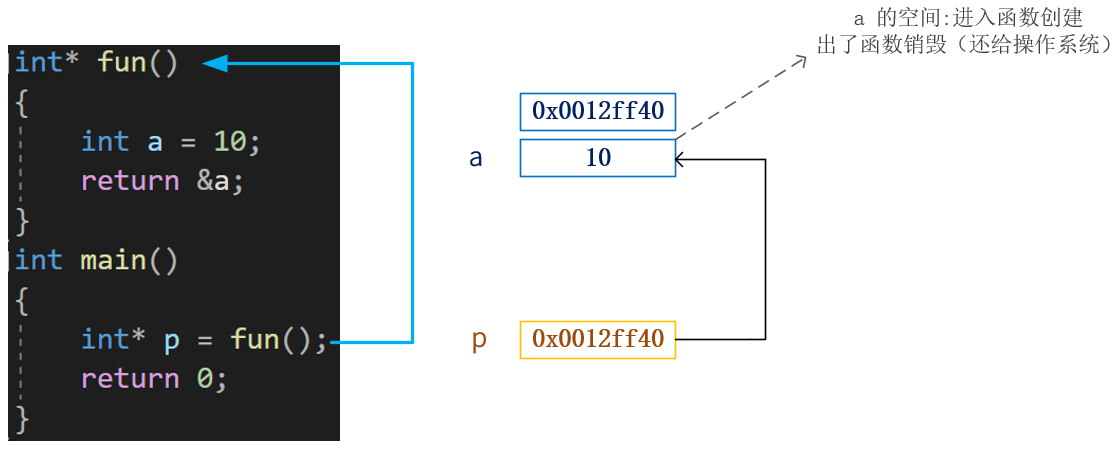
p 为野指针
当 fun 函数调用结束(fun 函数栈帧空间销毁),a 变量的空间销毁(还给操作系统,这块空间不属于我们了,不能使用了)
而p还保留着这块空间的地址,能够找到这块地址,但是不能使用访问
💡 如何避免野指针
1. 指针初始化
当明确知道指针指向哪⾥就直接赋值地址,如果不知道指针应该指向哪⾥,可以给指针赋值 NULL

( NULL 是C语⾔中定义的⼀个标识符常量,本质是 0,0 也是地址,但这个地址是⽆法使⽤的,读写该地址会报错)
对于 NULL 空指针(0 地址)是不能访问的,因为 *p 没有指向有效空间
正确的使用方式:
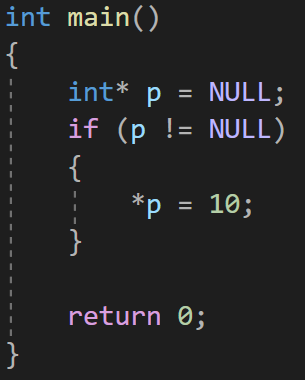
如果 p 不等于空,说明它指向有效的空间,就可以解引用它
所以 在初始化时 :给出明确地址 或者 赋值为空(空指针)
2. 小心指针越界
一个程序向内存申请了哪些空间,通过指针也就只能访问哪些空间,不能超出范围访问,超出了就是越界访问
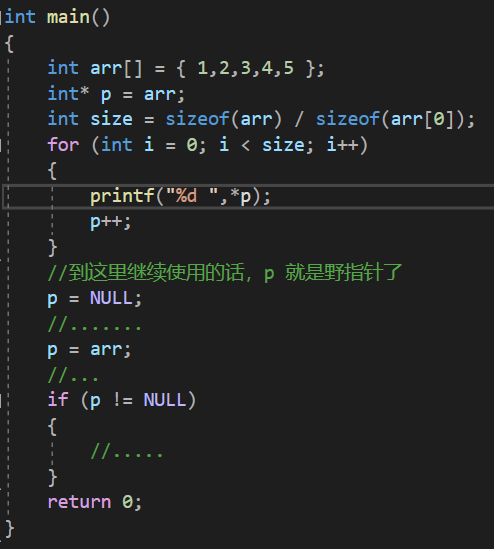
当指针指向的范围超出 arr 的范围,p 就是野指针
所以,在不使用 p 之后,先置为空,下次使⽤的时候,判断 p 不为 NULL 的时候再使⽤
**3. 指针指向空间释放,及时置NULL,**指针使用之前检查有效性
当指针变量指向⼀块区域的时候,可以通过指针访问该区域,当后期不再使用这个指针的时候,就把该指针置为 NULL
默认规则:只要是 NULL 指针就不去访问,同时使用指针之前可以判断指针是否为 NULL
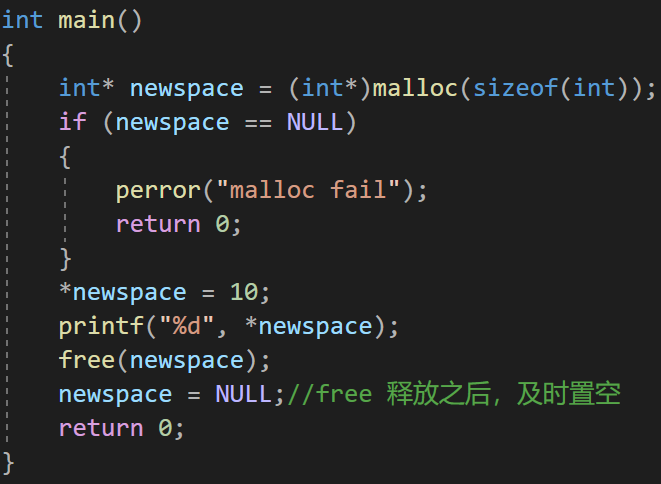
4. 避免返回局部变量的地址

arr 数组进入函数创建,出了函数销毁。当 p 再访问这块空间时,这块空间已经不属于当前程序了(局部变量在栈区,当返回一个局部变量的时候就是返回一块栈上空间的地址)
5. 指针使用之前检查有效性
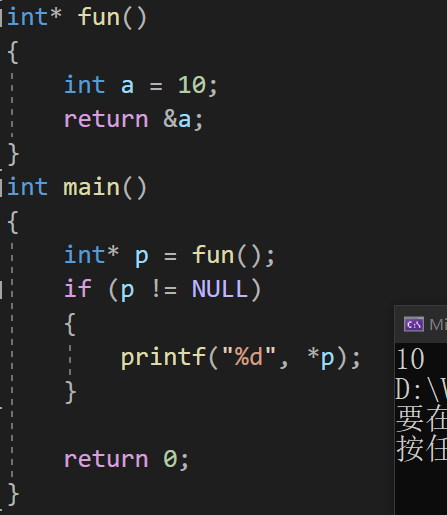
a的空间确实是销毁了(空间销毁,这块空间不属于当前程序,没有这块空间的使用权限)
当通过p所指向的非法地址,找到a的空间时,如果这块空间没有被使用,没有被覆盖,里面放的就是10,但这个值可能会发生变化
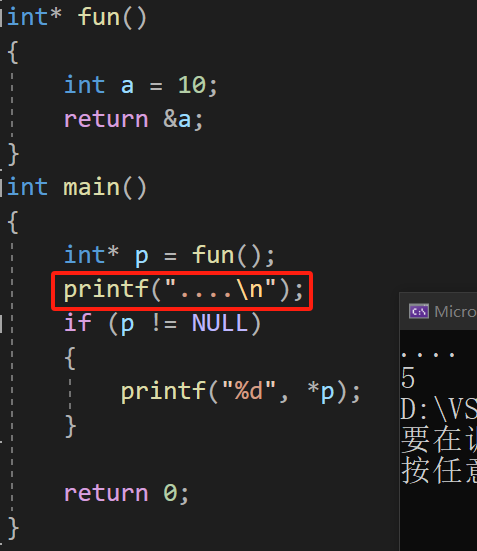
首先调用 fun,内存中会创建 fun 的函数栈帧,调用完成之后 fun 函数栈帧销毁,这块空间就会空出来,接着调用 printf 函数时,又会创建 printf 的函数栈帧,就会把上一次的函数栈帧覆盖了,10 就会改变
⭐ 总结 :
避免野指针:

附:
释放内存空间后,将指针置为NULL 是一个良好的编程习惯
当释放一个指针所指向的内存空间时,该指针仍然保留着指向已释放内存的地址。如果在后续的代码中尝试使用这个指针,可能会导致 悬空指针的问题,即:访问已经释放的内存块,引发不可预测的行为和错误。
为了避免悬空指针问题,可以在释放内存空间后立即将指针置为NULL,这样任何后续对该指针的使用都可以被及时检测到。
当你需要检查指针是否有效或重新分配内存时,检查指针是否为NULL可以提供一个简单可靠的方式。
六、指针和数组
🧩 数组名的理解

可以看到,数组名 和 数组首元素地址一样
💡 结论:
数组名 就是 数组首元素地址
🌟 例外:
除此之外,遇到的 所有的数组名 都是 数组首元素的地址

那么,也可以这样写:
用指针存放数组数组首元素地址:

可以看到地址完全相同
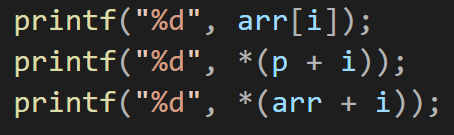
所以 p + i 计算的是数组 arr 下标为 i 的地址,那么,就可以直接通过指针来访问数组
同理,打印元素:
七、二级指针
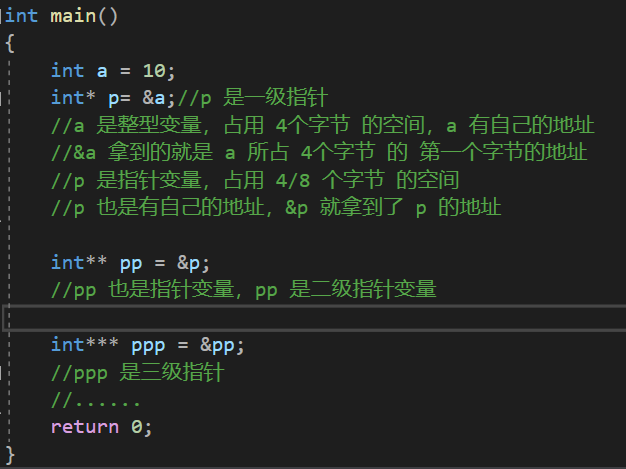
指针变量本质上也是一种变量,而所有变量都拥有自己的地址
那么,指针变量的地址该如何存储呢 ?
这就是 二级指针

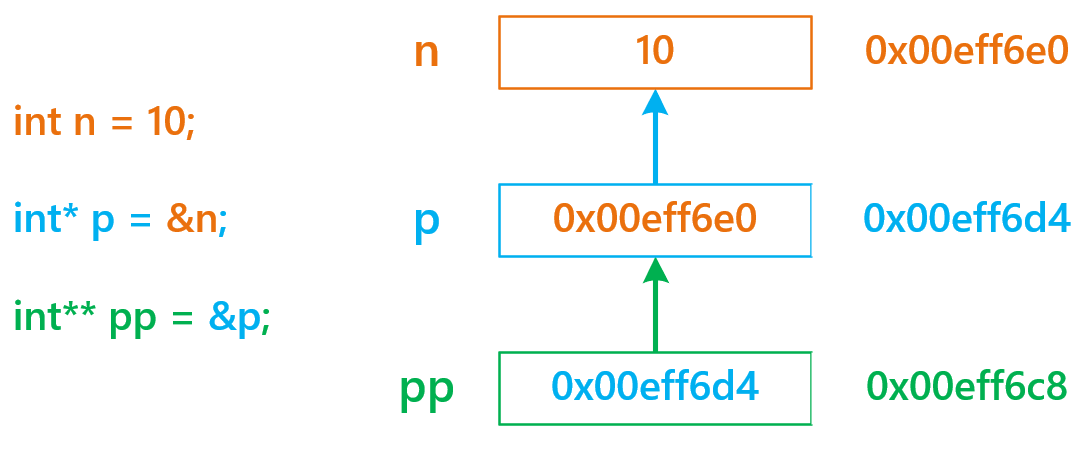
n 的地址存放在 一级指针 p 中,p 的地址存放在 二级指针 pp 中
💬 通过 pp 想找到 n
要 解引用 两次 :
第一次 解引用 pp 可以找到 p
第二次 再对 p 解引用 找到 n


二级指针变量是用来存放一级指针变量的地址的

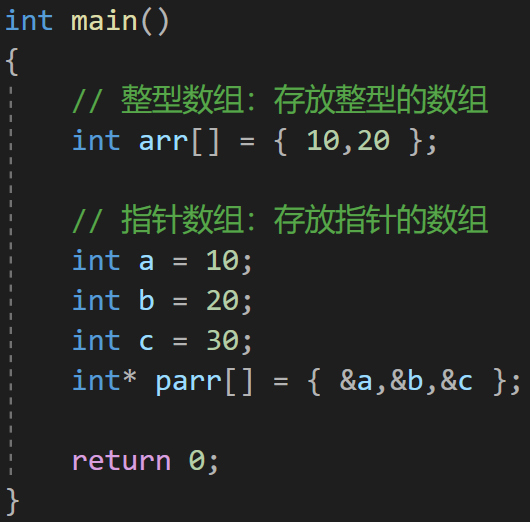
八、指针数组
存放指针的数组
int* arr3;
arr 是一个指针数组,每个元素的类型是指针


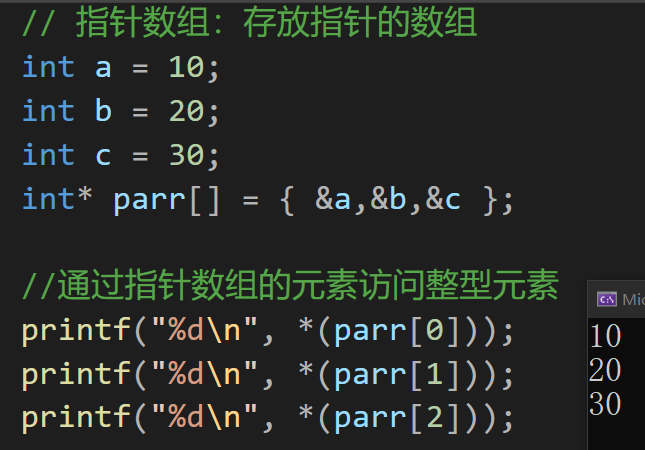

i 用来访问 parr 数组中的元素
j 用来访问 arr 数组中的元素
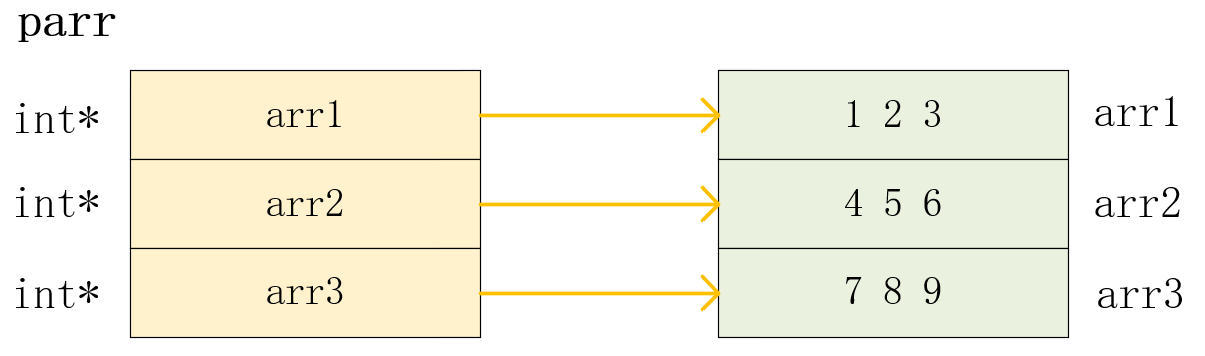
原始二维数组 :

两 者 等 价

知道这一点后
🎈 为什么数组下标从 0 开始 ?
0
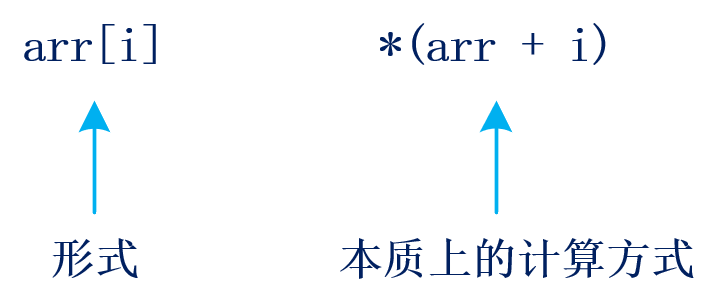
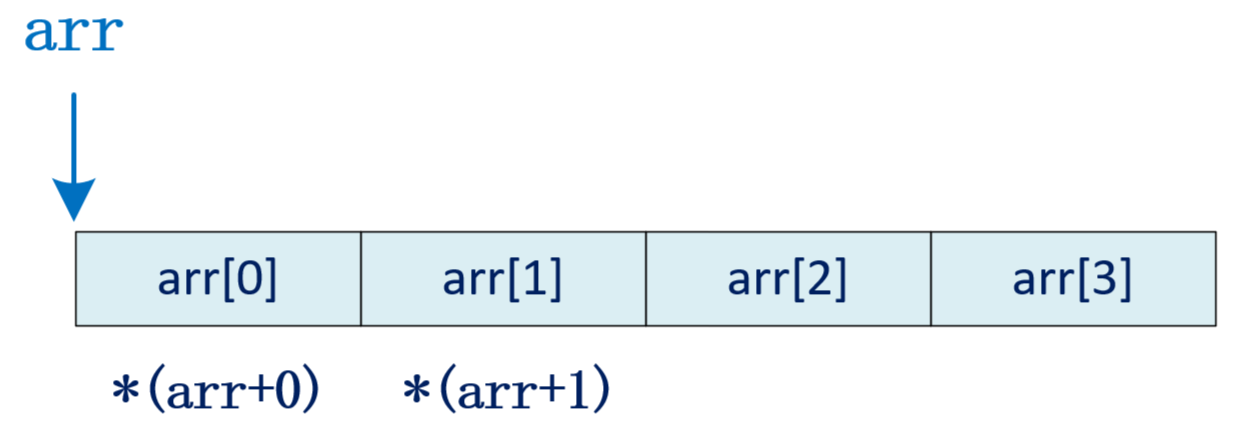
数组名 表示 数组首元素的地址
当我们访问arr[i] 时,编译器视角是:*(arr + i) ,而 下标本质是:相对于首元素的地址偏移量,首元素的偏移量为 0
🧲 所以:
arr0 就是 *(arr + 0) ,即首元素本身如果数组下标从 1 开始,那么 arr1 就是:*(arr + 1),会指向后一个位置
所以,数组下标从 0 开始使得 下标与偏移量保持一致

上篇(完)感谢浏览~~(努力写出更高质量的文章ing...)
努力更新.........坚持学习,大家加油,早日成为技术大佬 hh,有什么问题和建议都可以留言或私信找我交流,大家一起进步 ~~~