论文信息
论文题目:Wonder3D: Single Image to 3D using Cross-Domain Diffusion(Wonder3D:单图像到3D使用跨域扩散)
会议:CVPR2024
摘要:在这项工作中,我们介绍了Wonder3D,一种从单视图图像高效生成高保真纹理网格的新方法。最近基于分数蒸馏采样(SDS)的方法已经显示出从2D扩散先验中恢复3D几何形状的潜力,但它们通常存在耗时的每形状优化和几何不一致的问题。相比之下,某些作品通过快速网络推理直接产生三维信息,但其结果往往质量较低,缺乏几何细节。为了全面提高单视图重建任务的质量、一致性和效率,我们提出了一种生成多视图法线贴图和相应彩色图像的跨域扩散模型。为了确保生成的一致性,我们采用了多视图跨域注意机制,促进了视图和模态之间的信息交换。最后,我们引入了一种几何感知的法向融合算法,该算法仅在2 ~ 3分钟内从多视图2D表示中提取高质量的表面。我们的大量评估表明,与之前的工作相比,我们的方法获得了高质量的重建结果,鲁棒的泛化和良好的效率。

🎯 研究背景
想象一下,你只需要一张照片,就能在2-3分钟内生成一个高质量的3D模型。这听起来像科幻电影,但Wonder3D让这成为了现实!
传统方法的困境
在Wonder3D之前,单图像3D重建主要面临两大技术路线的困境:
1. 基于SDS优化的方法
- ✅ 优点:生成质量高,细节丰富
- ❌ 缺点:速度极慢,每个模型需要几十分钟甚至几小时
- 🔧 代表作:DreamFusion, Magic3D
2. 直接3D生成方法
- ✅ 优点:速度快,几秒钟出结果
- ❌ 缺点:质量差,缺乏几何细节,泛化性弱
- 🔧 代表作:Point-E, Shap-E
这就像是在"质量"和"速度"之间做选择题,而Wonder3D说:"小孩子才做选择,我全都要!"
🚀 核心创新
1. 跨域扩散模型:同时生成法线图和彩色图
传统思路的问题
单张图片 → 多视角彩色图 → 3D重建问题:彩色图包含的几何信息有限,重建效果差
Wonder3D的创新
单张图片 → 多视角法线图 + 多视角彩色图 → 3D重建优势:法线图直接编码表面几何信息,重建质量显著提升
2. 域切换器:一个模型生成两种数据
这是一个绝妙的设计!传统方法需要训练两个独立的模型:
- 模型A:生成法线图
- 模型B:生成彩色图
Wonder3D只用一个模型,通过"域切换器"告诉模型当前要生成什么:
# 伪代码示例
if domain_switcher == 0:
output = model.generate_normal_maps(input_image)
else:
output = model.generate_color_images(input_image)技术细节:
- 域标识符通过位置编码转换为嵌入向量
- 与时间嵌入拼接,注入到UNet中
- 不会破坏预训练权重,保持泛化能力
3. 跨域注意力机制:确保几何一致性
想象你在画一个苹果:
- 法线图告诉你表面的凹凸起伏
- 彩色图告诉你颜色和纹理
如果两者不一致,重建的3D模型就会很奇怪。跨域注意力机制确保同一视角的法线图和彩色图在几何上完全对应。
4. 几何感知的法线融合
从多个视角的法线图重建3D几何时,不是所有像素都同等重要:
几何感知权重公式:
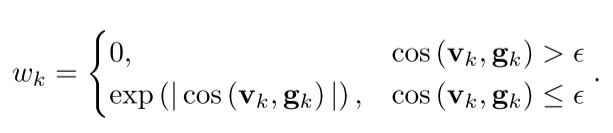
其中:
v_k:视线方向g_k:法线方向ε:阈值(接近0的负数)
直觉理解:
- 法线方向应该向外,视线方向向内
- 两者夹角越大,该像素的权重越高
- 这样可以过滤掉不准确的法线预测
🔬 技术架构
整体流程
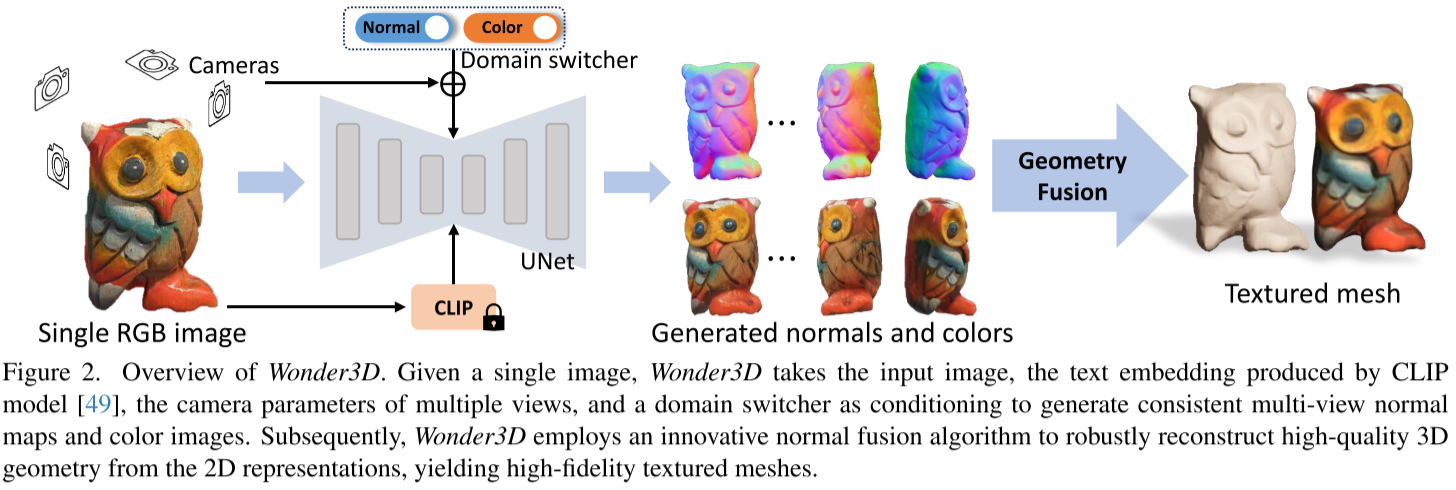
graph LR
A[单张输入图片] --> B[跨域扩散模型]
C[相机参数] --> B
D[域切换器] --> B
B --> E[多视角法线图]
B --> F[多视角彩色图]
E --> G[几何感知法线融合]
F --> G
G --> H[高质量3D网格]多视角跨域Transformer块
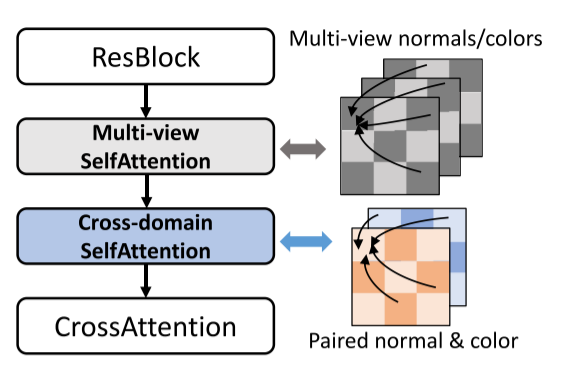
Wonder3D的核心是一个特殊设计的Transformer块,它同时处理多视角和跨域信息:
class Wonder3DTransformerBlock:
def forward(self, normal_features, color_features):
# 1. 多视角自注意力:确保视角间一致性
normal_features = multiview_attention(normal_features)
color_features = multiview_attention(color_features)
# 2. 跨域注意力:确保法线和颜色几何一致
normal_features, color_features = cross_domain_attention(
normal_features, color_features
)
# 3. 前馈网络
normal_features = mlp(normal_features)
color_features = mlp(color_features)
return normal_features, color_features📊 实验结果
定量对比
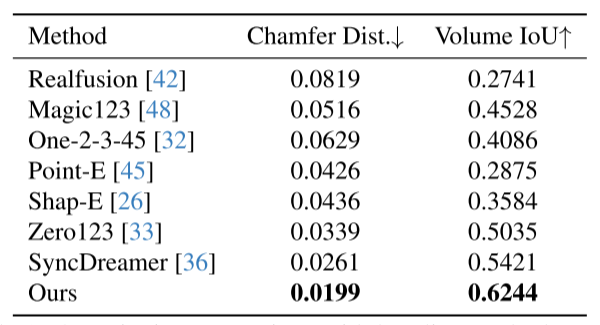 |
|---|
定性对比
从视觉效果来看:
- SyncDreamer:形状大致正确,但缺乏细节,纹理模糊
- Zero123:多视角不一致,存在"多脸问题"
- Wonder3D:几何细节丰富,纹理清晰,多视角一致
🛠️ 实现细节
训练数据
- 数据集:Objaverse LVIS子集(30k+对象)
- 视角设置:6个视角(前、后、左、右、前右、前左)
- 渲染工具:BlenderProc
- 图像分辨率:256×256
训练配置
# 训练超参数
batch_size = 512
learning_rate = 1e-4
training_steps = 30000
image_size = 256
num_views = 6
# 硬件需求
gpus = 8 * A800
training_time = 3天推理优化
SDF重建优化目标:
L = L_normal + L_rgb + L_mask + R_eik + R_sparse + R_smooth其中:
L_normal:几何感知法线损失L_rgb:颜色重建损失L_mask:掩码损失R_eik:Eikonal正则化R_sparse:稀疏正则化R_smooth:平滑正则化
🎯 创新点总结
1. 理论创新
- 跨域建模:首次将3D资产分布建模为法线图和彩色图的联合分布
- 域切换设计:优雅地解决了单模型多域生成问题
- 几何感知融合:基于几何原理的法线融合算法
2. 工程创新
- 高效架构:在预训练模型上微调,避免从零训练
- 注意力机制:巧妙结合多视角和跨域注意力
- 异常值处理:自动过滤低质量预测
3. 效果创新
- 质量突破:在所有评估指标上达到最佳效果
- 速度革命:2-3分钟完成高质量重建
- 泛化能力:在未见过的图像上表现优异
🚀 应用前景
1. 内容创作
- 游戏开发:快速生成游戏资产
- 影视制作:概念设计到3D模型的快速转换
- 虚拟现实:丰富VR/AR内容
2. 电商应用
- 商品展示:从产品照片生成3D展示
- 虚拟试穿:服装、饰品的3D建模
- 家具预览:家居产品的空间放置
3. 教育科研
- 文物保护:历史文物的数字化重建
- 医学影像:辅助医学3D建模
- 机器人视觉:提升机器人的3D感知能力
📚 延伸阅读
相关工作比较
| 方法类别 | 代表作 | 优点 | 缺点 |
|---|---|---|---|
| SDS优化 | DreamFusion, Magic3D | 质量高 | 速度慢 |
| 直接3D生成 | Point-E, Shap-E | 速度快 | 质量差 |
| 多视角生成 | SyncDreamer, MVDream | 一致性好 | 细节不足 |
| 跨域扩散 | Wonder3D | 质量高+速度快 | 计算资源需求高 |
技术发展趋势
- 更少视角:从6视角降低到3-4视角
- 更高分辨率:从256×256提升到512×512或更高
- 实时生成:从分钟级优化到秒级生成
- 端到端:集成更多下游任务
🤔 局限性与改进方向
当前局限
- 视角限制:只使用6个视角,对细长结构重建困难
- 计算需求:需要高端GPU进行训练
- 数据依赖:性能受训练数据质量影响
改进方向
- 更高效的多视角注意力:处理更多视角
- 自适应视角选择:根据物体特点动态选择视角
- 轻量化模型:降低推理计算需求
- 零样本泛化:提升对新领域图像的适应性
🎉 总结
Wonder3D代表了单图像3D重建领域的重大突破:
✨ 技术突破 :跨域扩散模型开创了新的技术路线
⚡ 效率革命 :将重建时间从小时级降低到分钟级
🎯 质量提升 :在所有评估指标上达到最佳效果
🌍 应用广泛:为内容创作、电商、教育等领域带来新机遇
这项工作不仅解决了长期存在的技术难题,更为3D内容生成的产业化应用铺平了道路。相信在不久的将来,我们每个人都能轻松地将照片转换为精美的3D模型!