读论文的方法:
1.title
2.abstract
3.introduction
4.method
5.experiments
6.conclusion
第一遍:标题、摘要、结论。可以看一看方法和实验部分重要的图和表。这样可以花费十几分钟时间了解到论文是否适合你的研究方向。
第二遍:确定论文值得读之后,可以快速的把整个论文过一遍,不需要知道所有的细节,需要了解重要的图和表,知道每一个部分在干什么,圈出相关文献。觉得文章太难,可以读引用的文献。
第三遍:提出什么问题,用什么方法来解决这个问题。实验是怎么做的。合上文章,回忆每一个部分在讲什么。
一 概念
1.激活函数 使函数从线性到非线性的辅助工具
2.神经元:某个输入或输出
3.神经元扩展与隐藏层:每套一层线性变换,神经元水平方向就扩展一层,扩展后中间层(原输出层)不再是最后的输出层,包含在复杂的函数变换之中,成为隐藏层
x1与x2经过一次线性变换后,再套一层激活函数得到隐藏层,隐藏层再经过一次线性变换,套一层激活函数得到输出层
4.神经网络:输入层-隐藏层-输出层这样一个结构叫神经网络
5.神经网络的前向传播:从输入层到隐藏层再到输出层的这样一个函数计算流程就是前向传播
6.神经网络的本质就是经过不断的线性变换和激活函数得到复杂的非线性函数,通过计算出非线性函数中的参数w和b,使得函数更好的拟合真是数据。
7.损失函数L:n个预测数据与真实数据的误差绝对值的和
均方误差MSE(损失函数的一种):L(w,b)=n个(预测数据与真实数据的误差)²的和,除以n
目标:求解让L最小的w和b的值
8.梯度下降
损失函数的导数=0可得到w b,但是神经网络比较复杂,只能通过不断调整w b等参数来逼近真实答案,调整的过程叫梯度下降
w/b的偏导指的是随着单一变量w/b的变化,L的变化率。
为了使得损失变小,要让w b往偏导数的反方向变化,这是因为偏导为正,说明随着 w/b的增加,损失增大,偏导为负,说明随着 w/b的增加,损失减小。
为了让损失一直变小,需要使得
w/b➕(➖w/b的偏导),如w=w-w的偏导。
为了控制变化的快慢,在w的偏导数前加一个系数η,w=w-ηw的偏导,这个过程叫梯度下降。
9.反向传播:直接求偏导很困难,需要从输出层开始,利用链式法则逐层求导,计算损失函数对每个参数(权重 w、偏置 b)的偏导数(即梯度),得到每个参数对损失的"影响程度"。
10.神经网络的一次训练:前向传播-计算损失-反向传播-更新参数(每个参数都朝着梯度的反方向变化)。因此训练过程就是不断调整参数的过程。
11.过拟合:训练数据上表现好,测试数据表现糟糕。
12.泛化能力:在没见过的数据上的表现能力。
13.数据增强:通过对图像裁剪 翻转 加噪声等操作在原有的数据中创造更多图像数据,这样不仅增加了数据,还增强了模型鲁棒性。
14.鲁棒性:不因为小的变化而对模型产生较大影响。
15.过拟合优化:增加数据(如数据增强),早停(提前终止训练过程防止过分拟合),正则化,dropout(训练时随机丢弃一些参数,避免过度依赖部分参数)
16.正则化:向损失函数中添加权重惩罚性抑制损失函数野蛮生长的方法
L1正则化:新损失函数=损失函数➕λ参数w绝对值的和
L2正则化:新损失函数=损失函数➕λ参数w平方的和
w是模型权重,λ是正则化强度,偏置b由于对模型复杂度影响很小一般不参数正则化,惩罚它很可能导致欠拟合。
λ越大,w就会被限制的越小,
控制参数的参数叫超参数
绝对值之和叫L1范数,平方和的平方根要L2范数
17.其它模型训练过程中遇到的问题和解决方法
梯度消失:梯度反向传播时越来越小导致参数更新困难
梯度爆炸:梯度数值越来越大,导致参数的调整幅度失去控制
解决:用梯度裁剪防止梯度更新过大;用合理的网络结构如残差网络来防止深层网络的梯度衰减;用合理的权重初始化和将输入数据归一化让梯度分布更平滑
收敛速度过慢:陷入局部最优和来回震荡
用动量法、RMSProp、Adam等自适应优化器来加速收敛,减少震荡
计算开销过大:数据规模太大,每次训练太耗时
用mini-batch把巨量的训练数据分割成小批次来减少单个的训练开销
18.全连接层FC:当前层的每个神经元与上一层的所有神经元都存在连接
19.卷积核:传统的卷积核是已知的固定矩阵,可以实现模糊效果、锐化效果、轮廓效果等;深度学习领域的卷积核是未知的,是被训练出来的。
卷积层相当于用一个卷积核替换掉全连接层的其中一层,大大减少权重参数量,同时更能捕捉图片的局部特征。
为什么说更能捕捉图片的局部特征?
卷积核的大小远小于输入图像,每个卷积核只和输入图像的局部区域连接。 比如用 3×3 卷积核扫描 32×32
图片,每个卷积核每次只依赖图片中3×3=9 个相邻像素(比如 3×3
区域内的像素灰度变化→边缘特征),输出一个特征值,能精准捕捉局部特征(边缘、纹理等)
32×32的图片,如果全连接层要输出 32×32=1024 个特征(和卷积层输出尺寸一致):
每个输出特征(神经元)都要和 1024 个输入像素全连接 → 每个输出对应 1024 个权重;
总参数量 = 1024(输出数)× 1024(输入数)= 1,048,576 个权重(还没算偏置)。
而卷积层只需要卷积核大小,也就是9个权重。
为什么每1个输出对应 1024 个权重?
全连接层中每个输出神经元,本质是一个 "带独立权重 + 偏置 + 激活函数" 的计算单元。
一个输出对应一个带权重激活函数,而每个输出和输入的连接都会对应一个新的带权重激活函数。1024个输出和1024个输入会生成1,048,576 个权重。
20.池化层:对卷积后的特征图像进行降维,减少计算量,同时保留主要特征
21.卷积神经网络:适用于图像识别的神经网络结构,局限性在于只能处理静态图片
22.词嵌入和嵌入矩阵
one-hot(独热编码)是将离散符号(如单词、类别)转化为数值向量的基础方法,核心是用 "高维稀疏向量" 表示离散元素,是文本、分类特征数值化的早期常用方式,向量中仅对应元素的位置为 1,其余位置全为 0;
词嵌入:one-hot的优化,把高维稀疏的文本转化为计算机可理解的低纬稠密的数值向量,且语义相近的单词向量距离更近
嵌入矩阵:实现这一转化的 "字典 + 映射工具"

23.循环神经网络RNN
专门处理序列数据的神经网络,核心特点是通过 "隐藏状态的循环传递" 保留序列的历史信息
缺点是无法捕捉长期以来和无法并行处理
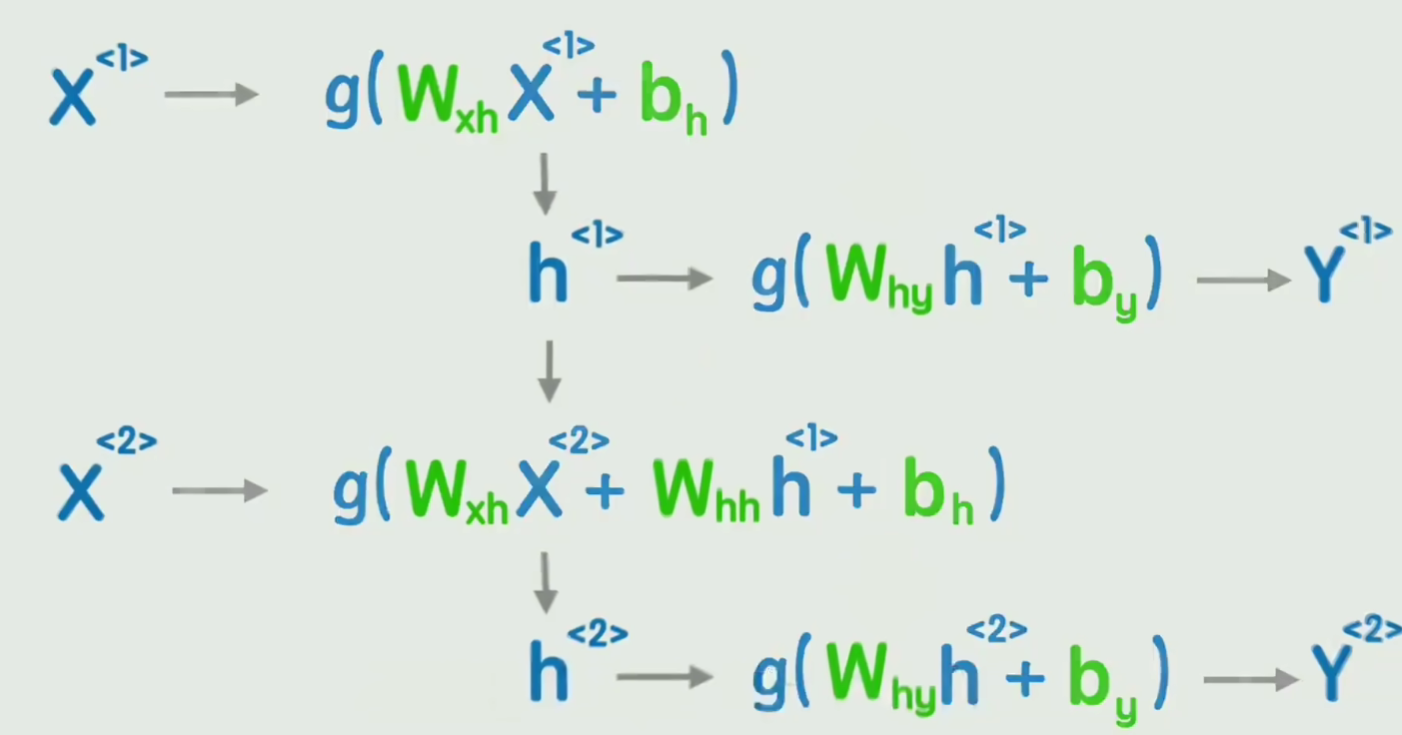
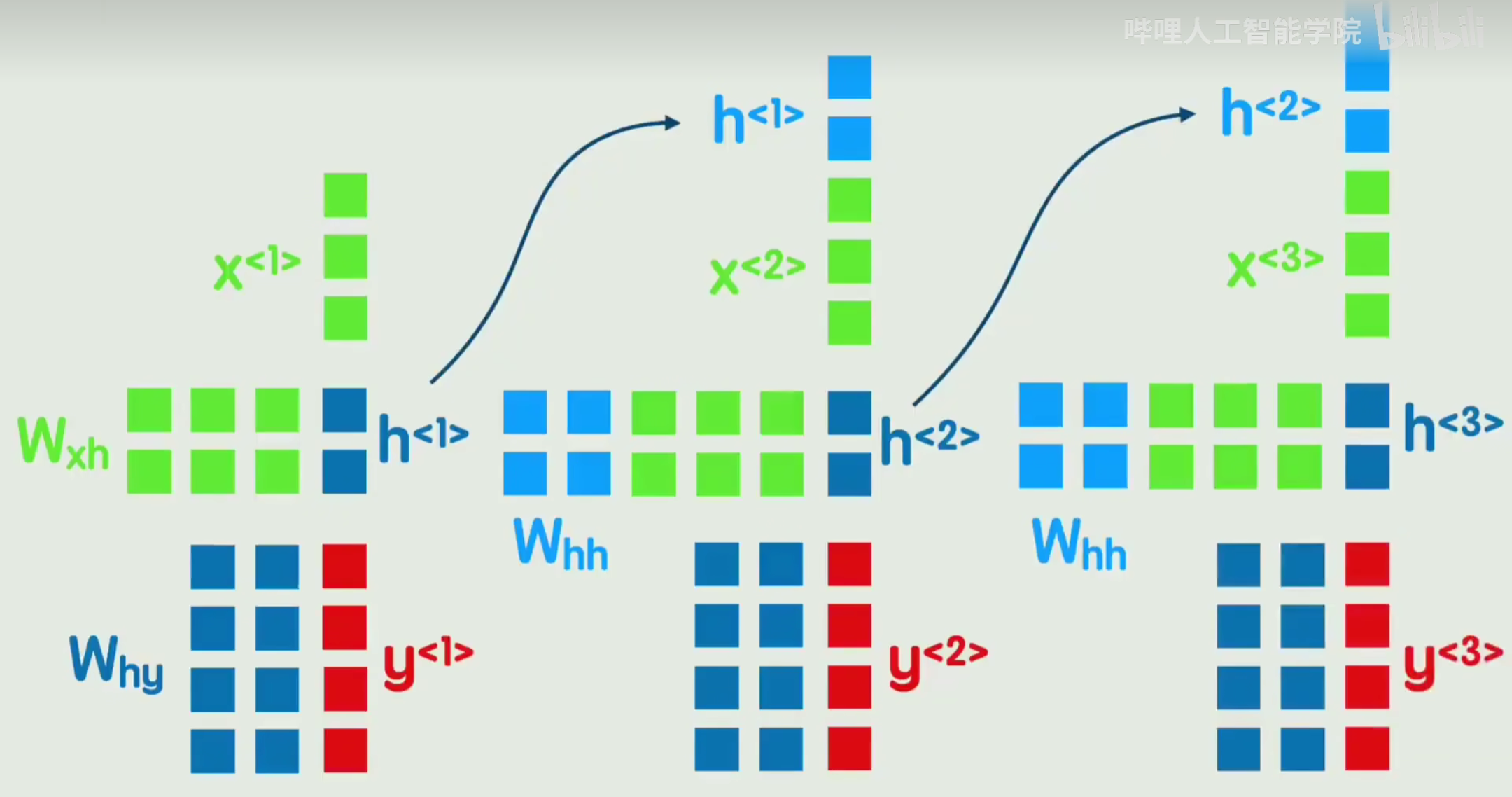
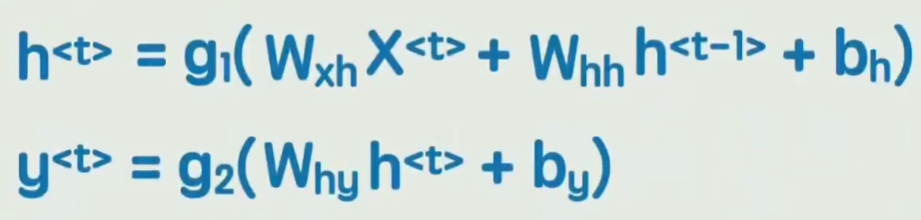
Wxh输入X到隐藏状态h的权重;
Whh上一时刻隐藏状态到当前时刻的权重(实现 "记忆传递");
Why隐藏状态h到输出Y的权重。